
Strategy for Precopy Live Migration and VM Placement in Data Centers Based on Hybrid Machine Learning




Abstract
1. Introduction
- A hybrid machine learning model that integrates the method, MDP, RF, and NSGA-III is used to precisely forecast the VM migration time and enhance the placement strategies.
- The MDP, RF method, and NSGA-III are used to improve prediction and efficiency in executing the VM precopy migration process.
- LVM strategies are used in the proposed model to reduce migration failures and decrease the overall transfer duration and downtime.
2. Background and Literature Review
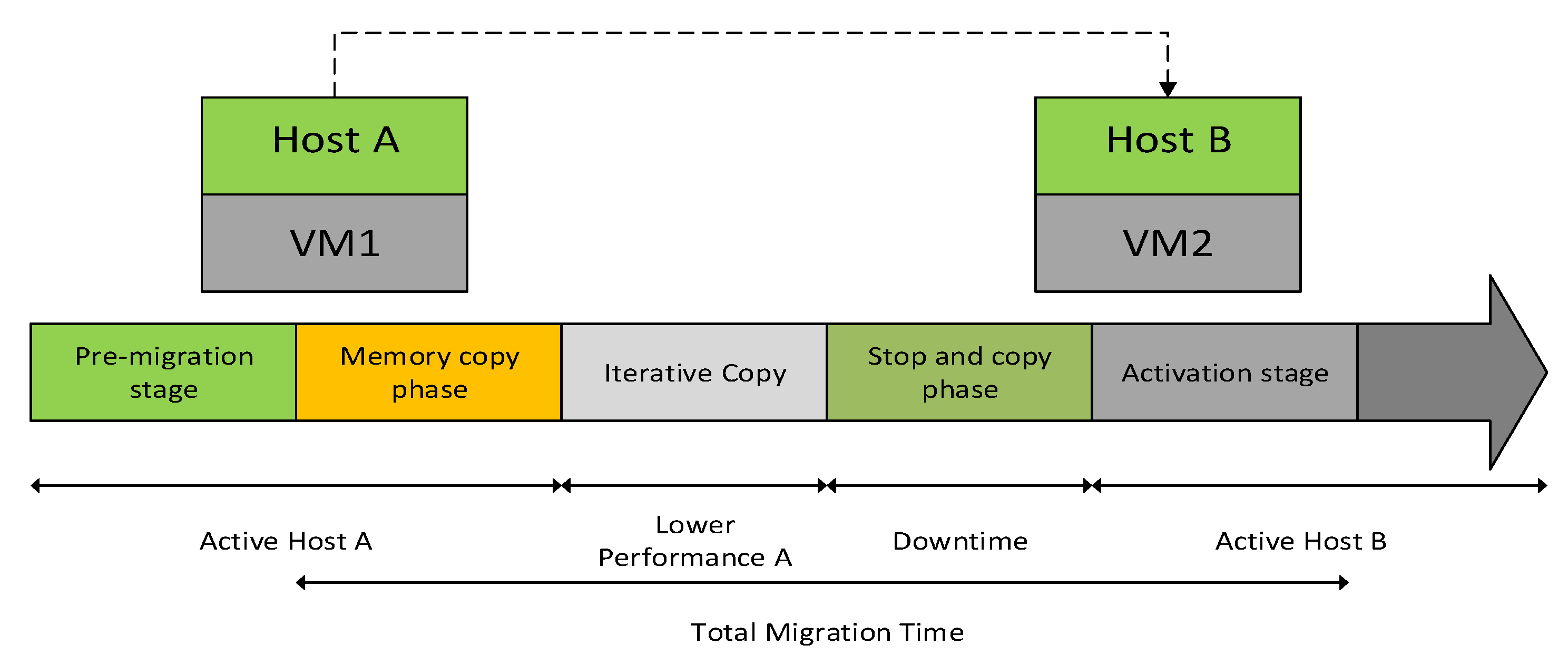
2.1. Live VM Migration Model
2.2. Previous Research on LVM and Machine Learning
3. Proposed Methodology
3.1. Hybrid Machine Learning Architecture for VM Placement Strategy
3.2. Dataset Description and Feature Engineering
3.3. Learning Modules and Optimization Strategy
3.4. Hybrid Machine Learning Evaluation Model
4. Results and Discussion
4.1. Results of Hybrid Machine Learning
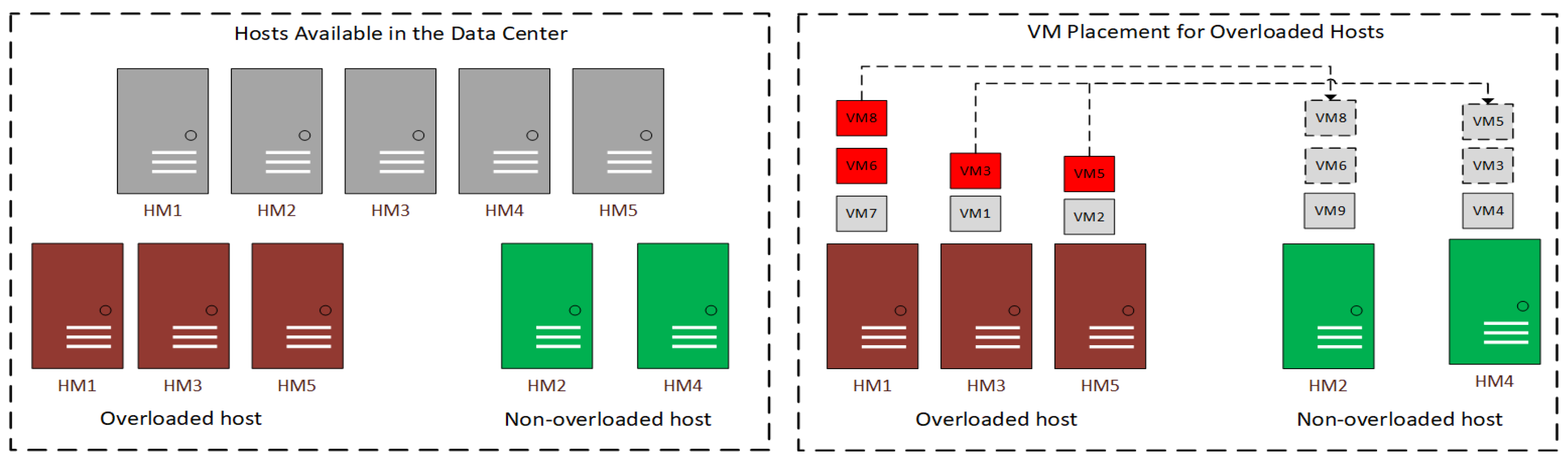
4.1.1. Migration Policy Analysis
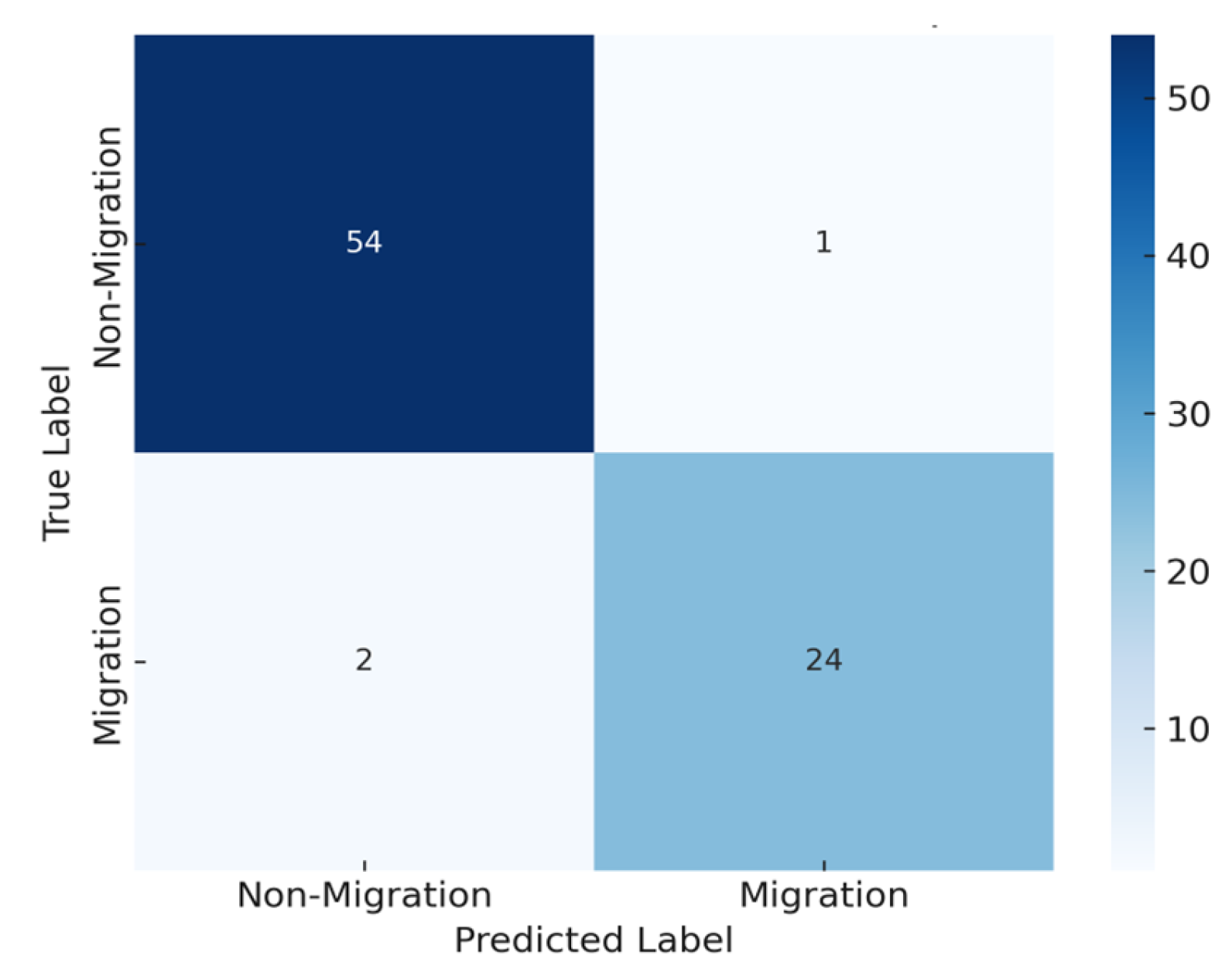
4.1.2. Migration Feasibility Prediction Results
4.1.3. NSGA-III Evolution Metric
4.2. Evaluation Model Prediction Error Analysis
SLA Compliance and Energy Efficiency of VM Migration
4.3. Comparison of Model Machine Learning VM Placement
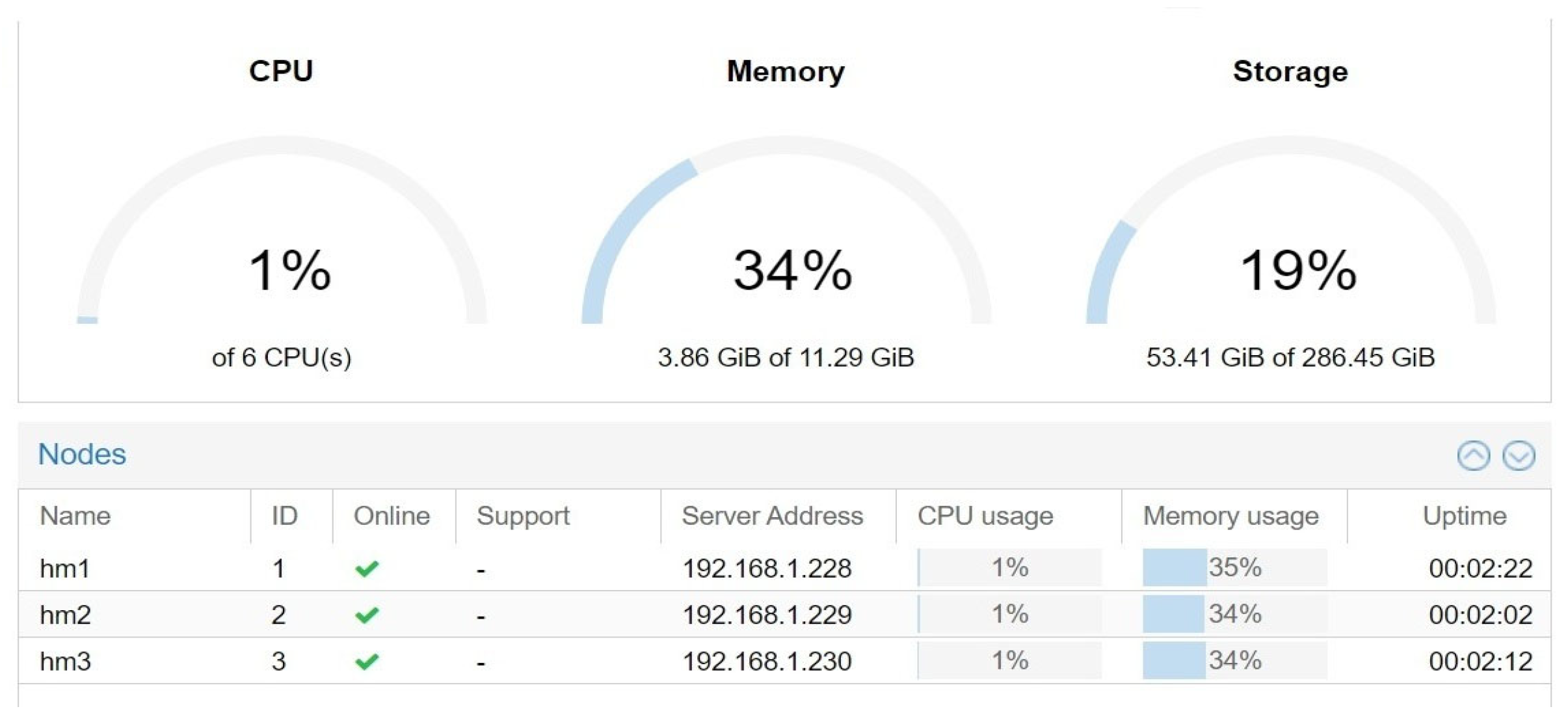
4.4. Experimental Setup
4.5. Results of the Implementation of Live Migration
4.6. Discussion of Hybrid Machine Learning VM Placement
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Haris, R.M.; Barhamgi, M.; Nhlabatsi, A.; Khan, K.M. Optimizing pre-copy live virtual machine migration in cloud computing using machine learning-based prediction model. Computing 2024, 106, 3031–3062. [Google Scholar] [CrossRef]
- Haris, R.M.; Khan, K.M.; Nhlabatsi, A.; Barhamgi, M. A machine learning-based optimization approach for pre-copy live virtual machine migration. Clust. Comput. 2024, 27, 1293–1312. [Google Scholar] [CrossRef]
- Motaki, S.E.; Yahyaouy, A.; Gualous, H. A prediction-based model for virtual machine live migration monitoring in a cloud datacenter. Computing 2021, 103, 2711–2735. [Google Scholar] [CrossRef]
- Mangalampalli, A.; Kumar, A. WBATimeNet: A deep neural network approach for VM Live Migration in the cloud. Future Gener. Comput. Syst. 2022, 135, 438–449. [Google Scholar] [CrossRef]
- Haris, R.M.; Khan, K.M.; Nhlabatsi, A. Live migration of virtual machine memory content in networked systems. Comput. Netw. 2022, 209, 108898. [Google Scholar] [CrossRef]
- Khodaverdian, Z.; Sadr, H.; Edalatpanah, S.A. A shallow deep neural network for selection of migration candidate virtual machines to reduce energy consumption. In Proceedings of the 2021 7th International Conference on Web Research (ICWR), Tehran, Iran, 19–20 May 2021; pp. 191–196. [Google Scholar]
- Sadr, H.; Salari, A.; Ashoobi, M.T.; Nazari, M. Cardiovascular disease diagnosis: A holistic approach using the integration of machine learning and deep learning models. Eur. J. Med. Res. 2024, 29, 455. [Google Scholar] [CrossRef]
- Zhao, H.; Feng, N.; Li, J.; Zhang, G.; Wang, J.; Wang, Q.; Wan, B. VM performance-aware virtual machine migration method based on ant colony optimization in cloud environment. J. Parallel Distrib. Comput. 2023, 176, 17–27. [Google Scholar] [CrossRef]
- Ishiguro, K.; Yasuno, N.; Aublin, P.L.; Kono, K. Revisiting VM-Agnostic KVM vCPU Scheduler for Mitigating Excessive vCPU Spinning. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 2615–2628. [Google Scholar] [CrossRef]
- Biswas, M.I.; Parr, G.P.; McClean, S.I.; Morrow, P.J.; Scotney, B.W. A Practical Evaluation in Openstack Live Migration of VMs Using 10Gb/s Interfaces. In Proceedings of the 2016 IEEE Symposium on Service-Oriented System Engineering (SOSE), Oxford, UK, 29 March–2 April 2016; pp. 346–351. [Google Scholar]
- Wei, P.; Zeng, Y.; Yan, B.; Zhou, J.; Nikougoftar, E. VMP-A3C: Virtual machines placement in cloud computing based on asynchronous advantage actor-critic algorithm. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 101549. [Google Scholar] [CrossRef]
- Annadanam, C.S.; Chapram, S.; Ramesh, T. Intermediate node selection for Scatter-Gather VM migration in cloud data center. Eng. Sci. Technol. Int. J. 2020, 23, 989–997. [Google Scholar] [CrossRef]
- Singh, S.; Singh, D. A Bio-inspired VM Migration using Re-initialization and Decomposition Based-Whale Optimization. ICT Express 2023, 9, 92–99. [Google Scholar] [CrossRef]
- Zhang, B.; Wang, X.; Wang, H. Virtual machine placement strategy using cluster-based genetic algorithm. Neurocomputing 2021, 428, 310–316. [Google Scholar] [CrossRef]
- Yazidi, A.; Ung, F.; Haugerud, H.; Begnum, K. Effective live migration of virtual machines using partitioning and affinity aware-scheduling. Comput. Electr. Eng. 2018, 69, 240–255. [Google Scholar] [CrossRef]
- Srinivas, B.V.; Mandal, I.; Keshavarao, S. Virtual Machine Migration-Based Intrusion Detection System in Cloud Environment Using Deep Recurrent Neural Network. Cybern. Syst. 2022, 55, 450–470. [Google Scholar] [CrossRef]
- Kumar, Y.; Kaul, S.; Hu, Y.-C. Machine learning for energy-resource allocation, workflow scheduling and live migration in cloud computing: State-of-the-art survey. Sustain. Comput. Inform. Syst. 2022, 36, 100780. [Google Scholar] [CrossRef]
- Shalu; Singh, D. Artificial neural network-based virtual machine allocation in cloud computing. J. Discret. Math. Sci. Cryptogr. 2021, 24, 1739–1750. [Google Scholar] [CrossRef]
- Ma, X.; He, W.; Gao, Y.; Ahmed, G. Virtual Machine Migration Strategy Based on Markov Decision and Greedy Algorithm in Edge Computing Environment. Wirel. Commun. Mob. Comput. 2023, 2023, 6441791. [Google Scholar] [CrossRef]
- Guo, J.; Shi, Y.; Chen, Z.; Yu, T.; Shirinzadeh, B.; Zhao, P. Improved SP-MCTS-Based Scheduling for Multi-Constraint Hybrid Flow Shop. Appl. Sci. 2020, 10, 6220. [Google Scholar] [CrossRef]
- Han, Z.; Tan, H.; Wang, R.; Chen, G.; Li, Y.; Lau, F.C.M. Energy-Efficient Dynamic Virtual Machine Management in Data Centers. IEEE/ACM Trans. Netw. 2019, 27, 344–360. [Google Scholar] [CrossRef]
- Gopu, A.; Thirugnanasambandam, K.; Rajakumar, R.; AlGhamdi, A.S.; Alshamrani, S.S.; Maharajan, K.; Rashid, M. Energy-efficient virtual machine placement in distributed cloud using NSGA-III algorithm. J. Cloud Comput. 2023, 12, 124. [Google Scholar] [CrossRef]
- Mohamed, M.F.; Dahshan, M.; Li, K.; Salah, A.; Khosravi, M.R. Virtual Machine Replica Placement Using a Multiobjective Genetic Algorithm. Int. J. Intell. Syst. 2023, 2023, 8378850. [Google Scholar] [CrossRef]
- Harwahyu, R.; Erasmus Ndolu, F.H.; Overbeek, M.V. Three layer hybrid learning to improve intrusion detection system performance. Int. J. Electr. Comput. Eng. (IJECE) 2024, 14, 1691–1699. [Google Scholar] [CrossRef]
- Shen, S.; Beek, V.V.; Iosup, A. Statistical Characterization of Business-Critical Workloads Hosted in Cloud Datacenters. In Proceedings of the 2015 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, Shenzhen, China, 4–7 May 2015; pp. 465–474. [Google Scholar]
- Iosup, A.; Li, H.; Jan, M.; Anoep, S.; Dumitrescu, C.; Wolters, L.; Epema, D.H.J. The Grid Workloads Archive. Future Gener. Comput. Syst. 2008, 24, 672–686. [Google Scholar] [CrossRef]
- Hidayat, T.; Ramli, K.; Mardian, R.D.; Mahardiko, R. Towards Improving 5G Quality of Experience: Fuzzy as a Mathematical Model to Migrate Virtual Machine Server in The Defined Time Frame. J. Appl. Eng. Technol. Sci. (JAETS) 2023, 4, 711–721. [Google Scholar] [CrossRef]
- Alyas, T.; Ghazal, T.M.; Alfurhood, B.S.; Ahmad, M.; Thawabeh, O.A.; Alissa, K.; Abbas, Q. Performance Framework for Virtual Machine Migration in Cloud Computing. Comput. Mater. Contin. 2022, 74, 6289–6305. [Google Scholar] [CrossRef]
- Hummaida, A.R.; Paton, N.W.; Sakellariou, R. Scalable Virtual Machine Migration using Reinforcement Learning. J. Grid Comput. 2022, 20, 15. [Google Scholar] [CrossRef]
- Kumar, J.; Singh, A.K.; Buyya, R. Ensemble learning based predictive framework for virtual machine resource request prediction. Neurocomputing 2020, 397, 20–30. [Google Scholar] [CrossRef]
- Kim, B.; Han, J.; Jang, J.; Jung, J.; Heo, J.; Min, H.; Rhee, D.S. A Dynamic Checkpoint Interval Decision Algorithm for Live Migration-Based Drone-Recovery System. Drones 2023, 7, 286. [Google Scholar] [CrossRef]
- Saberi, Z.A.; Sadr, H.; Yamaghani, M.R. An Intelligent Diagnosis System for Predicting Coronary Heart Disease. In Proceedings of the 2024 10th International Conference on Artificial Intelligence and Robotics (QICAR), Qazvin, Iran, 29 February 2024; pp. 131–137. [Google Scholar]
- Mosa, A.; Paton, N.W. Optimizing virtual machine placement for energy and SLA in clouds using utility functions. J. Cloud Comput. 2016, 5, 17. [Google Scholar] [CrossRef]
- Moocheet, N.; Jaumard, B.; Thibault, P.; Eleftheriadis, L. Minimum-energy virtual machine placement using embedded sensors and machine learning. Future Gener. Comput. Syst. 2024, 161, 85–94. [Google Scholar] [CrossRef]
- Zagloel, T.Y.M.; Harwahyu, R.; Maknun, I.J.; Kusrini, E.; Whulanza, Y. Developing Models and Tools for Exploring the Synergies between Energy Transition and the Digital Economy. Int. J. Technol. 2023, 14, 291–319. [Google Scholar] [CrossRef]
- Masdari, M.; Khezri, H. Efficient VM migrations using forecasting techniques in cloud computing: A comprehensive review. Clust. Comput. 2020, 23, 2629–2658. [Google Scholar] [CrossRef]
- Leka, H.L.; Fengli, Z.; Kenea, A.T.; Hundera, N.W.; Tohye, T.G.; Tegene, A.T. PSO-Based Ensemble Meta-Learning Approach for Cloud Virtual Machine Resource Usage Prediction. Symmetry 2023, 15, 613. [Google Scholar] [CrossRef]
- St-Onge, C.; Benmakrelouf, S.; Kara, N.; Tout, H.; Edstrom, C.; Rabipour, R. Generic SDE and GA-based workload modeling for cloud systems. J. Cloud Comput. 2021, 10, 6. [Google Scholar] [CrossRef]
- Tuli, S.; Ilager, S.; Ramamohanarao, K.; Buyya, R. Dynamic scheduling for stochastic edge-cloud computing environments using a3c learning and residual recurrent neural networks. IEEE Trans. Mob. Comput. 2020, 21, 940–954. [Google Scholar] [CrossRef]
- Dang-Quang, N.-M.; Yoo, M. An Efficient Multivariate Autoscaling Framework Using Bi-LSTM for Cloud Computing. Appl. Sci. 2022, 12, 3523. [Google Scholar] [CrossRef]
- Bhatt, C.; Singhal, S. Multi-Objective Reinforcement Learning for Virtual Machines Placement in Cloud Computing. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 1051–1058. [Google Scholar] [CrossRef]
- Chayan, B.; Sunita, S. Hybrid Metaheuristic Technique for Optimization of Virtual Machine Placement in Cloud. Int. J. Fuzzy Log. Intell. Syst. 2023, 23, 353–364. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Hyperparameter | Search Range | Optimal Value |
|---|---|---|---|
| MDP | gamma | 0.8, 0.9, 0.99 | 0.9 |
| MDP | theta | 0.0001, 0.001, 0.01 | 0.001 |
| RF | n_estimators | 300, 400, 500 | 400 |
| RF | max_depth | 15, 20, None | 20 |
| RF | max_features | ‘sqrt’, ‘log2’, None | ‘sqrt’ |
| RF | min_samples_split | 2, 4, 6 | 4 |
| RF | min_samples_leaf | 1, 2, 4 | 2 |
| RF | class_weight | (0:1, 1:10) | (0:1, 1:10) |
| RF | cv_folds | 5 (cross-validation folds) | 5 |
| NSGA-III | population_size | 50, 100, 150 | 100 |
| NSGA-III | num_generations | 50, 100, 150 | 100 |
| NSGA-III | crossover_probability | 0.6, 0.7, 0.8 | 0.7 |
| NSGA-III | mutation_probability | 0.2, 0.3, 0.4 | 0.3 |
| Class | Precision | Recall | F1 Score |
|---|---|---|---|
| Non-Migration (0) | 0.98 | 1.00 | 0.99 |
| Migration (1) | 1.00 | 0.92 | 0.96 |
| Author | Model Machine Learning | Accuracy (%) | MAPE (%) | SLA Compliance (%) | Energy Efficiency/Savings (%) |
|---|---|---|---|---|---|
| [37] | PSO Ensemble | - | 0.545 | - | - |
| [38] | Hull-White and GA | - | 3.70 | - | - |
| [39] | A3C and R2N2 | - | - | 31.9 | 14.4 |
| [40] | Multivariate Bi-LSTM | - | - | - | - |
| [41] | Multi-Objective RL (VMRL) | - | - | - | 17 |
| [42] | SA-IWDCA | - | - | - | 25 |
| Proposed Model | Hybrid (MDP, RF, and NSGA-III) | 98.77 | 7.69 | 93 | 90.8 |
| Server Name | CPU (MHz) | Memory (MiB) | Storage (GB) | IP Address |
|---|---|---|---|---|
| Server Proxmox HM 1 | 2 | 4048 | 150 | 192.168.1.228/24 |
| Server Proxmox HM 2 | 2 | 4048 | 100 | 192.168.1.229/24 |
| Server Proxmox HM 3 | 2 | 4048 | 100 | 192.168.1.230/24 |
| Server Librenms | 2 | 4048 | 40 | 192.168.1.69/24 |
| VM1 | 1 | 1048 | 10 | 192.168.1.10/24 |
| VM2 | 1 | 2048 | 20 | 192.168.1.11/24 |
| VM3 | 1 | 3048 | 30 | 192.168.1.12/24 |
| VM4 | 1 | 4048 | 40 | 192.168.1.13/24 |
| VM5 | 1 | 3048 | 30 | 192.168.1.14/24 |
| VM6 | 1 | 1048 | 10 | 192.168.1.15/24 |
| VM Name | HM Source | HM Destination | Total Migration Time (Minutes) | Downtime (ms) | Status |
|---|---|---|---|---|---|
| VM5 | HM2 | HM3 | 1.33 | 163 | Success |
| VM5 | HM3 | HM1 | 2.48 | 0 | Fail |
| VM4 | HM1 | HM3 | 2.01 | 0 | Fail |
| VM3 | HM3 | HM1 | 6.17 | 0 | Fail |
| VM5 | HM3 | HM2 | 2.14 | 103 | Success |
| VM5 | HM3 | HM2 | 1.24 | 93 | Success |
| VM4 | HM1 | HM3 | 7.25 | 57 | Success |
| VM Name | HM Source | HM Destination | Total Migration Time (Minutes) | Downtime (ms) | Status |
|---|---|---|---|---|---|
| VM2 | HM2 | HM3 | 2.30 | 42 | Success |
| VM5 | HM2 | HM3 | 1.23 | 64 | Success |
| VM2 | HM3 | HM2 | 2.43 | 84 | Success |
| VM3 | HM1 | HM3 | 4.02 | 39 | Success |
| VM3 | HM3 | HM1 | 3.59 | 61 | Success |
| VM4 | HM3 | HM1 | 3.38 | 32 | Success |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hidayat, T.; Ramli, K.; Harwahyu, R. Strategy for Precopy Live Migration and VM Placement in Data Centers Based on Hybrid Machine Learning. Informatics 2025, 12, 71. https://doi.org/10.3390/informatics12030071
Hidayat T, Ramli K, Harwahyu R. Strategy for Precopy Live Migration and VM Placement in Data Centers Based on Hybrid Machine Learning. Informatics. 2025; 12(3):71. https://doi.org/10.3390/informatics12030071
Chicago/Turabian StyleHidayat, Taufik, Kalamullah Ramli, and Ruki Harwahyu. 2025. "Strategy for Precopy Live Migration and VM Placement in Data Centers Based on Hybrid Machine Learning" Informatics 12, no. 3: 71. https://doi.org/10.3390/informatics12030071
APA StyleHidayat, T., Ramli, K., & Harwahyu, R. (2025). Strategy for Precopy Live Migration and VM Placement in Data Centers Based on Hybrid Machine Learning. Informatics, 12(3), 71. https://doi.org/10.3390/informatics12030071