Penalising Unexplainability in Neural Networks for Predicting Payments per Claim Incurred

Abstract
:1. Introduction
1.1. Rationale
1.2. Granular Claims Models
1.3. Neural Networks
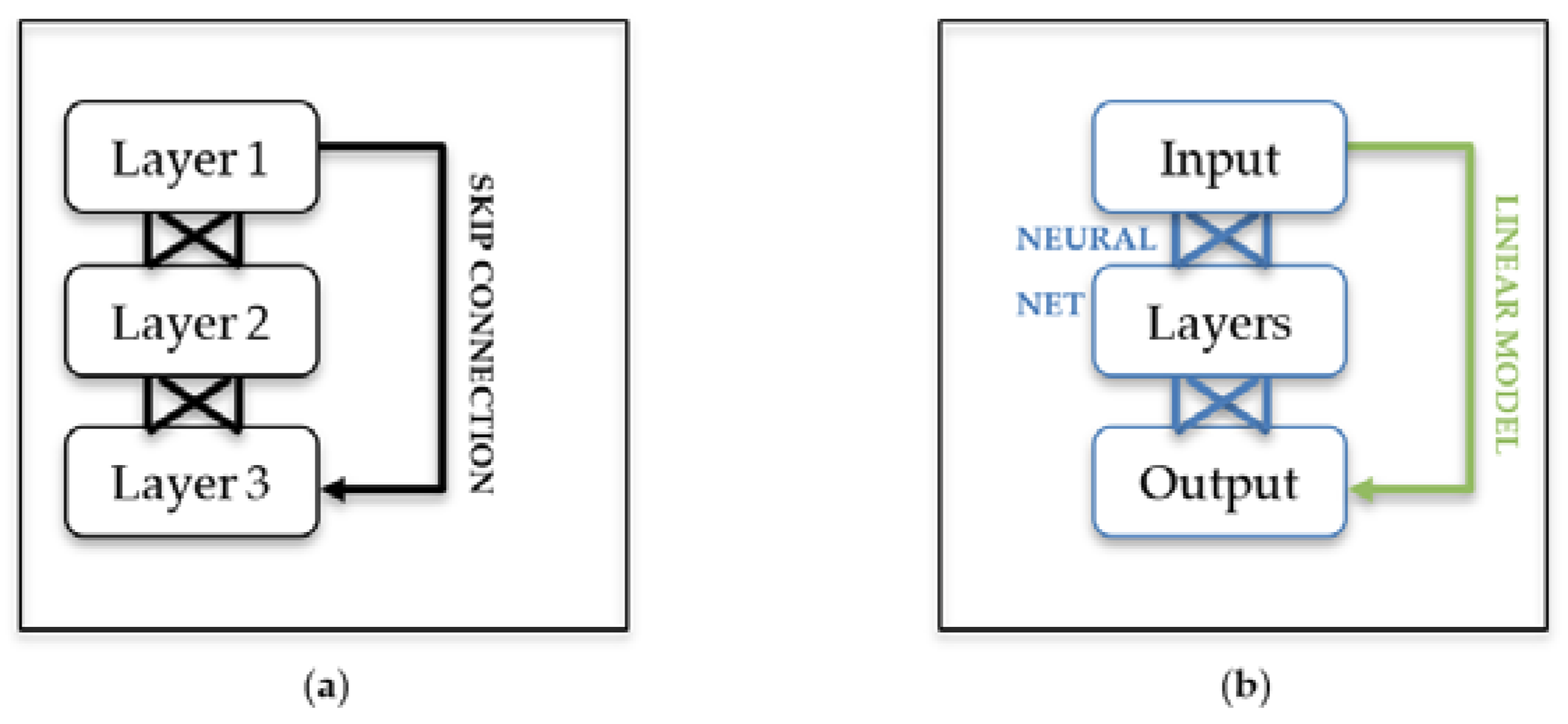
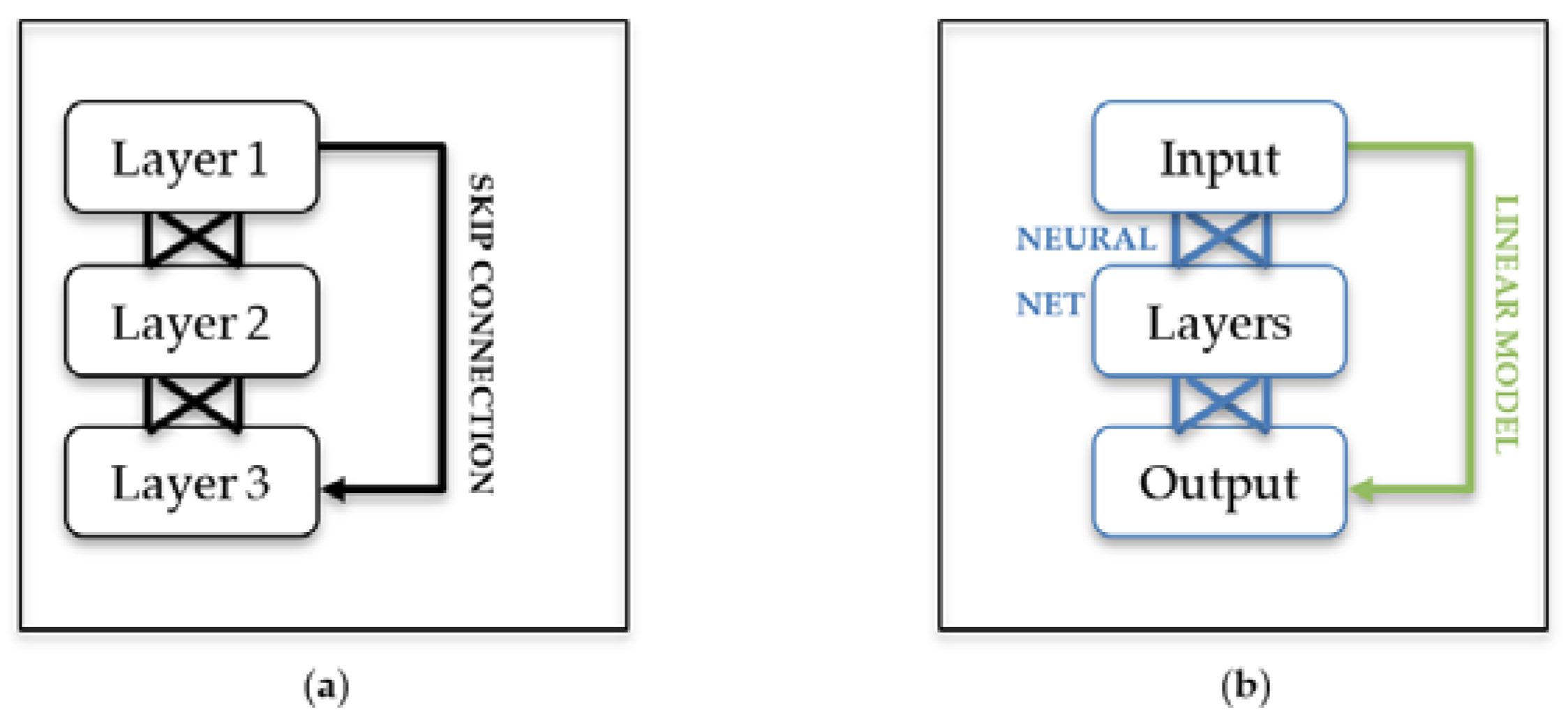
1.4. Residual Neural Networks
1.5. Embeddings
1.6. Hyperparameter Selection
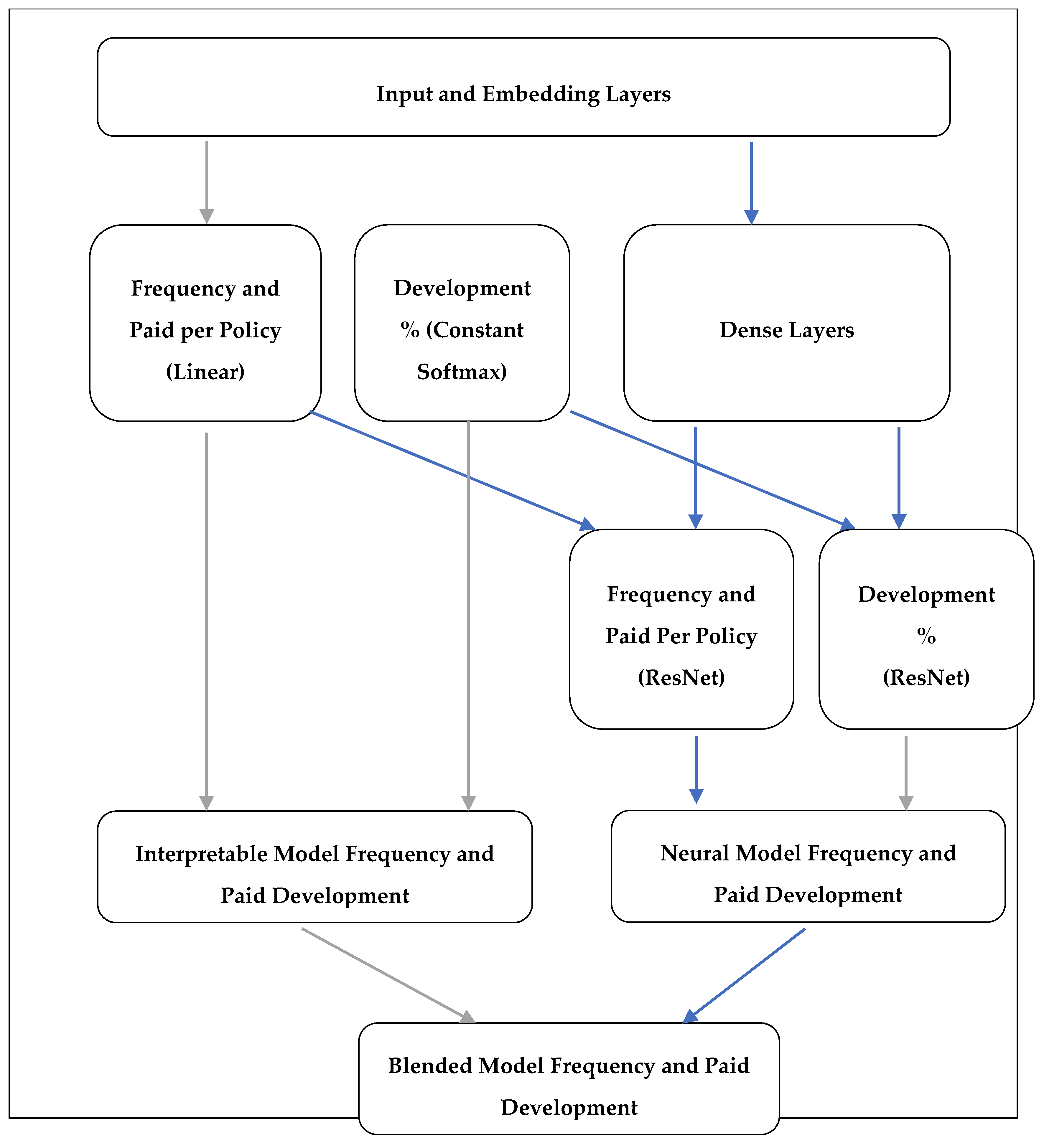
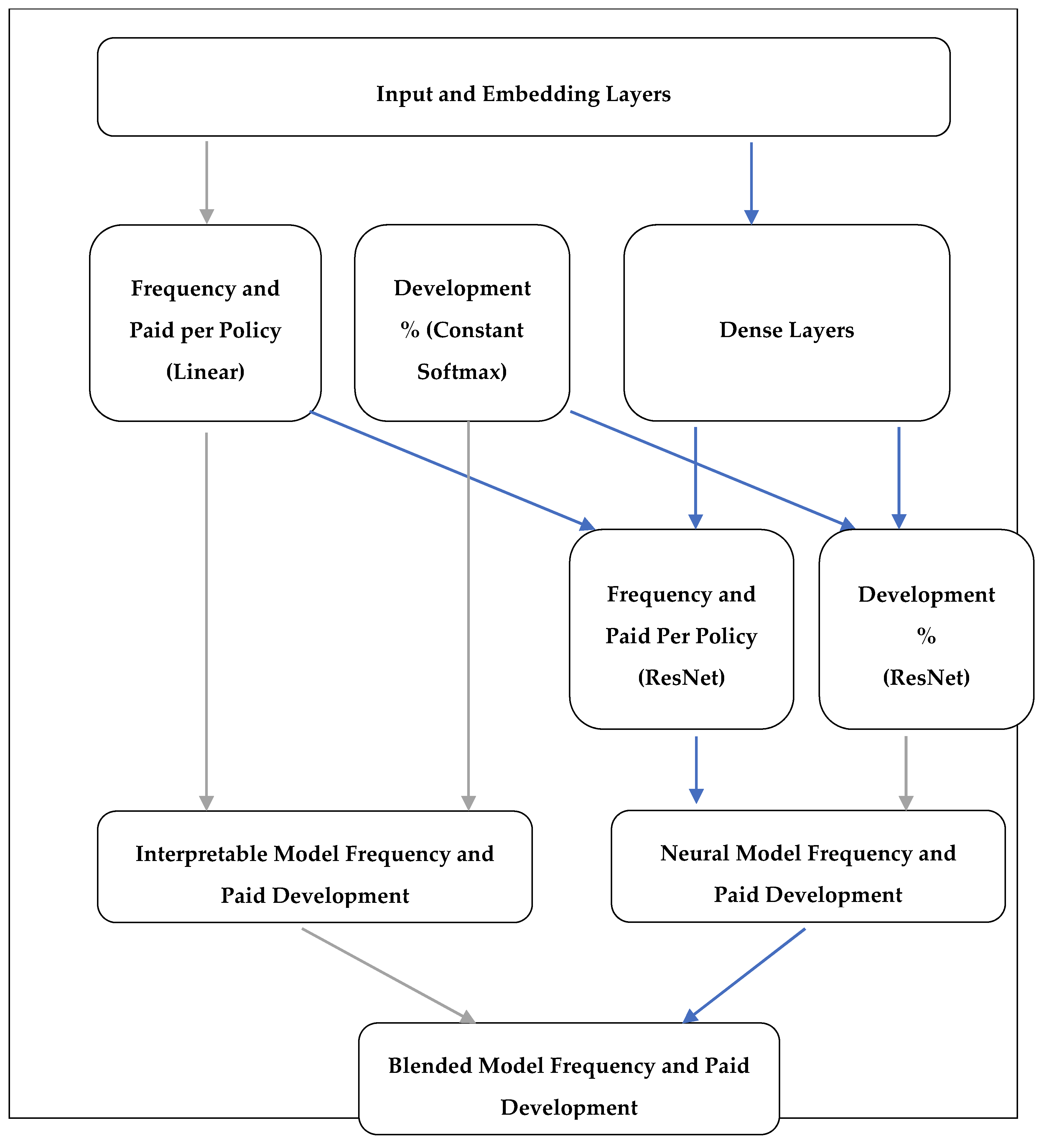
2. Model
2.1. Definitions
- The sum of ‘claim counts reported by delay’ by origin period is the incremental claims reported triangle,
- The sum of ‘claim payments by delay’ by origin period is the incremental payments triangle,
- If the claim counts and payments were the ultimates, it would be a typical GLM risk pricing dataset.
- The dataset remains reasonably compact as claims are in cross-tab format, which is beneficial from a memory usage perspective.
- xi be features, for policy exposures i, including the accident or origin period,
- wi,t be exposure weights for exposure i in delay period t, with missing data after the balance date being weighted as 0,
- Ci,t be claim count reported for the exposure in delay period t, with Ci = ΣCi,t and
- Pi,t be claim payments for the exposure in delay period t, with Pi = ΣPi,t.
2.2. From Payments Per Claim Incurrred to Granular Model
2.3. Network
2.4. Loss
2.5. Training: Dropout, Optimiser, Shuffling, Batch Size, and Learn Rate Scheduler
2.6. Language and Package
3. Dataset Used
3.1. Dataset Details
3.2. Cleaning and Sampling
3.3. Comparison with Manual Selections for Chain Ladder and PPCI
4. Results
4.1. Sampling Sizes
4.2. Bayesian Optimisation of Hyperparameters
4.3. Regularisation
5. Extending with Freeform Data—Claim Description
6. Conclusions
Funding
Conflicts of Interest
References
- Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of Bidirectional Transformers for Language Understanding. arXiv, arXiv:1810.04805. [Google Scholar]
- Fotso, Stephane. 2018. Deep Neural Networks for Survival Analysis Based on a Multi-Task Framework. arXiv, arXiv:1801.05512v1. [Google Scholar]
- He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Deep Residual Learning for Image Recognition. arXiv, arXiv:1512.03385. [Google Scholar]
- Kingma, Diederik, and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. arXiv, arXiv:1412.6980. [Google Scholar]
- Kuo, Kevin. 2018. DeepTriangle: A Deep Learning Approach to Loss Reserving. arXiv, arXiv:1804.09253v3. [Google Scholar]
- Miller, Hugh, Gráinne McGuire, and Greg Taylor. 2016. Self-Assembling Insurance Claim models. Available online: https://actuaries.asn.au/Library/Events/GIS/2016/4dHughMillerSelfassemblingclaimmodels.pdf (accessed on 24 August 2019).
- Poon, Jacky. 2018. Analytics Snippet: Multitasking Risk Pricing Using Deep Learning. Available online: https://www.actuaries.digital/2018/08/23/analytics-snippet-multitasking-risk-pricing-using-deep-learning (accessed on 13 June 2019).
- Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. 2016. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv, arXiv:1602.04938v3. [Google Scholar]
- Schelldorfer, Jürg, and Mario V. Wuthrich. 2019. Nesting Classical Actuarial Models into Neural Networks. Available online: https://ssrn.com/abstract=3320525 (accessed on 22 January 2019).
- Semenovich, Dimitri, Ian Heppell, and Yang Cai. 2010. Convex Models: A New Approach to Common Problems in Premium Rating. Sydney: The Institute of Actuaries of Australia. [Google Scholar]
- Smith, Leslie N. 2018. A disciplined approach to neural network hyper-parameters: Part 1—Learning rate, batch size, momentum, and weight decay. arXiv, arXiv:1803.09820v2. [Google Scholar]
- Srivastava, Nitish, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. The Journal of Machine Learning Research 15: 1929–58. [Google Scholar]
- Taylor, Greg, Gráinne McGuire, and James Sullivan. 2008. Individual claim loss reserving conditioned by case estimates. Annals of Actuarial Science 3: 215–56. [Google Scholar] [CrossRef]
- Vaughan, Joel, Agus Sudjianto, Erind Brahimi, Jie Chen, and Vijayan N. 2018. Nair. Explainable Neural Networks based on Additive Index Models. arXiv, arXiv:1806.01933v1. [Google Scholar]

{kind=link}
{kind=link}
| Origin Period | Feature 1 | … | Feature m | Claim Reported by Delay | Claim Paid Reported by Delay | Data Exists Flag by Delay 1 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x | c | p | w | |||||||||
| 1 | … | n | 1 | … | n | 1 | … | n | ||||
| 1 January 2015 | 1 | 0 | 0 | $2000 | 1 | 1 | ||||||
| 1 December 2016 | - | 0 | NaN | 0 | NaN | 1 | 0 | |||||
| 1 December 2015 | 0 | 1 | 0 | $3000 | 1 | 1 | ||||||
| Test | Sample Size | Seed | Chain Ladder SE Count | PPCI SE Paid | Model SE Count | Model SE Paid | Better Paid SE |
|---|---|---|---|---|---|---|---|
| 0 | 5000 | 1 | 1453.14 | 3436.19 | NaN | NaN | N |
| 1 | 5000 | 2 | 472.17 | 2447.26 | 256.78 | 2183.37 | Y |
| 2 | 5000 | 3 | 431.78 | 5638.29 | NaN | NaN | N |
| 3 | 5000 | 4 | 339.55 | 1652.14 | 224.21 | 3401.45 | N |
| 4 | 5000 | 5 | 1590.66 | 58,388.27 | NaN | NaN | N |
| 5 | 10,000 | 1 | 540.19 | 4070.24 | 823.89 | 5181.73 | N |
| 6 | 10,000 | 2 | 2533.18 | 51,956.42 | 389.81 | 44,884.23 | Y |
| 7 | 10,000 | 3 | 606.79 | 11,418.01 | 272.21 | 7511.17 | Y |
| 8 | 10,000 | 4 | 1810.21 | 209,956.66 | 976.48 | 202,351.99 | Y |
| 9 | 10,000 | 5 | 1057.81 | 52,508.37 | 270.61 | 42,912.06 | Y |
| 10 | 25,000 | 1 | 5575.31 | 35,060.89 | 2583.43 | 23,732.57 | Y |
| 11 | 25,000 | 2 | 4644.56 | 61,120.81 | 750.18 | 51,177.28 | Y |
| 12 | 25,000 | 3 | 1969.43 | 295,767.11 | NaN | NaN | N |
| 13 | 25,000 | 4 | 4054.21 | 309,086.25 | 1985.41 | 299,889.39 | Y |
| 14 | 25,000 | 5 | 1703.19 | 57,953.14 | 1362.94 | 67,186.30 | N |
| 15 | 50,000 | 1 | 25,487.11 | 133,176.94 | 2407.64 | 78,762.94 | Y |
| 16 | 50,000 | 2 | 6313.54 | 125,112.45 | 9515.98 | 116,294.24 | Y |
| 17 | 50,000 | 3 | 3744.60 | 196,970.08 | 6727.98 | 220,488.81 | N |
| 18 | 50,000 | 4 | 13,261.61 | 334,846.96 | 19,096.74 | 284,140.74 | Y |
| 19 | 50,000 | 5 | 4430.90 | 67,546.64 | 1606.70 | 57,256.59 | Y |
| 20 | 100,000 | 1 | 23,441.53 | 312,086.87 | 29,796.32 | 441,193.89 | N |
| 21 | 200,000 | 1 | 64,274.85 | 5,147,858.37 | 28,841.52 | 5,076,289.65 | Y |
| 250,000 with Bayes Opt | 151,959.56 | 1,260,099.15 | 201,002.33 | 961,150.56 | Y | ||
| Percentile | Model Paid | Actual Paid |
|---|---|---|
| 5% | 0.25 | 0.23 |
| 10.0% | 0.33 | 0.32 |
| 15.0% | 0.47 | 0.47 |
| 20.0% | 0.6 | 0.38 |
| 25.0% | 0.66 | 0.5 |
| 30.0% | 0.71 | 0.54 |
| 35.0% | 0.76 | 0.54 |
| 40.0% | 0.8 | 0.51 |
| 45.0% | 0.85 | 0.6 |
| 50.0% | 0.9 | 0.67 |
| 55.0% | 0.96 | 1.16 |
| 60.0% | 1.02 | 1.24 |
| 65.0% | 1.1 | 1.58 |
| 70.0% | 1.18 | 1.18 |
| 75.0% | 1.28 | 1.17 |
| 80.0% | 1.39 | 0.96 |
| 85.0% | 1.49 | 1.03 |
| 90.0% | 1.62 | 1.8 |
| 95.0% | 1.77 | 2.01 |
| 100.0% | 2.24 | 3.06 |
| Weight Decay (l2) | Paid w * | Dense Layer 1 | Dense Layer 2 | Dense Layer 3 |
|---|---|---|---|---|
| 0.0001 | 0.97 | 0.043 | 0.026 | 0.031 |
| 0.001 | 2.51 | 0.016 | 0.009 | 0.007 |
| 0.01 | 2.39 | 8.26 × 10−5 | 1.57 × 10−5 | 2.71 × 10−4 |
| 0.1 | 0.64 | 0.004 | 2.36 × 10−5 | 4.02 × 10−5 |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
H. L. Poon, J. Penalising Unexplainability in Neural Networks for Predicting Payments per Claim Incurred. Risks 2019, 7, 95. https://doi.org/10.3390/risks7030095
H. L. Poon J. Penalising Unexplainability in Neural Networks for Predicting Payments per Claim Incurred. Risks. 2019; 7(3):95. https://doi.org/10.3390/risks7030095
Chicago/Turabian StyleH. L. Poon, Jacky. 2019. "Penalising Unexplainability in Neural Networks for Predicting Payments per Claim Incurred" Risks 7, no. 3: 95. https://doi.org/10.3390/risks7030095
APA StyleH. L. Poon, J. (2019). Penalising Unexplainability in Neural Networks for Predicting Payments per Claim Incurred. Risks, 7(3), 95. https://doi.org/10.3390/risks7030095