Modeling Analytical Streams for Social Business Intelligence


Abstract
1. Introduction
- We present a comprehensive revision of the main methods proposed for Social Business Intelligence.
- We propose a streaming architecture specially aimed at Social Business Intelligence.
- We propose a new method to model analytical streams for Social Business Intelligence.
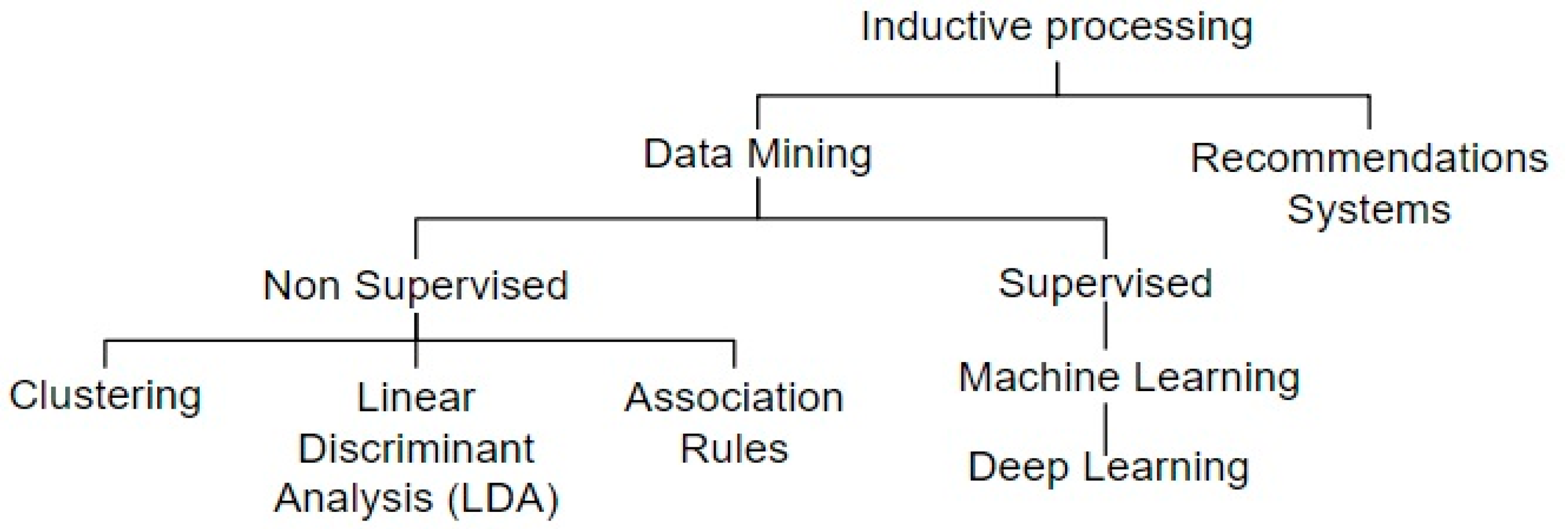
2. Methods and Task for Social Analysis
- Keep the data moving. To support real-time stream processing, messages must be processed in streaming. Due to the low latency of social data, the system must be able to process data “on the fly” and avoid costly storage operations.
- Support for ad-hoc stream queries to filter out events of interest and perform real-time analysis. Support for high-level query languages for continuous results and set up primitives and operators to manage common stream properties (such as data window size and calculation frequency). Some streaming languages include StreamSQL and C-SPARQL.
- Establish mechanisms for handling stream imperfections. In real applications, streaming data may arrive out of order, with some delay, with missing information or arrive in the wrong format. The system must be able to identify the type of error and offer automatic solutions for each case.
- It must be robust and fault tolerant. The first property is related to the possibility of dealing with execution errors and erroneous inputs, in turn guaranteeing outputs in accordance with the expected results. Furthermore, it is necessary to guarantee the availability and security of the data, so that if any module has a failure, the system can continue working (to face this it is convenient to keep processes in the background that often synchronize states with primary processes).
- Allow the integration of stored data with streaming data. A streaming architecture must support integrating data from two basic states: a long-term stage for keeping and batch processing historical information and a short-term stage for generating data in streaming. In many scenarios, it is necessary to compare a current state with past states in order to obtain better insights from the data (e.g., for machine learning tasks). It is therefore necessary to efficiently manage the storage and access of previous states. On the other hand, it is not always necessary to store historical data forever, but it is recommended to establish a time window that maintains the last period of interest so that in case of process failure it is possible to recalculate all data from the latest historical data, thus supporting fault tolerance.
- The system must be partitionable and scalable automatically. That is, it must be able to automatically balance process overload, distributing processes in threads transparently to the user.
- High speed processing and response. It must support high performance for a large volume of very low latency streaming data.
- Finally, we have included integration with LOD technologies to semantically enrich the input and output of data. SW technologies enable the linking and exploration of external sources for the discovery and acquisition of relevant data (e.g., the discovery of new dimensions of analysis). On the other hand, it is also useful to enable the publication of streaming data in some standard for LOD so that it can be easily understood by external applications.
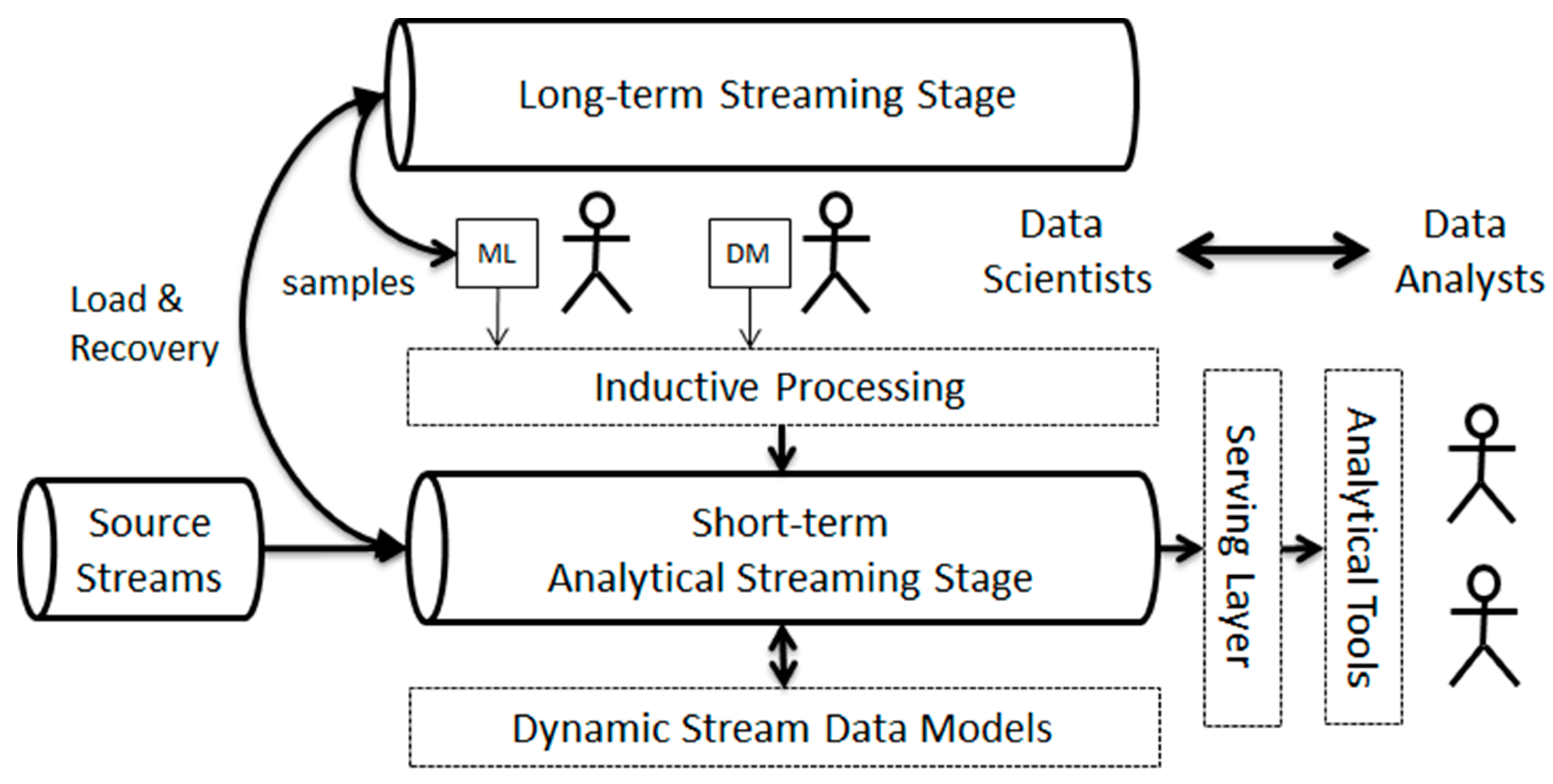
3. Proposed Architecture
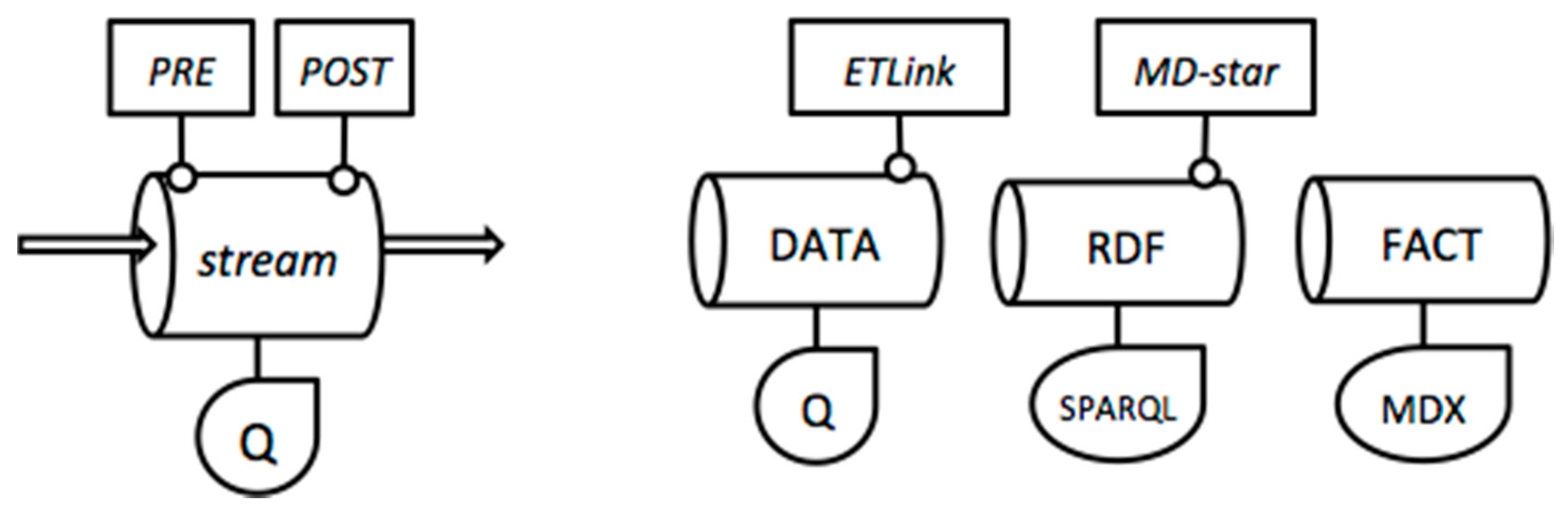
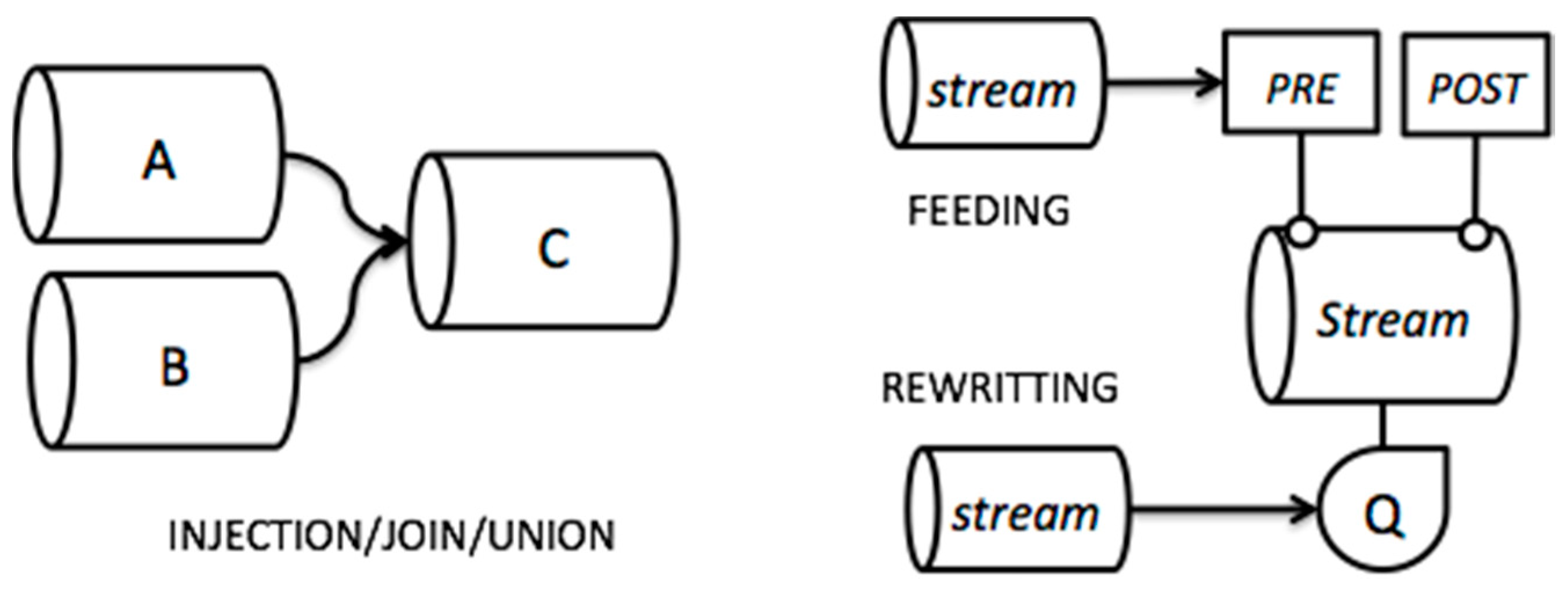
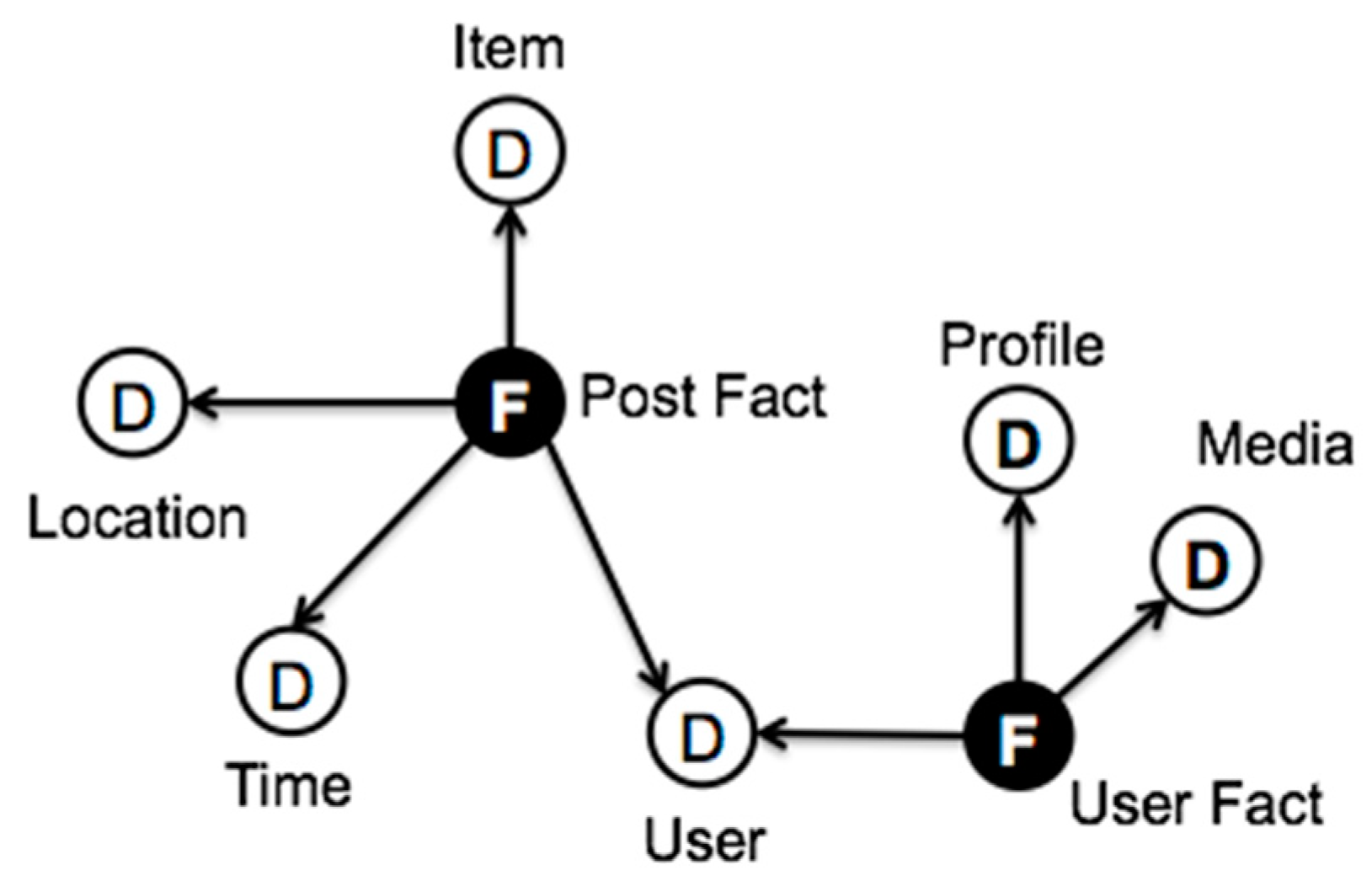
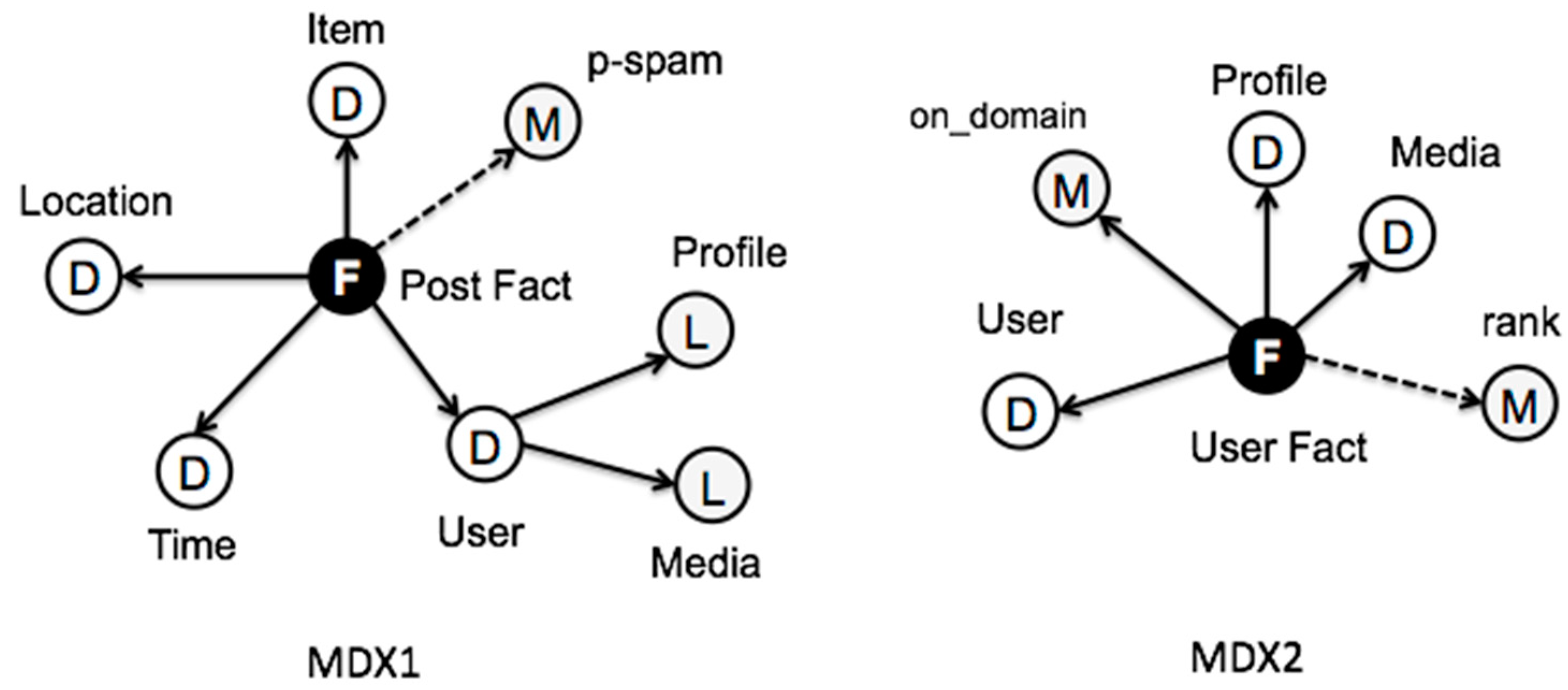
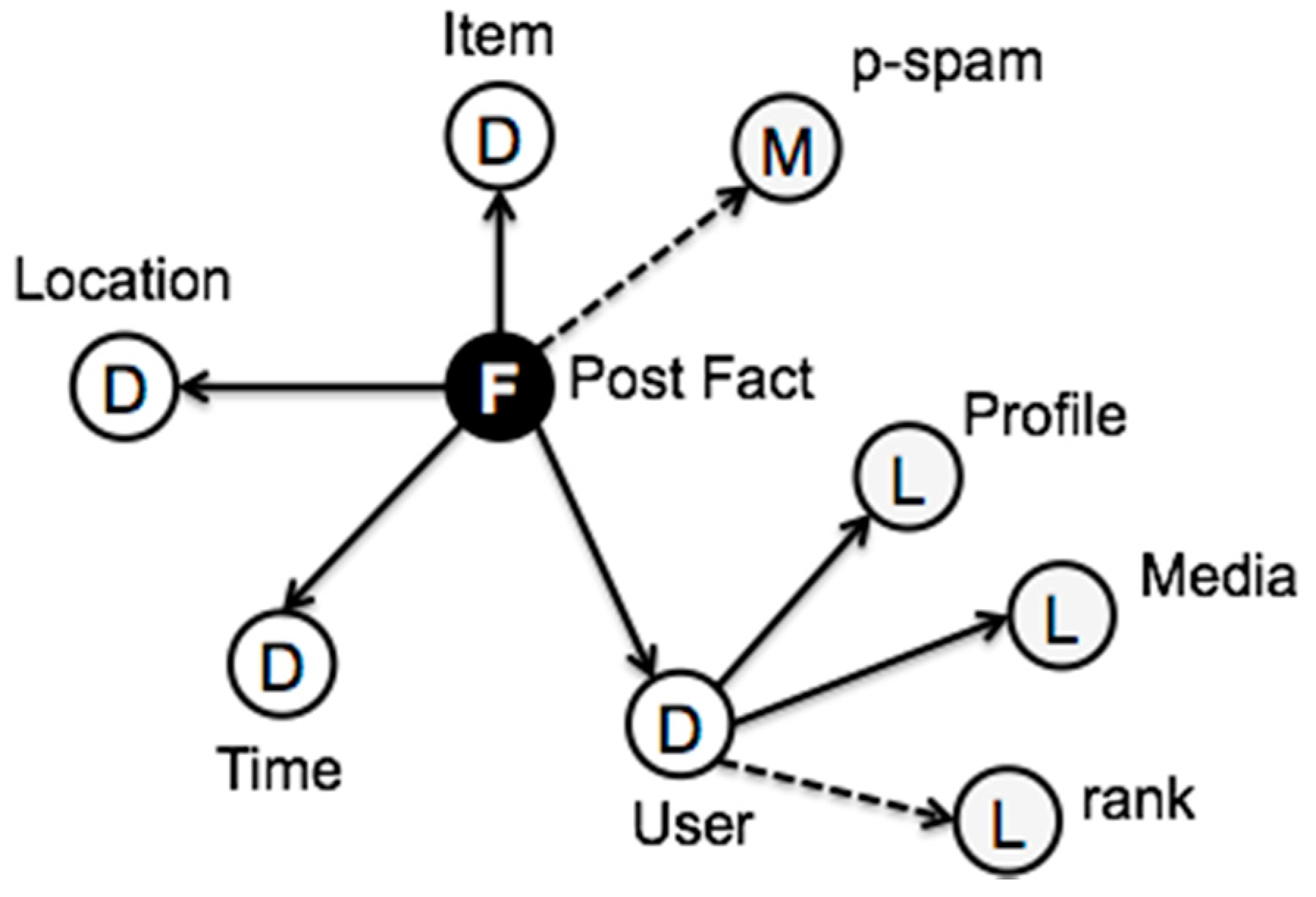
3.1. Stream Modeling
3.2. Multidimensional Coherence
3.3. Temporal Consistency
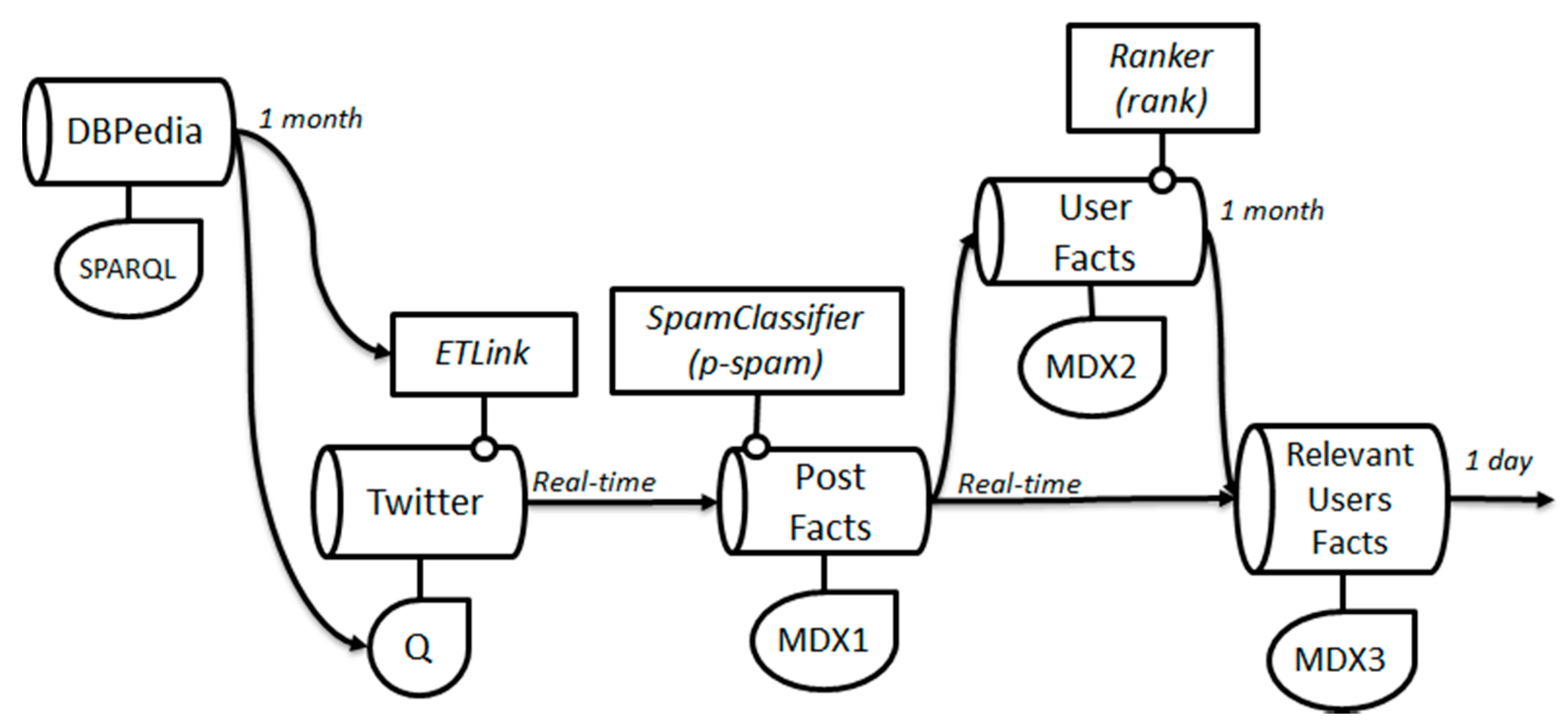
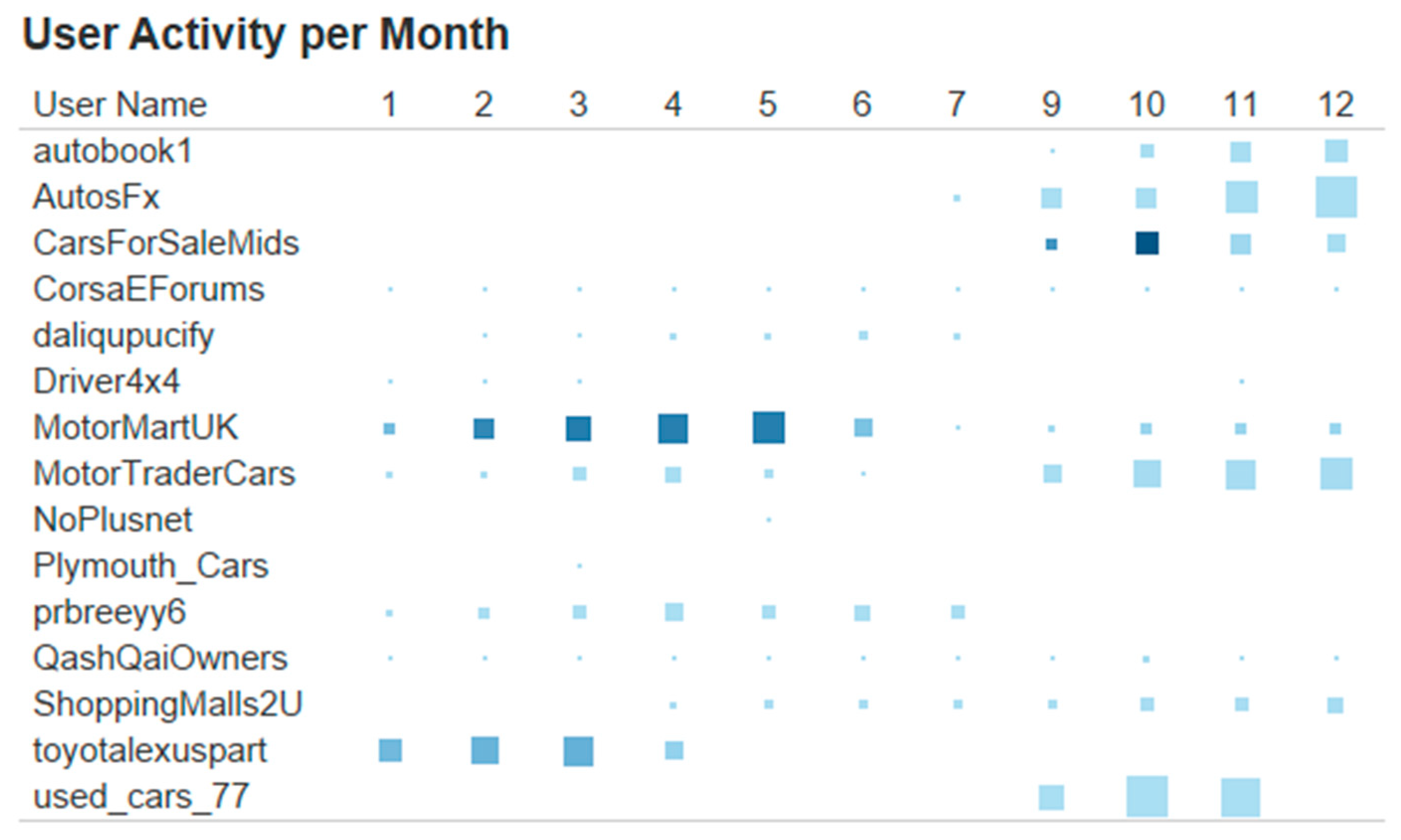
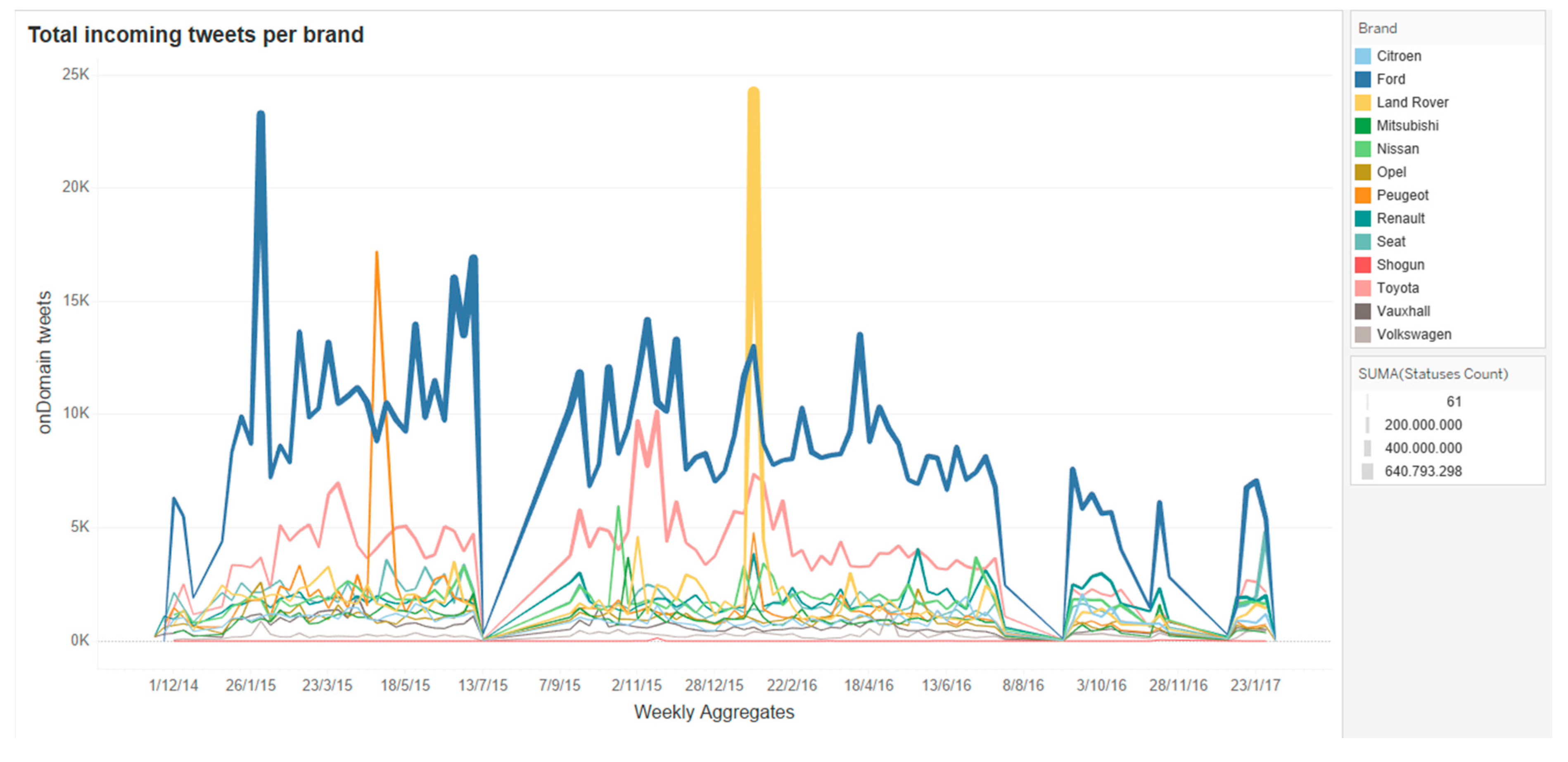
4. An Example Use Case
select ?car,?date,?brand where {
?car dbo:manufacturer ?brand.
?car dbo:productionStartYear ?date.
FILTER (?date > $one_month_ago$^^xsd:dateTime)
}
5. Prototype Implementation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Inmon, W. Building the Data Warehouse; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2005. [Google Scholar]
- Kreps, J. Questioning the Lambda Architecture 2014. Available online: https://www.oreilly.com/ideas/questioning-the-lambda-architecture (accessed on 11 June 2018).
- Berlanga, R.; García-Moya, L.; Nebot, V.; Aramburu, M.; Sanz, I.; Llidó, D. SLOD-BI: An Open Data Infrastructure for Enabling Social Business Intelligence. Int. J. Data Warehous. Data Min. 2015, 11, 1–28. [Google Scholar] [CrossRef]
- Liu, X.; Tang, K.; Hancock, J.; Han, J.; Song, M.; Xu, R.; Pokorny, B. A Text Cube Approach to Human, Social, Cultural Behavior in the Twitter Stream. In Proceedings of the International Conference on Social Computing, Behavioral-Cultural Modeling, and Prediction, Washington, DC, USA, 2–5 April 2013. [Google Scholar]
- Rosenthal, S.; Farra, N.; Nakov, P. SemEval-2017 Task 4: Sentiment Analysis in Twitter. In Proceedings of the 11th International Workshop on Semantic Evaluations (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017. [Google Scholar]
- Montejo-Ráez, A.; Martínez-Cámara, E.; Martín-Valdivia, M.; Ureña-López, L.A. Ranked Wordnet graph for sentiment polarity classification in Twitter. Comp. Speech Lang. 2014, 28, 93–107. [Google Scholar] [CrossRef]
- Volkova, S.; Bachrach, Y.; Armstrong, M.; Sharma, V. Inferring Latent User Properties from Texts Published in Social Media. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 4296–4297. [Google Scholar]
- Pennacchiotti, M.; Popescu, A.-M. A Machine Learning Approach to Twitter User Classification. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Catalonia, Spain, 17–21 July 2011; pp. 281–288. [Google Scholar]
- Colleoni, E.; Rozza, A.; Arvidsson, A. Echo Chamber or Public Sphere? Predicting Political Orientation and Measuring Political Homophily in Twitter Using Big Data. J. Commun. 2014, 64, 317–332. [Google Scholar] [CrossRef]
- Kapanipathi, P.; Jain, P.; Venkataramani, A.C. User interests identification on twitter using a hierarchical knowledge base. In Proceedings of the 11th European Semantic Web Conference ESWC 2017, Portorož, Slovenia, 28 May–1 June 2017. [Google Scholar]
- Miller, Z.; Dickinson, B.; Deitrick, W.; Hu, W.; Wang, A. Twitter spammer detection using data stream clustering. Inf. Sci. 2014, 260, 64–73. [Google Scholar] [CrossRef]
- Varol, O.; Ferrara, E.; Davis, C.; Menczer, F.; Flammini, A. Online Human-Bot Interactions: Detection, Estimation, and Characterization. Available online: https://arxiv.org/abs/1703.03107 (accessed on 11 June 2018).
- Subrahmanian, V.; Azaria, A.; Durst, S.; Kagan, V.; Galstyan, A.; Lerman, K.; Zhu, L.; Ferrara, E.; Flammini, A.; Menczer, F. The DARPA Twitter Bot Challenge. Computer 2016, 49, 38–46. [Google Scholar] [CrossRef]
- Ferrara, E.; Varol, O.; Davis, C.; Menczer, F.; Flammini, A. The Rise of Social Bots. Commun. ACM 2016, 59, 96–104. [Google Scholar] [CrossRef]
- Li, H.; Mukherjee, A.; Liu, B.; Kornfield, R.; Emery, S. Detecting Campaign Promoters on Twitter using Markov Random Fields. In Proceedings of the IEEE International Conference on Data Mining, Shenzhen, China, 14–17 December 2014. [Google Scholar]
- Roelens, I.; Baecke, P.; Benoit, D. Identifying influencers in a social network: The value of real referral data. Decis. Support Syst. 2016, 91, 25–36. [Google Scholar] [CrossRef]
- Xie, W.; Zhu, F.; Jiang, J.; Lim, E.-P.; Wang, K. TopicSketch: Real-Time Bursty Topic Detection from Twitter. IEEE Trans. Knowl. Data Eng. 2016, 28, 2216–2229. [Google Scholar] [CrossRef]
- Feng, W.; Zhang, C.; Zhang, W.; Han, J.; Wang, J.; Aggarwal, C.; Huang, J. STREAMCUBE: Hierarchical spatio-temporal hashtag clustering for event exploration over the Twitter stream. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015. [Google Scholar]
- Zhang, C.; Zhou, G.; Yuan, Q.; Zhuang, H.; Zheng, Y.; Kaplan, L.; Wang, S.; Han, J. GeoBurst: Real-Time Local Event Detection in Geo-Tagged Tweet Streams. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016. [Google Scholar]
- Zhou, X.; Chen, L. Event detection over twitter social media streams. VLDB J. 2014, 23, 381–400. [Google Scholar] [CrossRef]
- Atefeh, F.; Khreich, W. A Survey of Techniques for Event Detection in Twitter. Comput. Intell. 2013, 31, 132–164. [Google Scholar] [CrossRef]
- Zubiaga, A.; Spina, D.; Martínez, R.; Fresno, V. Real-time classification of Twitter trends. J. Assoc. Inf. Sci. Technol. 2015, 66, 462–473. [Google Scholar] [CrossRef]
- Cao, G.; Wang, S.; Hwang, M.; Padmanabhan, A.; Zhang, Z.; Soltani, K. A scalable framework for spatiotemporal analysis of location-based social media data. Comput. Environ. Urban Syst. 2015, 51, 70–82. [Google Scholar] [CrossRef]
- Smith, M.A. NodeXL: Simple Network Analysis for Social Media. In Encyclopedia of Social Network Analysis and Mining; Springer: New York, NY, USA, 2014. [Google Scholar]
- Barbieri, D.; Braga, D.; Ceri, S.; Della Valle, E.; Huang, Y.; Tresp, V.; Rettinger, A.; Wermser, H. Deductive and Inductive Stream Reasoning for Semantic Social Media Analytics. IEEE Intell. Syst. 2010, 25, 32–41. [Google Scholar] [CrossRef]
- Smith, M.A.; Shneiderman, B.; Milic-Frayling, N.; Mendes Rodrigues, E.; Barash, V.; Dunne, C.; Capone, T.; Perer, A.; Gleave, E. Analyzing (Social Media) Networks with NodeXL. In Proceedings of the Fourth International Conference on Communities and Technologies, New York, NY, USA, 25–27 June 2009; pp. 255–264. [Google Scholar]
- Berlanga, R.; Aramburu, M.; Llidó, D.; García-Moya, L. Towards a Semantic Data Infrastructure for Social Business Intelligence. In New Trends in Databases and Information Systems; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Nebot, V.; Berlanga, R. Statistically-driven generation of multidimensional analytical schemas from linked data. Knowl.-Based Syst. 2016, 110, 15–29. [Google Scholar] [CrossRef]
- Francia, M.; Gallinucci, E.; Golfarelli, M.; Rizzi, S. Social Business Intelligence in Action. In Proceedings of the Advanced Information Systems Engineering: 28th International Conference CAiSE, Ljubljana, Slovenia, 13–17 June 2016; pp. 33–48. [Google Scholar]
- Scholl, S.R.H. Discovering OLAP dimensions in semi-structured data. Inf. Syst. 2014, 44, 120–133. [Google Scholar]
- Mauri, A.; Calbimonte, J.; Dell’Aglio, D.; Balduini, M.; Brambilla, M.; Della Valle, E. TripleWave: Spreading RDF Streams on the Web. In Proceedings of the Semantic Web—ISWC 2016. ISWC 2016, Kobe, Japan, 17–21 October 2016. [Google Scholar]
- Balduini, M.; Della Valle, E.; Dell’Aglio, D.; Tsytsarau, M.; Palpanas, T.; Confalonieri, C. Social Listening of City Scale Events Using the Streaming Linked Data Framework; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–16. [Google Scholar]
- Zeng, D.; Chen, H.; Lusch, R. Social Media Analytics and Intelligence. IEEE Intell. Syst. 2010, 25, 13–16. [Google Scholar] [CrossRef]
- Nadal, S.; Herrero, V.; Romero, O.; Abelló, A.; Franch, X.; Vansummeren, S.; Valerio, D. A software reference architecture for semantic-aware Big Data systems. Inf. Softw. Technol. 2017, 90, 75–92. [Google Scholar] [CrossRef]
- Stonebraker, M.; Çetintemel, U.; Zdonik, S. The 8 Requirements of Real-Time Stream Processing. SIGMOD Rec. 2005, 34, 42–47. [Google Scholar] [CrossRef]
- Marz, N.; Warren, J. Big Data: Principles and Best Practices of Scalable Realtime Data Systems, 1st ed.; Manning Publications Co.: Greenwich, CT, USA, 2015. [Google Scholar]
- Javed, M.H.; Lu, X.; Panda, D.K. Characterization of Big Data Stream Processing Pipeline: A Case Study using Flink, Kafka. In Proceedings of the Fourth IEEE/ACM International Conference on Big Data Computing, Applications, Technologies, New York, NY, USA, 5–8 December 2017; pp. 1–10. [Google Scholar]
- Hebeler, J.; Fisher, M.; Blace, R.; Perez-Lopez, A. Semantic Web Programming; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- DBPedia Live. Available online: https://wiki.dbpedia.org/online-access/DBpediaLive (accessed on 20 June 2018).
- BabelNet Live. Available online: http://live.babelnet.org/ (accessed on 20 June 2018).
- Romero, O.; Abelló, A. A framework for multidimensional design of data warehouses from ontologies. Data Knowl. Eng. 2010, 69, 1138–1157. [Google Scholar] [CrossRef]
- Barbieri, D.F.; Braga, D.; Ceri, S.; Della Valle, E.; Grossniklaus, M. Querying RDF streams with C-SPARQL. SIGMOD Rec. 2010, 39, 20–26. [Google Scholar] [CrossRef]
- OWL Language. Available online: https://www.w3.org/OWL/ (accessed on 20 June 2018).
- JSON-LD. Available online: https://json-ld.org/ (accessed on 20 June 2018).
- Anaconda. Available online: https://anaconda.org/ (accessed on 20 June 2018).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Analysis Tasks | Features Class | References |
|---|---|---|---|
| Sentiment Analysis | Sentiment indicators. Communications analysis. User, groups, community, society. characterization Human, social and cultural behavior. | Post content | [3,4,5,6] |
| User Profiling | Author profiling, User classification. Inferring user properties (age, gender, income, education, etc.). Political orientation, ethnicity, and business fan detection. User interests identification. | User Metrics, Post content, Post metrics, Sentiment, Network | [7,8,9,10] |
| Spammers, Bots detections, Promoters, Influencer detection. | All | [11,12,13,14,15,16,17] | |
| Post Profiling | Campaigns, Topics, spam, meme, sarcasm, rumors, terrorism detection. | Post, Links, Bursts | |
| Event detection | Real-time events detection by location and time, events classification, protests and manifestations, detection of diseases and catastrophes, study of the displacement of people between cities. Real-time classification of trends. | Post content, Post metrics, Hashtag, Location, Time, Burst | [18,19,20,21,22,23] |
| Analysis of social network and Users interactions | Influence and correlation in social networks, social network dynamics, network, and node classification, detect influential nodes. | Graph Network, User metrics | [24] |
| Recommendations system | User, news, media recommendation. | User metrics, Post metrics, Time | [25] |
| Class | Description |
|---|---|
| User metrics | The user features refer to the metadata related to a user account on social networks. You can include data such as geo-location, friend list, number of mentions, etc. |
| Post content and metrics | Post features can be divided into two main parts: text contents and Post meta-data. With the text it is possible to analyze its content and identify clues based on the linguistic characteristics making use of natural language processing algorithms. From the text it is also possible to extract links, hashtags or embed multimedia. On the other hand, the metadata refer to the records of user interactions with the post, such as the number of responses, retweets, likes or date of publication. |
| Network | The initial aim of the network analysis is to capture the basic perceptions of its macrostructure. At the micro level, network analysts focus on the importance of individual nodes. Network features capture various dimensions of information dissemination patterns. Statistical features can be extracted from retweets, mentions, and hashtag co-occurrences. From the global network, metrics such as number of nodes, number of edges, density, and diameter can be extracted; the main task includes node and edge classifications based on degree, inter-centricity, and proximity centrality. On the other hand, analyses are carried out to search for communities and to compare typified nodes [26]. |
| Burst | A burst is a particular moment when the volume of tweets suddenly increases drastically. Burstiness is a spatio-temporal feature. We can measure how temporally bursty a keyword is at a location, and inversely in a concrete timing we can measure spatial burstiness [15,19]. |
| Time | Time features capture the temporal patterns of posting and post interactions (e.g., replies, retweets, likes); for example, the average time between two consecutive publications. |
| Sentiment | Sentiment features are built using sentiment analysis algorithms from the posts content. It is also possible to use metrics such as ratings, emotion, and satisfaction scores. |
| Model Type | KFC | LOD | References | Tasks Types |
|---|---|---|---|---|
| Social Business Intelligence, Batch processing, OLAP based | Social Facts Ontology, ETLink, OLAP, Analytic Tool | RDF | [3,27,28] | Sentiment analysis. Entity extraction, keyword extraction, event, and topic detection. |
| OLAP + ETL + Analytic Tools | No | [29,30] | ||
| SMA 1, Cube modeling, Batch processing | OLAP | No | [23] | Spatio-temporal analysis of social media data. Detection of diseases and catastrophes. Study of people displacement. |
| Text Cubes Batch processing | OLAP | No | [4] | Sentiment analysis. Study human, social and cultural behavior. |
| RDF Streams. Streaming processing | R2RML mappings | RDF streams | [31] | Publish and share RDF streams on the Web. |
| Streaming linking Data Server+ HTML5 browser | RDF streams | [32] | Sentiment analysis. Local events monitoring. Hasthags ranking. |
| Model Type | KFC 1 | LOD 2 | References | Tasks Types |
|---|---|---|---|---|
| SMI 3, Batch processing | ML framework | No | [8] | Political orientation, ethnicity, and business fan detection |
| SMI, Streaming processing | Online mode, Batch mode, Event Ranker | No | [19] | Real-time local event detection |
| StreamCUBE Batch processing Disk-based Storage | Spatial-temporal aggregation, Hashtag clustering, Event Ranker | No | [18] | Spatio-temporal hashtag clustering for event exploration |
| (Mixed) RDF Streams Streaming processing | DSMS 4, Abstracter DSMS, Deductive and Inductive reasoner | RDF Streaming OWL2-RL | [25] | User profiling and media recommendations using deductive and inductive reasoning. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lanza-Cruz, I.; Berlanga, R.; Aramburu, M.J. Modeling Analytical Streams for Social Business Intelligence. Informatics 2018, 5, 33. https://doi.org/10.3390/informatics5030033
Lanza-Cruz I, Berlanga R, Aramburu MJ. Modeling Analytical Streams for Social Business Intelligence. Informatics. 2018; 5(3):33. https://doi.org/10.3390/informatics5030033
Chicago/Turabian StyleLanza-Cruz, Indira, Rafael Berlanga, and María José Aramburu. 2018. "Modeling Analytical Streams for Social Business Intelligence" Informatics 5, no. 3: 33. https://doi.org/10.3390/informatics5030033
APA StyleLanza-Cruz, I., Berlanga, R., & Aramburu, M. J. (2018). Modeling Analytical Streams for Social Business Intelligence. Informatics, 5(3), 33. https://doi.org/10.3390/informatics5030033