1. Introduction
The Editors of this Special Issue pointed out that machine learning (ML) has no unanimous definition. In fact, the term “ML”, coined by
Samuel (
1959), is quite differently understood in the different communities. The general definition is that ML is concerned with the development of algorithms and techniques that allow computers to learn. The latter means a process of recognizing patterns in the data that are used to construct models; cf. “data mining” (
Friedman 1998). These models are typically used for prediction. In this note, we speak about ML for data based prediction and/or estimation. In such a context, one may say that ML refers to algorithms that computer codes apply to perform estimation, prediction, or classification. As said, they rely on pattern recognition (
Bishop 2006) for constructing purely data-driven models. The meaning of “model” is quite different here from what “model” or “modeling” means in the classic statistics literature; see
Breiman (
2001). He speaks of the data modeling culture (classic statistics) versus the algorithmic modeling coming from engineering and computer science. Many statisticians have been trying to reconcile these modeling paradigms; see
Hastie et al. (
2009). Even though the terminology comes from a different history and background, the outcome of this falls into the class of so-called semi-parametric methods; see
Ruppert et al. (
2003) or
Härdle et al. (
2004) for general reviews. According to that logic, ML would be a non-parametric estimation, whereas the explicit parametrization forms the modeling part from classic statistics.
Why should this be of interest? The Editors of this Special Issue also urge practitioners not to ignore what has already been learned about financial data when using presumably fully automatic ML methods. Regarding financial data for example,
Buch-Larsen et al. (
2005),
Bolancé et al. (
2012),
Scholz et al. (
2015,
2016), and
Kyriakou et al. (
2019) (among others) have shown the significant gains in estimation and prediction when including prior knowledge in nonparametric prediction. The first two showed how knowledge-driven data transformation improves nonparametric estimation of distribution and operational risk; the third paper used parametrically-guided ML for stock return prediction; the fourth imputed bond returns to improve stock return predictions; and the last proposed comparing different theory-driven benchmark models regarding their predictability.
Grammig et al. (
2020) combined the opposing modeling philosophies to predict stock risk premia. In this spirit, we will discuss the combination of purely data-driven methods with smart modeling, i.e., using prior knowledge. This will be exemplified along the analysis of the distributions (conditional and unconditional) of daily stock returns and calculations of their value-at-risk (VaR).
Notice finally that in the case of estimation, methods are desirable that permit practitioners to understand, maybe not perfectly, but quite well, what the method is doing to the data. This will facilitate the interpretation of results and any further inference. Admittedly, this is not always necessary and certainly also depends on the knowledge or imagination of the user. Yet, we believe it is often preferable to analyze data in a glass box than in a black box. This aspect is respected in our considerations.
Section 2 revisits the ideas of semiparametric statistics.
Section 3 provides an intensive treatment of the distribution modeling followed by its combination with local smoothing. In
Section 4, we give empirical illustrations.
Section 5 concludes. In the Appendix are given additional details.
2. Preliminary Considerations and General Ideas
It is helpful to first distinguish between global and local estimation. Global means that the parameter or function applies at any point and to the whole sample. Local estimation applies only to a given neighborhood, like for kernel regression. It is clear that localizing renders a method much more flexible; however, the global part allows for an easy modeling, and its estimation can draw on the entire sample. Non-parametric estimators are not local by nature; for example, power series based estimators are not. Unless you want to estimate a function with discontinuities, local estimators are usually smoothing methods; see
Härdle et al. (
2004). This distinction holds also for complex methods (cf. the discussion about extensions of neural networks to those that recognize local features), which often turn out to be related to weighted nearest neighbor methods; see
Lin and Jeon (
2006) for random forests or
Silverman (
1984) for splines. The latter is already a situation where we face a mixture of global and local smoothing; another one is orthogonal wavelet series (
Härdle et al. 1998).
Those mixtures are interesting because the global parts can borrow the strength from a larger sample and have a smoothing effect, while the local parts allow for the desired flexibility to detect local features. Power series can offer this only by including a (in practice unacceptable) huge number of parameters. This is actually a major problem of many complex methods, but mixtures allow substantially reducing this number. At the same time, they allow us to include prior knowledge about general features. For example, imposing shape restrictions is much simpler for mixtures (like splines) than it is for purely local smoothers; see
Meyer (
2008) and the references therein. Unless the number of parameters is pre-fixed, their selection happens via reduction through regularization, which can be implemented in many ways. Penalization methods like P-splines (
Eilers et al. 2015) or LASSO (
Tibshirani 1996) are popular. The corresponding problem for kernel, nearest neighbors, and related methods is the choice of the neighborhood size. In any case, one has to decide about the penalization criterion and a tuning parameter. The latter is until today an open question; presently, cross-validation-type methods are the most popular ones. For kernel based methods, see
Heidenreich et al. (
2013) and
Köhler et al. (
2014) for a review or
Nielsen and Sperlich (
2003) in the context of forecasting in finance.
The first question concerns the kind of prior information available, e.g., whether it is about the set of covariates, how they enter (linearly, additively, with interactions), the shape (skewness, monotonicity, number of modes, fat tails), or more generally, about smoothness. This is immediately followed by the question of how this can be included; in some cases, this is obvious (like if knowing the set of variables to be included); in some others, it is more involved (like including parameter information via Bayesian modeling). Knowledge about smoothness is typically supposed in order to justify a particular estimator and/or the selection method for the smoothing parameter. Information about the shape or how covariates enter the model comprises the typical ingredients of semiparametric modeling (
Horowitz 1998) to improve nonparametric estimation (
Glad 1998).
Consider the problem of estimating a distribution, starting with the unconditional case. In many situations, you are more interested in those regions for which data are hardly available. If you used then a standard local density estimator, you would try to estimate interesting parameters like VaR from only very few observations, maybe one to five, which is obviously not a good idea.
Buch-Larsen et al. (
2005) proposed to apply a parametric transformation using prior knowledge. Combining this way a local (kernel density) estimator with such a global one, however, allowed them to borrow strength from the model and from data that were further away. Similarly, consider conditional distributions. Locally, around a given value of the conditioning variable, you may have too few observations to estimate a distribution nonparametrically. Then, you may impose on this neighborhood the same probability law up to some moments, as we will do in our example below.
1Certainly, a good mixture of global and local fitting is problem-adapted. Then, the question falls into two parts: which is the appropriate parametric modeling, and how to integrate it with the flexible local estimator. For the former, you have to resort to expertise in the particular field. For the latter, we will discuss some popular approaches. All this will be exemplified with the challenges of modeling stock returns for five big Spanish companies and predicting their VaR.
In our example, the first step is to construct a parametric guide for the distribution of stock returns
Y. To this aim, we introduce the class of generalized beta-generated (BG) distributions (going back, among others, to
Eugene et al. (
2002) and
Jones (
2004)), as this distribution class allows modeling skewed distributions with potentially long or fat tails. While this is not a completely new approach, we present it with an explicit focus on the above outlined objectives including the calculation of VaRs and combining it with nonparametric estimation and/or validation. Our validation is more related to model selection and testing, today well understood and established, and therefore kept short. The former, i.e., the combination with nonparametric estimation, is discussed for the problem of analyzing conditional distributions and can be extended to the combination with methods for estimating in high dimensions. For this example, in which the prior knowledge enters via a distribution class, we discuss two approaches: one is based on the method of moments, the other one on maximum likelihood. The latter is popular due to
Rigby and Stasinopoulos (
2005) and
Severini and Staniswalis (
1994).
Rigby and Stasinopoulos (
2005) considered a fully parametrized model in which each distribution parameter (potentially transformed with a known link) is written as an additive function of covariates, typically including a series of random effects. They proposed a backfitting algorithm (implemented in the R library GAMLSS) to maximize a penalized likelihood corresponding to a posterior mode estimation using empirical Bayesian arguments.
Severini and Staniswalis (
1994) started out with the parametric likelihood, but localized it by kernels. This is maximized then for some given values of the covariates.
4. Empirical Illustration
Consider daily stock returns from 1 January 2015 to 31.12.2015 for five companies of the Spanish value-weighted index IBEX35; namely Amadeus (IT solutions for tourist industry), BBVA (global financial services), Mapfre (insurance market), Repsol (energy sector), and Telefónica (information and communications technology services); see
Table 1. The returns are negatively skewed in four of the five companies considered, but positively skewed in the last one.
We first fit the data by the maximum likelihood (ignoring dependence) to both distribution classes, working with standardized data.
Table 2 and
Table 3 show the parameter estimates with standard errors.
To choose between these two models, one may use the Bayesian information criterion (BIC). However, as our (working) likelihood neglects the dependence structure, it might not be reliable. While the three-parameter model presents the largest values for BIC (not shown), the gain, however, is always close to, or smaller than, 1%.
An alternative is to apply ML methods comparing the parametric estimates with purely nonparametric ones. This is not recommendable any longer when switching to conditional distributions due to the moderate sample sizes. In
Figure 2, you see how our models (in red) adapted to the empirical cdf (blue) for the stocks of Amadeus and BBVA. As expected, the three-parameter model gave slightly better fits. In practice, the interesting thing to see is where improvements occurred, if any. The practitioner has to judge then what is of interest for his/her problem; ML cannot do this for him/her. However, ML can offer specification tests; see
Gonzales-Manteiga and Crujeiras (
2013) for a review. For example, a test that formalizes our graphical analysis is the Kolmogorov–Smirnov (
) test:
where
is the empirical cdf and
is the cdf of the particular model class with
from
Table 2 and
Table 3. To calculate the
p-value, we can use the parametric bootstrap:
Step 1: For the observed sample, find the maximum likelihood estimator, , , and .
Step 2: Generate J bootstrap samples under (the data follow model F); fit them; and compute , , and for each bootstrap sample .
Step 3: Calculate the p-value as the fraction of synthetic bootstrap samples with a statistic greater than the empirical statistic obtained from the original data.
To obtain an approximate accuracy of the
p-value for
0.01, we generated
bootstrap samples.
Table 4 shows the results for both distribution classes and all datasets. It can be seen that with all
p-values larger than 0.499, both models could not be rejected at any reasonable significance level in any of the considered datasets.
Finally, let us see how different the VaR are, when calculated on the base of one model compared to the other; recall Equations (
7) and (
8). They were calculated at the 95% confidence level for all datasets; see
Table 5. The
model with two parameters provided slightly higher VaR values than the
model. The difference again seemed to be somewhat marginal, except maybe for Amadeus.
Let us turn to the estimation of the conditional distribution. Here, the integration of the ML happens by incorporating the covariates nonparametrically. For the sake of presentation and brevity, we restricted ourselves here to the moment based approach; for more details on the likelihood based one, we refer (besides the above cited literature) to the recent compendium of
Rigby et al. (
2019) and the references therein. Limiting ourselves to the moment based method automatically limited us to the skewed
t1 class; recall Equation (
6).
2 Furthermore, for the sake of illustration, we limited the exercise to the estimation of all distribution parameters as nonparametric functions of one given covariate
X, namely the IBEX35. It was obvious that estimates for
,
could equally well be the result of a complex multivariate regression or a variable selection procedure like LASSO. We estimated
(IBEX35) and
(IBEX35) using different methods provided by standard software; the presented results were obtained from penalized (cubic) spline regression with data-driven penalization. For details, consult
Ruppert et al. (
2003) and the SemiPar project.
Figure 3 gives an example of how this performed for the BBVA stocks.
Table 6 gives for the IBEX35 quantiles
,
,
the corresponding moment estimates of the different stock returns;
Table 7 the corresponding
for Formulas (
10) and (
11).
Table 8 gives the corresponding conditional VaRs obtained from Formula (
7).
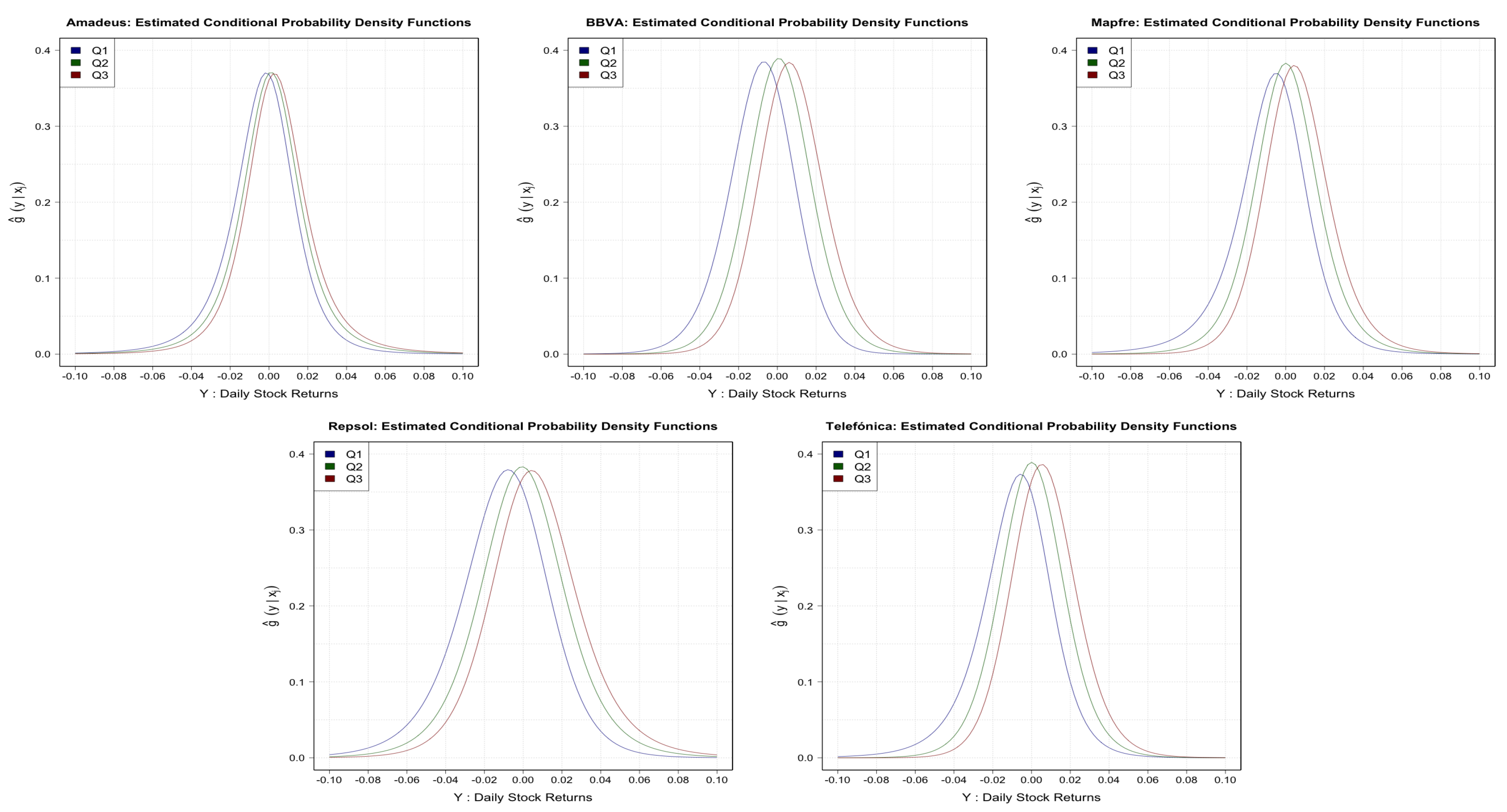
In
Figure 4, you can see the entire conditional distributions for the three IBEX35 quantiles. Finally, in
Figure 5, we plotted the resulting unconditional distributions when you integrate over the observed IBEX35 values; recall Equation (
12). They reflect quite nicely the asymmetries and some fat tails.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}