_Bryant.png)
Generating Paraphrase Using Simulated Annealing for Citation Sentences


Abstract
1. Introduction
- The abstract is a paraphrase of the sentence in the body of the paper
- The introductory part has a paraphrase equivalent to the methodology section
- The conclusion has a paraphrase equivalent to the experimental section
- Definition sentences have paraphrase equivalents with others that define the same construct
- The citation sentence that quotes the same paper is a paraphrase.
2. Related Work
2.1. Corpus Construction
2.2. Objective Function
2.3. Paraphrase Generator
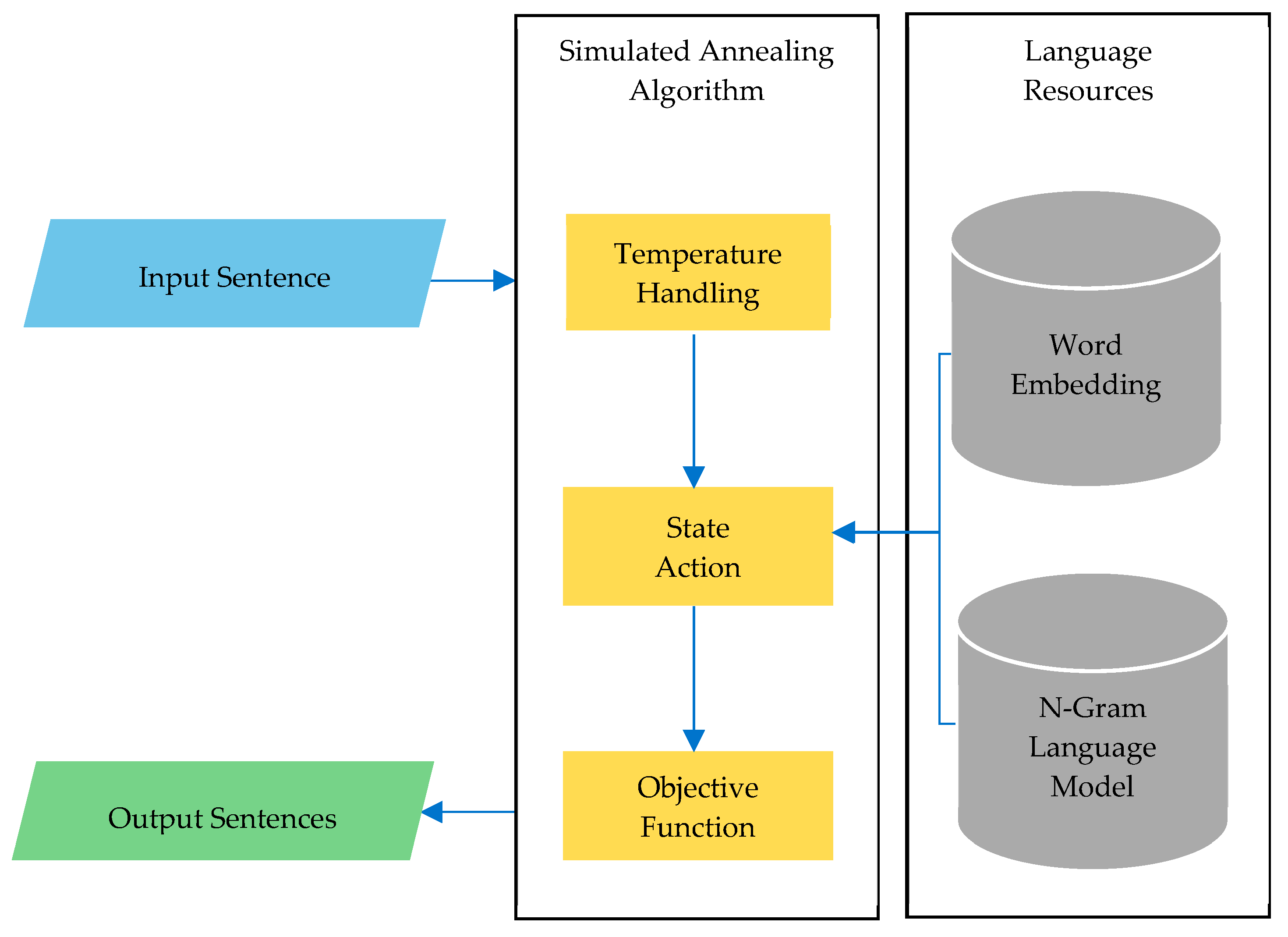
2.4. Simulated Annealing
3. Methods
3.1. Generator Model
- :
- represents the probability of the word given the previous words , …,
- :
- represents the count of the N-gram , …, in the training corpus
- :
- represents the count of the gram , …, in the training corpus
3.2. Objective Function
| Algorithm 1: Simulated Annealing for Sentence Generator |
| FUNCTION StoPGEN(x [0…n]: Array of token) return S [0…n]: Array of token |
| {function of sentence generator using simulated annealing} |
| DECLARATION |
| T, initial temperature |
| ∆T, temperature drop |
| s, current state {state is array of token} |
| Pscore, objective function |
| pLM (), language model probability function {return score} |
| most_similar (), get most similar token from word index |
| Neighbors (), get most similar token by neighbors from word index |
| ALGORITHM |
| T ← T0 |
| Sk ← x |
| while T > 0 and n do |
| action ← get_random_action () |
| if action = subtitution do |
| sk + 1[n] = max (pLM (most_similar (sk + 1[n]))) |
| else if action = insertion do |
| sk + 1[n] = max (pLM (neighbors ([sk + 1[n − 2], sk + 1[n − 1], sk + 1[n + 1], sk + 1[n + 2]])) |
| else |
| remove(sk + 1[n]) |
| ∆E ← Pscore (sk + 1)−Pscore (sk) |
| if min (1, e−∆E/T) >= rand (0,1) then |
| sk ← sk + 1 |
| end if |
| T ← T − ∆T |
| end while |
| return sk {new array of token} |
3.3. Dataset
- Sentences from scientific papers will be collected based on their function as citation sentences, abstracts, and content. This process uses the Dr. Inventor Framework [49].
- From the extraction results, the sentences selected white only have one citation target. The sentences that have two or more citation target was ignored.
- After the selection is made, the clustering process is carried out. Clustering sentence citations is the process of grouping sentences to get candidate pairs of sentences that have the same meaning. The clustering of citation sentences uses the K-Means algorithm [50] with Jaccard similarity, bigram representation, and TF-IDF.
- After the clustering process, each sentence in a cluster is paired with one another as a corpus candidate for the labeling stage.
4. Experiment
4.1. Dataset Evaluation
4.2. Experiment Scenario
4.3. Method Comparison
4.3.1. UPSA
4.3.2. Variant Auto Encoder
4.3.3. Lagging Variant Auto Encoder
4.3.4. CGHM
4.3.5. Modified UPSA
4.3.6. LSTM Encoder-Decoder
4.3.7. Bi-Directional LSTM
4.3.8. Transformer
4.4. Matrix Evaluation
4.4.1. BLEU Score
4.4.2. Rouge
5. Results
5.1. Dataset Agreement
5.2. Quantitative Evaluation
5.2.1. Generate the Quora and Twitter
5.2.2. Generate Citation Sentences
- StoPGEN1: Generates a sentence with a random action by selecting a random word position.
- StoPGEN2: Generates sentences with random actions by selecting words sequentially based on their position order in the sentence.
- StoPGEN3: Generates sentences with random actions by selecting words sequentially based on their position order in the sentence and using language models to select candidate accessors.
5.3. Qualitative Evaluation
5.3.1. Stochastic StoPGEN Results
5.3.2. Human Acceptability
6. Conclusions
7. Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Androutsopoulos, I.; Malakasiotis, P. A Survey of Paraphrasing and Textual Entailment Methods. J. Artif. Intell. Res. 2010, 38, 135–187. [Google Scholar] [CrossRef]
- Quirk, C.; Brockett, C.; Dolan, W. Monolingual Machine Translation for Paraphrase Generation; Association for Computational Linguistics: Stroudsburg, PA, USA, 2003. [Google Scholar]
- Lisa, C.M.L. Merging Corpus Linguistics and Collaborative Knowledge. Ph.D. Thesis, University of Birmingham, Birmingham, UK, 2009. [Google Scholar]
- Barrom-Cedeno, A.; Vila, M.; Marti, A. Plagiarism Meets Paraphrasing: Insights for the Next Generation in Automatic Plagiarism Detection. Assoc. Comput. Linguist. 2013, 10, 1–309. [Google Scholar] [CrossRef]
- Kittredge, R. Paraphrasing for Condensation in Journal Abstracting. J. Biomed. Inform. 2002, 35, 265–277. [Google Scholar] [CrossRef] [PubMed]
- Ilyas, R.; Widiyantoro, D.H.; Khodra, M.L. Building Candidate Monolingual Parallel Corpus from Scientific Papers. In Proceedings of the 2018 International Conference on Asian Language Processing, IALP, Bandung, Indonesia, 15–17 November 2018; pp. 230–233. [Google Scholar] [CrossRef]
- Teufel, S.; Siddharthan, A.; Tidhar, D. An Annotation Scheme for Citation Function. In Proceedings of the COLING/ACL 2006–SIGdial06: 7th SIGdial Workshop on Discourse and Dialogue, Sydney, Australia, 15–16 July 2006; pp. 80–87. [Google Scholar] [CrossRef]
- Liu, X.; Mou, L.; Meng, F.; Zhou, H.; Zhou, J.; Song, S. Unsupervised Paraphrasing by Simulated Annealing. arXiv 2019, 302–312. [Google Scholar] [CrossRef]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 65–72. [Google Scholar]
- Chen, D.L.; Dolan, W.B. Collecting Highly Parallel Data for Paraphrase Evaluation. In Proceedings of the ACL-HLT 2011, 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Volume 1, pp. 190–200. [Google Scholar]
- Carbonell, J.; Goldstein, J. Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries. In SIGIR Forum (ACM Special Interest Group on Information Retrieval); ACM: New York, NY, USA, 1998; pp. 335–336. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- NADAS, A. Estimation of Probabilities in the Language Model of the IBM Speech Recognition System. In IEEE Transactions on Acoustics Speech and Signal Processing; IEEE: New York, NY, USA, 1984; p. 27. [Google Scholar] [CrossRef]
- McKeown, K.R. Paraphrasing Questions Using Given and New Information. Am. J. Comput. Linguist. 1983, 9, 1. [Google Scholar]
- Lin, D.; Pantel, P. Discovery of Inference Rules for Question-Answering. Nat. Lang. Eng. 2001, 7, 343–360. [Google Scholar] [CrossRef]
- Kauchak, D.; Barzilay, R. Paraphrasing for Automatic Evaluation. In Proceedings of the Main Conference on Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics; Association for Computational Linguistics: New York, NY, USA, 2006; pp. 455–462. [Google Scholar]
- Prakash, A.; Hasan, S.A.; Lee, K.; Datla, V.; Qadir, A.; Liu, J.; Farri, O. Neural Paraphrase Generation with Stacked Residual LSTM Networks. arXiv 2016, arXiv:1610.03098. [Google Scholar]
- Vizcarra, G.; Ochoa-Luna, J. Paraphrase Generation via Adversarial Penalizations. In Proceedings of the Sixth Workshop on Noisy User-generated Text (W-NUT 2020); Association for Computational Linguistics: New York, NY, USA, 2020; pp. 249–259. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 2017, 5999–6009. [Google Scholar]
- Wang, S.; Gupta, R.; Chang, N.; Baldridge, J. A Task in a Suit and a Tie: Paraphrase Generation with Semantic Augmentation. Proc. Conf. AAAI Artif. Intell. 2019, 33, 7176–7183. [Google Scholar] [CrossRef]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-Based Neural Machine Translation. In Proceedings of the EMNLP 2015: Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar] [CrossRef]
- Ma, X.; Hovy, E. End-to-End Sequence Labeling via Bi-Directional LSTM-CNNs-CRF; Association for Computational Linguistics: Berlin, Germany, 2016; Volume 2, pp. 1064–1074. [Google Scholar] [CrossRef]
- Miao, N.; Zhou, H.; Mou, L.; Yan, R.; Li, L. CGMH: Constrained Sentence Generation by Metropolis-Hastings Sampling. AAAI Conf. Artif. Intell. 2019, 33, 6834–6842. [Google Scholar] [CrossRef]
- Lan, W.; Qiu, S.; He, H.; Xu, W. A Continuously Growing Dataset of Sentential Paraphrases. In Proceedings of the EMNLP 2017—Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 1224–1234. [Google Scholar]
- Bowman, S.R.; Vilnis, L.; Vinyals, O.; Dai, A.M.; Jozefowicz, R.; Bengio, S. Generating Sentences from a Continuous Space. In Proceedings of the CoNLL 2016—20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 10–21. [Google Scholar]
- Bhagat, R.; Hovy, E. What Is Paraphrase; Association for Computational Linguistics: New York, NY, USA, 2013; Volume 39. [Google Scholar] [CrossRef]
- Ganitkevitch, J.; Van Durme, B.; Callison-Burch, C. PPDB: The Paraphrase Database. In Proceedings of the NAACL-HLT–Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 758–764. [Google Scholar]
- Dolan, W.B.; Brockett, C. Automatically Constructing a Corpus of Sentential Paraphrases. In Proceedings of the Third International Workshop on Paraphrasing, Yamamoto, Japan, 14 October 2005; pp. 9–16. [Google Scholar]
- Xu, W.; Ritter, A.; Callison-burch, C.; Dolan, W.B.; Ji, Y. Extracting Lexically Divergent Paraphrases from Twitter. Trans. Assoc. Comput. Linguist. 2014, 2, 435–448. [Google Scholar] [CrossRef]
- Pavlick, E.; Rastogi, P.; Ganitkevitch, J.; Durme, B.V.; Callison-Burch, C. PPDB 2.0: Better Paraphrase Ranking, Fine-Grained Entailment Relations, Word Embeddings, and Style Classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Short Papers), Beijing, China, 26–31 July 2015; pp. 425–430. [Google Scholar]
- Shi, L. Rewriting and Paraphrasing Source Texts in Second Language Writing. J. Second Lang. Writ. 2012, 21, 134–148. [Google Scholar] [CrossRef]
- Teufel, S. Do “Future Work” Sections Have a Purpose? Citation Links and Entailment for Global Scientometric Questions. In Proceedings of the 2nd Joint Workshop on Bibliometric-enhanced Information Retrieval and Natural Language Processing for Digital Libraries, Tokyo, Japan, 7–11 August 2017. [Google Scholar]
- Takahashi, K.; Ishibashi, Y.; Sudoh, K.; Nakamura, S. Multilingual Machine Translation Evaluation Metrics Fine-Tuned on Pseudo-Negative Examples for WMT 2021 Metrics Task. In Proceedings of the WMT 2021–6th Conference on Machine Translation, Online, 10–11 November 2021; pp. 1049–1052. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadephia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Doddington, G. Automatic Evaluation of Machine Translation Quality Using N-Gram Co-Occurrence Statistics; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2002; p. 138. [Google Scholar] [CrossRef]
- Madnani, N.; Tetreault, J.; Chodorow, M. Re-Examining Machine Translation Metrics for Paraphrase Identification. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2012; pp. 182–190. [Google Scholar]
- Ji, Y.; Eisenstein, J. Discriminative Improvements to Distributional Sentence Similarity. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP 2013), Seattle, WA, USA, 18–21 October 2013; pp. 891–896. [Google Scholar]
- Brad, F. Neural Paraphrase Generation Using Transfer Learning; Association for Computational Linguistics: New York, NY, USA, 2017. [Google Scholar]
- Aziz, A.A.; Djamal, E.C.; Ilyas, R. Siamese Similarity Between Two Sentences Using Manhattan’s Recurrent Neural Networks. In Proceedings of the 2019 International Conference of Advanced Informatics: Concepts, Theory and Applications (ICAICTA), Yogyakarta, Indonesia, 20–22 September 2019; pp. 1–6. [Google Scholar]
- Saputro, W.F.; Djamal, E.C.; Ilyas, R. Paraphrase Identification Between Two Sentence Using Support Vector Machine. In Proceedings of the 2019 International Conference on Electrical Engineering and Informatics (ICEEI), Nanjing, China, 8–10 November 2019; pp. 406–411. [Google Scholar]
- Wubben, S.; Bosch, A.V.D.; Krahmer, E. Paraphrase Generation as Monolingual Translation: Data and Evaluation. In Proceedings of the 6th International Natural Language Generation Conference, Meath, Ireland, 7–9 July 2010; pp. 203–207. [Google Scholar]
- Mallinson, J.; Sennrich, R.; Lapata, M. Paraphrasing Revisited with Neural Machine Translation. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; pp. 881–893. [Google Scholar]
- Zhao, S.; Lan, X.; Liu, T.; Li, S. Application-Driven Statistical Paraphrase Generation. In Proceedings of the 47th Annual Meeting of the ACL and the 4th IJCNLP of the AFNLP, Suntec, Singapore, 2–7 August 2009; pp. 834–842. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. Nips 2014, 27, 3104–3112. [Google Scholar] [CrossRef]
- Parikh, A.P.; Täckström, O.; Das, D.; Uszkoreit, J. A Decomposable Attention Model for Natural Language Inference. arXiv 2016, arXiv:1606.01933. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Granville, V.; Rasson, J.P.; Krivánek, M. Simulated Annealing: A Proof of Convergence. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 652–656. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations Ofwords and Phrases and Their Compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Donoghue, D.P.; Saggion, H.; Dong, F.; Hurley, D.; Abgaz, Y.; Zheng, X.; Corcho, O.; Careil, J.-M.; Mahdian, B.; Zhao, X. Towards Dr Inventor: A Tool for Promoting Scientific Creativity; Jozef Stefan Institute: Ljubljana, Slovenia, 2014; p. 5. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. Applied Statistics 1979, 28, 100. [Google Scholar] [CrossRef]
- He, J.; Spokoyny, D.; Neubig, G.; Berg-Kirkpatrick, T. Lagging Inference Networks and Posterior Collapse in Variational Autoencoders. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019; pp. 1–15. [Google Scholar]
- Lin, C.-Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]



{kind=link}
{kind=link}
| No | Paper | Year | Name | Domain | Technique |
|---|---|---|---|---|---|
| 1 | Ganitkevitch et al. [27] | 2013 | PPDB | Free | Pivoting |
| 2 | Pavlick et al. [30] | 2013 | PPDB 2.0 | Free | Pivoting |
| 3 | Dolan et al. [28] | 2005 | MSRP | Free | SVM |
| 4 | Xu et al. [29] | 2014 | PIT | Multi-instance learning |
| Action Factor | Substitution | Insertion | Deletion |
|---|---|---|---|
| A | 90% | 5% | 5% |
| B | 80% | 10% | 10% |
| C | 70% | 15% | 15% |
| D | 60% | 20% | 20% |
| E | 50% | 25% | 25% |
| F | 40% | 30% | 30% |
| G | Uniform | ||
| Kappa Score | Significance |
|---|---|
| <0 | No agreement |
| 0.01–0.20 | Slight agreement |
| 0.21–0.40 | Fair agreement |
| 0.41–0.60 | Moderate agreement |
| 0.61–0.80 | Substantial agreement |
| 0.81–0.99 | Almost perfect agreement |
| 1 | Perfect agreement |
| Model | Quora | |||||
|---|---|---|---|---|---|---|
| BLEU | Rouge 1 | Rouge 2 | BLEU | Rouge 1 | Rouge 2 | |
| Supervised | ||||||
| VAE | 3.46 | 15.13 | 3.40 | 13.96 | 44.55 | 22.64 |
| LagVAE | 3.74 | 17.20 | 3.79 | 15.52 | 49.20 | 26.12 |
| CGHM | 5.32 | 19.96 | 5.44 | 15.73 | 48.73 | 26.12 |
| Unsupervised | ||||||
| UPSA | 5.30 | 19.96 | 5.44 | 18.21 | 59.51 | 32.63 |
| StoPGEN | 6.26 | 28.60 | 8.75 | 22.37 | 61.09 | 40.79 |
| Model | Action Factor | BLEU | Rouge 1 | Rouge 2 | Rouge L |
|---|---|---|---|---|---|
| StoPGEN1 | A | 44.74 | 58.64 | 39.71 | 55.28 |
| B | 46.23 | 60.34 | 40.63 | 56.73 | |
| C | 47.47 | 61.92 | 41.42 | 58.11 | |
| D | 48.78 | 63.56 | 42.25 | 59.54 | |
| E | 50.22 | 65.13 | 43.33 | 61.06 | |
| F | 51.59 | 66.71 | 44.22 | 62.43 | |
| G | 52.45 | 67.85 | 45.01 | 63.48 | |
| StoPGEN2 | A | 27.80 | 44.23 | 28.69 | 41.65 |
| B | 35.07 | 50.61 | 32.33 | 47.48 | |
| C | 40.72 | 55.85 | 35.31 | 52.16 | |
| D | 45.20 | 60.06 | 38.02 | 56.19 | |
| E | 49.16 | 63.73 | 40.86 | 59.71 | |
| F | 52.47 | 66.98 | 43.59 | 62.70 | |
| G | 54.58 | 68.98 | 45.54 | 64.62 | |
| StoPGEN3 | A | 27.69 | 46.04 | 28.55 | 42.87 |
| B | 35.13 | 52.83 | 32.86 | 49.23 | |
| C | 40.83 | 58.26 | 36.41 | 54.27 | |
| D | 45.77 | 62.68 | 39.69 | 58.42 | |
| E | 49.80 | 66.31 | 42.82 | 61.78 | |
| F | 53.36 | 69.44 | 45.65 | 64.69 | |
| G | 55.37 | 71.28 | 47.46 | 66.32 |
| Model | BLEU | Rouge 1 | Rouge 2 | Rouge L |
|---|---|---|---|---|
| Unsupervised | ||||
| StoPGEN3 | 55.37 | 71.28 | 47.46 | 66.32 |
| UPSA | 21.20 | 45.93 | 15.43 | 41.55 |
| Modified UPSA | 33.81 | 51.25 | 26.67 | 45.94 |
| Supervised | ||||
| LSTM encoder-decoder | 25.77 | 22.60 | 7.68 | 20.13 |
| bidirectional LSTM | 28.93 | 26.10 | 11.75 | 23.44 |
| Transformer | 18.91 | 20.70 | 7.83 | 18.46 |
| Input | We use pre-trained glove (pennington et. Al., 2014) embeddings for our purposes |
| Target | We use glove (pennington et. Al., 2014) for our word embeddings |
| Output 1 | Used trained glove (pennington et. Al., 2014) embeddings for implement through |
| Output 2 | Use pre-300 dimensional glove embeddings (pennington et. Al., 2014) word glove embeddings for our purposes |
| Output 3 | We use glove trained pretrained embedding (pennington et. Al., 2014) matrix for our through |
| Output 4 | Use trained glove word vectors trained glove word (pennington et. Al., 2014) embeddings for our purposes |
| Output 5 | We use pre-trained (pennington et. Al., 2014) embeddings for our purposes glove |
| Input | StoPGEN1 | StoPGEN2 | StoPGEN3 |
|---|---|---|---|
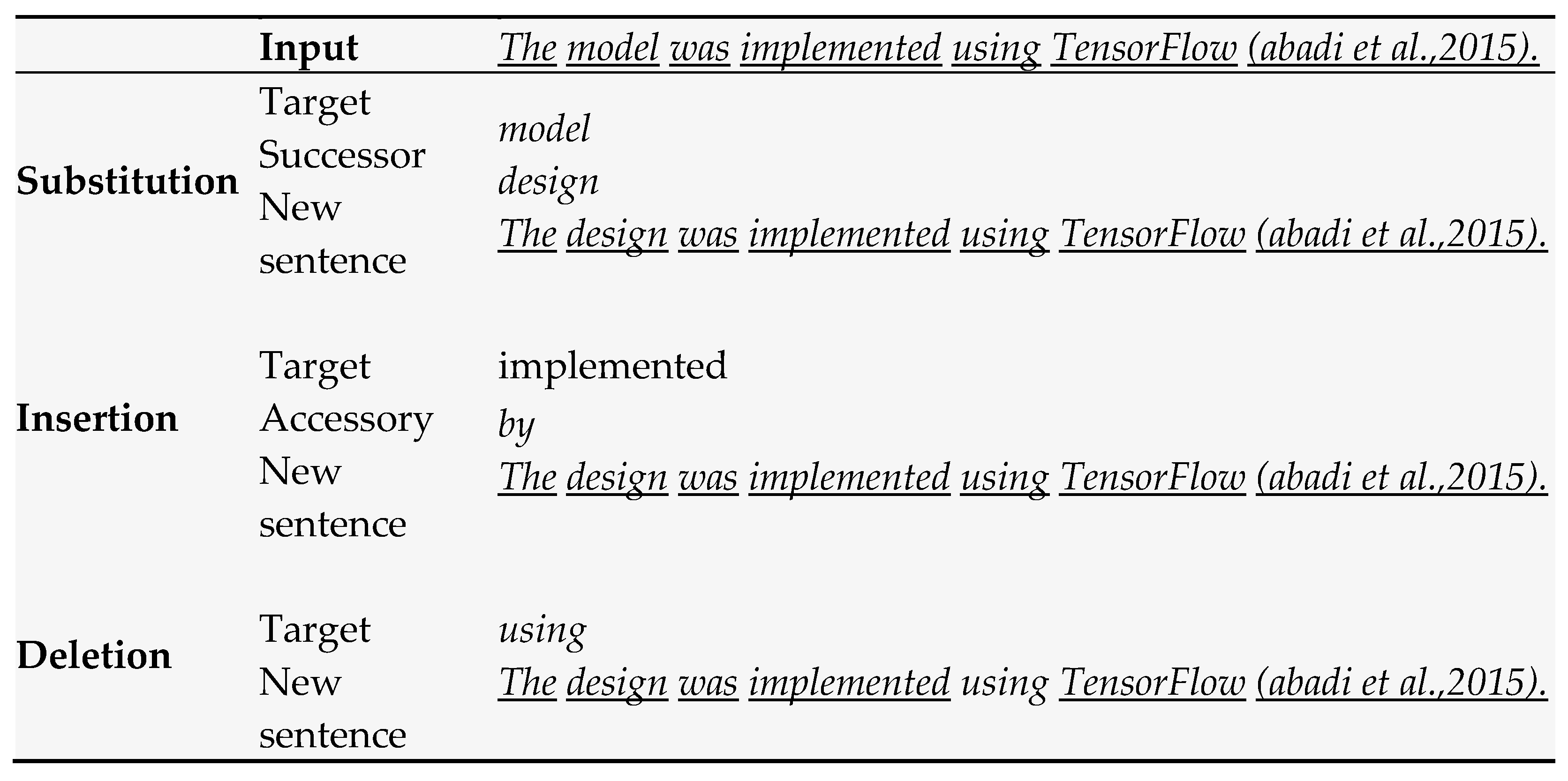
| the model was implemented using tensorflow (abadi et. al., 2015) | the model was based this implemented transformer using tensorflow implemented (abadi et. al.,2015) | the implemented transformer model transformer was transformer pytorch using tensorflow (abadi et. al., 2015) | the our implemented our model based was pytorch using tensorflow (abadi et. al., 2015) |
| du et al. (2017) pioneered nn-based qg by adopting the seq2seq architecture (sutskever et at, 2014) | du et al. (2017) pioneered nn-based qg by adopting seq2seq architecture based (sutskever et at, 2014) | du al et al. (2017) pioneered nn-based qg by furthermore seq2seq implement (sutskever et at, 2014) | du et al. (2017) pioneered nn-based qg by using seq2seq models (sutskever et at, 2014) |
| we use the spanish-english ner corpus introduced in the 2018 calcs competition (aguilar et. al., 2018), which contains a total of 67,223 tweets with 808,663 tokens | details dimensional 200 the corpus introduced in the data calcs competition (aguilar et. al., 2018) contains a of 67,223 tweets with 808,663 scratch tokens | details employ pre spanish-english ner corpus introduced in the 2018 calcs competition (aguilar et. al., 2018) which contains was descent total of 67,223 tweets with poor tokens | we use the spanish-english corpus in 2018 calcs competition (aguilar et. al., 2018) been it contains by was work a total 67,223 preserving tweets with 808,663 tokens |
| Model | Acceptability (with Action Label) |
|---|---|
| StoPGEN1 | 26.45 |
| StoPGEN2 | 27.09 |
| StoPGEN3 | 50.96 |
| Input | UPSA | Modified UPSA | StoPGEN3 |
|---|---|---|---|
| Tokenizing the output sentence: all words except special tokens are segmented by farasa (abdelali et al., 2016) and then tokenized with arabert tokenizer | The uk offers all words except special tokens of segmented by (abdelali et al., 2016) | The sentence all from initialize words from except user tokens are by farasa (abdelali et al., 2016) and then with tokenizer | Tokenizing the output sentence: all words tokens segmented farasa (abdelali et al., 2016) and then tokenized with arabert tokenizer |
| We use the spanish-english ner corpus introduced in the 2018 calcs competition (aguilar et al., 2018), which contains a total of 67,223 tweets with 808,663 tokens | We use the huge ner currency corpus introduced in the 2016 competition in (aguilar et al., 2018) | We use the spanishenglish corpus in 2018 calcs competition (aguilar et al., 2018) been it contains by was work a total 67,223 preserving tweets with 808,663 tokens | We the spanish-english ner corpus in the 2018 calcs competition (aguilar et al., 2018), which contains a total of 67,223 tweets with 808,663 tokens |
| The first one is heuristic rules such as treating identical words as the seed (artetxe et al., 2017), but this kind of method is restricted to languages sharing the alphabet | The one is heuristic rules such as treating identical words regarding the seed (artetxe et al., 2017) | First one transformer is transformer formation such bleu treating from senses identical from words as tialize the seed (artetxe et al., 2017) but partially work kind work of this method is this restricted to languages sharing the alphabet | The one heuristic rules such as the seed (artetxe et al., 2017), but this kind of method is restricted to languages sharing the alphabet |
| Model | Acceptability (without Action Label) |
|---|---|
| UPSA | 16.80 |
| Modified UPSA | 26.40 |
| StoPGEN3 | 50.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ilyas, R.; Khodra, M.L.; Munir, R.; Mandala, R.; Widyantoro, D.H. Generating Paraphrase Using Simulated Annealing for Citation Sentences. Informatics 2023, 10, 34. https://doi.org/10.3390/informatics10020034
Ilyas R, Khodra ML, Munir R, Mandala R, Widyantoro DH. Generating Paraphrase Using Simulated Annealing for Citation Sentences. Informatics. 2023; 10(2):34. https://doi.org/10.3390/informatics10020034
Chicago/Turabian StyleIlyas, Ridwan, Masayu Leylia Khodra, Rinaldi Munir, Rila Mandala, and Dwi Hendratmo Widyantoro. 2023. "Generating Paraphrase Using Simulated Annealing for Citation Sentences" Informatics 10, no. 2: 34. https://doi.org/10.3390/informatics10020034
APA StyleIlyas, R., Khodra, M. L., Munir, R., Mandala, R., & Widyantoro, D. H. (2023). Generating Paraphrase Using Simulated Annealing for Citation Sentences. Informatics, 10(2), 34. https://doi.org/10.3390/informatics10020034