_Bryant.png)
Audio Watermarking System in Real-Time Applications


Abstract
:1. Introduction
- Copyright protection: The watermark can identify ownership of an audio signal and prevent unauthorized actions, such as copying, playback, or tampering.
- Authentication: In this application, the embedded information verifies the legitimacy of the audio signal after distribution.
- Content identification and management: In scenarios where large volumes of content require automation, the watermark identifies and manages audio signals.
- Monitoring: Watermarking facilitates the retrieval of information while sharing audio signals.
- Second screen: The embedded information is used by another device for various purposes.
- This work proposes a system designed to be implemented in a live audio watermarking signal, where knowing a priori the host signal is unnecessary. The watermark embedding is additive in the time domain, using a spread spectrum (SS) technique and a low buffer size. The system achieves acceptable performance values, according to [4].
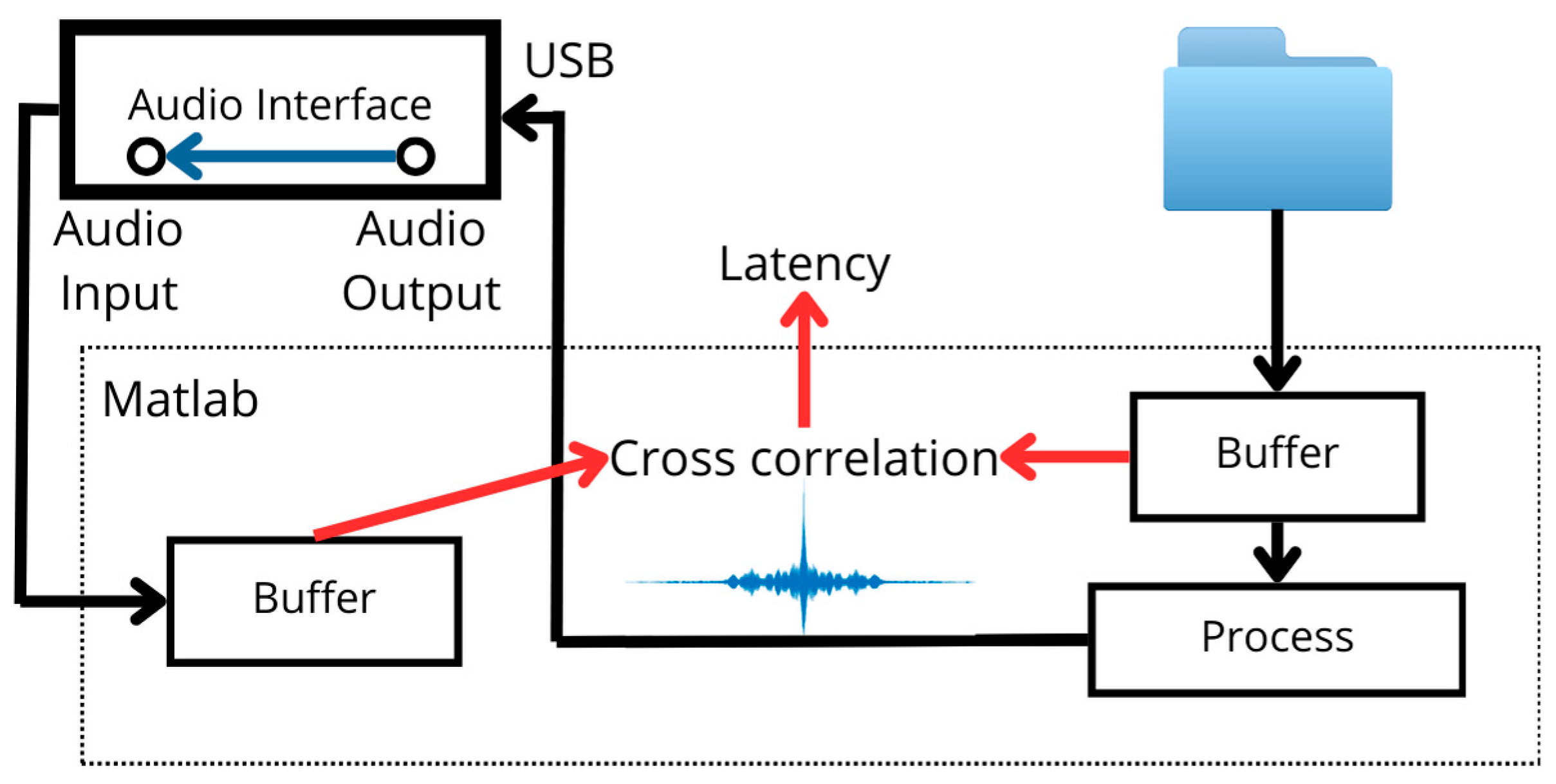
- Two methods are used to measure latency: The first modifies the loop-based approach in [9], while the second utilizes an oscilloscope and an external audio source. In both scenarios, the results show that the embedding process does not introduce a measurable latency.
2. Literature Review
3. Description of the Primary System
- Convolutional codification.
- SS modulation and demodulation.
- Gain modulation.
- Wiener filtering.
3.1. Convolutional Codification
3.2. SS Modulation and Demodulation
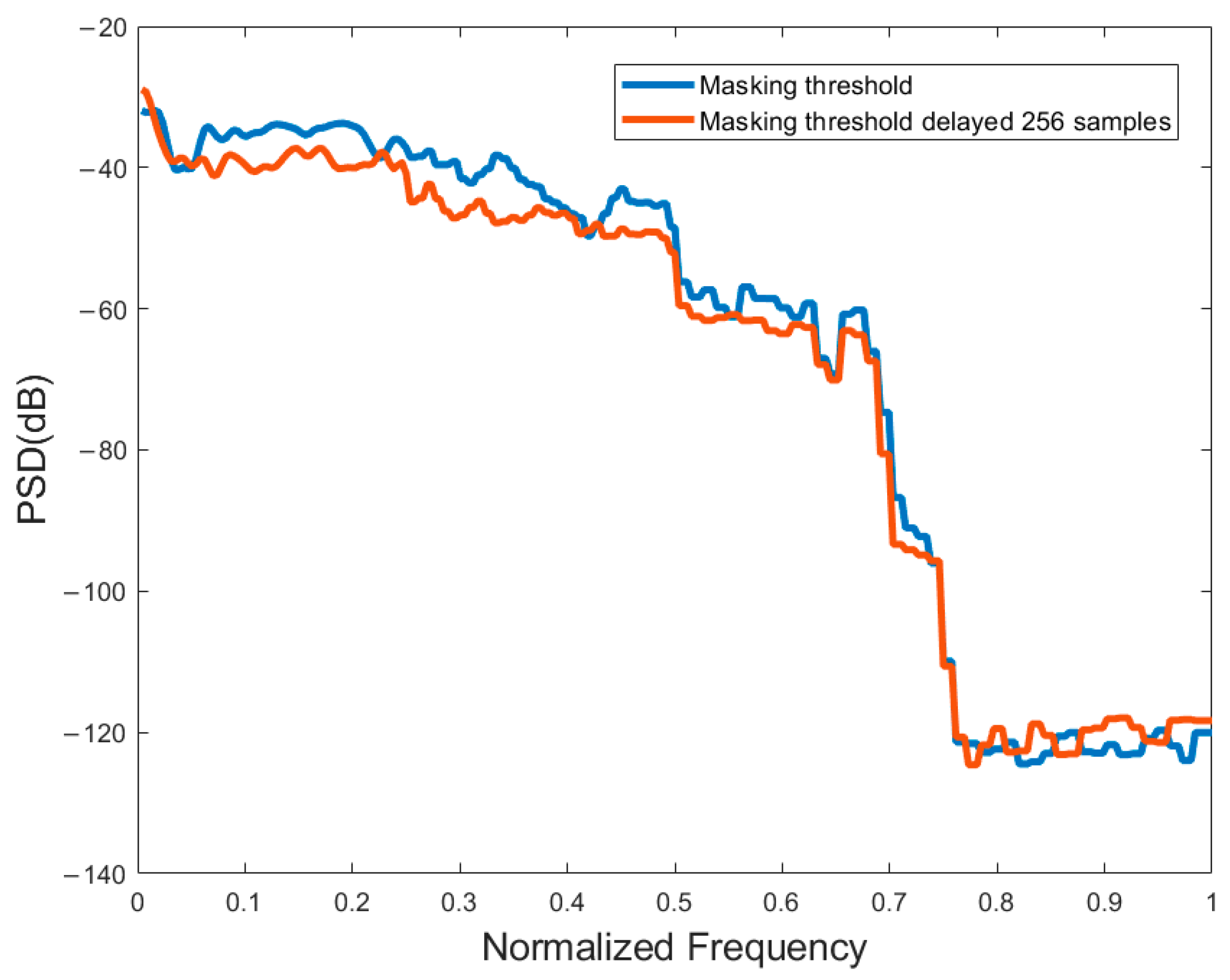
3.3. Gain Modulation
3.3.1. All-Pole Filter
3.3.2. Wiener Filter
4. System Working with Live Audio
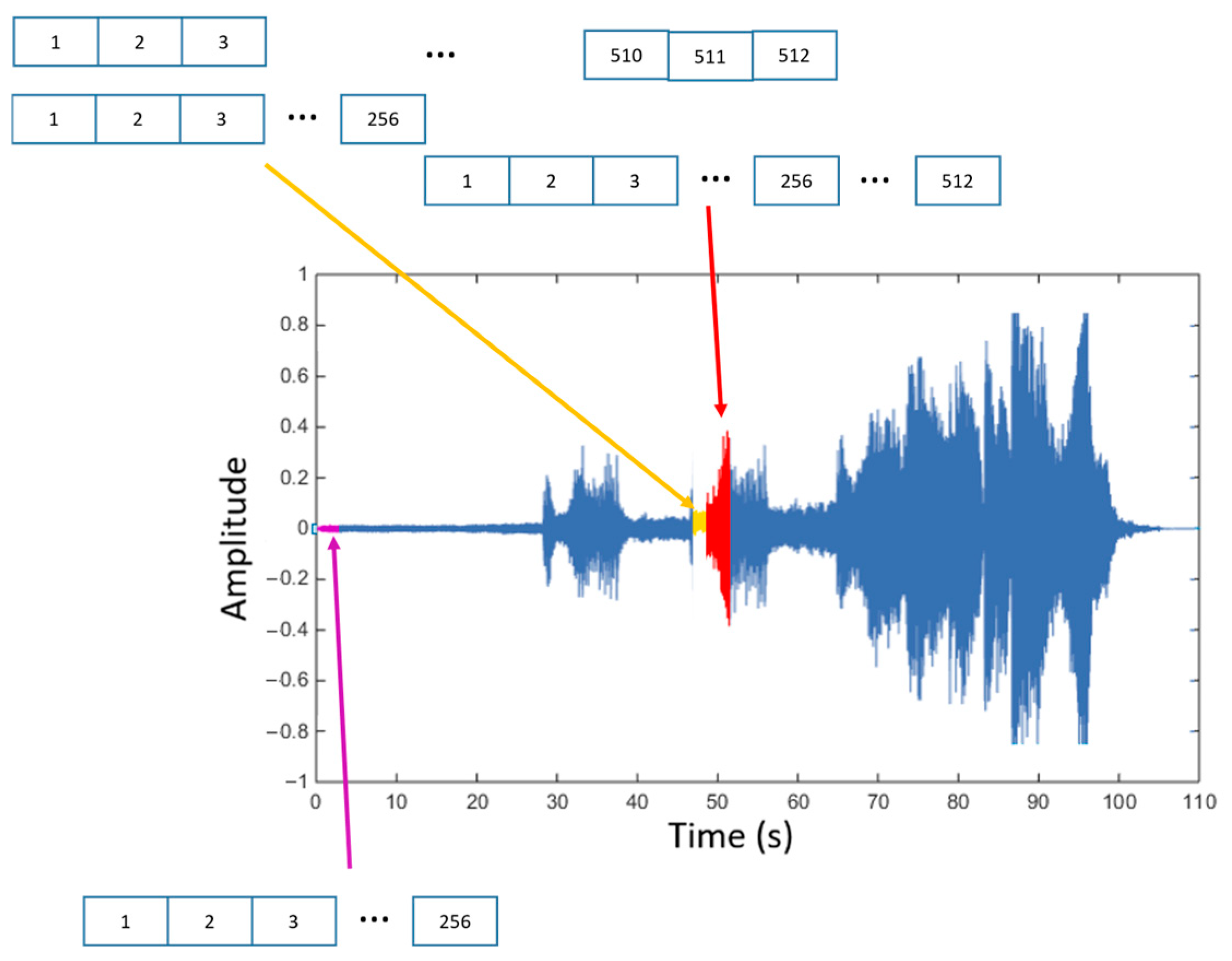
4.1. Working with Two Different Buffer Sizes
4.2. Real-Time Test
5. Comparison of Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nematollahi, M.A.; Vorakulpipat, C.; Rosales, H.G. Digital Watermarking Techniques and Trends, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Lin, Y.; Abdulla, W.H. Audio Watermark: A Comprehensive Foundation Using MATLAB; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Bajpai, J.; Kaur, A. A literature survey—various audio watermarking techniques and their challenges. In Proceedings of the 2016 6th International Conference—Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 451–457. [Google Scholar]
- Pourhashemi, S.M.; Mosleh, M.; Erfani, Y. A novel audio watermarking scheme using ensemble-based watermark detector and discrete wavelet transform. Neural Comput. Appl. 2021, 33, 6161–6181. [Google Scholar] [CrossRef]
- Hua, G.; Huang, J.; Shi, Y.Q.; Goh, J.; Thing, V.L.L. Twenty years of digital audio watermarking—A comprehensive review. Signal Process. 2016, 128, 222–242. [Google Scholar] [CrossRef]
- Yong, X.; Hua, G.; Yan, B. Digital Audio Watermarking: Fundamentals, Techniques and Challenges; Springer: Gateway East, Singapore, 2017. [Google Scholar]
- Moscatelli, R.; Stahel, K.; Kraneis, R.; Werner, C. Why real-time matters: Performance evaluation of recent ultra-low latency audio communication systems. In Proceedings of the 2024 IEEE 21st Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 6–9 January 2024; pp. 77–83. [Google Scholar]
- Rottondi, C.; Chafe, C.; Allocchio, C.; Sarti, A. An overview on networked music performance technologies. IEEE Access 2016, 4, 8823–8843. [Google Scholar] [CrossRef]
- Measure Audio Latency. MathWorks. Available online: https://www.mathworks.com/help/audio/ug/measure-audio-latency.html (accessed on 11 May 2022).
- Hu, H.-T.; Chang, J.-R.; Lin, S.-J. Synchronous blind audio watermarking via shape configuration of sorted LWT coefficient magnitudes. Signal Process. 2018, 147, 190–202. [Google Scholar] [CrossRef]
- Wu, Q.; Ding, R.; Wei, J. Audio watermarking algorithm with a synchronization mechanism based on spectrum distribution. Secur. Commun. Netw. 2022, 2022, 2617107. [Google Scholar] [CrossRef]
- Pourhashemi, S.M.; Mosleh, M.; Erfani, Y. Audio watermarking based on synergy between Lucas regular sequence and Fast Fourier Transform. Multimed. Tools Appl. 2019, 78, 22883–22908. [Google Scholar] [CrossRef]
- Wang, S.; Yuan, W.; Unoki, M. Multi-subspace echo hiding based on time-frequency similarities of audio signals. IEEE ACM Trans. Audio Speech Lang. Process. 2020, 28, 2349–2363. [Google Scholar] [CrossRef]
- Erfani, Y.; Pichevar, R.; Rouat, J. Audio watermarking using spikegram and a two-dictionary approach. IEEE Trans. Inf. Forensics Secur. 2017, 12, 840–852. [Google Scholar] [CrossRef]
- Su, Z.; Zhang, G.; Yue, F.; Chang, L.; Jiang, J.; Yao, X. SNR-constrained heuristics for optimizing the scaling parameter of robust audio watermarking. IEEE Trans. Multimed. 2018, 20, 2631–2644. [Google Scholar] [CrossRef]
- Elshazly, R.; Nasr, M.E.; Fouad, M.M.; Abdel-Samie, F.E. Intelligent high payload audio watermarking algorithm using color image in DWT-SVD domain. J. Phys. Conf. Ser. 2021, 2128, 012019. [Google Scholar] [CrossRef]
- Suresh, G.; Narla, V.L.; Gangwar, D.P.; Sahu, A.K. False-Positive-Free SVD based audio watermarking with integer wavelet transform. Circuits Syst. 2022, 41, 5108–5133. [Google Scholar] [CrossRef]
- Zhao, J.; Zong, T.; Xiang, Y.; Gao, L.; Hua, G.; Sood, K.; Zhang, Y. SSVS-SSVD based desynchronization attacks resilient watermarking method for stereo signals. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 448–461. [Google Scholar] [CrossRef]
- Yamni, M.; Daoui, A.; Karmouni, H.; Sayyouri, M.; Qjidaa, H.; Motahhir, S.; Aly, M.H. An efficient watermarking algorithm for digital audio data in security applications. Sci. Rep. 2023, 13, 18432. [Google Scholar] [CrossRef] [PubMed]
- Nita, V.A.; Stanomir, D. Real-time temporal audio watermarking for mobile communication. In Proceedings of the 2020 13th International Conference on Communications (COMM), Bucharest, Romania, 18–20 June 2020; pp. 81–84. [Google Scholar]
- Haridas, T.; Upasana, S.D.; Vyshnavi, G.; Krishnan, M.S.; Muni, S.S. Chaos-based audio encryption: Efficacy of 2D and 3D hyperchaotic systems. Frankl. Open 2024, 8, 100158. [Google Scholar] [CrossRef]
- Cruz, C.J.S.; Dolecek, G.J. Exploring performance of a spread spectrum-based audio watermarking system using convolutional coding. In Proceedings of the 2021 IEEE URUCON, Montevideo, Uruguay, 24–26 November 2021; pp. 104–107. [Google Scholar]
- Sklar, B. Digital Communications, Fundamentals, and Applications; Prentice Hall: Upper Saddle River, NJ, USA, 2001. [Google Scholar]
- ISO/IEC 11172-3:1993; Coding of Moving Pictures and Associated Audio for Digital Storage Media at Up to About 1,5 Mbit/s—Part 3: Audio. ISO/IEC: Geneva, Switzerland, 1993.
- Dutoit, T.; Marqu, F. How could music contain hidden information? In Applied Signal Processing: A MATLAB-Based Proof of Concept; Springer: New York, NY, USA, 2009; pp. 223–262. [Google Scholar]
- ITU-T, R. Methods for Objective Measurements of Perceived Audio Quality; International Telecommunication Union: Geneva, Switzerland, 2001; Volume 1387-1, p. 100. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Host Signal | Capacity (BPS) | Samples Used | ODG | BER |
|---|---|---|---|---|
| Classical | 78.75 | 512 | −0.471 | 0 |
| 256 | −0.501 | 0 | ||
| 110.25 | 512 | −0.921 | 0 | |
| 256 | −0.921 | 0 | ||
| Jazz | 78.75 | 512 | −0.530 | 0 |
| 256 | −0.530 | 0 | ||
| 110.25 | 512 | −0.561 | 0 | |
| 256 | −0.749 | 0 | ||
| Pop | 78.75 | 512 | −0.398 | 0 |
| 256 | −0.539 | 0 | ||
| 110.25 | 512 | −0.451 | 0 | |
| 256 | −0.468 | 0 | ||
| Rock | 78.75 | 512 | −0.161 | 0 |
| 256 | −0.161 | 0 | ||
| 110.25 | 512 | −0.194 | 0 | |
| 256 | −0.194 | 0 |
| Method | Buffer Size (Samples) | Watermarking | Latency (ms) | Standard Deviation (ms) |
|---|---|---|---|---|
| 1 | 512 | No | 30.08 | 0 |
| Yes | 30.61 | 0 | ||
| 256 | No | 22.63 | 0 | |
| Yes | 22.63 | 0 | ||
| 2 | 512 | No | 114.867 | 9.799 |
| Yes | 117.68 | 3.44 | ||
| 256 | No | 97.29 | 0.99 | |
| Yes | 98.36 | 1.03 |
| Reference | Imperceptibility (ODG) | Capacity (bps) | Robustness to MP3 (BER) | Security |
|---|---|---|---|---|
| [4] | −0.354 | 1225 | 0 | NR |
| [9] | −0.56 | 86.13 | 0.08 | Yes |
| [10] | −0.45 | 64 | 0.007 | NR |
| [11] | −0.915 | 1000–8000 | 0.019 | NR |
| [12] | −0.902 | 4–128 | NR | Yes |
| [13] | −0.44 | 177 | 0 | Yes |
| [14] | −0.6422 | NR | NR | Yes |
| [15] | NR | 3843.2 | 0 | Yes |
| [16] | −0.52 | 6553.6 | NR | Yes |
| [17] | −0.85 | 70 | 0 | NR |
| [18] | NR | 196 | 0 | Yes |
| [19] | NR | 91.1926 | 0 | NR |
| Proposed | −0.583 | 110.25 | 0 | Yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santin-Cruz, C.J.; Dolecek, G.J. Audio Watermarking System in Real-Time Applications. Informatics 2025, 12, 1. https://doi.org/10.3390/informatics12010001
Santin-Cruz CJ, Dolecek GJ. Audio Watermarking System in Real-Time Applications. Informatics. 2025; 12(1):1. https://doi.org/10.3390/informatics12010001
Chicago/Turabian StyleSantin-Cruz, Carlos Jair, and Gordana Jovanovic Dolecek. 2025. "Audio Watermarking System in Real-Time Applications" Informatics 12, no. 1: 1. https://doi.org/10.3390/informatics12010001
APA StyleSantin-Cruz, C. J., & Dolecek, G. J. (2025). Audio Watermarking System in Real-Time Applications. Informatics, 12(1), 1. https://doi.org/10.3390/informatics12010001