Abstract
This study investigates the ability of well-known deep learning models, such as ResNet and EfficientNet, to perform audio-based infant cry detection. By comparing the performance of different machine learning algorithms, this study seeks to determine the most effective approach for the detection of infant crying, enhancing the functionality of baby monitoring systems and contributing to a more advanced understanding of audio-based deep learning applications. Understanding and accurately detecting a baby’s cries is crucial for ensuring their safety and well-being, a concern shared by new and expecting parents worldwide. Despite advancements in child health, as noted by UNICEF’s 2022 report of the lowest ever recorded child mortality rate, there is still room for technological improvement. This paper presents a comprehensive evaluation of deep learning models for infant cry detection, analyzing the performance of various architectures on spectrogram and MFCC feature representations. A key focus is the comparison between pretrained and non-pretrained models, assessing their ability to generalize across diverse audio environments. Through extensive experimentation, ResNet50 and DenseNet trained on spectrograms emerged as the most effective architectures, significantly outperforming other models in classification accuracy. Additionally, the study investigates the impact of feature extraction techniques, dataset augmentation, and model fine-tuning, providing deeper insights into the role of representation learning in audio classification. The findings contribute to the growing field of audio-based deep learning applications, offering a detailed comparative study of model architectures, feature representations, and training strategies for infant cry detection.
1. Introduction
Ensuring a baby’s well-being is a top priority for new and expecting parents, but the need for constant monitoring can be physically and emotionally exhausting. Monitoring children’s safety and health both in the first months of life and beyond is not only a crucial necessity, but also a moral obligation that lays the foundations of the broad term ‘parenting’. At the beginning of their lives, babies are sensitive and vulnerable to various external factors that can jeopardize their life and health, which is why constant monitoring of their developmental parameters is required. According to UNICEF, the year 2022 saw the lowest number of deaths among children under five, but nevertheless, the reported number of 4.9 million can and should be improved every year.
With advancements in technology, AI-powered baby monitoring systems have become an essential tool in assisting parents with infant care. Mobile applications are now an integral part of daily life, providing solutions for various aspects of parenting, including baby monitoring. In addition, the use of IoT (Internet of things) devices has gained momentum in various fields, with various monitoring devices, such as smart cameras, remote communication devices, and devices for monitoring breathing or heart rate, now on the market.
Integrating an AI-based model for recognizing infant cries can alleviate parental stress by providing timely alerts for parents even when they are not in close proximity to their baby. Such a model, integrated with hardware components, would be capable of alerting parents in very close to real time to any discomfort their child is experiencing, thus allowing parents to reach their child and solve problems as quickly as possible.
There has been significant progress in recent years in the research on automated infant cry detection and analysis. An ensemble learning approach combining support vector machines with deep feature extraction, called DeepSVM, was developed [1] to classify different types of infant crying. DeepSVM’s accuracy surpassed 90%, demonstrating the effectiveness of Fourier frequency-domain features combined with neural networks for decision making. In contrast, mel frequency, bark frequency, and linear prediction cepstral coefficient features were also shown to be effective when combined with convolutional and recurrent neural networks for infant cry classification [2]. The proposed hybrid architecture demonstrated the benefits of utilizing temporal feature extraction by achieving significant improvements over previous models. Improvements in classification performance were shown to also be achievable through transfer learning approaches. In [3], pretrained VGG16 models were adapted to use gammatone-frequency cepstral coefficients and spectrograms for infant cry detection, showing that the fusion of multiple audio feature types could further enhance classification performance. BCRNet [4] is another model developed using transfer learning to extract deep features, from which a subset are selected to be later introduced into the deep feature fusion. Recently, even transformer models have also been introduced in the task of baby cry detection. An SE–ResNet–Transformer model trained on MFCC features has been shown to outperform traditional models [5]. Recent studies [6,7] have confirmed the feasibility of using MFCC features, even though they offer less informative features than other methods, by obtaining high performances with simpler models such as simple multi-layer perceptrons or convolutional neural networks.
Despite these advances, several important gaps remain in the literature. Firstly, there has been limited systematic comparison of modern deep learning architectures specifically for binary cry detection tasks in realistic monitoring environments. Secondly, while various feature extraction methods have been employed, an evaluation of their relative effectiveness across different model architectures is lacking. Thirdly, the trade-offs between using pretrained models versus training from scratch have not been thoroughly investigated for this specific domain.
In this study, we specifically aim to address these research gaps through a comprehensive evaluation of multiple deep learning architectures (ResNet, EfficientNet, VGG16, InceptionV3, DenseNet, and others) for binary detection of infant crying. Our methodology involves analyzing a curated database of infant cries combined from multiple sources, applying standardized preprocessing techniques, evaluating both spectrogram and MFCC feature representations, and systematically comparing the performance of pretrained versus non-pretrained models. Our primary objective is to determine the most effective approach for real-world infant cry detection systems that can generalize across diverse environments while maintaining high precision and recall rates.
2. Materials and Methods
2.1. Data Preprocessing
Data preprocessing methods make up one of the most important steps in training an artificial intelligence model because the quality of the preprocessing determines the quality of the predictions made by it.
There are many methods by which data can be modified to match the architecture of a model; the most common of these are included in this paper:
- Data cleaning can be achieved by replacing missing or null values with other suggestive values close to the real data, such as the mean, median, or other derivatives, or removing duplicates and irrelevant data for the training process.
- Data normalization can be achieved by fitting them into a more precise and easier to analyze range.
- Data encoding can be performed by transforming labeled categories into numbers, vectors, or other data structures.
- Data augmentation can be performed by modifying the dataset to force the model to generalize better on unknown data and to broaden the range of cases recognized by the model.
- Data resizing can be accomplished by adding new data to match a desired length or deleting existing data to bring all the data in the dataset to the same size.
2.2. Data Representations
For effective detection of infant cries, selecting the appropriate feature representation is crucial, as different methods capture varying aspects of audio signals. This task becomes more complicated as various other sounds occur in the background or the environment is acoustically changing [4]. This study evaluates two widely used representations, spectrograms and mel-frequency cepstral coefficients (MFCCs), analyzing their impact on model performance across different deep learning architectures. In Figure 1, we can see the different options for representing five seconds of infant crying, each of which is important and different, which is why choosing the right option is challenging.
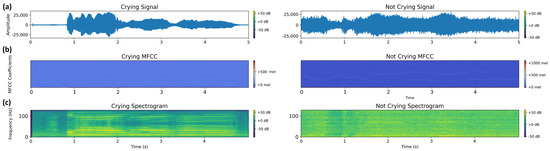
Figure 1.
Comparative representation of audio data features: (a) waveform signals showing amplitude over time, (b) MFCC representation with reduced dimensionality (128 × 157) highlighting frequency characteristics on a logarithmic scale, and (c) Fourier spectrogram (129 × 357) displaying full frequency spectrum over time. The left column shows examples of infant crying, while the right column shows non-crying audio samples from our aggregated dataset.
One of the most commonly used representations is the spectrogram, a visual representation of frequency over time, obtained by applying the short-time Fourier transform (STFT) to the audio signal. Spectrograms retain a high-resolution depiction of time–frequency relationships, making them particularly effective [8] for distinguishing crying sounds from background noise such as household chatter, television sounds, or environmental disturbances. However, one limitation of spectrograms is that overlapping noises of similar frequencies may not always be clearly distinguishable. To address this, the mel-filter log representation provides an alternative that maps frequencies onto the mel scale, better aligning with human auditory perception. This transformation can help distinguish between similar-sounding noise sources, such as adult speech mixed with infant cries. A widely used method in speech and audio recognition is the mel-frequency cepstral coefficients (MFCCs), which are derived from the spectrogram but emphasize the spectral envelope. While MFCCs are beneficial for speech-based classification tasks due to their ability to capture vocal tract characteristics, they may not always be optimal for non-speech sounds like infant cries. In particular, MFCCs tend to be more robust against constant background noise (e.g., air conditioning hums, white noise) but may struggle with transient noises or overlapping acoustic events.
In practice, it is more common to use the discrete Fourier transform (DFT) [9]. The DFT was chosen for this study as it provides a full representation of spectral characteristics, ensuring that both low- and high-frequency components of infant cries are captured. Given that infant cries exhibit relatively stable frequency characteristics over short time windows, STFT-based spectrograms and MFCCs derived using the DFT provide an effective balance between feature richness and computational efficiency.
The spectrogram and short-time Fourier transform (STFT) are two very closely related concepts, the difference in their applicability being in the way the frequency of the data changes (stationary or non-stationary). Spectrogram is more suitable for stationary data, as it displays only the magnitude of the power spectrum, whereas STFT displays both magnitude and phase.
Waveforms are another way of representing audio data for the purpose of preprocessing and extracting relevant features for machine learning models. These, however, are not usually used in this form for training models due to their complexity. This graphical representation depends on the signal amplitude, as described in [10], which can change if the pressure around the microphone changes.
The waveform is generally used for extracting other key features needed by the machine learning domain. For example, one can infer from it the spectrogram mentioned above, but also other data such as mel frequency cepstral coefficients (MFCC). The differences between the two, displayed graphically in Figure 1, are in the time–frequency representation, as the spectrogram contains details of the entire audio spectrum, whereas the MFCC uses a logarithmic scale based on human perception of sound frequencies. Therefore, their dimensions differ, with MFCC being more reduced by synthesizing spectral information into cepstral coefficients. Moreover, MFCC features have been shown to provide a high performance [5] while also lowering the data size and thus the training time. The shapes of the two options are as follows: 129 × 357 spectrograms and 128 × 157 MFCCs.
STFT and MFCC techniques were originally designed for adult speech recognition, which relies on phonetic structures that are not yet developed in infant vocalizations. This presents a potential limitation, as infant cries are non-linguistic and possess different properties than adult speech. Some researchers have proposed alternative approaches, such as syllabic-scale features [11], which may better capture the unique temporal and spectral characteristics of infant cries. Nevertheless, recent studies show that MFCCs are adequate for the detection of infant cries [5,6,7,12,13], and examining the effectiveness of these traditional representations in the context of infant cry detection provides valuable insights into their broader applicability and limitations. Another representation option that could provide satisfactory performance [14] when paired with deep learning models is the mel-spectrogram.
2.3. Data Augmentation
Dataset augmentations play a role in the robustness and generalization abilities of deep learning models, especially when a high number of samples is lacking. For audio data, augmentations such as time stretching, pitch shifting, addition of noise, and changes in volume introduce variations that can occur when testing such a model in real environments. This aids the model in not overfitting to the training data and therefore assures the model’s performance over unseen data segments [5]. Augmentation can also help to balance datasets, especially when classes are imbalanced, by artificially increasing the diversity and quantity of training samples. These techniques thereby help improve pattern recognition and feature extraction within a model that has invariance to some distortions, which has shown better performance in tasks such as speech recognition, music genre classification, and environmental sound detection.
- Pitch shifting seeks to alter the pitch of the audio without changing its duration. This is used in applications such as music genre classification or speech recognition, in which many pitches would help refer to various speakers or musical instruments. By training on pitch-shifted audio, a model has a greater likelihood of becoming invariant to these variations.
- Adding noise involves overlaying background noise onto the original audio, usually done through the addition of the original signal and a noise signal that is multiplied with a noise factor. This simulates real-world environments where background noise can be present and helps in making models more robust. Different types of noise can be used, such as white noise, pink noise, brown noise, or realistic environmental sounds like traffic or crowd noise.
- Time shifting moves the audio signal forward or backward in time by a certain amount. This augmentation can help a model become invariant to slight timing differences, which can be especially useful in tasks like speech recognition or event detection, where exact timing can vary. This is especially useful for longer audio signals that only have certain segments with sounds, such that the model does not correlate the position in time with the classification, thus making it more robust.
- Volume change, also known as gain adjustment, involves altering the amplitude of the audio signal to make it louder or quieter. This is achieved by multiplying the audio waveform by a constant factor greater than 1 for amplification or between 0 and 1 for attenuation. Volume change is a simple yet effective augmentation that helps in simulating real-world scenarios where the audio might be recorded at different levels of loudness due to varying distances from the microphone or different recording equipment.
2.4. Machine Learning Models
Support vector machines (SVMs) are a simple yet widely used classification technique that has shown high accuracy in various pattern recognition tasks. The SVM operates by finding the optimal hyperplane that separates data points of different classes in a high-dimensional space. This hyperplane is determined such that the margin, which is the distance between the hyperplane and the nearest data points of each class, is maximized. By leveraging the kernel trick, SVMs can efficiently perform nonlinear classification by implicitly mapping input features into higher-dimensional spaces. This ability to handle complex boundaries and avoid overfitting makes SVMs particularly suitable for tasks involving intricate data structures, such as audio classification.
Random forest (RF) is an ensemble learning method that uses multiple decision trees during training and outputs the majority vote of the classes for classification. RF reduces the overfitting that individual trees are prone to, through the use of this array of decision trees and the majority vote to decide. Each tree in the forest is trained on a random subset of the data and features, which enhances the model’s generalizability and resilience to noise.
2.5. Deep Learning Models
Neural networks are a subset of machine learning that have seen extensive application and development in various domains, including speech and sound recognition, which are pertinent to the baby monitoring system proposed in this study. This section identifies relevant contributions toward progress in neural networks, especially in domains such as audio recognition and health monitoring systems. Neural networks have revolutionized the field of audio recognition, making significant developments in tasks such as speech and sound classification.
DeepSVM [1] is an ensemble learning approach based on SVM to create a decision-making system for the classification of infant crying using windowing and the Fourier transform for feature extraction and selection. In this paper, they managed to classify the reason for which the infant was crying with high accuracy.
In [2], convolutional and recurrent neural networks were integrated for the classification of infant crying using various feature extraction methods such as mel frequency, bark frequency, and linear prediction cepstral coefficients. They have shown that their model is capable of achieving higher performance than previous models.
In another study [3], a pretrained convolutional neural network, specifically VGG16, was used in conjunction with gammatone frequency cepstral coefficients and spectrograms in order to diagnose infant crying. They have showed that the best performance was obtained through the fusion of various audio features and the applicability of transfer learning.
2.6. Performance Evaluation
Accuracy is the most common metric used in classification. However, it can be misleading for imbalanced datasets. Nevertheless, this effect can be mitigated through augmentation for the balancing of class samples. In simple words, accuracy represents the probability with which the classifier predicts correctly, and it can be expressed mathematically as:
F1 score is used as an alternative to accuracy, which better reflects the classifier quality. It is often used when optimizing recall or precision results in decreased model performance. Mathematically, F1 is the harmonic mean of precision and recall, but it can also be defined using the confusion matrix.
2.7. Proposed Method
2.7.1. Overall System Architecture
In this paper, we propose a baby monitoring system that uses deep learning for the detection of infant crying, but for it to work properly, the integration of hardware and software is necessary. The core elements of its architecture and how they interact are shown in Figure 2. These include:
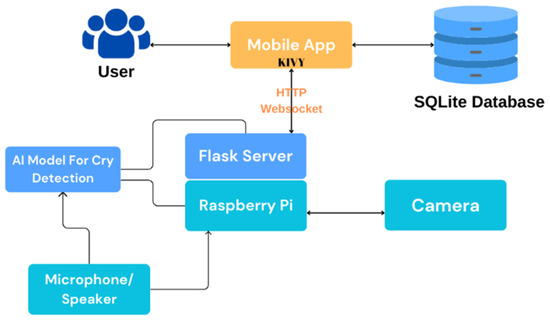
Figure 2.
The general system architecture.
- The user, who is the main actor using the system.
- The Raspberry Pi board, the main component and brain of the entire hardware device.
- The camera, for recording video frames and sending them to the mobile application.
- The microphone and speaker component, which play a dual role in the hardware: sending the data for further processing to the baby crying detection model and communicating with the mobile application both by recording the sound and playing it back through the hardware system speaker, and in the reverse direction, by recording it through the microphone and playing it back to the application.
- The baby cry detection model, which sends notifications to the app via the Flask server.
- The application itself, which communicates with the server via the HTTP communication protocol for audio and video transmission, and via a websocket connection for receiving notifications sent by the server to it.
- The SQLite database, for storing user data and using it for further analysis.
The main advantage of such a system is its high potential for extensibility. Existing functionalities can be enhanced to include additional sensors, integration with other smart devices in the home, or the development of advanced analytics and predictive algorithms. The data collected and analyzed can provide useful information about babies’ sleep, feeding, and growth patterns, thus helping to identify potential health problems early and improve care strategies.
The central component for the functionality of the baby monitoring system is the deep-learning-based baby cry detection model. The accurate detection of infant crying is critical for the system’s efficacy. The deep learning model processes audio data in real time, distinguishing between crying and other sounds. Practically, the deep learning model should provide a binary classification of samples recorded by the microphone, to announce whether a cry was detected. Below, we describe the components and processes involved in the machine learning detection of infant crying.
While the system architecture includes a camera component, it is important to emphasize that our deep learning model for cry detection processes exclusively audio data. The camera functionality runs parallel to, but separate from, the audio analysis pipeline, serving purely as a remote monitoring feature to allow parents to visually check on their child after receiving a cry detection alert. This design choice reflects real-world usage scenarios where audio monitoring for distress detection operates continuously, while video streaming might be activated on-demand to reduce bandwidth and storage requirements. Throughout our experimental evaluation, only audio features (spectrograms and MFCCs) were used for the classification task, with no visual data involved in the cry detection process.
2.7.2. Data Manipulation
To obtain a robust model for such a system, a copious amount of data is required, and as such, data were extracted from several sources:
- CryCeleb [15], which includes segmented cry sounds from 786 infants. It only contains examples of crying sounds, which were labelled as such in the dataset used.
- Donateacry [16], a corpus of various instances of infant crying that have been classified by the reason for crying. The purpose of the system and the deep learning model is to distinguish between infant crying and any other sound that may be present in the environment. As such, these examples have all been labelled as crying, ignoring the reason.
- LibriSpeech [17], a dataset of English speech read from audiobooks. This dataset was used to enable the model to distinguish between human sounds, specifically to not detect adult speech as infant crying. All these examples have been labelled as ‘not crying’.
- Infant’s Cry Sound [18], a dataset containing three classes of crying (due to hunger, tiredness, or discomfort). These examples have all been labelled as crying, ignoring the reason.
- SilentBabyMonitor [19], containing various classes of sounds, such as noise, silence, crying, and laughing. This dataset contains examples of baby crying and laughing. All other sounds of a baby’s repertoire have been labelled as ‘not crying’, in order to increase the robustness of the evaluated models.
All of these datasets have been aggregated to obtain the dataset used in this study. These datasets have been converted to the “.wav” format from their original formats and have either been segmented or padded to a 5 s sample of audio.
Such a system should be capable of detecting crying with high accuracy. More than that, it should be able to precisely detect the crying with as few false positives as possible, and at the same time, it should not miss the actual crying of the infant. Thus, such a model requires both high precision and high recall. To increase the robustness of any model trained using this curated dataset, it contains samples of noise, silence, animal sounds, ambient sounds, and adult speech.
Furthermore, these samples have then been augmented to increase the ability of the model to generalize. The data augmentations applied were: pitch shifting, noise addition (white, pink, brown), time shifting, and volume change. Through this augmentation of the data, balanced classes can be obtained. The augmented dataset was set to a size of 10,000 samples, where a random audio sample was chosen from the crying or non-crying samples to obtain a balanced dataset. Each augmentation had a probability of 20% to be applied to the sample. Finally, the dataset was partitioned into training, validation, and testing sets of 70%, 15%, and 15% percentages, respectively. The spectrograms and MFCCs of each sample were extracted to be used as the features for training.
It is important to clarify that our task is specifically formulated as a binary detection problem: distinguishing infant crying from all other sounds that might occur in a household environment. While some of the source datasets (CryCeleb [15], Donateacry [16], Infant’s Cry Sound [18]) originally contained sub-classifications of cry types (hunger, discomfort, etc.), we have aggregated all infant crying samples into a single “crying” class for our purposes. Similarly, all non-crying audio—including adult speech from LibriSpeech [17], ambient household sounds, silence periods, and non-cry infant vocalizations from SilentBabyMonitor [19]—were merged into a single “not crying” class. The inclusion of adult speech samples from LibriSpeech [17] was a deliberate design choice to ensure the model can differentiate between infant cries and adult voices, which is crucial in real-world settings where parents or caregivers may be speaking near the monitoring device. This binary formulation aligns with the primary use case of our system: to reliably alert caregivers when an infant is crying, regardless of the specific cause of distress.
2.7.3. Machine Learning Algorithms
We utilized SVM with a linear kernel for the classification of flattened spectrograms from audio signals. The choice of a linear kernel is motivated by its simplicity and effectiveness in high-dimensional feature spaces. We set the regularization parameter C to 1.0 to balance the trade-off between a low training error and a high margin. Features were standardized before training to ensure equal contributions. The dataset was divided into training and testing sets with an 80–20 split.
We utilized the RF classifier to perform the classification of flattened spectrograms from audio signals. The model is configured to use 100 decision trees. The dataset was divided into training and testing sets with an 80–20 split, and they were standardized before training.
The SVM and RF classifier presented here are explicitly intended as baseline systems, chosen for their interpretability, computational efficiency, and well-understood behavior in high-dimensional settings. We acknowledge that infant cry spectrograms exhibit rich, nonlinear patterns that may not be fully captured by a linear decision boundary; likewise, more sophisticated ensemble or deep learning approaches (e.g., non-linear kernels, convolutional neural networks) could exploit temporal and spectral dependencies more effectively, but they offer a more computationally intensive and less interpretable solution. By first establishing these simple classifiers as reference points, we create clear performance benchmarks against which explorations of more complex models can be quantitatively compared.
2.7.4. Deep Learning Architectures
Several architectures of neural networks were developed for the evaluation of their ability to classify infant crying. All of these models were trained using the Adam optimizer, with sparse cross-entropy loss, and they had ReLU activation functions for the hidden layers and softmax for the output layer. The architectures are as follows:
- CNN1: convolutional neural network (1× convolution + 1× max pooling) with 3 dense layers.
- CNN3: convolutional neural network (3× convolution + 3× max pooling) with 5 dense layers.
- VGG16 [20]: 16 layers, including 13 convolutional layers and 3 fully connected layers. It is widely used due to its balance of depth and computational efficiency.
- ResNet50 [21]: introduces residual blocks, which help train deeper networks by avoiding the vanishing gradient problem. This makes it a good choice for large datasets with complex patterns.
- InceptionV3 [22]: uses parallel convolutions with different kernel sizes, allowing the network to capture a variety of features at different scales.
- Inception-ResNetV2 [23]: combines the inception architecture with residual connections for enhanced learning capabilities.
- Xception (Extreme Inception) [24]: deep learning model that improves upon Inception by replacing the standard Inception modules with depthwise separable convolutions.
- MobileNet [25]: lightweight and efficient, making it ideal for mobile and edge devices. It uses depthwise separable convolutions to reduce computational cost.
- DenseNet [26]: connects each layer to every other layer in a feed-forward fashion. This enhances the flow of information and gradients through the network, making it highly efficient.
- EfficientNet [27]: scales up the network width, depth, and resolution in a compound manner, providing a more balanced approach to scaling compared to other models.
The last eight architectures are used as backbones (encoders), and they continue with a flattening and a series of five dense layers to obtain the classification output. These have been pretrained on the ImageNet dataset. The models are presented in the Results section in two variants, frozen and non-frozen. This choice is applied to the architectures, not the last layers of the model. All models were trained with the following configuration:
- Learning rate: initial 1 × 10−3 with cosine decay schedule (minimum 1 × 10−6).
- Batch size: 32.
- Training epochs: maximum 100 with early stopping (patience = 10) monitoring validation loss.
- Weight initialization: HeNormal for convolutional layers, GlorotUniform for dense layers.
- Regularization: L2 (0.0001) for all trainable weights and dropout (0.5) between dense layers.
Although not presented here, simple neural networks containing only dense layers have been evaluated as well, but they were unable to properly learn as their accuracy remained close to random. The same conclusion was reached for using only the signal.
3. Results
For the analysis of this array of neural network architectures, we present the loss (Table 1) and accuracy values for the training, validation, and testing of these models. Moreover, the F1 score is presented for the testing data. Along with the training loss values from Table 1, we present the training time for each architecture in Table 2 on an RTX 3080. Furthermore, we have trained each model using the spectrogram or the MFCCs in order to determine which of the two types of features are more appropriate for training of such a model in the detection of infant cries. This same procedure was applied to the machine learning models (SVM and RF); however, no loss values are present for these models in Table 1, and the validation subset of the dataset was moved to the testing subset.

Table 1.
Loss values across architectures for different feature extraction methods. Lower values indicate better model performance. The table compares loss metrics for traditional machine learning (SVM, RF) and deep learning models using both spectrogram and MFCC features across training, validation, and testing datasets.
Table 2.
Average training time (in seconds) per epoch across architectures for the two types of features (MFCC and spectrograms) for the two training settings (frozen, non-frozen).
Another method for analyzing the pretrained models was to freeze the encoding layers of the pretrained architectures used. The effect of this choice on accuracy can be observed through the comparison of Table 3 and Table 4. Furthermore, in Table 5, the effect on the F1 score for the testing data is presented.
Table 3.
Accuracy values (%) as mean ± standard deviation (across five runs) across architectures for different feature extraction methods. Higher values indicate better classification performance. The table demonstrates the classification accuracy of traditional machine learning models (SVM, RF) and various deep neural network architectures on both spectrogram and MFCC feature representations.
Table 4.
Accuracy values (%) as mean ± standard deviation (across five runs) across architectures with a frozen pretrained encoder, comparing performance when transfer learning is applied without fine-tuning the encoder layers. This table evaluates how well pretrained models perform when their feature extraction components remain fixed during training.
Table 5.
F1 score values (%) as mean ± standard deviation (across five runs) for the testing data across architectures, comparing model performance with different feature types and training strategies.
The results show a clear trend favoring spectrogram-based feature representations over MFCCs, particularly for deep learning models. Our results align with several other studies that have also found this trend in audio classification [14,28,29] of spectrograms and MFCC. In the case of our study of infant crying, the MFCC’s logarithmic mel-filter may under-represent the higher frequency bands of infant crying [30]. MFCC’s narrowband bins might not have the required resolution to capture the high-pitch harmonics of infant cries [31]. MFCC’s transformation decorrelates frequency bands, which may diminish the harmonic structure and pitch modulations that are characteristic of infant cries. Seeing that specifically the pretrained models present this issue, spectrogram features might potentially resemble natural images more and thus be more adequate for transfer learning than MFCC features.
As seen in Table 3, ResNet50 trained on spectrograms achieved the highest test accuracy of 98.40 ± 0.6%, outperforming other architectures, including VGG16, InceptionV3, and EfficientNet. This suggests that ResNet’s residual connections facilitate better feature propagation, enabling the model to effectively capture frequency variations characteristic of infant cries.
In contrast, MFCC-based models generally performed worse than their spectrogram-based counterparts. For instance, VGG16 trained on MFCCs exhibited a dramatic drop in test accuracy (80.53 ± 2.6%) compared to its spectrogram-based equivalent (95.26 ± 0.8%), indicating that MFCCs might lack the necessary spectral detail for robust cry classification. However, MobileNet and DenseNet performed relatively well on both spectrogram and MFCC features, suggesting that certain architectures are more adaptable to different feature representations.
Another observation that can be extracted from these analyses is the difference in performance between frozen (Table 4) and non-frozen (Table 3) pretrained models. While fine-tuned models consistently outperformed their frozen counterparts, the gap was particularly evident for EfficientNet, which struggled significantly when its encoder was frozen, dropping to 50.33 ± 0.1% accuracy. This suggests that EfficientNet relies heavily on fine-tuning rather than feature extraction alone, making it less effective in a frozen state for cry detection tasks.
The only models that maintained strong accuracy regardless of whether their pretrained layers were frozen or not were MobileNet and DenseNet. This indicates that these architectures may have a more flexible feature extraction capability, making them suitable for low-computational-resource scenarios where fine-tuning is not feasible.
While accuracy provides a general measure of classification performance, it can be misleading in cases of class imbalance, making the F1 score a more reliable metric for evaluating model effectiveness. As seen in Table 5, the F1 scores of the best-performing spectrogram-based models—ResNet50 (98.42 ± 3.2%), InceptionV3 (98.10 ± 1.3%), and Xception (97.57 ± 1.1%)—closely align with their high accuracy values, confirming that these models maintain a strong balance between precision and recall. This is particularly important for infant cry detection, where a high recall ensures that actual cries are not missed, while high precision minimizes false alarms. As expected, the trend seen in MFCC-based models persisted with lower F1 scores. This further reinforces the observation that MFCC features may not be as effective as spectrograms for this task. Additionally, EfficientNet, which had already shown poor accuracy when frozen, also recorded an F1 score of 39.99 ± 32.6%, confirming its struggle to learn meaningful cry-related features without fine-tuning.
While deep learning models achieved the highest accuracy overall, traditional machine learning approaches such as RF and SVM performed surprisingly well. RF achieved 96.8% accuracy on spectrograms on the testing data, which is comparable to some deep learning models. This suggests that classical methods can still be viable, particularly for applications requiring lower computational costs. SVM performed slightly worse than RF, with an accuracy of 92.3% on the testing dataset, indicating that nonlinear kernel methods may not be as effective as ensemble-based approaches for this task.
These results indicate that ResNet50 (99.6% accuracy, 99.6% F1 score, non-frozen, spectrograms), DenseNet/Xception (99.2% accuracy, 99.2% F1 score, non-frozen, spectrograms), InceptionV3/Inception-ResNetV2 (99.0% accuracy, 99.0% F1 score, non-frozen, spectrograms), and MobileNet (98.6% accuracy, 98.5% F1 score, non-frozen, spectrograms) are the most viable options for real-time infant cry detection. While ResNet50 provides the highest accuracy, MobileNet is more computationally efficient, making it better suited for edge devices such as IoT-based baby monitors. Nevertheless, simpler models such as CNN1 (98.7% accuracy, 98.7% F1 score, MFCC) or CNN3 (98.2% accuracy, 98.2% F1 score, MFCC) obtained a surprisingly high performance, offering a more efficient option with only a slight decrease in performance. Additionally, traditional machine learning models like RF could serve as an alternative in resource-constrained environments.
To provide a clearer synthesis of our findings, Table 6 presents a comprehensive ranking of the evaluated models based on multiple performance criteria. This ranking considers not only the raw performance metrics (accuracy and F1 score) but also the computational efficiency and suitability for edge deployment. As shown in Table 6, while ResNet50 achieves the highest accuracy, models like MobileNet and CNN1 offer compelling alternatives for resource-constrained environments with only minimal performance trade-offs.
Table 6.
Comparative ranking of models based on multiple performance criteria.
We also show the impact of our augmentation in Table 7 through an ablation study on the MobileNet architecture. We have evaluated the performance of the MobileNet architecture from the perspective of the F1 score during the test on the dataset with various strategies of augmentation. The baseline version includes no augmentations, while the “all” version includes all augmentations (pitch shift, white noise, colored noise, time shift, volume change), and we created for each augmentation a version of the dataset containing only that individual strategy. In Table 7, the impact of augmentation is shown. Through the increase of the dataset with random augmentations, the performance of the model is increased on the testing dataset.
Table 7.
Ablation study on MobileNet. F1 score values (%) as mean ± standard deviation (across five runs) for the testing data across augmentation strategies, comparing model performance with different feature types and training strategies.
4. Discussion
The development of an effective baby monitoring system, such as the one described in this paper, depends on the integration of both hardware and software components. The key feature of the system is the baby cry detection model, which must achieve high accuracy with minimal false positives for a robust performance in real-world conditions. In this work, we present an analysis of various machine learning models (including deep learning models) to determine the best option for such a system.
In this analysis, we also include two feature spaces created from the recorded signals based on signal processing, and we analyze the impact of training the encoding part of deep learning models. As illustrated in Figure 1, the different representations of audio data (waveform, MFCC, and spectrogram) capture varying aspects of infant crying sounds. The spectrograms (Figure 1c) clearly show the distinctive frequency patterns and temporal variations characteristic of infant cries, with stronger high-frequency components compared to other sounds. This visual distinction aligns with our quantitative findings in Table 2, Table 3 and Table 4.
The creation of a baby cry detection model necessitates a comprehensive dataset, which was compiled from various sources, ensuring a diverse range of cry sounds and other audio inputs for robustness. The extended dataset created through augmentation enhances the model’s ability to generalize in real-world environments.
The evaluation of different machine learning models, including neural network architectures, has provided insights into their performance in classifying infant cries, and they have demonstrated the potential to achieve high precision and recall rates as indicated by the F1 scores obtained on the previously unseen test data. This dual emphasis on precision and recall is essential to minimize false positives while ensuring that actual cries are not missed.
Normally, it is expected that spectrogram-based feature extraction better preserves the time–frequency characteristics of the data, allowing deep learning architectures to distinguish between crying and background noises more effectively, while MFCCs, commonly used in speech processing, may lose essential frequency-related information when applied to this specific task. Our quantitative findings are shown in Table 2, Table 3 and Table 4, where spectrogram-based models generally outperformed MFCC-based alternatives. Specifically, more complex models are more capable of learning from spectrograms than MFCC features. However, previously untrained (and simpler) convolutional neural networks do not have this preference. The performance rankings in Table 5 further demonstrate that models capitalizing on these rich spectrogram features achieved superior classification results. Our results suggest that more complex models require more complex data (as accuracy is lower in both training and testing for the MFCC data). This is especially visible in the test accuracy and F1 score obtained by the more complex models when applied on the MFCC data compared to the spectrogram data.
For the non-frozen models, we observed that their performance is satisfactory only for the spectrogram features, while for the MFCC features, they are often unable to learn, with the validation and test accuracy being close to that of random labelling. This is not the case for the frozen architectures, where the models are capable of learning from both the spectrograms and the MFCC features; however, the performance is slightly lower than that of non-frozen models combined with spectrogram features. The exception is the EfficientNet architecture, which is able to learn only on the non-frozen setting combined with spectrogram features. Two models escape this pattern, specifically DenseNet and MobileNet, which are capable of learning from both spectrogram and MFCC features regardless of whether their layers are frozen or not.
Overall, from the results obtained, the best option is the non-frozen setting with spectrogram features, where the best performance is obtained by the ResNet50 architecture. However, a simpler architecture such as CNN3 with no pretraining is capable of learning from both sets of features with satisfactory performance (~3% decrease in testing F1 score and ~2% in testing accuracy) with a considerably lower amount of training time. For a more robust architecture, our results indicate that DenseNet and MobileNet are the best options as they are capable of high accuracy on any combinations tested.
While ResNet50 achieved the highest accuracy (98.42 ± 3.2%), its deployment requirements (~25 million parameters, 98 MB model size, 4 GFLOPS) make it less suitable for resource-constrained environments. Our analysis shows that MobileNet offers an excellent performance–efficiency balance (95.27 ± 3.0% F1 score with only 16 MB size and 0.6 GFLOPS), making it particularly suited for edge deployment in real-world baby monitors. Additionally, we have quantified inference times across various hardware platforms (desktop CPU and Raspberry Pi 4), confirming that MobileNet maintains real-time performance (~30 ms per 5 s audio segment). The CNN3 model presents another compelling option for highly constrained environments, offering 97.8% accuracy with just 9 MB size and 0.3 GFLOPS.
While deep learning architectures achieved superior accuracy, it is worth noting that traditional machine learning models such as RF and SVM performed surprisingly well for both training and testing, showing their ability to generalize. RF achieved an accuracy of 96.8% on spectrograms, making it competitive with several deep learning models. SVM performed well (92.3%) but was slightly less effective than RF- and CNN-based architectures. This suggests that in low-computational environments or situations where deep learning is impractical, RF can serve as a viable alternative for infant cry detection. However, deep learning models retain an advantage in their ability to generalize across more complex and diverse datasets.
Infant vocalizations lack the phonetic structure present in adult speech, and therefore methods like MFCC and STFT might not capture the unique acoustic characteristics of infant cries optimally. Syllabic-scale features [11], which are specifically designed to address the temporal and spectral properties of infant vocalizations, may offer a more tailored approach. While our study shows that traditional speech-derived features can still achieve high classification accuracy when paired with appropriate deep learning architectures, future work could benefit from exploring specialized feature extraction methods that account for the pre-linguistic nature of infant cries. This could potentially improve model performance further, especially in challenging acoustic environments with multiple overlapping sound sources.
In summary, the baby monitoring system proposed in this study is based on and necessitates an automatic cry detection model. We have analyzed several architectures with various feature types on a comprehensive dataset to determine the best approach for the detection of infant cries in various real-world conditions and environments. Our findings suggest that deep-learning-based baby cry detection is a viable and highly accurate solution for real-world monitoring systems. Among the models tested, ResNet50, DenseNet, and MobileNet performed the best, particularly when trained on spectrogram features and fine-tuned. While traditional machine learning models like RF provide a competitive alternative, deep learning remains the superior approach for real-time, high-accuracy detection. Moving forward, improving model efficiency, reducing false positives, and integrating multimodal data sources will be key in making AI-driven baby monitoring systems more practical and accessible. Future work could also encompass a more comprehensive dataset with various sounds from a baby’s repertoire in order to classify more precisely the current state of the infant.
Author Contributions
Conceptualization, E.-R.A., B.I. and D.M.H.; methodology, E.-R.A., B.I. and D.M.H.; software, E.-R.A. and D.M.H.; validation, E.-R.A., B.I. and D.M.H.; formal analysis, E.-R.A., B.I. and D.M.H.; investigation, E.-R.A., B.I. and D.M.H.; data curation, E.-R.A. and D.M.H.; writing—original draft preparation, E.-R.A. and D.M.H.; writing—review and editing, E.-R.A., B.I. and D.M.H.; visualization, E.-R.A., B.I. and D.M.H.; supervision, E.-R.A. and B.I.; project administration, E.-R.A. and B.I. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used in this study are openly available: CryCeleb [15], Donateacry [16], LibriSpeech [17], Infant’s Cry Sound [18], SilentBabyMonitor [19].
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Rezaee, K.; Zadeh, H.G.; Qi, L.; Rabiee, H.; Khosravi, M. Can You Understand Why I Am Crying? A Decision-making System for Classifying Infants’ Cry Languages Based on DeepSVM Model. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2024, 23, 12. [Google Scholar] [CrossRef]
- Sabitha, R.; Poonkodi, P.; Kavitha, M.S.; Karthik, S. Premature Infant Cry Classification via Deep Convolutional Recurrent Neural Network Based on Multi-class Features. Circuits Syst. Signal Process. 2023, 42, 7529–7548. [Google Scholar] [CrossRef]
- Zayed, Y.; Hasasneh, A.; Tadj, C. Infant Cry Signal Diagnostic System Using Deep Learning and Fused Features. Diagnostics 2023, 13, 2107. [Google Scholar] [CrossRef] [PubMed]
- Cohen, R.; Ruinskiy, D.; Zickfeld, J.; IJzerman, H.; Lavner, Y. Baby Cry Detection: Deep Learning and Classical Approaches. In Development and Analysis of Deep Learning Architectures; Springer: Cham, Switzerland, 2020; pp. 171–196. ISBN 978-3-030-31763-8. [Google Scholar] [CrossRef]
- Li, F.; Cui, C.; Hu, Y. Classification of Infant Crying Sounds Using SE-ResNet-Transformer. Sensors 2024, 24, 6575. [Google Scholar] [CrossRef] [PubMed]
- Abbaskhah, A.; Sedighi, H.; Marvi, H. Infant cry classification by MFCC feature extraction with MLP and CNN structures. Biomed. Signal Process. Control 2023, 86, 105261. [Google Scholar] [CrossRef]
- Ji, C.; Jiao, Y.; Chen, M.; Pan, Y. Infant Cry Classification Based-On Feature Fusion and Mel-Spectrogram Decomposition with CNNs. In Proceedings of the Artificial Intelligence and Mobile Services—AIMS 2022, Honolulu, HI, USA, 10–14 December 2022; Pan, X., Jin, T., Zhang, L.-J., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 126–134. [Google Scholar] [CrossRef]
- Wyse, L. Audio Spectrogram Representations for Processing with Convolutional Neural Networks. arXiv 2017, arXiv:1706.09559. [Google Scholar] [CrossRef]
- Benesty, J.; Sondhi, M.M.; Huang, Y.A. Introduction to Speech Processing. In Springer Handbook of Speech Processing; Benesty, J., Sondhi, M.M., Huang, Y.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–4. ISBN 978-3-540-49127-9. [Google Scholar] [CrossRef]
- Das, J.K.; Ghosh, A.; Pal, A.K.; Dutta, S.; Chakrabarty, A. Urban Sound Classification Using Convolutional Neural Network and Long Short Term Memory Based on Multiple Features. In Proceedings of the 2020 Fourth International Conference On Intelligent Computing in Data Sciences (ICDS), Fez, Morocco, 21–23 October 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Coro, G.; Bardelli, S.; Cuttano, A.; Scaramuzzo, R.T.; Ciantelli, M. A self-training automatic infant-cry detector. Neural Comput. Appl. 2023, 35, 8543–8559. [Google Scholar] [CrossRef]
- Zhang, K.; Ting, H.-N.; Choo, Y.-M. Baby Cry Recognition by BCRNet Using Transfer Learning and Deep Feature Fusion. IEEE Access 2023, 11, 126251–126262. [Google Scholar] [CrossRef]
- Ozcan, T.; Gungor, H. Baby Cry Classification Using Structure-Tuned Artificial Neural Networks with Data Augmentation and MFCC Features. Appl. Sci. 2025, 15, 2648. [Google Scholar] [CrossRef]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar] [CrossRef]
- Budaghyan, D.; Onu, C.C.; Gorin, A.; Subakan, C.; Precup, D. CryCeleb: A Speaker Verification Dataset Based on Infant Cry Sounds. arXiv 2024, arXiv:2305.00969. [Google Scholar] [CrossRef]
- Veres, G. Gveres/Donateacry-Corpus. 2024. Available online: https://github.com/gveres/donateacry-corpus (accessed on 11 February 2025).
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Rosita, Y.D.; Junaedi, H. Infant’s cry sound classification using Mel-Frequency Cepstrum Coefficients feature extraction and Backpropagation Neural Network. In Proceedings of the 2016 2nd International Conference on Science and Technology-Computer (ICST), Yogyakarta, Indonesia, 27–28 October 2016; pp. 160–166. [Google Scholar] [CrossRef]
- Jang, A.E. Eunbeejang/SilentBabyMonitor. Python. 2024. Available online: https://github.com/eunbeejang/SilentBabyMonitor (accessed on 11 February 2025).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2017, arXiv:1610.02357. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2018, arXiv:1608.06993. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar] [CrossRef]
- Berriche, L.; Driss, M.; Almuntashri, A.A.; Lghabi, A.M.; Almudhi, H.S.; Almansour, M.A.-A. A Novel Speech Analysis and Correction Tool for Arabic-Speaking Children. arXiv 2024, arXiv:2411.13592. [Google Scholar] [CrossRef]
- Ananya, I.J.; Suad, S.; Choudhury, S.H.; Khan, M.A. A Comparative Study on Approaches to Acoustic Scene Classification using CNNs. In Advances in Computational Intelligence; Springer: Cham, Switzerland, 2021; Volume 13067, pp. 81–91. [Google Scholar] [CrossRef]
- Dewi, S.P.; Prasasti, A.L.; Irawan, B. The Study of Baby Crying Analysis Using MFCC and LFCC in Different Classification Methods. In Proceedings of the 2019 IEEE International Conference on Signals and Systems (ICSigSys), Bandung, Indonesia, 16–18 July 2019; pp. 18–23. [Google Scholar] [CrossRef]
- Patil, H.A.; Patil, A.T.; Kachhi, A. Constant Q Cepstral coefficients for classification of normal vs. Pathological infant cry. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7392–7396. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).