
Clustering-Based Extensions of the Common Age Effect Multi-Population Mortality Model


Abstract
1. Introduction
- How can one handle differences in the mortality of multiple populations which make the assumption of a single common age effect implausible?
- How can one identify clusters of populations with similar age effects?
- What information can be obtained on similarities and dissimilarities between the age effects of the considered populations by applying different clustering algorithms?
- How do CAE-type models based on a cluster analysis of populations perform on different data sets compared to several benchmark models from the literature?
2. Methodological Preliminaries
2.1. Notation
2.2. Overview of Existing Models
2.3. Poisson Maximum Likelihood Estimation
2.4. The Bayesian Information Criterion
3. Clustering-Based Common Age Effect Models
3.1. k-Means Clustering
3.2. Augmented Common Factor Clustering
- (the ACF model fits well to the data), and
- (i) (the random walk fits well to the estimated population-specific period effect), or(ii) and (the AR(1) process fits well to the estimated population-specific period effect and is mean-reverting).
- (the population-specific factor significantly enhances the fit), or
- (the common factor model does not fit well enough on its own).
3.3. Likelihood-Ratio-Based Clustering
3.4. Fuzzy Maximum Likelihood Clustering
4. Empirical Model Comparison
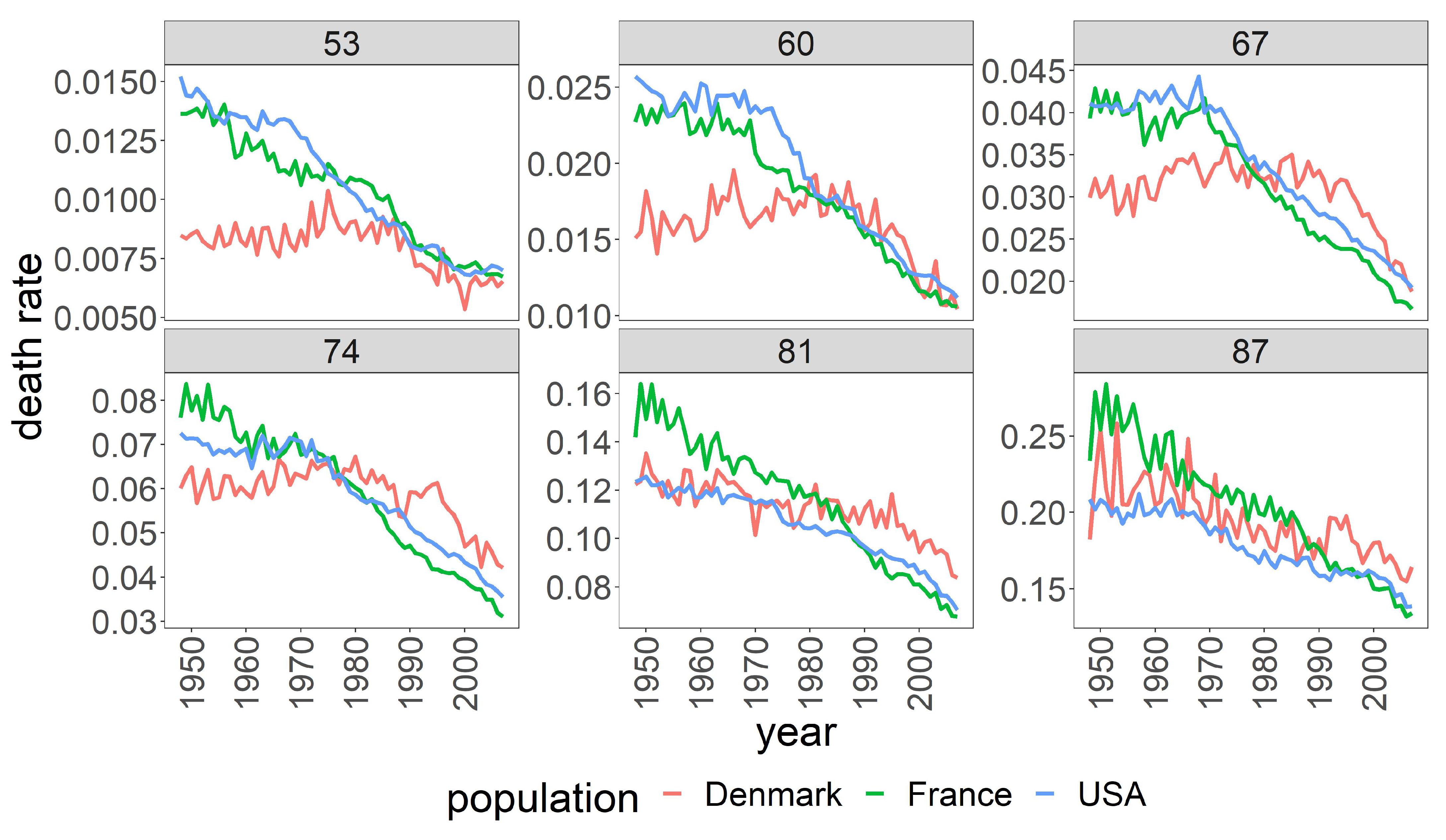
4.1. Data
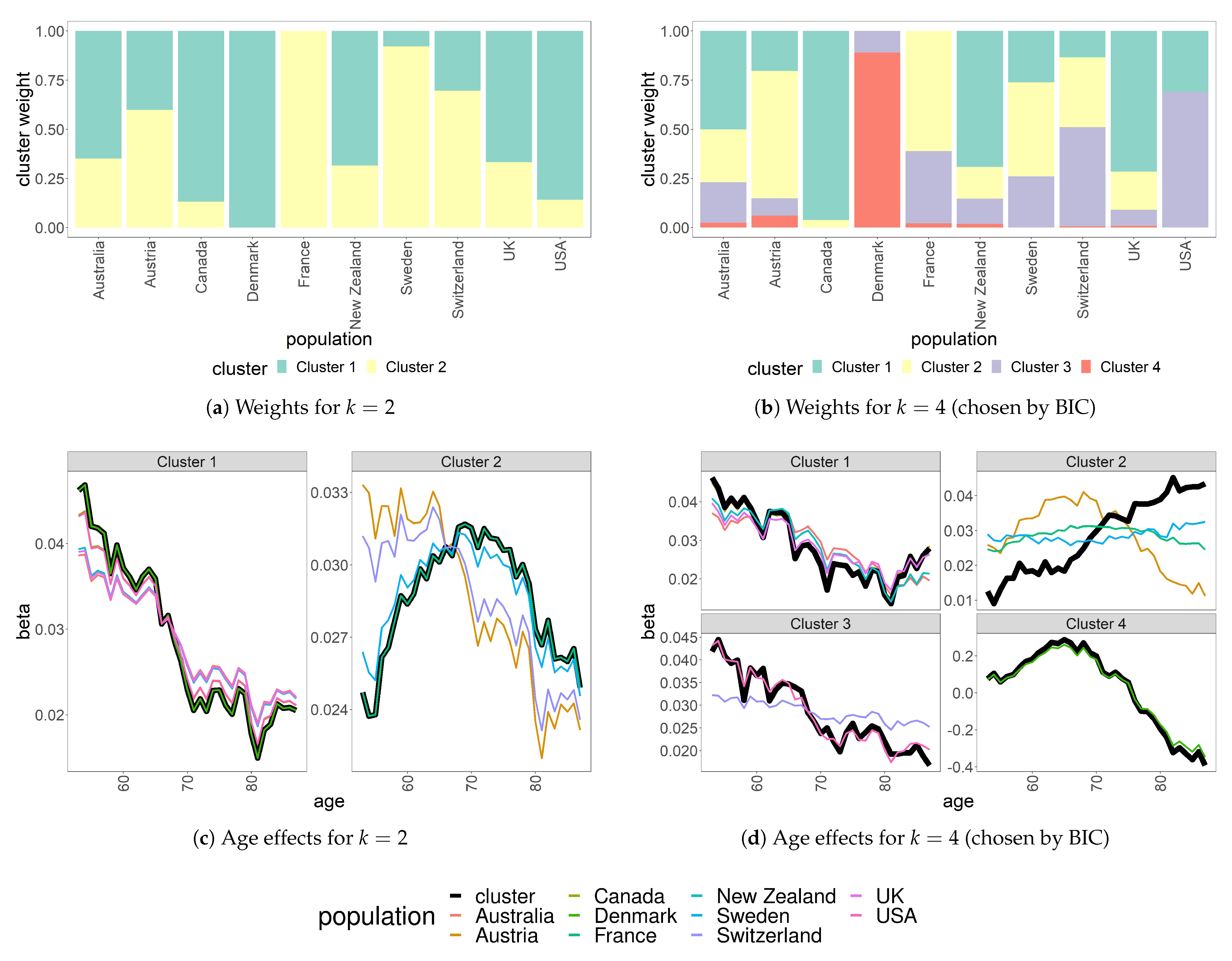
4.2. Clustering Results
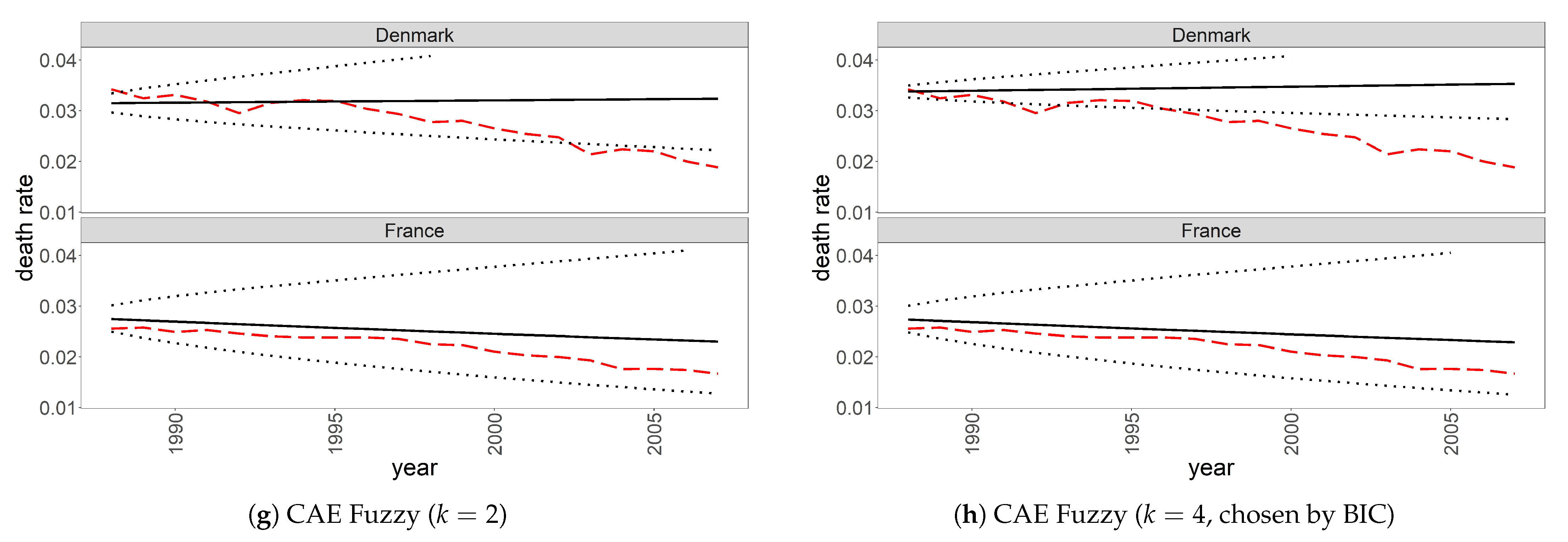
4.3. Goodness of Fit
4.4. Forecasting Performance
- ,
- mean absolute error, ,
- mean absolute percentage error, ,
- root-mean-square error, ,
5. Conclusions
- Given the availability of data containing features other than age, country and sex such as socioeconomic or health-related characteristics, our clustering-based models could be extended to include such features as well.
- A change point test or similar methods could be applied in order to find the optimal training period instead of selecting it arbitrarily (see Sweeting 2011).
- To make the clustering-based models more parsimonious, populations could not only share the age effect parameters but also the average mortality level parameters , which Wen et al. (2020) have found to work well for the standard CAE model. Alternatively, using more parameters to improve the fit, we could also include cohort effects (see Renshaw and Haberman 2006) or more than one age-period interaction term (see Kleinow 2015). For the latter extension, one would need to decide on how exactly the clustering of the age effects is determined.
- We have not devoted much attention to the projection of the time series and mostly just used the standard approach, i.e., the random walk with drift. Of course, there are more sophisticated ways to project these time series, for example using general ARIMA models or imposing a non-trivial correlation structure, and thereby ensure coherence or semicoherence (Li et al. 2017) of the projections within the clusters or explicitly model dependencies between the clusters.
- In this regard, it would also be interesting to introduce our clustering algorithms to the locally coherent modeling framework of Guibert et al. (2020). More precisely, all of the clustering algorithms in this paper can potentially be extended to cluster period effects instead of age effects as well. Two aspects which should be addressed in this context are the increased importance of choosing a suitable projection method for the obtained cluster-specific period effects and the necessity of a new identifiability analysis for a fuzzy clustering model on the period effects.
- Our figures clearly show that the estimated age effects lack smoothness, which affects the resulting fitted and projected death rates and, even before that, also might have an undesirable influence on the obtained clustering. It could be beneficial to smooth the parameters, for example via a penalized log-likelihood approach (see Delwarde et al. 2007). In particular, it would be interesting how this influences the clustering results and how it changes the remaining parameters of the fuzzy maximum likelihood clustering model. Moreover, for the k-means method, other dimension reduction techniques such as PCA (see Debón et al. 2017) could be applied to the age effect vectors as well before performing the clustering.
- With regard to our clustering algorithms, we have found that the BIC as a model selection criterion may lead to suboptimal out-of-sample performance. Other methods for selecting the number of clusters or other hyperparameters of the clustering-based models such as cross validation or the criteria used in Debón et al. (2017) should be investigated, which might lead to a further improvement in the out-of-sample performance of these models as exemplified by the fuzzy maximum likelihood clustering model in Table 3.
- We emphasize once more that the k-means algorithm is only one of many possible clustering methods that can be applied to the framework of Section 3.1. It would be interesting to compare it to other techniques like DBSCAN, spectral clustering or—using a different distance measure—k-medians clustering. In particular, instead of k-means one could also apply the fuzzy c-means algorithm and compare the obtained results to the fuzzy maximum likelihood clustering approach we have proposed (see Hatzopoulos and Haberman 2013).
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Calculating the Number of Free Parameters
Appendix B. Details on the ACF Clustering Algorithm
| Algorithm A1 The ACF fitting and clustering algorithm, see Section 3.2. |
Input: Death rates , explanation ratio threshold , improvement ratio threshold . Output: Number of clusters k, clustering function C, calibrated ACF model parameters and , time series processes for projecting and .
|
Appendix C. Hierarchical Clustering in the Likelihood-Ratio-Based Clustering Algorithm
References
- Bergeron-Boucher, Marie-Pier, Vladimir Canudas-Romo, Marius D. Pascariu, and Rune Lindahl-Jacobsen. 2018. Modeling and forecasting sex differences in mortality: A sex-ratio approach. Genus 74: 20. [Google Scholar] [CrossRef]
- Bezdek, James C. 1981. Pattern Recognition with Fuzzy Objective Function Algorithms. Advanced Applications in Pattern Recognition. Boston: Springer. [Google Scholar] [CrossRef]
- Booth, Heather, John Maindonald, and Len Smith. 2002. Applying Lee-Carter under conditions of variable mortality decline. Population Studies 56: 325–36. [Google Scholar] [CrossRef]
- Brillinger, David R. 1986. The natural variability of vital rates and associated statistics. Biometrika 42: 693–734. [Google Scholar] [CrossRef]
- Brouhns, Natacha, Michel Denuit, and Jeroen K. Vermunt. 2002. A Poisson log-bilinear regression approach to the construction of projected lifetables. Insurance: Mathematics and Economics 31: 373–93. [Google Scholar] [CrossRef]
- Cairns, Andrew J. G. 2014. Modeling and Management of Longevity Risk: Pension Research Council Working Paper, PRC WP2013-19. In Recreating Sustainable Retirement: Resilience, Solvency, and Tail Risk. Edited by Olivia S. Mitchell, Raimond Maurer and P. Brett Hammond. Oxford: Oxford University Press. [Google Scholar] [CrossRef]
- Cairns, Andrew J. G., David P. Blake, and Kevin Dowd. 2006. Pricing Death: Frameworks for the Valuation and Securitization of Mortality Risk. ASTIN Bulletin 36: 79–120. [Google Scholar] [CrossRef]
- Cairns, Andrew J. G., David P. Blake, Kevin Dowd, Guy D. Coughlan, David P. Epstein, Alen Ong, and Igor Balevich. 2009. A Quantitative Comparison of Stochastic Mortality Models Using Data From England and Wales and the United States. North American Actuarial Journal 13: 1–35. [Google Scholar] [CrossRef]
- Cairns, Andrew J. G., David P. Blake, Kevin Dowd, Guy D. Coughlan, and Marwa Khalaf-Allah. 2011. Bayesian Stochastic Mortality Modelling for Two Populations. ASTIN Bulletin 41: 29–59. [Google Scholar]
- Chen, Hua, Richard MacMinn, and Tao Sun. 2015. Multi-population mortality models: A factor copula approach. Insurance: Mathematics and Economics 63: 135–46. [Google Scholar] [CrossRef]
- Danesi, Ivan Luciano, Steven Haberman, and Pietro Millossovich. 2015. Forecasting mortality in subpopulations using Lee–Carter type models: A comparison. Insurance: Mathematics and Economics 62: 151–61. [Google Scholar] [CrossRef]
- Debón, Ana, L. Chaves, Steven Haberman, and F. Villa. 2017. Characterization of between-group inequality of longevity in European Union countries. Insurance: Mathematics and Economics 75: 151–65. [Google Scholar] [CrossRef]
- Delwarde, Antoine, Michel Denuit, and Paul H. C. Eilers. 2007. Smoothing the Lee–Carter and Poisson log-bilinear models for mortality forecasting. Statistical Modelling: An International Journal 7: 29–48. [Google Scholar] [CrossRef]
- Delwarde, Antoine, Michel Denuit, Montserrat Guillén, and A. Vidiella. 2006. Application of the Poisson log-bilinear projection model to the G5 mortality experience. Belgian Actuarial Bulletin 6: 54–68. [Google Scholar]
- Enchev, Vasil, Torsten Kleinow, and Andrew J. G. Cairns. 2017. Multi-population mortality models: Fitting, forecasting and comparisons. Scandinavian Actuarial Journal 2017: 319–42. [Google Scholar] [CrossRef]
- Giordano, Giuseppe, Steven Haberman, and Maria Russolillo. 2019. Coherent modeling of mortality patterns for age-specific subgroups. Decisions in Economics and Finance 42: 189–204. [Google Scholar] [CrossRef]
- Guibert, Quentin, Stéphane Loisel, Olivier Lopez, and Pierrick Piette. 2020. Bridging the Li-Carter’s Gap: A Locally Coherent Mortality Forecast Approach. Preprint. Available online: https://hal.archives-ouvertes.fr/hal-02472777 (accessed on 19 February 2021).
- Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2017. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed. Berlin: Springer. [Google Scholar]
- Hatzopoulos, Peter, and Steven Haberman. 2013. Common mortality modeling and coherent forecasts. An empirical analysis of worldwide mortality data. Insurance: Mathematics and Economics 52: 320–37. [Google Scholar] [CrossRef]
- Human Mortality Database. 2019. University of California, Berkeley (USA), and Max Planck Institute for Demographic Research, Rostock (Germany). Available online: https://www.mortality.org (accessed on 2 July 2019).
- Hyndman, Rob J., Heather Booth, and Farah Yasmeen. 2013. Coherent mortality forecasting: The product-ratio method with functional time series models. Demography 50: 261–83. [Google Scholar] [CrossRef]
- Kleinow, Torsten. 2015. A common age effect model for the mortality of multiple populations. Insurance: Mathematics and Economics 63: 147–52. [Google Scholar] [CrossRef]
- Kleinow, Torsten, and Andrew J. G. Cairns. 2013. Mortality and smoking prevalence: An empirical investigation in ten developed countries. British Actuarial Journal 18: 452–66. [Google Scholar] [CrossRef][Green Version]
- Lee, Ronald D. 2000. The Lee-Carter Method for Forecasting Mortality, with Various Extensions and Applications. North American Actuarial Journal 4: 80–91. [Google Scholar] [CrossRef]
- Lee, Ronald D., and Lawrence R. Carter. 1992. Modeling and Forecasting U.S. Mortality. Journal of the American Statistical Association 87: 659–71. [Google Scholar] [CrossRef]
- Léger, Ainhoa-Elena, and Stefano Mazzuco. 2020. What Can We Learn from Functional Clustering of Mortality Data? An Application to HMD Data. Preprint. Available online: http://arxiv.org/pdf/2003.05780v1 (accessed on 19 February 2021).
- Li, Johnny S.-H., Wai-Sum Chan, and Rui Zhou. 2017. Semicoherent Multipopulation Mortality Modeling: The Impact on Longevity Risk Securitization. Journal of Risk and Insurance 84: 1025–65. [Google Scholar] [CrossRef]
- Li, Johnny S.-H., Rui Zhou, and Mary R. Hardy. 2015. A step-by-step guide to building two-population stochastic mortality models. Insurance: Mathematics and Economics 63: 121–34. [Google Scholar] [CrossRef]
- Li, Nan, and Ronald D. Lee. 2005. Coherent Mortality Forecasts for a Group of Populations: An Extension of the Lee-Carter Method. Demography 42: 575–94. [Google Scholar] [CrossRef]
- Meslé, France, and Jacques Vallin. 2002. Mortalité en Europe: la divergence Est-Ouest. Population 57: 171. [Google Scholar] [CrossRef]
- Nielsen, Bent, and Jens P. Nielsen. 2010. Identification and Forecasting in the Lee-Carter Model. Working Paper. Available online: https://ssrn.com/abstract=1722538 (accessed on 19 February 2021).
- Oppers, S. Erik, Ken Chikada, Frank Eich, Patrick Imam, John Kiff, Michael Kisser, Mauricio Soto, and Tao Sun. 2012. The Financial Impact of Longevity Risk. In Global Financial Stability Report—The Quest for Lasting Stability. Washington, DC: International Monetary Fund, Chapter 4. [Google Scholar]
- Pitacco, Ermanno, Michel Denuit, Steven Haberman, and Annamaria Olivieri. 2008. Modelling Longevity Dynamics for Pensions and Annuity Business. Oxford: Oxford University Press. [Google Scholar]
- R Core Team. 2019. R: A Language and Environment for Statistical Computing. Vienna: R Core Team. [Google Scholar]
- Renshaw, Arthur E., and Steven Haberman. 2006. A cohort-based extension to the Lee–Carter model for mortality reduction factors. Insurance: Mathematics and Economics 38: 556–70. [Google Scholar] [CrossRef]
- Sweeting, Paul J. 2011. A Trend-Change Extension of the Cairns-Blake-Dowd Model. Annals of Actuarial Science 5: 143–62. [Google Scholar] [CrossRef]
- Villegas, Andrés M., Steven Haberman, Vladimir K. Kaishev, and Pietro Millossovich. 2017. A comparative study of two-populations models for the assessment of basis risk in longevity hedges. ASTIN Bulletin 47: 631–79. [Google Scholar] [CrossRef]
- Wen, Jie, Andrew J. G. Cairns, and Torsten Kleinow. 2020. Fitting Multi-Population Mortality Models to Socio-Economic Groups. Annals of Actuarial Science (to appear). [Google Scholar] [CrossRef]
- Wen, Jie, Torsten Kleinow, and Andrew J. G. Cairns. 2020. Trends in Canadian Mortality by Pension Level: Evidence from the CPP and QPP. North American Actuarial Journal 41: 1–29. [Google Scholar] [CrossRef]
- Wickham, Hadley. 2016. Ggplot2: Elegant Graphics for Data Analysis/Hadley Wickham; with Contributions by Carson Sievert, Use R! 2nd ed. Switzerland: Springer. [Google Scholar]
- Zhou, Rui, Johnny S.-H. Li, and Ken S. Tan. 2013. Pricing Standardized Mortality Securitizations: A Two-Population Model With Transitory Jump Effects. Journal of Risk and Insurance 80: 733–74. [Google Scholar] [CrossRef]
- Zugic, Richard, Gavin Jones, Costas Yiasoumi, Kerry McMullan, Andreas Tacke, Michael Held, and Benoit Moreau. 2010. Longevity. Position Paper, CRO Forum. Available online: https://www.thecroforum.org/wp-content/uploads/2010/11/Longevity-Risk.pdf (accessed on 19 February 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster | k-Means | ACF-Based | Likelihood-Ratio-Based (AL) | Fuzzy ML Clustering () | Fuzzy ML Clustering () |
|---|---|---|---|---|---|
| 1 | AUT | AUS, AUT, CAN, CHE, FRA, SWE, UK, USA | AUS | AUS, CAN, DNK, NZL, UK, USA | AUS, CAN, NZL, UK |
| 2 | CHE, FRA, SWE | DNK | AUT, DNK | AUT, CHE, FRA, SWE | AUT, FRA, SWE |
| 3 | AUS, CAN, NZL, UK, USA | NZL | CAN | - | CHE, USA |
| 4 | DNK | - | FRA, UK | - | DNK |
| 5 | - | - | NZL | - | - |
| 6 | - | - | SWE, USA | - | - |
| 7 | - | - | CHE | - | - |
| Model | Lmax | npar | BIC |
|---|---|---|---|
| ACF (SVD) | — | 1299 | −75,684 |
| CAE (cPCA) | — | 774 | −78,483 |
| ILC (SVD) | — | 1080 | −77,550 |
| ILC (MLE) | −86,791 | 1080 | 183,893 |
| CAE (MLE) | −91,299 | 774 | 189,988 |
| CAE, | |||
| k-means | −87,584 | 876 | 183,532 |
| CAE, | |||
| ACF-based | −90,986 | 842 | 190,009 |
| CAE, | |||
| LR (av. linkage) | −88,233 | 978 | 185,803 |
| CAE Fuzzy, | |||
| −87,983 | 816 | 183,756 | |
| CAE Fuzzy, | |||
| (chosen by BIC) | −87,054 | 894 | 182,643 |
| Model | Bias | MAE | MAPE | RMSE |
|---|---|---|---|---|
| ACF (SVD) | 5.92‰ | 6.77‰ | 20.91% | 9.65‰ |
| CAE (cPCA) | 5.97‰ | 6.72‰ | 19.95% | 9.80‰ |
| ILC (SVD) | 5.94‰ | 6.76‰ | 20.40% | 9.99‰ |
| ILC (MLE) | 6.01‰ | 6.75‰ | 20.38% | 10.05‰ |
| CAE (MLE) | 6.14‰ | 6.75‰ | 19.64% | 9.82‰ |
| CAE, | ||||
| k-means | 6.04‰ | 6.68‰ | 20.29% | 9.94‰ |
| CAE, | ||||
| ACF-based | 6.06‰ | 6.68‰ | 19.98% | 9.65‰ |
| CAE, | ||||
| LR (av. linkage) | 6.37‰ | 7.01‰ | 20.04% | 10.58‰ |
| CAE Fuzzy, | ||||
| 5.90‰ | 6.47‰ | 19.63% | 9.43‰ | |
| CAE Fuzzy, | ||||
| (chosen by BIC) | 6.03‰ | 6.76‰ | 20.27% | 10.16‰ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schnürch, S.; Kleinow, T.; Korn, R. Clustering-Based Extensions of the Common Age Effect Multi-Population Mortality Model. Risks 2021, 9, 45. https://doi.org/10.3390/risks9030045
Schnürch S, Kleinow T, Korn R. Clustering-Based Extensions of the Common Age Effect Multi-Population Mortality Model. Risks. 2021; 9(3):45. https://doi.org/10.3390/risks9030045
Chicago/Turabian StyleSchnürch, Simon, Torsten Kleinow, and Ralf Korn. 2021. "Clustering-Based Extensions of the Common Age Effect Multi-Population Mortality Model" Risks 9, no. 3: 45. https://doi.org/10.3390/risks9030045
APA StyleSchnürch, S., Kleinow, T., & Korn, R. (2021). Clustering-Based Extensions of the Common Age Effect Multi-Population Mortality Model. Risks, 9(3), 45. https://doi.org/10.3390/risks9030045