A Review and Characterization of Progressive Visual Analytics




Abstract
1. Motivation
- to realize responsive client-server visualizations using incremental data transmissions [4],
- to make computational processes more transparent through execution feedback and control [5],
- to steer visual presentations by prioritizing the display of regions of interest [6],
- to provide fluid interaction by respecting human time constraints [7], or
- to base early decisions on partial results, trading precision for speed [8].
- a collection and review of scholarly publications on the topic of PVA from various domains;
- a characterization of PVA capturing the reasons, benefits, and challenges of employing it;
- a set of recommendations for implementing PVA sourced from a range of publications.
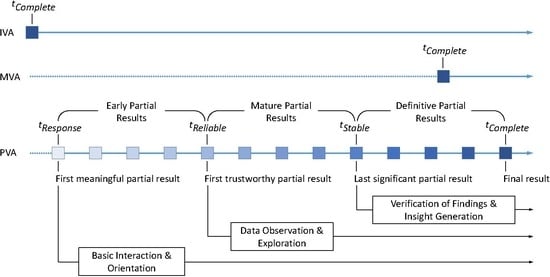
2. PVA Fundamentals
- With PVA, we are able to start the interactive analysis right after in parallel to the further refinement of the view. Yet with MVA, view generation and interactive analysis can only be done in sequence, so that the overall time spent on generating and utilizing the visualization extends well beyond .
- With PVA, we yield a sufficiently good partial result as early as and no later than , which is in most cases still well before MVA’s completion time. PVA’s is irrelevant, since if we wanted a final and polished result, we would have used MVA in the first place.
3. Review Procedure
4. A Characterization of PVA
4.1. Reasons for Using PVA
- Quasi-indefinite computations: These are computations that will theoretically terminate at some point, but reaching this point is a few thousand years out, e.g., due to combinatorial explosion [32].
- Delayed computations: These types of computations can be completed within reasonable time, but it is still taking too long to meet a given deadline by which the result is needed.
- Task completion: Initiating a computational task, such as a query or complex filter operation on large datasets, should not stall the flow of analysis for more than 10 s.
- Immediate response: In an interactive setting, such as tuning computational parameters in a GUI, feedback to the made changes should appear in 1 s.
- Perceptual update: Computations initiated through direct interaction with the view should complete in under 1 s to ensure smooth updates without noticeable stutter or flickering.
- Monolithic computations: In this instance, the focus lies on the complexity and opacity of the computational process that cannot be observed, understood, or steered while running its course [5].
- Monolithic visualizations: Here the focus lies on the visualization produced by the process and being shown in all its cluttered, overplotted detail as a single monolithic end result [6].
4.2. Benefits of Using PVA
- process-specific: a monotonously converging progressive computation is likely to yield useful results earlier than one that is highly fluctuating and bound to produce “surprises”;
- task-specific: a high-level overview task requires less detail to be shown than an in-depth comparison;
- domain-specific: a social media analysis can accept a higher margin of error than analyzing patient records to make a clinical treatment decision;
- user-specific: some users with experience in progressive computations may be able to see early on “where this is going”, while others wait a little longer before feeling comfortable to work with a partial result.
- hard early completion: this terminates the running computation and starts with the next analytical step based on the findings made up to that point;
- soft early completion: this also starts with the next analytical step, but the computation is only paused and not terminated [1].
- monitor the computation in its course for understanding and possibly debugging the algorithmics behind it (cp. software visualization);
- steer the computation through interactive reparametrization of algorithms or reprioritization of data chunks, adapting the PVA process to early observations and emerging analysis interests;
- observe the build-up of complex visualizations step by step, showing increasing numbers of visual elements to convey even dense, detailed, and cluttered visualizations;
4.3. Challenges of Using PVA
5. Requirements
5.1. Process-Driven Characterization
- Data requirements concerning aspects from the ingestion and subdivision of the data, to prioritization and aggregation strategies for data in a PVA solution;
- Processing requirements dealing with all aspects from the progressive implementation of the computation to its execution and control;
- Visualization requirements regarding all aspects from visual feedback about the running process to the dynamic presentation of the incremental outcome;
- Interaction requirements including all aspects from meeting human time constraints to providing structured interaction with the process.
5.2. User-Driven Characterization
5.2.1. Requirements for Providing PVA Benefits
- Meaningfulness (S14): Partial results should reflect the overall result by coming in the same format (sometimes called structure preservance M24) and be appropriate to be taken in by a human analyst.
- Interestingness (Hel1, S15, M29): Partial results are of no use, if those parts of the data, which interest the analyst most, get processed and shown last. Hence, it is important to be able to prioritize data and process it in order of decreasing interestingness.
- Relevance (S16): Some parts of the data may not only be of lesser interest to the user, but actually be entirely irrelevant to the analysis task at hand. Being able to exclude irrelevant data from processing can further streamline the creation of useful partial results by making it faster and less cluttered.
5.2.2. Requirements for Mitigating PVA Challenges
6. A Use Case Scenario
6.1. The Visual Analysis Setting
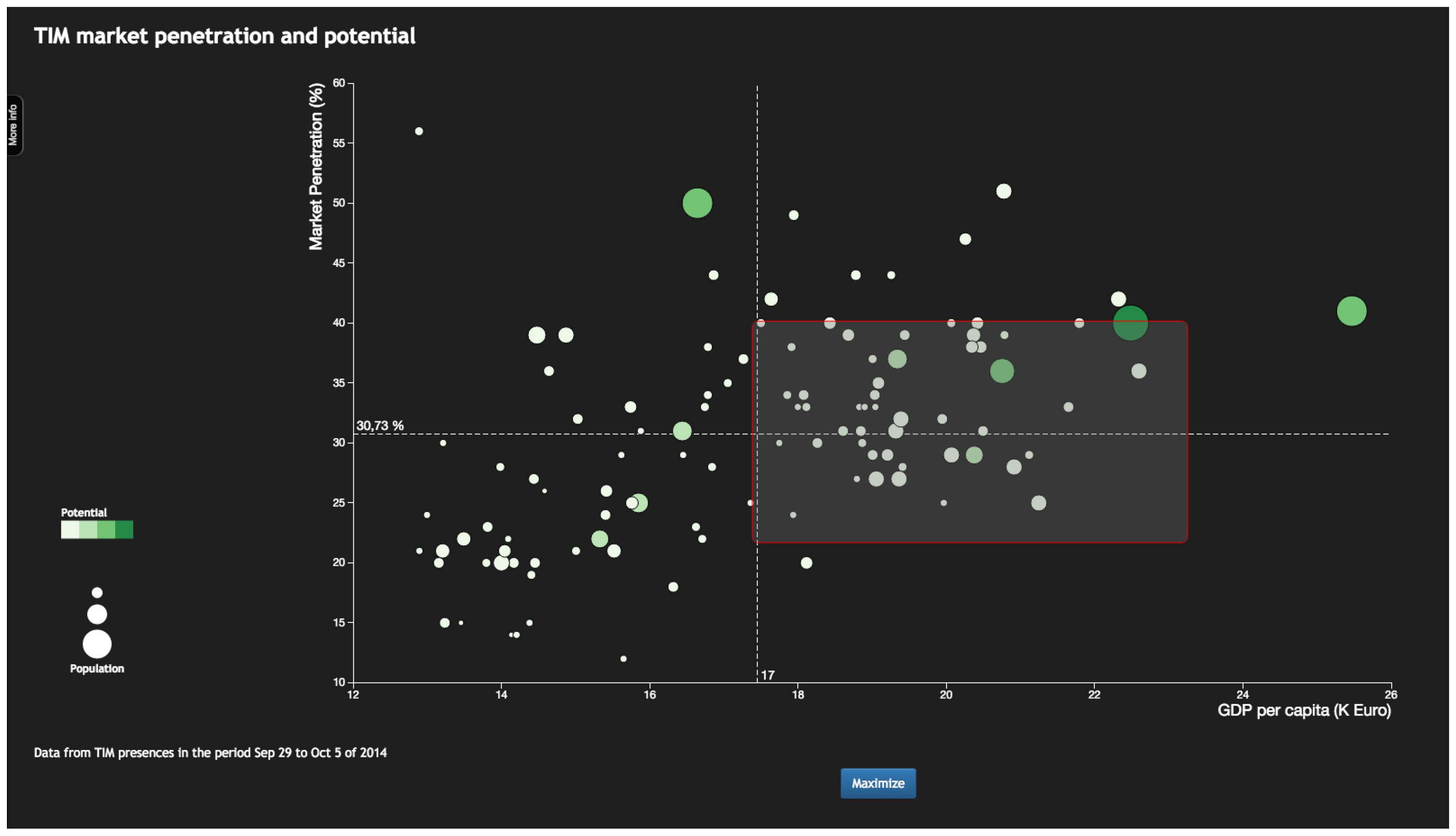
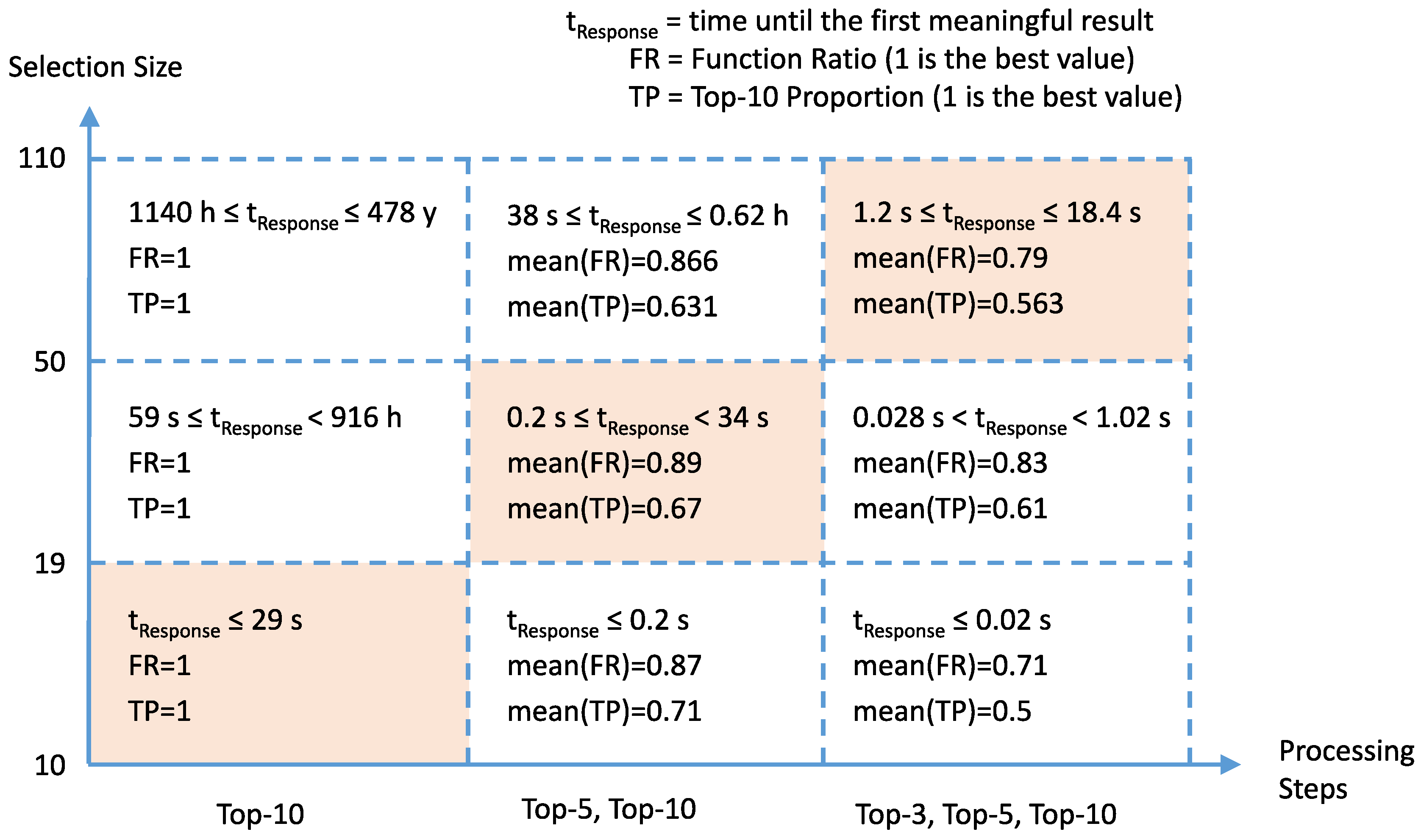
- The analyst selects 30 to 50 candidate provinces in a scatterplot. This scatterplot displays the provinces according to numerical properties that will likely have an influence on the success of the marketing campaign—e.g., market penetration and average income as shown in Figure 3.
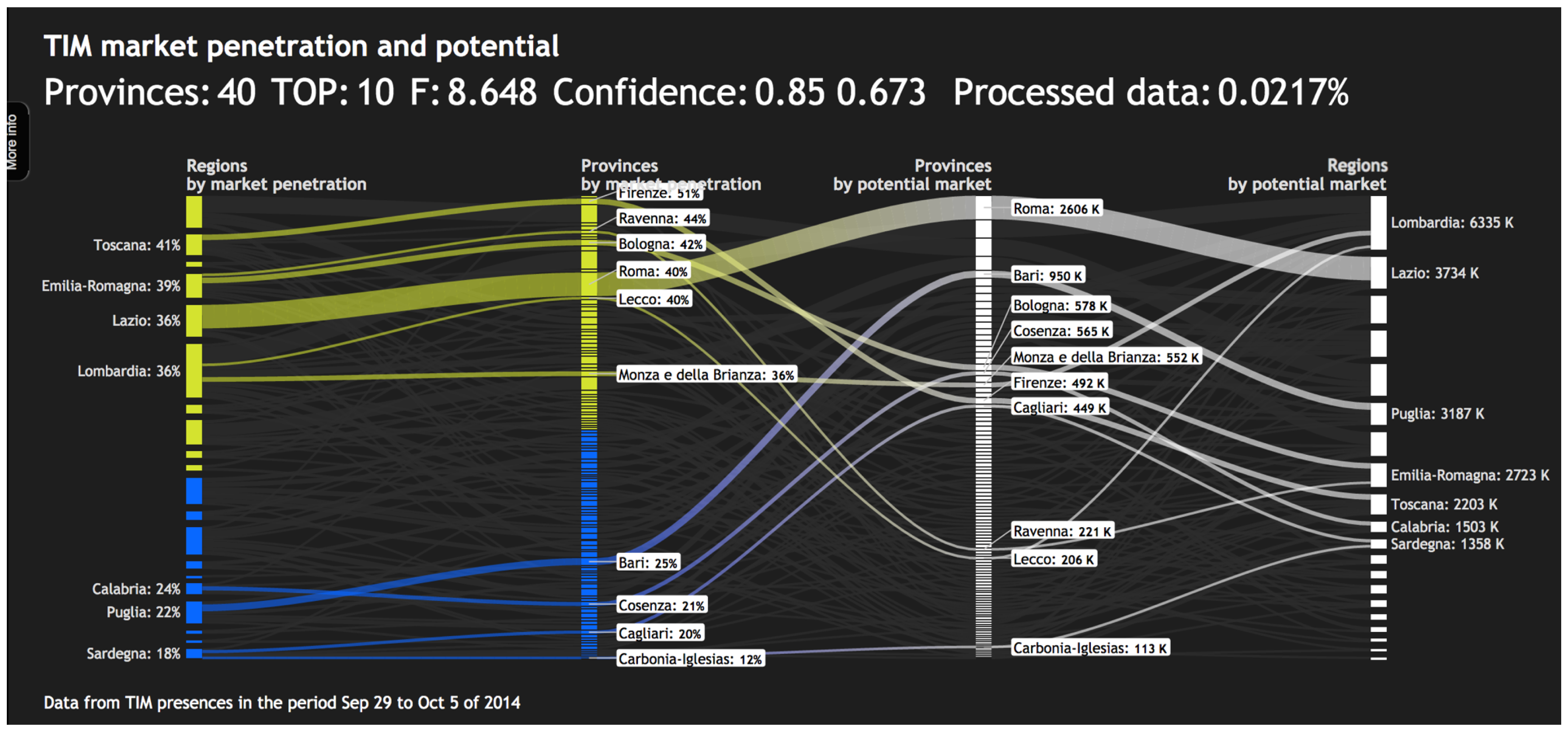
- Among those candidate provinces, a Top-10 subset is computed that maximizes the objective function. The subset is displayed in a Sankey diagram, which allows the user to explore the numeric properties of these provinces as well as their relation to the provinces not included in the Top-10—see Figure 4.
- Depending on the interactive assessment of the current set of Top-10 provinces, the analyst can either go back to the scatterplot to choose a different candidate set, or conclude the analysis with the current result and launch the marketing campaign in those ten provinces.
6.2. Characterization as a PVA Scenario
6.3. A Solution Design following the PVA Recommendations
6.4. User Feedback
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HCI | Human-Computer Interaction |
| IVA | Instantaneous Visual Analytics |
| MDS | Multi-Dimensional Scaling |
| MVA | Monolithic Visual Analytics |
| PVA | Progressive Visual Analytics |
| RoI | Return of Investment |
| SIM | Subscriber Identity Module |
| SNE | Stochastic Neighbor Embedding |
| TIM | Telecom Italia Mobile |
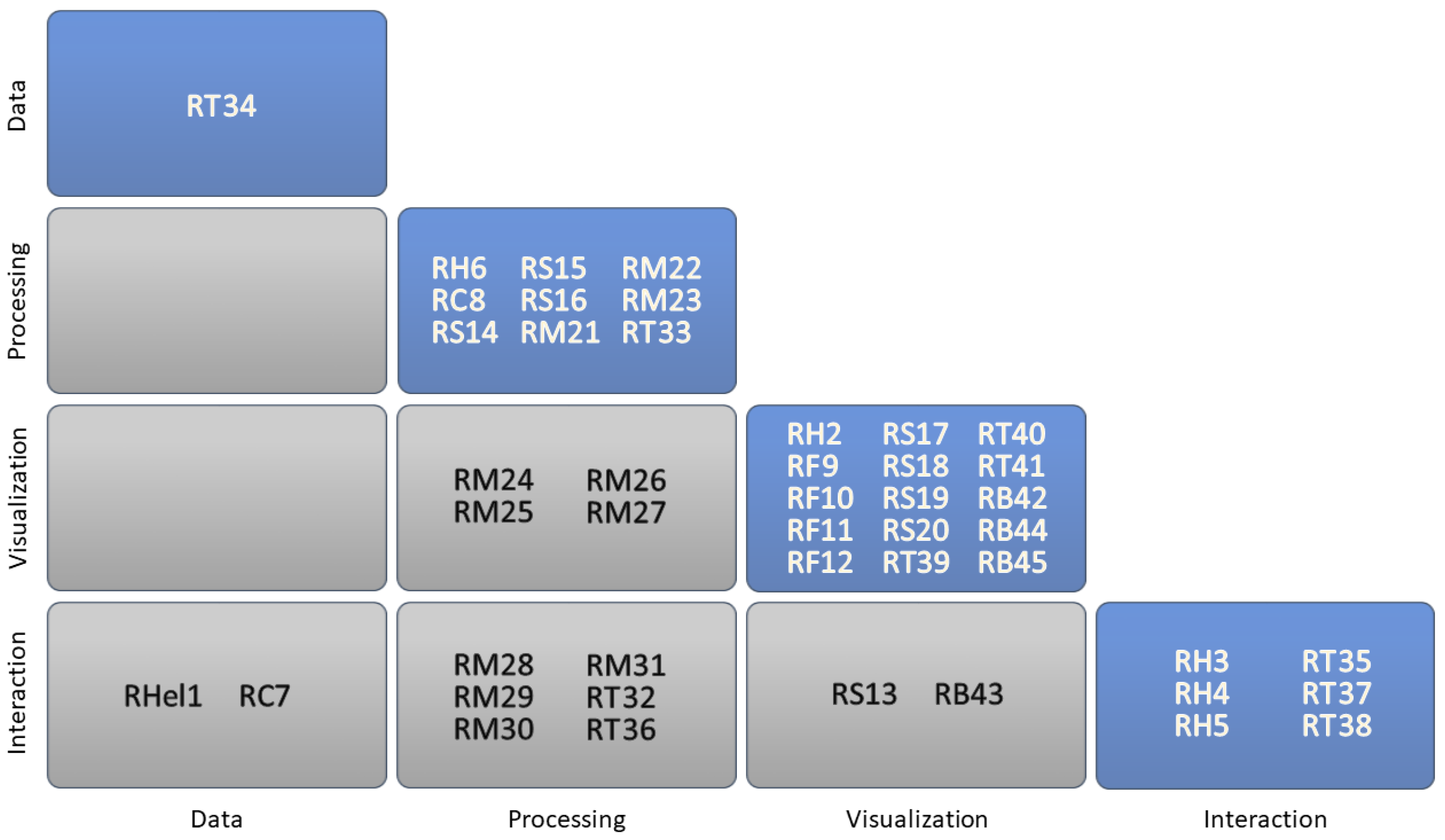
Appendix A. List of requirements

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Requirement | Description | Source |
|---|---|---|
| Hel1 | Process interesting data early, so users can get satisfactory results quickly, halt processing, and move on to their next request | Hellerstein et al., 1999 (Preferential data delivery: online reordering) |
| H2 | Enable monitoring the visualization and seeing what’s new each time a new increment of data is processed and loaded into the system | Hetzler et al., 2005 (Section 3.1) |
| H3 | Allow the explicit control of updates arrival | Hetzler et al., 2005 (Section 3.2) |
| H4 | Minimize the disruption to the analytic process flow and the interaction flow | Hetzler et al., 2005 (Section 3.2) |
| H5 | Provide full interactivity for dynamic datasets | Hetzler et al., 2005 (Section 3.3) |
| H6 | Provide dynamic update features | Hetzler et al., 2005 (Section 3.4) |
| C7 | Allow users to communicate progressive samples to the system | Chandramouli et al., 2013 (Section 1.1) |
| C8 | Allow efficient and deterministic query processing over progressive samples, without the system itself trying to reason about specific sampling strategies or confident estimation | Chandramouli et al., 2013 (Section 1.1) |
| F9 | Uncertainty visualization should be easy to interpret | Ferreira et al., 2014 (Design Goals) |
| F10 | Visualizations should be consistent across tasks | Ferreira et al., 2014 (Design Goals) |
| F11 | Maintain spatial stability of visualizations across sample size | Ferreira et al., 2014 (Design Goals) |
| F12 | Minimize visual noise | Ferreira et al., 2014 (Design Goals) |
| S13 | Managing the partial results in the visual interface should not interfere with the user’s cognitive workflow | Stolper et al., 2014 (Section 1) |
| S14 | Produce increasingly meaningful partial results | Stolper et al., 2014 (Section 4.3) |
| S15 | Allow users to focus the algorithm to subspaces of interest | Stolper et al., 2014 (Section 4.3) |
| S16 | Allow users to ignore irrelevant subspaces | Stolper et al., 2014 (Section 4.3) |
| S17 | Minimize distractions by not changing views excessively | Stolper et al., 2014 (Section 4.3) |
| S18 | Provide cues to indicate where new results have been found by analytics | Stolper et al., 2014 (Section 4.3) |
| S19 | Support an on-demand refresh when analysts are ready to explore the latest results | Stolper et al., 2014 (Section 4.3) |
| S20 | Provide an interface to specify where analytics should focus, as well as the portions of the problem space that should be ignored | Stolper et al., 2014 (Section 4.3) |
| M21 | Provide feedback on the aliveness of the execution | Mühlbacher et al., 2014 (Section 3.1) |
| M22 | Provide feedback on the absolute progress of the execution | Mühlbacher et al., 2014 (Section 3.1) |
| M23 | Provide feedback on the relative progress of the execution | Mühlbacher et al., 2014 (Section 3.1) |
| M24 | Generate structure-preserving intermediate results | Mühlbacher et al., 2014 (Section 3.2) |
| M25 | Provide aggregated information | Mühlbacher et al., 2014 (Section 3.2) |
| M26 | Provide feedback on the uncertainty of a result | Mühlbacher et al., 2014 (Section 3.2) |
| M27 | Provide provenance information, including any meta-information concerning simplifications made for generating a partial result | Mühlbacher et al., 2014 (Section 3.2) |
| M28 | Allow for execution control by cancellation | Mühlbacher et al., 2014 (Section 3.3) |
| M29 | Allow altering the sequence of intermediate results through prioritization | Mühlbacher et al., 2014 (Section 3.3) |
| M30 | Provide inner result control for steering a single ongoing computation before it eventually returns a final result | Mühlbacher et al., 2014 (Section 3.4) |
| M31 | Provide outer result control to generate a result from multiple consecutive executions of a computation | Mühlbacher et al., 2014 (Section 3.4) |
| T32 | Employ human time constants | Turkay et al., 2017 (Section 2.1, DR1) |
| T33 | Employ online learning algorithms | Turkay et al., 2017 (Section 2.2, DR2) |
| T34 | Employ an adaptive sampling mechanism (convergence & temporal constraints) | Turkay et al., 2017 (Section 2.2.2, DR3) |
| T35 | Facilitate the immediate initiation of computations after user interaction | Turkay et al., 2017 (Section 2.3.1, DR4) |
| T36 | Provide interaction mechanisms enabling management of the progression | Turkay et al., 2017 (Section 2.3.1, DR5) |
| T37 | Design interaction taking into account fluctuations | Turkay et al., 2017 (Section 2.3.1, DR6) |
| T38 | Provide interaction mechanisms to define structured investigation sequence | Turkay et al., 2017 (Section 2.3.2, DR7) |
| T39 | Support the interpretation of the evolution of the results through suitable visualizations | Turkay et al., 2017 (Section 2.4.1, DR8) |
| T40 | Inform analysts on the progress of computations and indicate the time-to-completion | Turkay et al., 2017 (Section 2.4.3, DR9) |
| T41 | Inform analysts on the uncertainty in the computations and the way the computations develop | Turkay et al., 2017 (Section 2.4.3, DR10) |
| B42 | Show the analysis pipeline | Badam et al., 2017 (Section 7.3) |
| B43 | Support monitoring mode and exploration mode | Badam et al., 2017 (Section 7.3) |
| B44 | Provide similarity anchors | Badam et al., 2017 (Section 7.3) |
| B45 | Use consistently visualized quality measures | Badam et al., 2017 (Section 7.3) |
References
- Stolper, C.; Perer, A.; Gotz, D. Progressive visual analytics: User-driven visual exploration of in-progress analytics. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1653–1662. [Google Scholar] [CrossRef] [PubMed]
- Fekete, J.D.; Primet, R. Progressive Analytics: A Computation Paradigm for Exploratory Data Analysis. arXiv, 2016; arXiv:1607.05162. [Google Scholar]
- Schulz, H.J.; Angelini, M.; Santucci, G.; Schumann, H. An Enhanced Visualization Process Model for Incremental Visualization. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1830–1842. [Google Scholar] [CrossRef] [PubMed]
- Glueck, M.; Khan, A.; Wigdor, D. Dive in! Enabling progressive loading for real-time navigation of data visualizations. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI), Toronto, ON, Canada, 26 April–1 May 2014; Schmidt, A., Grossman, T., Eds.; ACM: New York, NY, USA, 2014; pp. 561–570. [Google Scholar] [CrossRef]
- Mühlbacher, T.; Piringer, H.; Gratzl, S.; Sedlmair, M.; Streit, M. Opening the black box: Strategies for increased user involvement in existing algorithm implementations. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1643–1652. [Google Scholar] [CrossRef] [PubMed]
- Rosenbaum, R.; Schumann, H. Progressive refinement: more than a means to overcome limited bandwidth. In Proceedings of the Conference on Visualization and Data Analysis (VDA), San Jose, CA, USA, 18–22 January 2009; Börner, K., Park, J., Eds.; SPIE: Bellingham, WA, USA, 2009; p. 72430I. [Google Scholar] [CrossRef]
- Turkay, C.; Kaya, E.; Balcisoy, S.; Hauser, H. Designing Progressive and Interactive Analytics Processes for High-Dimensional Data Analysis. IEEE Trans. Vis. Comput. Graph. 2017, 23, 131–140. [Google Scholar] [CrossRef] [PubMed]
- Fisher, D.; Popov, I.; Drucker, S.M.; Schraefel, M. Trust Me, I’m Partially Right: Incremental Visualization Lets Analysts Explore Large Datasets Faster. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI), Austin, TX, USA, 5–10 May 2012; Konstan, J.A., Chi, E.H., Höök, K., Eds.; ACM: New York, NY, USA, 2012; pp. 1673–1682. [Google Scholar] [CrossRef]
- Song, D.; Golin, E. Fine-grain visualization algorithms in dataflow environments. In Proceedings of the IEEE Conference on Visualization (VIS), San Jose, CA, USA, 25–29 October 1993; Nielson, G.M., Bergeron, D., Eds.; IEEE: Piscataway, NJ, USA, 1993; pp. 126–133. [Google Scholar] [CrossRef]
- Hellerstein, J.M.; Avnur, R.; Chou, A.; Hidber, C.; Olston, C.; Raman, V.; Roth, T.; Haas, P.J. Interactive Data Analysis: The Control Project. IEEE Comput. 1999, 32, 51–59. [Google Scholar] [CrossRef]
- Frey, S.; Sadlo, F.; Ma, K.L.; Ertl, T. Interactive Progressive Visualization with Space-Time Error Control. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2397–2406. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Choo, J.; Lee, C.; Lee, H.; Reddy, C.K.; Park, H. PIVE: Per-Iteration Visualization Environment for Real-time Interactions with Dimension Reduction and Clustering. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 1–9 February 2017; Singh, S., Markovitch, S., Eds.; AAAI: Menlo Park, CA, USA, 2017; pp. 1001–1009. [Google Scholar]
- Moritz, D.; Fisher, D.; Ding, B.; Wang, C. Trust, but Verify: Optimistic Visualizations of Approximate Queries for Exploring Big Data. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI), Denver, CO, USA, 6–11 May 2017; Lampe, C., Schraefel, M.C., Hourcade, J.P., Appert, C., Wigdor, D., Eds.; ACM: New York, NY, USA, 2017; pp. 2904–2915. [Google Scholar] [CrossRef]
- Kwon, B.C.; Verma, J.; Haas, P.J.; Demiralp, Ç. Sampling for Scalable Visual Analytics. IEEE Comput. Graph. Appl. 2017, 37, 100–108. [Google Scholar] [CrossRef] [PubMed]
- Zgraggen, E.; Galakatos, A.; Crotty, A.; Fekete, J.D.; Kraska, T. How Progressive Visualizations Affect Exploratory Analysis. IEEE Trans. Vis. Comput. Graph. 2017, 23, 1977–1987. [Google Scholar] [CrossRef] [PubMed]
- Lins, L.; Klosowski, J.T.; Scheidegger, C. Nanocubes for Real-Time Exploration of Spatiotemporal Datasets. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2456–2465. [Google Scholar] [CrossRef] [PubMed]
- Nocke, T.; Heyder, U.; Petri, S.; Vohland, K.; Wrobel, M.; Lucht, W. Visualization of Biosphere Changes in the Context of Climate Change. In Proceedings of the International Conference on IT and Climate Change (ITCC), Berlin, Germany, 25–26 September 2008; Wohlgemuth, V., Ed.; Trafo Wissenschaftsverlag: Berlin, Germany, 2009; pp. 29–36. [Google Scholar]
- Sacha, D.; Stoffel, A.; Stoffel, F.; Kwon, B.C.; Ellis, G.; Keim, D.A. Knowledge Generation Model for Visual Analytics. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1604–1613. [Google Scholar] [CrossRef] [PubMed]
- Badam, S.K.; Elmqvist, N.; Fekete, J.D. Steering the Craft: UI Elements and Visualizations for Supporting Progressive Visual Analytics. Comput. Graph. Forum 2017, 36, 491–502. [Google Scholar] [CrossRef]
- Marai, G.E. Activity-Centered Domain Characterization for Problem-Driven Scientific Visualization. IEEE Trans. Vis. Comput. Graph. 2018, 24, 913–922. [Google Scholar] [CrossRef] [PubMed]
- Amar, R.A.; Stasko, J.T. Knowledge Precepts for Design and Evaluation of Information Visualizations. IEEE Trans. Vis. Comput. Graph. 2005, 11, 432–442. [Google Scholar] [CrossRef] [PubMed]
- Fink, A. Conducting Research Literature Reviews: From the Internet to Paper, 4th ed.; SAGE Publishing: Thousand Oaks, CA, USA, 2014. [Google Scholar]
- Hellerstein, J.M.; Haas, P.J.; Wang, H.J. Online Aggregation. SIGMOD Record 1997, 26, 171–181. [Google Scholar] [CrossRef]
- Ding, X.; Jin, H. Efficient and Progressive Algorithms for Distributed Skyline Queries over Uncertain Data. IEEE Trans. Knowl. Data Eng. 2012, 24, 1448–1462. [Google Scholar] [CrossRef]
- Chandramouli, B.; Goldstein, J.; Quamar, A. Scalable Progressive Analytics on Big Data in the Cloud. Proc. VLDB Endow. 2013, 6, 1726–1737. [Google Scholar] [CrossRef]
- Im, J.F.; Villegas, F.G.; McGuffin, M.J. VisReduce: Fast and responsive incremental information visualization of large datasets. In Proceedings of the IEEE International Conference on Big Data (BigData), Silicon Valley, CA, USA, 6–9 October 2013; Hu, X., Lin, T.Y., Raghavan, V., Wah, B., Baeza-Yates, R., Fox, G., Shahabi, C., Smith, M., Yang, Q., Ghani, R., et al., Eds.; IEEE: Piscataway, NJ, USA, 2013; pp. 25–32. [Google Scholar] [CrossRef]
- Procopio, M.; Scheidegger, C.; Wu, E.; Chang, R. Load-n-Go: Fast Approximate Join Visualizations That Improve Over Time. In Proceedings of the Workshop on Data Systems for Interactive Analysis (DSIA), Phoenix, AZ, USA, 1–2 October 2017. [Google Scholar]
- Hetzler, E.G.; Crow, V.L.; Payne, D.A.; Turner, A.E. Turning the bucket of text into a pipe. In Proceedings of the IEEE Symposium on Information Visualization (InfoVis), Minneapolis, MN, USA, 23–25 October 2005; Stasko, J., Ward, M.O., Eds.; IEEE: Piscataway, NJ, USA, 2005; pp. 89–94. [Google Scholar] [CrossRef]
- Wong, P.C.; Foote, H.; Adams, D.; Cowley, W.; Thomas, J. Dynamic visualization of transient data streams. In Proceedings of the IEEE Symposium on Information Visualization (InfoVis), Seattle, WA, USA, 20–21 October 2003; Munzner, T., North, S., Eds.; IEEE: Piscataway, NJ, USA, 2003; pp. 97–104. [Google Scholar] [CrossRef]
- García, I.; Casado, R.; Bouchachia, A. An Incremental Approach for Real-Time Big Data Visual Analytics. In Proceedings of the IEEE International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Vienna, Austria, 22–24 August 2016; Younas, M., Awan, I., Haddad, J.E., Eds.; IEEE: Piscataway, NJ, USA, 2016; pp. 177–182. [Google Scholar] [CrossRef]
- Crouser, R.J.; Franklin, L.; Cook, K. Rethinking Visual Analytics for Streaming Data Applications. IEEE Int. Comput. 2017, 21, 72–76. [Google Scholar] [CrossRef]
- Angelini, M.; Corriero, R.; Franceschi, F.; Geymonat, M.; Mirabelli, M.; Remondino, C.; Santucci, G.; Stabellini, B. A Visual Analytics System for Mobile Telecommunication Marketing Analysis. In Proceedings of the International EuroVis Workshop on Visual Analytics (EuroVA), Groningen, The Netherlands, 6–7 June 2016; Andrienko, N., Sedlmair, M., Eds.; Eurographics Association: Aire-la-Ville, Switzerland, 2016. [Google Scholar] [CrossRef]
- Elmqvist, N.; Vande Moere, A.; Jetter, H.C.; Cernea, D.; Reiterer, H.; Jankun-Kelly, T.J. Fluid interaction for information visualization. Inform. Vis. 2011, 10, 327–340. [Google Scholar] [CrossRef]
- Shneiderman, B. Response time and display rate in human performance with computers. ACM Comput. Surv. 1984, 16, 265–285. [Google Scholar] [CrossRef]
- Card, S.; Robertson, G.; Mackinlay, J. The information visualizer, an information workspace. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI), New Orleans, LA, USA, 27 April–2 May 1991; Robertson, S.P., Olson, G.M., Olson, J.S., Eds.; ACM: New York, NY, USA, 1991; pp. 181–188. [Google Scholar] [CrossRef]
- Liu, Z.; Heer, J. The Effects of Interactive Latency on Exploratory Visual Analysis. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2122–2131. [Google Scholar] [CrossRef] [PubMed]
- Qu, H.; Zhou, H.; Wu, Y. Controllable and Progressive Edge Clustering for Large Networks. In Graph Drawing. GD 2006. Lecture Notes in Computer Science; Kaufmann, M., Wagner, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 399–404. [Google Scholar] [CrossRef]
- Jo, J.; Seo, J.; Fekete, J.D. A Progressive k-d tree for Approximate k-Nearest Neighbors. In Proceedings of the Workshop on Data Systems for Interactive Analysis (DSIA), Phoenix, AZ, USA, 1–2 October 2017; Chang, R., Scheidegger, C., Fisher, D., Heer, J., Eds.; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Fisher, D. Big Data Exploration Requires Collaboration Between Visualization and Data Infrastructures. In Proceedings of the Workshop on Human-In-the-Loop Data Analytics (HILDA), San Francisco, CA, USA, 26 June–1 July 2016; Binnig, C., Fekete, A., Nandi, A., Eds.; ACM: New York, NY, USA, 2016; pp. 16:1–16:5. [Google Scholar] [CrossRef]
- Crotty, A.; Galakatos, A.; Zgraggen, E.; Binnig, C.; Kraska, T. The Case for Interactive Data Exploration Accelerators (IDEAs). In Proceedings of the Workshop on Human-In-the-Loop Data Analytics (HILDA), San Francisco, CA, USA, 26 June–1 July 2016; Binnig, C., Fekete, A., Nandi, A., Eds.; ACM: New York, NY, USA, 2016; pp. 11:1–11:6. [Google Scholar] [CrossRef]
- Angelini, M.; Santucci, G. On Visual Stability and Visual Consistency for Progressive Visual Analytics. In Proceedings of the International Conference on Information Visualization Theory and Applications (IVAPP), Porto, Portugal, 27 February–1 March 2017; Linsen, L., Telea, A., Braz, J., Eds.; SciTePress: Setúbal, Portugal, 2017; pp. 335–341. [Google Scholar] [CrossRef]
- Ferreira, N.; Fisher, D.; König, A.C. Sample-oriented task-driven visualizations: Allowing users to make better, more confident decisions. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI), Paris, France, 27 April–2 May 2014; Schmidt, A., Grossman, T., Eds.; ACM: New York, NY, USA, 2014; pp. 571–580. [Google Scholar] [CrossRef]
- Angelini, M.; Santucci, G. Modeling Incremental Visualizations. In Proceedings of the International EuroVis Workshop on Visual Analytics (EuroVA), Leipzig, Germany, 17–18 June 2013; Pohl, M., Schumann, H., Eds.; Eurographics Association: Aire-la-Ville, Switzerland, 2013; pp. 13–17. [Google Scholar] [CrossRef]
- Frishman, Y.; Tal, A. Online Dynamic Graph Drawing. IEEE Trans. Vis. Comput. Graph. 2008, 14, 727–740. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Xu, L.; Chang, R.; Hellerstein, J.M.; Wu, E. Making Sense of Asynchrony in Interactive Data Visualizations. arXiv, 2018; arXiv:1806.01499. [Google Scholar]
- Rahman, S.; Aliakbarpour, M.; Kong, H.K.; Blais, E.; Karahalios, K.; Parameswaran, A.; Rubinfield, R. I’ve Seen “Enough”: Incrementally Improving Visualizations to Support Rapid Decision Making. Proc. VLDB Endow. 2017, 10, 1262–1273. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D., Jr.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Kobourov, S.G. Force-Directed Drawing Algorithms. In Handbook of Graph Drawing and Visualization; Tamassia, R., Ed.; CRC Press: Boca Raton, FL, USA, 2013; Chapter 12; pp. 383–408. [Google Scholar]
- Pezzotti, N.; Höllt, T.; van Gemert, J.; Lelieveldt, B.P.; Eisemann, E.; Vilanova, A. DeepEyes: Progressive Visual Analytics for Designing Deep Neural Networks. IEEE Trans. Vis. Comput. Graph. 2018, 24, 98–108. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Zhang, H.; Liu, Y.; Zhang, Y.; Zhang, X. Pattern Discovery: A Progressive Visual Analytic Design to Support Categorical Data Analysis. J. Vis. Lang. Comput. 2017, 43, 42–49. [Google Scholar] [CrossRef]
- Boukhelifa, N.; Perrin, M.E.; Huron, S.; Eagan, J. How Data Workers Cope with Uncertainty: A Task Characterisation Study. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI), Denver, CO, USA, 6–11 May 2017; Lampe, C., Schraefel, M.C., Hourcade, J.P., Appert, C., Wigdor, D., Eds.; ACM: New York, NY, USA, 2017; pp. 3645–3656. [Google Scholar]
- Pham, D.T.; Dimov, S.S.; Nguyen, C.D. An Incremental k-means Algorithm. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2004, 218, 783–795. [Google Scholar] [CrossRef]
- Williams, M.; Munzner, T. Steerable, Progressive Multidimensional Scaling. In Proceedings of the IEEE Symposium on Information Visualization (InfoVis), Austin, TX, USA, 10–12 October 2004; Ward, M.O., Munzner, T., Eds.; IEEE: Piscataway, NJ, USA, 2004; pp. 57–64. [Google Scholar] [CrossRef]
- Pezzotti, N.; Lelieveldt, B.; van der Maaten, L.; Hollt, T.; Eisemann, E.; Vilanova, A. Approximated and user steerable tSNE for progressive visual analytics. IEEE Trans. Vis. Comput. Graph. 2017, 23, 1739–1752. [Google Scholar] [CrossRef] [PubMed]
- Rosenbaum, R.; Hamann, B. Progressive Presentation of Large Hierarchies Using Treemaps. In Advances in Visual Computing; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Kuno, Y., Wang, J., Pajarola, R., Lindstrom, P., Hinkenjann, A., Encarnação, M.L., et al., Eds.; Number 5876 in Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; pp. 71–80. [Google Scholar] [CrossRef]
- Heinrich, J.; Bachthaler, S.; Weiskopf, D. Progressive Splatting of Continuous Scatterplots and Parallel Coordinates. Comput. Graph. Forum 2011, 30, 653–662. [Google Scholar] [CrossRef]
- Rosenbaum, R.; Zhi, J.; Hamann, B. Progressive parallel coordinates. In Proceedings of the IEEE Pacific Visualization Symposium (PacificVis), Songdo, Korea, 28 February–2 March 2012; Hauser, H., Kobourov, S., Qu, H., Eds.; IEEE: Piscataway, NJ, USA, 2012; pp. 25–32. [Google Scholar] [CrossRef]





© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Angelini, M.; Santucci, G.; Schumann, H.; Schulz, H.-J. A Review and Characterization of Progressive Visual Analytics. Informatics 2018, 5, 31. https://doi.org/10.3390/informatics5030031
Angelini M, Santucci G, Schumann H, Schulz H-J. A Review and Characterization of Progressive Visual Analytics. Informatics. 2018; 5(3):31. https://doi.org/10.3390/informatics5030031
Chicago/Turabian StyleAngelini, Marco, Giuseppe Santucci, Heidrun Schumann, and Hans-Jörg Schulz. 2018. "A Review and Characterization of Progressive Visual Analytics" Informatics 5, no. 3: 31. https://doi.org/10.3390/informatics5030031
APA StyleAngelini, M., Santucci, G., Schumann, H., & Schulz, H.-J. (2018). A Review and Characterization of Progressive Visual Analytics. Informatics, 5(3), 31. https://doi.org/10.3390/informatics5030031