1. Introduction
Economic decisions are closely linked to risk. Several types of risk can affect the survival of financial institutions. Among these risks, we can mention market risk, credit risk, and operational risk. Credit risk is the most common risk and is defined as the probability of loss due to the default of the borrower on the required payments, and its severity is determined by the amount of defaulted debt. Credit risk assessment is the evaluation done by financial institutions on the future ability of borrowers to meet their financial obligations. The variables that must be analyzed will depend on the type of credit to be granted. This situation leads to the collection of many variables for the purpose of analyzing the borrowers. Some variables depend on the personal situation of the customer, whereas others depend on the general economic environment. Thus, it is important to analyze, at the time of granting a loan, the macroeconomic environment in which the client operates, in addition to the borrowers’ specific conditions. In this way, a more comprehensive analysis of the debtor can be carried out. The goal is to recommend a more precise answer to the credit official.
Thanks to information technology, numerous processes automatically register their operations, producing large repositories of historical information. These records contain not only the data upon which the decision was made (approval/rejection), but also the repercussions of the decision (default/repayment). Therefore, financial institutions have information about instances of past granted credit and the success or failure of the repayment. Our goal is twofold: (i) to identify and generalize the criteria used to grant credits and (ii) to identify the common features of successes and mistakes.
It is important to indicate that in most countries there are government institutions that oversee financial institutions and enforce suitable regulations. One of these regulations requires financial institutions to be responsible for establishing the methodologies and processes to identify, measure, control, and monitor credit risk. In addition, financial institutions must set a system in place to monitor credit risk levels permanently. In general, these regulations leave some room for discretion. This situation means that each entity, for each credit type (commercial, consumption, housing, and microcredit) selects the best model, within some general principles and criteria, for credit risk assessment. Implemented methodologies can consider the combination of quantitative and qualitative criteria, in accordance with the experience and strategic policies of the firm. Therefore, it is relevant to the financial industry to develop new and better models. Such enhanced models should be based not only on the historical information of the clients but also on other internal and external information in order to produce better risk-controlled decisions.
The CEO of a financial institution aims to increase the volume of operations granted, without affecting global risk decision making, based on expert analytical methodologies that allow the expected loss to be determined based on the probability of default, the level of exposure, and the severity of the loss, which helps to control overall financial risk. Another issue that must be considered is that, in order to attract more customers, the granting process must be quick. Consequently, financial institutions must improve their prediction accuracy, make decisions in a short period of time and provide the credit officer with understandable criteria for the acceptance/rejection of credit applications.
This article proposes the construction of a predictive model, based on the personal and microeconomic information of borrowers, as well as contextual macroeconomic information, in order to aid in the decision-making process of credit granting. Among the different classification techniques existing in the data mining area, classification rules are extremely attractive due to their explanatory capacity (
Kotsiantis 2007).
A classification rule is a conditional expression in the form:
IF A THEN B
Where A is the antecedent of the rule and B is its consequent. The antecedent of the rules used in this article is formed by a conjunction of expressions of the form . If this conjunction is true, then the rule produces the consequent as a result. This consequent will be of the form .
In the literature, different methods exist for generating classification rules, using either qualitative or quantitative attributes (
Fürnkranz and Kliegr 2015). However, the high cardinality of the generated rule set, as well as the rigor with which each antecedent is expressed, leads to the application being impractical. Although different metrics can be applied to identify which rules are the most relevant, the thresholds calculated on the numerical attributes will continue to be rigid. This makes the application of the rules rather difficult.
In this article we propose the application of Particle Swarm Optimization (PSO), a well-known optimization technique, to generate a list of classification rules. We consider different variants of cluster initialization, in order to extend the representation of the solutions. Classification rules operate on fuzzy numerical information, thus avoiding the use of rigid thresholds when determining the conditions that form the background of the rules. This process is carried out using fuzzy attributes, whose values are determined in linguistic terms.
For example, if Income is a numeric attribute, its participation in the antecedent of a rule requires setting a range, e.g., . Instead of using it in this way, the algorithm presented in this paper proposes to convert it, for example, into a diffuse attribute that takes Low, Medium, and High values and allows them to participate in the conjunction with an expression of the form . Consequently, numerical thresholds will not be used in the precedent of the rule, thus facilitating its understanding by the credit officer. As a result, a set of rules that may or may not be diffuse, of low cardinality, with a background formed by few conditions, and offering acceptable classification accuracy will be obtained.
In this article, we propose: (i) the application of an optimization technique based on particle swarms to generate a list of classification rules, taking into account different variants when initializing the clusters; (ii) to operate on the number of particles that will carry out the search; and (iii) to extend the representation of the solutions found to express fuzzy conditions. The result will be a set of rules that may be fuzzy or crisp, is of low cardinality, has an antecedent formed by few conditions, and offers an acceptable classification accuracy.
This work is organized in the following way:
Section 2 briefly describes the relevant related work;
Section 3 presents the different PSO variants used;
Section 4 shows the results obtained; and
Section 5 summarizes the conclusions and describes some future research lines.
2. Related Literature
There are different techniques that allow for improvement of credit scoring models. The seminal work by
Altman (
1968) opened a research line that began working with statistical methods, including logistic regression and linear discriminants (
Mahmoudi and Duman 2015;
Zhichao et al. 2017).
After decades of research, machine learning techniques emerged as powerful alternatives. In this line, Support Vector Machines (SVM) (
Bellotti and Crook 2009;
Harris 2013;
Li et al. 2017) and multiperceptron neural networks are capable of improving the performance of credit models (
Tavana et al. 2018;
Zhao et al. 2015). There are hybrid models that combine fuzzy logic with SVM (
Wang et al. 2005) or fuzzy logic with optimization techniques (
Chen 2006). There are also hybrid models that select the most salient previous features and reduce the dimension of the input space, which in turn enhance the results (
Leo et al. 2019;
Malhotra and Malhotra 2003;
Oreski and Oreski 2014). The authors in
Leo et al. (
2019) provide an excellent review on the risk management techniques used by financial institutions. In spite of the fact that these machine learning models present good accuracy, they are not considered particularly useful, as explaining the response obtained is difficult (
Baesens et al. 2003). In other words, these machine learning models provide an answer that is hard to relate to specific characteristics of the credit or the borrower.
Recently, the authors in
Millán-Solarte and Caicedo-Cerezo (
2018) compared the results of logistic regression, linear discriminants, neural networks, and decision trees. The classical logistic regression model is frequently used to estimate the probability that the client of a financial institution will default on his or her payments. However, logistic regression alone is not as efficient as other techniques. Consequently, the authors in
Millán-Solarte and Caicedo-Cerezo (
2018) proposed hybrid models that combine logistic regression with decision trees. Their results were much better. Nevertheless, these types of models do not use fuzzy logic, taking away the advantage in the interpretation of the rules obtained.
In contrast to the previous techniques, classification rules are a widely accepted model when seeking to justify the responses obtained because they formalize, in a clear way, the knowledge discovered. They are considered more natural and understandable, providing experts (in our case, credit officers) with the possibility of analyzing the criteria used when giving an answer.
There are several methods for generating rules, which generally use an incremental criterion to define the composition of the antecedent. During the process, available cases are inspected, and conditions are added to the antecedent so that the rule gains accuracy at the cost of losing support. In this sense, a wide variety of solutions can be found in the literature, such as methods based on pruned trees (e.g., PART algorithm by
Frank and Witten (
1998)) or specific metrics, such as PRISM algorithm by
Cendrowska (
1987). Regardless of the option chosen, the rules obtained tend to have an antecedent with a large average length.
On the other hand, another type of alternative can be found to build classification rules. This is the case for competitive neural networks. Once the neural network is trained, the centroids (represented by the positions of the neurons) can be used to identify the most representative characteristics or attributes, in order to explain patterns or relationships in the input information. This approach has been used as a departing point to obtain classification rules (
Hung and Huang 2010;
Pateritsas et al. 2007). However, this type of response does not present good precision, as the characterization obtained is representative of a set of cases in an unsupervised manner. That is, the associations identified by the neural network are equivalent to those that could be obtained with other clustering techniques and do not obey a class distribution (
Reyes et al. 2013).
Support Vector Machines (SVM) can be also used as a starting point for rule generation. However, they are considered “black boxes”, since the generated rules are frequently complex and difficult to understand (
Barakat and Bradley 2010;
Núñez et al. 2002). Other methods suitable for rule extraction are population based techniques that allow relationships among items and, as a result, obtain a set of rules (
Gandhi et al. 2010;
Kennedy 2010;
Wang et al. 2006,
2007). These techniques can be defined as processes of search and optimization, which improve the available solutions by means of iterative strategies until achieving an optimal value.
Different strategies based on population optimization techniques have also been proposed to determine sets of rules. In most cases, as in the solutions analyzed in this article, the result is a list of rules. The construction of such a list requires repeated executions of the selected technique. Modeling the extraction of rules as an optimization problem involves defining the representation to be used, the way to measure the performance of individuals throughout the process, and the operators that will guide the search to the best solutions. In
Al-Maqaleh and Shahbazkia (
2012) a Genetic Algorithm (GA) was used to evolve the conditions that make up the conjunction that determines the antecedent. An alternative proposal, known as Ant Colony Optimization (ACO), is presented in
Medland et al. (
2012). In the latter case, the results obtained are very good, although the computational time can be prohibitive for very large data sets. ACO performs better with qualitative attributes, while GA achieves better results with numerical attributes. Unfortunately, most of the existing methods cover historical information using large and complex sets of rules that become difficult to understand and consume a large amount of resources (
Carvajal Montealegre 2015).
In previous studies, we used methods such as C4.5 and PART (
Lanzarini et al. 2015,
2017). In the case of C4.5, the method of finding classification rules is through a pruned tree whose branches are mutually exclusive and allow classification of the examples. In the case of PART, a list of rules equivalent to those generated by the proposed classification method is given but in a deterministic way. The operation of PART is based on the construction of partial trees. Each tree is created in a similar way to the one proposed by C4.5; however, during the process, errors are calculated in each expansion and pruning is performed when increments are detected. A detailed description of this algorithm is in
Frank and Witten (
1998).
Another technique used is Optimization by PSO particle cluster, (
Lanzarini et al. 2015,
2017), which is a search and optimization technique that can be applied in different contexts. PSO is used to select, simultaneously, the conditions where the conjunction will give rise to the antecedent of each rule. The use of PSO in the extraction of rules requires some particular considerations. Although all aspects are important, the definition of the aptitude function, which measures the performance of the rules as they are formed, is the central aspect in achieving an efficient set of rules. If the process of searching for solutions (in this case rules) starts from a position close to the optimum, the time of obtaining it will be considerably reduced. This starting point of the process was solved using a competitive neural network. Additionally,
Shihabudheen and Pillai (
2018), concludes that methods using PSO achieve more accuracy than gradient-based techniques or SVM.
Although partition algorithms provide greater accuracy, this is achieved through a greater number of rules, which makes understanding more difficult. In fact, the difference in accuracy between both types of methods is within the range of 1 to 3 percentage points. The accuracy of the classification based on PSO is very good and is comparable to the other methods, however, in relation, the number of rules is between 10 and 20 times greater in the methods of partition. More detailed discussion on this feature can be found in
Lanzarini et al. (
2015) and
Jimbo et al. (
2016).
It is important to note that although smart systems have several advantages over traditional linear programming or time series calculation techniques, for financial institutions, their use does not replace a credit expert; instead, it provides support so that they can more easily evaluate a loan.
The rules express, through their respective antecedents, conditions that must be met in order to obtain the desired response. These conditions can be relaxed using fuzzy sets (
Zadeh 1965,
1996). Credit classification is a problem, where the knowledge of the credit expert is generally available. Therefore, it is feasible to obtain adequate fuzzy propositions that interpret the rules of the loan officer.
The rationale for using an optimization technique, such as PSO, that allows obtaining fuzzy rules not only makes possible a trade-off between the accuracy and simplicity of the rules (
Bagheri et al. 2014) but also deals with the granting of credits as a more successful task on the part of the loan officers. This is because the risk to the financial institution decreases due to the analysis carried out, leading them to make appropriate decisions with greater accuracy by verifying a reduced number of rules in the shortest time possible.
This article analyzes different techniques, based on particle clusters, capable of obtaining classification rules operating over qualitative and quantitative attributes. Emphasis is placed on the importance of the use of fuzzy sets when expressing the conditions that involve numerical attributes. This setting not only facilitates the understanding and application of the rules but also offers a significantly higher precision vis-à-vis crisp conditions.
3. PSO for Rule Extraction
Particle Swarm Optimization (PSO) is a population metaheuristic proposed by
Eberhart and Kennedy (
1995), where each individual of the population (called a particle) represents a possible solution to the problem and is adapted following three factors: the particle’s current knowledge (its ability to solve the problem), its historical knowledge or previous experience (its memory), and the historical knowledge or previous experiences of the individuals located in its neighborhood (social knowledge). To measure the performance of the particle as a solution to the problem, a fitness function is used. This technique works by iteratively improving the fitness value of all the particles of the population by combining the three aforementioned factors. Algorithm 1 contains the pseudocode of a basic PSO algorithm.
In this paper, we analyzed different variants of the PSO model. We applied them in order to obtain classification rules. This is an iterative process that starts with the selection of the class that determines the consequent, as the one that with the largest number of uncovered examples and adapts a population of particles following Algorithm 1. Each individual of the population corresponds to the antecedent of a different rule. Therefore, all the rules determined by the set of particles have the same consequent: the a priori selected class. Upon completion of the adaptation process, the best individual in the population will result in a new rule that will be added to the list. The examples correctly covered by this last rule will be removed from the data set. The process is repeated starting with the selection of the new class with the largest number of examples, for which the most suitable antecedent will be searched. The process ends when enough cases have been covered.
| Algorithm 1 Pseudocode of basic PSO method |
Set initial population1 Determine the initial velocity of particles while end condition is not met do Adjust the velocity of particles for each particle of the population do Evaluate its fitness Register its current location if it is the best solution found so far end for for each particle of the population do Identify the best global solution found within the neighborhood Calculate the movement direction of the particle Move the particle Verify that the particle does not move beyond the search space. end for end while Return: the best solution found
|
The different variants analyzed in this paper extend the particle representation by combining the continuous PSO, defined by
Eberhart and Kennedy (
1995) to determine the limits of the numerical attributes with the binary PSO by
Kennedy and Eberhart (
1997), to select which attributes will be part of the antecedent. In all cases, the neighborhood used to obtain the best solution is global, i.e., the entire population. Regarding the initial position of the particles within the population, and with the aim of reducing the construction time of the rule set, a competitive neural network has been used to identify the most promising areas of the search space. In other words, the algorithm performs, first, a grouping of the examples. Then, taking into account the centroids, particles are placed in order to generate the rules. The competitive neural networks used were Self Organization Map (SOM) and Learning Vector Quantization (LVQ). Both networks are intended to make a grouping of the input data, offering centroids as a result. Each centroid seeks to represent a set of input data based on a previously defined similarity or distance measure. The difference between SOM and LVQ lies on the learning mechanism. Whereas SOM is a unsupervised learning network, LVQ is a supervised learning network. SOM aims to provide additional information regarding the way in which groupings are organized. This is better than any other ‘winner-take-all’ type clustering technique, such as k-means. In contrast, as LVQ uses (during training) information on the expected response, it presents a better fit to the centroids. In this article, we use both architectures, with LVQ as the best performer.
In this way, particles begin the adaptation process within the most promising area of the search space, requiring fewer iterations in order to get a good solution. The size of the population is an important factor in the performance of the algorithm. Therefore, fixed and variable population PSO methods were analyzed. Fixed population PSO defines the population size before starting the search process. Population size definition puts certain limitations on the efficacy and efficiency of the algorithm. On the one hand, if few individuals are used, several areas of the search space will remain unexplored. On the other hand, if too many individuals are used, convergence time will increase.
This inconvenience could by bypassed using the variable population PSO (VarPSO) proposed by
Lanzarini et al. (
2008). This method allows one to control the number of particles throughout the adaptive process, using concepts such as lifetime and neighborhood. VarPSO eliminates the necessity to define beforehand the quantity of solutions to be used. The population size variation is based on a modification of the adaptive process allowing the addition and/or elimination of individuals based on their ability to solve the problem. This is mainly done through the concept of life time, which allows the determination of the time that each element belongs to the population. PSO tends to quickly populate the explored areas with good fitness. To avoid overpopulation over a restricted area, each individual’s neighborhood is analyzed, and the worst solutions of very populated areas are eliminated.
Among the variants analyzed using PSO, the best results were obtained with Fuzzy Rules Variable Patricle Swarm Optimization (FRvarPSO) that uses a cluster of particles of variable size, initialized through a competitive neural network and incorporating fuzzy attributes to express the conditions related to numerical variables. The goal of this method is to obtain a low cardinality and easy to interpret set of classification rules with adequate accuracy. We consider two important aspects. First, the ability of the method to operate with fuzzy attributes. Second, the addition of information based on membership degrees both in the fitness evaluation and in the way the search is carried out through the optimization technique.
The i-th particle of the population (for models FRvarPSO) is represented in the following way:
is a binary vector that stores the current position of the particle and indicates which items or conditions make up the antecedent of the rule according to PSO.
and are combined to determine the direction towards which the particle will move.
stores the best solution found by the particle so far.
is the fitness value of individual i.
is the fitness value of the best local solution found (vector ).
is a binary vector that indicates the possible values taken by each linguistic variable.
is a vector of real values that stores the average membership degrees of the examples that meet the rule, for each value of the linguistic variable.
indicates the change in direction of , with membership degree .
stores the best solution found by the particle for the membership degrees of the linguistic variable.
indicates which items or conditions make up the rule’s antecedent that actually represent the particle, and whose fitness is in .
is an integer number that indicates the remaining life time of the particle. This parameter is only used in variable population models.
The movement of the
i-th particle is controlled using a variant of PSO directed by the velocity vectors
and
, where
is the result of applying the sigmoid function. The binary individual that selects the conditions that make up the antecedent of the rule is expressed in
and emerges from
after removing the invalid solutions. In order to decide the value with which each linguistic variable may participate in the condition, vector
is added according to the average membership degrees of each linguistic variable in the different fuzzy sets. This average is calculated according to the membership degrees of the examples that comply with the antecedent of the rule when evaluating fitness. This vector is the one used to modify the velocity vector
, as indicated in the real PSO version. Then,
is the result of applying the sigmoid function to
. Thus, it is a binary vector that indicates the possible values that each linguistic variable, if selected, can take. The fitness function of the PSO version that gives the best result, and whose representation was recently described, is the following.
where
support is a numerical value that measures the representativeness of the rule, and
confidence is another numerical value that represents the accuracy.
Support is calculated as the ratio of the number of cases or credit applications that the rule correctly predicts to the total number of studied cases.
Confidence is the quotient between the number of times the rule response is correctly divided by the number of times the rule is applied. In both cases, these are numerical values belonging to the interval
. If a rule has 0 support, that rule is incorrect in all cases: No credit application fulfills the rules, either because it does not verify the antecedent, or the consequent, or both. A rule with confidence 1 has always responded correctly.
factor1 is a penalty value in case the support is not within the ranges established in the algorithm. The second term in the fitness function reflects the importance given to the number of attributes included in the antecedent, and
factor2 is a constant.
The main difference of this work compared to
Jimbo et al. (
2018), is the detail obtained with the three optimization techniques used: (i) basic PSO, (ii) variable population PSO, and (iii) variable population PSO with fuzzy rules. Additionally, in this work we detail the variables that are used, emphasizing role of fuzzy variables in credit scoring problems.
4. Data and Results
This paper uses data from three financial institutions from Ecuador, regarding credit operations between January 2012 and December 2016. We analyze each institution separately. The data set includes not only personal and economic information about the clients, but also the history of more than granted 129,000 credit applications. Granted loans have several associated characteristics at the personal, microeconomic, and macroeconomic levels.
We analyze three data structures. The first one is related to credit subjects. This structure includes information from the borrowers, guarantors, and co-debtors of the credit and contingent operations, as well as the cardholders with overdue balances. The second structure includes all operations granted. This structure includes credit and contingent operations that have been granted, renewed, refinanced, or restructured each month. The last structure is related to transaction balances. It is updated monthly and includes the details of the balances of credit and contingent operations that are still active, indicating overdue operations and detailing the number of days.
In the case of microeconomic variables, the behavior of the client can be identified through three types of variables:
Descriptive variables: These define the general characteristics of the client, such as age, province of residence, economic activity, equity, gender, marital status, level of education, ocupation, housing ownership, family responsibilities, income, and expenses.
Credit history: This includes a summary of the customer’s previous operations. A representative list of variables is: quantity of previous credit operations, amount of such operations, interest rate, lines of credit, fulfillment of previous payments, collateral, and purpose of the loan.
Characterization of the loan: This is information about the repayment of previous loans. Loan unperformance is classified according to the length of late payment (30, 90, 180, 360, and +360 days).
The advantage of this data analysis is that the credit subject’s behavior over a time horizon is reviewed, including the customer’s past behavior.
In order to reduce the cardinality of the input data set, we conduct a correlation analysis in order to eliminate less representative variables. In order to reduce the cardinality of the input data set, we filter possible input variables by means of correlational analysis. The correlation matrix measures the relationships between pairs of variables. When the value of the relationship approaches one the variables, they are strongly related. On the contrary, when the value of the relationship is close to zero, the relationship is weaker. This allows us to eliminate the least representative variables. Several fields were also unified to include the income, expenses, and debts of the credit subject. The variables that were considered after the transformation were: year, month, province, destination of the loan, overdue days, value of the operation, cash and equivalent, total income, total assets, total expenses, and total debts.
Among the macroeconomic variables studied were: the consumer price index (CPI), Unified Basic Remuneration (UBR), and the stock market price of Corporación Favorita
1. Additionally, we took into account the type of credit, province, and date of the credit.
In addition to the value of the operation, we introduce, in our model, the following variables regarding the loan applicant’s financial situation: cash and equivalents, total income, total assets, total expenses, and total debts. These are not considered as numerical variables, but as linguistic ones. For example, the borrower’s income can be considered as “low”, “medium”, or “high”, with a degree of membership between 0 and 1. This assigned value, with its degree of membership was granted by the credit expert, according to the economic reality of Ecuador. For example, if low income is considered for the range of , the variable , would be defined as with a membership degree of 0.8.
Fuzzy membership functions are considered triangular. The values of fuzzy attributes were determined based on Unified Basic Remuneration (UBR), that is, the current value of the basic salary for each year.
Figure 1 shows the membership function of the variables “value of the operation” and “cash and equivalents”, related to the data of the Savings and Credit Cooperative
2. In the case of the variable, “value of the operation” (in dollars), we defined three ranges of values: low, for operations in the interval
; medium, for operations in the interval
; and high for operations in the interval
. In the case of the variable “cash and equivalents”, the intervals are: Low
, Medium
, and High
. The fuzzy sets were defined with the help of an expert in the area of credit risk, according to the economic situation of Ecuador. For a detailed review of how fuzzy sets works, see
Klir and Yuan (
1995).
The proposed FRvarPSO method was compared with the performance of several methods that combine fixed and variable population PSO, initialized with two different competitive neural networks: LVQ and SOM (
Kohonen 2012).
The result of the classification rules of the fuzzy models also indicates the level of risk in granting the credit. The antecedent of the classification rules is formed by nominal and/or linguistic variables, facilitating the interpretation by the credit officer.
Classification rules are characterized in that their consequent, also called the conclusion of the rule, identifies the value of the class that applies to the examples covered by those rules. Therefore, the consequent of all the rules that make up the set of rules must refer to the same attribute or characteristic, which corresponds to the expected response. In the case of our credit granting problem, the consequent refers to the granting or denial of credit. An example of a classification rule applied to credit risk is:
IF (Income is high) AND (Expenses is medium) AND (delinquency is low) THEN (grant the credit).
We performed 25 independent runs for each method and computed the mean and standard deviations of the classification accuracy and the resulting number of rules. One important feature of our method is that the algorithm uses random values in order to ensure the movement of the particle is not excessively deterministic. The most important characteristic of this paper’s results is the accuracy improvement with respect to what is reported in
Lanzarini et al. (
2008). This accuracy improvement is due to set of fuzzy classification rules, which stems from micro and macroeconomic variables.
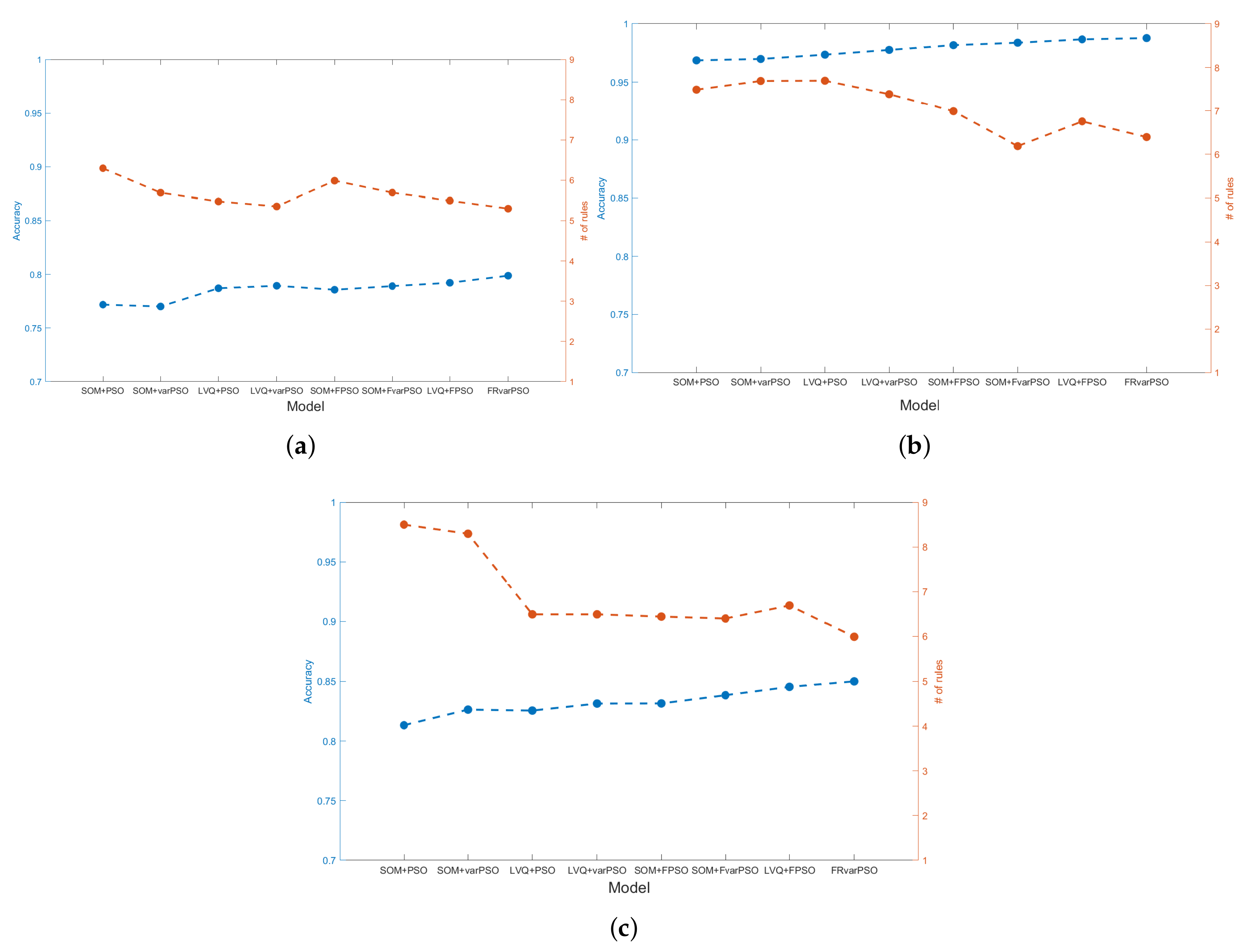
The performance of the methods SOM+PSO, SOM+varPSO, LVQ+PSO, and LVQ+varPSO, and their fuzzy versions SOM+Fuzzy PSO, SOM+Fuzzy varPSO, LVQ+Fuzzy PSO, and LVQ+Fuzzy varPSO, is detailed in
Table 1 and graphically displayed in
Figure 2. We observe that for all three financial institutions, the method FRvarPSO exhibits the best accuracy with the lowest number of rules. In other words, FRvarPSO offers the most straightforward model for any level of accuracy. As a consequence, this provides the credit analyst easier arguments to understand the reason for granting or denying credit.
5. Conclusions
In the present article, we carried out a comparative analysis of several classification methods. We applied these methods to real credit risk analysis, based on the combination of a competitive neural network (either SOM or LVQ) and an optimization technique (either PSO or varPSO). We compared the performance of crisp and fuzzy versions of the models. The results obtained in the fuzzy versions were satisfactory.
We detect that the proposed FRvarPSO method combines very good precision with a low cardinality rule set. A financial institution could use this technique in order to manage their credit risk. At the same time, this could help credit officers improve their understanding of the decision model, as the rules are formed by fuzzy variables. This situation could improve the solvency of financial institutions, as well as enhance the transparency in loan granting decisions.
The use of a fuzzy logic approach in a credit scoring problem, in order to reduce the risk in granted loans, reinforces the viability and sustainability of microfinance institutions. Fuzzy logic is useful where there is uncertainty, as in the case of granting credit. Working variables are characterized by their conceptual vagueness and imprecision. Their treatment as fuzzy variables is suitable and it is fully justified. The use of linguistic terms contextualizing observed values through membership functions allows the expression and interpretation of rules in a more reasonable way.
Considering that FRvarPSO is a hybrid method that uses fuzzy logic, neural networks, and optimization techniques, it represents an alternative with greater performance than those models that use a single technique, such as linear discriminant methods, logistic regression methods, or neural networks. Additionally, our method has the advantage of allowing the identification of the risk in the granting of credit, with considerable precision.
The empirical application of this paper was conducted in the financial market of Ecuador. However, our results can be extrapolated to other markets (not only in Latin America), as credit scoring relies not only on the customer’s financial health, but on the overall strength of the economy. Future research will include a deeper study on the methods for optimizing the variables membership functions. This could lead to an improvement in the FRvarPSO model. Studies could also consider the incorporation of a defuzzification procedure for the output variable, to indicate the percentage of risk that is taken by granting a given credit. This measurement will provide the credit committee with strategic information on the consequences of lowering the threshold for granting credit.






{kind=link}
{kind=link}