3.2. Discussion
Every computation was made within the Windows environment on an Intel i7 processor. The computational time spent by the Hugin Expert software in developing each OOBN in the paper is equal on average to six minutes and includes maximizing the data likelihood with the Chow–Liu procedure and the NPC algorithm to limit inconsistencies among the set of conditional independence and dependence statements and estimating the conditional probability tables from the data with the EM algorithm. However evaluating the efficiency of the procedure as well as discussing the computational complexity of the OOBN go beyond the scopes of the paper. The interested reader can refer to more specialized texts in literature, such as:
Liu et al. (
2016) and
Galia (
2004).
Moving to the discussion,
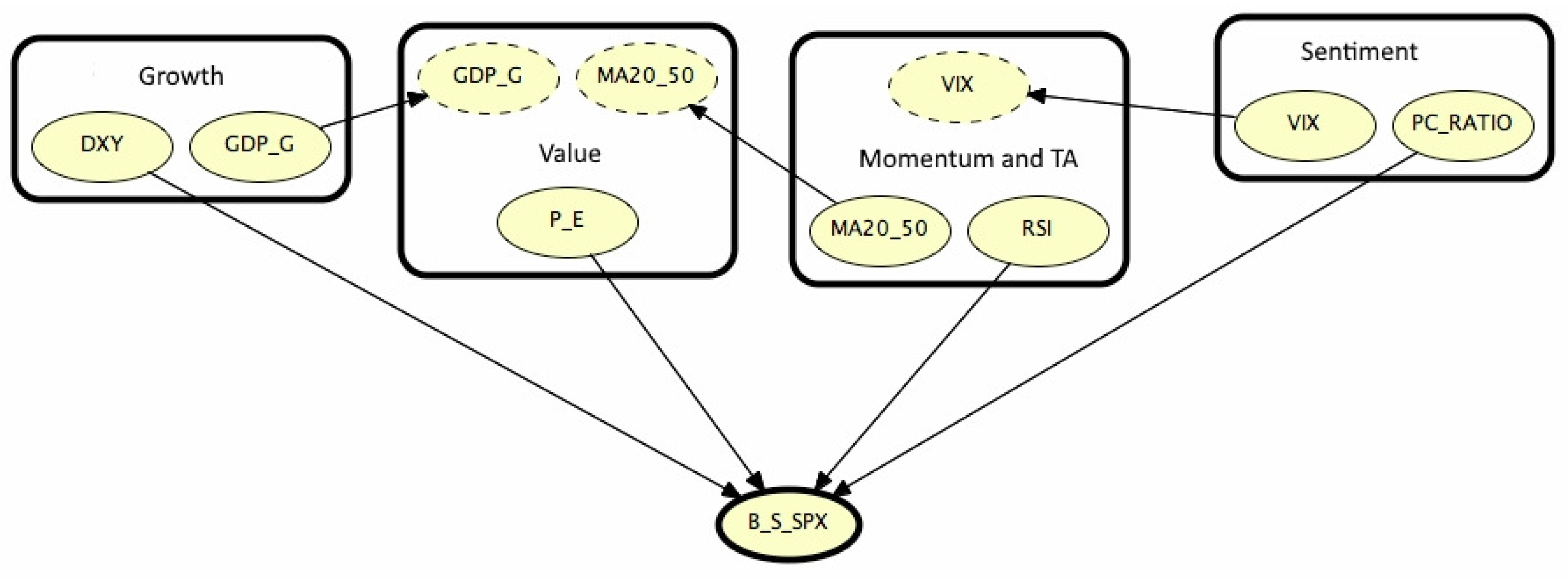
Figure 4 visualizes the results for the first time segment, illustrating its meaning and relevance: comments on the OOBN refer to
, while remarks on the trading signal refer to
. Similar considerations apply for other examined periods so that the conclusion we draw now can be extended to them in a straightforward manner.
From
Figure 4, we may see as
is conditioned by four instance nodes belonging to the classes indicated in
Section 2; in detail, the output nodes are: DXY (Growth), P
E (Value), RSI (Momentum and TA) and PC
Ratio (Sentiment). Besides Growth and Value classes communicate via the node
that is a parent node within the Value class; MA20
50 is the bridge between Value and Momentum/TA, which in turn is connected to the Sentiment group by the VIX.
From this representation, one can appreciate the simplicity of the final hierarchy that hides the intricacy of ties existing among the variables:
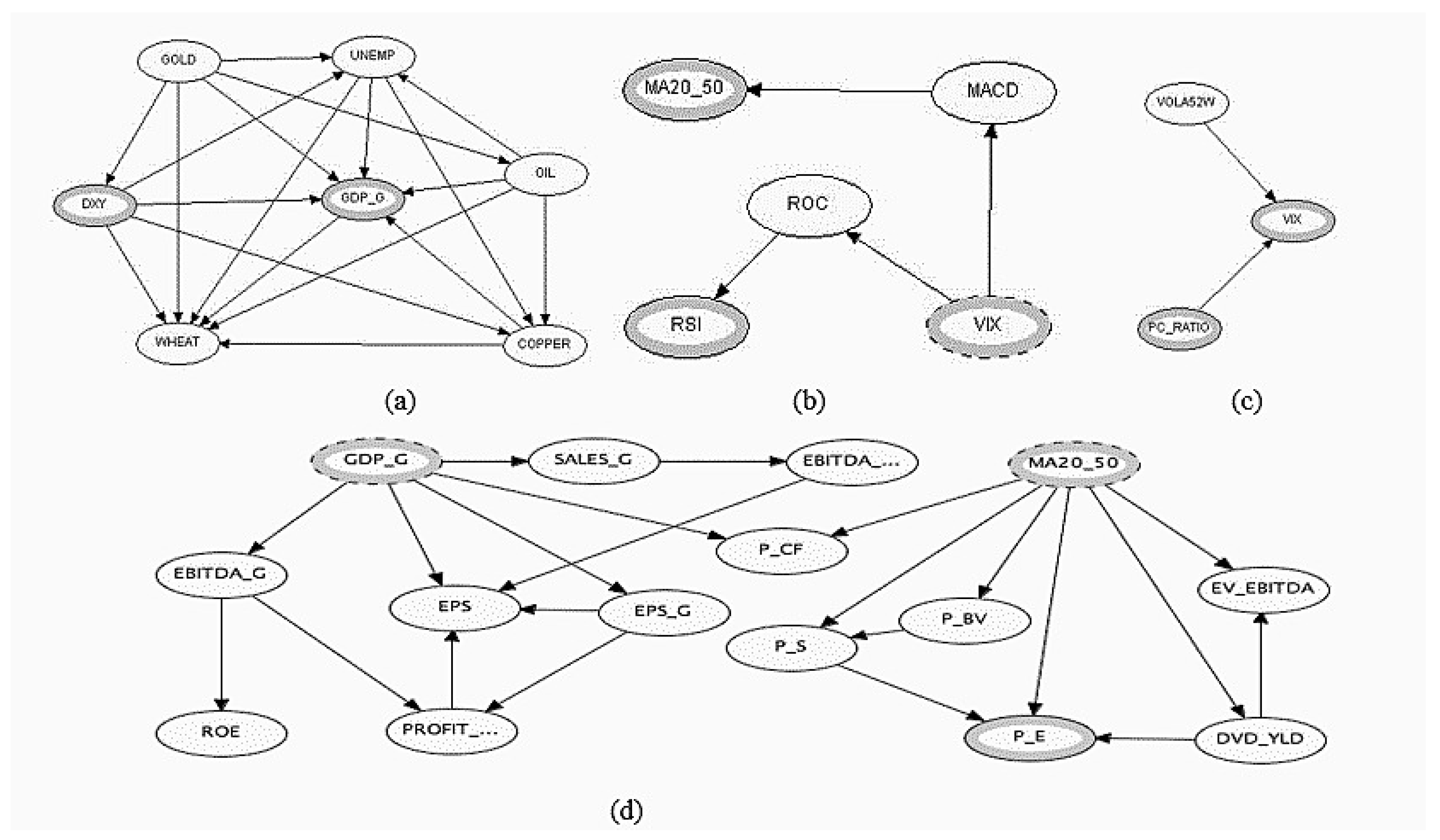
Figure 5 unveils the structure of these complex relationships for each object.
From
Figure 5, we observe that there is a BN inside each class of the OOBN presented in
Figure 4. Analyzing the ties inside of those BNs, it is possible to get additional insights about the final aspect of the OOBN. To motivate this assertion, we discuss the case of the BN inside the Growth class: clearly similar considerations can be extended to the other classes. More in detail, the behavior of GOLD directly affects all the nodes in the Growth class (
Figure 5a), while the opposite happens to WHEAT that is directly conditioned by any node inside the class. Other
big influencers are DXY and OIL, directly insisting on four over six nodes of the class; among the greatest
followers, on the other hand, we find COPPER and
on which insist five on six nodes. The fact that DXY is an instance node in the OOBN in
Figure 4 is probably due to the sensitivity in changes of the other nodes in the class, as shown in
Figure 6 with the aid of tornado plots comparing the relative importance of the class nodes. In detail, we simulate the sensitivity of each variable to a
change in the values of the remaining ones, putting them in order from the highest to the lowest response. To make an example, looking at
Figure 6a, we may observe the response of
with respect to
fluctuations of the other variables, appearing on the left–hand side of the plot: the sensitivity is at the highest level with DXY; nevertheless, it is maintained at high level also with respect to changes in the variables UNEMP, OIL, GOLD and COPPER, while it is notably lower with WHEAT. Similar considerations can be applied to the other tornado plots.
Moreover, in the light of the results in
Figure 5 and
Figure 6, the driving role of DXY with respect to the S&P 500 becomes more understandable.
Overall, disclosed information is multipurpose. First, it aids at revealing the hierarchy of ties in the market in a very simplified way: the main point is that, from the set of dependency among 26 indicators, we extract only four output nodes driving the index. This has notable implications when deriving the CPT for the S&P 500, as it is necessary to address instead of probabilities for each state.
Furthermore, with respect to the remarks done for the Growth class, we have also highlighted the existence of a richest network of relations behind those drivers. Second, we are going to show that this information can be managed to operate buy/sell/neutral actions on the S&P 500, and hence to simulate the impact on the index of changes in its drivers.
Table 9 examines the role of outputs on the S&P 500 in the four regimes and adds some clues to understand the overall direction of the index, as explained in previous rows. Here, the dependency structure for the S&P 500 index (
) is built under the rationale that the drivers should move either towards the same direction or not, thus suggesting an overall direction of the index, coded by numbers: In-trend (1), Reversal (2) or Sideward (0). In more detail, In-trend is connected to a bullish stage, with increasing price levels from a week to another; the opposite happens in the presence of Reversal, while Sideward is generally associated with uncertainty in the market, with prices moving in a lateral fashion, i.e., sometimes up and sometimes down, without any defined trend.
The overall impact of the drivers varies in time. During the first period, three output nodes on four agree in suggesting an in-trend position (1). Moving from the first to the second period, we have again three indicators over four aligned towards in-trend, but the final decision is for a Reversal (2), this, in our opinion, testifying the major influence of the PCRatio over the remaining indexes. The same occurs in the fourth regime. The situation in the third regime is different from other ones, as we have two drivers suggesting to stay in-trend and two indicating the opposite. In this perfect balancing situation, the final decision (1) is kept according to the suggestions of Value and Sentiment indicators. These remarks therefore suggest the prominent role played by Sentiment indicators.
To support these conclusions, we examined the performance of a trading system inspired by the results discussed in
Table 9, through the trail described in
Section 3.1. Results are reported in
Table 10.
The results in
Table 10 highlight a very good performance of the trading system based on the OOBNs: with the exception of
, in fact, the %CDC is sensitively over 60%, with peaks over 80% in the case of
. Indeed, the performance of all the indicators are aligned to %CDC and confirm the satisfactory behavior of the trading system. A possible explanation for the results in the second testing period can be probably retrieved in observing that
includes weeks where the 2008 financial crisis was at its very blooming stage. The Average Volatilty (AV) values seem supporting this conclusion.
Furthermore, we provided in
Table 11 the comparison of the performance among the Buy and Hold (B&H), the näive and (Näive) and the OOBN-based (OOBN-b) strategies. B&H is a passive investment strategy for which the investor buys stocks and holds them for the whole period regardless of fluctuations in the market with no concern for short-term price movements and technical indicators. The Näive is a strategy assuming to buy in uptrend periods and to sell during downtrends. The performance was computed as:
Here,
is the log-return
in the B&H case, while we have
as defined in (11) for the OOBN-b; finally, when dealing with the näive strategy, it is:
during uptrend periods and
when the time series goes downtrend. In practice, (
13) evaluates the convenience of investing each unit capital at the rate
for each week of the testing period.
We can note that the performance of the OOBN-b strategy is always higher than both the B&H and the Näive. This is true also during the downtrend periods and when B&H and Näive, respectively, poorly performed. This evidence then supports the idea that the OOBN can be successfully combined with trading systems.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}