1. Introduction
The Growth-Optimal Portfolio (GOP) theory is influential in portfolio management
Kelly (
1956);
Latane (
1959);
Markowitz (
1959);
Thorp and Kassouf (
1967) along with modern portfolio theory
Markowitz (
1952). The GOP advocates to allocate investment capital at the (asymptotic) expected growth-optimal allocation so as to maximize the long-term expected compounded return of the portfolio. The attractive property of such portfolios includes optimal asymptotic growth, hence the name.
Despite its theoretical advantage, the growth-optimal allocation is also known to be generally too risky in practice
Maclean et al. (
2009);
Thorp and Kassouf (
1967);
Vince (
1990);
Zenios and Ziemba (
2006);
Zhu (
2007);
Vince et al. (
2013), and various methods have been suggested to reduce the risk exposure of expected growth-optimal allocations. One unsatisfactory aspect of these methods is that they are heuristic, and there is no theoretical justification on why and how to do it.
Recently, in
Vince and Zhu (
2015), Vince and Zhu observed that the GOP neglected two important practical considerations. First, the GOP optimizes the expected optimal growth assuming an infinite investment horizon. In reality, investors only invest in a finite time horizon. Second, in the GOP theory, the focus is on the expected growth only. Risk is ignored. In practice, of course, risk is a critical factor for any investment decision. Incorporating these two practical considerations in analyzing the bet size of the game of blackjack, Vince and Zhu showed in
Vince and Zhu (
2015) analytically and experimentally that the optimal bet size suggested by Kelly’s formula
Kelly (
1956), a predecessor of the GOP theory, needs to be adjusted downward considerably.
We consider our findings in terms of points within a return manifold, which we term a leverage space, the surface of expected geometric return in dimensions for N simultaneous events, at Q periods. Each of the N events is characterized by an axis in the -dimensional manifold and bound between zero, where nothing is risked, and one, where the risk is as small as possible so as to assure total loss with the manifestation of the worst case. Further, whenever there exists a cumulative outcome or feedback mechanism that can range positive or negative from one discrete point to another, we reside at some loci on the return surface within the leverage space manifold whether we acknowledge this or not, and pay the consequences or reap the benefits of such loci therein.
GOP, in effect, states that one should select those coordinates in the leverage space at the (asymptotic,
) peak. We note that Kelly’s formula
Kelly (
1956) refers to this asymptotic peak. Using the model in
Vince and Zhu (
2013) to represent expected geometric return as a function of
Q, we find that for a single position with a positive expectation, expected growth is always maximized at a fraction risked of 1.0 for
. As
Q increases, this expected growth-optimal fraction rapidly decreases toward its asymptotic value as specified by the Kelly criterion (the shape of the return surface within the leverage space manifold is a function of
Q), and thus, we generally use this asymptotic value for all situations as a proxy for the actual expected growth-optimal fraction in all cases except for small values for
Q. Given the unwieldy model for actual expected growth in
Vince and Zhu (
2013), we use as a proxy herein Kelly’s formula for the average expected growth per play assuming infinite play, express this as expected growth after
Q plays, and very accurately derive values for the curve over the domain
at any given, but not too small values for
Q in our analysis. The point becomes moot in the context discussed here as the important loci discussed in this paper do not appear until
Q reaches satisfactory values to satisfy this requirement. Thus, the Kelly criterion solution is always less aggressive than what actually is the expected growth-optimal fraction for any finite horizon.
Further, as demonstrated in
Vince and Zhu (
2015), we scale the Kelly criterion answer using the worst case, so as to comport to being an actual fraction to risk so that multiple, simultaneous propositions can be considered properly (relative to each other), short sales considered, etc., such that we are always using a fraction and thus bounding the axes of the leverage space manifold at zero and one for all possible simultaneous propositions. This is discussed further at the beginning of
Section 3.
The results in
Vince and Zhu (
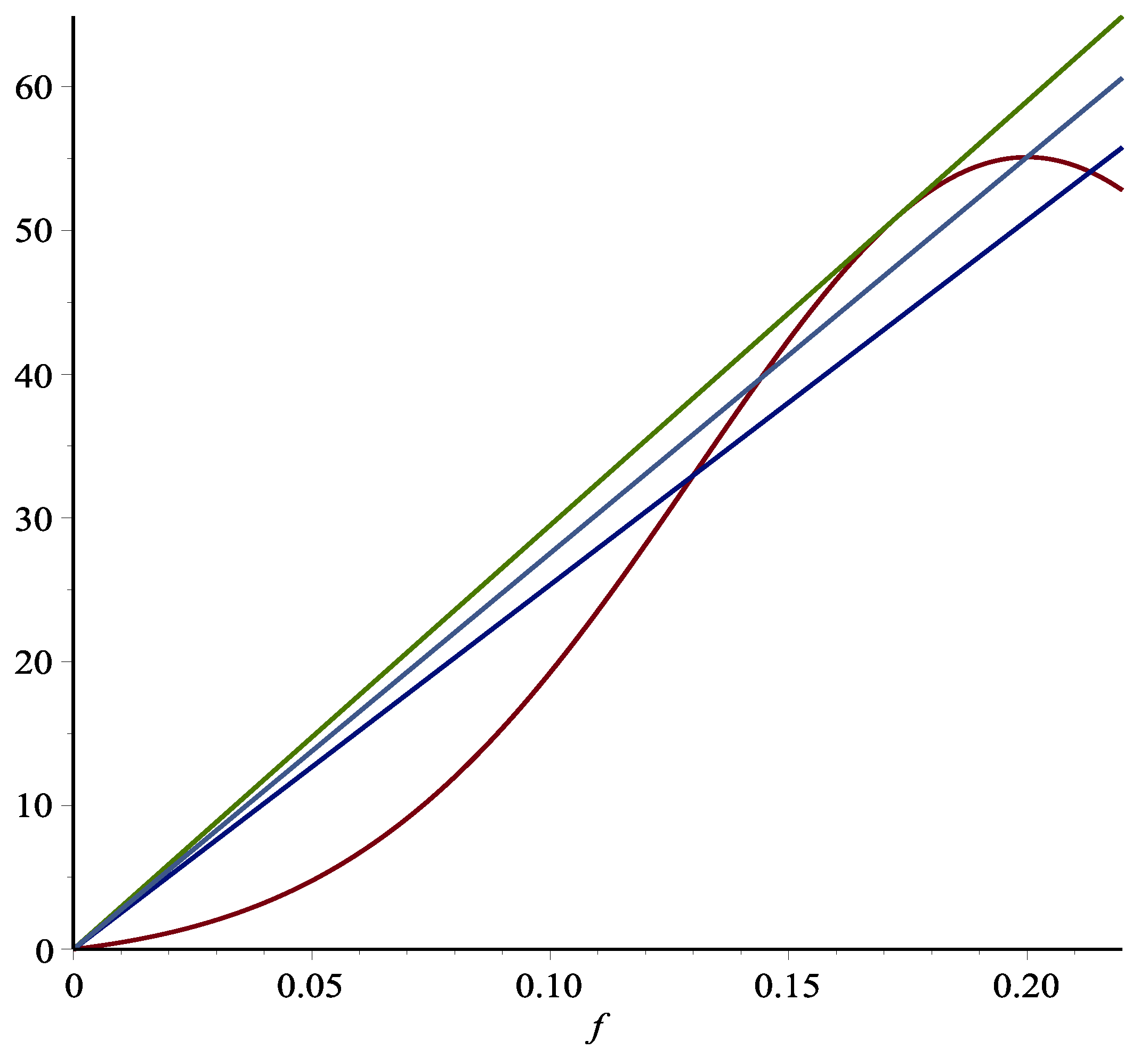
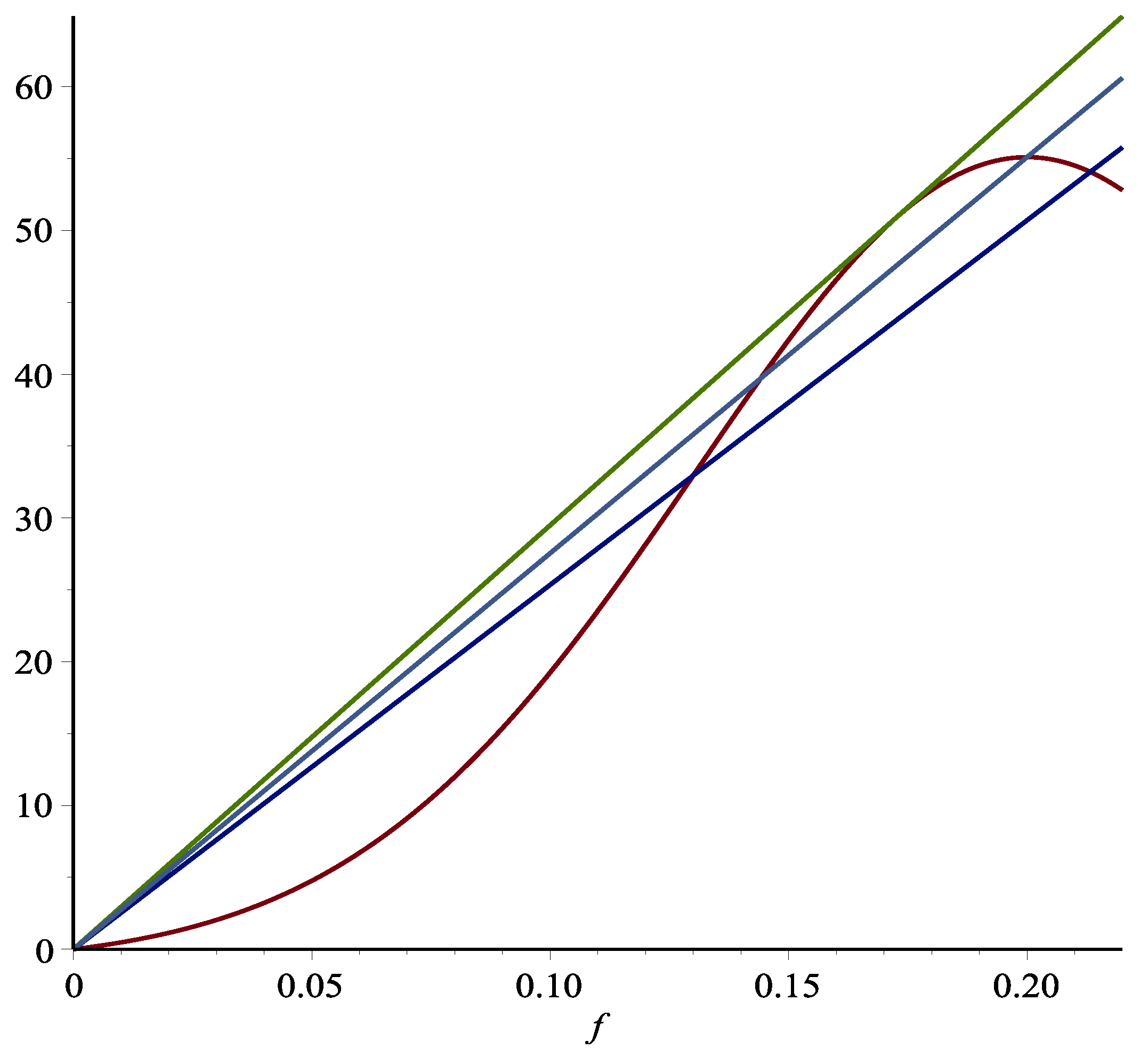
2015) were based on two simple observations: the graph of the total return function for playing blackjack hands a finite number of times is a bell-shaped curve, and the risk, as measured by the maximum drawdown, is approximately proportional to the bet size. As a result, the slope of the line connecting
and any point on the return curve is proportional to the return/risk ratio where the risk is measured by the maximum drawdown. Thus, the optimal bet size maximizing the return/risk ratio is the line emanating from
and tangent to the return curve depicted in
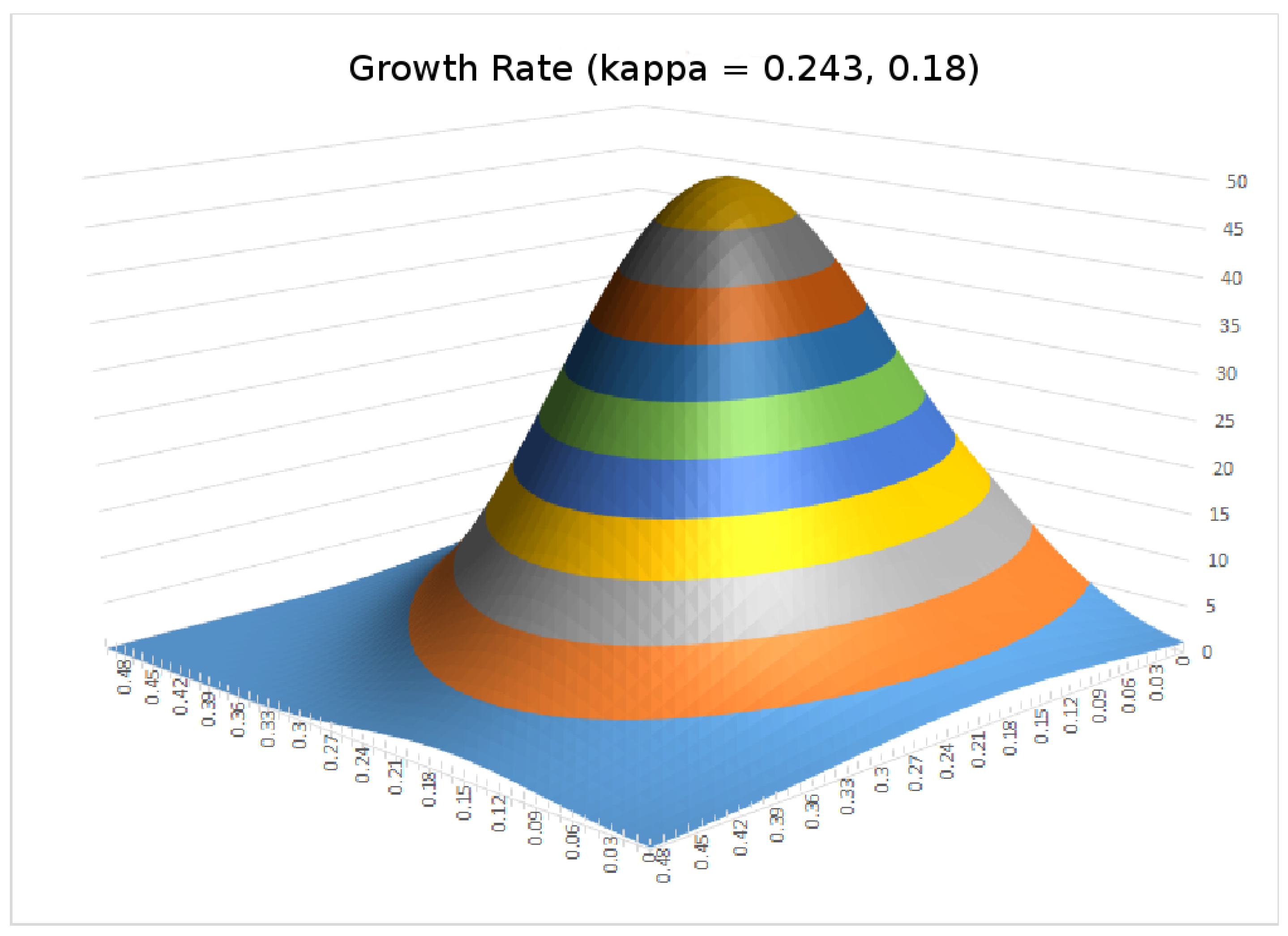
Figure 1.
We can see that the corresponding bet size for this point is somewhat more conservative than the Kelly-optimal bet size corresponding to the peak of the return curve. Moreover, also noteworthy in
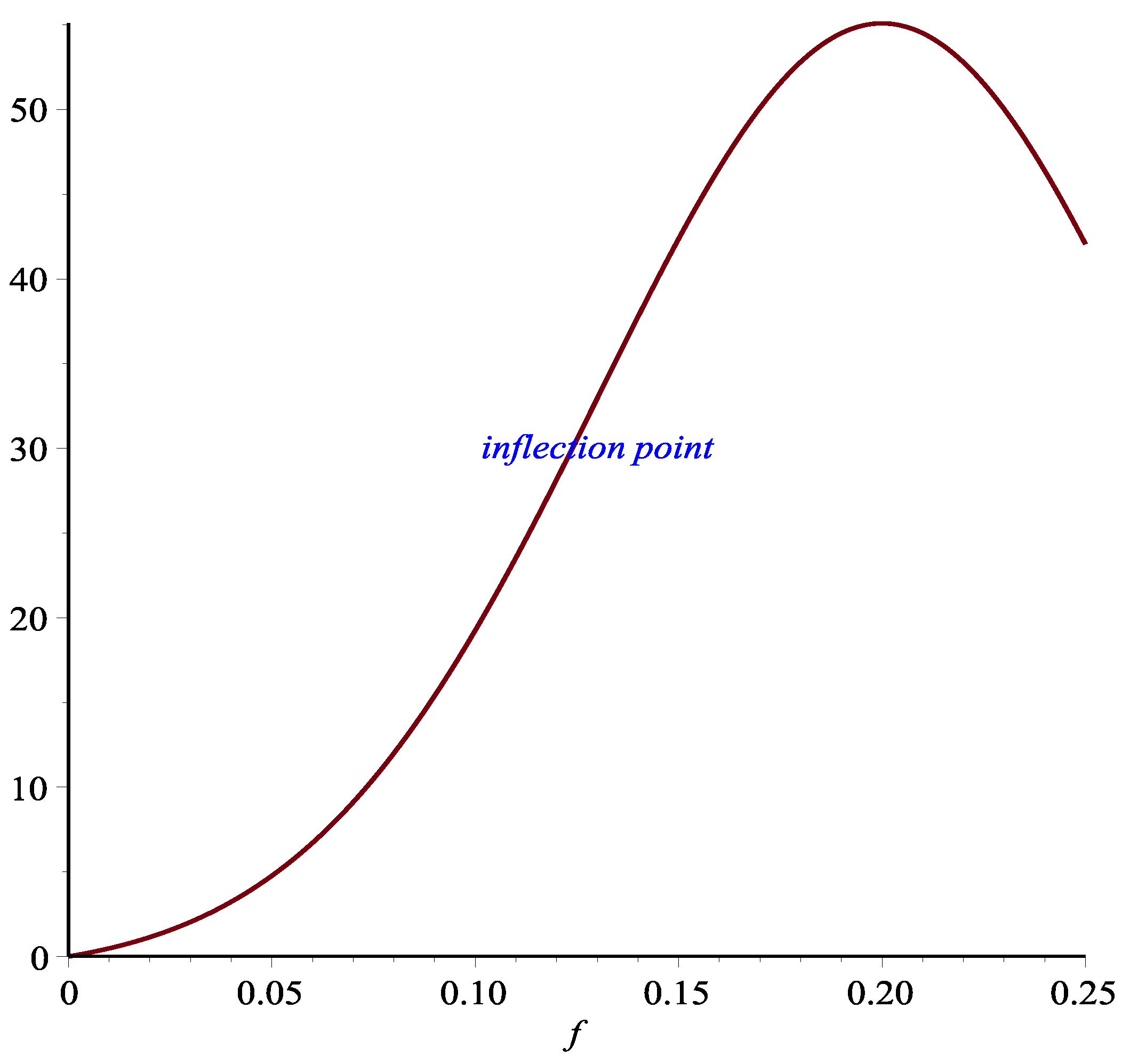
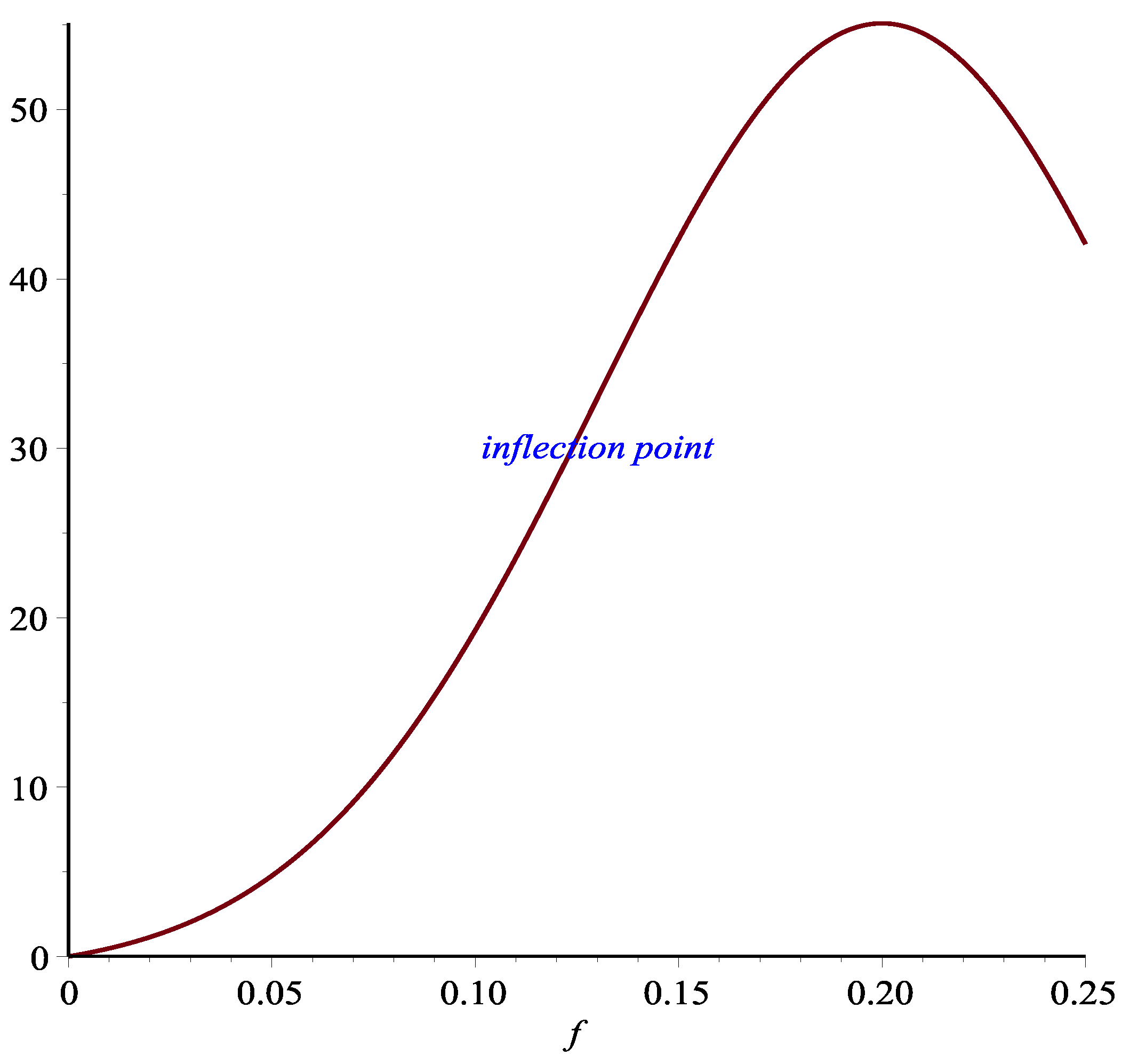
Figure 1 is the inflection point corresponding to the lower line. This inflection point can be seen more clearly in
Figure 2.
The inflection point is significant in that it is the boundary of increasing or decreasing marginal return when the bet size increases. If one were to pursue increasing the return/risk ratio, then it does not make sense to stop before reaching the inflection point. However, increasing the bet size beyond the inflection point arguably is a matter of choice. Because between the inflection point and the return/risk maximum point, while increasing the bet size still improves the return/risk ratio, the marginal benefit of doing so diminishes. Thus, the interval between the inflection point and the return/risk maximizing point is a reasonable region for players with different risk aversion to choose their appropriate strategy. Indeed, these observations are corroborated by Monte Carlo simulations in
Vince and Zhu (
2015).
Both of these aforementioned points are a function of horizon,
Q, and migrate towards the asymptotic peak as
.
1Although
Vince and Zhu (
2015) focuses on bet size for playing blackjack, the idea and methods also apply to general capital allocation for investment problems involving multiple risky assets or investment strategies. In fact, inflection points have been discussed in
Vince and Zhu (
2013) in a more general context. The main goal of this paper is to provide a practical guide on how to implement the idea in
Vince and Zhu (
2013;
2015) for investment problems involving multiple investment instruments. When there are multiple assets involved, the path from the optimal GOP allocation to the completely riskless position of all cash (bonds) is not unique. In fact, there are infinitely many possible paths from which to choose. Although given a risk measure, one can argue it is reasonable to follow a path that on every level of the return manifold, the path should travel through the point that minimizes the risk measure. In reality, finding such a path may turn out to be very costly. Therefore, other alternative choices of paths should also be allowed. The risk measure when involving multiple assets and investment strategies is also more complicated. For each investment strategy, the same argument in
Vince and Zhu (
2015) still applies, and the size of the funds allocated to it is approximately proportional to the drawdown. However, the proportional constants for different investment strategies may well be different. Moreover, the total drawdown will also depend on how the drawdowns for different investment strategies are correlated, adding more technical issues into the equation.
Once a return/risk path is determined, the return function along this path becomes a one-variable function of the parameter that defines the path. One may attempt to use the method in
Vince and Zhu (
2015) to determine the trade-off between return and risk. However, the idea in
Vince and Zhu (
2015) as alluded to in the previous paragraph only works when the parameter is proportional to the risk. This only happens for a few return/risk paths. In practical capital allocation problems, the comparison of different return/risk paths is often necessary. We show that the inflection points on different return/risk paths are all on one manifold determined by Sylvester’s criterion of negative definiteness of a matrix involving the derivatives of the return functions and provides a reasonable approximation. Similarly, we also develop equations characterizing the manifolds of all return-/risk-optimal points.
The rest of the paper is arranged as follows: we first illustrate our results using a simple concrete example in the next section. Then, we discuss the general model and growth-optimal allocation in
Section 3.
Section 4 discusses the return/risk paths and special cases in which the methods in
Vince and Zhu (
2015) directly apply. In
Section 5 and
Section 6, we develop methods of characterizing the manifolds of inflection points and return-/risk-optimal points, respectively. We also discuss approximations where appropriate. We then discuss application examples in
Section 7. We conclude in
Section 8 and discuss avenues for further research regarding this material.
2. An Example
Let us consider playing a game where two coins are tossed independently at the same time. Coin 1 is a 0.50/0.50 coin that pays 2:1, and Coin 2 is a 0.60/0.40 coin that pays 1:1 (to be non-symmetrical, as the simplest case). We play
times. The joint probability distribution is summarized in
Table 1.
For
being the amounts risked on Coin 1 and Coin 2, respectively,
, then the expected return function is:
where:
is the expected log return function.
Figure 3 plots
r as a function of
and
.
Note that each of the four summands in the definition of
is a composition of the strictly concave log function and a nontrivial affine function and, therefore, strictly concave. Thus,
itself is also a strictly concave function on its domain in the leverage space
. We know that strictly concave functions have at most one maximum point. On the other hand,
approaches
as
approaches the upper and right boundaries of the leverage space
. Since both games have a positive expected return, neither the left boundary of the leverage space where
, nor the lower boundary where
will contain the maximum for the log return function
. Thus,
must attain a unique maximum in the interior of the leverage space. As the composition of the monotonic increasing function
and the log return functions
,
and
share the same maxima, it follows that
also has a unique maximum in the interior of the leverage space, which is the Kelly-optimal bet sizes for these two games played simultaneously. We can determine this Kelly-optimal point by applying the first order necessary condition:
and represent it by the vector
. As discussed above,
is the unique solution to (
1).
As pointed out in
Maier-Paape and Zhu (
2018), practically important risk measures related to expected (log) drawdowns can be linearly approximated by position size. Thus, in what follows, we will use position size as a proxy for the risk, an approach already used in
Vince and Zhu (
2015). For a single game as discussed in
Vince and Zhu (
2015), the magnitude of this proportional constant is not important, as long as the expected (log) drawdown is approximately proportional to the bet size. Now that we are considering two different games together, the proportional constants for the two games are in general different. When trying to approximate the aggregated drawdown, it is now important to estimate the two different proportional constants. Simulating these two games for 2000 rounds of playing 50 simultaneous tosses (
) each, then calculating the mean, demonstrates that for the two individual games, the expected drawdowns are proportional to
and
, where
and
, respectively.
Another complication in discussing the approximation of the aggregated drawdowns in this situation is that we need to consider the correlation of the two drawdowns. When the two drawdowns occur independently of each other (referring to the overlap of their duration in time), the aggregated drawdown is roughly the largest between the two linear approximations, i.e., . The other extreme is that the two drawdowns are completely dependent so that the aggregated drawdown is proportional to . In general, there are some correlations between the drawdowns of the two games, and we get something in between.
For each level t of the return r, a risk-averse investor may select, on the level curve of , the point that minimizes the risk as measured by the drawdown. As t progresses from zero to the maximum of the return, will trace out a curve in the leverage space from to . Each different choice of the approximation of the drawdown corresponds to such a curve. If we draw all such curves, they then aggregately provide us a region in leverage space that represents allocations achieving minimum risk under the given return. Since it is impossible to trace infinitely many such curves, we focus on the two extreme cases alluded to above to derive the boundaries of this region.
Consider the completely dependent case first. Our problem becomes, for each
,
Observing that changing
to
does not change the solution, we see that Problem (
2) is a convex optimization problem and, therefore, has a unique solution determined by the Lagrange multiplier rule:
Taking the ratio of the two components and using the computation of
in (
1), we can see that the curve
is determined by the equation:
starting from
until it intercepts one of the coordinate axes. Afterwards, it follows the intercepted coordinate axis to
. We will name this curve Path 1 for reference in the future.
The other extreme is that the two drawdowns always happen in non-overlapping time intervals. Then, we need to solve the convex constrained minimization problem:
In this optimality condition,
, corresponding to
, and leads to
. Similarly,
corresponds to
and leads to
. It follows that before either
reaches
or
reaches
, we should always have
, which corresponds to
. Thus, the path
follows the line:
until either
reaches
or
reaches
. After that, it follows the straight line to
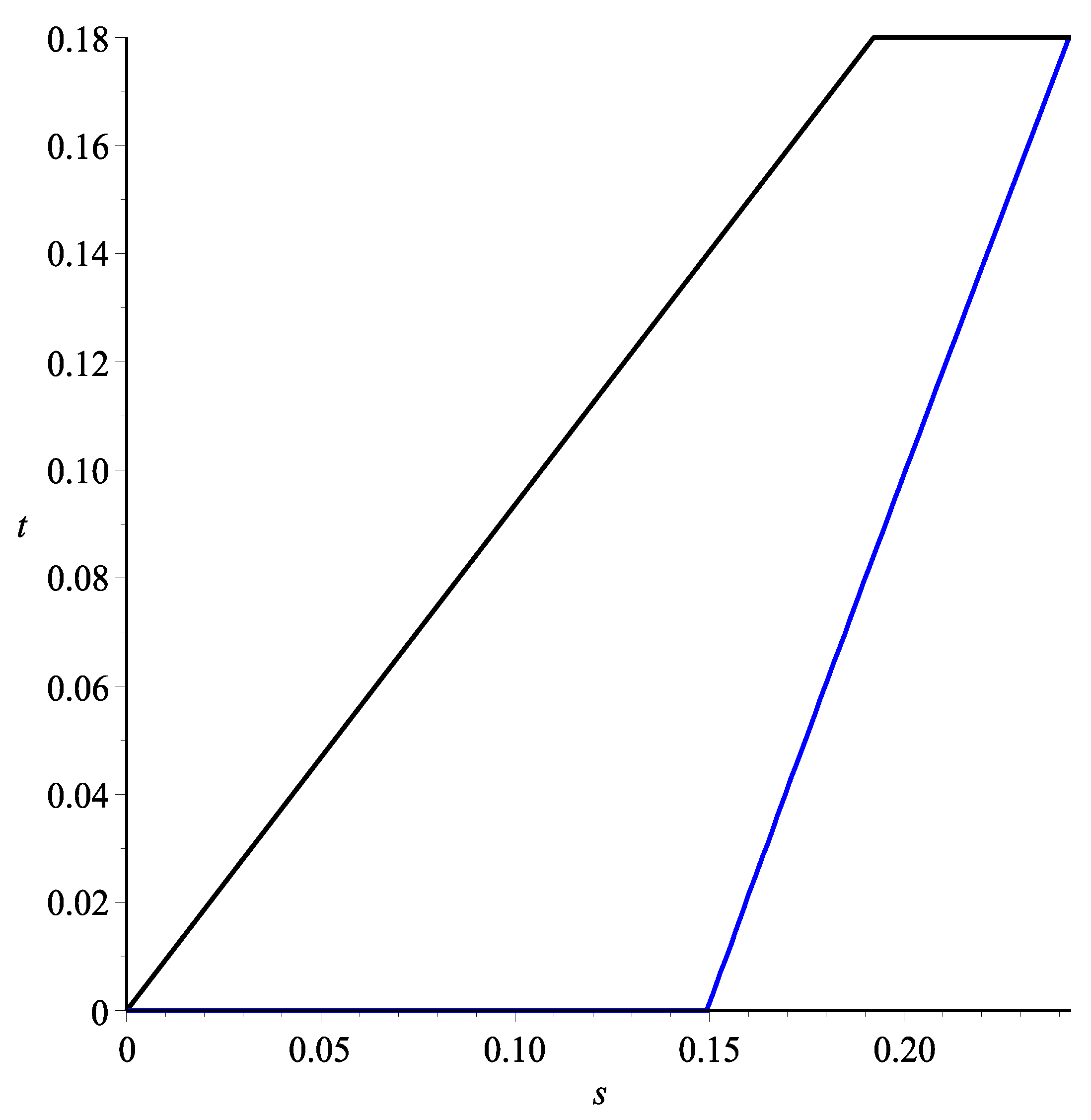
. We will name this curve Path 2. For
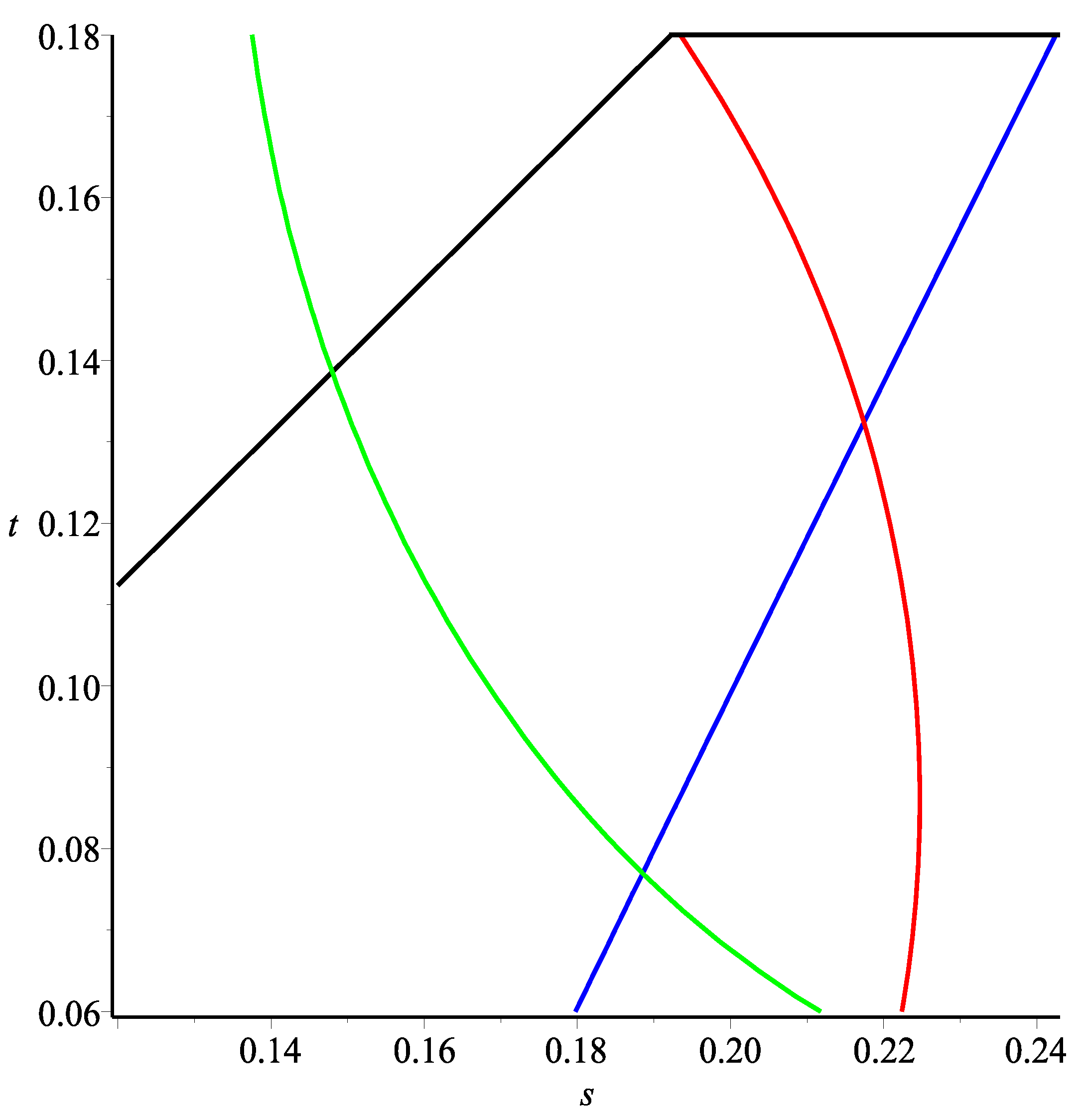
and
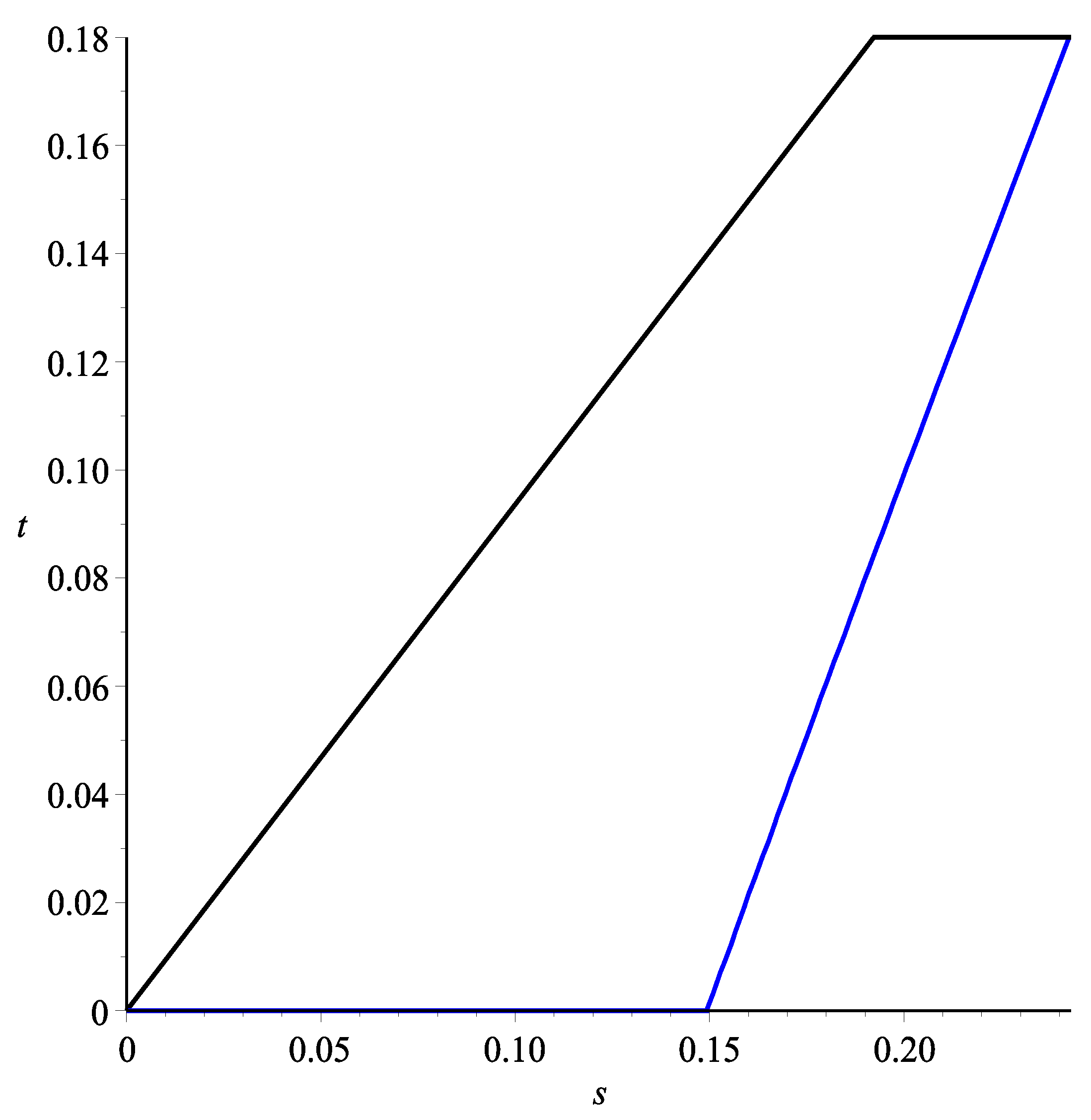
, the two curves discussed above are illustrated in
Figure 4, where the curves corresponding to (
3) and (
5) are colored in blue and black, respectively. In general, the drawdown will fall in between these two extreme cases.
Next, we consider the return/risk optimizing point
and the inflection point
on these paths. As we will see in
Section 5:
determines the curve at which the inflection of the graph of
r occurs. To determine
for the completely dependent case, we need to maximize
. The optimality condition is:
which is equivalent to:
Using
to dot product both sides and canceling
yield:
It turns out that this is true in general (the proof uses a similar calculation involving subdifferentials for convex functions and will be given in
Section 6). Thus, the
point corresponding to any curve will have to be on the curve defined by Equation (
7). In particular, we can find the
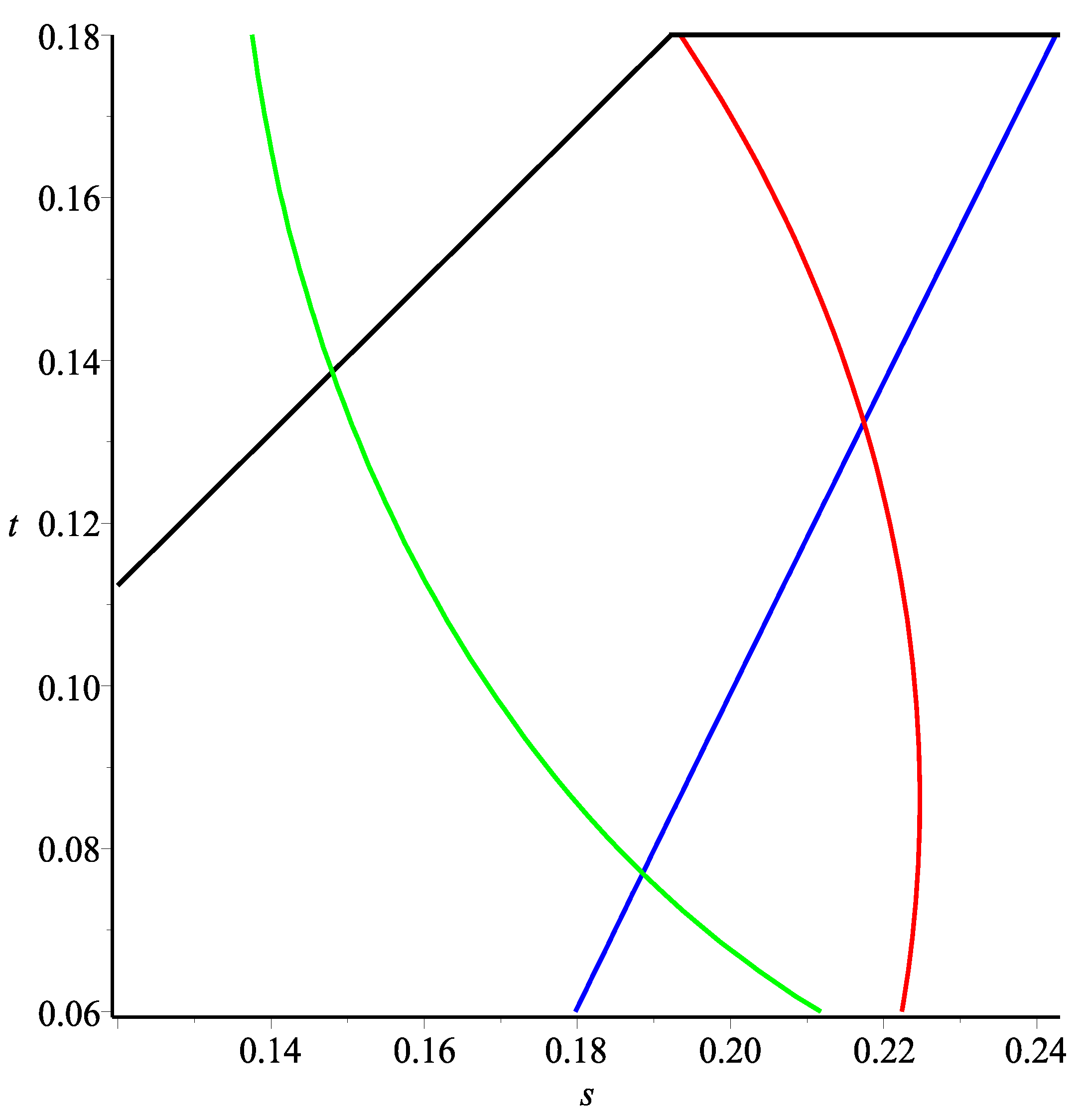
points corresponding to the independent and completely dependent cases by looking at the interception of the corresponding curves as shown in
Figure 5, in which the curves corresponding to Equations (
6) and (
7) are represented in red and green, respectively, and the blue and black curves again represent (
3) and (
5), respectively. The corresponding significant points are summarized in
Table 2 below.
3. The General Model
Consider investing in
M investment systems represented by a random vector
with
N different outcomes
where
. The random variable
represents the absolute gain (loss) of the
investment asset. We consider investing in those investment systems for
Q holding periods and suppose that
. We wish to determine how best to allocate funds into those investment systems. We re-scale so that the allocation can be represented in leverage space
Vince (
2009). Let
. Assume there is no arbitrage opportunities so that
for all
. Define the scaled random vector
and the scaled outcome
. Then,
. Now, each allocation can be represented by a vector
where
represents the fraction of the total number of shares one can invest in the
investment vehicle such that the worst loss
will result in the loss of all the investment capital. We further assume that the
M investment assets are independent enough so that:
We note that condition (
8) amounts to saying that there does not exist a nontrivial portfolio
x such that
for all
. Since in this paper, we consider the simplified case where the riskless bond has an interest of zero, such a portfolio, in fact, replicates a riskless bond. In other words, we are considering a market in which there is no nontrivial bond replicating portfolio as defined in
Maier-Paape and Zhu (
2018).
Given the above setting, the expected gain per period is:
Then, the total return can be approximated by
. We have seen in
Vince and Zhu (
2015) that, for reasonably large
Q, this approximation is quite accurate for the case of
. Thus, we will use this approximation in the analysis below. We note that using the log return function:
we have the representation:
Since the exponential function is monotone increasing and the log return function is strictly concave given Condition (
8) (see (
Maier-Paape and Zhu 2018, Proposition 6)),
attains a unique maximum, which can be determined by solving the equation:
or equivalently:
We denote the solution and note that this is the asymptotic growth-optimal allocation and therefore is independent of Q.
4. Return/Risk Paths
As illustrated in the example discussed in
Section 2, we know that the allocation
is usually too risky. In practice, one needs to reduce the risk and take a middle ground between
and
. It is clear from the example in
Section 2 that there are many possible paths connecting these two possible allocations providing various trade-offs between risk and return.
Definition 1. Let X be the vector of random variables introduced in Section 3 representing the gains of a group of risky assets. A mapping is called a return/risk path with respect to X, if it has the following properties - 1.
f has piecewise continuous second order derivatives.
- 2.
and .
- 3.
is an increasing function on .
- 4.
There is a risk measure m on the leverage space such that is an increasing function on .
- 5.
for all where exists.
The meaning of Properties 4 and 5 is that the return/risk path must move toward the direction of increasing the reward with the maximum rate while increasing the risk. It is easy to see that both Path 1 and Path 2 in the example in
Section 2 are return/risk paths. Along such paths, we can show that an inflection point always exits as long as
Q is large enough.
Theorem 1. Let be a return/risk path. Then, when Q is sufficiently large, the function has an inflection point on , which is determined by the equation: Proof. Direct computation shows that:
and:
where:
Since there are only finitely many points on
where
does not exist, we denote
as the last such point before
b. Since
is unique,
. Thus, there are infinitely many
where
. Thus, we can choose
such that
. Observing that
and
is negative definite, we have
. On the other hand, for
Q sufficiently large:
Thus,
has a solution on
. □
Since c can be chosen arbitrarily close to b, when , the inflection point related to Q approaches .
On the other hand, the relationship between the risk measure and the parameters in these two paths is different. For Path 2, the risk measure is piecewise linearly related to the parameter
t. Thus, we can use
t as a proxy for the risk and using the method in
Vince and Zhu (
2015) for one risky asset to determine
t values corresponding to the inflection point and the return/risk maximum point. However, this is not the case for Path 1 in which the risk
as a nonlinear function of
t is not proportional to
t. Thus, it is not always possible to use the return/risk path to convert a problem involving multiple strategies into one with only one parameter and use the method discussed in
Vince and Zhu (
2015). In the following two sections, we seek more generic ways of finding inflection points and return/risk maximizing points.
7. Applications
We now turn to concrete examples to illustrate how to apply the theory discussed in the previous sections.
Example 1. First, we recall the example of betting two simultaneous hands of blackjack in Vince and Zhu (2015). In this example, although there are two players involved, their strategy is the same. Thus, by symmetry, we can reason that the two players should use the same bet size. As a result, the problem is reduced such that there is only one bet size to calculate, and it can be solved using the methods in Vince and Zhu (2015). However, in general, such a reduction is most of the time impossible.
Example 2. A small, private equity firm is considering further funding for two very separate companies over the course of 72 months (six years) into the future. They wish to maximize their marginal increase in return with respect to the marginal increase in risk over this period, investing simultaneously in both companies.
Their study of these companies reveals that for each million provided in funding, Company A will show a monthly profit of $15,300 with a probability of 0.4 or a loss of $5000 with a probability of 0.6.
In considering Company B, there is a 0.8 probability of a $5000 monthly profit and a 0.2 probability of a $9200 monthly loss.
Assuming the returns on the two companies are statistically independent leads to the joint probabilities represented in
Table 3.
However, further analysis of the past, given that the month-by-month performance of the two companies is in part contingent on business conditions, amends the probabilities to show greater interdependency, and our private equity firm deems the probabilities associated with these outcomes, when taken together, to be more accurately as in
Table 4.
Thus, the log return function and the cumulative return function in this case are:
and:
respectively.
Numerically solving equation:
we find the peak of the (asymptotic) expected growth-optimal allocations to be
for Company A and Company B, respectively, with an average growth per month of
. Next, we consider the risk-adjusted return. In this case, since we only invest in a relatively short 72-month time-frame, it is reasonable to assume the risk related to the two companies is proportional to the largest monthly loss of −5000 and −9200, respectively. In the leverage space, this is to say the risks of Companies A and B are proportional to
and
, respectively. Moreover, the probability of such losses occurring simultaneously is relatively high at
. Therefore, we assume that the aggregated risk is proportional to their sum
. We can see that the path that corresponds to the least risk for each level set is given by the equation:
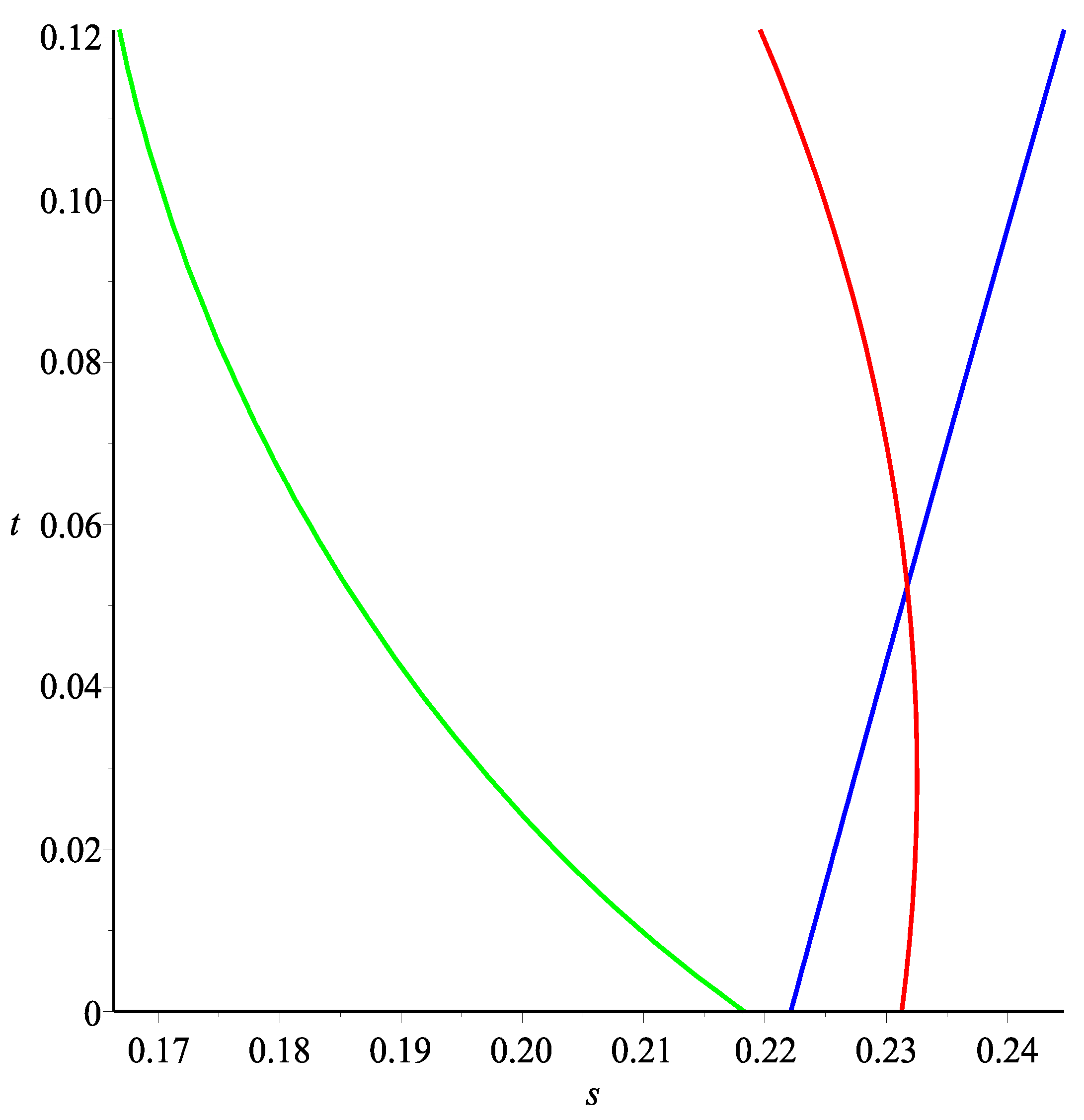
This path is depicted in
Figure 6, which follows the horizontal axis and then the blue line. Depicted in
Figure 6 as well are the curves corresponding to the inflection points in green and the return/risk maximizing points in red, calculated using the methods in
Section 5 and
Section 6. This gives us an estimate of
and
.
8. Conclusions and Further Research
Theoretical analysis, Monte Carlo simulation, and analysis of real-world examples showed that by the practical consideration of investment in a finite horizon and adjusting for risk, the leverage on different risky investment strategies suggested by the classical growth-optimal portfolio theory needs to be adjusted down considerably. We show that the inflection point and return/risk maximizing point discussed in
Vince and Zhu (
2015) are reasonable loci in leverage space in cases of capital allocation to risky assets or investment strategies. However, when multiple strategies are involved, reducing risk exposure from the growth optimal allocation,
, there exists infinitely many choices of paths. Analyzing the problem path by path is difficult. We established equations for determining the manifolds of inflection points and the return/risk maximizing points. These equations can be solved numerically to determine a region for reasonable choices of leverage. Examples were presented to show how to apply these methods in practice.
As usual, our research here leads to additional questions of practical importance. For example, portfolio insurance allocates a certain percentage to the underlying asset or portfolio based on the delta of a hypothetical option on the underlying asset or portfolio. Thus, portfolio insurance is a practice where one traverses along the return curve between its bounds as a function of the underlying price relative to its hypothetical option. The curve is identical in shape to the return curves discussed here, as reinvestment is constantly occurring (and thus, delta and f are interchangeable in this context), yet, the practitioners, in order to mimic the hypothetical option, are not capitalizing on any of the important growth-regulation points mentioned in this paper.
Similarly, inverse Exchange Traded Funds (ETFs) and leveraged ETFs (cases of constant reinvestment) have a delta embedded within them as:
This delta too, a number between zero and some number whose absolute value can be greater than one, is followed so as to track the promoted criterion of the ETF, e.g., “triple long ETF”. Yet, as with portfolio insurance, the implementors, in keeping with the promoted criterion of the ETF, are not able to capitalize on the important growth-regulating points (perhaps to be used as bounds on the delta). Further research into this area is clearly warranted.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}