On Collocations and Their Interaction with Parsing and Translation

Abstract
:1. Introduction
2. Using Parsing for Collocation Identification
- relativization
- various global challenges that we inevitably have to face
- 2.
- passivisation
- the challenges faced by the pharmaceutical industry today
- 3.
- interrogation
- Which challenges do online media face in terms of press freedom?

3. Using Translation for Collocation Identification
- Approaches that exploit translation archives represented by parallel corpora or source-target pairs of monolingual corpora for identifying translation equivalents for MWEs/collocations;
- Approaches that take into account word alignment information for detecting and ranking monolingual MWE/collocation candidates.
3.1. The First Trend: Exploiting Corpora for Collocation Identification
3.2. The Second Trend: Exploiting Word Alignments
4. Exploiting Collocations for Syntactic Parsing
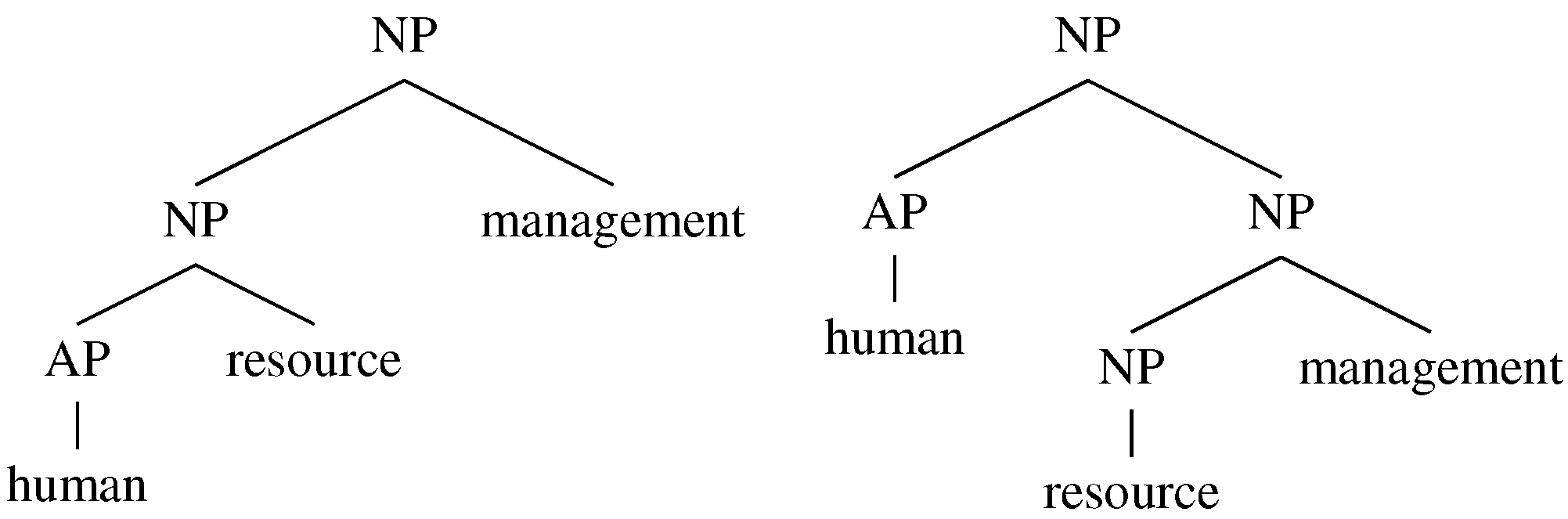
5. Exploiting Collocations in Machine Translation
“SMT output is often surprisingly good with respect to short distance collocations, but often (...) correct choices are missed in cases where selectional restrictions take effect on distant words.”
- the people who rely on us to give full support when it is needed les gens qui comptent sur nous pour apporter un soutien complet quand il est néecessaire
- and it is certainly right to give massive support to these areas [...] et il est certainement droit de *donner un soutien massif à ces domaines.
6. Conclusions
Acknowledgments
Conflicts of Interest
References
- Sag, I.A.; Baldwin, T.; Bond, F.; Copestake, A.; Flickinger, D. Multiword Expressions: A Pain in the Neck for NLP. In Proceedings of the Third International Conference on Intelligent Text Processing and Computational Linguistics (CICLING 2002), Mexico City, Mexico, 17–23 February 2002; pp. 1–15.
- Villavicencio, A.; Bond, F.; Korhonen, A.; McCarthy, D. Introduction to the special issue on multiword expressions: Having a crack at a hard nut. Comput. Speech Lang. 2005, 19, 365–377. [Google Scholar] [CrossRef]
- Heid, U. Computational Phraseology: An Overview. In Phraseology: An Interdisciplinary Perspective; Granger, S., Meunier, F., Eds.; John Benjamins: Amsterdam, The Netherlands, 2008; pp. 337–360. [Google Scholar]
- Jackendoff, R. The Architecture of the Language Faculty; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Mel’čuk, I. Collocations and Lexical Functions. In Phraseology. Theory, Analysis, and Applications; Cowie, A.P., Ed.; Claredon Press: Oxford, UK, 1998; pp. 23–53. [Google Scholar]
- Erman, B.; Warren, B. The idiom principle and the open choice principle. Text 2000, 20, 29–62. [Google Scholar] [CrossRef]
- Oxford Collocations Dictionary for Students of English; Lea, D.; Runcie, M. (Eds.) Oxford University Press: Oxford, UK, 2002.
- Benson, M.; Benson, E.; Ilson, R. The BBI Dictionary of English Word Combinations; John Benjamins: Amsterdam, The Netherlands, Philadelphia, PA, USA, 1986. [Google Scholar]
- Fontenelle, T. Collocation Acquisition from a Corpus or from a Dictionary: A Comparison. In Proceedings of the I-II. Papers submitted to the 5th EURALEX International Congress on Lexicography in Tampere, Tampere, Finland, 4–9 August 1992; pp. 221–228.
- Gildea, D.; Palmer, M. The Necessity of Parsing for Predicate Argument Recognition. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 239–246.
- Daille, B. Approche Mixte Pour l’Extraction Automatique de Terminologie: Statistiques Lexicales et Filtres Linguistiques. Ph.D. Thesis, Université Paris 7, Paris, France, 1994. [Google Scholar]
- Pearce, D. A Comparative Evaluation of Collocation Extraction Techniques. In Proceedings of the Third International Conference on Language Resources and Evaluation, Las Palmas, Spain, 29–31 May 2002; pp. 1530–1536.
- Evert, S. The Statistics of Word Cooccurrences: Word Pairs and Collocations. Ph.D. Thesis, University of Stuttgart, Stuttgart, Germany, 2004. [Google Scholar]
- Pecina, P. Lexical Association Measures: Collocation Extraction. Ph.D. Thesis, Charles University in Prague, Prague, Czech Republic, 2008. [Google Scholar]
- Stubbs, M. Words and Phrases: Corpus Studies of Lexical Semantics; Blackwell: Oxford, UK, 2002. [Google Scholar]
- Church, K.; Hanks, P. Word association norms, mutual information, and lexicography. Comput. Linguist. 1990, 16, 22–29. [Google Scholar]
- Justeson, J.S.; Katz, S.M. Technical terminology: Some linguistic properties and an algorithm for identification in text. Nat. Lang. Eng. 1995, 1, 9–27. [Google Scholar] [CrossRef]
- Zaiu Inkpen, D.; Hirst, G. Acquiring Collocations for Lexical Choice Between Near-Synonyms. In Proceedings of the Workshop on Unsupervised Lexical Acquisition (ACL-02), Philadephia, PA, USA, 6–12 July 2002; pp. 67–76.
- Todiraşcu, A.; Tufiş, D.; Heid, U.; Gledhill, C.; Ştefănescu, D.; Weller, M.; Rousselot, F. A Hybrid Approach to Extracting and Classifying Verb+Noun Constructions. In Proceedings of the Sixth International Language Resources and Evaluation (LREC’08), Marrakech, Morocco, 28–30 May 2008.
- Smadja, F. Retrieving collocations from text: Xtract. Comput. Linguist. 1993, 19, 143–177. [Google Scholar]
- Breidt, E. Extraction of V-N-Collocations from Text Corpora: A Feasibility Study for German. In Proceedings of the Workshop on Very Large Corpora: Academic and Industrial Perspectives, Columbus, Ohio, USA, 22 June 1993; pp. 74–83.
- Kim, S.; Yoon, J.; Song, M. Automatic extraction of collocations From Korean text. Comput. Humanit. 2001, 35, 273–297. [Google Scholar] [CrossRef]
- Heid, U. On Ways Words Work Together—Research Topics in Lexical Combinatorics. In Proceedings of the 6th Euralex International Congress on Lexicography (EURALEX ’94), Amsterdam, The Netherlands, 30 August–3 September 1994; pp. 226–257.
- Krenn, B. Collocation Mining: Exploiting Corpora for Collocation Idenfication and Representation. In Proceedings of the Sprachkommunikation, Vorträge der gemeinsamen Veranstaltung 5. Konferenz zur Verarbeitung natürlicher Sprache (KONVENS 2000), Ilmenau, Germany, 9–12 October 2000; pp. 209–214.
- Schulte im Walde, S. A Collocation Database for German Verbs and Nouns. In Proceedings of the 7th Conference on Computational Lexicography and Corpus Research, Budapest, Hungary, 3 April 2003.
- Lü, Y.; Zhou, M. Collocation Translation Acquisition Using Monolingual Corpora. In Proceedings of the 42nd Meeting of the Association for Computational Linguistics, ACL’04), Barcelona, Spain, 21–26 July 2004; pp. 167–174.
- Villada Moirón, M.B.N. Data-Driven Identification of Fixed Expressions and Their Modifiability. Ph.D. Thesis, University of Groningen, Groningen, The Netherlands, 2005. [Google Scholar]
- Orliac, B.; Dillinger, M. Collocation Extraction for Machine Translation. In Proceedings of the Machine Translation Summit IX, New Orleans, Lousiana, USA, 23–27 September 2003; pp. 292–298.
- Blaheta, D.; Johnson, M. Unsupervised Learning of Multi-Word Verbs. In Proceedings of the ACL Workshop on Collocation: Computational Extraction, Analysis and Exploitation, Toulouse, France, 6–7 July 2001; pp. 54–60.
- Pearce, D. Synonymy in Collocation Extraction. In Proceedings of the NAACL Workshop on WordNet and Other Lexical Resources: Applications, Extensions and Customizations, Pittsburgh, PA, USA, 2–7 June 2001; pp. 41–46.
- Lin, D. Extracting Collocations from Text Corpora. In Proceedings of the First Workshop on Computational Terminology, Montreal, Canada, 15 August 1998; pp. 57–63.
- Lin, D. Automatic Identification of Non-Compositional Phrases. In Proceedings of the 37th annual meeting of the Association for Computational Linguistics on Computational Linguistics, College Park, MD, USA, 20–26 June 1999; pp. 317–324.
- Charest, S.; Brunelle, E.; Fontaine, J.; Pelletier, B. Élaboration Automatique d’un Dictionnaire de Cooccurrences Grand Public. In Proceedings of the Actes de la 14e Conférence sur le Traitement Automatique des Langues Naturelles (TALN 2007), Toulouse, France, 5–8 June 2007; pp. 283–292.
- Pecina, P. Lexical association measures and collocation extraction. Lang. Resour. Eval. 2010, 1, 137–158. [Google Scholar] [CrossRef]
- Church, K.; Gale, W.; Hanks, P.; Hindle, D. Parsing, Word Associations and Typical Predicate-Argument Relations. In Proceedings of the International Workshop on Parsing Technologies, Pittsburgh, PA, USA, 28–31 August 1989; pp. 103–112.
- Wermter, J.; Hahn, U. Paradigmatic Modifiability Statistics for the Extraction of Complex Multi-Word Terms. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing (HLT ’05), Vancouver, Canada, 6–8 October 2005; pp. 843–850.
- Bourigault, D. LEXTER, vers un outil linguistique d’aide à l’acquisition des connaissances. Actes des 3èmes Journées d’acquisition des Connaissances, Dourdan, France, April 1992. [Google Scholar]
- Jacquemin, C.; Klavans, J.L.; Tzoukermann, E. Expansion of Multi-Word Terms for Indexing and Retrieval Using Morphology and Syntax. In Proceedings of the 35th Annual Meeting on Association for Computational Linguistics, Madrid, Spain, 7–12 July 1997; pp. 24–31.
- Kilgarriff, A.; Rychly, P.; Smrz, P.; Tugwell, D. The Sketch Engine. In Proceedings of the Eleventh EURALEX International Congress, Lorient, France, 15–19 July 2004; pp. 105–116.
- Wehrli, E. Fips, A “Deep” Linguistic Multilingual Parser. In Proceedings of the ACL 2007 Workshop on Deep Linguistic Processing, Prague, Czech Republic, 28 June 2007; pp. 120–127.
- Dunning, T. Accurate methods for the statistics of surprise and coincidence. Comput. Linguist. 1993, 19, 61–74. [Google Scholar]
- Maynard, D.; Ananiadou, S. A Linguistic Approach to Terminological Context Clustering. In Proceedings of Natural Language Pacific Rim Symposium (NLPRS ’99), Beijing, China, 5–7 November 1999; pp. 346–351.
- Padó, S.; Lapata, M. Dependency-based construction of semantic space models. Comput. Linguist. 2007, 33, 161–199. [Google Scholar] [CrossRef]
- Seretan, V. Syntax-Based Collocation Extraction, Text, Speech and Language Technology; Springer: Dordrecht, The Netherlands, 2011. [Google Scholar]
- Kupiec, J. An Algorithm for Finding Noun Phrase Correspondences in Bilingual Corpora. In Proceedings of the 31st Annual Meeting of the Association for Computational Linguistics, Columbus, Ohio, USA, 22–26 June 1993; pp. 17–22.
- Van der Eijk, P. Automating the Acquisition of Bilingual Terminology. In Proceedings of the Sixth Conference on European chapter of the Association for Computational Linguistics, Utrecht, The Netherlands, 22–26 June 1993; pp. 113–119.
- Dagan, I.; Church, K. Termight: Identifying and Translating Technical Terminology. In Proceedings of the 4th Conference on Applied Natural Language Processing (ANLP), Stuttgart, Germany, 13–15 October 1994; pp. 34–40.
- Smadja, F.; McKeown, K.; Hatzivassiloglou, V. Translating collocations for bilingual lexicons: A statistical approach. Comput. Linguist. 1996, 22, 1–38. [Google Scholar]
- Bai, M.H.; You, J.M.; Chen, K.J.; Chang, J.S. Acquiring Translation Equivalences of Multiword Expressions by Normalized Correlation Frequencies. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; pp. 478–486.
- Villada Moirón, B.N.; Tiedemann, J. Identifying Idiomatic Expressions Using Automatic Word-Alignment. In Proceedings of the Workshop on Multi-Word-Expressions in a Multilingual Context, Trento, Italy, 3 April 2006; pp. 33–40.
- Caseli, H.D.M.; Ramisch, C.; das Graças Volpe Nunes, M.; Villavicencio, A. Alignment-based extraction of multiword expressions. Lang. Resour. Eval. 2010, 44, 59–77. [Google Scholar] [CrossRef]
- Manning, C.D.; Schütze, H. Foundations of Statistical Natural Language Processing; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Seretan, V.; Wehrli, E. Collocation Translation Based on Sentence Alignment and Parsing. In Proceedings of the Actes de la 14e Conférence sur le Traitement Automatique des Langues Naturelles, TALN 2007, Toulouse, France, 5–8 June 2007; pp. 401–410.
- Wehrli, E.; Nerima, L.; Scherrer, Y. Deep Linguistic Multilingual Translation and Bilingual Dictionaries. In Proceedings of the Fourth Workshop on Statistical Machine Translation, Athens, Greece, 30–31 April 2009; pp. 90–94.
- Koehn, P. Europarl: A Parallel Corpus for Statistical Machine Translation. In Proceedings of the Tenth Machine Translation Summit (MT Summit X), Phuket, Thailand, 12–16 September 2005; pp. 79–86.
- Hindle, D.; Rooth, M. Structural ambiguity and lexical relations. Comput. Linguist. 1993, 19, 103–120. [Google Scholar]
- Alshawi, H.; Carter, D. Training and scaling preference functions for disambiguation. Comput. Linguist. 1994, 20, 635–648. [Google Scholar]
- Berthouzoz, C.; Merlo, P. Statistical Ambiguity Resolution for Principle-Based Parsing. In Recent Advances in Natural Language Processing: Selected Papers from RANLP’97, Current Issues in Linguistic Theory; Nicolov, N., Mitkov, R., Eds.; John Benjamins: Amsterdam, The Netherlands, Philadelphia, PA, USA, 1997; pp. 179–186. [Google Scholar]
- Wehrli, E. Parsing and Collocations. In Natural Language Processing; Christodoulakis, D., Ed.; Springer Verlag: Berlin/Heidelberg, Germany, 2000; pp. 272–282. [Google Scholar]
- Brun, C. Terminology Finite-State Preprocessing for Computational LFG. In Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics, Montreal, Canada, 10–14 August 1998; pp. 196–200.
- Zhang, Y.; Kordoni, V.; Villavicencio, A.; Idiart, M. Automated Multiword Expression Prediction for Grammar Engineering. In Proceedings of the Workshop on Multiword Expressions: Identifying and Exploiting Underlying Properties, Sydney, Australia, 23 July 2006; pp. 36–44.
- Alegria, I.N.; Ansa, O.; Artola, X.; Ezeiza, N.; Gojenola, K.; Urizar, R. Representation and Treatment of Multiword Expressions in Basque. In Proceedings of the Second ACL Workshop on Multiword Expressions: Integrating Processing, Barcelona, Spain, 26 July 2004; pp. 48–55.
- Villavicencio, A.; Kordoni, V.; Zhang, Y.; Idiart, M.; Ramisch, C. Validation and Evaluation of Automatically Acquired Multiword Expressions for Grammar Engineering. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 1034–1043.
- Ratnaparkhi, A. Statistical Models for Unsupervised Prepositional Phrase Attachment. In Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics, Montreal, Canada, 10–14 August 1998; pp. 1079–1085.
- Pantel, P.; Lin, D. An Unsupervised Approach to Prepositional Phrase Attachment Using Contextually Similar Words. In Proceedings of the 38th Annual Meeting of the Association for Computational Linguistics, Hong Kong, China, 1–8 October 2000; pp. 101–108.
- Volk, M. Combining Unsupervised and Supervised Methods for PP Attachment Disambiguation. In Proceedings of the 19th International Conference on Computational Linguistics (COLING’02), Taipei, Taiwan, 24 August 24–1 September 2002; pp. 25–32.
- Wehrli, E.; Seretan, V.; Nerima, L. Sentence Analysis and Collocation Identification. In Proceedings of the Workshop on Multiword Expressions: from Theory to Applications, MWE 2010, Beijing, China, 28 August 2010; pp. 27–35.
- The Economist. Available online at http://www.economist.com (accessed 2002–2013).
- Heylen, D.; Maxwell, K.G.; Verhagen, M. Lexical Functions and Machine Translation. In Proceedings of the 15th International Conference on Computational Linguistics (COLING 1994), Kyoto, Japan, 5–9 August 1994; pp. 1240–1244.
- Fillmore, C.; Kay, P.; O’Connor, C. Regularity and idiomaticity in grammatical constructions: The case of let alone. Language 1988, 64, 501–538. [Google Scholar] [CrossRef]
- Heid, U.; Raab, S. Collocations in Multilingual Generation. In Proceeding of the Fourth Conference of the European Chapter of the Association for Computational Linguistics (EACL’89), Manchester, UK, 10–12 April 1989; pp. 130–136.
- Liu, Z.; Wang, H.; Wu, H.; Li, S. Improving Statistical Machine Translation with Monolingual Collocation. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 825–833.
- Liu, Z.; Wang, H.; Wu, H.; Liu, T.; Li, S. Reordering with Source Language Collocations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 1036–1044.
- Tsvetkov, Y.; Wintner, S. Extraction of Multi-word Expressions from Small Parallel Corpora. In Proceedings of the Coling 2010: Posters, Beijing, China, 23–27 August 2010; pp. 1256–1264.
- Bouamor, D.; Semmar, N.; Zweigenbaum, P. Identifying Bilingual Multi-Word Expressions for Statistical Machine Translation. In Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 23–25 May 2012.
- Babych, B.; Eberle, K.; Geiß, J.; Ginestí-Rosell, M.; Hartley, A.; Rapp, R.; Sharoff, S.; Thomas, M. Design of a Hybrid High Quality Machine Translation System. In Proceedings of the Joint Workshop on Exploiting Synergies between Information Retrieval and Machine Translation (ESIRMT) and Hybrid Approaches to Machine Translation (HyTra), Avignon, France, 23–24 April 2012; pp. 101–112.
- Bod, R. Unsupervised Syntax-Based Machine Translation: The Contribution of Discontiguous Phrases. In Proceedings of the MT Summit XI, Copenhagen, Denmark, 10–14 September 2007; pp. 51–56.
- Wehrli, E.; Seretan, V.; Nerima, L.; Russo, L. Collocations in a Rule-Based MT System: A Case Study Evaluation of Their Translation Adequacy. In Proceedings of the 13th Annual Meeting of the European Association for Machine Translation, Barcelona, Spain, 14–15 May 2009; pp. 128–135.
- Carpuat, M.; Diab, M. Task-based Evaluation of Multiword Expressions: a Pilot Study in Statistical Machine Translation. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, California, USA, 2–4 June 2010; pp. 242–245.
- Naskar, S.K.; Toral, A.; Gaspari, F.; Way, A. A Framework for Diagnostic Evaluation of MT Based on Linguistic Checkpoints. In Proceedings of the 13th Machine Translation Summit, Xiamen, China, 19–23 September 2011; pp. 529–536.
- 1.The reader is referred to [3] for a detailed classification of multi-word expressions and an overview of their computational treatment.
- 2.A two-sample t-test was conducted to compare the number of grammatical pairs in the two methods’ output. There was a significant difference in the output: t(982) = 10.78, .
- 3.A similar two-sample t-test was conducted to compare the number of pairs considered as worth of storing in a lexicon. The difference is statistically significant: two-sample t(982) = 2.90, .
- 4.Two-sample t-tests have been conducted to compare the number of: (1) grammatical pairs; (2) pairs considered as worth storing in a lexicon; and (3) pairs marked as collocations. The differences obtained are statistically significant: (1) two-sample t(1435) = 26.65, ); (2) two-sample t(1435) = 11.04, ; 3) two-sample t(1435) = 9.15, .
- 5.We experimented with and without dictionary information (in our case, the lexical databases of the Its-2 in-house machine translation system [54]).
- 6.A McNemar test was conducted to compare the number of cases in which the translation became better vs. worse. For English-French, the difference (14 vs. 4) is statistically significant (). For Italian-French, the difference (16 vs. 3) is very statistically significant ().
© 2014 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Seretan, V. On Collocations and Their Interaction with Parsing and Translation. Informatics 2014, 1, 11-31. https://doi.org/10.3390/informatics1010011
Seretan V. On Collocations and Their Interaction with Parsing and Translation. Informatics. 2014; 1(1):11-31. https://doi.org/10.3390/informatics1010011
Chicago/Turabian StyleSeretan, Violeta. 2014. "On Collocations and Their Interaction with Parsing and Translation" Informatics 1, no. 1: 11-31. https://doi.org/10.3390/informatics1010011
APA StyleSeretan, V. (2014). On Collocations and Their Interaction with Parsing and Translation. Informatics, 1(1), 11-31. https://doi.org/10.3390/informatics1010011