
Clinical Text Classification for Tuberculosis Diagnosis Using Natural Language Processing and Deep Learning Model with Statistical Feature Selection Technique


Abstract
1. Introduction
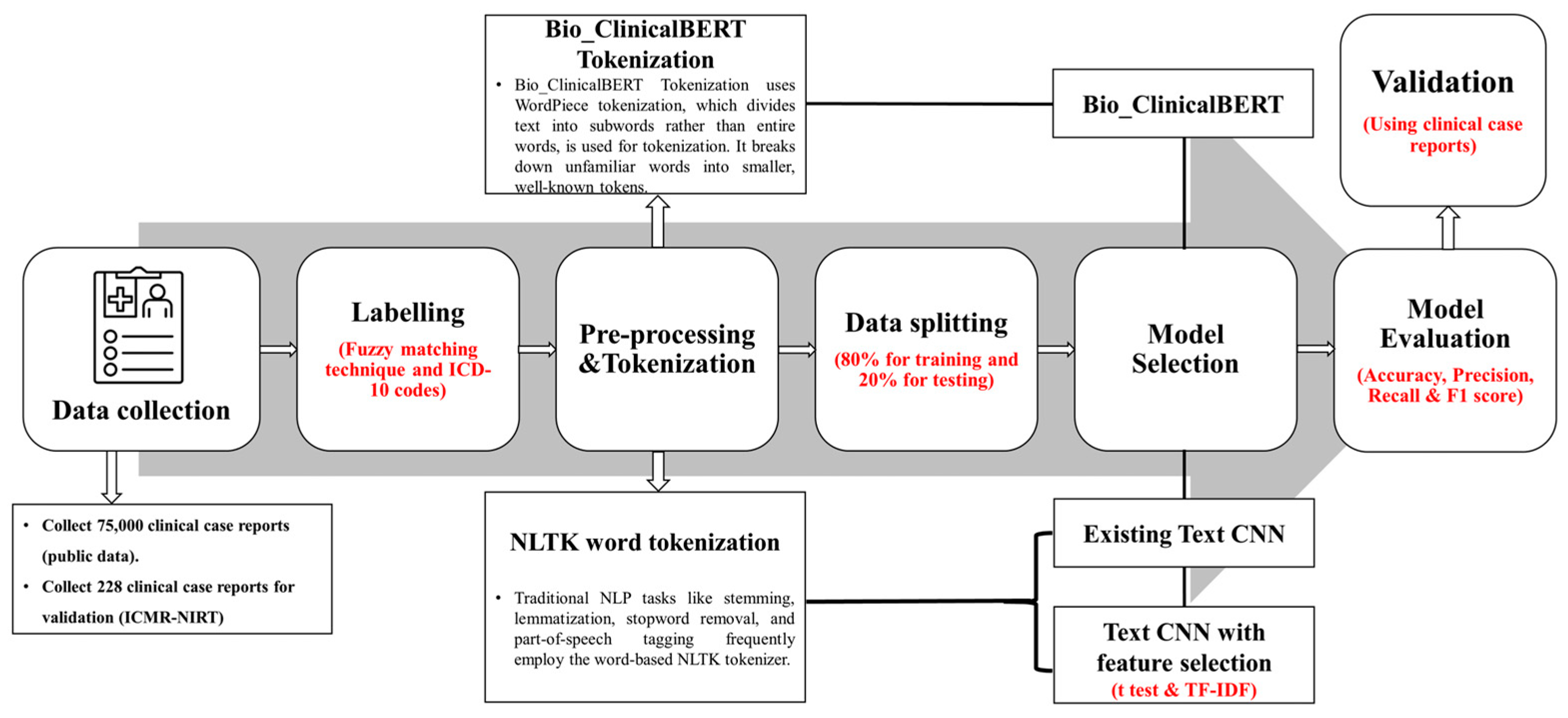
2. Materials and Methods
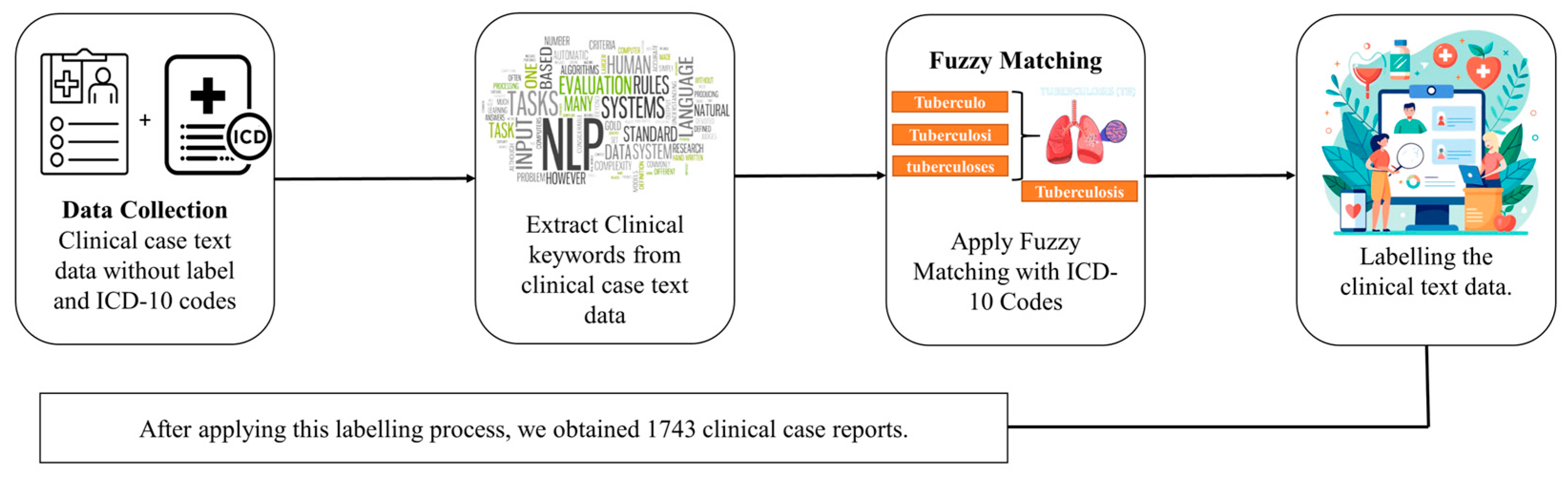
2.1. Dataset Labeling and Preprocessing
2.2. Challenges of Handling Clinical Notes
2.3. Model Architectures
2.3.1. Text CNN
2.3.2. Bio_ClinicalBERT
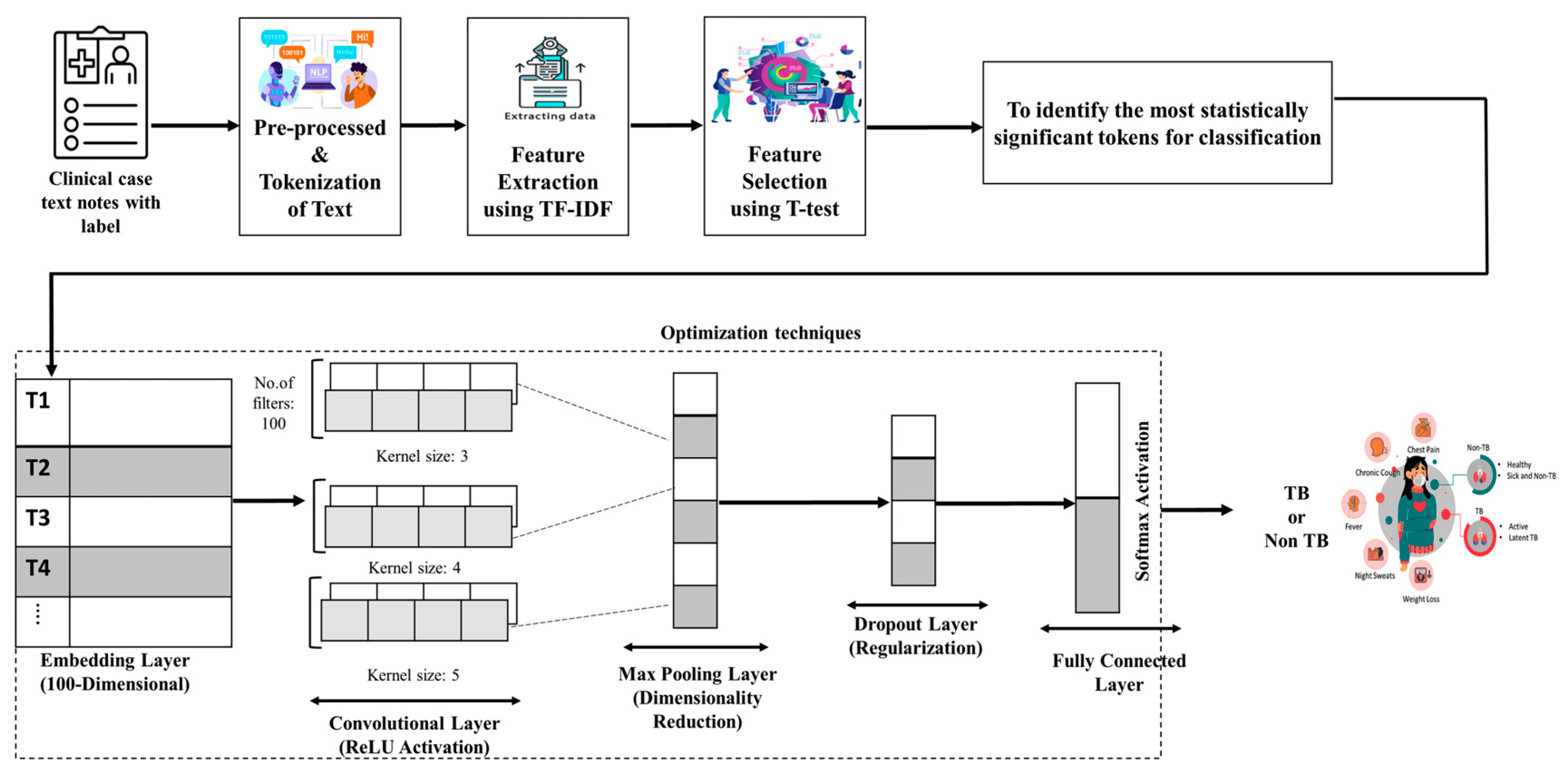
2.3.3. Proposed Text CNN with Feature Selection
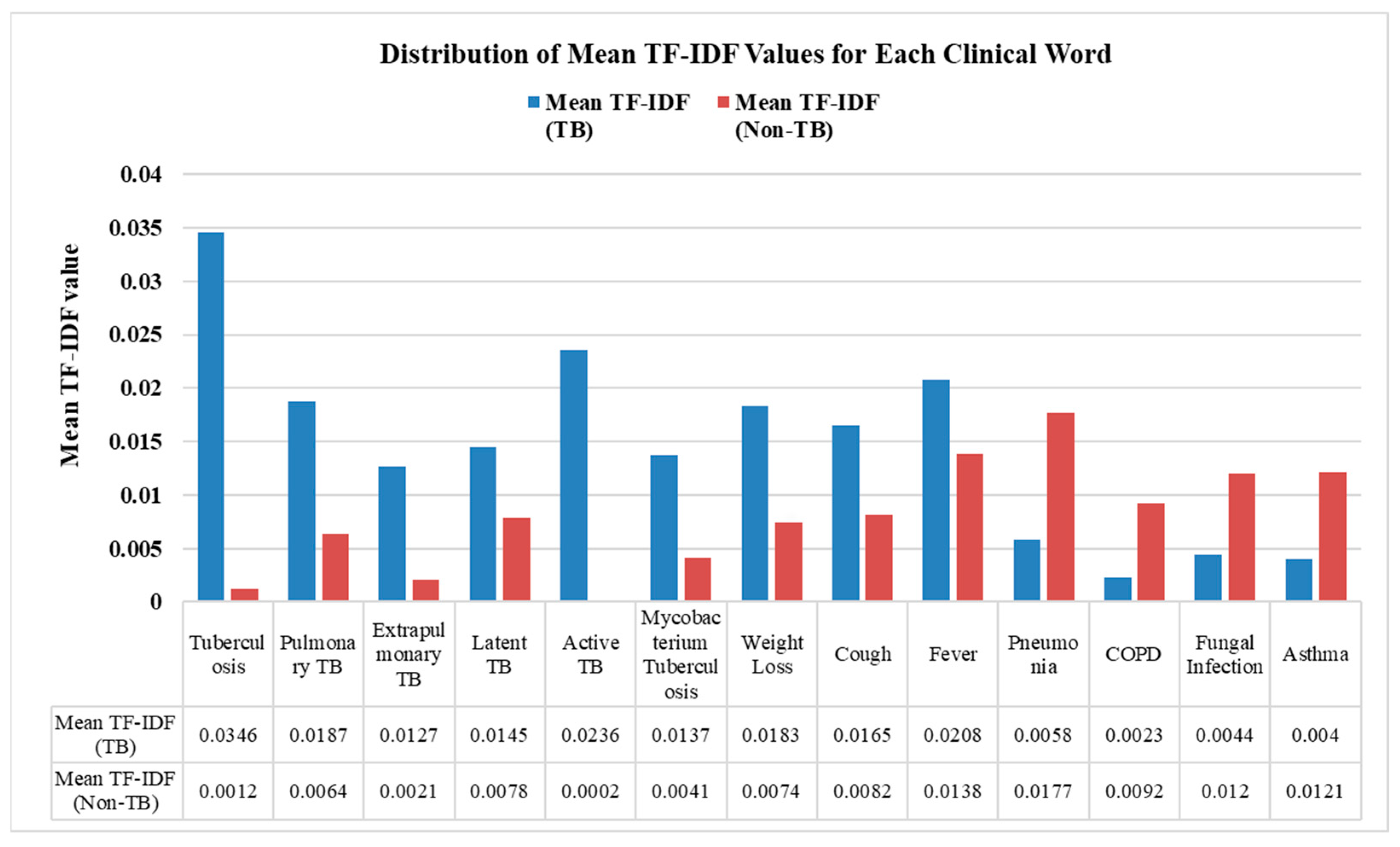
2.3.4. TF-IDF
2.3.5. T-Test
2.4. Model Setup Details
2.5. Model Evaluation
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TB | Tuberculosis |
| Non-TB | Non-Tuberculosis |
| AI | Artificial Intelligence |
| EHR | Electronic Health Record |
| ML | Machine Learning |
| ICD | International Categorization of Diseases |
| WHO | World Health Organization |
| NLP | Natural Language Processing |
| EMR | Electronic Medical Record |
| DL | Deep Learning |
| DNN | Deep Neural Network |
| MIMIC II | Multiparameter Intelligent Monitoring in Intensive Care II |
| MIMIC-III | Medical Information Mart for Intensive Care III |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| Text CNN | Text Convolutional Neural Network |
| TP | True Positives |
| TN | True Negatives |
| FP | False Positives |
| FN | False Negatives |
| BERT | Bidirectional Encoder Representations from Transformers |
| TF-IDF | Term Frequency–Inverse Document Frequency |
| IDF | Inverse Document Frequency |
| ReLU | Rectified Linear Unit |
| GeLU | Gaussian Error Linear Unit |
| NLTK | Natural Language Toolkit |
| AUC | Area Under the Curve |
| LLM | Large Language Model |
References
- Global Tuberculosis Report 2024. Available online: https://www.who.int/publications/i/item/9789240101531 (accessed on 17 March 2025).
- Falzon, D.; Timimi, H.; Kurosinski, P.; Migliori, G.B.; Van Gemert, W.; Denkinger, C.; Isaacs, C.; Story, A.; Garfein, R.S.; Bastos, L.G.D.V.; et al. Digital Health for the End TB Strategy: Developing Priority Products and Making Them Work. Eur. Respir. J. 2016, 48, 29–45. [Google Scholar] [CrossRef] [PubMed]
- Reid, M.J.A.; Arinaminpathy, N.; Bloom, A.; Bloom, B.R.; Boehme, C.; Chaisson, R.; Chin, D.P.; Churchyard, G.; Cox, H.; Ditiu, L.; et al. Building a Tuberculosis-Free World: The Lancet Commission on Tuberculosis. Lancet 2019, 393, 1331–1384. [Google Scholar] [CrossRef] [PubMed]
- Bagheri, A. Text Mining in Healthcare: Bringing Structure to Electronic Health Records. Ph.D. Thesis, Utrecht University, Utrecht, The Netherlands, 2021. [Google Scholar] [CrossRef]
- Sutton, R.T.; Pincock, D.; Baumgart, D.C.; Sadowski, D.C.; Fedorak, R.N.; Kroeker, K.I. An Overview of Clinical Decision Support Systems: Benefits, Risks, and Strategies for Success. npj Digit. Med. 2020, 3, 17. [Google Scholar] [CrossRef] [PubMed]
- Department of Health & Human Services. Available online: https://www.hhs.gov/ (accessed on 5 February 2025).
- Spasic, I.; Nenadic, G. Clinical Text Data in Machine Learning: Systematic Review. JMIR Med. Inform. 2020, 8, e17984. [Google Scholar] [CrossRef]
- Lenivtseva, Y.; Kopanitsa, G. Investigation of Content Overlap in Proprietary Medical Mappings. In ICT for Health Science Research; IOS Press: Amsterdam, The Netherlands, 2019; pp. 41–45. [Google Scholar] [CrossRef]
- Kaur, R.; Ginige, J.A. Analysing Effectiveness of Multi-Label Classification in Clinical Coding. In Proceedings of the Australasian Computer Science Week Multiconference, Sydney, NSW, Australia, 29–31 January 2019; ACM: New York, NY, USA, 2019; pp. 1–9. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Rastegar-Mojarad, M.; Moon, S.; Shen, F.; Afzal, N.; Liu, S.; Zeng, Y.; Mehrabi, S.; Sohn, S.; et al. Clinical Information Extraction Applications: A Literature Review. J. Biomed. Inform. 2018, 77, 34–49. [Google Scholar] [CrossRef]
- Alemu, A.; Hulth, A.; Megyesi, B. General-Purpose Text Categorization Applied to the Medical Domain. 2007. Available online: https://www.diva-portal.org/smash/record.jsf?pid=diva2:40971 (accessed on 5 March 2025).
- Larkey, L.S.; Croft, W.B. Automatic Assignment of Icd9 Codes to Discharge Summaries; Technical report; University of Massachusetts at Amherst: Amherst, MA, USA, 1995; Available online: https://www.academia.edu/download/30740467/10.1.1.49.816.pdf (accessed on 6 February 2025).
- International Classification of Diseases (ICD). Available online: https://www.who.int/standards/classifications/classification-of-diseases (accessed on 6 February 2025).
- Li, F.; Yu, H. ICD Coding from Clinical Text Using Multi-Filter Residual Convolutional Neural Network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8180–8187. [Google Scholar] [CrossRef]
- Mullenbach, J.; Wiegreffe, S.; Duke, J.; Sun, J.; Eisenstein, J. Explainable Prediction of Medical Codes from Clinical Text. arXiv 2018. [Google Scholar] [CrossRef]
- Jiang, F.; Jiang, Y.; Zhi, H.; Dong, Y.; Li, H.; Ma, S.; Wang, Y.; Dong, Q.; Shen, H.; Wang, Y. Artificial Intelligence in Healthcare: Past, Present and Future. Stroke Vasc. Neurol. 2017, 2, e000101. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Resta, M.; Sonnessa, M.; Tànfani, E.; Testi, A. Unsupervised Neural Networks for Clustering Emergent Patient Flows. Oper. Res. Health Care 2018, 18, 41–51. [Google Scholar] [CrossRef]
- Bagheri, A.; Giachanou, A.; Mosteiro, P.; Verberne, S. Natural Language Processing and Text Mining (Turning Unstructured Data into Structured). In Clinical Applications of Artificial Intelligence in Real-World Data; Asselbergs, F.W., Denaxas, S., Oberski, D.L., Moore, J.H., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 69–93. [Google Scholar] [CrossRef]
- Yim, W.; Yetisgen, M.; Harris, W.P.; Kwan, S.W. Natural Language Processing in Oncology: A Review. JAMA Oncol. 2016, 2, 797–804. [Google Scholar] [CrossRef]
- Byrd, R.J.; Steinhubl, S.R.; Sun, J.; Ebadollahi, S.; Stewart, W.F. Automatic Identification of Heart Failure Diagnostic Criteria, Using Text Analysis of Clinical Notes from Electronic Health Records. Int. J. Med. Inform. 2014, 83, 983–992. [Google Scholar] [CrossRef] [PubMed]
- Jamian, L.; Wheless, L.; Crofford, L.J.; Barnado, A. Rule-Based and Machine Learning Algorithms Identify Patients with Systemic Sclerosis Accurately in the Electronic Health Record. Arthritis Res. Ther. 2019, 21, 305. [Google Scholar] [CrossRef] [PubMed]
- Koopman, B.; Karimi, S.; Nguyen, A.; McGuire, R.; Muscatello, D.; Kemp, M.; Truran, D.; Zhang, M.; Thackway, S. Automatic Classification of Diseases from Free-Text Death Certificates for Real-Time Surveillance. BMC Med. Inform. Decis. Mak. 2015, 15, 53. [Google Scholar] [CrossRef]
- Kocbek, S.; Cavedon, L.; Martinez, D.; Bain, C.; Mac Manus, C.; Haffari, G.; Zukerman, I.; Verspoor, K. Text Mining Electronic Hospital Records to Automatically Classify Admissions against Disease: Measuring the Impact of Linking Data Sources. J. Biomed. Inform. 2016, 64, 158–167. [Google Scholar] [CrossRef]
- Bagheri, A.; Sammani, A.; Van Der Heijden, P.G.M.; Asselbergs, F.W.; Oberski, D.L. ETM: Enrichment by Topic Modeling for Automated Clinical Sentence Classification to Detect Patients’ Disease History. J. Intell. Inf. Syst. 2020, 55, 329–349. [Google Scholar] [CrossRef]
- Sammani, A.; Bagheri, A.; van der Heijden, P.G.; Te Riele, A.S.; Baas, A.F.; Oosters, C.A.J.; Oberski, D.; Asselbergs, F.W. Automatic Multilabel Detection of ICD10 Codes in Dutch Cardiology Discharge Letters Using Neural Networks. npj Digit. Med. 2021, 4, 37. [Google Scholar] [CrossRef]
- Huang, K.; Altosaar, J.; Ranganath, R. ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission. arXiv 2020. [Google Scholar] [CrossRef]
- Jonnagaddala, J.; Liaw, S.-T.; Ray, P.; Kumar, M.; Chang, N.-W.; Dai, H.-J. Coronary Artery Disease Risk Assessment from Unstructured Electronic Health Records Using Text Mining. J. Biomed. Inform. 2015, 58, S203–S210. [Google Scholar] [CrossRef]
- Menger, V.; Scheepers, F.; van Wijk, L.M.; Spruit, M. DEDUCE: A Pattern Matching Method for Automatic de-Identification of Dutch Medical Text. Telemat. Inform. 2018, 35, 727–736. [Google Scholar] [CrossRef]
- Kam, H.J.; Kim, H.Y. Learning Representations for the Early Detection of Sepsis with Deep Neural Networks. Comput. Biol. Med. 2017, 89, 248–255. [Google Scholar] [CrossRef]
- Wang, H.; Li, Y.; Khan, S.A.; Luo, Y. Prediction of Breast Cancer Distant Recurrence Using Natural Language Processing and Knowledge-Guided Convolutional Neural Network. Artif. Intell. Med. 2020, 110, 101977. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y. Convolutional Neural Network for Sentence Classification. 2015. Available online: https://uwspace.uwaterloo.ca/items/42654efd-45e2-4c67-b906-158e7e349188 (accessed on 1 February 2025).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent Neural Network Regularization. arXiv 2015. [Google Scholar] [CrossRef]
- Nievas Offidani, M.A.; Delrieux, C.A. Dataset of Clinical Cases, Images, Image Labels and Captions from Open Access Case Reports from PubMed Central (1990–2023). Data Brief 2024, 52, 110008. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Jeong, Y.-S. Sentiment Classification Using Convolutional Neural Networks. Appl. Sci. 2019, 9, 2347. [Google Scholar] [CrossRef]
- Hughes, M.; Li, I.; Kotoulas, S.; Suzumura, T. Medical Text Classification Using Convolutional Neural Networks. In Informatics for Health: Connected Citizen-Led Wellness and Population Health; IOS Press: Amsterdam, Switzerland, 2017; pp. 246–250. [Google Scholar] [CrossRef]
- Widiastuti, N.I. Convolution Neural Network for Text Mining and Natural Language Processing. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2019; Volume 662, p. 052010. [Google Scholar]
- Xu, J.; Xi, X.; Chen, J.; Sheng, V.S.; Ma, J.; Cui, Z. A Survey of Deep Learning for Electronic Health Records. Appl. Sci. 2022, 12, 11709. [Google Scholar] [CrossRef]
- Emilyalsentzer/Bio_ClinicalBERT Hugging Face. Available online: https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT (accessed on 15 February 2025).
- Lam, S.L.Y.; Lee, D.L. Feature Reduction for Neural Network Based Text Categorization. In Proceedings of the 6th International Conference on Advanced Systems for Advanced Applications, Hsinchu, Taiwan, 21 April 1999; IEEE Computer Society: Washington, DC, USA, 1999; pp. 195–202. [Google Scholar] [CrossRef]
- Deng, X.; Li, Y.; Weng, J.; Zhang, J. Feature Selection for Text Classification: A Review. Multimed. Tools Appl. 2019, 78, 3797–3816. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, H.; Liu, R.; Lv, W.; Wang, D. T-Test Feature Selection Approach Based on Term Frequency for Text Categorization. Pattern Recognit. Lett. 2014, 45, 1–10. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Clinical Text Classification with Rule-Based Features and Knowledge-Guided Convolutional Neural Networks. BMC Med. Inform. Decis. Mak. 2019, 19, 71. [Google Scholar] [CrossRef]
- Rios, A.; Kavuluru, R. Convolutional Neural Networks for Biomedical Text Classification: Application in Indexing Biomedical Articles. In Proceedings of the 6th ACM Conference on Bioinformatics, Computational Biology and Health Informatics, Atlanta, GA, USA, 9–12 September 2015; ACM: New York, NY, USA, 2015; pp. 258–267. [Google Scholar] [CrossRef]
- Liang, H.; Sun, X.; Sun, Y.; Gao, Y. Text Feature Extraction Based on Deep Learning: A Review. J. Wirel. Com. Netw. 2017, 2017, 211. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Text CNN | Text CNN with T-Test | Bio_ClinicalBERT | |
|---|---|---|---|---|
| Model Hyperparameters | Embedding dimensions | 100 | 100 | 768 |
| Number of Filters/Encoders | 100 | 100 | 12 encoders | |
| Filter size | (3, 4, 5) | (3, 4, 5) | - | |
| Number of classes | 2 | 2 | 2 | |
| Dropout | 0.5 | 0.5 | 0.1 | |
| Activation function | ReLU | ReLU | GeLU (in Transformer layers), Softmax (final layer) | |
| Optimizer | Adam | Adam | Adam | |
| Training Parameter | Batch size | 16 | 16 | 8 |
| Epoch size | 8 | 8 | 3 | |
| Learning rate | 0.001 | 0.001 | 5.00 × 10−5 | |
| Total Parameters | 1.12 M | 1.12 M | 108 M |
| Model Name | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|
| Text CNN | 72.22 | 88.89 | 79.69 | 0.86 |
| Bio_ClinicalBERT | 83.33 | 80.54 | 81.91 | 0.85 |
| Proposed Text CNN with t-test | 88.19 | 90.71 | 89.44 | 0.91 |
| Model Name | True Positive | False Positive | False Negative | True Negative |
|---|---|---|---|---|
| Text CNN | 104 | 40 | 13 | 192 |
| Bio_ClinicalBERT | 120 | 24 | 29 | 176 |
| Proposed Text CNN with t-test | 127 | 17 | 13 | 192 |
| Model Name | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|
| Text CNN | 85.47 | 98.66 | 91.68 | 0.835 |
| Bio_ClinicalBERT | 100 | 76.11 | 86 | 0.877 |
| Proposed Text CNN with t-test | 100 | 98.85 | 99.42 | 0.982 |
| Model Name | True Positive | False Positive | False Negative | True Negative |
|---|---|---|---|---|
| Text CNN | 147 | 25 | 2 | 54 |
| Bio_ClinicalBERT | 172 | 0 | 54 | 2 |
| Proposed Text CNN with t-test | 172 | 0 | 2 | 54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahamed, S.F.; Karuppasamy, S.; Chinnaiyan, P. Clinical Text Classification for Tuberculosis Diagnosis Using Natural Language Processing and Deep Learning Model with Statistical Feature Selection Technique. Informatics 2025, 12, 64. https://doi.org/10.3390/informatics12030064
Ahamed SF, Karuppasamy S, Chinnaiyan P. Clinical Text Classification for Tuberculosis Diagnosis Using Natural Language Processing and Deep Learning Model with Statistical Feature Selection Technique. Informatics. 2025; 12(3):64. https://doi.org/10.3390/informatics12030064
Chicago/Turabian StyleAhamed, Shaik Fayaz, Sundarakumar Karuppasamy, and Ponnuraja Chinnaiyan. 2025. "Clinical Text Classification for Tuberculosis Diagnosis Using Natural Language Processing and Deep Learning Model with Statistical Feature Selection Technique" Informatics 12, no. 3: 64. https://doi.org/10.3390/informatics12030064
APA StyleAhamed, S. F., Karuppasamy, S., & Chinnaiyan, P. (2025). Clinical Text Classification for Tuberculosis Diagnosis Using Natural Language Processing and Deep Learning Model with Statistical Feature Selection Technique. Informatics, 12(3), 64. https://doi.org/10.3390/informatics12030064