
Visual Analysis of Relationships between Heterogeneous Networks and Texts: An Application on the IEEE VIS Publication Dataset


Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
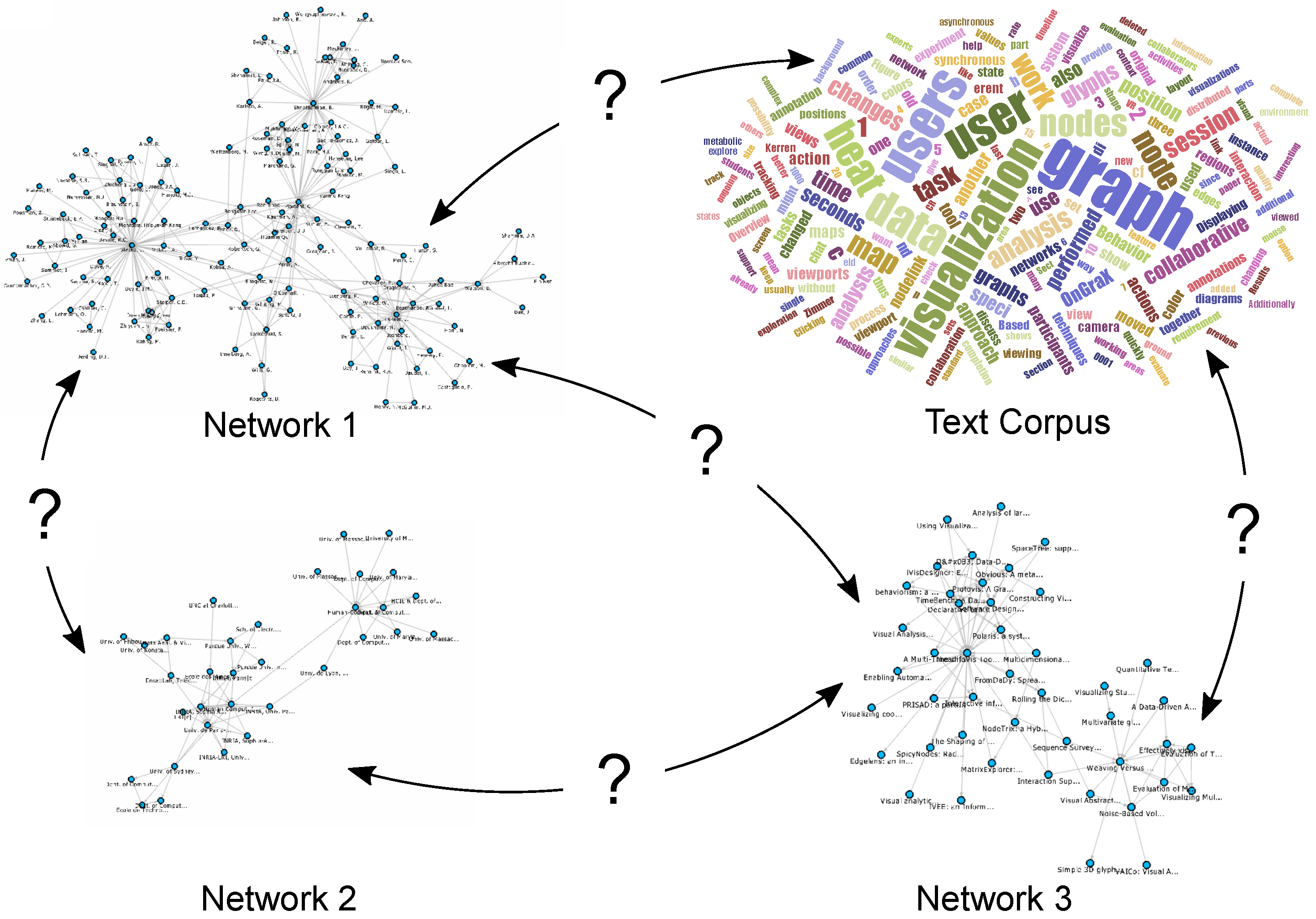
- we present a scalable system that gives analysts the possibility to interactively specify and explore mappings across interconnected heterogeneous networks with thousands of nodes and related data derived from text corpora;
- we provide a way to perform a search based on main keywords and semantically similar terms over the entire text corpus to find related nodes, which represent, for instance, papers, authors or affiliations;
- we introduce the technique “Hub2Go”, which enables users to quickly add and examine these nodes in the interconnected networks views; and
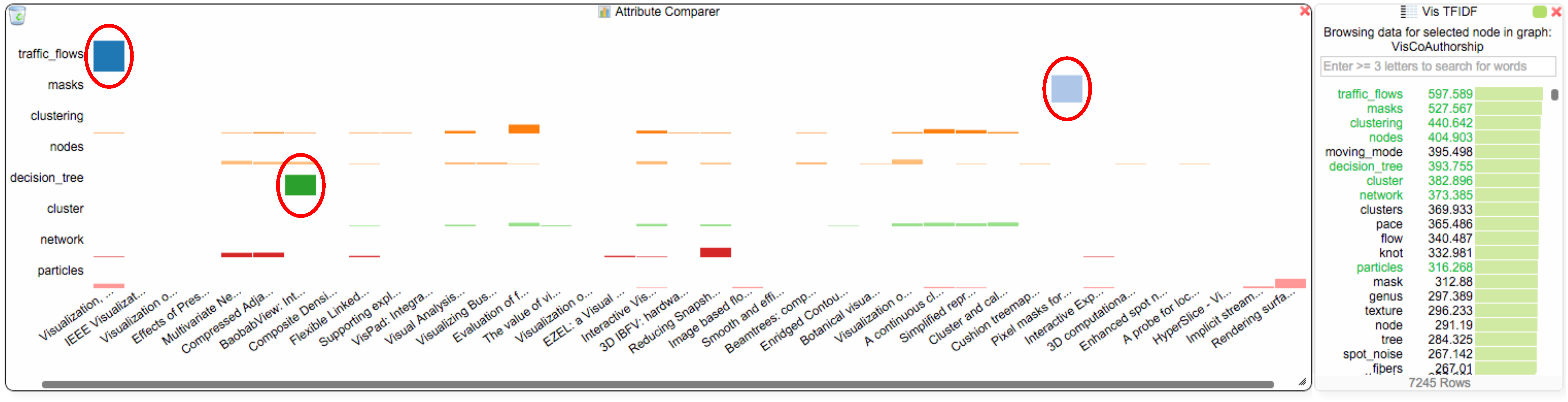
- we give the option to directly compare the usage of specific terms across a selection of nodes.
2. Related Work
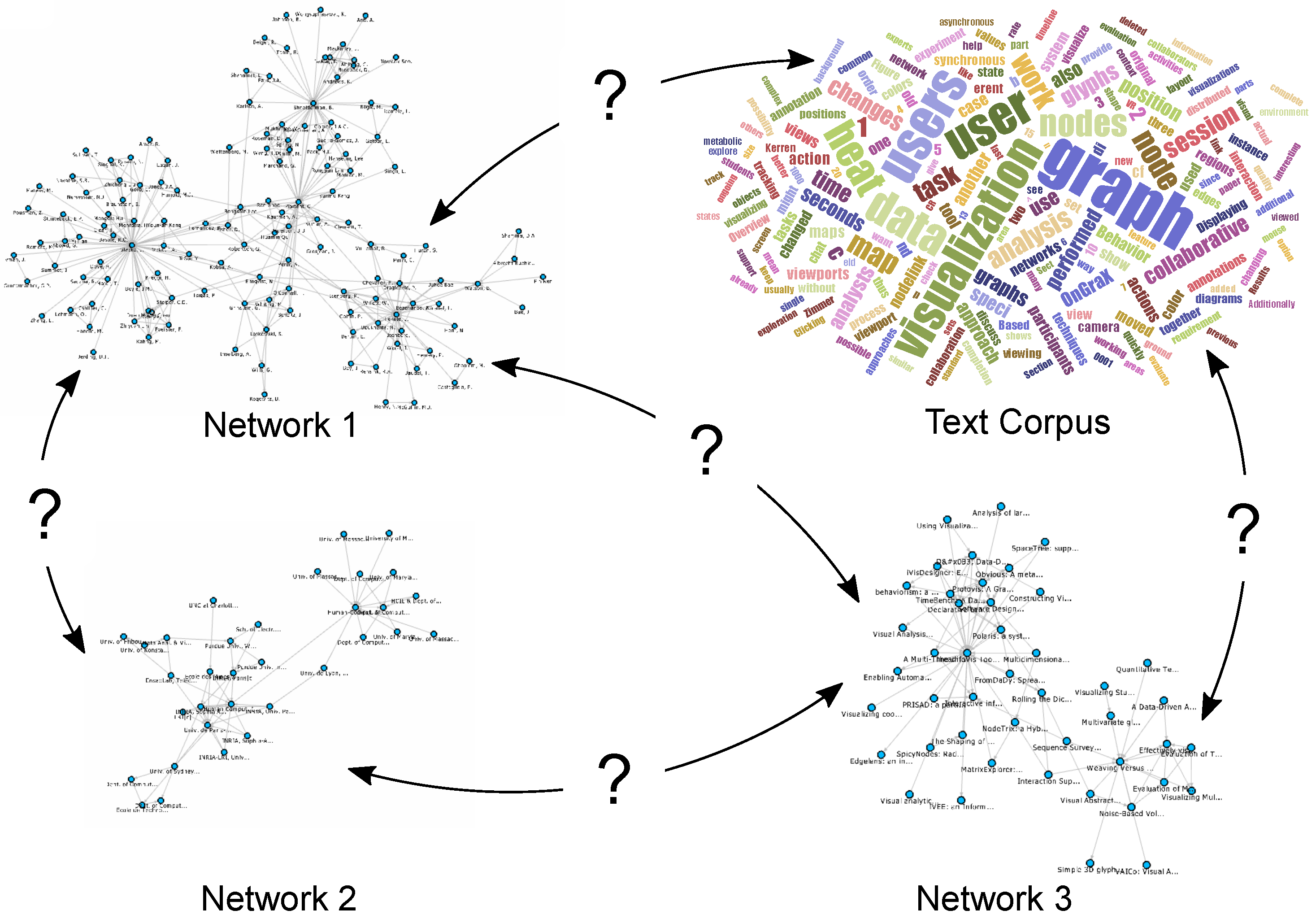
3. Data Sources and Preprocessing
3.1. Text Preprocessing
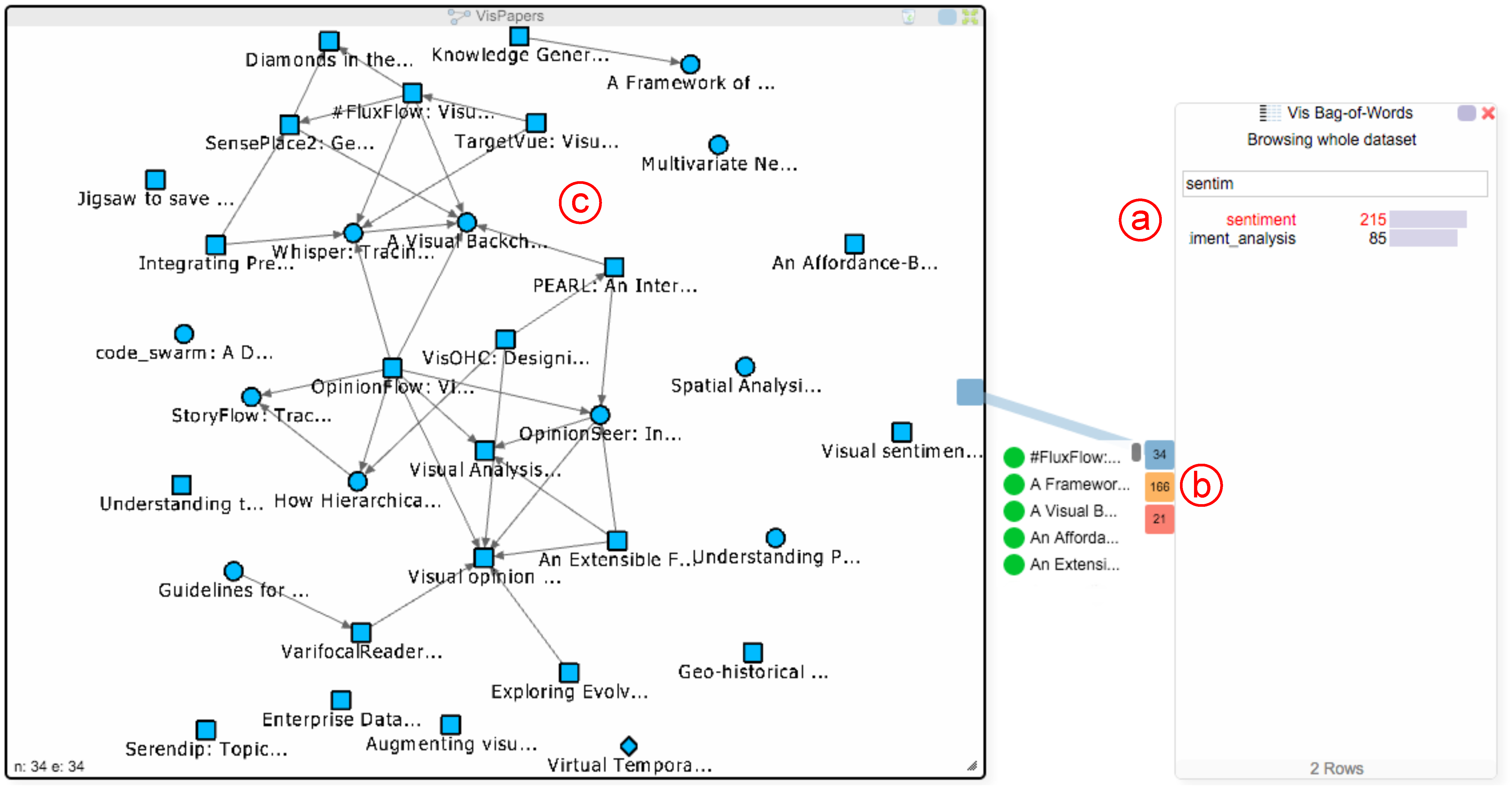
3.2. Bag-of-Words
3.3. Word Similarity
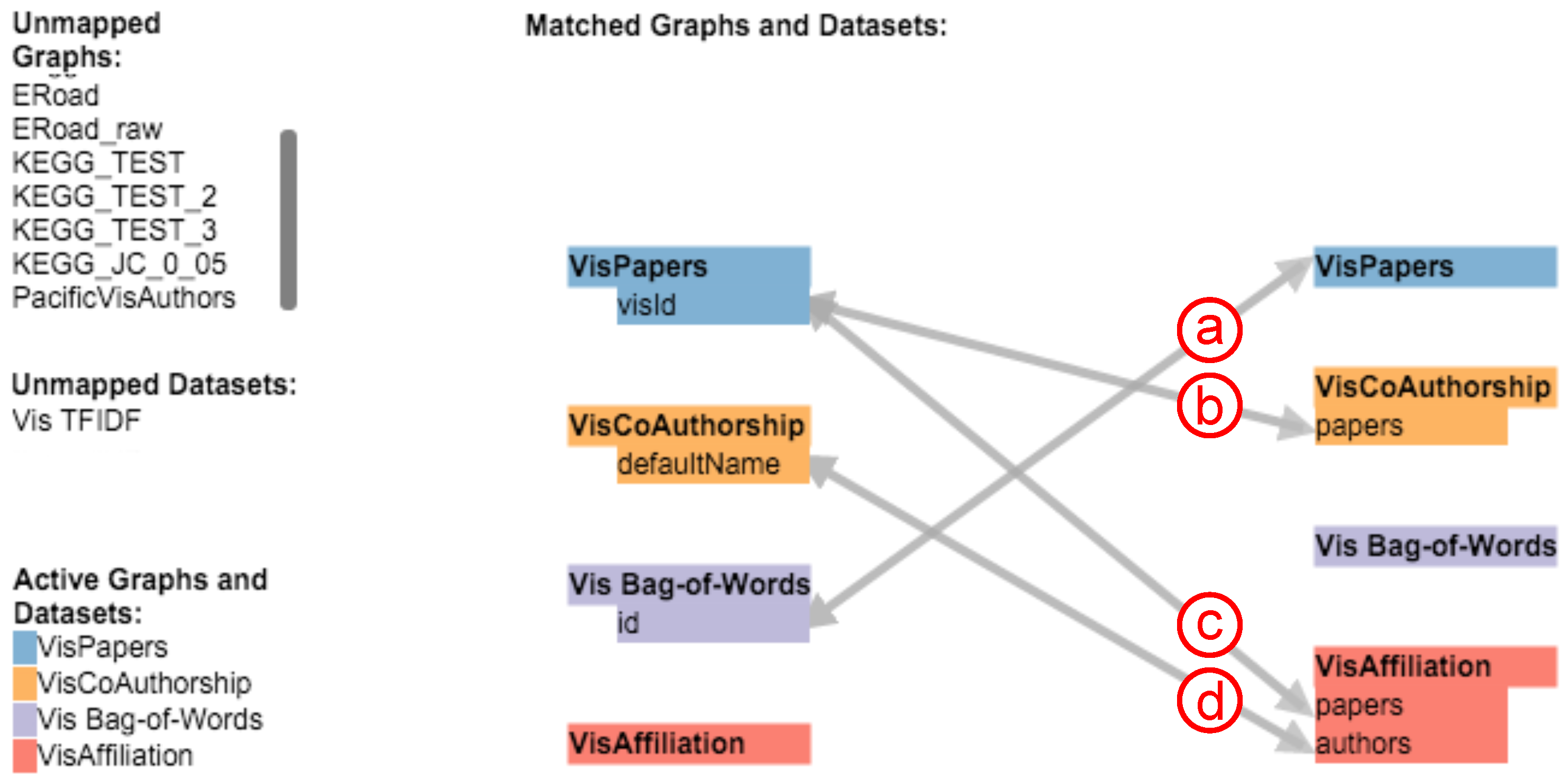
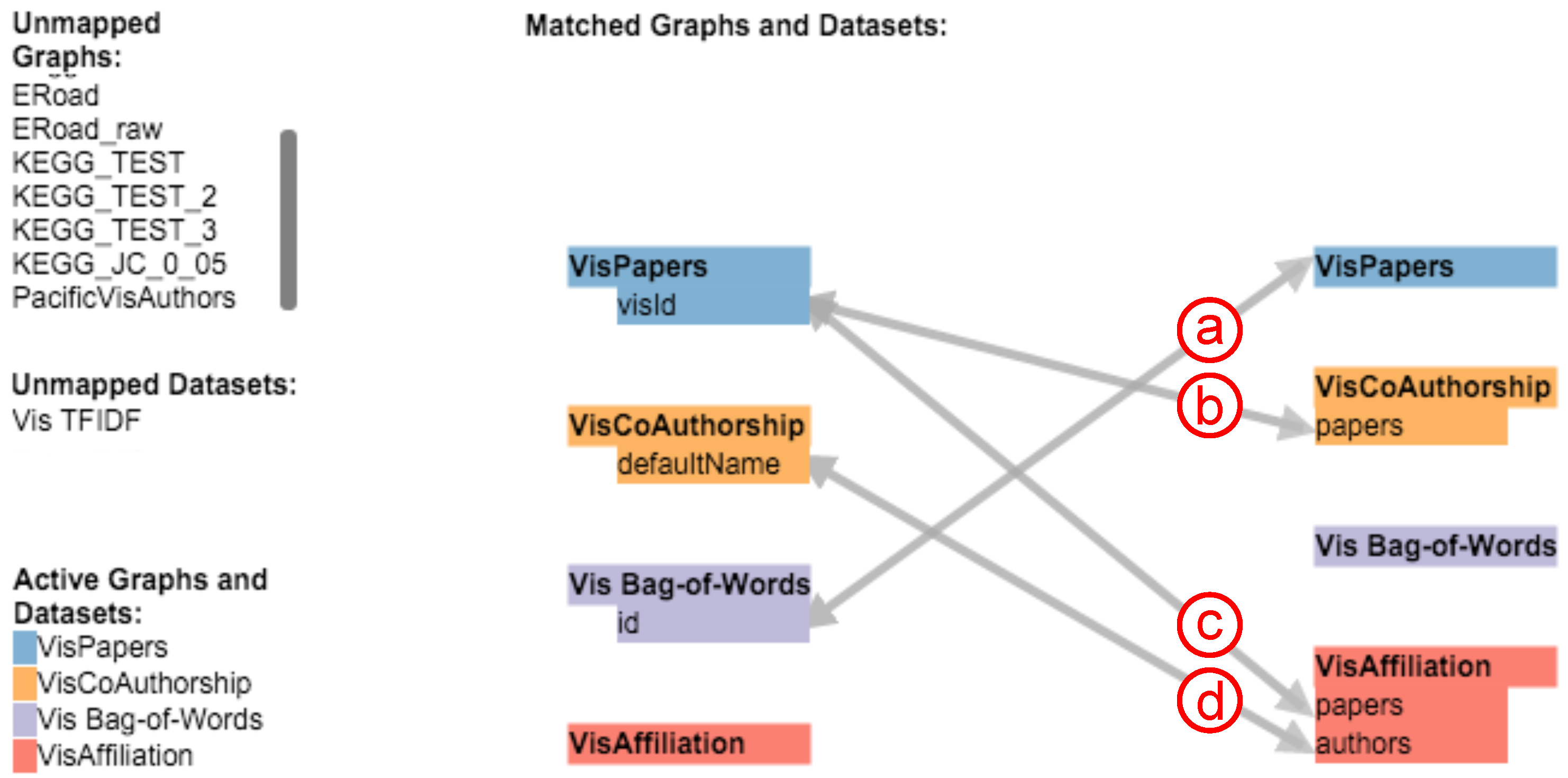
4. Specifying Attribute Mappings
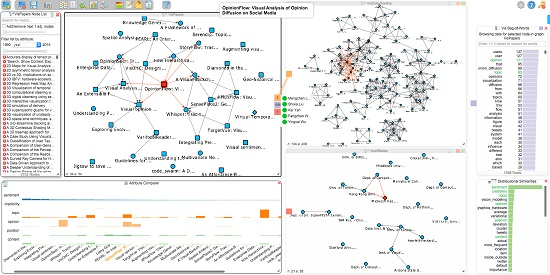
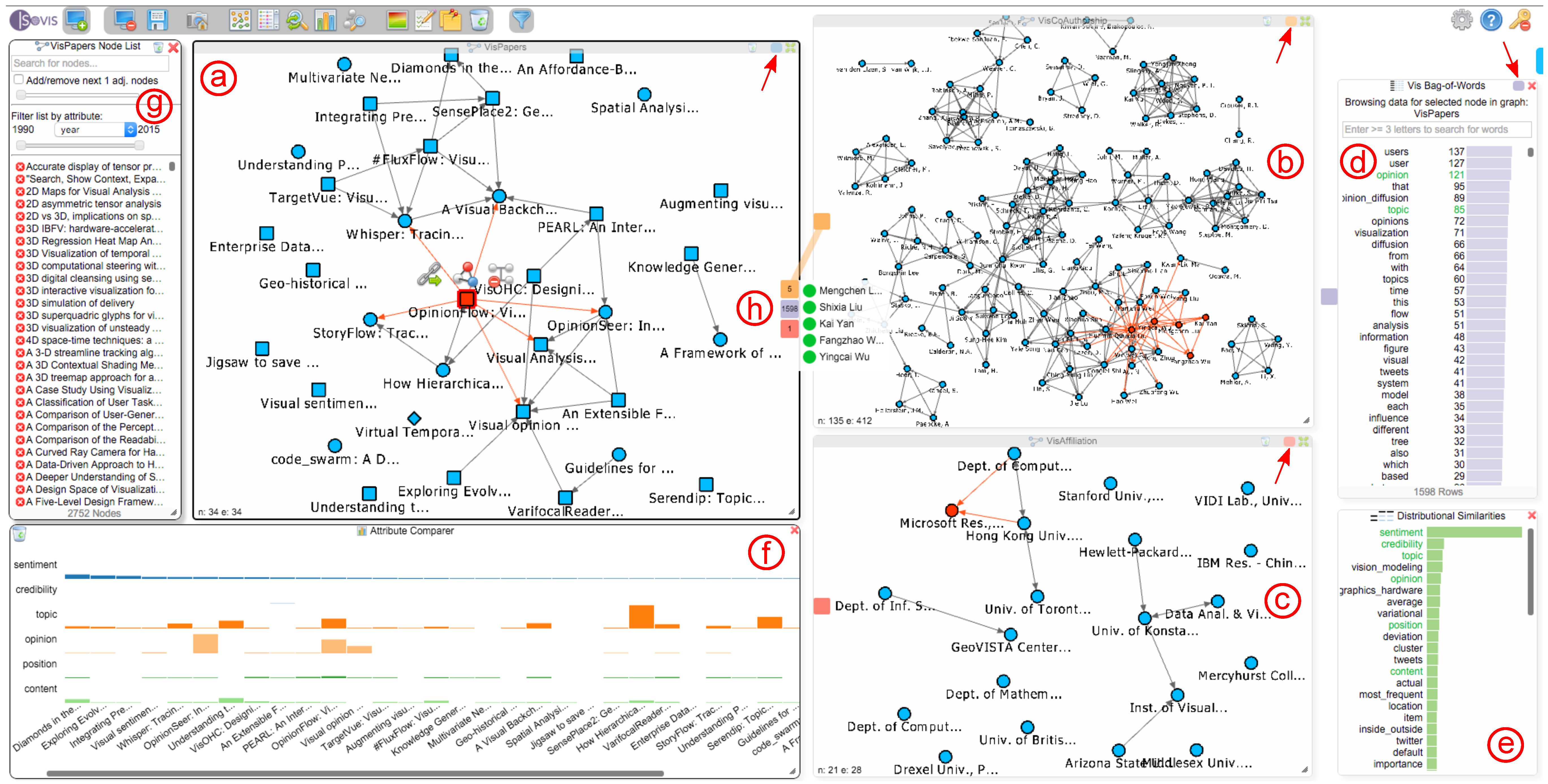
5. Visualization Approach
5.1. Visual Design
5.2. Hub2Go
6. Use Case
- Q1,
- author question: Which words/terms does van Wijk use in his papers? Answering this question would provide the student a first impression about van Wijk’s most important research areas.
- Q2,
- author question: Does he usually focus on the same terms throughout his papers or does he address various different topics, which would indicate a broad research interest?
- Q3,
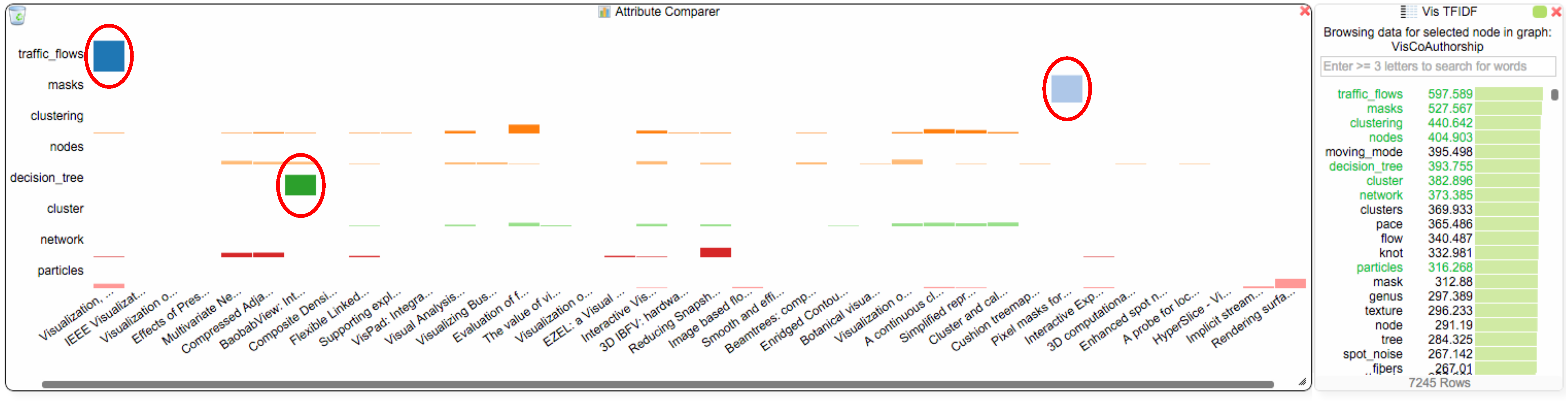
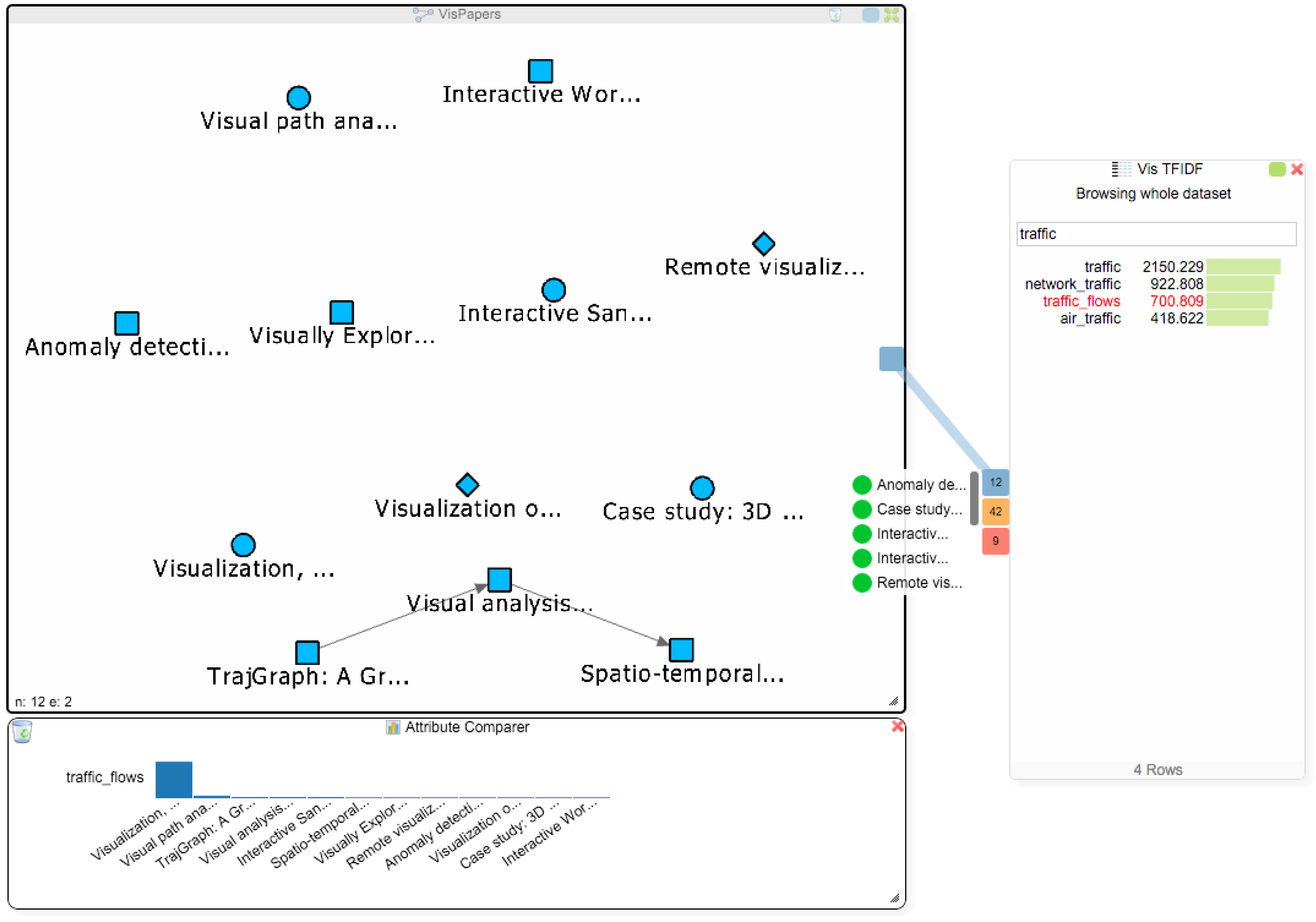
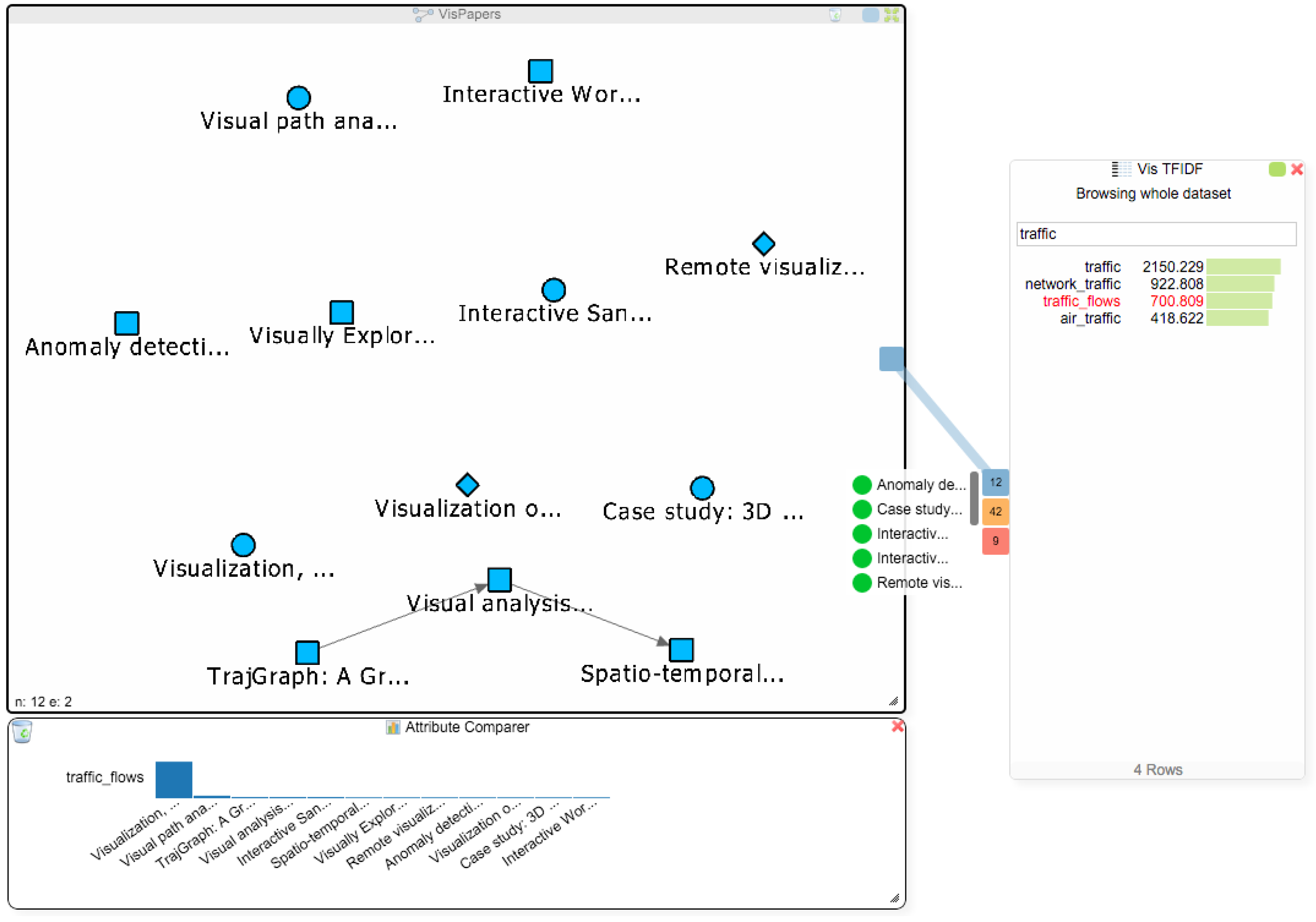
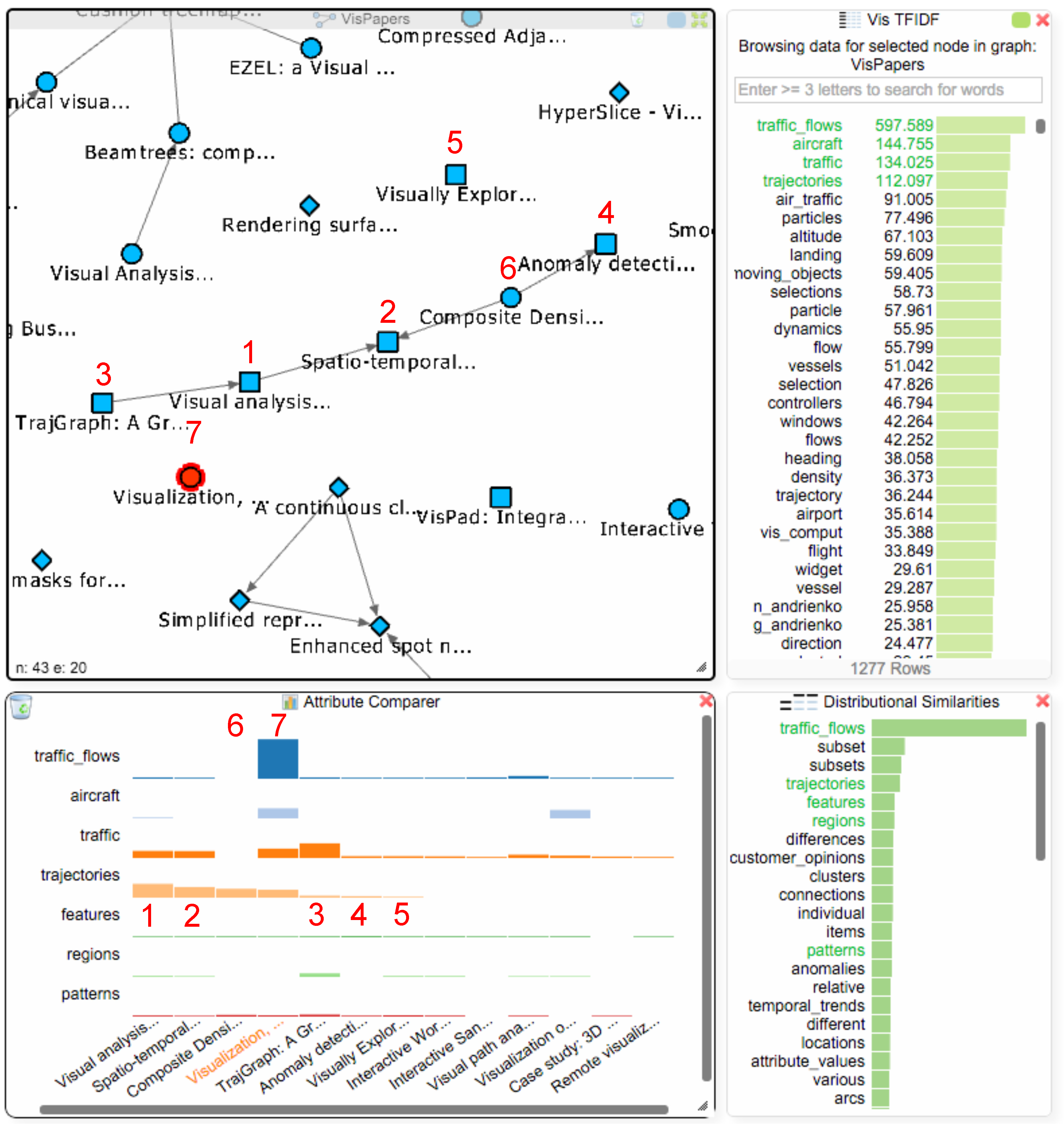
- paper question: Are there other papers related to the term “traffic_flows” that might be of interest to the student?
- Q4,
- paper question: Considering the term “traffic_flows”: are other terms in other papers used in a similar context, which would make those papers also interesting to the student?
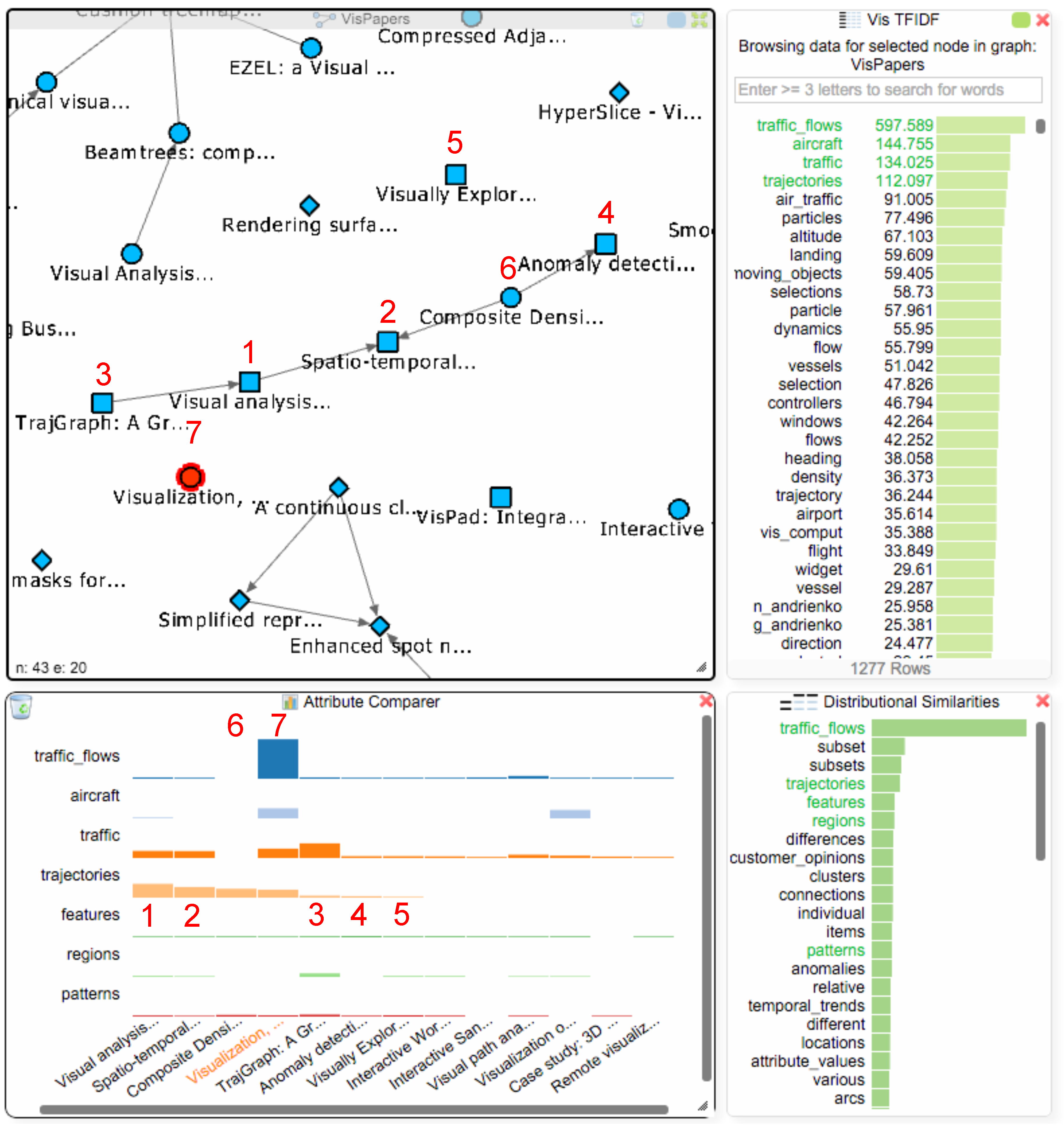
Analysis Step 1:
Analysis Step 2:
Analysis Step 3:
Analysis Step 4:
7. Discussion
8. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- IEEE VIS. IEEE Visualization Conference (VIS). Available online: http://ieeevis.org. (accessed on 9 May 2017).
- Kerren, A.; Purchase, H.; Ward, M.O. Multivariate Network Visualization; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2014. [Google Scholar]
- von Landesberger, T.; Kuijper, A.; Schreck, T.; Kohlhammer, J.; van Wijk, J.; Fekete, J.D.; Fellner, D. Visual Analysis of Large Graphs: State-of-the-Art and Future Research Challenges. Comput. Gr. Forum 2011, 30, 1719–1749. [Google Scholar] [CrossRef]
- Lex, A.; Streit, M.; Kruijff, E.; Schmalstieg, D. Caleydo: Design and Evaluation of a Visual Analysis Framework for Gene Expression Data in its Biological Context. In Proceedings of the 3rd IEEE Pacific Visualization Symposium, IEEE, PacificVis ’10, Taipei, Taiwan, 2–5 March 2010; pp. 57–64. [Google Scholar]
- Lex, A.; Partl, C.; Kalkofen, D.; Streit, M.; Gratzl, S.; Wassermann, A.M.; Schmalstieg, D.; Pfister, H. Entourage: Visualizing Relationships between Biological Pathways Using Contextual Subsets. IEEE Trans. Vis. Comput. Gr. 2013, 19, 2536–2545. [Google Scholar] [CrossRef] [PubMed]
- May, T.; Steiger, M.; Davey, J.; Kohlhammer, J. Using Signposts for Navigation in Large Graphs. Comput. Gr. Forum 2012, 31, 985–994. [Google Scholar] [CrossRef]
- Henry, N.; Fekete, J.D.; McGuffin, M.J. NodeTrix: A Hybrid Visualization of Social Networks. IEEE Trans. Vis. Comput. Gr. 2007, 13, 1302–1309. [Google Scholar] [CrossRef] [PubMed]
- Moscovich, T.; Chevalier, F.; Henry, N.; Pietriga, E.; Fekete, J.D. Topology-Aware Navigation in Large Networks. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009; pp. 2319–2328. [Google Scholar]
- Heer, J.; Perer, A. Orion: A System for Modeling, Transformation and Visualization of Multidimensional Heterogeneous Networks. Inf. Vis. 2012, 13, 111–133. [Google Scholar] [CrossRef]
- Liu, Z.; Navathe, S.B.; Stasko, J.T. Ploceus: Modeling, Visualizing, and Analyzing Tabular Data as Networks. Inf. Vis. 2014, 13, 59–89. [Google Scholar] [CrossRef]
- Kucher, K.; Kerren, A. Text Visualization Techniques: Taxonomy, Visual Survey, and Community Insights. In Proceedings of the 8th IEEE Pacific Visualization Symposium, 2015, PacificVis ’15, Hangzhou, China, 14–17 April 2015; pp. 117–121. [Google Scholar]
- Federico, P.; Heimerl, F.; Koch, S.; Miksch, S. A Survey on Visual Approaches for Analyzing Scientific Literature and Patents. IEEE Trans. Vis. Comput. Gr. 2016. [Google Scholar] [CrossRef] [PubMed]
- Görg, C.; Liu, Z.; Kihm, J.; Choo, J.; Park, H.; Stasko, J. Combining Computational Analyses and Interactive Visualization for Document Exploration and Sensemaking in Jigsaw. IEEE Trans. Vis. Comput. Gr. 2013, 19, 1646–1663. [Google Scholar] [CrossRef]
- Shen, Z.; Ogawa, M.; Teoh, S.T.; Ma, K.L. BiblioViz: A System for Visualizing Bibliography Information. In Proceedings of the 2006 Asia-Pacific Symposium on Information Visualisation, Tokyo, Japan, 1–3 February 2006; Volume 60, pp. 93–102. [Google Scholar]
- Zhao, J.; Collins, C.; Chevalier, F.; Balakrishnan, R. Interactive Exploration of Implicit and Explicit Relations in Faceted Datasets. IEEE Trans. Vis. Comput. Gr. 2013, 19, 2080–2089. [Google Scholar] [CrossRef] [PubMed]
- Van Ham, F.; Wattenberg, M.; Viegas, F.B. Mapping Text with Phrase Nets. IEEE Trans. Vis. Comput. Gr. 2009, 15, 1169–1176. [Google Scholar] [CrossRef] [PubMed]
- Kairam, S.; Riche, N.H.; Drucker, S.; Fernandez, R.; Heer, J. Refinery: Visual Exploration of Large, Heterogeneous Networks through Associative Browsing. Comput. Gr. Forum 2015, 34, 301–310. [Google Scholar] [CrossRef]
- Chen, F.; Chiu, P.; Lim, S. Topic Modeling of Document Metadata for Visualizing Collaborations over Time. In Proceedings of the 21st International Conference on Intelligent User Interfaces, Sonoma, CA, USA, 7–10 March 2016; pp. 108–117. [Google Scholar]
- Liu, S.; Chen, Y.; Wei, H.; Yang, J.; Zhou, K.; Drucker, S.M. Exploring Topical Lead-Lag across Corpora. IEEE Trans. Knowl. Data Eng. 2015, 27, 115–129. [Google Scholar] [CrossRef]
- Heimerl, F.; Han, Q.; Koch, S.; Ertl, T. CiteRivers: Visual Analytics of Citation Patterns. IEEE Trans. Vis. Comput. Gr. 2016, 22, 190–199. [Google Scholar] [CrossRef] [PubMed]
- Zimmer, B.; Kerren, A. Harnessing WebGL and WebSockets for a Web-Based Collaborative Graph Exploration Tool. In Proceedings of the 15th International Conference on Web Engineering, Rotterdam, The Netherlands, 23–26 June 2015; pp. 583–598. [Google Scholar]
- Zimmer, B.; Kerren, A. OnGraX: A Web-Based System for the Collaborative Visual Analysis of Graphs. J. Graph Algorithms Appl. 2017, 21, 5–27. [Google Scholar] [CrossRef]
- Isenberg, P.; Heimerl, F.; Koch, S.; Isenberg, T.; Xu, P.; Stolper, C.; Sedlmair, M.; Chen, J.; Möller, T.; Stasko, J. Visualization Publication Dataset, 2015. Available online: http://www.vispubdata.org/ (accessed on 9 May 2017).
- Chuang, J.; Manning, C.D.; Heer, J. Without the Clutter of Unimportant Words: Descriptive Keyphrases for Text Visualization. ACM Trans. Comput.-Hum. Interact. 2012, 19, 1–29. [Google Scholar] [CrossRef]
- Turney, P.D.; Pantel, P. From Frequency to Meaning: Vector Space Models of Semantics. J. Artif. Intell. Res. 2010, 37, 141–188. [Google Scholar]
- Turian, J.; Ratinov, L.; Bengio, Y. Word Representations: A Simple and General Method for Semi-supervised Learning. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 384–394. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the Neural Information Processing Systems Conference, Lake Tahoe, Nevada, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Dohar, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Kanerva, P.; Kristofersson, J.; Holst, A. Random Indexing of Text Samples for Latent Semantic Analysis. In Proceedings of the 22nd Annual Conference of the Cognitive Science Society, Cognitive Science Society, Philadelphia, PA, USA, 13–15 August 2000; p. 1036. [Google Scholar]
- Sahlgren, M.; Holst, A.; Kanerva, P. Permutations as a Means to Encode Order in Word Space. In Proceedings of the 30th Annual Conference of the Cognitive Science Society. Cognitive Science Society, Washington, DC, USA, 23–26 July 2008; pp. 1300–1305. [Google Scholar]
- Sahlgren, M.; Gyllensten, A.C.; Espinoza, F.; Hamfors, O.; Holst, A.; Karlgren, J.; Olsson, F.; Persson, P.; Viswanathan, A. The Gavagai Living Lexicon. In Proceedings of the 10th International Conference on Language Resources and Evaluation, Portorož, Slovenia, 23–28 May 2016; pp. 344–350. [Google Scholar]
- Harrower, M.; Brewer, C.A. ColorBrewer.org: An Online Tool for Selecting Colour Schemes for Maps. Cartogr. J. 2003, 40, 27–37. [Google Scholar] [CrossRef]
- Laboratories, K. KEGG: Kyoto Encyclopedia of Genes and Genomes. Available online: http://www.genome.jp/kegg/ (accessed on 9 May 2017).
- Chau, D.H.; Kittur, A.; Hong, J.I.; Faloutsos, C. Apolo: Making Sense of Large Network Data by Combining Rich User Interaction and Machine Learning. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 167–176. [Google Scholar]
- Gladisch, S.; Schumann, H.; Tominski, C. Navigation Recommendations for Exploring Hierarchical Graphs. In Proceedings of the 9th International Symposium on Advances in Visual Computing, Part II, Crete, Greece, 29–31 July 2013; pp. 36–47. [Google Scholar]
- Roberts, J.C. State of the Art: Coordinated & Multiple Views in Exploratory Visualization. In Proceedings of the Fifth International Conference on Coordinated and Multiple Views in Exploratory Visualization, Zürich, Switzerland, 2 July 2007; pp. 61–71. [Google Scholar]
- yWorks. yFiles for Java. Available online: https://www.yworks.com/products/yfiles-for-java. (accessed on 9 May 2017).
- Khronos Group. WebGL Specification. Editor’s Draft 24 February 2017. Available online: http://www.khronos.org/registry/webgl/specs/latest (accessed on 9 May 2017).


© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zimmer, B.; Sahlgren, M.; Kerren, A. Visual Analysis of Relationships between Heterogeneous Networks and Texts: An Application on the IEEE VIS Publication Dataset. Informatics 2017, 4, 11. https://doi.org/10.3390/informatics4020011
Zimmer B, Sahlgren M, Kerren A. Visual Analysis of Relationships between Heterogeneous Networks and Texts: An Application on the IEEE VIS Publication Dataset. Informatics. 2017; 4(2):11. https://doi.org/10.3390/informatics4020011
Chicago/Turabian StyleZimmer, Björn, Magnus Sahlgren, and Andreas Kerren. 2017. "Visual Analysis of Relationships between Heterogeneous Networks and Texts: An Application on the IEEE VIS Publication Dataset" Informatics 4, no. 2: 11. https://doi.org/10.3390/informatics4020011
APA StyleZimmer, B., Sahlgren, M., & Kerren, A. (2017). Visual Analysis of Relationships between Heterogeneous Networks and Texts: An Application on the IEEE VIS Publication Dataset. Informatics, 4(2), 11. https://doi.org/10.3390/informatics4020011