
IER-SMCEM: An Implicit Expression Recognition Model of Emojis in Social Media Comments Based on Prompt Learning


Abstract
:1. Introduction
- By applying IEEA to an existing publicly accessible dataset, we have created a sentiment analysis dataset for Chinese and English social comments. Because it is difficult to collect and process data in other languages, the target language of this study is based on Chinese and English.
- In this paper, IEPM is designed to address the challenge of recognizing implicit expressions of emojis in financial text analysis models.
- In this paper, we validate the positive impact of recognizing implicit expressions of emojis on financial text analysis tasks using a financial sentiment analysis model.
2. Related Work
2.1. Semantic Analysis Technology
2.2. Financial Text Analysis and Dataset Challenge
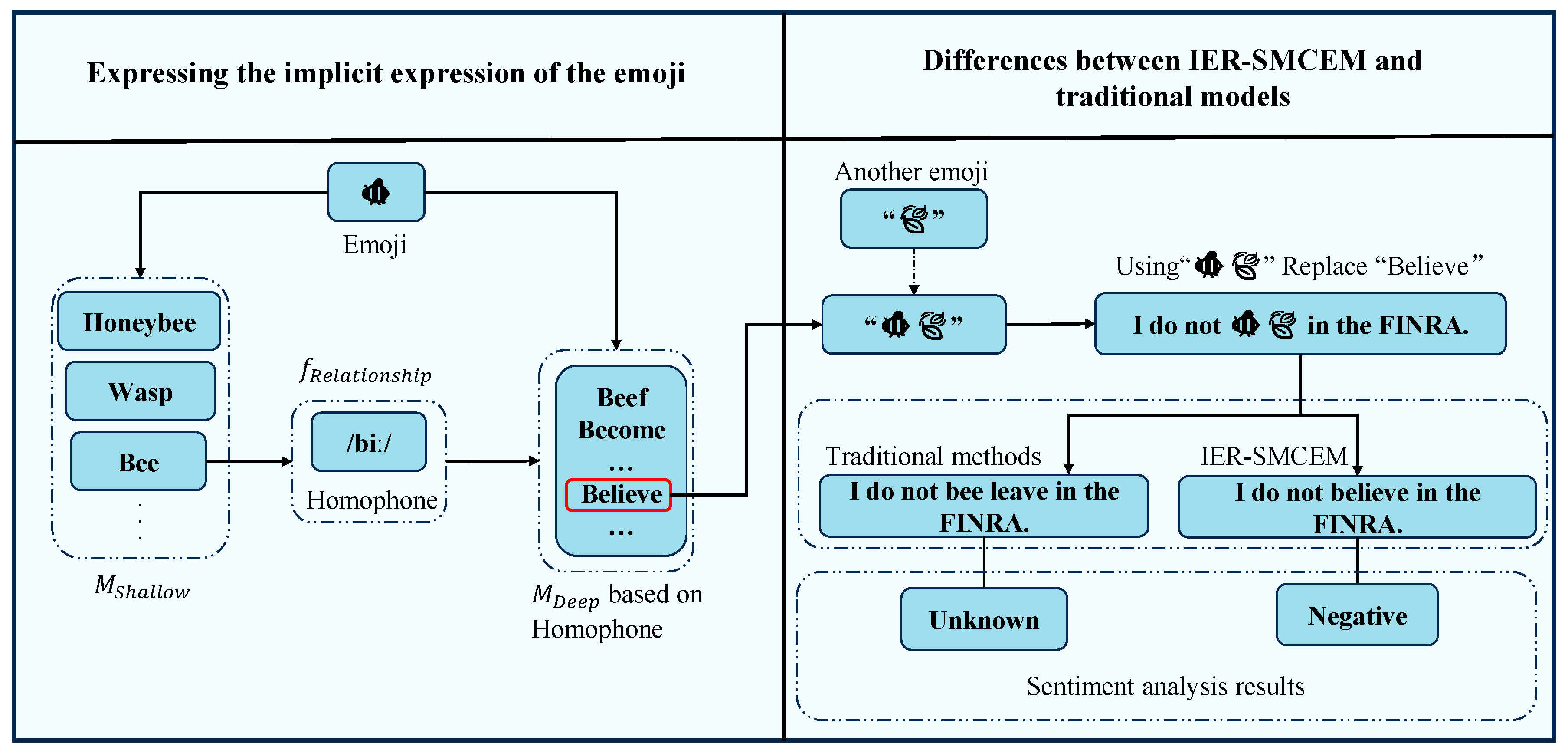
3. Implicit Expression of Emojis
 ). Different expressions can arise depending on the language, cultural background, or domain, making the automated annotation of implicit expressions in emojis particularly difficult [8]. Given the significant variations in cultural contexts across different domains, this chapter focuses on the implicit expressions communicated through emoji harmonics. In Table 2, emojis utilize harmonics (e.g.,
). Different expressions can arise depending on the language, cultural background, or domain, making the automated annotation of implicit expressions in emojis particularly difficult [8]. Given the significant variations in cultural contexts across different domains, this chapter focuses on the implicit expressions communicated through emoji harmonics. In Table 2, emojis utilize harmonics (e.g., 
 , ) to achieve implicit expressions.
, ) to achieve implicit expressions.4. Methods

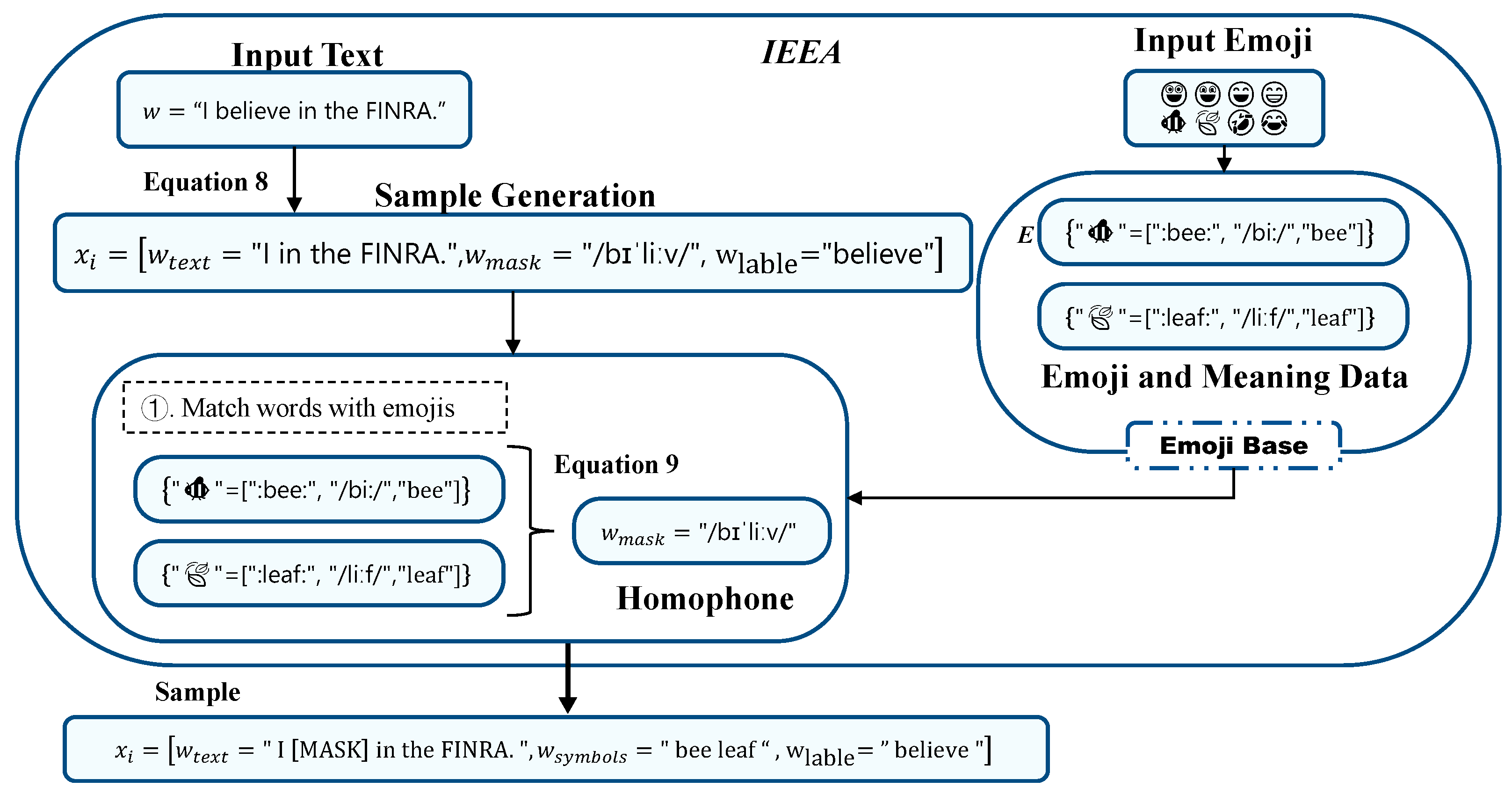
 in the FINRA.” in the template “Related: [symbol]. Complete this sentence: [input] [mask].” Then, the input of the model is “ Related: bee leaf. Complete this sentence: I do not [mask] in the FINRA.” Finally, the prediction result of the model is “believe.” This paper introduces Bert’s workflow to explain how the model is predicted.
in the FINRA.” in the template “Related: [symbol]. Complete this sentence: [input] [mask].” Then, the input of the model is “ Related: bee leaf. Complete this sentence: I do not [mask] in the FINRA.” Finally, the prediction result of the model is “believe.” This paper introduces Bert’s workflow to explain how the model is predicted.4.1. Implicit Emoji Enhancement Algorithm (IEEA)
4.2. Implicit Emoji Prediction Module (IEPM)
5. Results
5.1. Dataset
5.2. Ambiguity Analysis
5.3. Pre-Trained Models
5.4. Prompt Template
5.5. Evaluation
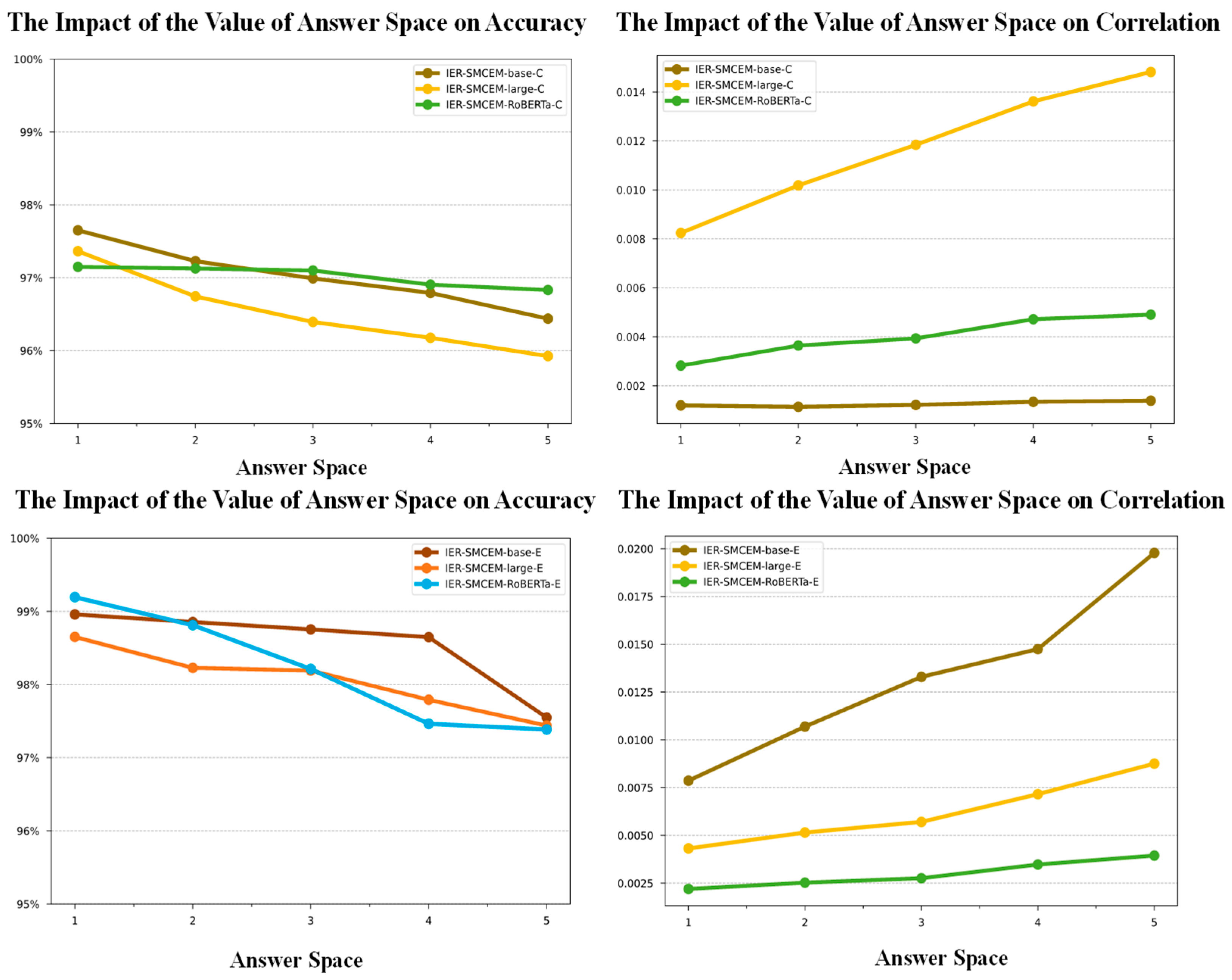
5.6. Selection of Answer Space
5.7. The Semantic Recovery of Traditional Models
5.8. Experimental Results of Prompt Templates
6. Case Study
7. Application
8. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Du, K.; Xing, F.; Mao, R.; Cambria, E. Financial Sentiment Analysis: Techniques and Applications. ACM Comput. Surv. 2024, 56, 1–42. Available online: https://stocktwits.com/ (accessed on 24 April 2024). [CrossRef]
- Zhou, Z.; Ma, L.; Liu, H. Trade the event: Corporate events detection for news-based event-driven trading. arXiv 2021, arXiv:2105.12825. [Google Scholar]
- Lin, W.; Liao, L.C. Lexicon-based prompt for financial dimensional sentiment analysis. Expert Syst. Appl. 2024, 244, 122936. [Google Scholar] [CrossRef]
- Padmanayana, V.; Bhavya, K. Stock market prediction using Twitter sentiment analysis. Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 2021, 7, 265–270. [Google Scholar] [CrossRef]
- Singla, A.; Gupta, M. Exploring the potential of dogecoin promoted by elon musk. J. Metaverse Blockchain Technol. 2024, 2, 35–43. [Google Scholar] [CrossRef]
- Carrillo, H.E.; Pennington, R.; Zhang, Y. Is an Emoji Worth a Thousand Words? The Effect of Emoji Usage on Nonprofessional Investors’ Perceptions. J. Inf. Syst. 2022, 36, 1–15. [Google Scholar] [CrossRef]
- Chen, S.; Xing, F. Understanding Emojis for Financial Sentiment Analysis. In Proceedings of the ICIS 2023, Hyderabad, India, 10–13 December 2023; Available online: https://aisel.aisnet.org/icis2023/socmedia_digcollab/socmedia_digcollab/3 (accessed on 24 April 2024).
- Lu, X.; Cao, Y.; Chen, Z.; Liu, X. A first look at emoji usage on github: An empirical study. arXiv 2018, arXiv:1812.04863. [Google Scholar]
- Zhou, Y.; Xu, P.; Wang, X.; Lu, X.; Gao, G.; Ai, W. Emojis decoded: Leveraging chatgpt for enhanced understanding in social media communications. arXiv 2024, arXiv:2402.01681. [Google Scholar] [CrossRef]
- Zhao, Z.; Rao, G.; Feng, Z. DFDS: A domain-independent framework for document-level sentiment analysis based on RST. In Proceedings of the Web and Big Data: First International Joint Conference, APWeb-WAIM 2017, Beijing, China, 7–9 July 2017; Proceedings, Part I 1. Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 297–310. [Google Scholar]
- Zhang, Y.; Zhang, Y. Tree communication models for sentiment analysis. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3518–3527. [Google Scholar]
- Liu, J.; Zhang, Y. Attention modeling for targeted sentiment. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, Valencia, Spain, 3–7 April 2017; pp. 572–577. [Google Scholar]
- Alquézar, R.; Sanfeliu, A. Recognition and learning of a class of context-sensitive languages described by augmented regular expressions. Pattern Recognit. 1997, 30, 163–182. [Google Scholar] [CrossRef]
- Park, S.B.; Zhang, B.T. Text chunking by combining hand-crafted rules and memory-based learning. In Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics, Sapporo, Japan, 7–12 July 2003; pp. 497–504. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT understands, too. arXiv 2021, arXiv:2103.10385. [Google Scholar] [CrossRef]
- Ding, N.; Hu, S.; Zhao, W.; Chen, Y.; Liu, Z.; Zheng, H.T.; Sun, M. Openprompt: An open-source framework for prompt-learning. arXiv 2021, arXiv:2111.01998. [Google Scholar]
- Schulhoff, S.; Ilie, M.; Balepur, N.; Kahadze, K.; Liu, A.; Si, C.; Li, Y.; Gupta, A.; Han, H.; Schulhoff, S.; et al. The prompt report: A systematic survey of prompting techniques. arXiv 2024, arXiv:2406.06608. [Google Scholar]
- Schick, T.; Schütze, H. Exploiting cloze questions for few shot text classification and natural language inference. arXiv 2020, arXiv:2001.07676. [Google Scholar]
- Hu, S.; Ding, N.; Wang, H.; Liu, Z.; Li, J.; Sun, M. Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification. arXiv 2021, arXiv:2108.02035. [Google Scholar]
- Aliprand, J.M. The unicode standard. Libr. Resour. Tech. Serv. 2000, 44, 160–167. [Google Scholar] [CrossRef]
- Hu, T.; Guo, H.; Sun, H.; Nguyen, T.V.; Luo, J. Spice up your chat: The intentions and sentiment effects of using emojis. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11, pp. 102–111. [Google Scholar]
- Cramer, H.; De Juan, P.; Tetreault, J. Sender-intended functions of emojis in US messaging. In Proceedings of the 18th International Conference on Human-Computer Interaction with Mobile Devices and Services, Florence, Italy, 6–9 September 2016; pp. 504–509. [Google Scholar]
- Qiu, L.; Wang, W.; Pang, J. The persuasive power of emoticons in electronic word-of-mouth communication on social networking services. MIS Q. 2023, 47, 511. [Google Scholar] [CrossRef]
- Ai, W.; Lu, X.; Liu, X.; Wang, N.; Huang, G.; Mei, Q. Untangling emoji popularity through semantic embeddings. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11, pp. 2–11. [Google Scholar]
- Lu, X.; Ai, W.; Liu, X.; Li, Q.; Wang, N.; Huang, G.; Mei, Q. Learning from the ubiquitous language: An empirical analysis of emoji usage of smartphone users. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 770–780. [Google Scholar]
- Chen, Z.; Shen, S.; Hu, Z.; Lu, X.; Mei, Q.; Liu, X. Emoji-powered representation learning for cross-lingual sentiment classification. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 251–262. [Google Scholar]
- Felbo, B.; Mislove, A.; Søgaard, A.; Rahwan, I.; Lehmann, S. Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm. arXiv 2017, arXiv:1708.00524. [Google Scholar]
- Barbieri, F.; Kruszewski, G.; Ronzano, F.; Saggion, H. How cosmopolitan are emojis? Exploring emojis usage and meaning over different languages with distributional semantics. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 531–535. [Google Scholar]
- Mikolov, T. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2013; Volume 26. [Google Scholar]
- Tino, P.; Schittenkopf, C.; Dorffner, G. Financial volatility trading using recurrent neural networks. IEEE Trans. Neural Netw. 2001, 12, 865–874. [Google Scholar] [CrossRef]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT, Minneapolis, Minnesota, USA, 2–7 June 2019; Volume 1, p. 2. [Google Scholar]
- Chan, S.W.K.; Chong, M.W.C. Sentiment analysis in financial texts. Decis. Support Syst. 2017, 94, 53–64. [Google Scholar] [CrossRef]
- Deveikyte, J.; Geman, H.; Piccari, C.; Provetti, A. A sentiment analysis approach to the prediction of market volatility. Front. Artif. Intell. 2022, 5, 836809. [Google Scholar] [CrossRef] [PubMed]
- de França Costa, D.; da Silva, N.F.F. INF-UFG at FiQA 2018 Task 1: Predicting sentiments and aspects on financial tweets and news headlines. In Proceedings of Companion Proceedings of the The Web Conference 2018; International World Wide Web Conferences Steering Committee: Republic and Canton of Geneva, Switzerland, 2018; pp. 1967–1971. [Google Scholar] [CrossRef]
- Cortis, K.; Freitas, A.; Daudert, T.; Huerlimann, M.; Zarrouk, M.; Handschuh, S.; Davis, B. Semeval-2017 task 5: Fine-grained sentiment analysis on financial microblogs and news. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 519–535. [Google Scholar]
- Xing, F.; Malandri, L.; Zhang, Y.; Cambria, E. Financial sentiment analysis: An investigation into common mistakes and silver bullets. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 978–987. [Google Scholar]
- Deng, S.; Huang, Z.; Sinha, A.P.; Zhao, H. The interaction between microblog sentiment snd stock returns. MIS Q. 2018, 42, 895-A13. [Google Scholar] [CrossRef]
- Long, S.; Lucey, B.; Xie, Y.; Yarovaya, L. “I just like the stock”: The role of Reddit sentiment in the GameStop share rally. Financ. Rev. 2023, 58, 19–37. [Google Scholar] [CrossRef]
- Sampietro, A. Emojis and the performance of humour in everyday electronically-mediated conversation: A corpus study of WhatsApp chats. Internet Pragmat. 2021, 4, 87–110. [Google Scholar] [CrossRef]
- Cui, J.; Dandan, Y.R.; Jiang, G. Judging emoji by occupation: A case of emoji-based sarcasm interpretation. Acta Psychol. 2023, 234, 103870. [Google Scholar] [CrossRef]
- Munikar, M.; Shakya, S.; Shrestha, A. Fine-grained sentiment classification using BERT. In Proceedings of the 2019 Artificial Intelligence for Transforming Business and Society (AITB), Kathmandu, Nepal, 5 November 2019; Volume 1, pp. 1–5. [Google Scholar]
- Oghina, A.; Breuss, M.; Tsagkias, M.; De Rijke, M. Predicting imdb movie ratings using social media. In Proceedings of the Advances in Information Retrieval: 34th European Conference on IR Research, ECIR 2012, Barcelona, Spain, 1–5 April 2012; Proceedings 34. Springer: Berlin/Heidelberg, Germany, 2012; pp. 503–507. [Google Scholar]
- Li, Y.; Yu, B.; Xue, M.; Liu, T. Enhancing pre-trained Chinese character representation with word-aligned attention. arXiv 2019, arXiv:1911.02821. [Google Scholar]
- Liu, B.; Xu, W.; Xiang, Y.; Wu, X.; He, L.; Zhang, B.; Zhu, L. Noise learning for text classification: A benchmark. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 4557–4567. [Google Scholar]
- Page, B.I. The theory of political ambiguity. Am. Political Sci. Rev. 1976, 70, 742–752. [Google Scholar] [CrossRef]
- Basile, A.; Crupi, R.; Grasso, M.; Mercanti, A.; Regoli, D.; Scarsi, S.; Yang, S.; Cosentini, A.C. Disambiguation of company names via deep recurrent networks. Expert Syst. Appl. 2024, 238, 122035. [Google Scholar] [CrossRef]
- Huang, Y.; Giledereli, B.; Köksal, A.; Özgür, A.; Ozkirimli, E. Balancing methods for multi-label text classification with long-tailed class distribution. arXiv 2021, arXiv:2109.04712. [Google Scholar]
- Hartmann, J. Emotion English Distilroberta-Base. 2022. Available online: https://huggingface.co/j-hartmann/emotion-english-distilroberta-base/ (accessed on 24 April 2024).
- Ahmadi, J. Investigating the relationship between investor sentiments and fraudulent financial reporting with emphasis on political connections. J. Account. Manag. Vis. 2023, 6, 285–302. [Google Scholar]
- Ramsheh, M.; Arefmanesh, Z.; Rostami, R.; Khastar, Z. Investor Sentiment and the Likelihood of Fraudulent Financial Reporting in Petroleum and Petrochemical Industries: The Moderating Role of Risk Disclosure. Pet. Bus. Rev. 2023, 7, 1–14. [Google Scholar]
- Vamossy, D.F.; Skog, R.P. EmTract: Extracting emotions from social media. Int. Rev. Financ. Anal. 2025, 97, 103769. [Google Scholar] [CrossRef]
- Lewis, R.J. An introduction to classification and regression tree (CART) analysis. In Proceedings of the Annual Meeting of the Society for Academic Emergency Medicine, San Francisco, CA, USA, 22–25 May 2000; p. 14. [Google Scholar]
- Pathy, A.; Meher, S. Predicting algal biochar yield using eXtreme Gradient Boosting (XGB) algorithm of machine learning methods. Algal Res. 2020, 50, 102006. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Content | Emojis | Semantics |
|---|---|---|
Just bought the dip   . Time to HODL and watch it go . Time to HODL and watch it go   . Not financial advice, just pure vibes! . Not financial advice, just pure vibes! | [: Hole; Downward] [ : Diamond; Hands][ : Rocket; Moon][ : Rocket] | Endless Downwards; Diamond Hands; Soaring Stock Prices; Soaring Stock Prices; |
Market be like: , but my portfolio’s like:   . Guess we’re all just clowning around until the next bull run . Guess we’re all just clowning around until the next bull run   | [: Downwards] [ : Clown; Flying Money][ : Bull; Flexed Biceps] | Downwards Trend; Juggled by the Market; Expecting the Market to Rebound |
| Emojis | Public Annotations | Semantics |
|---|---|---|
 | [Rocket] [Chart Increasing] | Rapid Increase in Share Price |
| [Gem Stone] [Raising Hands] | Diamond Hands |
| [Banana] | Contempt |
| [Rocket] | Significant Increase |
  | [Bar Chart] [Bullseye] | Precise Stock Price Forecast |
| Content | Content with Emojis |
|---|---|
| I do not believe in the FINRA. | I do not in the FINRA. |
| It seemed like a bad idea. | It seemed like a bad  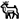 . . |
| Dataset | Train Set | Validation Set | Test Set |
|---|---|---|---|
| IEEA-E | 14,394 | 3676 | 4410 |
| Content | Example1 | Example2 |
|---|---|---|
| Text | 动资金 1 | 财务欺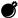 2 2 |
| Semantics | Working capital | Financial fraud |
| Dataset | Train Set | Validation Set | Test Set |
|---|---|---|---|
| IEEA-C | 16,010 | 5113 | 5191 |
| Score | Type | Range |
|---|---|---|
| Levenshtein Distance (↓) 1 | distance | |
| InDel (↑) | similarity | |
| Jaro–Winkler (↑) | similarity | |
| Jaccard (↑) | similarity |
| Before Replacement | After Replacement |
|---|---|
| This show really is the Broadway American Idol. It has singing, the British Guy, A guy who’s sometimes nice, and a super-nice woman. | This show really is the Broadway American Idol. It has  , the , the   , a who’s sometimes , a who’s sometimes  , and a , and a  . 1 . 1 |
is “singing”. is “British Guy”. is “guy”. is “nice”. is “super-nice woman”.| Model | Model-Layer | Pre-Training Tasks |
|---|---|---|
| Bert-base-E | 12-layer | MLM (static mask), NSP |
| Bert-large-E | 24-layer | MLM (static mask), NSP |
| Roberta-E | 12-layer | MLM (dynamic mask) |
| Bert-base-C | 12-layer | MLM (static mask), NSP |
| Bert-large-C | 24-layer | MLM (static mask), NSP |
| Roberta-C | 12-layer | MLM (dynamic mask) |
| Hyper-Parameters | IEEA-C | IEEA-E |
|---|---|---|
| learning rate | 1 × 10−5 | 2 × 10−5 |
| training batch size | 32 | 32 |
| maximum context length | 128 | 128 |
| number of training epochs | 20 | 20 |
| Type | -E | -E | -E |
| Prompt Template | [input] [mask] | Complete this sentence: [input] [mask] | Related: [symbol]. Complete this sentence: [input] [mask]. |
| Example | I do not [mask] in the FINRA. | Complete this sentence: I do not [mask] in the FINRA. | Related: bee leaf. Complete this sentence: I do not [mask] in the FINRA. |
| Type | -C | -C | -C |
| Prompt Template | [input] [mask] | 请补全这个成语:[input] [mask]。 1 | 请补全这个成语:[input] [mask]。提示:与[symbol]有关。 2 |
| Translation | [input] [mask] | Please complete this idiom: [input] [mask]. | Please complete this idiom: [input] [mask]. Tip: It is related to [symbol]. |
| Example | [mask]动资金 | 请补全这个成语: [mask]动资金 | 请补全这个成语:[mask]动资金。提示:与牛有关。 |
| Answer Space Step | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| IER-SMCEM-base-E | 4 | 4.5 | 5 | 5.5 | 6 |
| IER-SMCEM-Roberta-E | 9 | 9.5 | 10 | 10.5 | 11 |
| IER-SMCEM-large-E | 7 | 7.5 | 8 | 8.5 | 9 |
| IER-SMCEM-base-C | 6.5 | 7 | 7.5 | 8 | 8.5 |
| IER-SMCEM-Roberta-C | 6.5 | 7 | 7.5 | 8 | 8.5 |
| IER-SMCEM-large-C | 6.5 | 7 | 7.5 | 8 | 8.5 |
| Original Data | Sentiment Label | Implicit Expressions | Analysis Results | IER-SMCEM | Analysis Results |
|---|---|---|---|---|---|
| I believe in the FINRA. Well actually, I forgot to mention that ‘diamond hands’ is typically ‘paper hands’ when faced with market fluctuations. | Positive | I in the FINRA.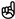  , I forgot to mention that ‘ , I forgot to mention that ‘ ’ is typically ’ is typically  when faced with market fluctuations. when faced with market fluctuations. | Negative | I believe in the FINRA. Well actually, I forgot to mention that ‘diamond hands’ is typically ‘paper hands’ when faced with market fluctuations. | Positive |
| For the most part, I spy was an amusing lark that will probably rank as one of Murphy’s better performances in one of his lesser-praised movies. | Positive | For the most part, I  was an amusing was an amusing 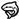 that will probably that will probably  as one of Murphy’s as one of Murphy’s  performances in one of his lesser-praised movies. performances in one of his lesser-praised movies. | Neutral | For the most part, I spy was an amusing lark that will probably rank as one of Murphy’s better performances in one of his lesser-praised movies. | Positive |
| Sentiment Analysis | IEEA-E | IEEA-C |
|---|---|---|
| Positive | 11,240 | 13,157 |
| Negative | 11,240 | 13,157 |
| IER-SMCEM-Base-E | IER-SMCEM-Large-E | IER-SMCEM-Roberta-E | ||||
|---|---|---|---|---|---|---|
| Recover | False | True | False | True | False | True |
| TextCNN | 70.37% | 73.65% | 69.66% | 73.65% | 70.37% | 72.51% |
| BiLSTM | 77.95% | 80.04% | 79.16% | 80.39% | 77.81% | 79.47% |
| Bert | 81.18% | 81.85% | 80.97% | 82.10% | 81.46% | 81.68% |
| Bert-large | 83.45% | 85.79% | 84.01% | 86.50% | 82.10% | 83.02% |
| CART | 61.87% | 63.49% | 61.87% | 63.27% | 61.87% | 62.50% |
| XGB | 69.52% | 72.37% | 69.52% | 72.23% | 69.52% | 71.16% |
| DistilRoBERTa | 84.23% | 87.42% | 84.73% | 87.00% | 87.28% | 87.99% |
| IER-SMCEM-Base-C | IER-SMCEM-Large-C | IER-SMCEM-Roberta-C | ||||
|---|---|---|---|---|---|---|
| Recover | False | True | False | True | False | True |
| TextCNN | 82.24% | 84.61% | 82.85% | 83.69% | 82.76% | 83.59% |
| BiLSTM | 81.07% | 81.62% | 83.65% | 83.74% | 83.46% | 84.86% |
| Bert | 81.39% | 81.48% | 80.96% | 81.29% | 81.62% | 81.91% |
| Bert-large | 79.41% | 80.31% | 78.28% | 80.92% | 80.26% | 80.45% |
| CART | 69.66% | 71.05% | 69.65% | 70.91% | 69.65% | 71.19% |
| XGB | 62.56% | 64.14% | 62.56% | 63.95% | 62.56% | 64.19% |
| DistilRoBERTa | 86.74% | 87.07% | 84.16% | 87.92% | 85.66% | 86.46% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Wang, C.; Liu, Z.; Deng, H.; Li, Q.; Zheng, B. IER-SMCEM: An Implicit Expression Recognition Model of Emojis in Social Media Comments Based on Prompt Learning. Informatics 2025, 12, 56. https://doi.org/10.3390/informatics12020056
Zhang J, Wang C, Liu Z, Deng H, Li Q, Zheng B. IER-SMCEM: An Implicit Expression Recognition Model of Emojis in Social Media Comments Based on Prompt Learning. Informatics. 2025; 12(2):56. https://doi.org/10.3390/informatics12020056
Chicago/Turabian StyleZhang, Jun, Chaobin Wang, Ziyu Liu, Hongli Deng, Qinru Li, and Bochuan Zheng. 2025. "IER-SMCEM: An Implicit Expression Recognition Model of Emojis in Social Media Comments Based on Prompt Learning" Informatics 12, no. 2: 56. https://doi.org/10.3390/informatics12020056
APA StyleZhang, J., Wang, C., Liu, Z., Deng, H., Li, Q., & Zheng, B. (2025). IER-SMCEM: An Implicit Expression Recognition Model of Emojis in Social Media Comments Based on Prompt Learning. Informatics, 12(2), 56. https://doi.org/10.3390/informatics12020056