1. Introduction
During the last few decades, credit quality emerged as an essential indicator for banks’ lending decisions (
Thomas et al. 2017). Numerous elements reflect the borrower’s creditworthiness, and the use of credit scoring mechanisms could moderate the estimation of the probability of default (PD) while predicting the individual’s payment performance. The existing literature concentrates on understanding why organizations’ lending mechanisms are successful at decreasing defaults or addressing the issues from an economic theory perspective; see, e.g.,
Brau and Woller (
2004);
Jarrow and Protter (
2019). More specifically,
Demirgüç-Kunt et al. (
2020) reported that almost one-third of the world’s adult population were unbanked, according to a 2017 world bank report. Therefore, they rely on micro-finance institutions’ services.
Jarrow and Protter (
2019) acknowledged the gap in the existing literature on how to determine fair lending rates in micro-finance, which would be granting lending access (or credit) to low-income populations excluded from traditional financial services.
Credit scoring refers to the process of evaluating an individual’s creditworthiness that reflects the level of credit risk and determines whether an application of the individual should be approved or declined (
Thomas et al. 2017). Financial lending services assess credit risk by employing decision models and techniques. These institutions assess the level of risk required to meet their financial obligations (
Zhao et al. 2015). Credit scoring is essential in a micro-lending context, although a lack of credit history and sometimes even a bank account requires innovative ways to assess an individual’s creditworthiness. Financial institutions and non-bank lenders who regularly provide credit information on their customers’ accounts to the credit bureau can obtain credit information reports from the bureau to appraise new loan applications’ creditworthiness and examine accounts on pay-per-use fees and a membership fee. However, the statutory framework for credit reporting access data varies from country to country. Thus, depending on the jurisdiction, borrower permission might be required to provide data to the bureau and access a credit report (
IFC 2006). However, for unbanked customers, such a centralized record of past credit history is often missing. A growing group of quantitative and qualitative techniques has been developed to model these credit management decisions in determining micro-lending scoring rates by considering various credit elements and macroeconomic indicators. Early studies have attempted to address the issue mainly by employing linear or logistic regression (
Provenzano et al. 2020). While such models are commonly fitted to generate reasonably accurate estimation, these early era techniques have been succeeded by machine learning techniques that have been extensively applied in various scientific disciplines, for example, medicine, biochemistry, meteorology, economics, and hospitality. For example,
Ampountolas and Legg (
2021);
Aybar-Ruiz et al. (
2016);
Bajari et al. (
2015);
Barboza et al. (
2017);
Carbo-Valverde et al. (
2020);
Cramer et al. (
2017);
Fernández-Delgado et al. (
2014);
Hutter et al. (
2019);
Kang et al. (
2015);
Zhao et al. (
2017) have reported applications of machine learning in a variety of fields and achieved staggering results. In credit scoring, in particular,
Provenzano et al. (
2020) reported good estimation results using machine learning.
Similarly, numerous studies on the applicability of machine learning techniques have been implemented in other areas of finance due to their ability to recognize a set of financial data trends; see, e.g.,
Carbo-Valverde et al. (
2020);
Hanafy and Ming (
2021). Related studies indicated that a combination of machine learning methods could offer high credit scores accuracy; see, e.g.,
Petropoulos et al. (
2019);
Zhao et al. (
2015). Nowadays, credit risk assessment has become a rather typical practice for financial institutions, with decisions generally received based on the borrowers’ credit history. However, the situation is rather different for institutions providing micro-finance services (micro-finance institutions—MFIs).
The novelty in this research is a classifier that indicates the creditworthiness of a new customer for a micro-lending organization. For such organizations, third-party information on consumer creditworthiness is often unavailable. We propose to evaluate credit risk using a combination of machine and deep learning classifiers. Using real data, we compared the accuracy and specificity of various machine learning algorithms and demonstrated these algorithms’ efficacy in successfully classifying customers into various risk classes. This is the first empirical study to examine the use of machine learning for credit scoring in micro-lending organizations in the academic literature to the best of the authors’ knowledge.
In this assessment, we have compared seven machine and deep learning models to quantify the models’ estimation accuracy when measuring individuals’ credit scores. In our experiments, ensemble classifiers (XGBoost, Adaboost, and random forest) exhibited better classification performance in terms of accuracy, about 80%, whereas the popular multilayer perceptron model yielded about 70% accuracy. We tuned the classifier’s hyperparameters to obtain the best possible decision boundaries for better institutional micro-lending assessment decisions for all the classifiers. While these experiments were for a single dataset, they point to micro-lending institutions’ choices in terms of off-the-shelf machine learning algorithms for assessing the creditworthiness of micro-loan applicants.
This research is organized as follows:
Section 2 provides an overview of prior literature on each machine learning technique we employ to evaluate credit scoring. Even though these techniques are standard, we provide an overview here for completeness of discussion. In
Section 3, we introduce the research methodology and data evaluation.
Section 4 presents the analytic results of the various machine learning techniques, and in
Section 5, we discuss the results. Finally,
Section 6 contains the research conclusions.
3. Methodology
3.1. Data Collection
The data used in this paper were obtained from Innovative Microfinance Limited (IML), a micro-lending institution in Ghana. It started operating in 2009. The data are an extract of information that IML could make available to us on micro-loans from January 2012 to July 2018, during a period of economic and political stability. During this period, the market’s liquidity risk was the most significant risk (
Johnson and Victor 2013). A total sample size of 4450 customers was extracted, but 46 rows were entirely deleted due to many missing values in those rows. The data fundamentally consist of customer information, such as demographic information, amount of money borrowed, frequency of loan repayment (weekly or monthly), outstanding loan balance, number of repayments and number of days in arrears. To reduce the level of variability in the loan amount, we took the logarithm of it and named the new variable “log amount”. Additionally, given the fact that the micro-loans have different periods of repayment and frequency of repayment, all interest rates were annualized to take care of these differences by bringing them to a common denominator in terms of time.
Table 1 below is a list of the variables used in this paper to fit our classification models.
3.2. Definitions of Risk Classes
In this paper, we consider three risk classes for the multi-class classification problem. A risk is considered “good” if the customer is not in arrears or is in arrears for less than 30 days; it is considered “average” if the customer is in arrears between 30 and 91 days; finally, it is considered “poor if the customer is in arrears for more than 91 days.
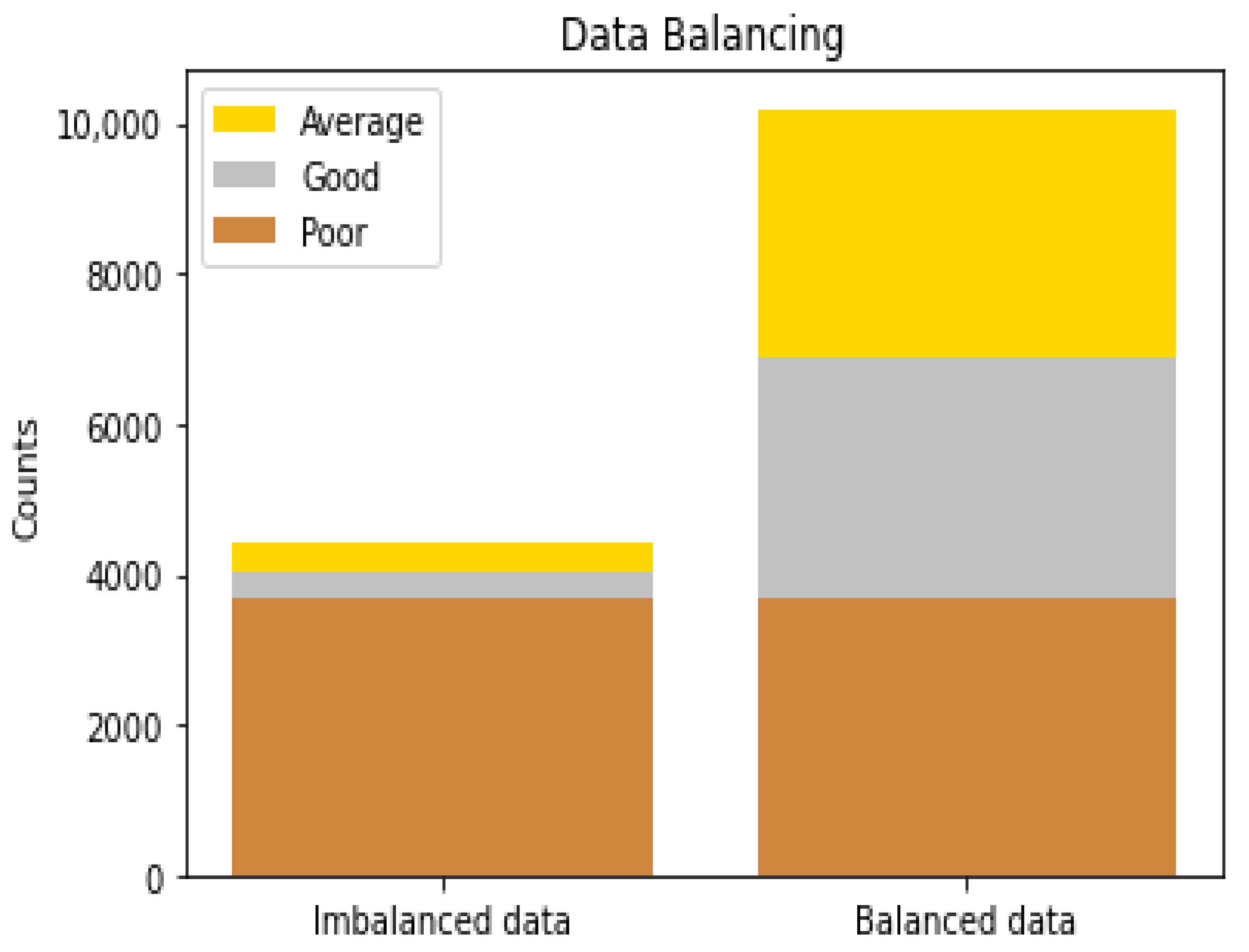
3.3. Data Balancing
After classifying all customers into the various risk classes, we encountered an imbalance data situation wherein 83.72% of the entire data set belonged to the poor risk class. In such a case, the danger is that any model fitted to the data might end up predicting the majority risk class all the time, even though the model diagnostics show that the model is good. To address this class imbalance condition, we adopted the machine learning synthetic minority over-sampling technique for nominal and continuous (SMOTENC for short) to over-sample the minority classes to achieve fair representation for all classes in the data set. After this, the majority class constituted only 36.19% of the data set.
Figure 1 shows the nature of the data set before and after applying the SMOTENC algorithm:
3.4. Training–Test Set Split
For all the models fitted in this study, we split the balanced data into 80% for the training set and 20% for the testing set (validation). Unless otherwise stated, all analyses presented in this paper were done using the Python programming language.
3.5. Summary Statistics of Features
Table 2 presents the summary statistics of the numerical features used in this paper. A second quartile (median) value of 31 for age implies that 50% of customers are 31 years old or younger, while the remaining 50% are more than 31 years old. Meanwhile, 25% of customers are 26 (first quartile) years old or younger, and about 75% are 58 years old (third quartile) or younger. A positive skewness for age means that most customers are below the mean age. This also explains why the median age is lower than the mean age. Additionally, a negative excess kurtosis implies that age distribution is platykurtic in nature (i.e., it has a flat top, a plateau). Thus, the distribution is less peaked than that of the Gaussian distribution. The explanations given for the descriptive statistics of age can be transferred (in a parallel sense) to explain that of the remaining features.
Note that even though annualized rate is positively skewed, the original interest rates (i.e., before they were annualized) have negative skewness, which means most customers pay an interest rate higher than the mean value. However, this conclusion could be biased, given that the micro-loans have varying durations and frequencies of payment. Hence, this paper adopted annualized rate. Loan amount had a standard deviation of 4169.1886, which negatively influenced the classifiers, most likely due to the wide dispersion. Therefore in this paper, log amount was used instead.
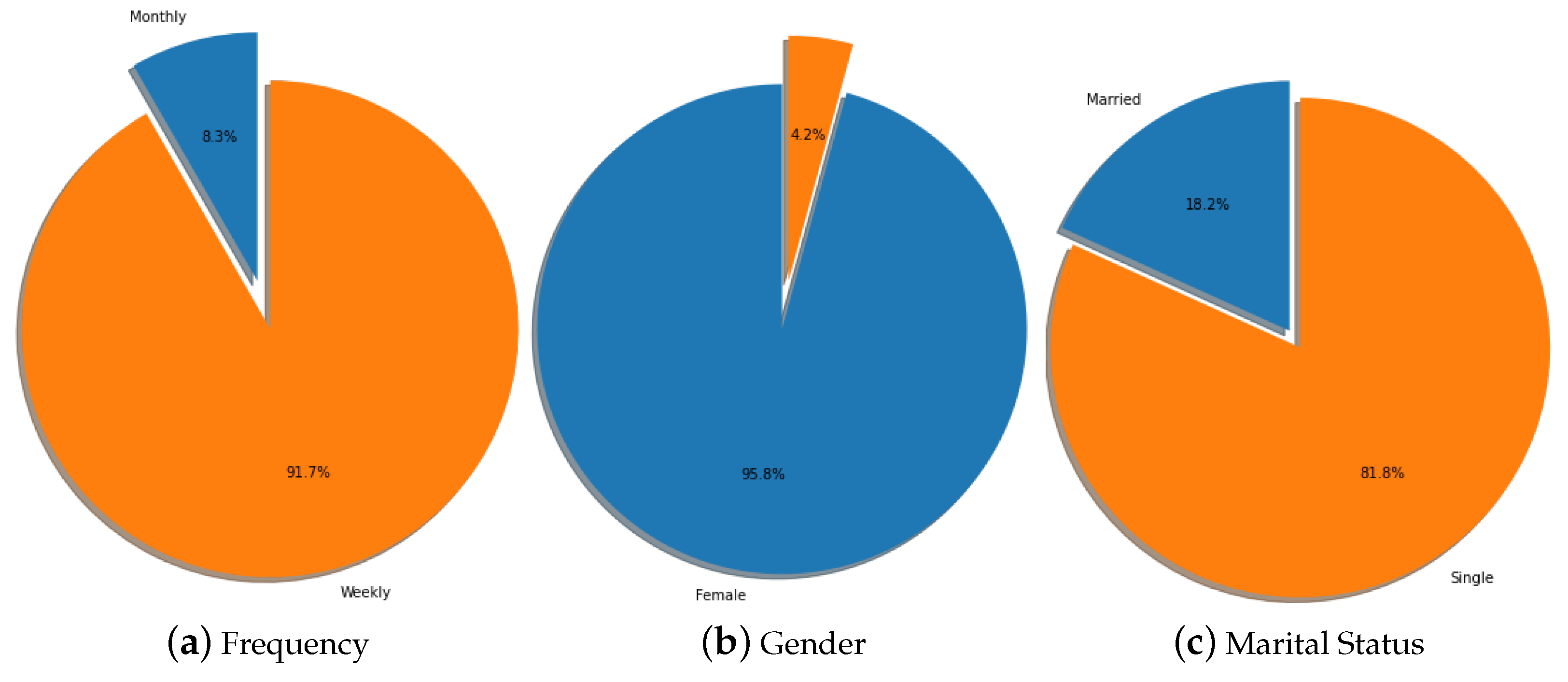
For the categorical features, we used each category’s proportions to describe them as shown in
Figure 2 below.
In
Figure 2 above, gender is the most disproportionate feature, with the majority being women. This is not surprising because previous studies have shown that about 75% of micro-credit clients worldwide are women and have proven to have higher repayment rates, and will usually accept micro-credit more easily than men (
Chikalipah 2018). For example, Grameen Bank currently has 96.77% of its customers being women due to the extensive micro-credit services it offers (
Grameen Bank 2020).
3.6. Feature Selection
The dataset had more variables than those used in this paper. Some of the variables were of no use to us, such as customer ID which is simply a unique customer identifier for all customers in the data. Other variables, such as date of birth, date disbursed, and date due were not used. However, we did calculate the age feature from the date of birth and date disburse by finding the difference in days between the date on which the loan was issued to each customer and birth date. The number of days was then divided by days to obtain the age in years at the time of issuing the micro-loan. The choice of days was to capture leap year effects in the age calculations. Additionally, note that to obtain the age at which a customer joined the scheme, the curtated age (i.e., the whole number part of the age) was considered; the fractional (i.e., decimal) part of the age was ignored. We chose to use the customers’ personal information, which included age, gender, and marital status, as our first choice of features.
Outstanding loan balance was not used because for a new customer the outstanding loan balance is the same as the loan amount. Moreover, there is a high positive linear correlation of 0.97 between these two variables. Eliminating one of them from the model helped to remove the confounding effect from the models. This confounding effect is a result of the presence of multicollinearity between these features. In such a situation, one of the features becomes redundant. Eliminating one such feature from the models helps prevent them from overfitting or underfitting, which avoids the case where a small change in the data leads to a drastic effect on the model in question. Some authors hold the notion that the multicollinearity effect is tamed in machine learning models, but it still has some effect on the models; besides, this notion is not widely accepted.
After this, frequency, interest rates, and number of repayments were then added to the set of features, since they were the only remaining variables that could be used as predictors. As explained earlier, log amount and annualized rate were used instead of amount and interest rate.
4. Results
In this section, we present analytic results of the various machine learning models adopted in this paper. All model diagnostic metrics in this paper are based on the validation/test set.
4.1. Prediction Accuracy
The idea here was to determine which model performs best with our data, and as a first step, we considered each model’s overall out-of-sample prediction accuracy on the test set. Note that as a rule of thumb, it is advisable to use the global f1-scores for model comparison instead of the accuracy metric; however, in our case, the two metrics were the same for all classifiers. The results are shown in the table below:
From
Table 3, the least performing model in terms of prediction accuracy was the artificial neural network multilayer perceptron. Unlike the popular opinion held about neural network models in the literature, the predictive power did not improve irrespective of the number of hidden layers and/or hidden nodes. However, note that the best performing models were the machine learning ensemble classifiers (random forest, XGBoost, and Adaboost). XGBoost and Adaboost slightly outperformed the random forest classifier. Note that apart from the out-of-sample prediction accuracy on the validation set, other model diagnostic metrics such as confusion matrix, receiver operating characteristic (ROC) curve, area under the curve (AUC), f1-score, precsion, and recall showed that the ensemble classifiers performed better with our data set than the rest of the models. Therefore, for the rest of this paper, we concentrate our analyses on the ensemble classifiers.
4.2. Confusion Matrix
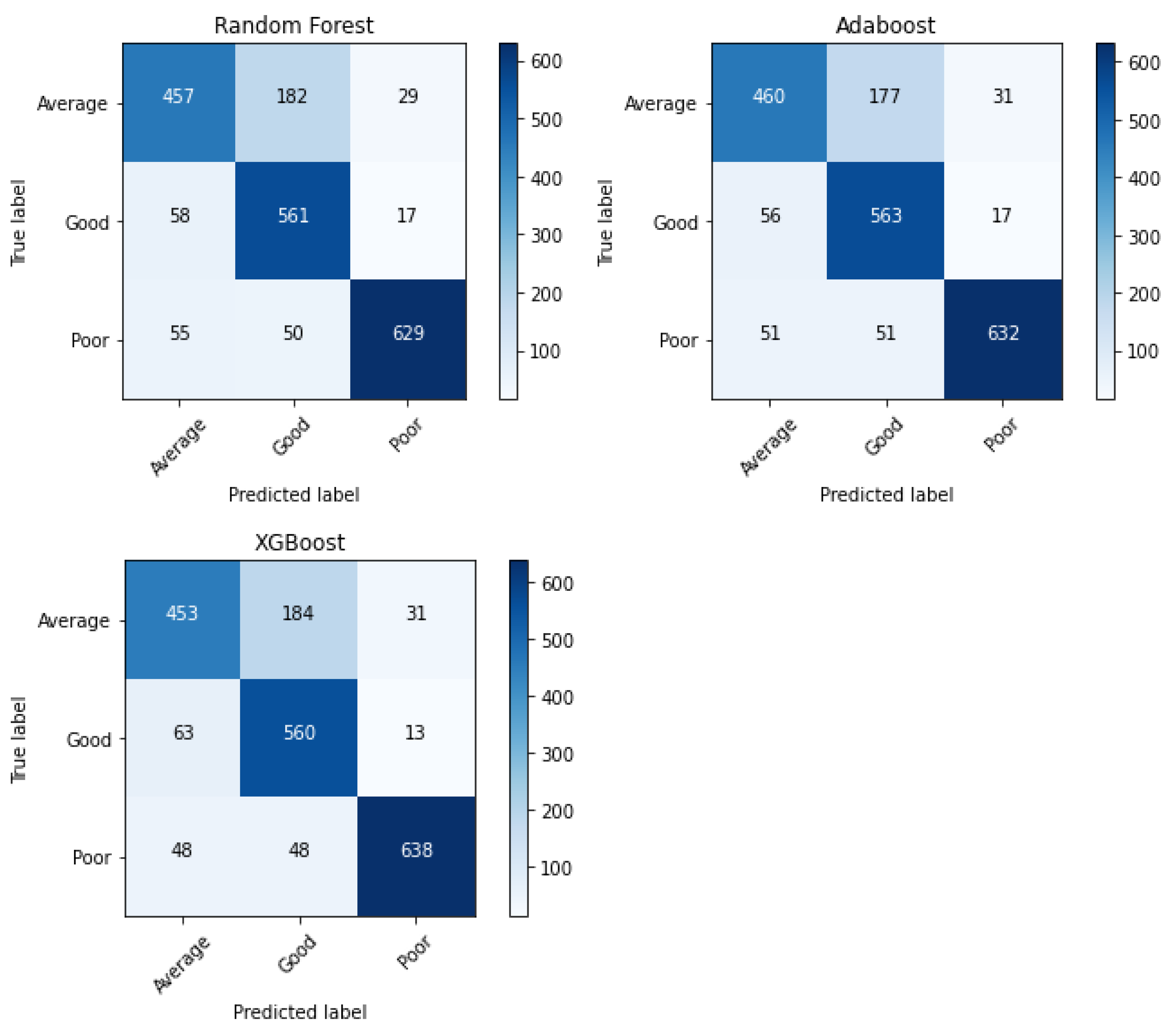
There is a need to look at the confusion matrix to assess a classification model’s quality of classification. For an ideal confusion matrix, we expect to get values only on the leading/principal diagonal, since they represent correct classification; values off-diagonal are those that were misclassified. Hence,
Figure 3 illustrates the confusion matrix for each of our ensemble classifiers.
Figure 3 above shows that most of the values lie along the principal diagonal for all the ensemble classifiers, and the more values we record on the principal diagonal, the more evidence we have of correct classification. However, one thing that is easily noticeable is that most of the misclassifications are recorded between the average and good risk classes for all the classifiers. This is most likely because the decision boundary between the two classes is not so visible; hence, the classifiers cannot easily identify it, leading to some misclassifications between the two classes. However, for each classifier, the hyperparameters were tuned to obtain the best possible model that could quickly and easily identify the decision boundaries for a better classification experience.
4.3. Classification Report
In this subsection, we examine each classifier’s precision, recall, and f1-score.
Hence,
Table 4 below presents the classification report for the XGBoost model. Note that precision is the ratio of predicted values of a risk class that actually belong to that class to all values. In any of the confusion matrices above, it is the ratio of the values on the leading diagonal to the sum of all values in that column. Recall (true positive rate), on the other hand, is a ratio of the actual values of a risk class that were actually predicted as belonging to that class. Precision and recall usually have inverse relations, and the f1-score is a metric that measures both precision and recall together; it presents a combined picture of both precision and recall. It is a harmonic mean of the two metrics. Support is the actual number of occurrences of a particular risk class in the data set (usually the validation data). The accuracy parameter is simply the overall predictive power of the classifier. It is simply the ratio of the sample data that the classification model correctly classified. In each of the confusion matrices above, the sum of all elements on the principal diagonal is divided by the sum of all elements in the confusion matrix to obtain each classifier’s accuracy. The micro-average metric is the arithmetic mean of the precision, recall, and f1-scores, while the weighted average computes the weighted average of the precision, recall, and f1-scores. Note that these two metrics (micro-average and weighted average) compute precision, recall, and f1-score globally for the classifier. Global support is the sum of the individual supports for each risk class. The explanation given above for the XGBoost classifier can be mirrored for the random forest and AdaBoost classifiers; therefore, we present the same metrics for the random forest and AdaBoost classifiers in
Table 5 and
Table 6 below. Note that the three ensemble classifiers have identical values for all the model diagnostic metrics.
4.4. Sensitivity Analysis
Here we present the receiver operating characteristic (ROC) curves and their respective areas under the curve (AUCs). ROC curves and AUCs are used to measure the quality of a classifier’s output; thus, they measure how correctly a classifier has been tuned. Movement along the ROC curve is typically a trade-off between the classifier’s sensitivity (true positive rate (TPR)) and specificity (TNR), and the steeper the curve, the better. For the ROC curve, sensitivity increases as we move up, and specificity decreases as we move right. The ROC curve along a 45
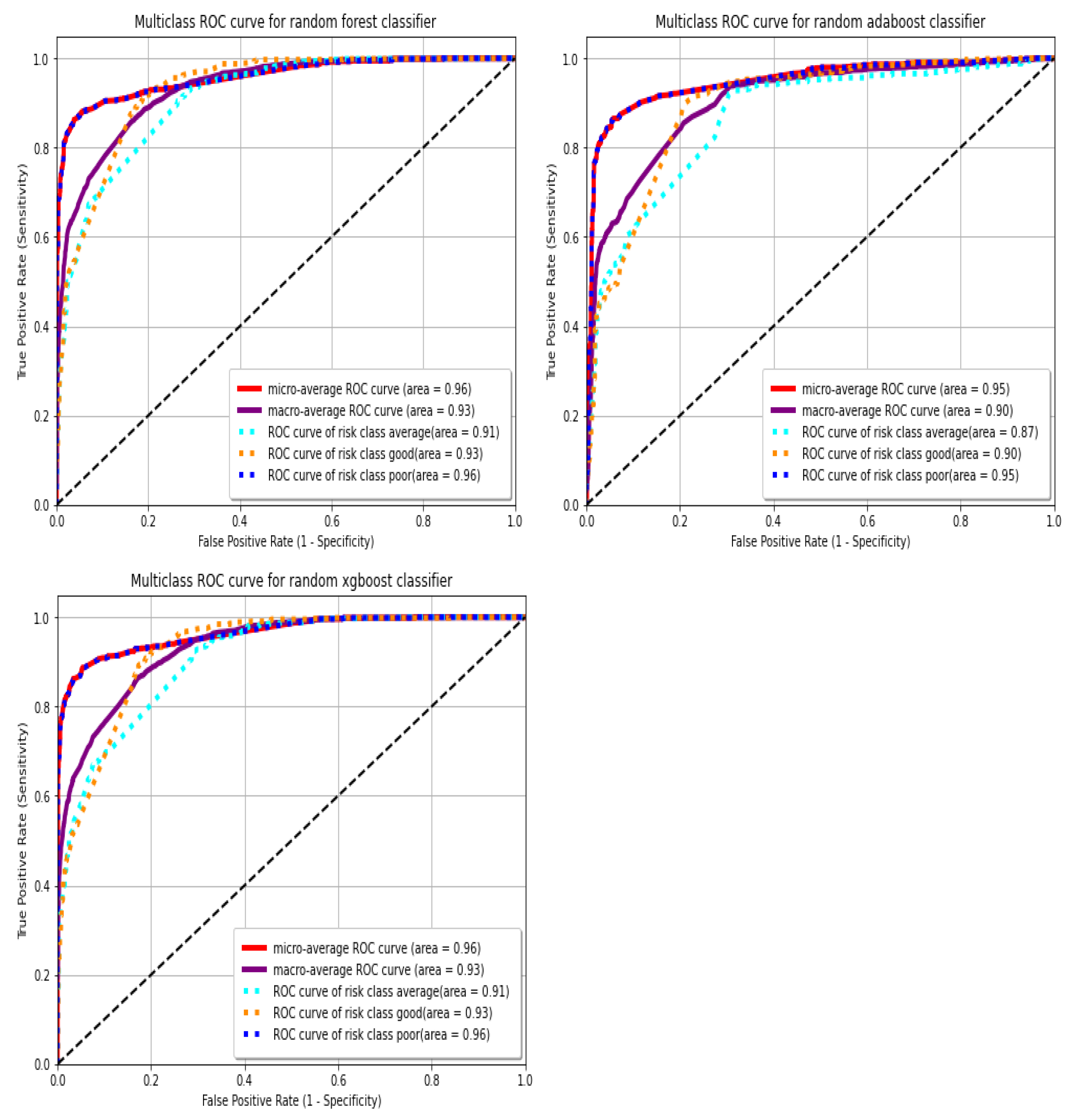
angle is as good a tossing a coin (i.e., a classifier as good as a random guess). Additionally, the closer the AUC is to 1, the better it is. Consider the figures below (
Figure 4):
In
Figure 4, for each classifier, we show the ROC curve and AUC for each risk class. ROC curves are typically for binary classification, but we used them pairwise for each class for multiclass classification. We adopted the one-versus-rest approach. This approach evaluates how best each classifier can predict a particular risk class against all other risk classes. Hence, we have an ROC curve and AUC for each class against the rest of the classes, and the unweighted averages of all these ROC curves and AUCs are the global (macro) ROC curve and AUC for that classifier; this means each risk class is treated with an equal weight of
if there are
k classes. The micro-average metric is a weighted average taking into effect the contribution of each risk class. It calculates a single performance metric instead of several performance metrics that are averaged in the case of a macro-averaged AUC. Mostly, in a multiclass classification problem, the micro-average is desired if there is a class imbalance situation (i.e., if the main concern is the overall performance on the data and not any particular risk class in question). In that case, the micro-average tends to bring the weighted average metric closer to the majority class metric. However, in this paper, the class imbalance problem was taken care of, even before fitting the classification models. The results for each classifier are shown in
Figure 4 above. The ROC curves and AUCs for all the ensemble classifiers look quite good, as the ROC curves are high above the 45
line, and the AUCs are high above the 0.5 (random guess) threshold. This is an indication that our ensemble classifiers have good predictive power, far better than random guessing. Note that the ROC curves and AUCs presented for all the classifiers above are based on the validation/test set.
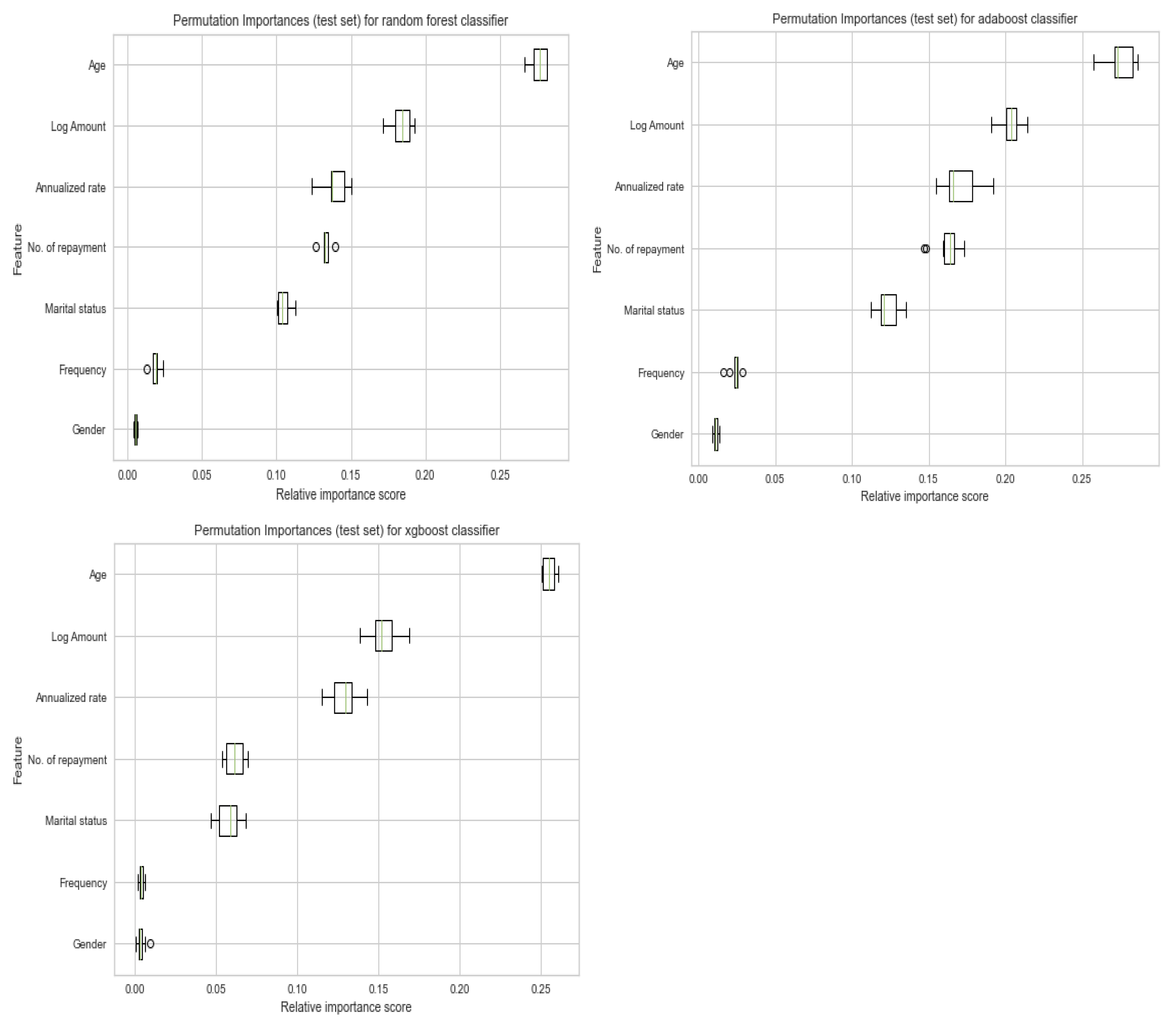
4.5. Feature Importance
In this subsection, we evaluate the relative importance of each predictive variable in predicting default. Consider the
Figure 5 below:
Figure 5 above adopted the permutation importance score (on the validation/test set) to evaluate our predictive features’ relative importance in predicting defaults on micro-loans. The choice of permutation importance score is due to its ability to overcome the impurity-based feature importance score’s significant drawbacks. As revealed in the Scikit Learn documentation, the impurity-based feature importance score suffers from two major drawbacks. First of all, it gives priority to features with many distinct elements (i.e., features with very high cardinality); hence, it favors numerical features at the expense of categorical features. Secondly, it is based on the training set. It, therefore, does not necessarily reflect a feature’s importance or contribution when making predictions on an out-of-sample data set (i.e., test set)—thus, the documentation states, “The importances can be high even for features that are not predictive of the target variable, as long as the model has the capacity to use them to overfit”.
For all our classifiers, the top three most important features in predicting default on micro-loans are age, log amount, and annualized rate. We also realized that numerical features have more relative importance in predicting default than categorical features for all the classifiers.
4.6. Tuning of Hyperparameters
In this subsection, we present the optimal hyperparameters obtained for each of the top three ensemble classifiers. Consider the
Table 7 below:
Note that for all the classifiers, default values were used for any hyperparameters not listed in the table above. For all the classifiers, the hyperparameter “number of estimators” has proven to be very crucial in getting optimal accuracy. The hyperparameter “eta/learning rate” has also shown great importance in the XGBoost and AdaBoost classifiers. It is noticed that there is a trade-off between learning rate and number of estimators for the boosting classifiers (i.e., there is an inversely proportional relationship between them). Additionally, note that by keeping all other optimal parameters constant, model accuracy increases with an increasing number of estimators until it reaches the point of the optimal values reported in
Table 7 above. Above this level, the accuracy starts to reduce such that if it were plotted, it would have a bell shape. This holds for the top three ensemble classifiers presented in this paper.
5. Discussion
This paper evaluated the usefulness of machine learning models in assessing defaulting in a micro-credit environment. In micro-credit, there is usually no central credit database of customers and very little to no information at all on a customer’s credit history; this situation is predominant in Africa, where we got our data from. This makes it hard for micro-lending institutions to determine whom to deny or not deny micro-loans. To overcome the drawback, this paper demonstrates that machine learning algorithms are powerful in extracting hidden information in the data set, which helps to assess defaults in micro-credit. All performance metrics adopted in this paper were those based on the validation/test set. The data imbalance situation in the original data set was solved using the SMOTENC algorithm. Several machine learning models were fitted to the data set, but this paper reported only those models that recorded overall accuracy of 70% or higher on the validation set. Most of the models reported in this paper are tree-based algorithms, possibly because we have many categorical features in our data set, and tree-based classifiers have been known to generally work better with such data sets than other machine learning algorithms that are not tree-based. Among the models reported in this paper, the top three best performing classifiers (random forest, XGBoost, and Adaboost) are all ensemble classifiers and tree-based algorithms as well. It might be the case that tree-based algorithms are powerful for predicting defaulting in a micro-credit environment. All ensemble classifiers reported an overall accuracy of at least 80% on the validation set. Other performance measures adopted also revealed that the ensemble classifiers have good predictive power in assessing defaults in micro-credit (as shown in
Section 4.2,
Section 4.3 and
Section 4.4). We adopted multiclass classification algorithms because they give us an extra advantage of having the average risk class so that customers predicted to be in that class can be further investigated regarding to whether to deny or offer them micro-loans.
It is good to note that annualized rate was among the top three most important features for predicting default. This is in line with the works of
Bhalla (
2019);
Conlin (
1999);
Jarrow and Protter (
2019), which point out that exploitative lending rates are one of the main causes of defaulting in micro-credit. We also noticed that even though loan repayment frequency is among the least important features, the number of repayments counts very much in assessing defaulting in micro-credit situations. This is also in line with the MSc thesis of Titus Nyarko Nde who discovered that defaults on micro-loans tend to worsen after six months, by which time customers become tired of repaying their loans, and he recommended that the duration of repayment of micro-loans should not exceed six months. Gender was the least important feature for predicting defaulting for all the classifiers. This was most likely due to the fact that the feature gender was made up of almost only women. This is also in line with the aforementioned MSc thesis, wherein gender was the only insignificant feature for predicting survival probabilities in the Cox proportional hazard model.
This paper also discovered that numerical features had more relative importance for predicting defaults on micro-loans than categorical features for the top three ensemble classifiers.
Having access to real-life data is usually not an easy task, and most articles usually use online data sets (such as the Iris data set and the Pima Indians onset of diabetes data set) that are already prepared into some format to work well with most machine learning algorithms. However, in this paper, we demonstrated that machine learning algorithms could predict defaulting on a real-life data set of micro-loans. Our case was that the available literature on credit risk modeling has not given much attention to credit risk in a micro-credit environment to the best of the authors’ knowledge, which is what we have done. Those factors make this paper unique.
Based on this paper’s findings, future studies will focus on how to derive fair lending rates in a micro-credit environment to avoid exploiting people who patronize micro-credit. This is because much attention has not been given to this topic in the micro-credit environment in the literature; see, e.g.,
Jarrow and Protter (
2019). Additionally, note that all the algorithms adopted in this paper are static in nature and do not consider the temporal aspects of risk. In other words, we did not predict how long a customer will spend in the assigned credit class (“poor”, “average”, or “good”). If we can predict the average time to credit migration from one risk class to another, the lender can take into account loan duration and/or interest rates. Future studies will adopt other algorithms that are able to predict the expected duration of an event before it occurs. Ghana’s economy was stable during the period of the data. However, future studies will consider incorporating macroeconomic variables such as inflation and unemployment rate into our models to predict defaults in a micro-credit environment. We will also consider the influences of economic shocks, such as global pandemics (such as COVID-19), on micro-credit scoring.
6. Conclusions
This research evaluated individuals’ credit risk performance in a micro-finance environment using machine learning and deep learning techniques. While traditional methods utilizing models such as linear regression are commonly adopted to estimate reasonable accuracy nowadays, these models have been succeeded by extensive employment of machine and deep learning models that have been broadly applied and produce prediction outcomes with greater precision. Using real data, we compared the various machine learning algorithms’ accuracy by performing detailed experimental analysis while classifying individuals’ requesting a loan into three classes, namely, good, average, and poor.
The analytic results revealed that machine learning algorithms are capable of being employed to model credit risk in a micro-credit environment even in the absence of a central credit database and/or credit history. Generally, tree-based machine learning algorithms have shown a better performance with our real-life data than others, and the most performing models are all ensemble classifiers.
Bajari et al. (
2015);
Carbo-Valverde et al. (
2020);
Fernández-Delgado et al. (
2014) found that the Random Forest classifier generated the most accurate prediction. Our study on a specific data set demonstrates that XGBoost, AdaBoost, and random forest classifiers perform with roughly the same prediction accuracy (within 0.4%). Overall prediction accuracy of at least 80% (on the validation set) for these ensemble classifiers on a real-life data set is very impressive. Numerical features generally have shown to have higher relative importance when predicting default on micro-loans than categorical features. Additionally, interest rates have been listed among the top three most significant features for predicting defaulting, and this has become one of our next research focus: to come up with a way to avoid exploitative lending in a micro-credit environment. Moreover, the algorithms adopted in our paper are more affordable in terms of implementation such that micro-lending institutions, even in the developing world, can easily adapt them for micro-credit scoring.
This study, like any other, came not without limitations. Although our work was concentrated on employing real data from a micro-lending institution, we will base our experimental analysis on a more extensive data set in future works. While some broad qualitative conclusions about the importance of various features and the use of ensemble classifiers in micro-lending scenarios can be drawn from our results, the particular choice of features, etc., may not be universally applicable across other countries and other institutions. The use of an extensive data set might boost the model’s performance and provide more accurate estimations. Similarly, we might control the number of outliers more efficiently while understanding machine learning algorithms’ limits. Including the temporal aspects of credit risk is another promising direction for future research.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}