Optimal Stopping and Utility in a Simple Modelof Unemployment Insurance


Abstract
1. Introduction
2. Optimal Stopping Problem
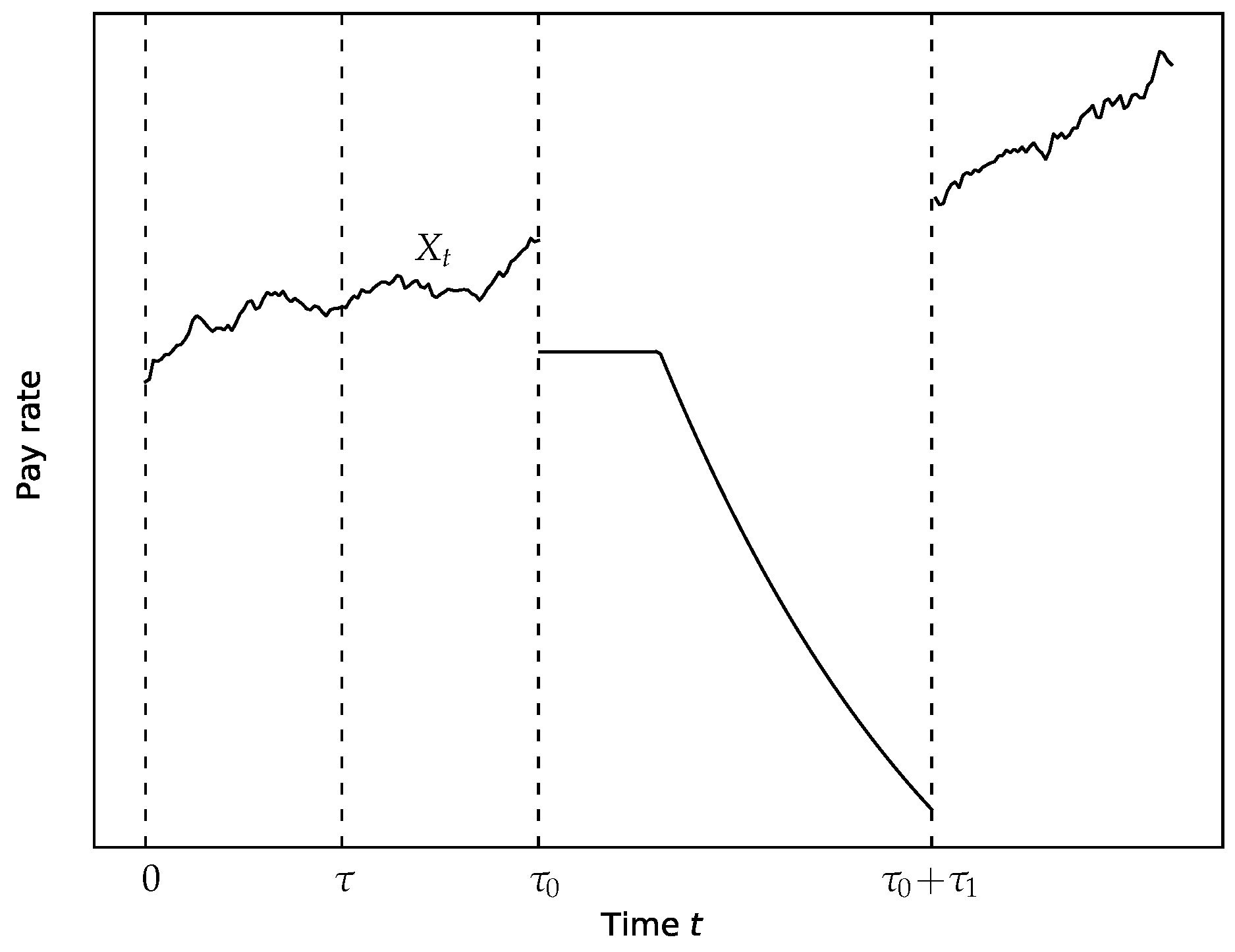
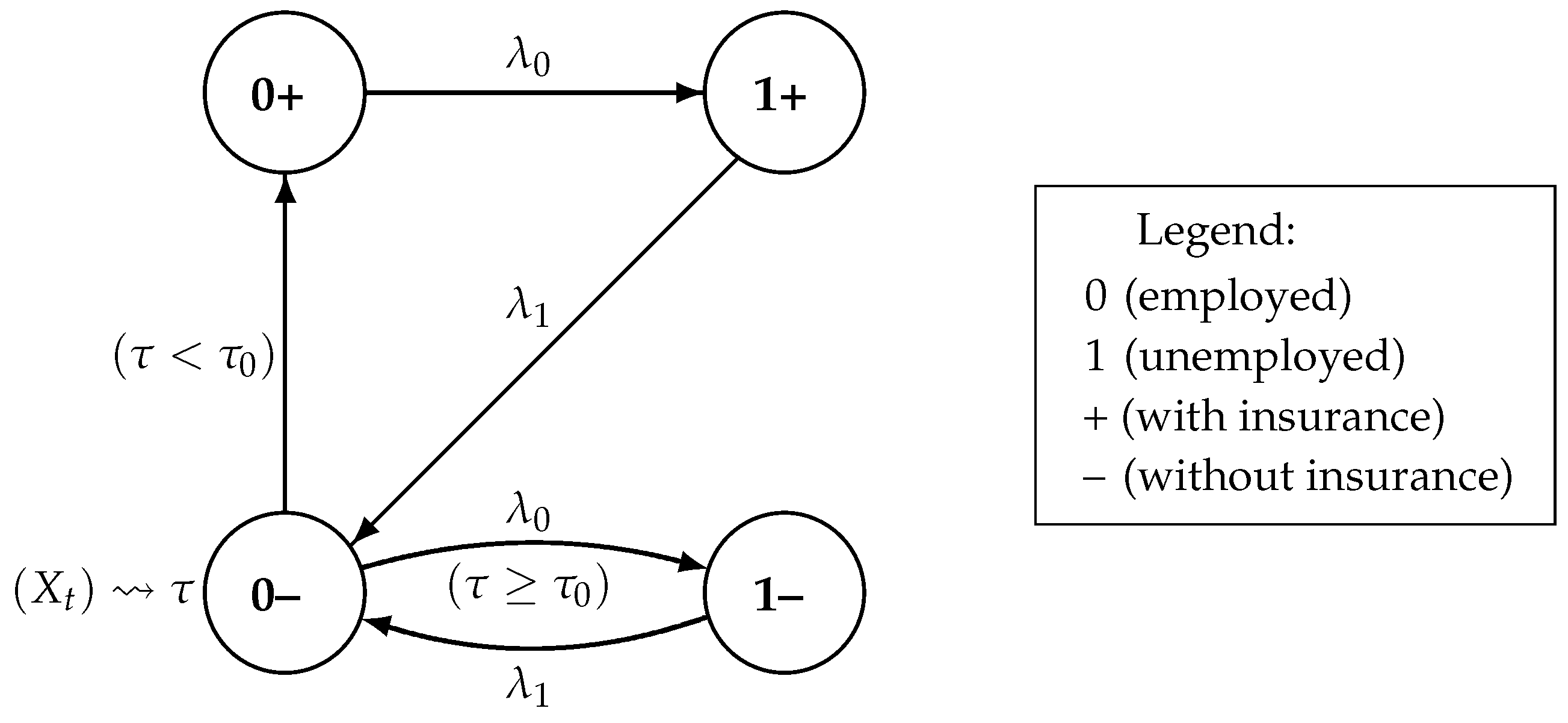
2.1. The Model of Unemployment Insurance
2.2. Setting the Optimal Stopping Problem
2.3. Allowing for Mortality
2.4. A Priori Properties of the Value Function
- (i)
- and, moreover, for all ;
- (ii)
- for all .
2.5. The Optimal Stopping Rule
2.6. Deterministic Case
3. Solving the Optimal Stopping Problem
3.1. Guessing the Solution
3.2. Free-Boundary Problem
3.3. Verification of the Found Solution
- (i)
- Let us first show that ). If the map was a -function (i.e., with continuous second derivative), then the classical Itô formula (Øksendal 2003, Theorem 4.1.2, p. 44) applied to would yield, on account of (1) and (36),whereHowever, for the function given by (43), its -smoothness breaks down at the point , where it is only . However, is strictly convex on (i.e., ) and linear on , and we can define the action at by using the one-sided second derivative, say,In this situation, a generalization of the Itô formula holds, known as the Itô–Meyer formula (see (Shiryaev 1999, chp. VIII, §2a, p. 757)), which ensures that the representation (45) is still valid.Recall that by construction (see the differential equation in (38)), we haveMoreover, it is easy to check using (47) that the equality (48) also extends to . On the other hand, on account of the condition (11) and the definition of b in (42), for we getbecause, due to the Equation (40) and the inequality ,According to formula (46), is a continuous local martingale (Shiryaev 1999, chp. II, §1c, p. 101). Let be a localizing sequence of bounded stopping times, so that (-a.s.) and the stopped process is a martingale, for each .Now, let be an arbitrary stopping time of (. From (51) we getusing that for all (see (44)). Taking expectation on both sides of the inequality (52) givessince by Doob’s optional sampling theorem (Yeh 1995, Theorem 8.10, p.131)Finally, taking in (54) the supremum over all stopping times , we obtainas claimed.
- (ii)
- Let us now prove the opposite inequality, (). According to (30) and (44), we readily have for . Next, fix and consider the representation (45) with t replaced by , where is the localizing sequence of stopping times for () as before. Then, by virtue of the identity (48) (which, as has been explained, is also true for ), it follows thatSimilarly as above, taking expectation on both sides of the equality (55) and again applying Doob’s optional sampling theorem to the martingale , we obtainNote that, for , we have and (-a.s.), henceUsing that , observe that, -a.s.,because on the event , while on the event . Hence, letting in (56) and using the dominated convergence theorem (Shiryaev 1996, §II.6, Theorem 3, p. 187), we get, on account of (57),according to (17). That is, we have proved that for all , as required.
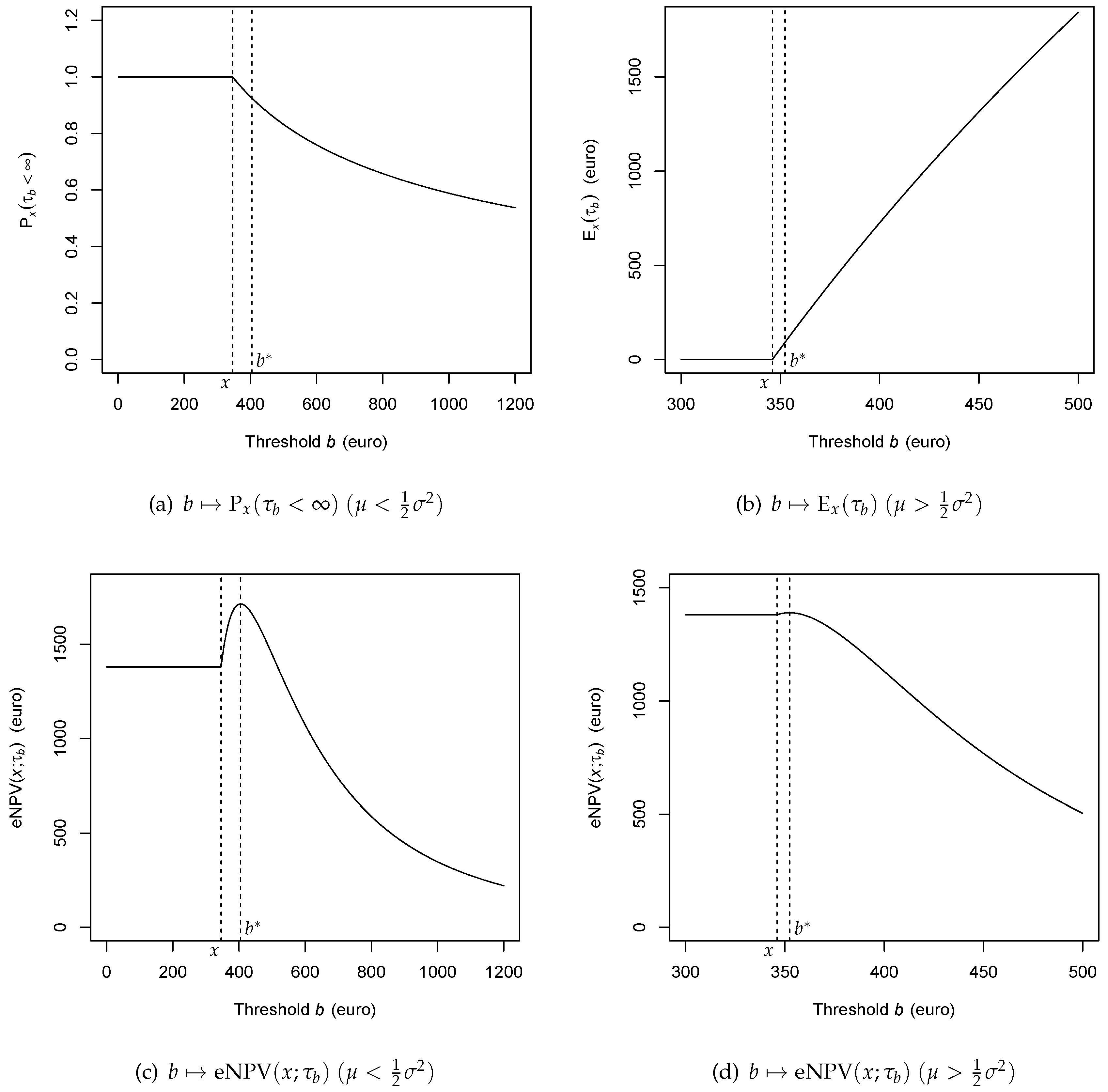
4. Elementary Solution of the Reduced Problem
4.1. Distribution of the Hitting Time
4.2. Alternative Derivation
4.3. Direct Maximization
5. Statistical Issues and Numerical Illustration
5.1. Specifying the Model Parameters
- The loss of job rate can be extracted from the publicly available data about the mean length at work, which is theoretically given by .
- Likewise, the inflation rate r is also in the public domain.
- To specify the wage growth rate , a simple approach is just to set as a crude version of a “tracking” rule. However, it may be possible that the individual’s wage growth rate is, to some extent, stipulated by the job contract—for example, that it must not exceed the inflation rate r by more than 1% per annum (applicable, e.g., to civil servants) or, by contrast, that it must be no less than r minus 0.5% per annum (more realistic in the private sector). In practical terms, this would often mean that the actual growth rate is kept on the lowest predefined level.
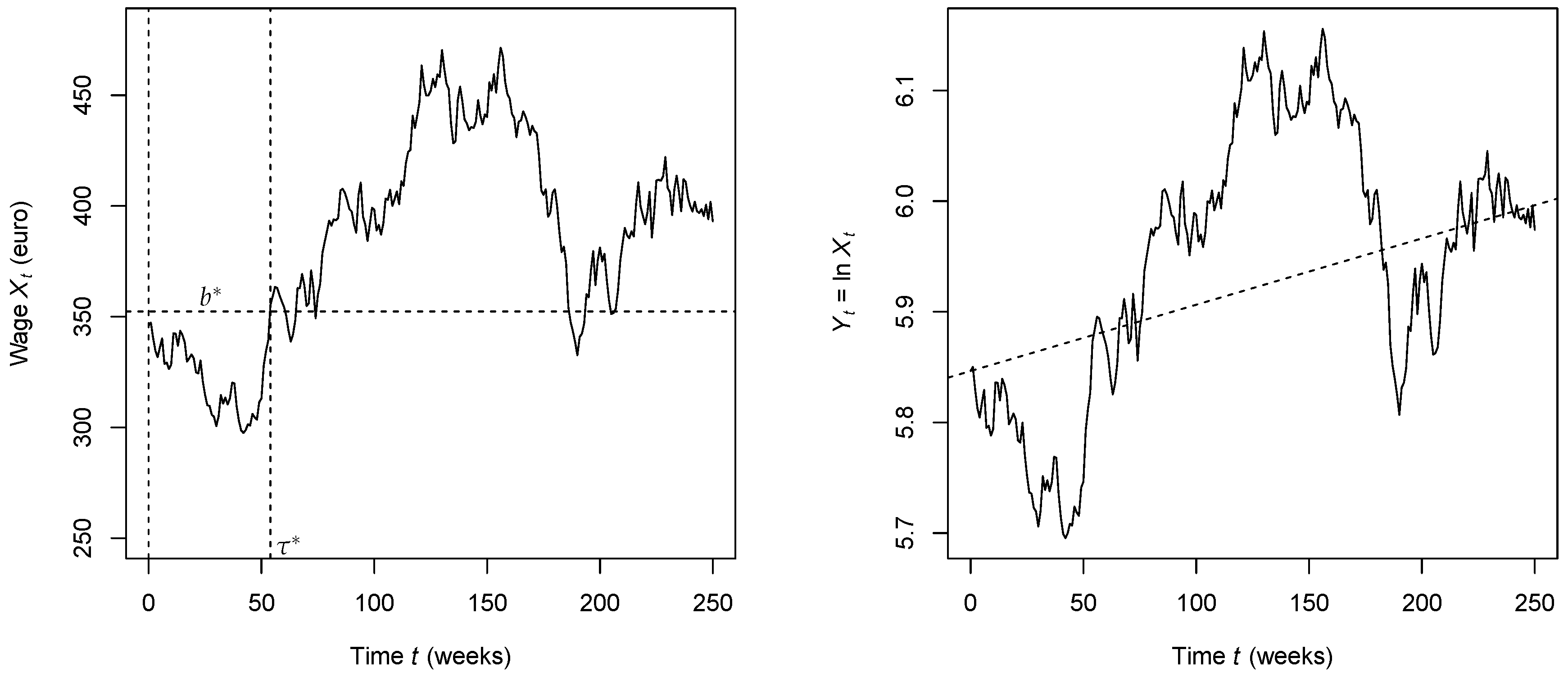
- More generally, the wage growth rate can be estimated by observing the wage process . This can be implemented by first using regression analysis on and estimating the regression line slope (see (2)). In addition, the volatility can be estimated by using a suitable quadratic functional of the sample path .
- Finally, knowing the benefit schedule (which should be available through the insurance policy’s terms and conditions), it is in principle possible to calculate, or at least estimate the value .
5.2. Estimating the Drift and Volatility
5.3. Hypothesis Testing
5.4. Numerical Examples
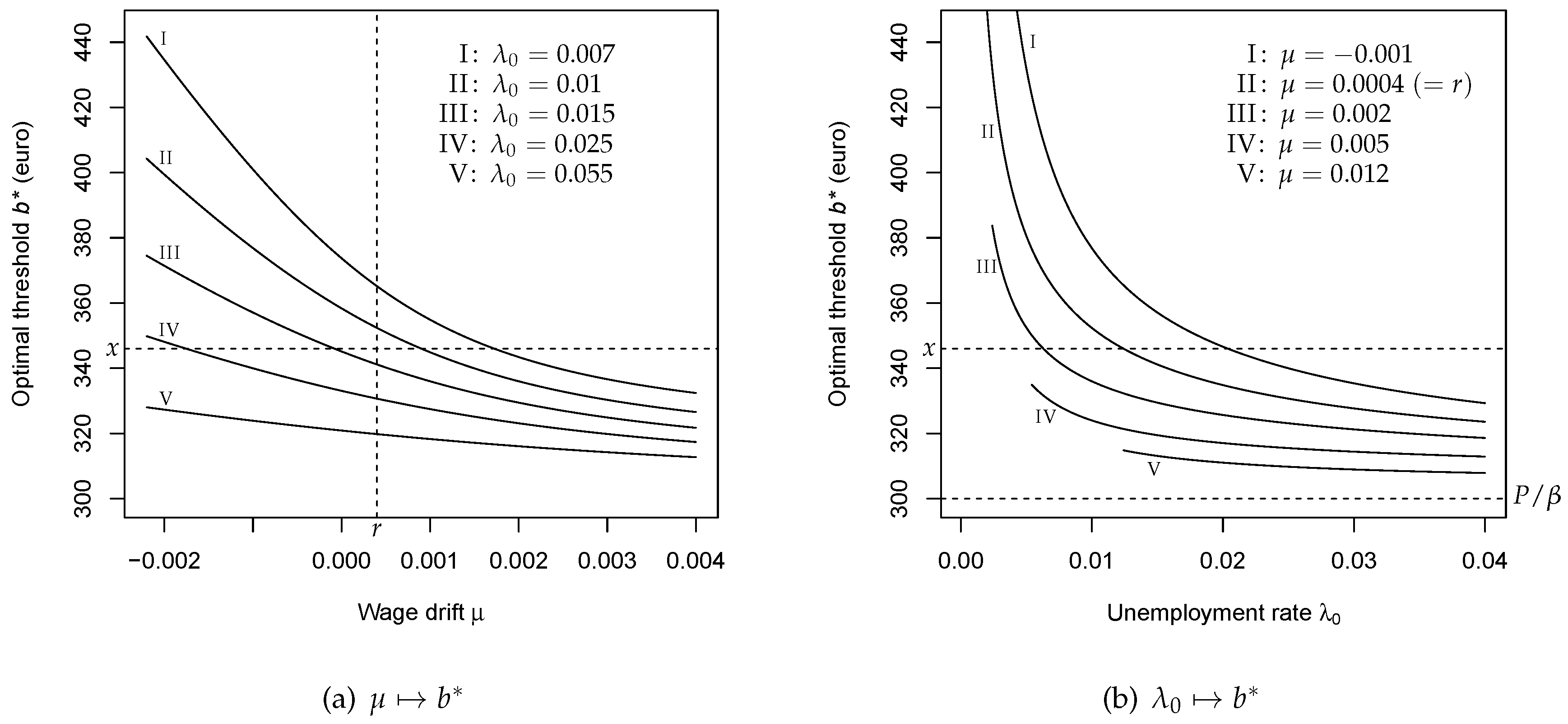
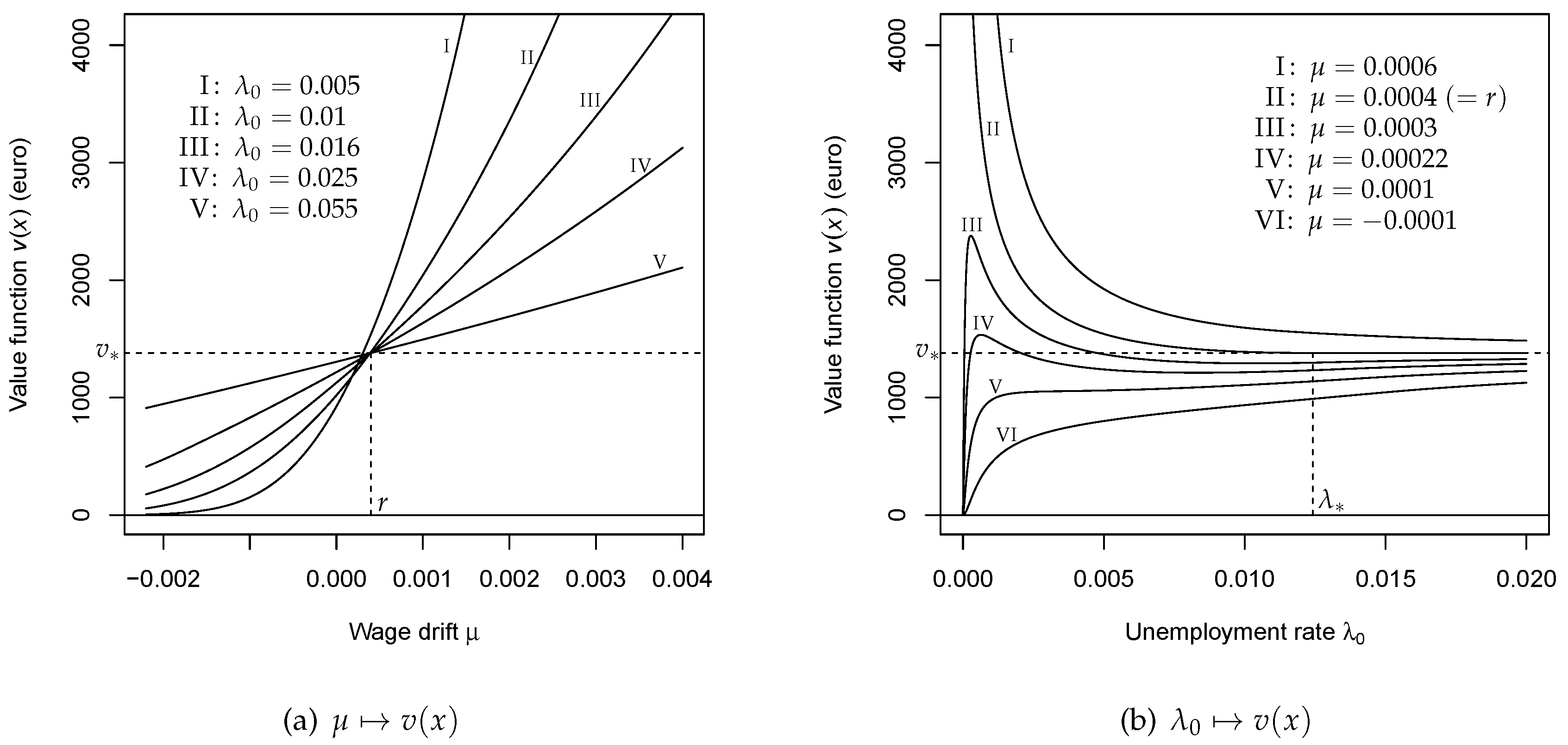
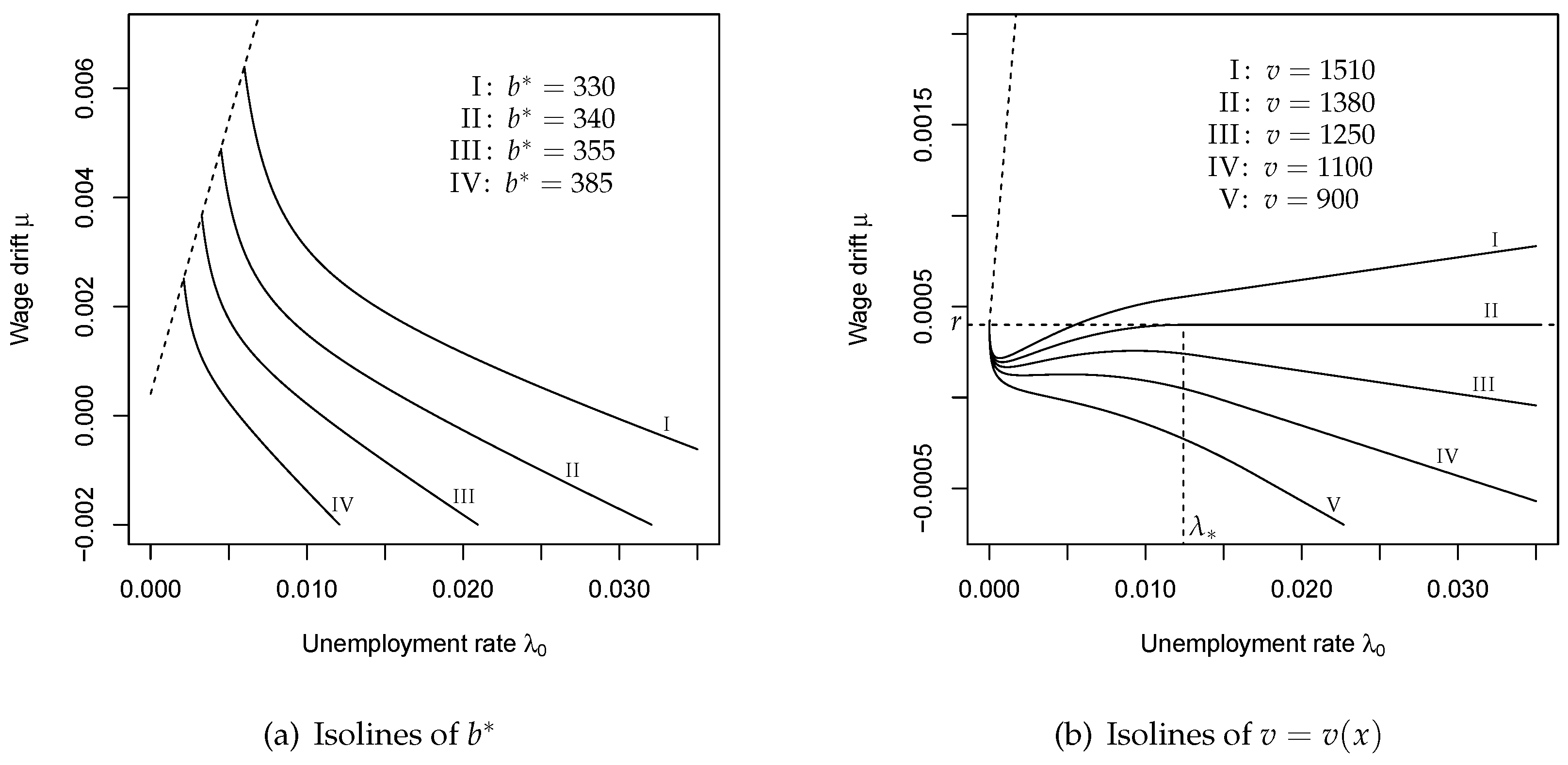
6. Parametric Dependencies
6.1. Monotonicity
6.2. Limiting Values
6.3. Comparative Statics and Sensitivity Analysis
6.4. Economic Interpretation
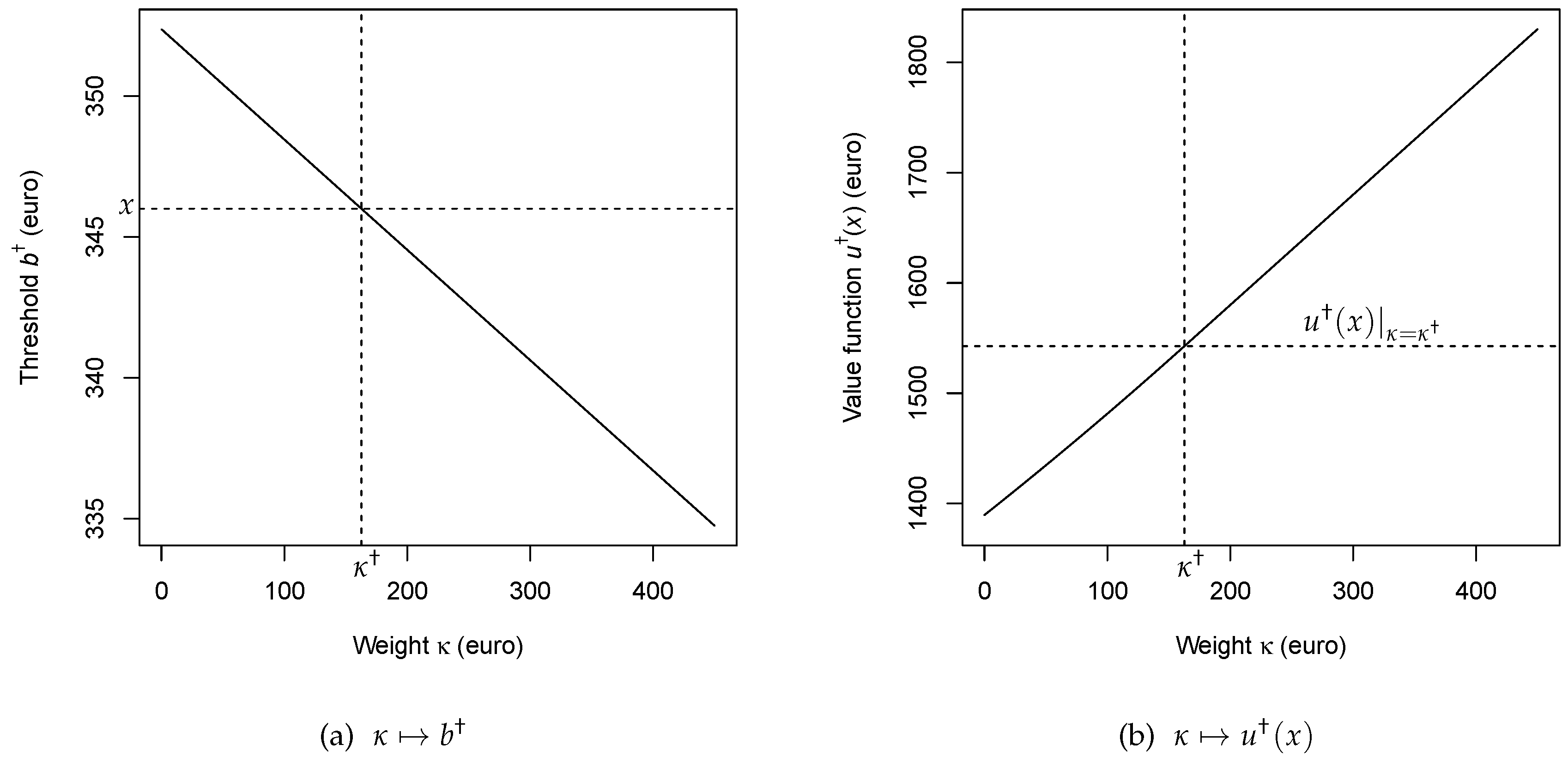
7. Including Utility Considerations
7.1. Perpetual American Call Option
7.2. Heuristic Optimal Stopping Models with Utility
7.3. Suboptimal Solutions
7.4. Connections to Expected Utility Theory
8. Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Acemoglu, Daron, and Robert Shimer. 2000. Productivity gains from unemployment insurance. European Economic Review 44: 1195–224. [Google Scholar] [CrossRef]
- Baily, Martin Neil. 1978. Some aspects of optimal unemployment insurance. Journal of Public Economics 10: 379–402. [Google Scholar] [CrossRef]
- Borch, Karl. 1961. The utility concept applied to the theory of insurance. ASTIN Bulletin 1: 245–55. [Google Scholar] [CrossRef]
- Boshuizen, Frans A., and José M. Gouweleeuw. 1995. A continuous-time job search model: General renewal processes. Communications in Statistics. Stochastic Models 11: 349–69. [Google Scholar] [CrossRef]
- Chen, Xiaoshan, Xun Li, and Fahuai Yi. 2019. Optimal stopping investment with non-smooth utility over an infinite time horizon. Journal of Industrial and Management Optimization 15: 81–96. [Google Scholar] [CrossRef]
- Choi, Kyoung Jin, and Gyoocheol Shim. 2006. Disutility, optimal retirement, and portfolio selection. Mathematical Finance 16: 443–67. [Google Scholar] [CrossRef]
- De Angelis, Tiziano, and Gabriele Stabile. 2019. On the free boundary of an annuity purchase. Finance and Stochastics 23: 97–137. [Google Scholar] [CrossRef]
- Dhami, Sanjit. 2016. The Foundations of Behavioral Economic Analysis. Oxford: Oxford University Press. [Google Scholar]
- Durrett, Rick. 1999. Essentials of Stochastic Processes, 1st ed. Springer Texts in Statistics. Springer: New York. [Google Scholar]
- Ekström, Erik, and Bing Lu. 2011. Optimal selling of an asset under incomplete information. International Journal of Stochastic Analysis 2011: 543590. [Google Scholar] [CrossRef]
- Estevão, Marcello, and Filipa Sá. 2008. The 35-hour workweek in France: Straightjacket or welfare improvement? (with comments by Barbara Petrongolo and panel discussion). Economic Policy 23: 417–63. [Google Scholar] [CrossRef]
- Etheridge, Alison. 2002. A Course in Financial Calculus. Cambridge: Cambridge University Press. [Google Scholar] [CrossRef]
- Fredriksson, Peter, and Bertil Holmlund. 2006. Optimal unemployment insurance design: Time limits, monitoring, or workfare? International Tax and Public Finance 13: 565–85. [Google Scholar] [CrossRef][Green Version]
- Gerrard, Russell, Bjarne Højgaard, and Elena Vigna. 2012. Choosing the optimal annuitization time post-retirement. Quantitative Finance 12: 1143–59. [Google Scholar] [CrossRef]
- GoCompare. 2018. Unemployment Protection Insurance (Search & Comparison Web Site). Available online: www.gocompare.com/unemployment-protection (accessed on 22 August 2019).
- Gubian, Alain, Stéphane Jugnot, Frédéric Lerais, and Vladimir Passeron. 2004. Les effets de la RTT sur l’emploi: Des estimations ex ante aux évaluations ex post (French). [The effects of the shorter working week on employment: From ex-ante simulations to ex-post evaluations.]. Économie et Statistique 376–377: 25–54. Available online: www.persee.fr/doc/estat_0336-1454_2004_num_376_1_7233 (accessed on 22 August 2019). [CrossRef]
- Hairault, Jean-Olivier, François Langot, Sébastien Ménard, and Thepthida Sopraseuth. 2007. Optimal unemployment insurance in a life cycle model. Society for Economic Dynamics Meeting Papers, Paper 422. 25p. Available online: https://economicdynamics.org/meetpapers/2007/paper_422.pdf (accessed on 22 August 2019).
- Henderson, Vicky, and David Hobson. 2008. An explicit solution for an optimal stopping/optimal control problem which models an asset sale. Annals of Applied Probability 18: 1681–705. [Google Scholar] [CrossRef]
- Holmlund, Bertil. 1998. Unemployment insurance in theory and practice. Scandinavian Journal of Economics 100: 113–41. [Google Scholar] [CrossRef]
- Hopenhayn, Hugo A., and Juan Pablo Nicolini. 1997. Optimal unemployment insurance. Journal of Political Economy 105: 412–38. [Google Scholar] [CrossRef]
- Jang, Bong-Gyu, Seyoung Park, and Yuna Rhee. 2013. Optimal retirement with unemployment risks. Journal of Banking and Finance 37: 3585–604. [Google Scholar] [CrossRef]
- Jensen, Uwe. 1997. An optimal stopping problem in risk theory. Scandinavian Actuarial Journal 1997: 149–59. [Google Scholar] [CrossRef]
- Kaas, Rob, Marc Goovaerts, Jan Dhaene, and Michel Denuit. 2008. Modern Actuarial Risk Theory Using R, 2nd ed. Berlin: Springer. [Google Scholar] [CrossRef]
- Karpowicz, Anna, and Krzysztof Szajowski. 2007. Double optimal stopping of a risk process. Stochastics 79: 155–67. [Google Scholar] [CrossRef]
- Kerr, Kevin B. 1996. Unemployment compensation systems and reforms in selected OECD countries. Background Paper BP-415E, Library of Parliament, Parliamentary Research Branch. Ottawa: Government of Canada Publications. 22p. Available online: http://publications.gc.ca/collections/Collection-R/LoPBdP/BP-e/bp415-e.pdf (accessed on 22 August 2019).
- Kolsrud, Jonas, Camille Landais, Peter Nilsson, and Johannes Spinnewijn. 2018. The optimal timing of unemployment benefits: Theory and evidence from Sweden. American Economic Review 108: 985–1033. [Google Scholar] [CrossRef]
- Landais, Camille, Arash Nekoei, Peter Nilsson, David Seim, and Johannes Spinnewijn. 2017. Risk-based selection in unemployment insurance: Evidence and implications. IFS Working Paper W17/22. London: Institute for Fiscal Studies. 69p. [Google Scholar] [CrossRef]
- Landais, Camille, and Johannes Spinnewijn. 2017. The value of unemployment insurance. CEPR Discussion Paper No. DP13624. London: Centre for Economic Policy Research (CEPR). 70p. Available online: https://cepr.org/active/publications/discussion_papers/dp.php?dpno=12364 (accessed on 22 August 2019).
- McCall, John J. 1970. Economics of information and job search. The Quarterly Journal of Economics 84: 113–26. [Google Scholar] [CrossRef]
- Merton, Robert C. 1969. Lifetime portfolio selection under uncertainty: The continuous-time case. The Review of Economics and Statistics 51: 247–57. [Google Scholar] [CrossRef]
- Merton, Robert C. 1971. Optimum consumption and portfolio rules in a continuous-time model. Journal of Economic Theory 3: 373–413. [Google Scholar] [CrossRef]
- Muciek, Bogdan Krzysztof. 2002. Optimal stopping of a risk process: Model with interest rates. Journal of Applied Probability 39: 261–70. [Google Scholar] [CrossRef]
- Neumann, John von, and Oskar Morgenstern. 1953. Theory of Games and Economic Behavior, 3rd ed. Princeton: Princeton University Press. [Google Scholar]
- Øksendal, Bernt. 2003. Stochastic Differential Equations: An Introduction with Applications, 6th ed. Universitext. Berlin: Springer. [Google Scholar] [CrossRef]
- Peskir, Goran, and Albert Shiryaev. 2006. Optimal Stopping and Free-Boundary Problems. Lectures in Mathematics, ETH Zürich. Basel: Birkhäuser. [Google Scholar] [CrossRef]
- Pham, Huyên. 2009. Continuous-Time Stochastic Control and Optimization with Financial Applications. Stochastic Modelling and Applied Probability. Berlin: Springer, vol. 61. [Google Scholar] [CrossRef]
- Rebollo-Sanz, Yolanda F., and J. Ignacio García-Pérez. 2015. Are unemployment benefits harmful to the stability of working careers? The case of Spain. SERIEs 6: 1–41. [Google Scholar] [CrossRef][Green Version]
- Shiryaev, Albert N. 1996. Probability, 2nd ed. Graduate Texts in Mathematics. New York: Springer, vol. 95. [Google Scholar] [CrossRef]
- Shiryaev, Albert N. 1999. Essentials of Stochastic Finance: Facts, Models, Theory. Advanced Series on Statistical Science & Applied Probability; Singapore: World Scientific, vol. 3. [Google Scholar] [CrossRef]
- Stabile, Gabriele. 2006. Optimal timing of the annuity purchase: Combined stochastic control and optimal stopping problem. International Journal of Theoretical and Applied Finance 9: 151–70. [Google Scholar] [CrossRef]
- Villeneuve, Stéphane. 2007. On threshold strategies and the smooth-fit principle for optimal stopping problems. Journal of Applied Probability 44: 181–98. [Google Scholar] [CrossRef]
- WageIndicator. 2018. Minimum Wages in France with effect from 01-01-2018 to 31-12-2018. Available online: https://wageindicator.org/salary/minimum-wage/france/archive/minimum-wages-in-france-with-effect-from-01-01-2018-to-31-12-2018 (accessed on 22 August 2019).
- Wang, Tan, and Tony S. Wirjanto. 2016. Risk aversion, uncertainty, unemployment insurance benefit and duration of “wait” unemployment. Annals of Economics and Finance 7: 1–34. Available online: http://aeconf.com/Articles/May2016/aef170101.pdf (accessed on 22 August 2019).
- Yeh, James. 1995. Martingales and Stochastic Analysis. Series on Multivariate Analysis; Singapore: World Scientific, vol. 1. [Google Scholar] [CrossRef]
| 1 | For technical convenience, we choose to work with continuous-time models, but our ideas can also be adapted to discrete time (which may be somewhat more natural, since the wage process is observed by the individual on a weekly time scale). |
| 2 | Impact of individualistic (not always rational) perception in economics and financial markets is the subject of the modern behavioral economics (see, e.g., a recent monograph by Dhami 2016). |
| 3 | More specifically, according to the French UI system back in the 1990s (Kerr 1996, p. 8), a worker aged 50 or more, with eight months of insurable employment in the last twelve months, was entitled to full benefits equal to 57.4% of the final wage payable for the first eight months, thereafter declining by 15% every four months; however, the payments continued for no longer than 21 months overall. This leads to choosing the following numerical values in (6): , (weeks) and (per week). The restriction of the benefit term by weeks can be taken into account in our model by adjusting the parameter from the condition , giving . A more conservative choice is to use a tail probability condition, for example, , yielding (with ). |
| 4 | This conclusion is in accord with the general optimal stopping theory (Peskir and Shiryaev 2006, §2.2). |
| 5 | The equivalence of the problems (105) and (106), which we have established directly, is not a coincidence: it is known (Villeneuve 2007, Proposition 3.1, p.185) that, under mild assumptions, the solution of the general optimal stopping problem does not change with the positive truncation of . |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) Derivatives | ||
| Derivative | Example 2 | Example 3 |
| (b) Increments (euro) | ||
| Increment | Example 2 | Example 3 |
| () | ||
| () | ||
| () | ||
| () | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anquandah, J.S.; Bogachev, L.V. Optimal Stopping and Utility in a Simple Modelof Unemployment Insurance. Risks 2019, 7, 94. https://doi.org/10.3390/risks7030094
Anquandah JS, Bogachev LV. Optimal Stopping and Utility in a Simple Modelof Unemployment Insurance. Risks. 2019; 7(3):94. https://doi.org/10.3390/risks7030094
Chicago/Turabian StyleAnquandah, Jason S., and Leonid V. Bogachev. 2019. "Optimal Stopping and Utility in a Simple Modelof Unemployment Insurance" Risks 7, no. 3: 94. https://doi.org/10.3390/risks7030094
APA StyleAnquandah, J. S., & Bogachev, L. V. (2019). Optimal Stopping and Utility in a Simple Modelof Unemployment Insurance. Risks, 7(3), 94. https://doi.org/10.3390/risks7030094