
Multi-Model Dialectical Evaluation of LLM Reasoning Chains: A Structured Framework with Dual Scoring Agents

 ,
,  , , , and
, , , and
Abstract
1. Introduction
1.1. Background and Objectives of the Study
1.2. Research Gap and Novelty
- i.
- Introducing a modular, dialectically structured pipeline for multi-model reasoning;
- ii.
- Combining rubric-based scoring with rule-based semantic analysis of ethical values and argumentative flaws;
- iii.
- Supporting flexible model assignment and comparative evaluation of reasoning roles;
- iv.
- Storing all outputs in a graph database for persistent and structured inspection;
- v.
- Demonstrating the framework using open-weight models (Gemma 7B, Mistral 7B, Dolphin-Mistral, Zephyr 7B) and independent evaluators (LLaMA 3.1, GPT-4o).
1.3. Related Work
2. Materials and Methods
2.1. Conceptual Design
- stating a position,
- confronting it with counterarguments, and
- synthesizing a coherent conclusion.
2.2. Reasoning Pipeline
2.3. Prompt Engineering
2.4. Models and Configuration
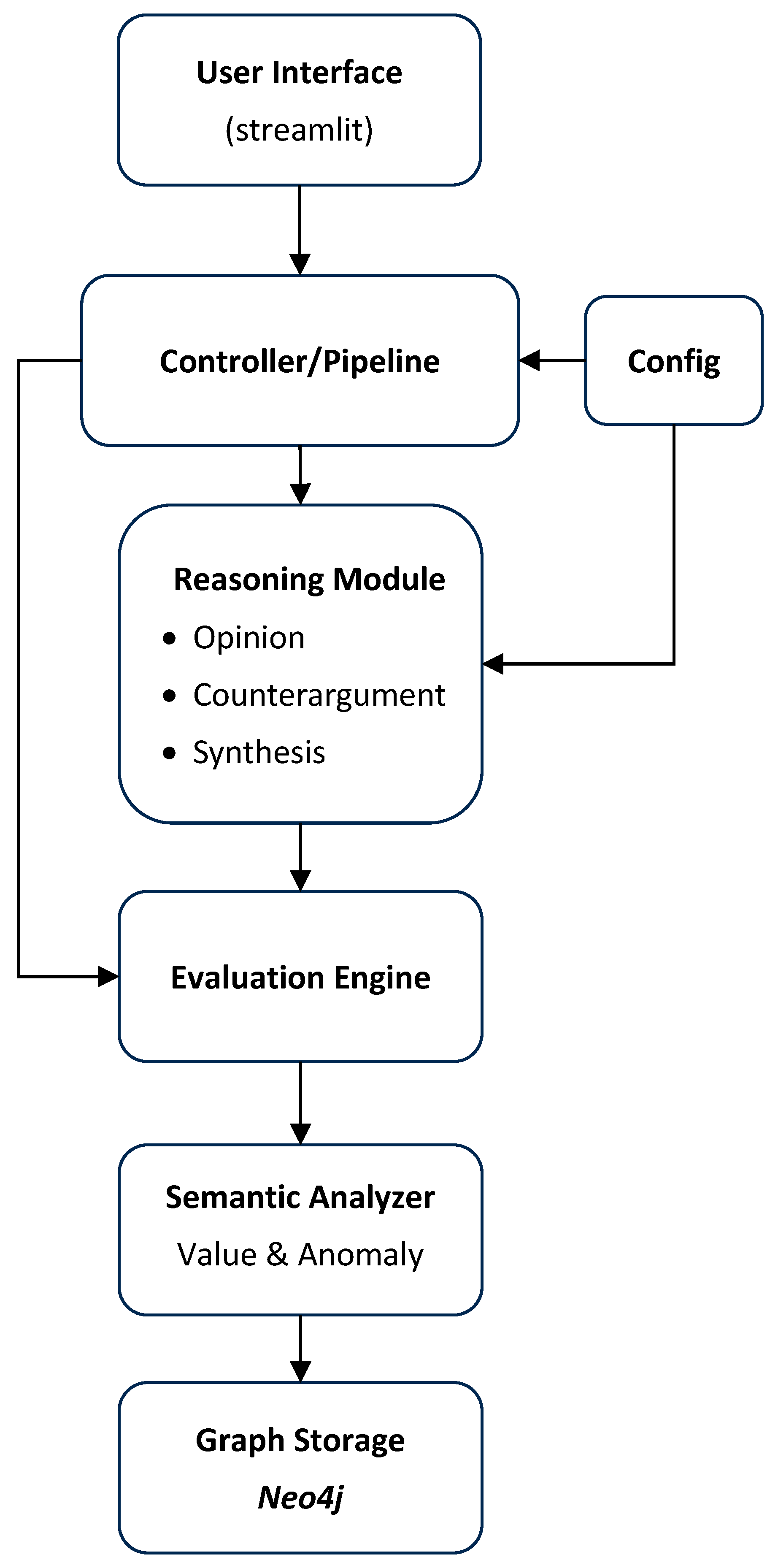
2.5. System Architecture
- MATCH (s:Synthesis)-[:EXPRESSES] → (v:Value)
- WHERE toLower(v.name) = “empathy”
- RETURN s.text, v.name
2.6. Prompt Set
- Is democracy still the best form of government in the age of digital manipulation?
- Can artificial intelligence make moral decisions?
- Should freedom of speech include the right to spread misinformation?
- Is universal basic income a viable solution to job automation?
- Can privacy be protected in a data-driven world?
- Is geoengineering a morally acceptable solution to climate change?
- Should developing countries prioritize economic growth over environmental sustainability?
- Can large language models be truly creative?
- Is social media a threat to democratic discourse?
- Should human enhancement through biotechnology be regulated or encouraged?
2.7. Evaluation Criteria
3. Results
3.1. Model Performance
- i.
- Clarity: fluency, readability, syntactic precision;
- ii.
- Coherence: logical structure, argumentative progression;
- iii.
- Originality: novelty, avoidance of generic phrasing;
- iv.
- Dialecticality: ability to integrate opposing perspectives into a unified conclusion.
3.2. Semantic Evaluation
3.3. Comparative Insights
4. Discussion
4.1. Interpreting Model Differences
4.2. Implications for LLM Evaluation
4.3. Study Limitations
4.4. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Example Prompt and Reasoning Chain
References
- Kishore, P.; Salim, R.; Todd, W.; Zhu, W.-J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th ACL, Philadelphia, PA, USA, 6–12 July 2002; Available online: https://www.aclweb.org/anthology/P02-1040 (accessed on 25 May 2025).
- Lin, C.-Y. ROUGE: A Package for Automatic Evaluation of Summaries; Text Summarization Branches Out; ACL: Stroudsburg, PA, USA, 2004; Available online: https://www.aclweb.org/anthology/W04-1013 (accessed on 25 May 2025).
- Pranav, R.; Zhang, J.; Konstantin, L.; Percy, L. SQuAD: 100,000+ Questions for Machine Comprehension of Text; EMNLP: Austin, TX, USA, 2016; Available online: https://arxiv.org/abs/1606.05250 (accessed on 25 May 2025).
- Jason, W.; Wang, X.; Schuurmans, D.; Bosma, M.; Chi, E.; Le, Q.V.; Zhou, D. Chain of Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2022, arXiv:2201.11903. Available online: https://arxiv.org/abs/2201.11903 (accessed on 25 May 2025).
- Madaan, A.; Tandon, N.; Gupta, P.; Hallinan, S.; Gao, L.; Wiegreffe, S.; Alon, U.; Dziri, N.; Prabhumoye, S.; Yang, Y.; et al. Self-Refine: Iterative Refinement with Self-Feedback. arXiv 2023, arXiv:2303.17651. Available online: https://arxiv.org/abs/2303.17651 (accessed on 25 May 2025). [CrossRef]
- Shinn, N.; Cassano, F.; Berman, E.; Gopinath, A.; Narasimhan, K.; Yao, S. Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv 2023, arXiv:2303.11366. Available online: https://arxiv.org/abs/2303.11366 (accessed on 25 May 2025). [CrossRef]
- Park, J.S.; Joseph, O.B.; Cai, C.J.; Morris, M.R.; Liang, P.; Bernstein, M.S. Generative Agents: Interactive Simulacra of Human Behavior. arXiv 2023, arXiv:2304.03442. Available online: https://arxiv.org/abs/2304.03442 (accessed on 25 May 2025). [CrossRef]
- Du, Y.; Li, S.; Torralba, A.; Tenenbaum, J.B.; Mordatch, I. Improving Factuality and Reasoning in Language Models through Multiagent Debate. arXiv 2023, arXiv:2305.14325. Available online: https://arxiv.org/abs/2305.14325 (accessed on 25 May 2025). [CrossRef]
- Yao, S.; Yu, D.; Zhao, J.; Shafran, I.; Griffiths, T.L.; Cao, Y.; Narasimhan, K. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv 2023, arXiv:2305.10601. Available online: https://arxiv.org/abs/2305.10601 (accessed on 25 May 2025). [CrossRef]
- Li, Y.; Yang, C.; Ettinger, A. When Hindsight is Not 20/20: Testing Limits on Reflective Thinking in Large Language Models. arXiv 2024, arXiv:2404.09129. Available online: https://arxiv.org/abs/2404.09129 (accessed on 25 May 2025). [CrossRef]
- Ioan, S.; Pecheanu, E.; Cocu, A.; Istrate, A.; Anghel, C.; Iacobescu, P. Non-Intrusive Monitoring and Detection of Mobility Loss in Older Adults Using Binary Sensors. Sensors 2025, 25, 2755. [Google Scholar] [CrossRef]
- Zhu, K.; Zhao, Q.; Chen, H.; Wang, J.; Xie, X. PromptBench: A Unified Library for Evaluation of Large Language Models. arXiv 2023, arXiv:2312.07910. Available online: https://arxiv.org/abs/2312.07910 (accessed on 25 May 2025).
- Bhat, V. RubricEval: A Scalable Human-LLM Evaluation Framework for Open-Ended Tasks; Stanford CS224N Final Report; Stanford University: Stanford, CA, USA, 2023; Available online: https://web.stanford.edu/class/cs224n/final-reports/256846781.pdf (accessed on 25 May 2025).
- Hashemi, H.; Eisner, J.; Rosset, C.; Van Durme, B.; Kedzie, C. LLM-Rubric: A Multidimensional, Calibrated Approach to Automated Evaluation of Natural Language Texts. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), Bangkok, Thailand, 11–16 August 2024; pp. 13806–13834. Available online: https://aclanthology.org/2024.acl-long.745 (accessed on 25 May 2025).
- Schwartz, S.H. An Overview of the Schwartz Theory of Basic Values. Online Read. Psychol. Cult. 2012, 2, 11. [Google Scholar] [CrossRef]
- Zheng, C.; Liu, Z.; Xie, E.; Li, Z.; Li, Y. Progressive-Hint Prompting Improves Reasoning in Large Language Models. arXiv 2023, arXiv:2304.09797. Available online: https://arxiv.org/abs/2304.09797 (accessed on 25 May 2025). [CrossRef]
- Webb, T.; Mondal, S.S.; Momennejad, I. Improving Planning with Large Language Models: A Modular Agentic Architecture. arXiv 2023, arXiv:2310.00194. Available online: https://arxiv.org/abs/2310.00194 (accessed on 25 May 2025).
- Gu, Y.; Tafjord, O.; Kuehl, B.; Haddad, D.; Dodge, J.; Hajishirzi, H. OLMES: A Standard for Language Model Evaluations. arXiv 2024, arXiv:2406.08446. Available online: https://arxiv.org/abs/2406.08446 (accessed on 25 May 2025). [CrossRef]
- Structured Outputs: Making LLMs Reliable for Document Processing. Generative AI Newsroom. 2024. Available online: https://generative-ai-newsroom.com/structured-outputs-making-llms-reliable-for-document-processing-c3b6b2baed36 (accessed on 25 May 2025).
- Kuchnik, M.; Smith, V.; Amvrosiadis, G. Validating Large Language Models with ReLM. arXiv 2022, arXiv:2211.15458. Available online: https://arxiv.org/abs/2211.15458 (accessed on 25 May 2025).
- Scherrer, N.; Shi, C.; Feder, A.; Blei, D. Evaluating the Moral Beliefs Encoded in LLMs. In Proceedings of the NeurIPS 2023, New Orleans, Louisiana, 10–16 December 2023; Available online: https://openreview.net/forum?id=O06z2G18me (accessed on 25 May 2025).
- Sidana, N. Running Models with Ollama Step-by-Step. Medium. 2024. Available online: https://medium.com/@nsidana123/running-models-with-ollama-step-by-step-b3bdbfd91e8e (accessed on 25 May 2025).
- Prompt Engineering Guide. Gemma 7B. 2025. Available online: https://www.promptingguide.ai/models/gemma (accessed on 25 May 2025).
- Google AI for Developers. Gemma Formatting and System Instructions. 2024. Available online: https://ai.google.dev/gemma/docs/formatting (accessed on 25 May 2025).
- Hugging Face. Cognitivecomputations/Dolphin-2.8-Mistral-7b-v02. 2024. Available online: https://huggingface.co/cognitivecomputations/dolphin-2.8-mistral-7b-v02 (accessed on 25 May 2025).
- Hugging Face. HuggingFaceH4/zephyr-7b-beta. 2024. Available online: https://huggingface.co/HuggingFaceH4/zephyr-7b-beta (accessed on 25 May 2025).
- Meta AI. Introducing Llama 3.1: Our Most Capable Models to Date. 2024. Available online: https://ai.meta.com/blog/meta-llama-3-1/ (accessed on 25 May 2025).
- Asprino, L.; De Giorgis, S.; Gangemi, A.; Bulla, L.; Marinucci, L.; Mongiovì, M. Uncovering Values: Detecting Latent Moral Content from Natural Language with Explainable and Non-Trained Methods. In Proceedings of the Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, Dublin, Ireland, 27 May 2022; pp. 33–41. Available online: https://aclanthology.org/2022.deelio-1.4.pdf (accessed on 25 May 2025).
- Chen, G.; Dong, S.; Shu, Y.; Zhang, G.; Sesay, J.; Karlsson, B.F.; Fu, J.; Shi, Y. AutoAgents: A Framework for Automatic Agent Generation. arXiv 2023, arXiv:2309.17288. Available online: https://arxiv.org/abs/2309.17288 (accessed on 25 May 2025).
- Liu, X.; Chen, J.; Li, C.; Song, X.; Wang, Y. CAMEL: Communicative Agents for Mind Exploration of Large-Scale Language Model Society. arXiv 2023, arXiv:2303.17760. Available online: https://arxiv.org/abs/2303.17760 (accessed on 25 May 2025).
- Ni, H. Extracting Insights from Unstructured Data with LLMs & Neo4j. Medium, 15 January 2025. Available online: https://watchsound.medium.com/extracting-insights-from-unstructured-data-with-llms-neo4j-914b1f193c64 (accessed on 25 May 2025).
- Sahoo, P.; Singh, A.K.; Saha, S.; Jain, V.; Mondal, S.; Chadha, A. A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications. arXiv 2024, arXiv:2402.07927. Available online: https://arxiv.org/abs/2402.07927 (accessed on 25 May 2025). [CrossRef]
- Lum, K.; Anthis, J.R.; Robinson, K.; Nagpal, C.; Alexander, D.A. Bias in Language Models: Beyond Trick Tests and Toward RUTEd Evaluation. arXiv 2024, arXiv:2402.12649. Available online: https://arxiv.org/abs/2402.12649 (accessed on 25 May 2025). [CrossRef]
- Microsoft Learn. Evaluation and Monitoring Metrics for Generative AI. Available online: https://learn.microsoft.com/en-us/azure/ai-foundry/concepts/evaluation-metrics-built-in (accessed on 25 May 2025).
- Confident AI. G-Eval: The Definitive Guide. Available online: https://www.confident-ai.com/blog/g-eval-the-definitive-guide (accessed on 25 May 2025).
- Padmakumar, V.; Yueh-Han, C.; Pan, J.; Chen, V.; He, H. Beyond Memorization: Mapping the Originality-Quality Frontier of Language Models. arXiv 2025, arXiv:2504.09389. Available online: https://arxiv.org/abs/2504.09389 (accessed on 25 May 2025). [CrossRef]
- Cohn, A.G.; Hernandez-Orallo, J. Dialectical language model evaluation: An initial appraisal of the commonsense spatial reasoning abilities of LLMs. arXiv 2023, arXiv:2304.11164. Available online: https://arxiv.org/abs/2304.11164 (accessed on 25 May 2025). [CrossRef]
- Pathak, A.; Gandhi, R.; Uttam, V.; Devansh; Nakka, Y.; Jindal, A.R.; Ghosh, P.; Ramamoorthy, A.; Verma, S.; Mittal, A.; et al. Rubric Is All You Need: Enhancing LLM-based Code Evaluation With Question-Specific Rubrics. arXiv 2025, arXiv:2503.23989. Available online: https://arxiv.org/abs/2503.23989 (accessed on 25 May 2025).
- Rebmann, A.; Schmidt, F.D.; Glavaš, G.; van der Aa, H. On the Potential of Large Language Models to Solve Semantics-Aware Process Mining Tasks. arXiv 2025, arXiv:2504.21074. Available online: https://arxiv.org/abs/2504.21074 (accessed on 25 May 2025). [CrossRef]
- Huang, X.; Ruan, W.; Huang, W.; Jin, G.; Dong, Y. A Survey of Safety and Trustworthiness of Large Language Models Through the Lens of Verification and Validation. Artif. Intell. Rev. 2024, 57, 175. [Google Scholar] [CrossRef]
- Alva-Manchego, F.; Scarton, C.; Specia, L. The (Un) Suitability of Automatic Evaluation Metrics for Text Simplification. Comput. Linguist. 2021, 47, 861–889. Available online: https://aclanthology.org/2021.cl-4.28/ (accessed on 25 May 2025). [CrossRef]
- Iacobescu, P.; Marina, V.; Anghel, C.; Anghele, A.-D. Evaluating Binary Classifiers for Cardiovascular Disease Prediction: Enhancing Early Diagnostic Capabilities. J. Cardiovasc. Dev. Dis. 2024, 11, 396. [Google Scholar] [CrossRef]
- Anghele, A.-D.; Marina, V.; Dragomir, L.; Moscu, C.A.; Anghele, M.; Anghel, C. Predicting Deep Venous Thrombosis Using Artificial Intelligence: A Clinical Data Approach. Bioengineering 2024, 11, 1067. [Google Scholar] [CrossRef]
- Reddy, P. A Framework of Rhetorical Moves Designed to Scaffold the Development of Research Proposals. Int. J. Dr. Stud. 2023, 18, 77–97. Available online: https://ijds.org/Volume18/IJDSv18p077-097Reddy8855.pdf (accessed on 25 May 2025). [CrossRef]
- Vengal, T. LLMs: A Review of Their Capabilities, Limitations and Evaluation. LinkedIn. 2023. Available online: https://www.linkedin.com/pulse/llms-review-capabilities-limitations-evaluation-thomas-vengal (accessed on 25 May 2025).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Model Role | Input Components | Expected Output | Prompt Characteristics |
|---|---|---|---|---|
| Opinion | Initial Opinion Generator | User Question | Reasoned answer with a clear stance | Direct question → Encourage 2–3 justifications |
| Counterargument | Counterargument Generator | User Question + Opinion | Logical critique or objection | Structured to challenge reasoning, not emotion |
| Synthesis | Synthesis Generator | Question + Opinion + Counterargument | Integrated and balanced conclusion | Instruction to reconcile both views fairly |
| Evaluation | Evaluator | Full chain (Q + Opinion + Counter + Synthesis) | Structured JSON scores for clarity, coherence, originality, and dialecticality | Includes rubric, formatting constraints, and scoring examples |
| Semantic Analysis | Value and Anomaly Detector | Final Synthesis | List of expressed values and detected anomalies | Pattern matching over ethical keywords and rhetorical cues |
| Model Name | Architecture | Size | Training Source | Role in Pipeline | Strengths/Limitations |
|---|---|---|---|---|---|
| Gemma 7B | Decoder only | 7B | Google DeepMind | Full generation pipeline | Structured reasoning; concise but less nuanced. |
| Mistral 7B | Decoder only | 7B | Mistral AI | Full generation pipeline | Fast and coherent; can sound generic. |
| Dolphin-Mistral | Mistral finetuned | 7B | Eric Hartford/HF | Full generation pipeline | Assertive and fluent; less formal tone. |
| Zephyr 7B-beta | Decoder only | 7B | HuggingFace/HuggingChat | Full generation pipeline | Dialogue-tuned; context-aware but occasionally verbose. |
| LLaMA 3.1 (eval) | Decoder only | ~8B | Meta AI | Evaluator | Precise scoring; may inflate clarity. |
| ChatGPT 4o (eval) | Multimodal Transformer | N/A | OpenAI | Evaluator | Fluent and balanced; slightly lenient on originality. |
| Semantic Analyzer | Rule-based module | N/A | Custom (in-house) | Post-synthesis analysis | Deterministic, fast; limited to predefined patterns. |
| Dimension | Score 3 (Low) | Score 6 (Medium) | Score 9 (High) |
|---|---|---|---|
| Clarity | Response is vague, confusing, or poorly structured. | Response is understandable but includes unclear or awkward parts. | Response is precise, well-articulated, and easy to follow. |
| Coherence | Ideas are disjointed with weak logical progression. | Some logical flow, but transitions or links between ideas are inconsistent. | Strong logical structure, with well-connected and logically sound reasoning. |
| Originality | Response is generic or highly repetitive. | Some novel elements or moderate insight. | Highly original with creative and insightful reasoning. |
| Dialecticality | Synthesis ignores or restates initial arguments with no integration. | Some engagement with counterpoints, but the synthesis lacks depth. | Successfully integrates opposing views into a unified, thoughtful synthesis. |
| Model | Clarity (LLaMA) | Clarity (GPT-4o) | Coherence (LLaMA) | Coherence (GPT-4o) | Originality (LLaMA) | Originality (GPT-4o) | Dialecticality (LLaMA) | Dialecticality (GPT-4o) |
|---|---|---|---|---|---|---|---|---|
| Dolphin-Mistral | 8.0 | 8.0 | 8.8 | 7.1 | 5.4 | 6.1 | 8.0 | 7.1 |
| Gemma 7B | 8.0 | 9.0 | 9.0 | 9.0 | 6.0 | 8.0 | 8.1 | 9.0 |
| Mistral 7B | 8.2 | 8.0 | 8.8 | 8.0 | 6.0 | 7.0 | 8.4 | 8.0 |
| Zephyr 7B | 8.4 | 8.2 | 8.9 | 8.2 | 5.7 | 5.8 | 8.0 | 7.6 |
| Evaluation Dimension | Pearson Correlation (r) |
|---|---|
| Clarity | 0.165 |
| Coherence | 0.332 |
| Originality | 0.450 |
| Dialecticality | 0.081 |
| Mean | 0.257 |
| Model | Avg. Values | Avg. Anomalies |
|---|---|---|
| Dolphin-Mistral | 1.3 | 0.4 |
| Gemma 7B | 1.9 | 0.6 |
| Mistral 7B | 2.5 | 0.4 |
| Zephyr 7B | 1.9 | 0.5 |
| Dimension | Dolphin-Mistral | Gemma 7B | Mistral 7B | Zephyr 7B |
|---|---|---|---|---|
| Clarity | Moderate | High | High | High |
| Coherence | Moderate | High | High | High |
| Originality | Low | Moderate | Moderate–High | Low |
| Dialecticality | Moderate | Moderate | High | Moderate |
| Value Expression | Low (1.3) | Moderate (1.9) | High (2.5) | Moderate (1.9) |
| Rhetorical Anomalies | Low (0.4) | High (0.6) | Low (0.4) | Moderate (0.5) |
| Style Summary | Directive | Assertive | Integrative | Neutral |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anghel, C.; Anghel, A.A.; Pecheanu, E.; Susnea, I.; Cocu, A.; Istrate, A. Multi-Model Dialectical Evaluation of LLM Reasoning Chains: A Structured Framework with Dual Scoring Agents. Informatics 2025, 12, 76. https://doi.org/10.3390/informatics12030076
Anghel C, Anghel AA, Pecheanu E, Susnea I, Cocu A, Istrate A. Multi-Model Dialectical Evaluation of LLM Reasoning Chains: A Structured Framework with Dual Scoring Agents. Informatics. 2025; 12(3):76. https://doi.org/10.3390/informatics12030076
Chicago/Turabian StyleAnghel, Catalin, Andreea Alexandra Anghel, Emilia Pecheanu, Ioan Susnea, Adina Cocu, and Adrian Istrate. 2025. "Multi-Model Dialectical Evaluation of LLM Reasoning Chains: A Structured Framework with Dual Scoring Agents" Informatics 12, no. 3: 76. https://doi.org/10.3390/informatics12030076
APA StyleAnghel, C., Anghel, A. A., Pecheanu, E., Susnea, I., Cocu, A., & Istrate, A. (2025). Multi-Model Dialectical Evaluation of LLM Reasoning Chains: A Structured Framework with Dual Scoring Agents. Informatics, 12(3), 76. https://doi.org/10.3390/informatics12030076