Fitness Activity Recognition on Smartphones Using Doppler Measurements

 , ,
, ,  , and
, and
Abstract
1. Introduction
2. Physical Principles and Preprocessing Algorithm
3. Hardware Limitations and Placement
4. Classification Methods and Evaluation
4.1. Classical Machine Learning Classification Schemes
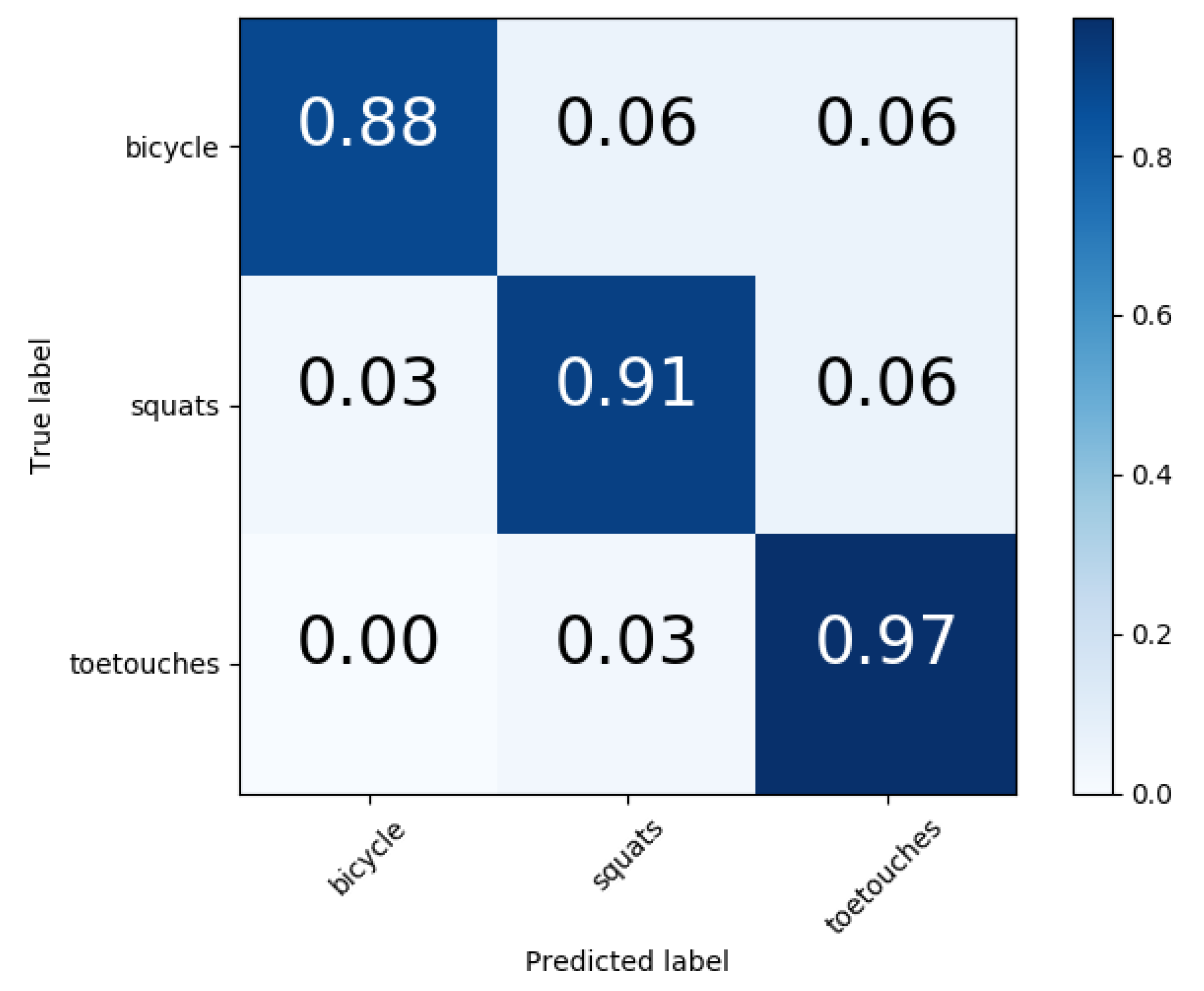
4.2. Evaluation and Comparison
4.3. Activity Recognition Based on Convolutional Neural Networks
5. Conclusion and Outlook
Author Contributions
Conflicts of Interest
References
- Anderson, F.; Grossman, T.; Matejka, J.; Fitzmaurice, G. YouMove: Enhancing Movement Training with an Augmented Reality Mirror. In Proceedings of the 26th Annual ACM Symposium on User Interface Software and Technology, St. Andrews, UK, 8–11 October 2013; pp. 311–320. [Google Scholar]
- Velloso, E.; Bulling, A.; Gellersen, H. MotionMA: Motion Modelling and Analysis by Demonstration. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 1309–1318. [Google Scholar]
- Kirchbuchner, F.; Grosse-Puppendahl, T.; Hastall, M.R.; Distler, M.; Kuijper, A. Ambient Intelligence from Senior Citizens’ Perspectives: Understanding Privacy Concerns, Technology Acceptance, and Expectations. In Ambient Intelligence; Springer: Berlin, Germany, 2015; pp. 48–59. [Google Scholar]
- Ding, H.; Shangguan, L.; Yang, Z.; Han, J.; Zhou, Z.; Yang, P.; Xi, W.; Zhao, J. FEMO: A Platform for Free-weight Exercise Monitoring with RFIDs. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Korea, 1–4 November 2015; pp. 141–154. [Google Scholar]
- Mitchell, E.; Monaghan, D.; O’Connor, N.E. Classification of Sporting Activities Using Smartphone Accelerometers. Sensors 2013, 13, 5317–5337. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, A. Implicit human computer interaction through context. Pers. Technol. 2000, 4, 191–199. [Google Scholar] [CrossRef]
- Lu, H.; Pan, W.; Lane, N.D.; Choudhury, T.; Campbell, A.T. SoundSense: Scalable Sound Sensing for People-centric Applications on Mobile Phones. In Proceedings of the 7th International Conference on Mobile Systems, Applications, and Services, Kraków, Poland, 22–25 June 2009; ACM: New York, NY, USA, 2009; pp. 165–178. [Google Scholar]
- Schweizer, I.; Bärtl, R.; Schulz, A.; Probst, F.; Mühlhäuser, M. NoiseMap-Real-time participatory noise maps. In Proceedings of the Second International Workshop on Sensing Applications on Mobile Phones, Seattle, WA, USA, 1–4 November 2011. [Google Scholar]
- Popescu, M.; Li, Y.; Skubic, M.; Rantz, M. An acoustic fall detector system that uses sound height information to reduce the false alarm rate. In Proceedings of the 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Vancouver, BC, Canada, 20–24 August 2008; pp. 4628–4631. [Google Scholar]
- Fu, B.; Karolus, J.; Grosse-Puppendahl, T.; Herrmann, J.; Kuijper, A. Opportunities for Activity Recognition using Ultrasound Doppler Sensing on Unmodified Mobile Phones. In Proceedings of the 2nd international Workshop on Sensor-based Activity Recognition and Interaction, Rostock, Germany, 25–26 June 2015. [Google Scholar]
- Gupta, S.; Morris, D.; Patel, S.; Tan, D. SoundWave: Using the Doppler Effect to Sense Gestures. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, Texas, USA, 5–10 May 2012; pp. 1911–1914. [Google Scholar]
- Aumi, M.T.I.; Gupta, S.; Goel, M.; Larson, E.; Patel, S. DopLink: Using the Doppler Effect for Multi-device Interaction. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; pp. 583–586. [Google Scholar]
- Sun, Z.; Purohit, A.; Bose, R.; Zhang, P. Spartacus: Spatially-aware Interaction for Mobile Devices Through Energy-efficient Audio Sensing. In Proceedings of the 11th Annual International Conference on Mobile Systems, Applications, and Services, Taipei, Taiwan, 25–28 June 2013; pp. 263–276. [Google Scholar]
- Yang, Q.; Tang, H.; Zhao, X.; Li, Y.; Zhang, S. Dolphin: Ultrasonic-Based Gesture Recognition on Smartphone Platform. In Proceedings of the 2014 IEEE 17th International Conference on Computational Science and Engineering (CSE), Chengdu, China, 19–21 December 2014; pp. 1461–1468. [Google Scholar]
- Ruan, W.; Sheng, Q.Z.; Yang, L.; Gu, T.; Xu, P.; Shangguan, L. AudioGest: Enabling Fine-grained Hand Gesture Detection by Decoding Echo Signal. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; ACM: New York, NY, USA, 2016; pp. 474–485. [Google Scholar]
- Nandakumar, R.; Gollakota, S.; Watson, N. Contactless Sleep Apnea Detection on Smartphones. In Proceedings of the 13th Annual International Conference on Mobile Systems, Applications, and Services, Florence, Italy, 18–22 May 2015; ACM: New York, NY, USA, 2015; pp. 45–57. [Google Scholar]
- Nandakumar, R.; Iyer, V.; Tan, D.; Gollakota, S. FingerIO: Using Sonar for Fine-Grained Finger Tracking. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016. [Google Scholar]
- Xi, W.; Huang, D.; Zhao, K.; Yan, Y.; Cai, Y.; Ma, R.; Chen, D. Device-free Human Activity Recognition Using CSI. In Proceedings of the 1st Workshop on Context Sensing and Activity Recognition, Seoul, Korea, 1 November 2015; pp. 31–36. [Google Scholar]
- Fu, B.; Gangatharan, D.V.; Kuijper, A.; Kirchbuchner, F.; Braun, A. Exercise Monitoring On Consumer smartphones Using Ultrasonic Sensing. In Proceedings of the 4th International Workshop on Sensor-based Activity Recognition and Interaction, Rostock, Germany, 21–22 September 2017; ACM: New York, NY, USA, 2017. [Google Scholar]
- Shan, X.J.; Yin, J.Y.; Yu, D.L.; Li, C.F.; Zhao, J.J.; Zhang, G.F. Analysis of artificial corner reflector’s radar cross section: A physical optics perspective. Arabian J. Geosci. 2013, 6, 2755–2765. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Smith, G.E.; Woodbridge, K.; Baker, C.J. Naíve Bayesian radar micro-doppler recognition. In Proceedings of the 2008 International Conference on Radar, Adelaide, SA, Australia, 2–5 September 2008; pp. 111–116. [Google Scholar]
- Ritchie, M.; Fioranelli, F.; Borrion, H.; Griffiths, H. Multistatic micro-doppler radar feature extraction for classification of unloaded/loaded micro-drones. IET Radar Sonar Navig. 2017, 11, 116–124. [Google Scholar] [CrossRef]
- Steinwart, I.; Christmann, A. Support Vector Machines; Springer Publishing Company, Incorporated: Berlin, Germany, 2008. [Google Scholar]
- Ronao, C.A.; Cho, S.B. Human Activity Recognition with Smartphone Sensors Using Deep Learning Neural Networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5—RmsProp: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Exercise | Minimum (TS) | Maximum (TS) | Minimum Duration (s) | Maximum Duration (s) |
|---|---|---|---|---|
| Bicycle | 13 | 31 | 0.60 | 1.44 |
| Squats | 12 | 42 | 0.55 | 1.95 |
| Toe touches | 11 | 25 | 0.51 | 1.16 |
| Estimators | Max Features | Tree Depth |
|---|---|---|
| 300 | sqrt | 100 |
| Kernel | Penalty Parameter | |
|---|---|---|
| Linear | 0.0001 | 1 |
| True Label | Predicted Label | |
|---|---|---|
| Positive Sample | Negative Sample | |
| Positive Sample | TP | FN |
| Negative Sample | FP | TN |
| Naive Bayes | Random Forest | Support Vector Machine | AdaBoost | |
|---|---|---|---|---|
| Precision | 64% | 77% | 84% | 77% |
| Recall | 61% | 68% | 83% | 75% |
| Accuracy | 60% | 72% | 83% | 76% |
| Naive Bayes | Random Forest | Support Vector Machine | AdaBoost | |
|---|---|---|---|---|
| Precision | 51% | 68% | 74% | 67% |
| Recall | 51% | 60% | 70% | 61% |
| Accuracy | 55% | 64% | 74% | 65% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, B.; Kirchbuchner, F.; Kuijper, A.; Braun, A.; Vaithyalingam Gangatharan, D. Fitness Activity Recognition on Smartphones Using Doppler Measurements. Informatics 2018, 5, 24. https://doi.org/10.3390/informatics5020024
Fu B, Kirchbuchner F, Kuijper A, Braun A, Vaithyalingam Gangatharan D. Fitness Activity Recognition on Smartphones Using Doppler Measurements. Informatics. 2018; 5(2):24. https://doi.org/10.3390/informatics5020024
Chicago/Turabian StyleFu, Biying, Florian Kirchbuchner, Arjan Kuijper, Andreas Braun, and Dinesh Vaithyalingam Gangatharan. 2018. "Fitness Activity Recognition on Smartphones Using Doppler Measurements" Informatics 5, no. 2: 24. https://doi.org/10.3390/informatics5020024
APA StyleFu, B., Kirchbuchner, F., Kuijper, A., Braun, A., & Vaithyalingam Gangatharan, D. (2018). Fitness Activity Recognition on Smartphones Using Doppler Measurements. Informatics, 5(2), 24. https://doi.org/10.3390/informatics5020024