
Conversion of Legal Text to a Logical Rules Set from Medical Law Using the Medical Relational Model and the World Rule Model for a Medical Decision Support System

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
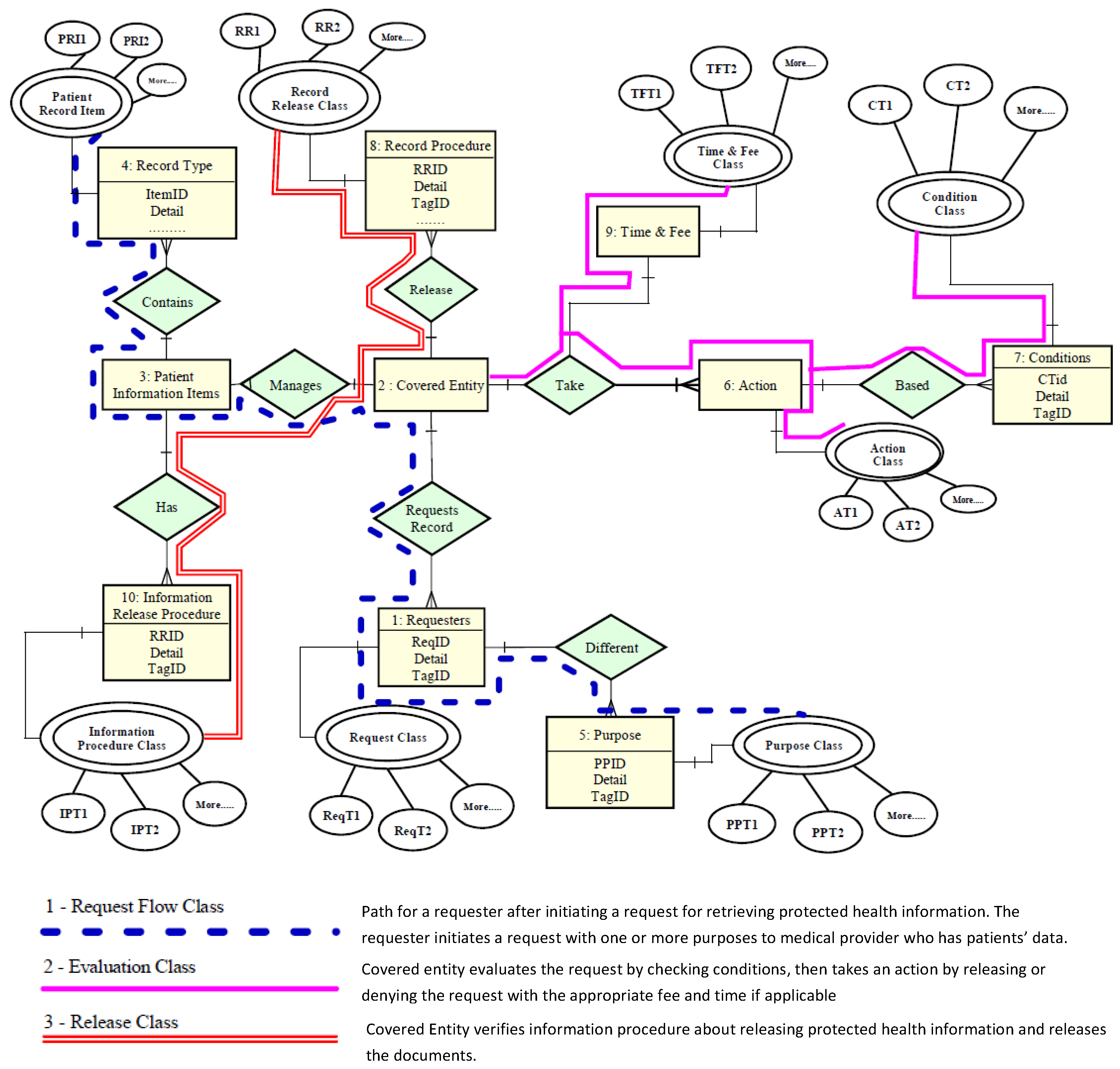
2.1. Concept Space of HIPAA
2.2. Tags’ Set
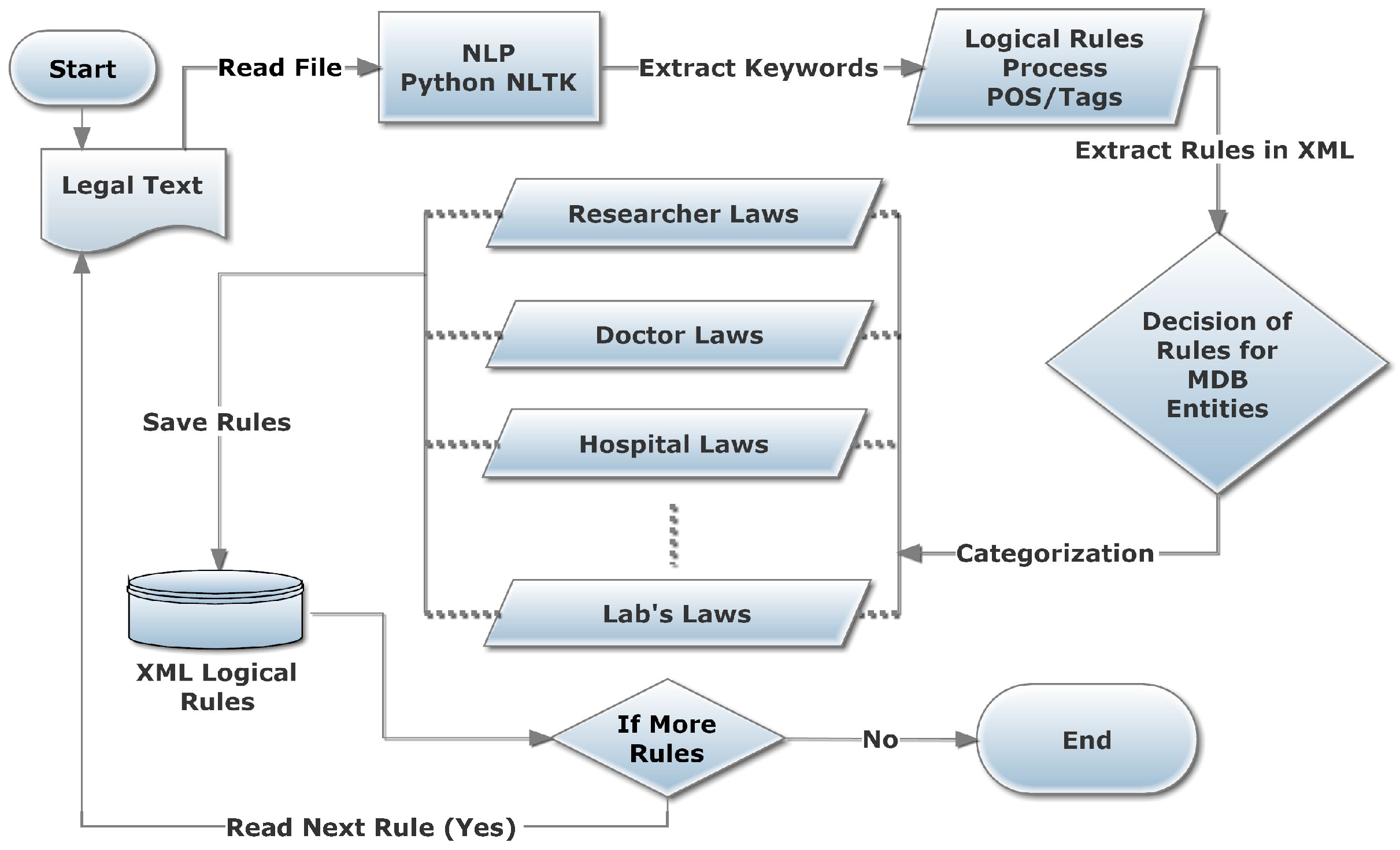
2.3. Rule Set Formation from HIPAA
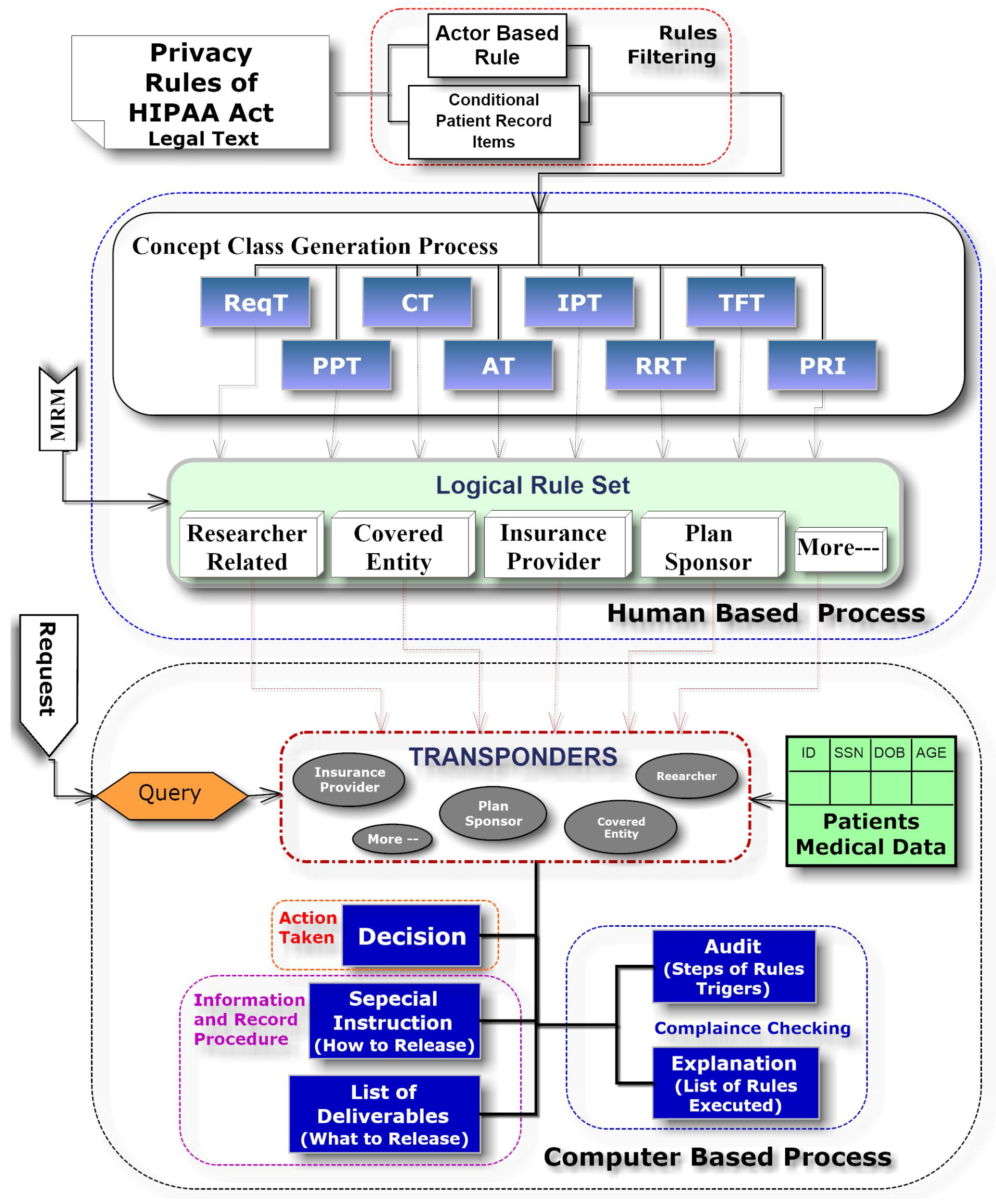
2.4. HIPAA Rules’ Filtration through the World Rule Model
<rules>
<rule ruleid = "164.512.b">
<Request>access</Request>
<Requester>patient</Requester>
<Entity>hospital</Entity>
<AccessLevel>permission</AccessLevel>
<Condition>hospital_Law_3</Condition>
<CrossReference>164.508.a.1</CrossReference>
</rule>
</rules>
 |
3. Results
3.1. Rule Set for the Researcher from HIPAA
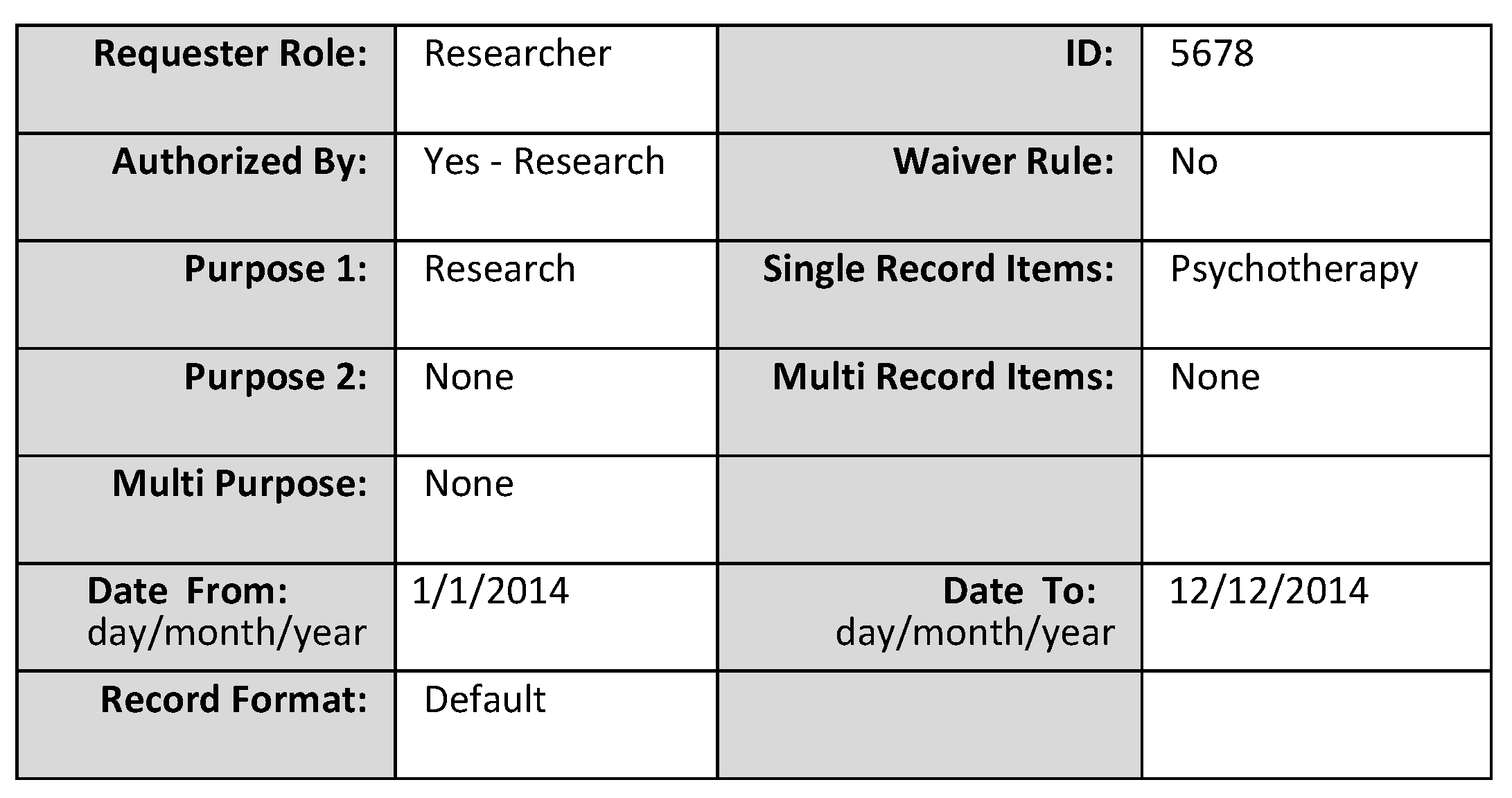
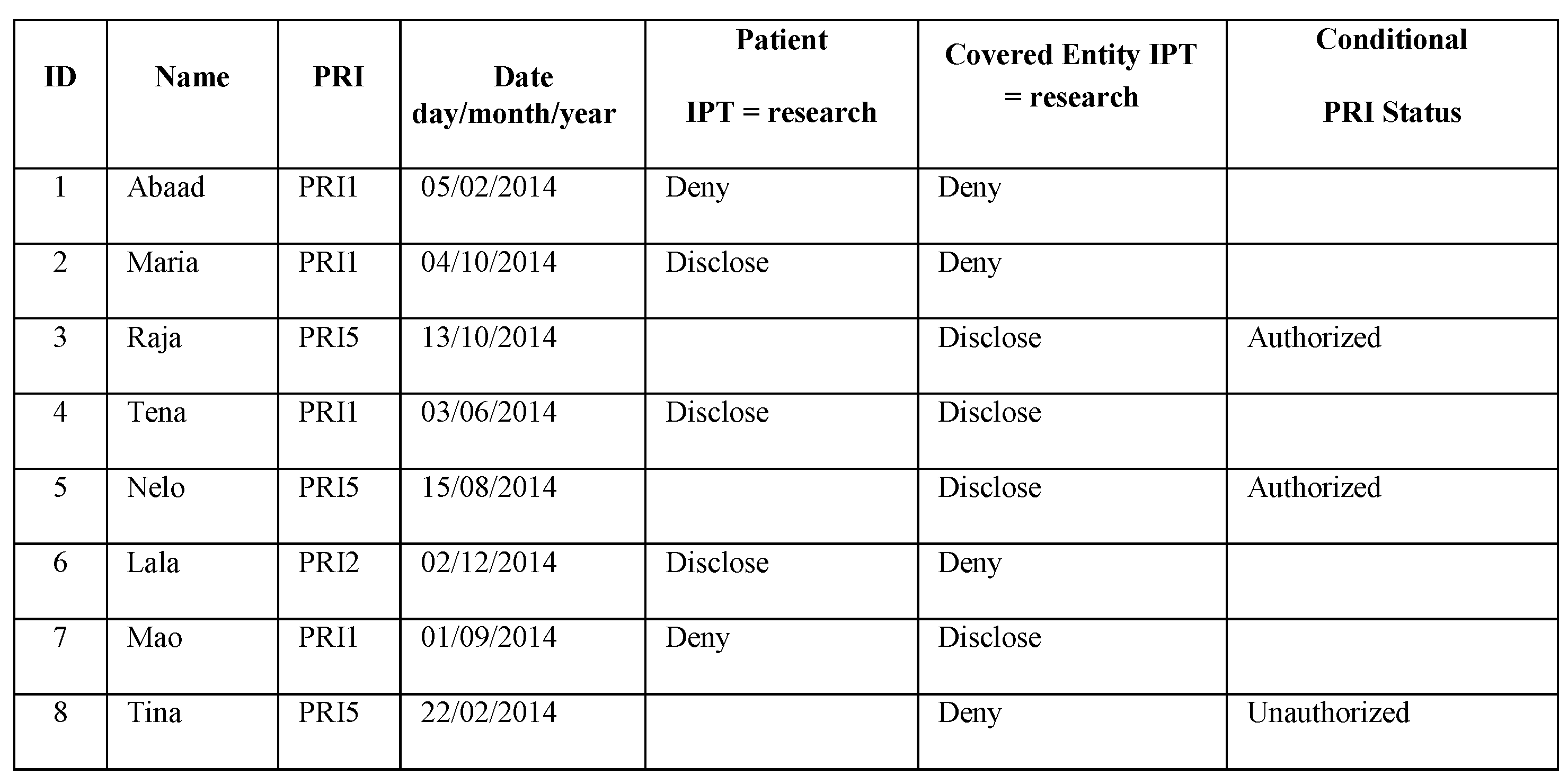
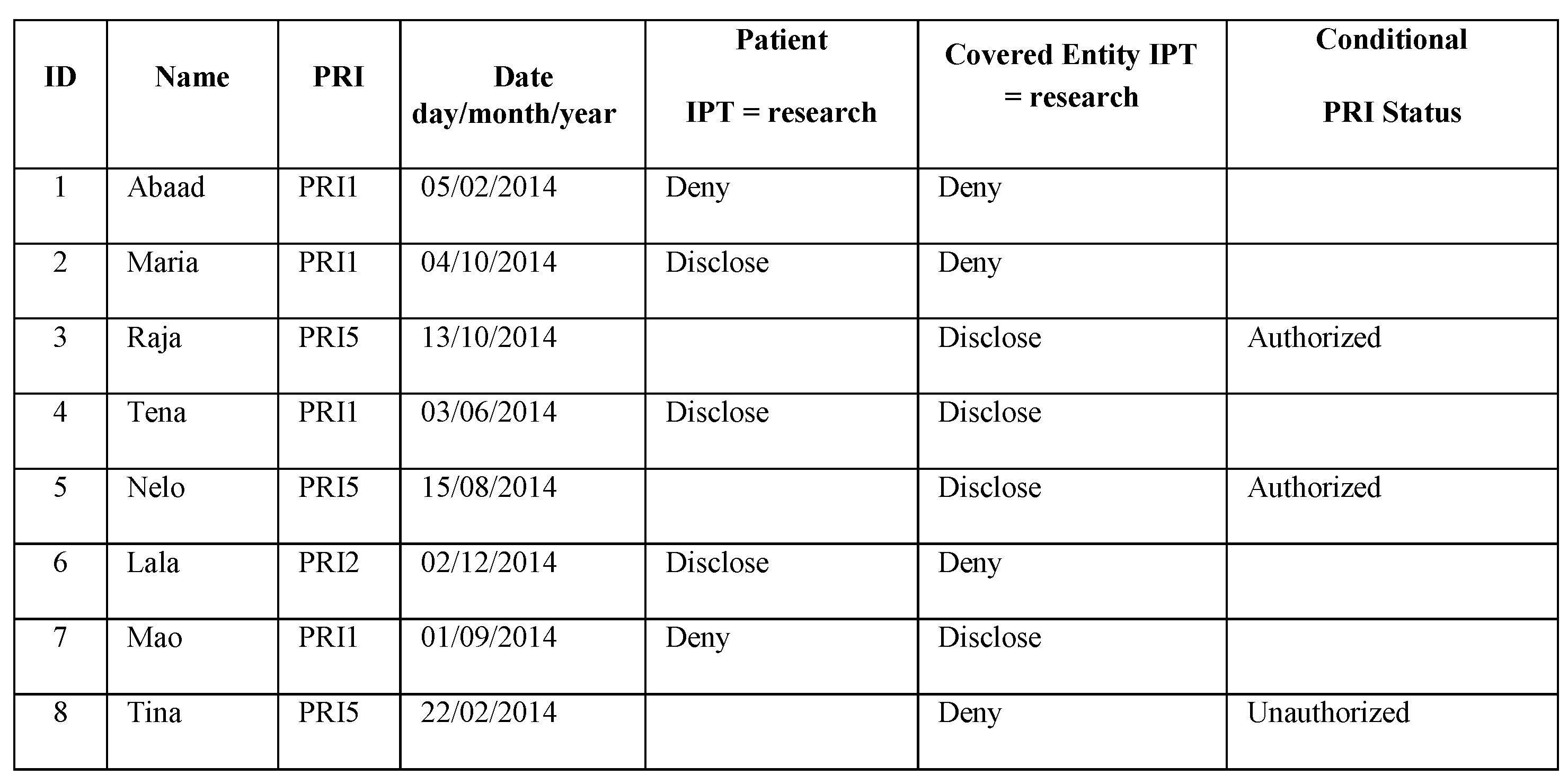
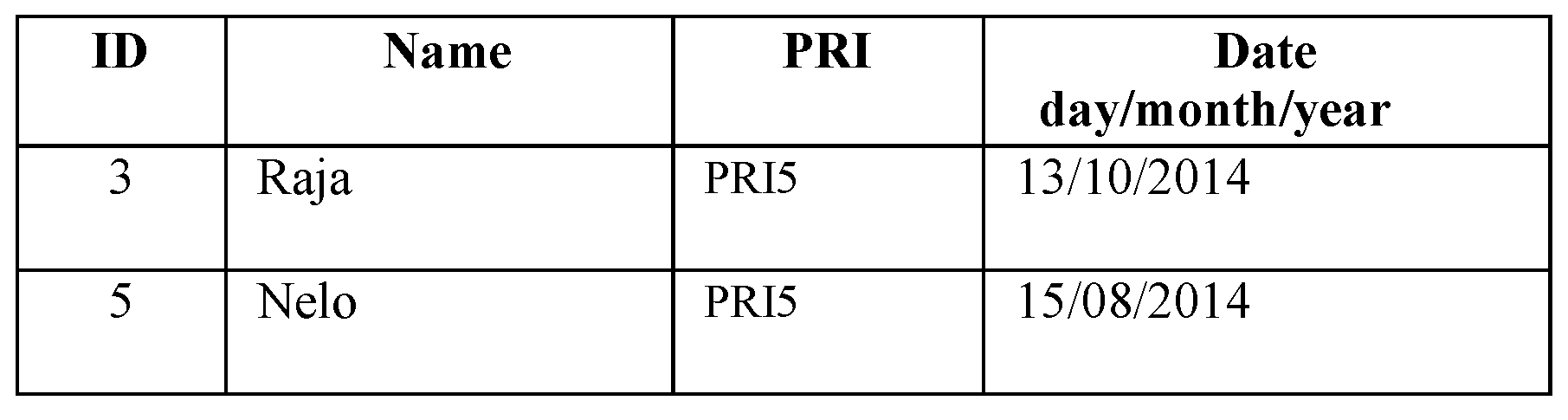
3.2. Query and Result
Researcher Example
4. Discussion
5. Conclusions
6. Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- O’Neill, A. An action framework for compliance and governance. Clin. Gov. Int. J. 2014, 19, 342–359. [Google Scholar] [CrossRef]
- Breaux, T.D.; Anton, A.I. Analyzing regulatory rules for privacy and security requirements. IEEE Trans. Softw. Eng. 2008, 34, 5–20. [Google Scholar] [CrossRef]
- Breaux, T.D. Legal Requirements Acquisition for the Specification of Legally Compliant Information Systems. Ph.D. Thesis, North Carolina State University, Raleigh, NC, USA, 2009. [Google Scholar]
- Maxwell, J.C.; Anton, A.I.; Swire, P.; Riaz, M.; McCraw, C.M. A legal cross-references taxonomy for reasoning about compliance requirements. Requir. Eng. 2012, 17, 99–115. [Google Scholar] [CrossRef]
- Otto, P.N.; Antón, A.I. Addressing legal requirements in requirements engineering. In Proceedings of the 15th IEEE International Conference on Requirements Engineering, RE ’07, Delhi, India, 15–19 October 2007; pp. 5–14.
- Massey, A.K.; Otto, P.N.; Hayward, L.J.; Antón, A.I. Evaluating existing security and privacy requirements for legal compliance. Requir. Eng. 2010, 15, 119–137. [Google Scholar] [CrossRef]
- Maxwell, J.C.; Antón, A.I. The production rule framework: Developing a canonical set of software requirements for compliance with law. In Proceedings of the 1st ACM International Health Informatics Symposium, Arlington, VA, USA, 11–12 November 2010; pp. 629–636.
- Alshugran, T.; Dichter, J.; Rusu, A. Extending XACML to express and enforce laws and regulations privacy policies. In Proceedings of the 2015 IEEE Long Island Systems, Applications and Technology Conference (LISAT), Farmingdale, NY, USA, 1 May 2015; pp. 1–5.
- Hodge, J.G. Health information privacy and public health. J. Law Med. Ethics 2003, 31, 663–671. [Google Scholar] [CrossRef] [PubMed]
- Medical Privacy, U.S. Department of Health and Human Services. National Standards to Protect the Privacy of Personal Health Information; Office for Civil Rights: Washington, DC, USA, 2000. Available online: http://www.hhs.gov/ocr/hipaa/finalreg.html (accessed on 12 August 2014).
- HIPAA Administrative. 45 CFR, Parts 160, 162 and 164; Department of Health and Human Services, Office for Civil Rights: Washington, DC, USA, 2009. Available online: http://www.hhs.gov (accessed on 13 August 2014).
- Breaux, T.D.; Vail, M.W.; Anton, A.I. Towards regulatory compliance: Extracting rights and obligations to align requirements with regulations. In Proceedings of the 14th IEEE International Conference Requirements Engineering, Minneapolis/St. Paul, MN, USA, 11–15 September 2006; pp. 49–58.
- Wilson, J.F. Health Insurance Portability and Accountability Act Privacy rule causes ongoing concerns among clinicians and researchers. Ann. Intern. Med. 2006, 145, 313–316. [Google Scholar] [CrossRef] [PubMed]
- Sherman, D.M. A Prolog model of the income tax act of Canada. In Proceedings of the 1st International Conference on Artificial Intelligence and Law, New York, NY, USA, 1 December 1987; pp. 127–136.
- Borrelli, M.A. Prolog and the Law: Using Expert Systems to Perform Legal Analysis in the UK. Softw. Law J. 1989, 3, 687–715. [Google Scholar]
- Lam, P.E.; Mitchell, J.C.; Sundaram, S. A Formalization of HIPAA for a Medical Messaging System; Springer: Berlin, Heidelberg, Germany, 2009. [Google Scholar]
- Maxwell, J.C.; Anton, A.I. Developing production rule models to aid in acquiring requirements from legal texts. In Proceedings of the 17th IEEE International Requirements Engineering Conference, RE ’09, Atlanta, GA, USA, 31 August–4 September 2009; pp. 101–110.
- Maxwell, J.C.; Anton, A.I. A Refined Production Rule Model for Aiding in Regulatory Compliance; North Carolina State University: Raleigh, NC, USA, 2010. [Google Scholar]
- DeYoung, H.; Garg, D.; Jia, L.; Kaynar, D.; Datta, A. Experiences in the logical specification of the HIPAA and GLBA privacy laws. In Proceedings of the 9th Annual ACM Workshop on Privacy in the Electronic Society, Chicago, IL, USA, 4–8 October 2010; pp. 73–82.
- Garg, D.; DeYoung, H.; Kaynar, D.; Datta, A. Logical Specification of the GLBA and HIPAA Privacy Laws; Carnegie-Mellon University: Pittsburgh, PA, USA, 2010. [Google Scholar]
- Li, J.S.; Zhou, T.S.; Chu, J.; Araki, K.; Yoshihara, H. Design and development of an international clinical data exchange system: The international layer function of the Dolphin Project. J. Am. Med. Inform. Assoc. 2011, 18, 683–689. [Google Scholar] [CrossRef] [PubMed]
- Takemura, T.; Araki, K.; Arita, K.; Suzuki, T.; Okamoto, K.; Kume, N.; Kuroda, T.; Takada, A.; Yoshihara, H. Development of fundamental infrastructure for nationwide EHR in Japan. J. Med. Syst. 2012, 36, 2213–2218. [Google Scholar] [CrossRef] [PubMed]
- Tello-Leal, E.; Chiotti, O.; Villarreal, P.D. Process-oriented integration and coordination of healthcare services across organizational boundaries. J. Med. Syst. 2012, 36, 3713–3724. [Google Scholar] [CrossRef] [PubMed]
- Khan, I.; Alwarsh, M.; Khan, J.I. A comprehension approach for formalizing privacy rules of HIPAA for decision support. In Proceedings of the 12th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 4–7 December 2013; Volume 2, pp. 390–395.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Considered Items in the Study | A | B | C | D | |
|---|---|---|---|---|---|
| 1 | Clauses are linked within the same section | Y | Y | Y | Y |
| 2 | Direct cross-references are considered | Y | Y | Y | Y |
| 3 | Indicates applied rule as a result of a query | Y | Y | Y | Y |
| 4 | Provides the type of action taken as a result of a query | Y | N | Y | Y |
| 5 | What information will be released is considered | Y | N | Y | Y |
| 6 | Study covers all of the privacy sections of HIPAA | Y | N | N | Y |
| 7 | How information will be released is considered | Y | N | N | N |
| 8 | Medical relational model for HIPAA | Y | N | N | N |
| 9 | Unreferenced information between sections is covered | Y | N | N | N |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, I.; Sher, M.; Khan, J.I.; Saqlain, S.M.; Ghani, A.; Naqvi, H.A.; Ashraf, M.U. Conversion of Legal Text to a Logical Rules Set from Medical Law Using the Medical Relational Model and the World Rule Model for a Medical Decision Support System. Informatics 2016, 3, 2. https://doi.org/10.3390/informatics3010002
Khan I, Sher M, Khan JI, Saqlain SM, Ghani A, Naqvi HA, Ashraf MU. Conversion of Legal Text to a Logical Rules Set from Medical Law Using the Medical Relational Model and the World Rule Model for a Medical Decision Support System. Informatics. 2016; 3(1):2. https://doi.org/10.3390/informatics3010002
Chicago/Turabian StyleKhan, Imran, Muhammad Sher, Javed I. Khan, Syed M. Saqlain, Anwar Ghani, Husnain A. Naqvi, and Muhammad Usman Ashraf. 2016. "Conversion of Legal Text to a Logical Rules Set from Medical Law Using the Medical Relational Model and the World Rule Model for a Medical Decision Support System" Informatics 3, no. 1: 2. https://doi.org/10.3390/informatics3010002
APA StyleKhan, I., Sher, M., Khan, J. I., Saqlain, S. M., Ghani, A., Naqvi, H. A., & Ashraf, M. U. (2016). Conversion of Legal Text to a Logical Rules Set from Medical Law Using the Medical Relational Model and the World Rule Model for a Medical Decision Support System. Informatics, 3(1), 2. https://doi.org/10.3390/informatics3010002