
Deep Hedging under Rough Volatility


Abstract
:1. Introduction
2. Setup and Notation
- Take a well-understood model class that generalises the modelling to more realistic market scenarios, but where the generalisation no longer satisfies assumptions made in the original architecture.
- Test the robustness of the method if the assumption is violated by controlling for the error as the deviation from the assumption increases.
- Modify the network architecture accordingly if necessary.
3. Hedging and Network Architectures for Rough Volatility
3.1. Hedging under Rough Volatility
3.2. The Rough Bergomi Model (rBergomi)
3.3. Performance of the Deep Hedging Scheme (with the Original Feedforward Architecture) Compared to the Model Hedge under rBergomi
3.4. Implications on the Network Architecture
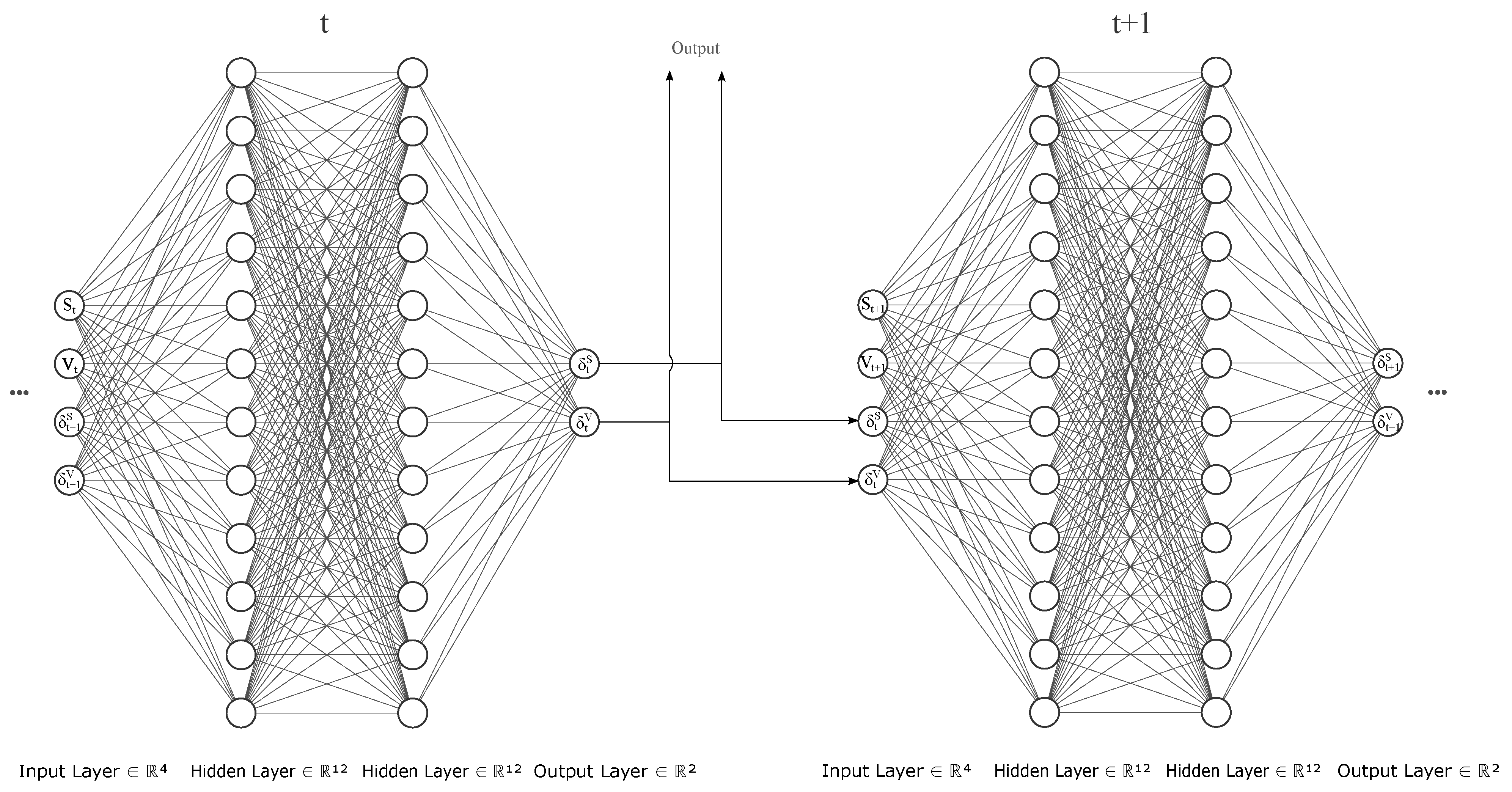
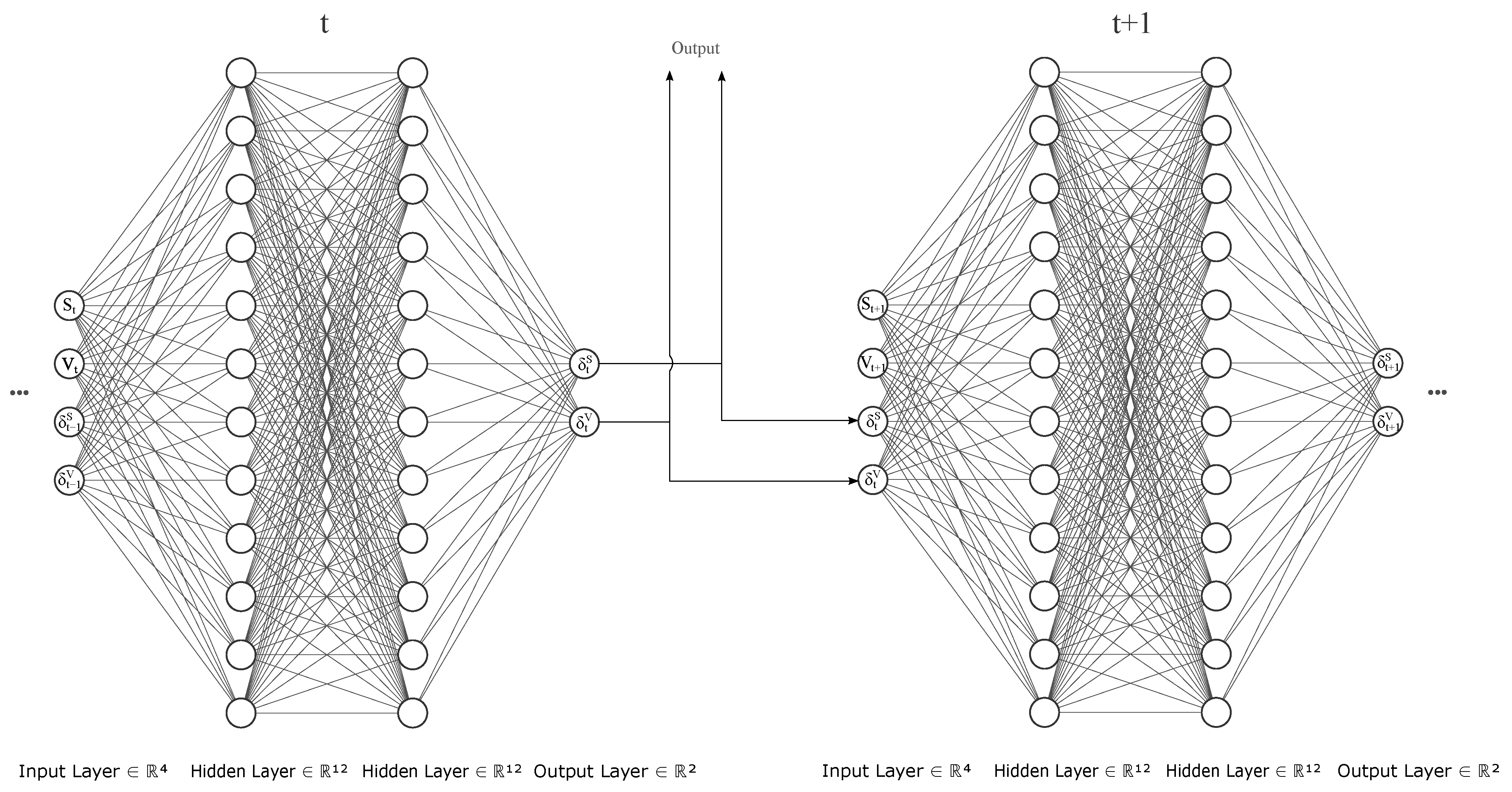
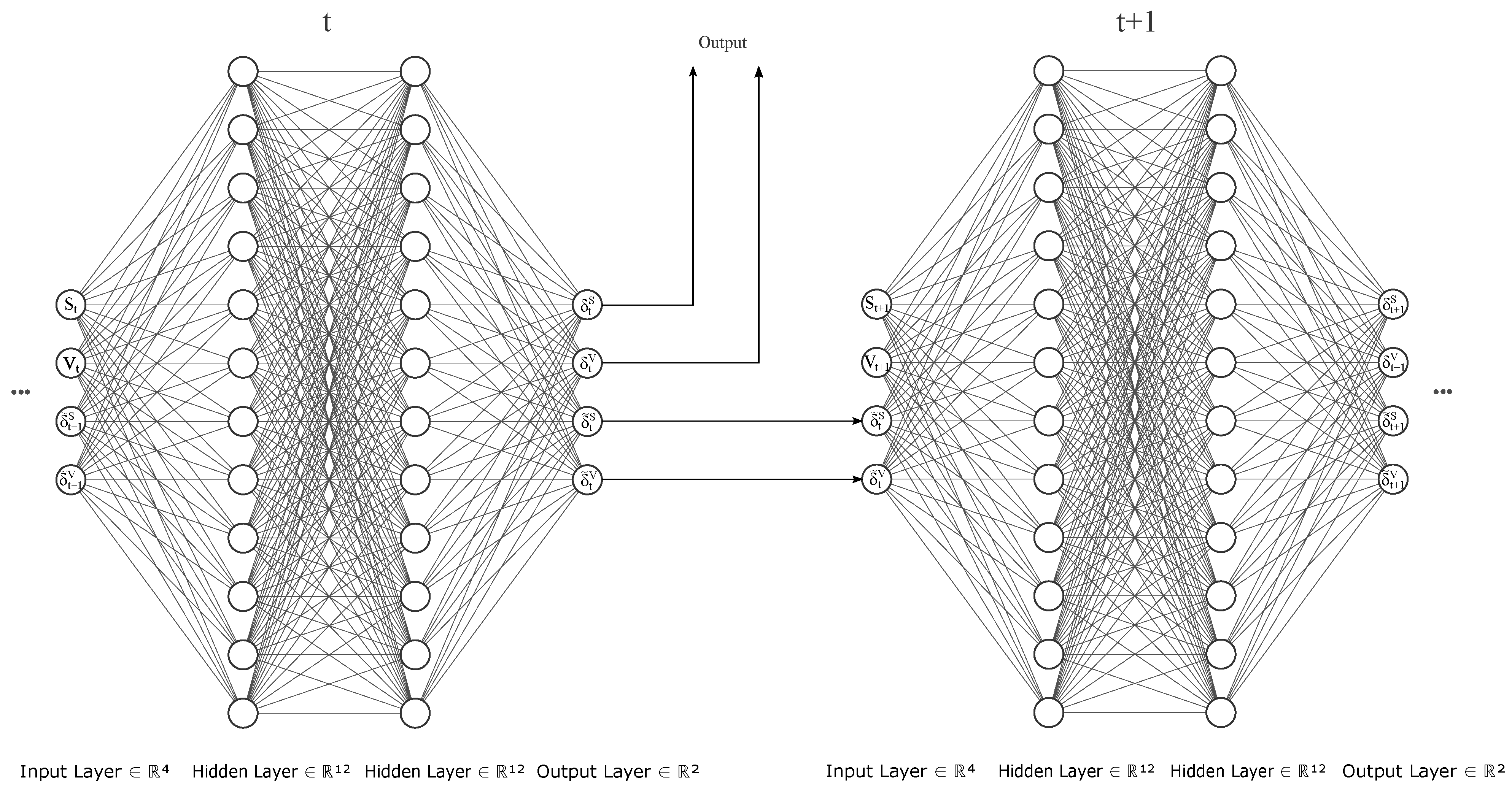
3.5. Proposed Fully Recurrent Architecture
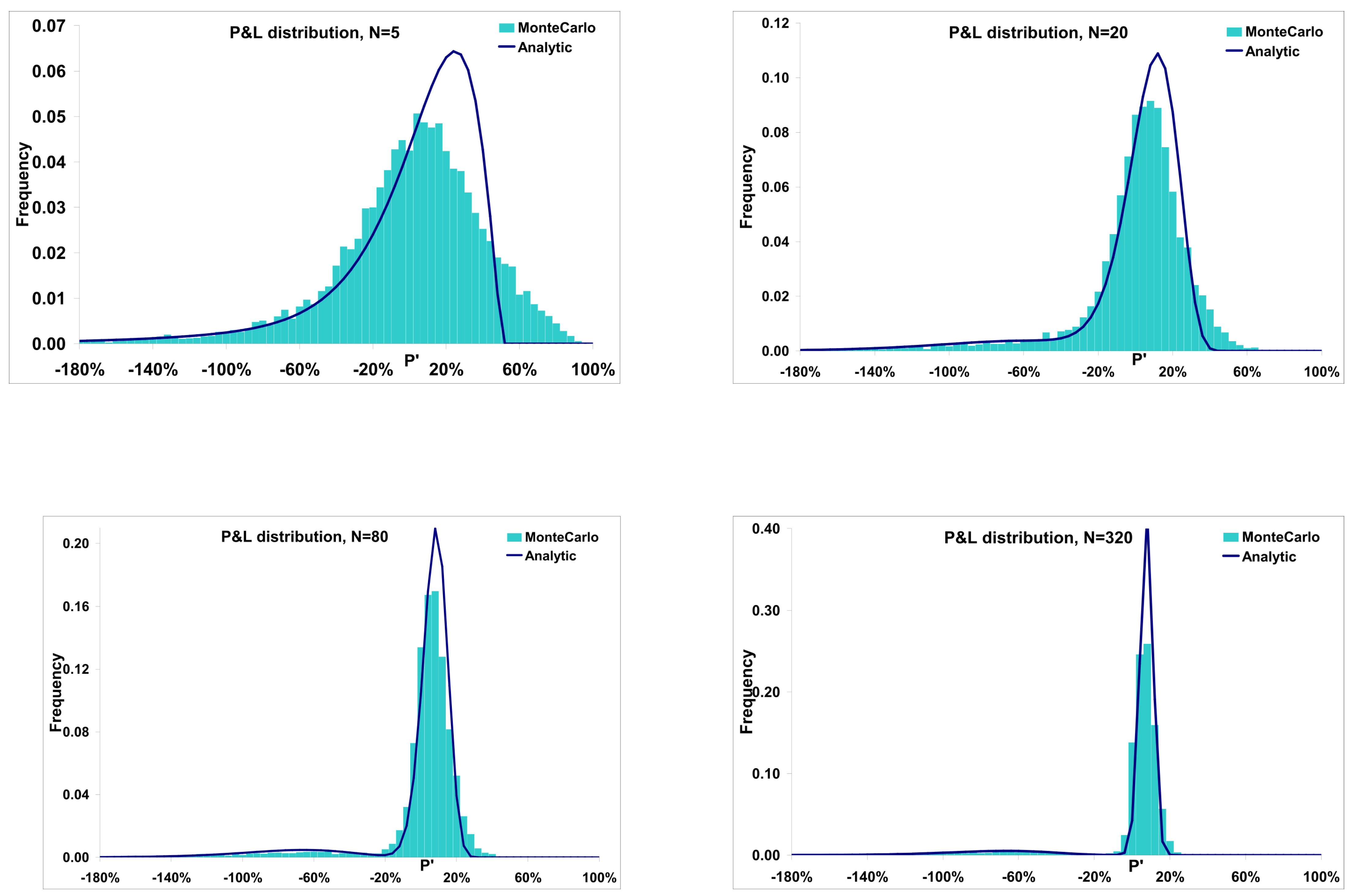
4. Hedging Performance and Hedging P&L under the Rough Bergomi Model
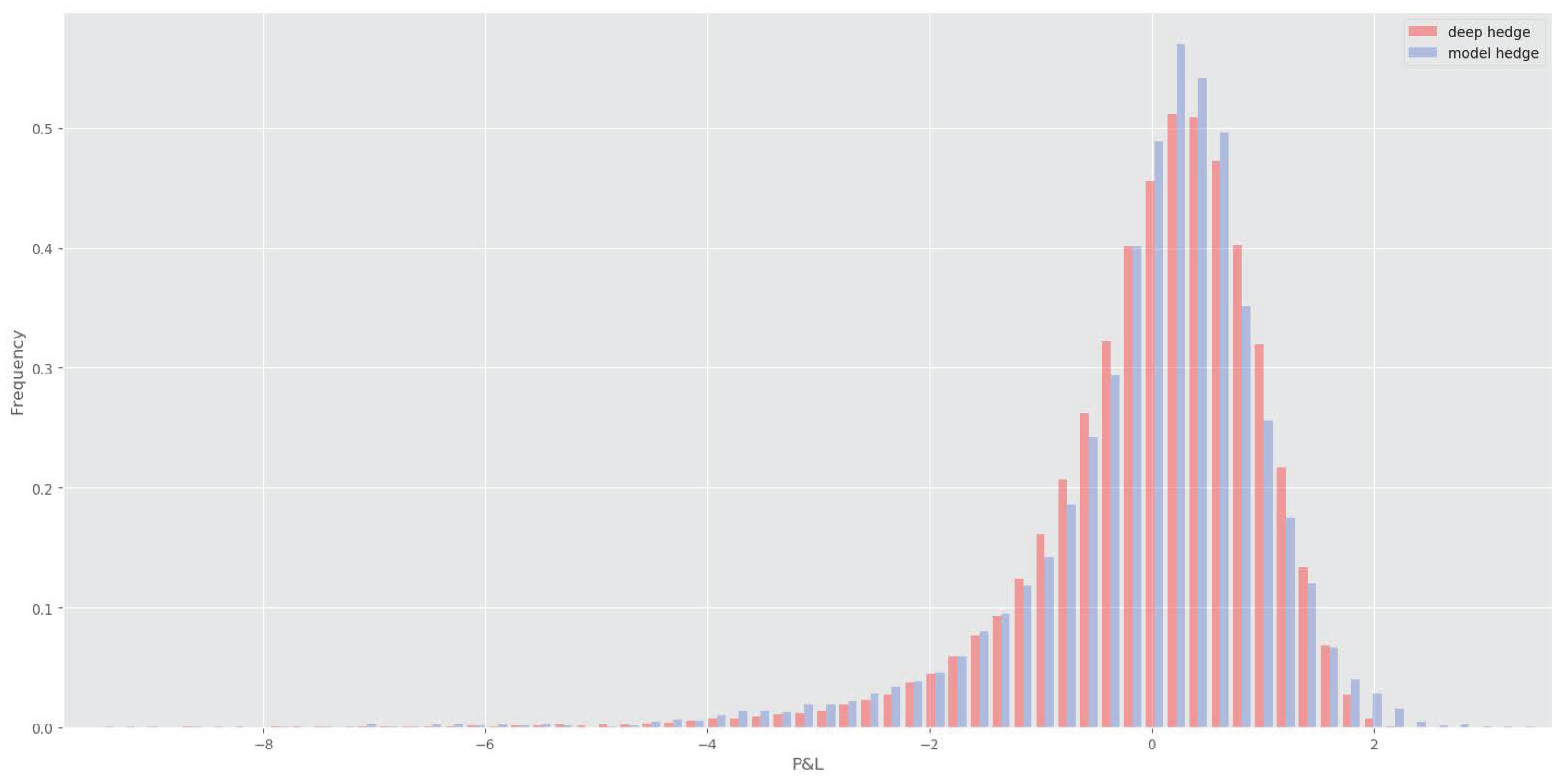
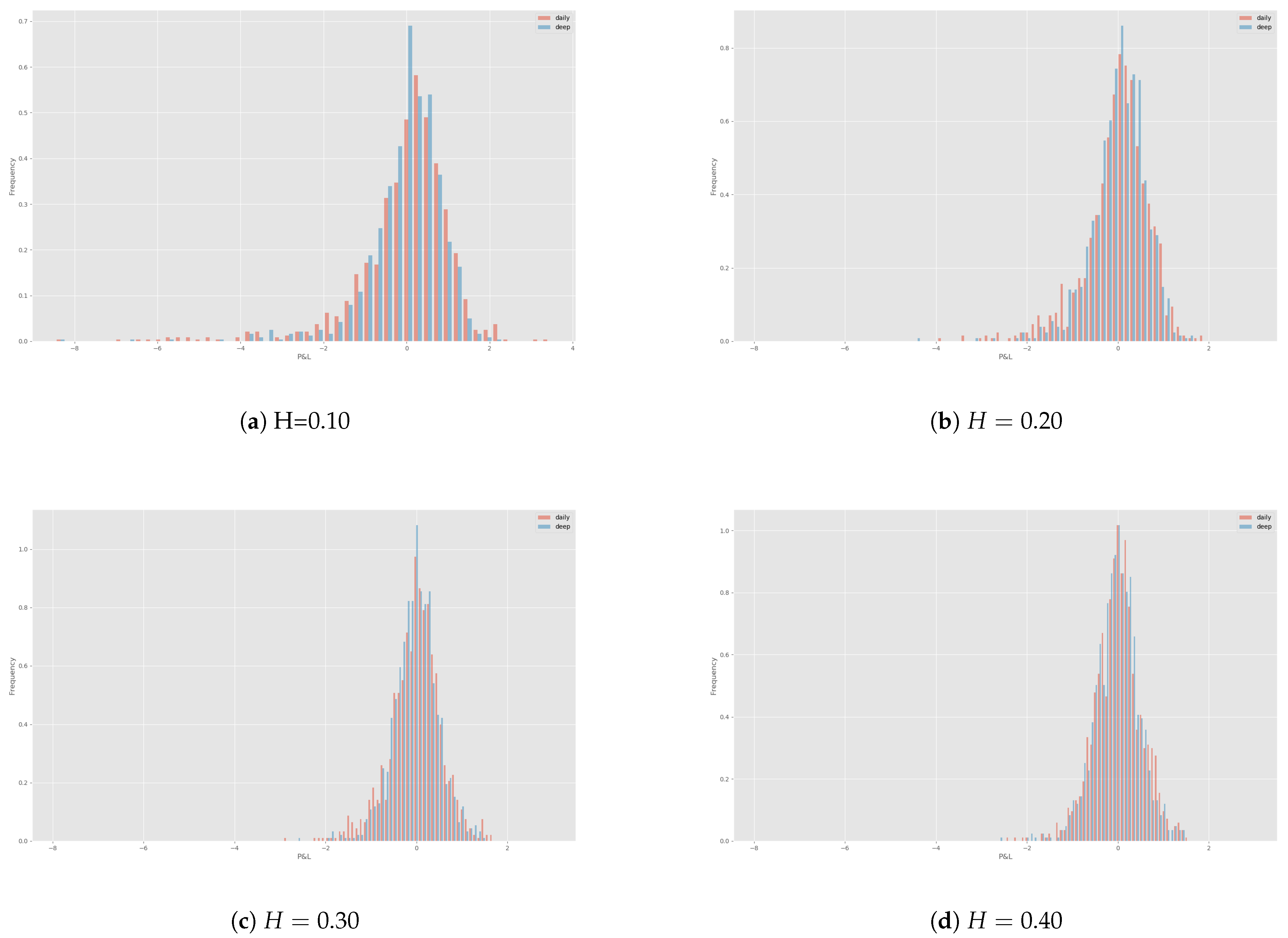
4.1. Deep Hedge under Rough Bergomi
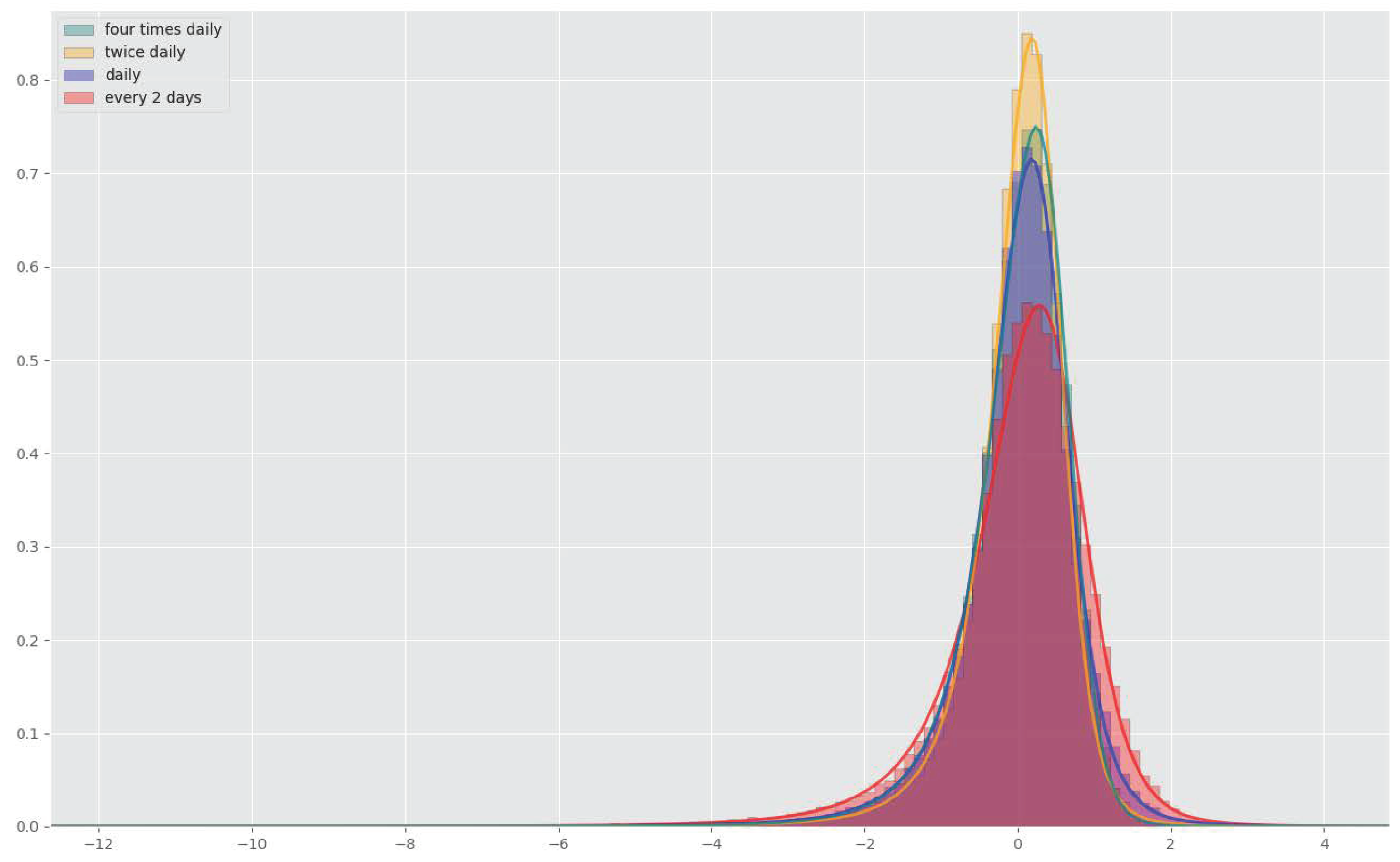
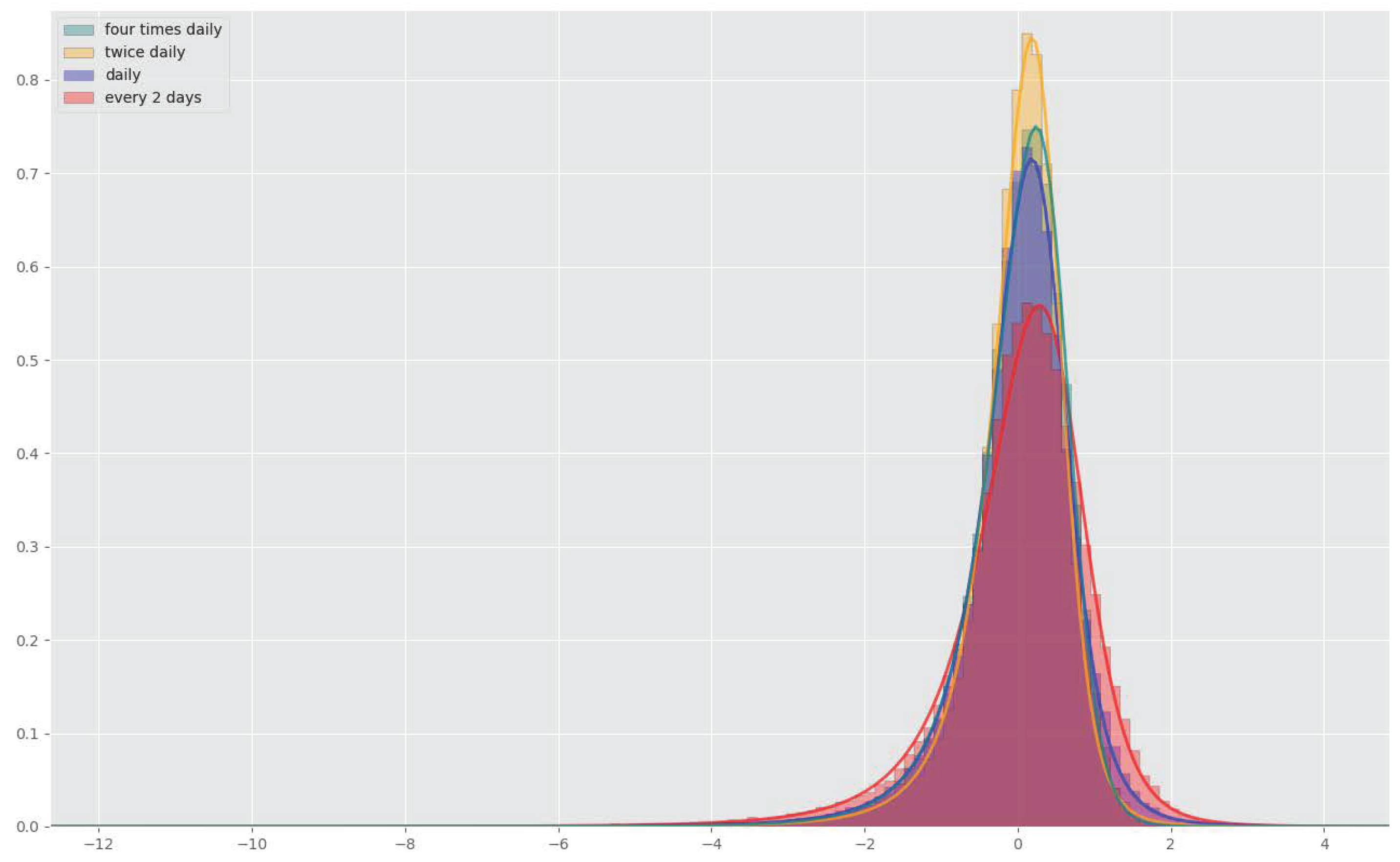
4.2. Rehedges
4.3. Relation to the Literature
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Path Derivatives
Appendix B. Functional Itô Formula
- i
- The SDE (5) admits a weak solution .
- ii
- for all .
- i
- (Regular case) For any , exist for and for ,
- ii
- (Singular case) For any , exists for with . There exists s.t., for some
Appendix C. Discretisation of the Gateaux Derivative
| 1 | For the numerical implementation of the resulting strategies that we consider in the following sections, we naturally consider again the discrete filtration introduced above in Section 2, representing a discretisation of the continuous market. |
| 2 | Several estimation procedures of the Hurst parameter were used; see, e.g., (Di Matteo 2007; Di Matteoet al. 2005). Estimations of the paths simulated with the hybrid scheme (Bennedsenet al. 2017; McCrickerd and Pakkanen 2018) were on the other hand in alignment with the input parameter. |
| 3 | Note that by completely recurrent we do not mean the same network is used at each time step, but that the hidden state is passed on to the cell in the next time step along with current portfolio positions. |
| 4 | For Heston parameters the quadratic losses were under original architecture and under the fully recurrent one. Both training times were fairly similar as well. |
| 5 | All the experiments were performed on a Dell-HQIQ2UV laptop with Intel i7-8550U CPU using TensorFlow v1.3. |
References
- Alòs, Elisa, Jorge A. León, and Josep Vives. 2007. On the short-time behavior of the implied volatility for jump-diffusion models with stochastic volatility. Finance and Stochastics 11: 571–89. [Google Scholar] [CrossRef] [Green Version]
- Bayer, Christian, Blanka Horvath, Aitor Muguruza, Benjamin Stemper, and Mehdi Tomas. 2019. On deep calibration of (rough) stochastic volatility models. arXiv arXiv:1908.08806. [Google Scholar]
- Bayer, Christian, Peter Friz, and Jim Gatheral. 2015. Pricing under rough volatility. Quantitative Finance 16: 887–904. [Google Scholar] [CrossRef]
- Bennedsen, Mikkel, Asger Lunde, and Mikko S. Pakkanen. 2017. Hybrid scheme for brownian semistationary processes. Finance and Stochastics 21: 931–65. [Google Scholar] [CrossRef] [Green Version]
- Benth, Fred Espen, Nils Detering, and Silvia Lavagnini. 2020. Accuracy of deep learning in calibrating HJM forward curves. arXiv arXiv:2006.01911. [Google Scholar]
- Bolko, Anine E., Kim Christensen, Mikko S. Pakkanen, and Bezirgen Veliyev. 2020. Roughness in spot variance? A GMM approach for estimation of fractional log-normal stochastic volatility models using realized measures. arXiv arXiv:2010.04610. [Google Scholar]
- Buehler, Hans, Blanka Horvath, Terry Lyons, Imanol Perez Arribas, and Ben Wood. 2020a. A data-driven market simulator for small data environments. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Buehler, Hans, Blanka Horvath, Terry Lyons, Imanol Perez Arribas, and Ben Wood. 2020b. Generating financial markets with signatures. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Buehler, Hans, Lukas Gonon, Josef Teichmann, and Ben Wood. 2019. Deep hedging. Quantitative Finance 19: 1271–91. [Google Scholar] [CrossRef]
- Carmona, Philippe, Gérard Montseny, and Laure Coutin. 1998. Application of a Representation of Long Memory Gaussian Processes. Publications du Laboratoire de statistique et probabilités. Toulouse: Laboratoire de Statistique et Probabilités. [Google Scholar]
- Cont, Rama, and David-Antoine Fournié. 2013. Functional itô calculus and stochastic integral representation of martingales. The Annals of Probability 41: 109–33. [Google Scholar] [CrossRef]
- Cuchiero, Christa, Martin Larsson, and Josef Teichmann. 2020. Deep neural networks, generic universal interpolation, and controlled ODEs. SIAM Journal on Mathematics of Data Science 2: 901–19. [Google Scholar] [CrossRef]
- Cuchiero, Christa, Wahid Khosrawi, and Josef Teichmann. 2020. A generative adversarial network approach to calibration of local stochastic volatility models. Risks 8: 101. [Google Scholar] [CrossRef]
- Di Matteo, Tiziana. 2007. Multi-scaling in finance. Quantitative Finance 7: 21–36. [Google Scholar] [CrossRef]
- Di Matteo, Tiziana, Tomaso Aste, and Michel M. Dacorogna. 2005. Long-term memories of developed and emerging markets: Using the scaling analysis to characterize their stage of development. Journal of Banking & Finance 29: 827–51. [Google Scholar]
- Dupire, Bruno. 2019. Functional itô calculus. Quantitative Finance 19: 721–29. [Google Scholar] [CrossRef]
- Fukasawa, Masaaki. 2010. Asymptotic analysis for stochastic volatility: Martingale expansion. Finance and Stochastics 15: 635–54. [Google Scholar] [CrossRef] [Green Version]
- Föllmer, Hans, and Alexander Schied. 2016. Stochastic Finance: An Introduction in Discrete Time. New York: De Gruyter. [Google Scholar]
- Gassiat, Paul. 2019. On the martingale property in the rough bergomi model. Electronic Communications in Probability 24. [Google Scholar] [CrossRef]
- Gatheral, Jim, Thibault Jaisson, and Mathieu Rosenbaum. 2018. Volatility is rough. Quantitative Finance 18: 933–49. [Google Scholar] [CrossRef]
- Gierjatowicz, Patryk, Marc Sabate-Vidales, David Šiška, Lukasz Szpruch, and Žan Žurič. 2020. Robust pricing and hedging via neural SDEs. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- He, Changhong, J. Shannon Kennedy, Thomas F. Coleman, Peter A. Forsyth, Yuying Li, and Kenneth R. Vetzal. 2007. Calibration and hedging under jump diffusion. Review of Derivatives Research 9: 1–35. [Google Scholar] [CrossRef] [Green Version]
- Henry-Labordere, Pierre. 2019. Generative models for financial data. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Hernandez, Andres. 2016. Model calibration with neural networks. Risk. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. Long short-term memory. Neural Computation 9: 1735–80. [Google Scholar] [CrossRef] [PubMed]
- Horvath, Blanka, Aitor Muguruza, and Mehdi Tomas. 2021. Deep learning volatility: A deep neural network perspective on pricing and calibration in (rough) volatility models. Quantitative Finance 21: 1. [Google Scholar] [CrossRef]
- Ilhan, Aytaç, Mattias Jonsson, and Ronnie Sircar. 2009. Optimal static-dynamic hedges for exotic options under convex risk measures. Stochastic Processes and their Applications 119: 3608–32. [Google Scholar] [CrossRef] [Green Version]
- Jacquier, Antoine, and Mugad Oumgari. 2019. Deep curve-dependent pdes for affine rough volatility. arXiv arXiv:1906.02551. [Google Scholar]
- Kac, Mark. 1949. On distributions of certain wiener functionals. Transactions of the American Mathematical Society 65: 1–13. [Google Scholar] [CrossRef]
- Kondratyev, Alexei, and Christian Schwarz. 2019. The market generator. Econometrics: Econometric & Statistical Methods - Special Topics eJournal. [Google Scholar] [CrossRef]
- Liu, Shuaiqiang, Anastasia Borovykh, Lech A. Grzelak, and Cornelis W. Oosterlee. 2019. A neural network-based framework for financial model calibration. Journal of Mathematics in Industry 9: 9. [Google Scholar] [CrossRef]
- Livieri, Giulia, Saad Mouti, Andrea Pallavicini, and Mathieu Rosenbaum. 2018. Rough volatility: Evidence from option prices. IISE Transactions 50: 767–76. [Google Scholar] [CrossRef]
- McCrickerd, Ryan, and Mikko S. Pakkanen. 2018. Turbocharging monte carlo pricing for the rough bergomi model. Quantitative Finance 18: 1877–86. [Google Scholar] [CrossRef] [Green Version]
- Pascanu, Razvan, Caglar Gulcehre, Kyunghyun Cho, and Yoshua Bengio. 2014. How to construct deep recurrent neural networks. Paper presented at Second International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14–16. [Google Scholar]
- Ruf, Johannes, and Weiguan Wang. 2020. Neural networks for option pricing and hedging: A literature review. The Journal of Computational Finance 24. [Google Scholar] [CrossRef]
- Schweizer, Martin. 1995. Variance-optimal hedging in discrete time. Mathematics of Operations Research 20: 1–32. [Google Scholar] [CrossRef]
- Sepp, Artur. 2012. An approximate distribution of delta-hedging errors in a jump-diffusion model with discrete trading and transaction costs. Quantitative Finance 12: 1119–41. [Google Scholar] [CrossRef]
- Viens, Frederi, and Jianfeng Zhang. 2019. A martingale approach for fractional brownian motions and related path dependent PDEs. The Annals of Applied Probability 29: 3489–540. [Google Scholar] [CrossRef] [Green Version]
- Wiese, Magnus, Lianjun Bai, Ben Wood, and Hans Buehler. 2019. Deep hedging: Learning to simulate equity option markets. arXiv arXiv:1911.01700. [Google Scholar] [CrossRef] [Green Version]
- Wiese, Magnus, Robert Knobloch, Ralf Korn, and Peter Kretschmer. 2020. Quant GANs: Deep generation of financial time series. Quantitative Finance 20: 1419–40. [Google Scholar] [CrossRef] [Green Version]
- Xu, Mingxin. 2005. Risk measure pricing and hedging in incomplete markets. Annals of Finance 2: 51–71. [Google Scholar] [CrossRef]
- Xu, Tianlin, Li K. Wenliang, Michael Munn, and Beatrice Acciaio. 2020. Cot-gan: Generating sequential data via causal optimal transport. arXiv arXiv:2006.08571. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quadratic Hedging Loss | ||
|---|---|---|
| Model Hedge | Deep Hedge | |
| 1.45 | 1.16 (*1.12) | |
| 0.52 | 0.67 | |
| 0.34 | 0.46 | |
| 0.24 | 0.36 | |
| Hurst Parameter | ||||||||
|---|---|---|---|---|---|---|---|---|
| H | ||||||||
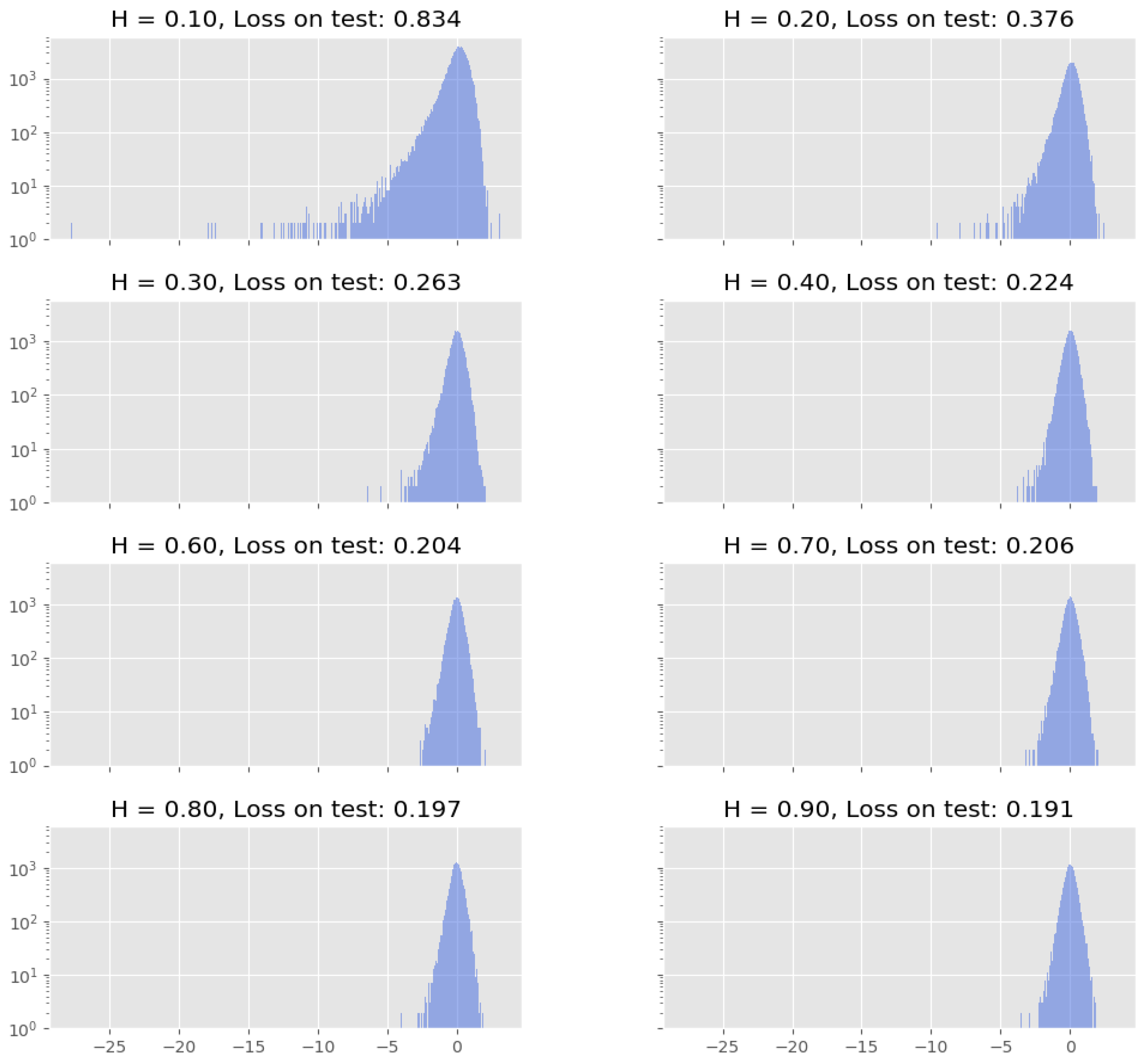
| Quad. loss | 0.834 (*0.628) | 0.376 | 0.263 | 0.244 | 0.204 | 0.206 | 0.197 | 0.191 |
| Quadratic Hedging Loss | |||
|---|---|---|---|
| Model Hedge | Deep Hedge | Deep Hedge—fRNN | |
| 1.45 | 1.16 (*1.12) | 0.83 (*0.63) | |
| 0.52 | 0.67 | 0.38 | |
| 0.34 | 0.46 | 0.26 | |
| 0.24 | 0.36 | 0.22 | |
| Rehedging Frequency | ||||
|---|---|---|---|---|
| Every Two Days | Daily | Twice Daily | Four Times Daily | |
| Quadratic loss | 1.11 | 0.65 | 0.46 | 0.52 |
| Training time (h) | 3.1 | 7.5 | 19.6 | 45.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Horvath, B.; Teichmann, J.; Žurič, Ž. Deep Hedging under Rough Volatility. Risks 2021, 9, 138. https://doi.org/10.3390/risks9070138
Horvath B, Teichmann J, Žurič Ž. Deep Hedging under Rough Volatility. Risks. 2021; 9(7):138. https://doi.org/10.3390/risks9070138
Chicago/Turabian StyleHorvath, Blanka, Josef Teichmann, and Žan Žurič. 2021. "Deep Hedging under Rough Volatility" Risks 9, no. 7: 138. https://doi.org/10.3390/risks9070138
APA StyleHorvath, B., Teichmann, J., & Žurič, Ž. (2021). Deep Hedging under Rough Volatility. Risks, 9(7), 138. https://doi.org/10.3390/risks9070138