1. Introduction
In recent years, there has been a new trend in which universities, research institutions and researchers capture, integrate, store and analyze their research information into a research information system (RIS). Other names for the term RIS are current research information system (CRIS), especially in Europe, and RIMS (research information management system), RNS (research networking system) or FAR (faculty activity reporting). The RIS is a central database or federated information system [
1,
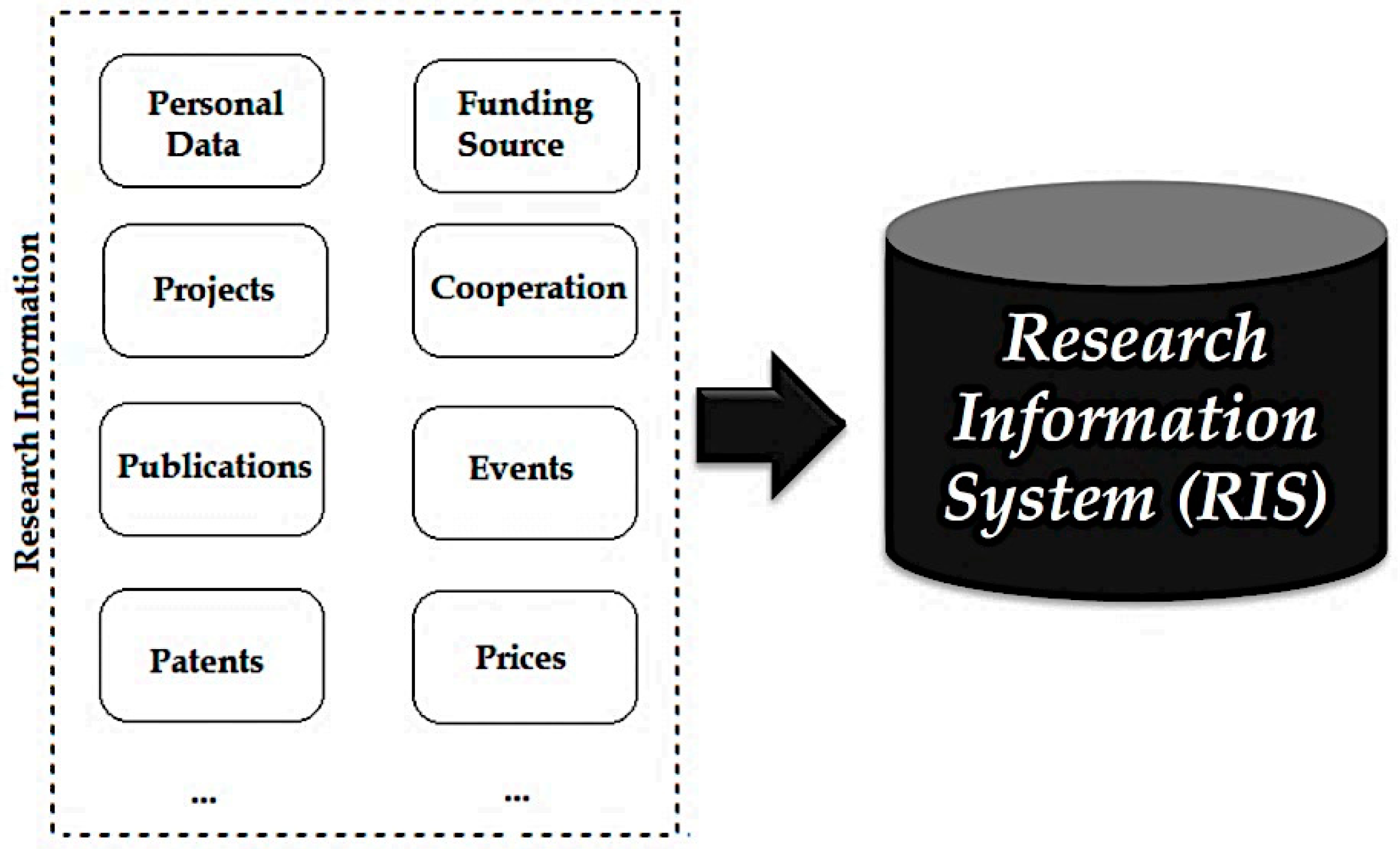
2] that can be used to collect, manage and provide a variety of information about research activities and research results. The information represented here are metadata about an institution’s research activities, e.g., personal data, projects, third-party funds, publications, patents and prizes, etc. and are referred to as research information [
3]. The following
Figure 1 illustrates the type of research information. Further definitions of the term RIS in the literature can be found in the related papers [
4,
5,
6].
For the institutions, it is a useful tool to clearly present their own research profile and thus an effective tool for information management. The unification and facilitation of strategic research reporting creates added value for the administrators, as well as for the scientists. The expense of documenting projects is reduced for the scientists, thus gaining more time for the actual research process. The RIS can also support additional helper functions for scientists: e.g., the creation of CVs and publication lists, or other reuse of the aggregated data from RIS on a website.
The most important decision-making and reporting tools in many institutions are RIS that collectively integrate the data from many heterogeneous and independent information systems. In order to avoid structural and content-related data quality issues and thereby reduce the effective use of research information, the transformation of research information takes place during the integration process. “Data integration improves the usability of data by improving consistency, completeness, accessibility, and other dimensions of data quality” [
7]. Data integration is the correct, complete and efficient merging of data and content from heterogeneous sources into a consistent and structured set of information for effective interpretation by users and applications [
8]. Filling of RIS should already be ensured in good quality as part of the integration process. However, they should be continually defined, measured, analyzed, and improved to increase interoperability with external systems, improve performance and usability, and address data quality issues [
9]. Therefore, investing in the topic of data integration is particularly useful when the achievement of high data quality is paramount [
10]. This is also the case for RIS users and it is expected that decisions based on relevant, complete, correct and current data will increase the chance of getting better results [
11].
The purpose of this paper will be to present the process of data transformation that controls and improves the data quality issues in RIS, to enable institutions to perform in-depth analysis and evaluation on existing or current data, and thus to meet the needs of their decision makers.
The first chapter discusses the causes of data quality issues in RIS that may be responsible for reducing data quality. Subsequently, the phases of the integration process are described in the context of RIS. The chapter concludes with approaches to eliminate data quality issues from external data sources in the transformation phase into RIS.
2. Causes of Data Quality Issues in the Context of Integrating Research Information
Data quality defined as “fitness for use” and its assurance is recognized as a valid and important activity, but in practice only a few people list it the highest priority [
12]. The quality of the data depends to a great extent on the use of data and synergies of customer needs, the usability and the access of data [
13]. Therefore, during evaluating and improving data quality, the involvement of data users and other data groups is important because they play a high role in data entry, data processing, and data analysis [
14]. The subject of data quality should not be considered a one-time action and should therefore be an object of constant care and attention (“quality management”), in order to improve system performance, as well as the user satisfaction and acceptance [
2]. Ensuring effective and long-term data quality increasement requires continuous data quality management.
Data integration is a key issue in data quality and is one of the basic activities to improve the quality of data distributed in independent data sources [
15]. This is because it can reduce both structural and semantic heterogeneity and redundancy, and increase availability and completeness [
15].
Integrating research information with heterogeneous systems into the RIS is a difficult task for the institutions. This is mainly due to the fact that a number of interfaces must be developed in order to allow an exchange of information between the systems [
16] and to solve problems related to the provision of interoperability to information systems by the resolution of the heterogeneity between systems on the level of data [
17].
Poor or dirty research information designates in a RIS that does not meet the required data quality requirement at a given time. Valid research information (good) becomes invalid research information (bad) if it contains erroneous information, distorting research reporting or even causing serious errors in the RIS. These distortions and errors occur because the research information used contains [
2]:
Data quality issues in RIS are generally very diverse, which makes it reasonable to categorize the causes of poor data quality of research information. The causes of data quality issues are in data collection, data transfer, and data integration from the data sources to the RIS. The data sources must be first differentiated into internal and external data sources. Internal data sources are information systems of a research institution that manage internal research information. This includes, in particular, databases of the central administrations (e.g., personnel administration with data on employees, financial accounting with data on projects, income and expenditure and libraries with their data on publications, etc.). External data sources are used in RIS to supplement or replace manual entries. This applies in particular to publications. In many research institutions, scientists have to report their publications. This research information can then be supplemented with external publication databases, and in some cases the research institutions only use external data sources for publication data.
With an increase in various data sources, systems and interfaces in the research management process, the likelihood of data quality issues increases as well. When collecting research information, user errors (such as wrong spelling, missing input, incomplete, incorrect and non-current recording, etc.) are covered. The causes of input errors are a potential source of errors not only for administrators who edit incurred research information accumulated in the institutions. The causer could also be the supporting software systems used, which make false inputs. Reasons for the occurrence of data quality issues are also format differences or conversion errors, etc.
When transferring different heterogeneous systems with different standardized exchange formats (e.g., the Common European Research Information Format [CERIF] data model and the German Research Core Dataset [RCD] data model) in a RIS, new data quality issues may also arise. Particularly problematic is the erroneous mapping of research information from the sources to the RIS [
18]. However, the heterogeneity of information systems and their schemas often requires a more expressive mapping language, because the relationships between different data models cannot be captured by simple links with semantics like “sameAs” or “isSimilarTo” [
18].
If semantic errors occur, research information can lose all of its informational content, representing a wrong or incomplete part of reality in RIS. This is one of the biggest challenges of integrating research information. Detailed information on these problems and the solution can be found in the related paper [
19].
Another common cause of data inconsistency in RIS is that the research information exists in different data models and structures and is collected independently. To define the unified interface, an integrated schema must be designed that covers all aspects of each database and summarizes common aspects [
20].
When developing source data systems, there are a variety of error characteristics, e.g., poor database design, in which referential integrity, as well as dependencies and uniqueness, have not received enough attention, e.g., duplicate key IDs are not considered in the case of incorrect modelling, which can lead to massive problems when they are used in a RIS, which can enormously increase the cost of integration or even jeopardize the overall integrity of the data source system [
21].
The explained causes of insufficient research information clarify the complexity of data quality issues in the daily work of the RIS. But they are just starting points where such causes can be detected in universities and research institutions and so focus on treatment centers of data quality issues. Where just the elimination of the causes promise better data quality of research information. Universities and research institutions face this huge challenge because the biggest impact of poor data quality is usually the cost of strategic mismanagement by research management due to erroneous data.
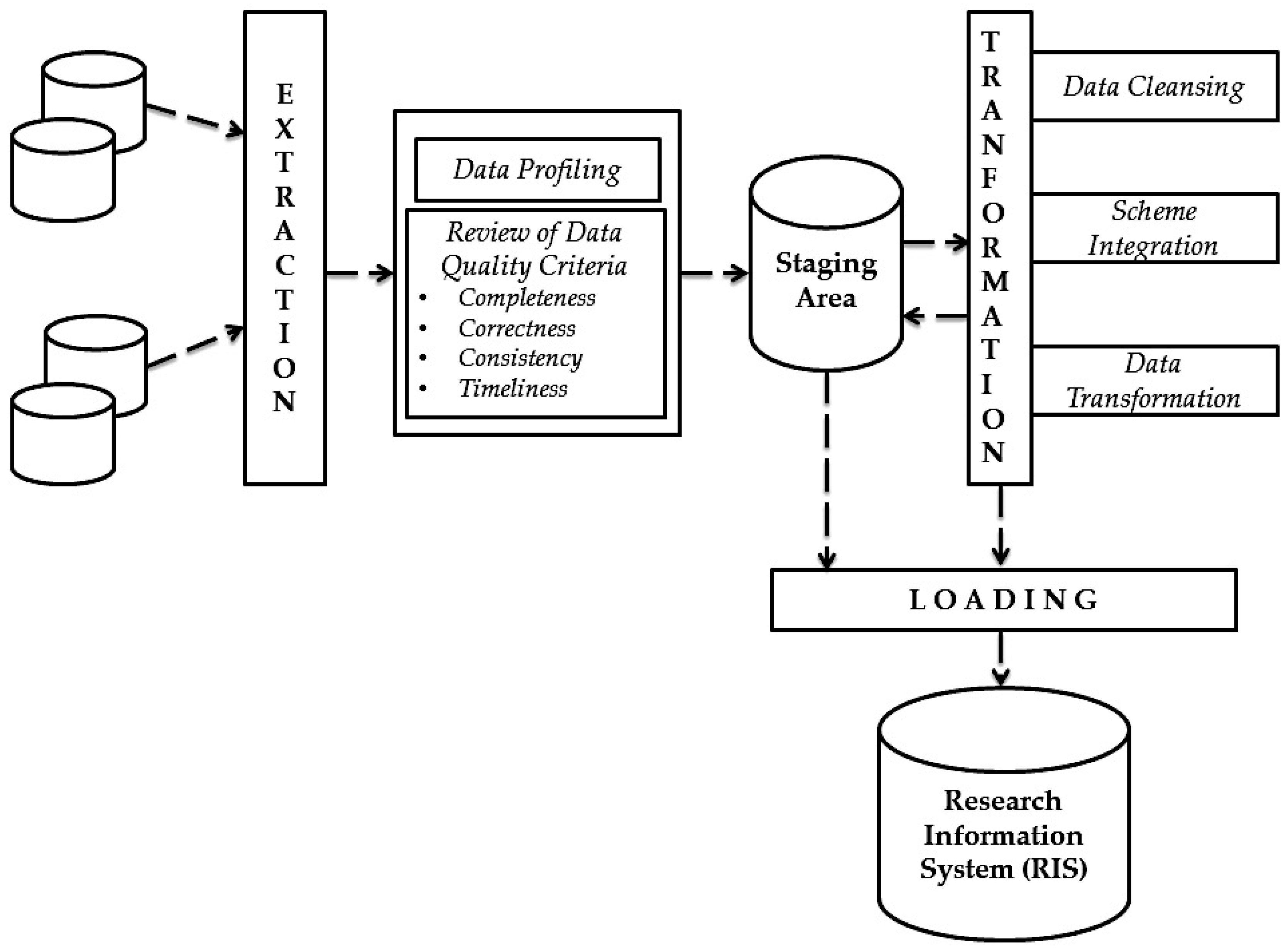
3. Integration of Research Information—Extraction, Transformation and Load (ETL)
The volume of data in universities and research institutes is constantly growing, and at the same time, the need to analyze a consistent view increases. Analyzes are intended to provide insights into operational research management as well as help with decision-making in strategic planning and control. In a RIS, research information from all the relevant data sources and information systems (this level contains, for example, databases from the administration) of an institution is brought together and kept in a uniform schema. The filling of RIS takes place via the ETL process. A variety of definitions and explanations of this term can be found in [
22,
23].
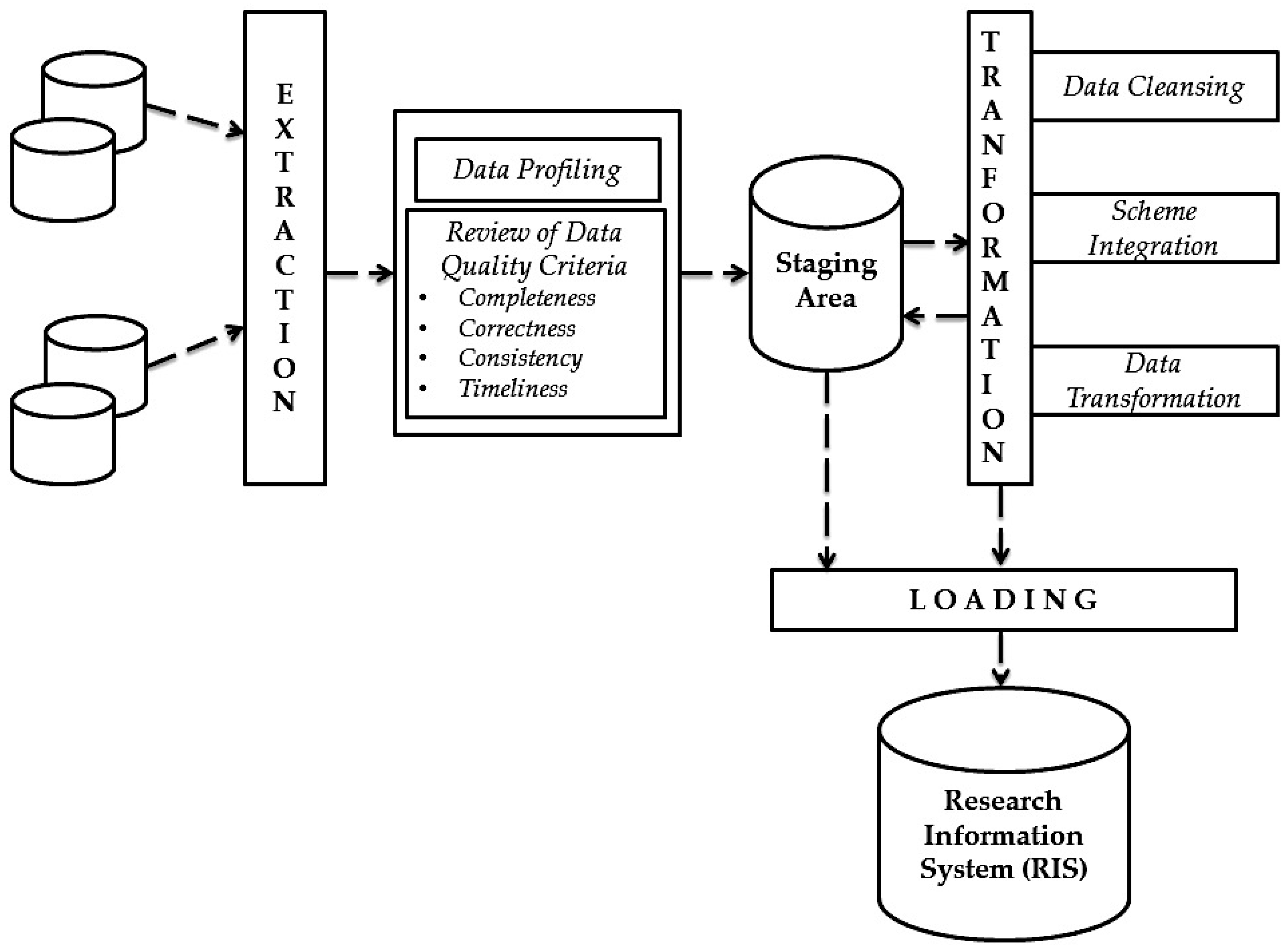
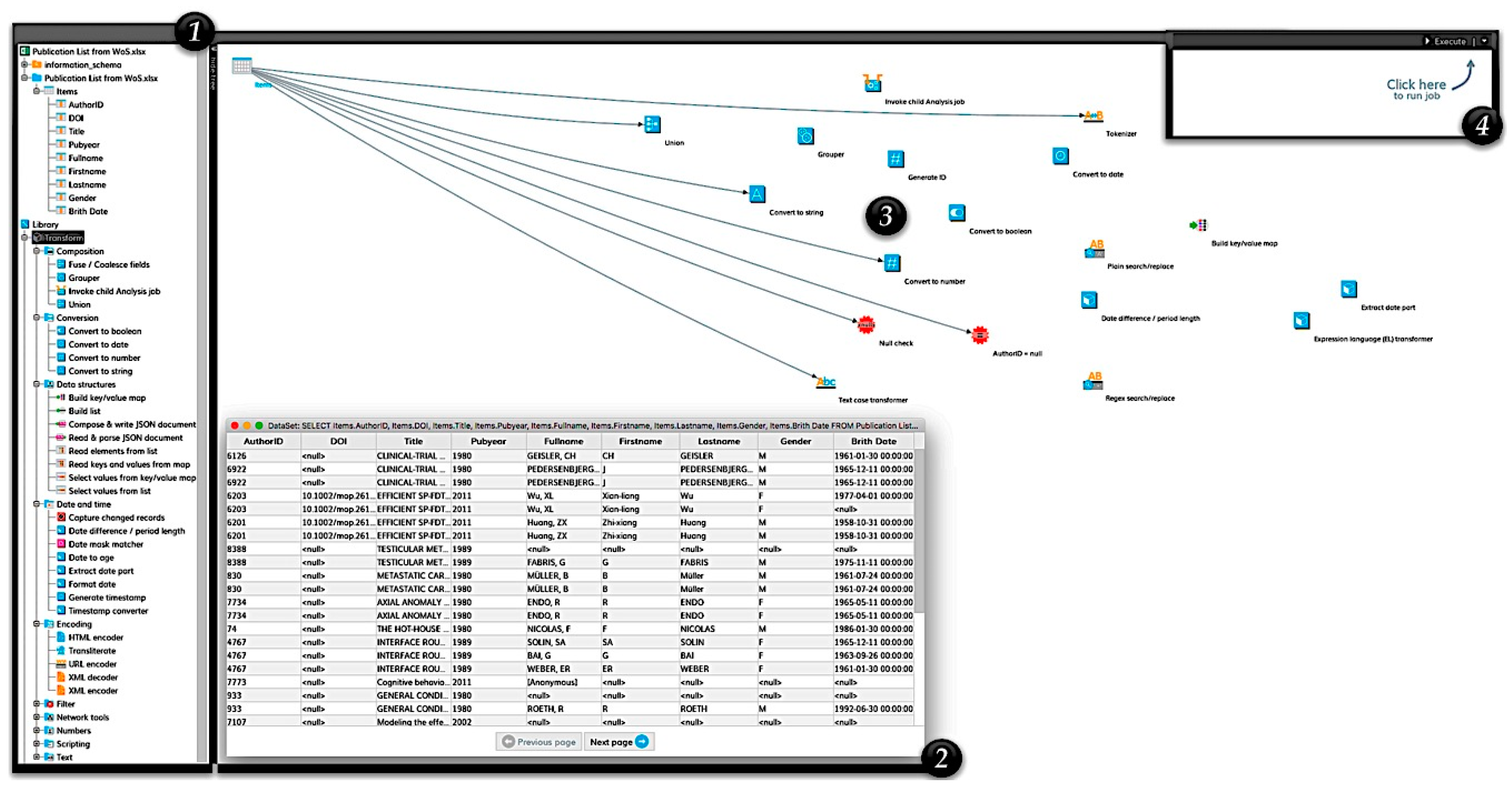
During an ETL process, data is first extracted from source systems. In the following transformation phase, data is cleaned up, processed, and transformed into the target schema. Subsequently, during the loading phase, the previously extracted and transformed data are written to the target system, e.g., RIS. This process is the same as transferring enterprise data to the data warehouse. ETL processes generally play an important role in data integration and are used wherever data from different source systems must be transferred to other data storage systems and adapted to new requirements. The research institutions can either program the ETL processes or can be developed and executed with the help of tools. Due to the high complexity of ETL processes, the use of a tool is highly recommended in most cases [
24]. The process of the ETL knowledge recognition process from the integrated data sources in the context of RIS is illustrated by the following
Figure 2.
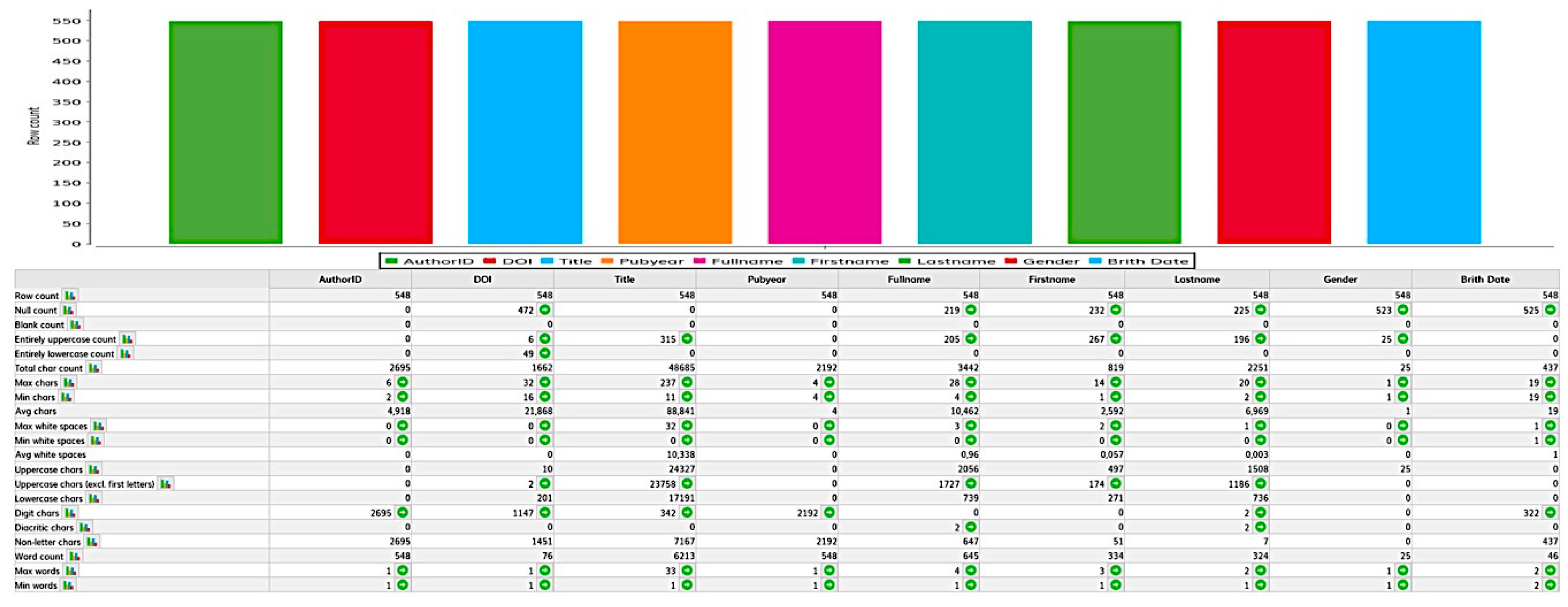
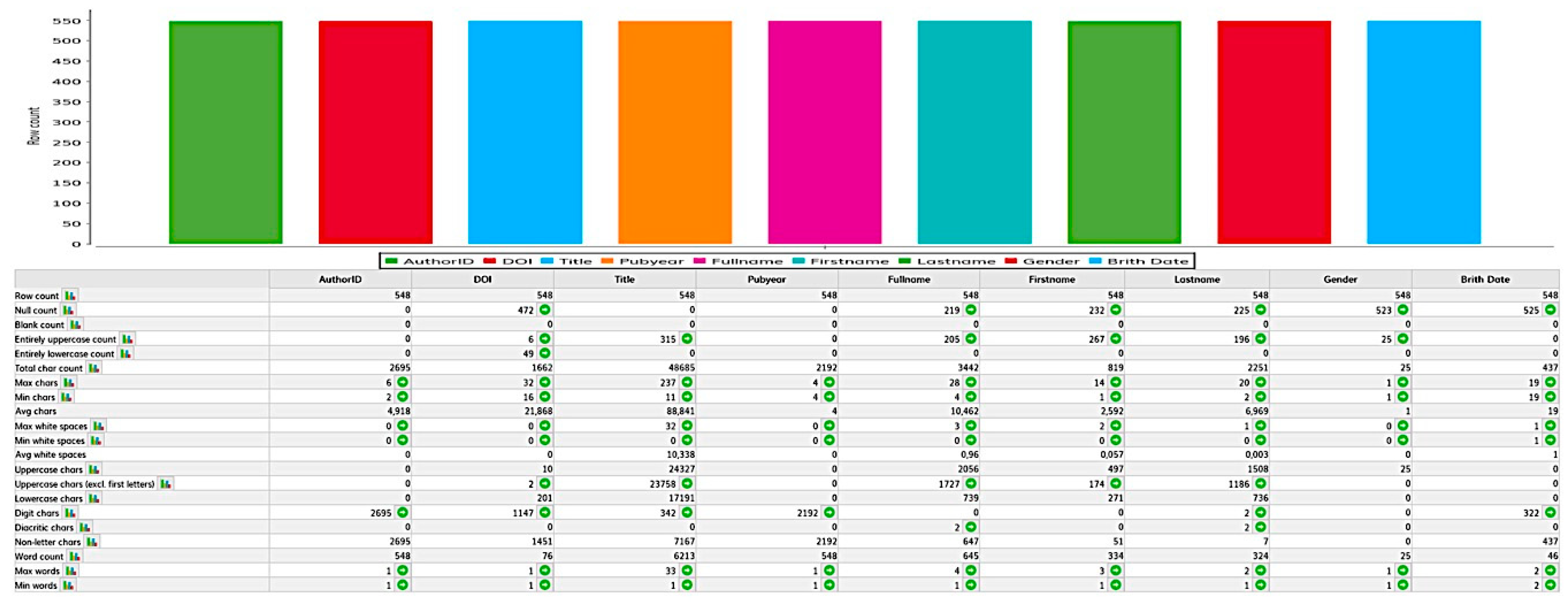
The first step of the ETL process is extraction. In this initial step, a portion of the research information from the sources is usually extracted and provided for transformation. The sources can consist of different information systems with different data formats and data structures. Before the actual extraction, the relevant sources and research information must be identified and selected. Different factors play a role in selection. On the one hand, the quality of research information must be taken into account. For external data sources, this can fluctuate and thus not always be guaranteed in the long term. Once the relevant data has been identified, it must be analyzed during data profiling and checked for its technical quality. Detailed information on data profiling in the context of RIS can be found in the related paper [
25].
Research information from an institution usually needs to be available for different application and usage scenarios. Therefore, it is necessary to define and verify application-dependent quality criteria that can be assessed by appropriate metrics. In the context of RIS, only the four data quality criteria (completeness, correctness, consistency and timeliness) and their corresponding metrics are considered because they are used intensively in scientific institutions to check and measure their data quality.
Table 1 shows a quality criteria model for measuring research information in RIS during the ETL process.
The four selected metrics have been found to be easy to measure. In addition, a particularly representative illustration of the reporting for the RIS users and provide an improved basis for decision-making [
1]. Detailed information on measuring data quality in RIS can be found in the related paper [
1].
These criteria can be used to define requirements for data quality from different stakeholders (in particular from RIS users or RIS administrators) that must be met in order to select the research information.
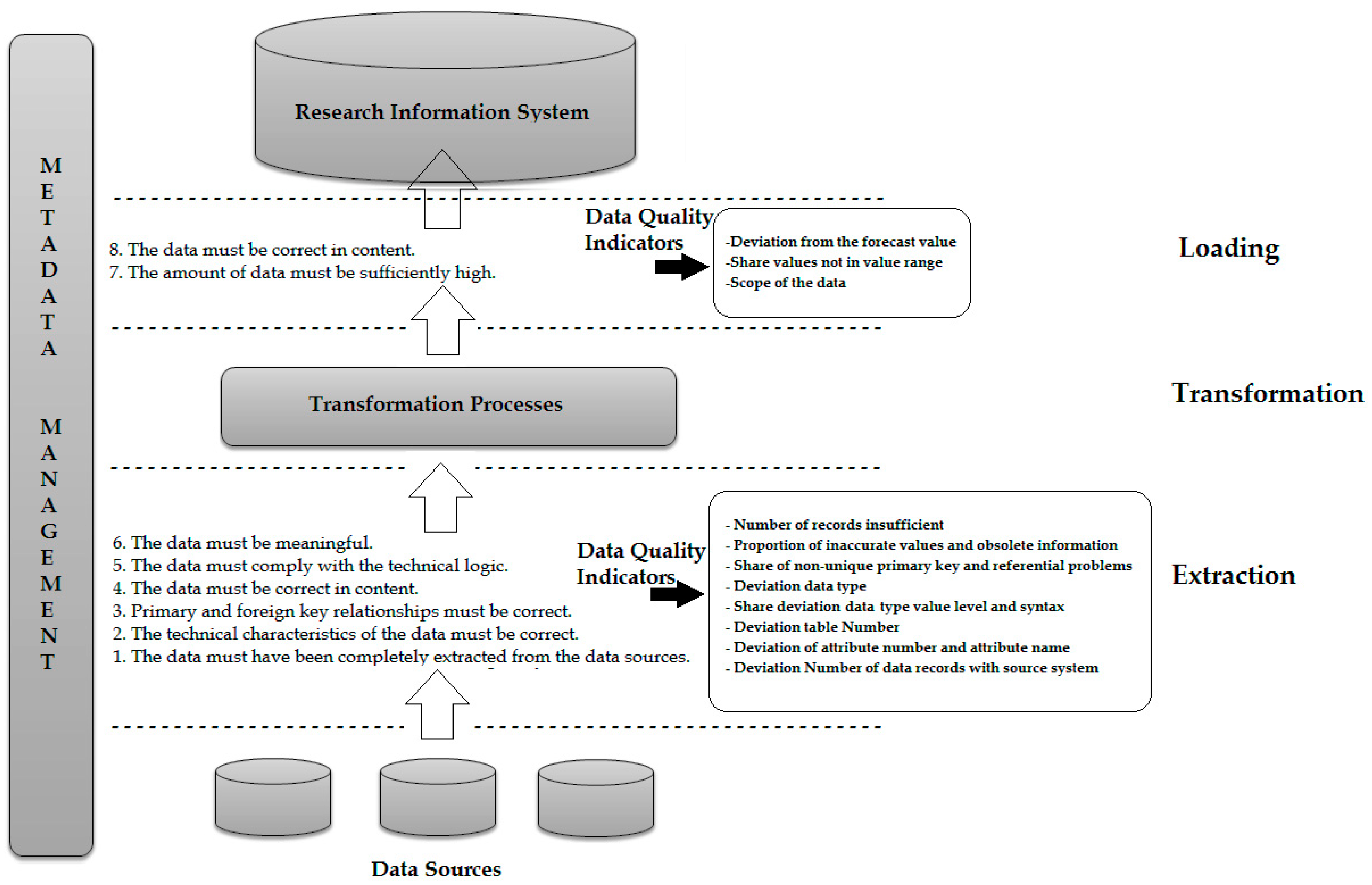
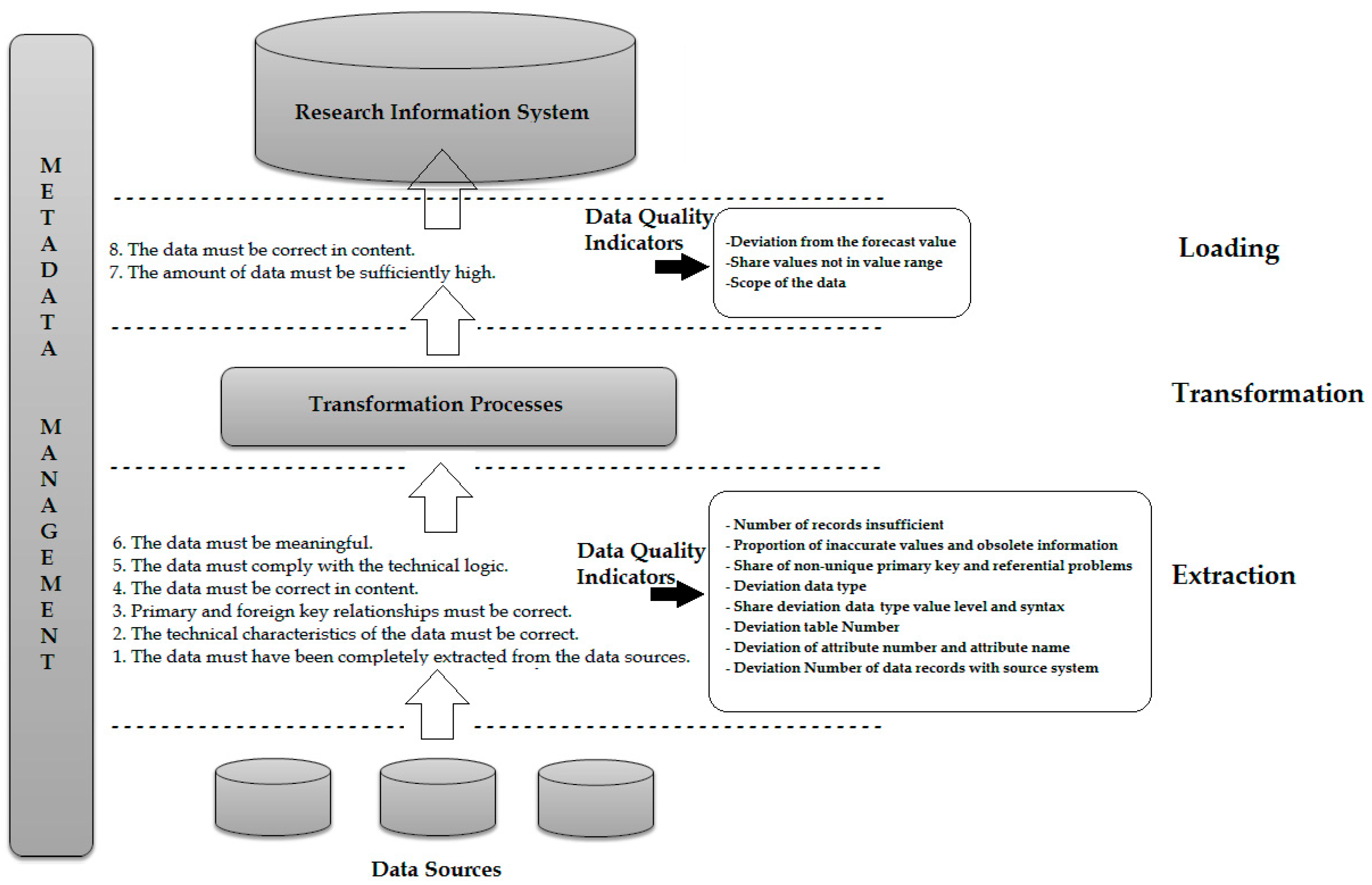
Figure 3 demonstrates these requirements with their possible data quality metrics in the context of RIS, which provide quality criteria determined in the ETL process.
Data quality issues from the operational systems are detected early in the extraction layer to allow early intervention in the time-consuming ETL process. In the requirements for the content correctness, completeness, consistency and timeliness of the data, however, a new calculation of the data quality indicators in the loading layer makes sense. For example, these data quality indicators from the requirement for content correctness are derived, e.g., “share values not in value list”, “proportion of inaccurate values” or “proportion of outdated information”. These indicators are calculated in the loading layer for data that has been newly created as part of the transformation process. Thus, the substantive correctness of the underlying data can be checked a second time. Furthermore, transformation processes can increase/reduce the amount of data. Therefore, it is important to check if there is enough data after the transformation. In the transformation phase of the ETL process, measures can be made to improve data quality. There are exactly four measures that can be taken subsequently [
24]:
Pass the entry without error (ignore),
Pass the entry and mark the affected column (flag),
Discard/sort out the entry (detect/extract),
Stop the ETL flow (raise critical error).
The potential for improving data quality must therefore be considered when selecting research information. After the selection of the research information to be extracted, these are loaded into a so-called staging area. Staging improves the reliability of the ETL process, allowing ETL processes that maintain the research information in a staging area to be rebooted in the event of a failure without re-accessing the data sources [
24].
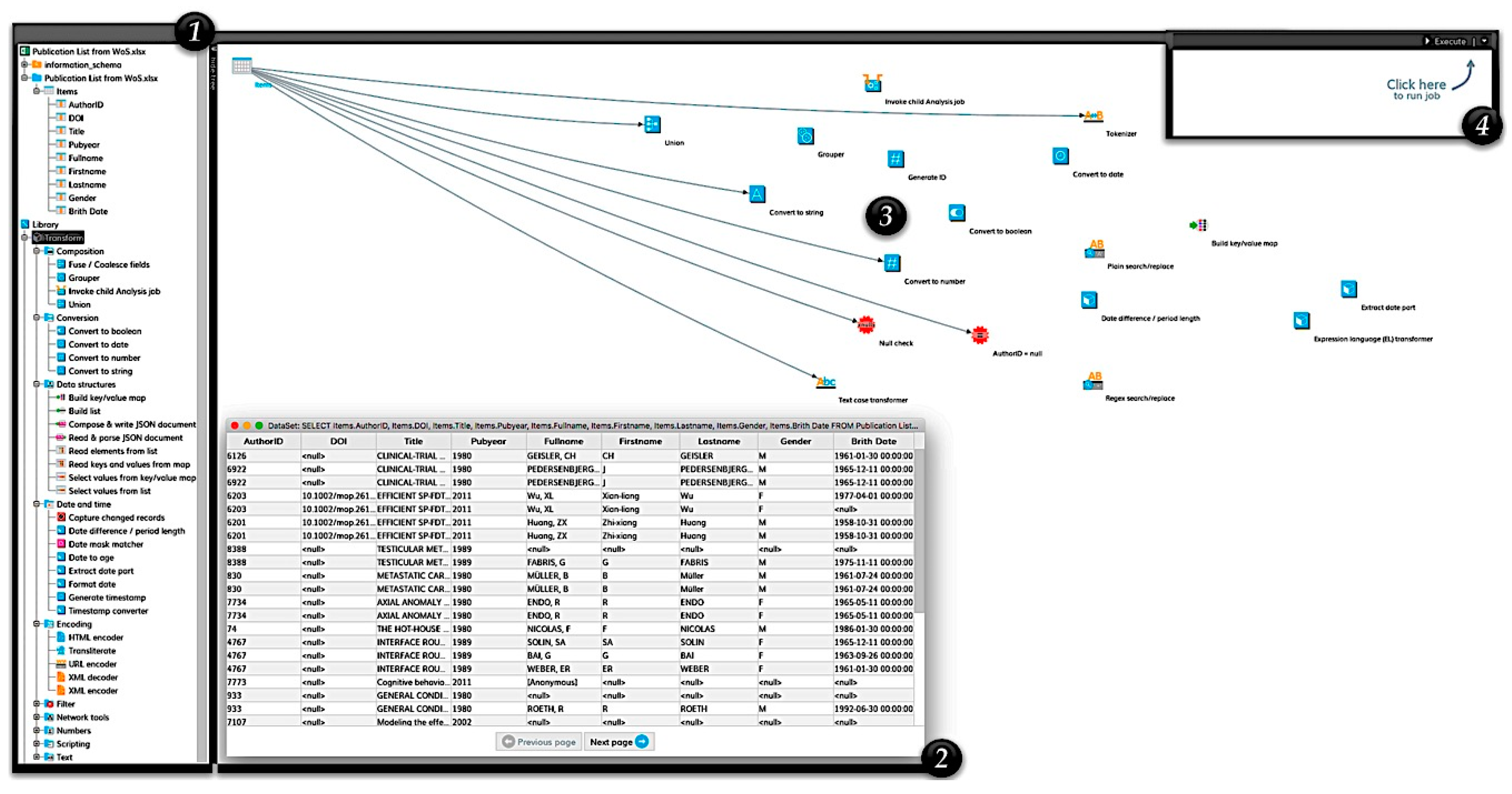
The next step in data integration is the transformation of research information. During the transformation phase, the processing of the research information takes place. This occurs in three sub-phases: data cleansing, schema integration, and data transformation. Detailed information on these phases using the standards of research information (e.g., European CERIF and German RCD) can be found in the related paper [
19].
When cleaning up research information, incorrect source data is treated. This is necessary because they could distort the results of the analyzes carried out on the research information. Data cleansing can use a variety of specialized methods (such as parsing, standardization, enhancement, matching, and consolidation) to eliminate errors when integrating multiple data sources. Detailed information on the cleansing of research information can be found in the related paper [
3].
Since the data sources come from different operational systems, they are often schematic-heterogeneous. For integration into the RIS, however, these must be converted into a uniform scheme. After the data sources are cleaned up and transformation rules for schema integration are defined, transformations can be defined that adapt and expand the research information according to the requirements of the RIS. After performing all transformations, the loading phase follows. In the final step of the ETL process (loading phase), the adjusted and transformed research information is written to the RIS. Thereafter, the research information can already be used for the RIS analyzes.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}