The Effect of Evidence Transfer on Latent Feature Relevance for Clustering

 ,
, 
Abstract
:1. Introduction
- We provide an information-theoretic interpretation of the effects of evidence transfer on the latent space;
- We study the overall relevance of latent features after the manipulation conducted by evidence transfer;
- We inspect the ranking variations of individual latent features caused by evidence transfer.
Background
2. Materials and Methods
2.1. Evidence Transfer
| Algorithm 1: The evidence transfer method utilised for clustering |
 |
2.2. Information Bottleneck
2.3. Evidence Transfer Interpretation
3. Results
3.1. Experimental Setup
3.1.1. Datasets
3.1.2. Evidence
3.1.3. Metrics
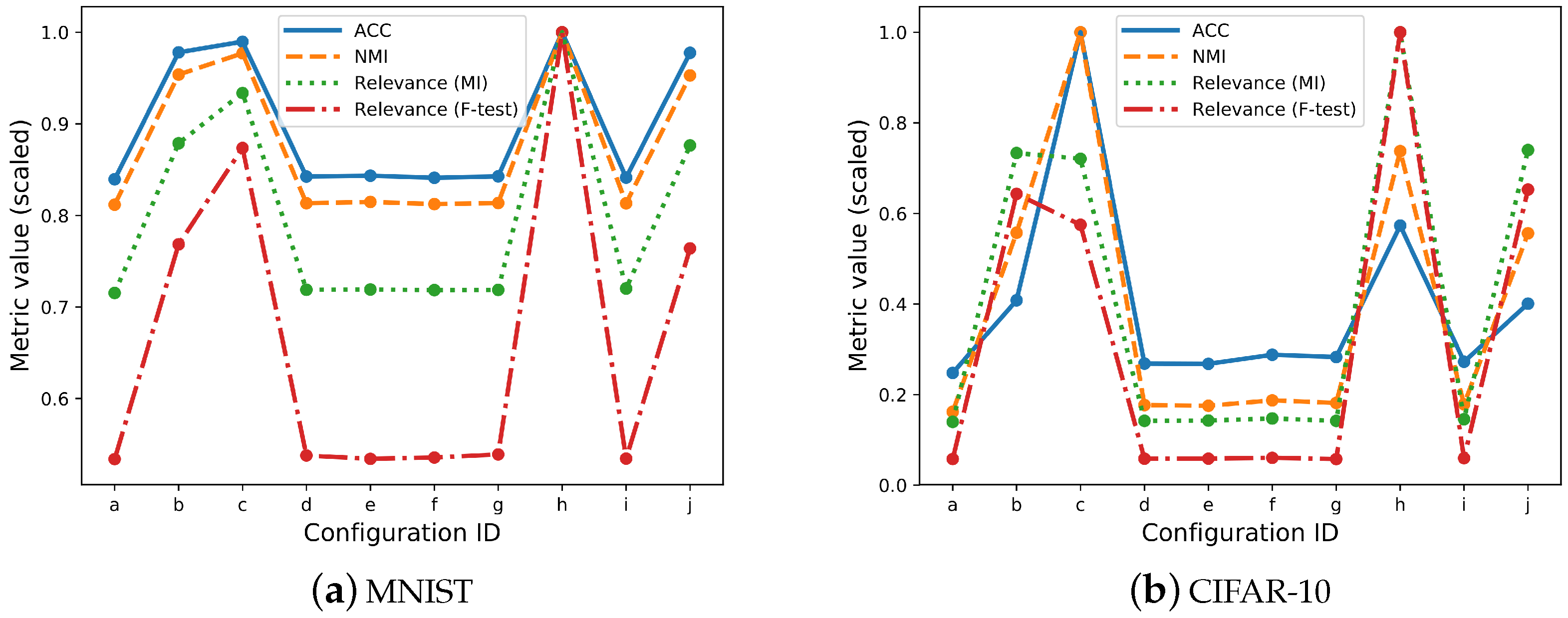
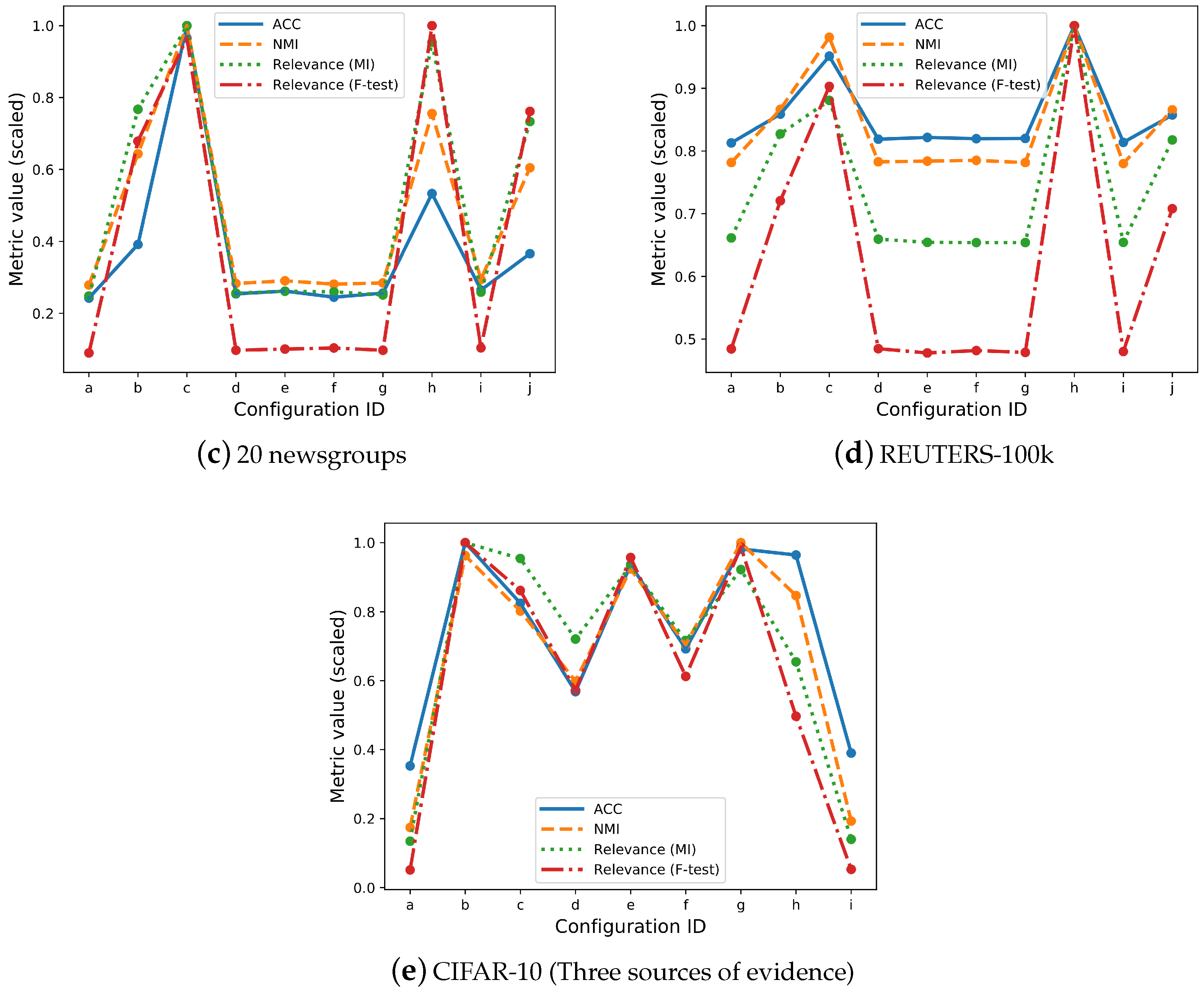
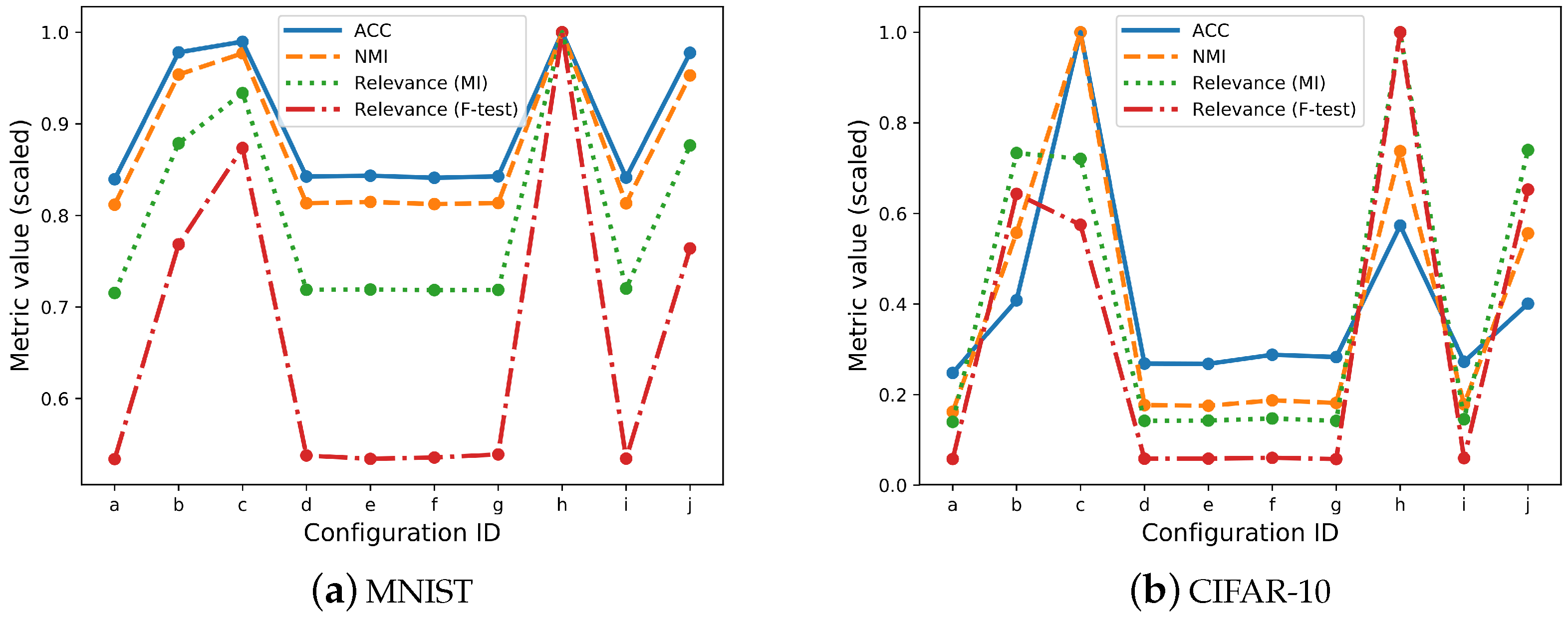
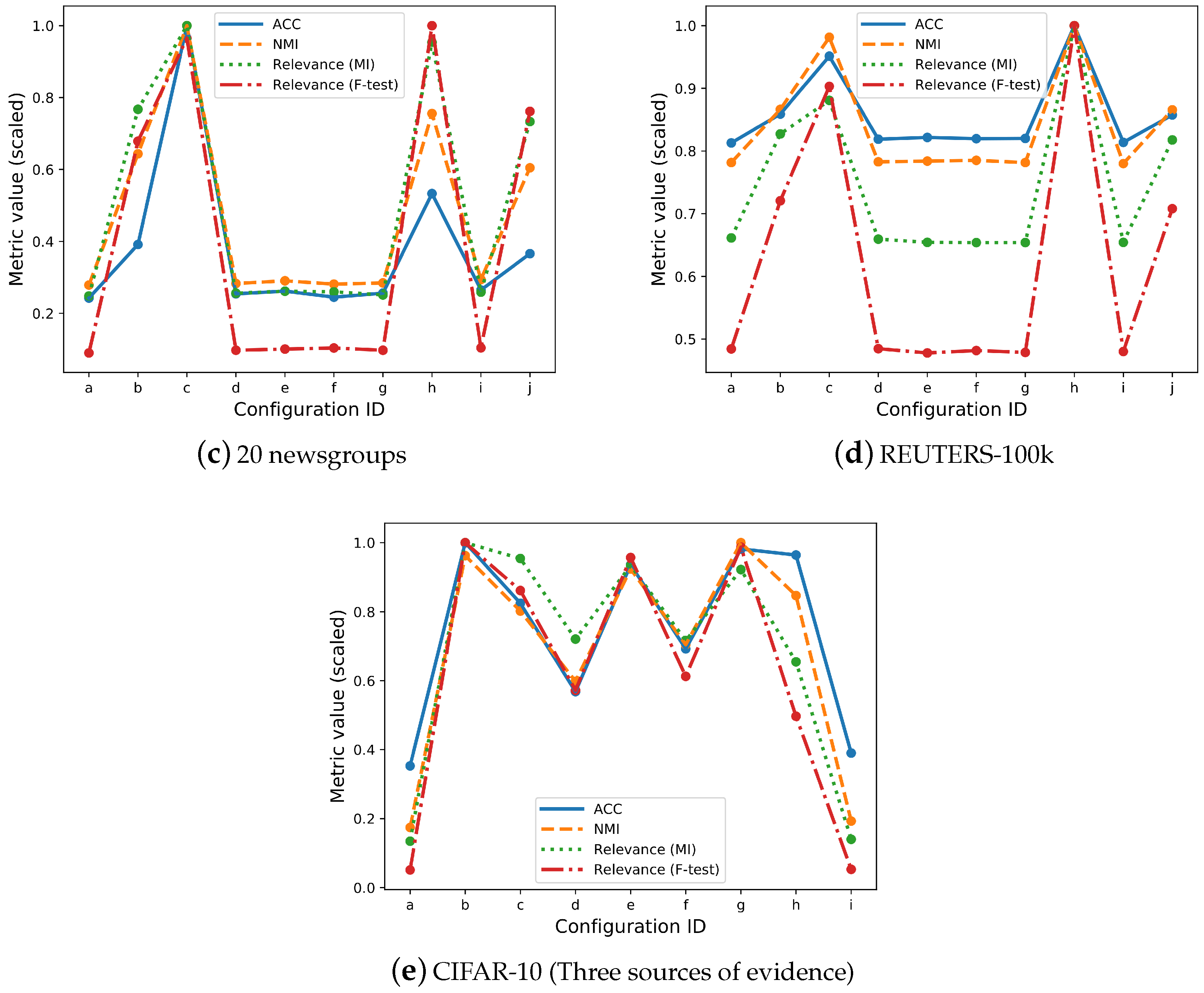
3.2. Overall Relevance
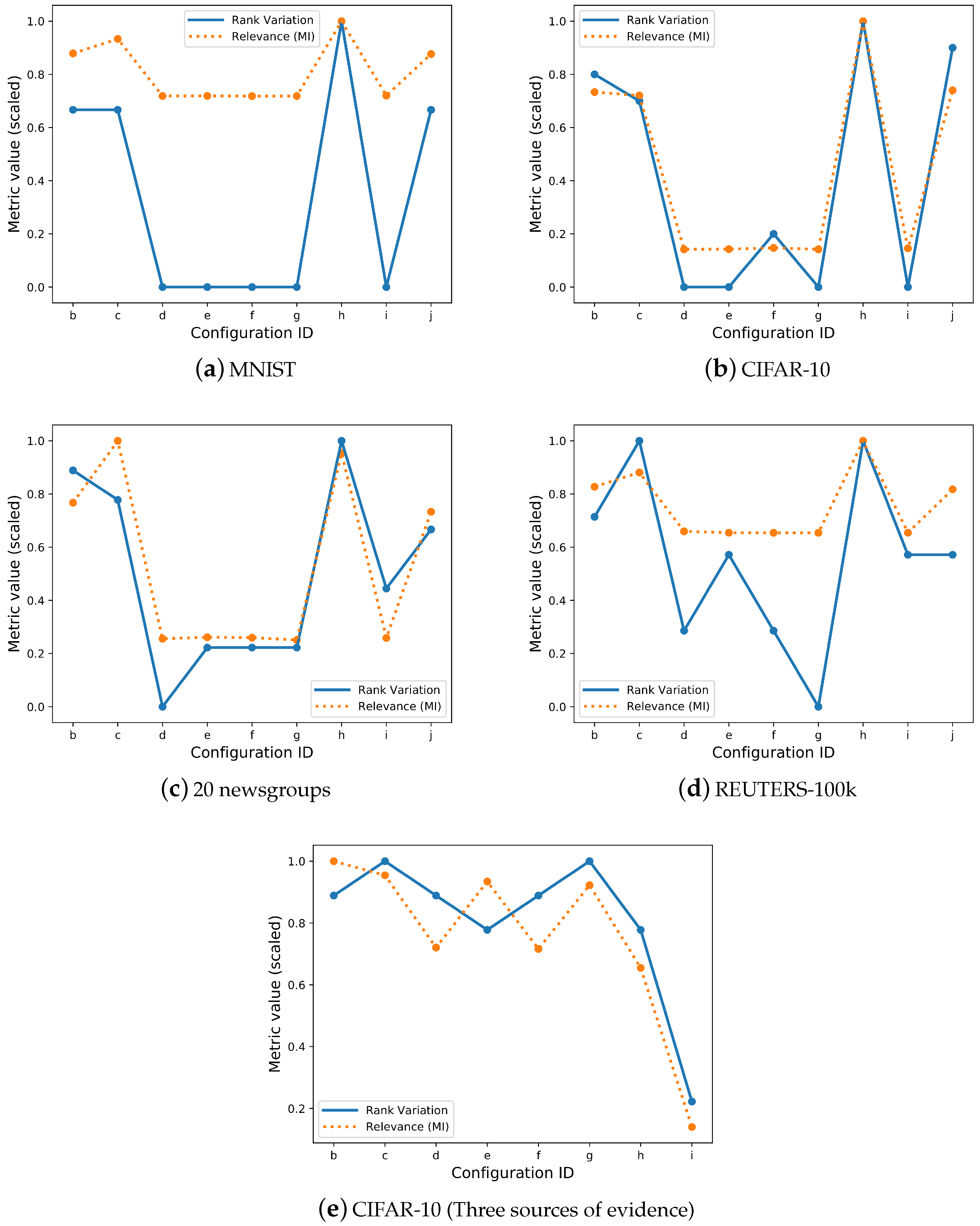
3.3. Individual Latent Feature Relevance
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| VAE | Variational AutoEncoder |
References
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. 2019. Available online: https://openai.com/blog/better-language-models (accessed on 30 March 2019).
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Jiang, Z.; Zheng, Y.; Tan, H.; Tang, B.; Zhou, H. Variational Deep Embedding: An Unsupervised and Generative Approach to Clustering. arXiv 2017, arXiv:1611.05148. [Google Scholar]
- Caruana, R.; Lou, Y.; Gehrke, J.; Koch, P.; Sturm, M.; Elhadad, N. Intelligible Models for HealthCare: Predicting Pneumonia Risk and Hospital 30-day Readmission. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; ACM: New York, NY, USA, 2015; pp. 1721–1730. [Google Scholar]
- Marasco, E.; Wild, P.; Cukic, B. Robust and interoperable fingerprint spoof detection via convolutional neural networks. In Proceedings of the 2016 IEEE Symposium on Technologies for Homeland Security (HST), Waltham, MA, USA, 10–11 May 2016; pp. 1–6. [Google Scholar]
- Lipton, Z.C. The Mythos of Model Interpretability. Queue 2018, 16, 30:31–30:57. [Google Scholar] [CrossRef]
- Samek, W.; Wiegand, T.; Müller, K.R. Explainable Artificial Intelligence: Understanding, Visualizing and Interpreting Deep Learning Models. arXiv 2017, arXiv:1708.08296. [Google Scholar]
- Davvetas, A.; Klampanos, I.A.; Karkaletsis, V. Evidence Transfer for Improving Clustering Tasks Using External Categorical Evidence. arXiv 2018, arXiv:1811.03909v2. [Google Scholar]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. arXiv 2000, arXiv:physics/0004057. [Google Scholar]
- Peng, H.; Long, F.; Ding, C.H.Q. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Dobbins, C.; Rawassizadeh, R. Towards Clustering of Mobile and Smartwatch Accelerometer Data for Physical Activity Recognition. Informatics 2018, 5, 29. [Google Scholar] [CrossRef]
- Mansbridge, N.; Mitsch, J.; Bollard, N.; Ellis, K.; Miguel-Pacheco, G.G.; Dottorini, T.; Kaler, J. Feature Selection and Comparison of Machine Learning Algorithms in Classification of Grazing and Rumination Behaviour in Sheep. Sensors 2018, 18, 3532. [Google Scholar] [CrossRef]
- Ruangkanokmas, P.; Achalakul, T.; Akkarajitsakul, K. Deep Belief Networks with Feature Selection for Sentiment Classification. In Proceedings of the 2016 7th International Conference on Intelligent Systems, Modelling and Simulation (ISMS), Bangkok, Thailand, 25–27 January 2016; pp. 9–14. [Google Scholar]
- Schreyer, M.; Sattarov, T.; Borth, D.; Dengel, A.; Reimer, B. Detection of Anomalies in Large Scale Accounting Data using Deep Autoencoder Networks. arXiv 2017, arXiv:1709.05254. [Google Scholar]
- Nezhad, M.Z.; Zhu, D.; Li, X.; Yang, K.; Levy, P. SAFS: A deep feature selection approach for precision medicine. In Proceedings of the 2016 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Shenzhen, China, 15–18 December 2016; pp. 501–506. [Google Scholar]
- Ibrahim, R.; Yousri, N.; Ismail, M.; M El-Makky, N. Multi-level gene/MiRNA feature selection using deep belief nets and active learning. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 3957–3960. [Google Scholar]
- Taherkhani, A.; Cosma, G.; McGinnity, T.M. Deep-FS: A feature selection algorithm for Deep Boltzmann Machines. Neurocomputing 2018, 322, 22–37. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Li, Y.; Chen, C.Y.; Wasserman, W.W. Deep Feature Selection: Theory and Application to Identify Enhancers and Promoters; Research in Computational Molecular Biology; Przytycka, T.M., Ed.; Springer International Publishing: Cham, Switzerland, 2015; pp. 205–217. [Google Scholar]
- Chang, C.; Rampásek, L.; Goldenberg, A. Dropout Feature Ranking for Deep Learning Models. arXiv 2017, arXiv:1712.08645. [Google Scholar]
- Tabakhi, S.; Moradi, P. Relevance–redundancy feature selection based on ant colony optimization. Pattern Recognit. 2015, 48, 2798–2811. [Google Scholar] [CrossRef]
- Roffo, G.; Melzi, S.; Cristani, M. Infinite Feature Selection. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 4202–4210. [Google Scholar]
- Roffo, G.; Melzi, S.; Castellani, U.; Vinciarelli, A. Infinite Latent Feature Selection: A Probabilistic Latent Graph-Based Ranking Approach. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1407–1415. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Tishby, N. Opening the Black Box of Deep Neural Networks via Information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Burgess, C.P.; Higgins, I.; Pal, A.; Matthey, L.; Watters, N.; Desjardins, G.; Lerchner, A. Understanding disentangling in β-VAE. arXiv 2018, arXiv:1804.03599. [Google Scholar]
- Alemi, A.; Fischer, I.; Dillon, J.; Murphy, K. Deep Variational Information Bottleneck. arXiv 2017, arXiv:1612.00410. [Google Scholar]
- Alemi, A.A.; Fischer, I.; Dillon, J.V. Uncertainty in the Variational Information Bottleneck. arXiv 2018, arXiv:1807.00906. [Google Scholar]
- Achille, A.; Soatto, S. Information Dropout: Learning Optimal Representations Through Noisy Computation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2897–2905. [Google Scholar] [CrossRef]
- Mosca, A.; Magoulas, G.D. Distillation of Deep Learning Ensembles as a Regularisation Method. In Advances in Hybridization of Intelligent Methods: Models, Systems and Applications; Hatzilygeroudis, I., Palade, V., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 97–118. [Google Scholar]
- Mosca, A.; Magoulas, G.D. Customised ensemble methodologies for deep learning: Boosted Residual Networks and related approaches. Neural Comput. Appl. 2018. [Google Scholar] [CrossRef]
- Bengio, Y.; Yao, L.; Alain, G.; Vincent, P. Generalized Denoising Auto-encoders As Generative Models. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Curran Associates Inc.: Red Hook, NY, USA, 2013; Volume 1, pp. 899–907. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised Deep Embedding for Clustering Analysis. arXiv 2016, arXiv:1511.06335. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Lang, K. Newsweeder: Learning to filter netnews. In Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995; pp. 331–339. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Lewis, D.D.; Yang, Y.; Rose, T.G.; Li, F. RCV1: A New Benchmark Collection for Text Categorization Research. J. Mach. Learn. Res. 2004, 5, 361–397. [Google Scholar]
- Ross, B.C. Mutual Information between Discrete and Continuous Data Sets. PLoS ONE 2014, 9, e87357. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Ding, C.; Peng, H. Minimum Redundancy Feature Selection from Microarray Gene Expression Data. In Proceedings of the IEEE Computer Society Conference on Bioinformatics, Stanford, CA, USA, 11–14 August 2003; IEEE Computer Society: Washington, DC, USA, 2003. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| ID | Configuration | Relevance (MI) | Relevance (F-Test) | Rank Variation | ACC | NMI |
|---|---|---|---|---|---|---|
| (a) | Baseline | 0.473 | 0.247 | - | 0.820 | 0.763 |
| (b) | Real evidence (w: 3) | 0.582 | 0.356 | 0.4 | 0.956 | 0.896 |
| (c) | Real evidence (w: 10) | 0.618 | 0.405 | 0.4 | 0.967 | 0.918 |
| (d) | White noise (w: 3) | 0.476 | 0.249 | 0 | 0.823 | 0.764 |
| (e) | White noise (w: 10) | 0.476 | 0.247 | 0 | 0.824 | 0.765 |
| (f) | Random index (w: 3) | 0.476 | 0.248 | 0 | 0.822 | 0.763 |
| (g) | Random index (w: 10) | 0.476 | 0.250 | 0 | 0.823 | 0.764 |
| (h) | Real (w: 3) + Real (w: 4) | 0.662 | 0.463 | 0.6 | 0.977 | 0.939 |
| (i) | Noise (w: 3) + Noise (w: 10) | 0.477 | 0.248 | 0 | 0.822 | 0.764 |
| (j) | Real (w: 3) + Noise (w: 3) | 0.580 | 0.354 | 0.4 | 0.955 | 0.895 |
| ID | Configuration | Relevance (MI) | Relevance (F-Test) | Rank Variation | ACC | NMI |
|---|---|---|---|---|---|---|
| (a) | Baseline | 0.112 | 0.039 | - | 0.228 | 0.134 |
| (b) | Real evidence (w: 3) | 0.586 | 0.435 | 0.8 | 0.375 | 0.463 |
| (c) | Real evidence (w: 10) | 0.576 | 0.388 | 0.7 | 0.919 | 0.830 |
| (d) | White noise (w: 3) | 0.113 | 0.039 | 0 | 0.247 | 0.147 |
| (e) | White noise (w: 10) | 0.114 | 0.039 | 0 | 0.246 | 0.145 |
| (f) | Random index (w: 3) | 0.118 | 0.041 | 0.2 | 0.265 | 0.155 |
| (g) | Random index (w: 10) | 0.113 | 0.039 | 0 | 0.260 | 0.151 |
| (h) | Real (w: 3) + Real (w: 4) | 0.799 | 0.676 | 1 | 0.527 | 0.613 |
| (i) | Noise (w: 3) + Noise (w: 10) | 0.116 | 0.040 | 0 | 0.251 | 0.148 |
| (j) | Real (w: 3) + Noise (w: 3) | 0.591 | 0.441 | 0.9 | 0.368 | 0.462 |
| ID | Configuration | Relevance (MI) | Relevance (F-Test) | Rank Variation | ACC | NMI |
|---|---|---|---|---|---|---|
| (a) | Baseline | 0.282 | 0.052 | - | 0.212 | 0.250 |
| (b) | Real evidence (w: 5) | 0.871 | 0.390 | 0.8 | 0.342 | 0.578 |
| (c) | Real evidence (w: 20) | 1.136 | 0.554 | 0.7 | 0.875 | 0.898 |
| (d) | White noise (w: 3) | 0.290 | 0.056 | 0 | 0.222 | 0.254 |
| (e) | White noise (w: 10) | 0.297 | 0.058 | 0.2 | 0.229 | 0.261 |
| (f) | Random index (w: 5) | 0.295 | 0.059 | 0.2 | 0.214 | 0.253 |
| (g) | Random index (w: 20) | 0.285 | 0.056 | 0.2 | 0.224 | 0.256 |
| (h) | Real (w: 5) + Real (w: 6) | 1.083 | 0.574 | 0.9 | 0.466 | 0.679 |
| (i) | Noise (w: 3) + Noise (w: 10) | 0.294 | 0.060 | 0.4 | 0.232 | 0.264 |
| (j) | Real (w: 5) + Noise (w: 3) | 0.833 | 0.438 | 0.6 | 0.320 | 0.543 |
| ID | Configuration | Relevance (MI) | Relevance (F-Test) | Rank Variation | ACC | NMI |
|---|---|---|---|---|---|---|
| (a) | Baseline | 0.285 | 0.236 | - | 0.411 | 0.327 |
| (b) | Real evidence (w: 4) | 0.356 | 0.351 | 0.5 | 0.435 | 0.363 |
| (c) | Real evidence (w: 10) | 0.379 | 0.439 | 0.7 | 0.481 | 0.411 |
| (d) | White noise (w: 3) | 0.284 | 0.236 | 0.2 | 0.414 | 0.328 |
| (e) | White noise (w: 10) | 0.282 | 0.232 | 0.4 | 0.416 | 0.328 |
| (f) | Random index (w: 4) | 0.281 | 0.234 | 0.2 | 0.415 | 0.329 |
| (g) | Random index (w: 10) | 0.281 | 0.233 | 0 | 0.415 | 0.327 |
| (h) | Real (w: 4) + Real (w: 5) | 0.430 | 0.486 | 0.7 | 0.506 | 0.419 |
| (i) | Noise (w: 3) + Noise (w: 10) | 0.282 | 0.234 | 0.4 | 0.412 | 0.327 |
| (j) | Real(w: 4) + Noise (w: 3) | 0.352 | 0.344 | 0.4 | 0.434 | 0.362 |
| ID | Configuration | Relevance (MI) | Relevance (F-test) | Rank Variation | ACC | NMI |
|---|---|---|---|---|---|---|
| (a) | Baseline | 0.112 | 0.024 | - | 0.228 | 0.134 |
| (b) | Real (w: 3) + Real (w: 4) + Real (w: 5) | 0.830 | 0.467 | 0.8 | 0.646 | 0.743 |
| (c) | Real (w: 3) + Real (w: 4) + Noise (w: 3) | 0.792 | 0.402 | 0.9 | 0.533 | 0.619 |
| (d) | Real (w: 3) + Noise (w: 3) + Noise (w: 10) | 0.598 | 0.267 | 0.8 | 0.367 | 0.462 |
| (e) | Real (w: 3) + Real (w: 5) + Noise (w: 3) | 0.775 | 0.447 | 0.7 | 0.605 | 0.713 |
| (f) | Real (w: 3) + Noise (w: 3) + Noise (w: 10) | 0.594 | 0.286 | 0.8 | 0.447 | 0.544 |
| (g) | Real (w: 4) + Real (w: 5) + Noise (w: 3) | 0.765 | 0.461 | 0.9 | 0.634 | 0.772 |
| (h) | Real (w: 5) + Noise (w: 3) + Noise (w: 10) | 0.543 | 0.232 | 0.7 | 0.623 | 0.654 |
| (j) | Noise (w: 3) + Noise (w: 10) + Noise (w: 5) | 0.116 | 0.025 | 0.2 | 0.252 | 0.149 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Davvetas, A.; Klampanos, I.A.; Skiadopoulos, S.; Karkaletsis, V. The Effect of Evidence Transfer on Latent Feature Relevance for Clustering. Informatics 2019, 6, 17. https://doi.org/10.3390/informatics6020017
Davvetas A, Klampanos IA, Skiadopoulos S, Karkaletsis V. The Effect of Evidence Transfer on Latent Feature Relevance for Clustering. Informatics. 2019; 6(2):17. https://doi.org/10.3390/informatics6020017
Chicago/Turabian StyleDavvetas, Athanasios, Iraklis A. Klampanos, Spiros Skiadopoulos, and Vangelis Karkaletsis. 2019. "The Effect of Evidence Transfer on Latent Feature Relevance for Clustering" Informatics 6, no. 2: 17. https://doi.org/10.3390/informatics6020017
APA StyleDavvetas, A., Klampanos, I. A., Skiadopoulos, S., & Karkaletsis, V. (2019). The Effect of Evidence Transfer on Latent Feature Relevance for Clustering. Informatics, 6(2), 17. https://doi.org/10.3390/informatics6020017