1. Introduction
The mathematical formulation of risks is based purely on probability. Let Y be a random variable on the probability space where represents the space of all possible outcomes, is the -algebra, and P is the probability measure. For a single outcome is the realization of .
In general,
provides a non-random amount of loss for the risk
. One of the most fundamental and important risk measures is the value-at-risk (VaR) which provides a measure for the loss of the risk about its tail distribution (
Linsmeier and Pearson 2000). VaR is exactly the threshold value such that the probability of a risk exceeds this value in a given probability level
Financial institutions and insurance companies commonly use .
In risk measurement and financial mathematics, the concept of acceptance set refers to a set that is acceptable to both the regulator and the investor. Acceptance sets are studied in a vast number of researches with clear applications in practice. The acceptance set,
, for a scalar risk measure of some risk
is given by
where
is the Lebesgue
p-dimensional space. The above acceptance set considers only a single risk
Y. The set-valued risk measures were developed for quantifying and investigating systems of dependent risks having certain acceptance sets (
Jouini et al. 2004). These risk measures are defined as a map from subset
V of possible outcomes of losses
to the Euclidean space
, and are defined by
(
Jouini et al. 2004;
Aubin and Frankowska 2009;
Hamel et al. 2011;
Hamel et al. 2013;
Landsman et al. 2016;
Molchanov and Cascos 2016;
Shushi 2018;
Landsman et al. 2018b). The acceptance set for set-valued risk measure
is given by
In this paper, we extend the formulation of risks into a topological framework, which allows analyzing more information about the risks such as their topological structure, a distance measure of the risk with its risk measure, and a new type of acceptance set of the risks which takes into account the uncertainty of the risk and not only its measure.
Definition 1. We define a topological risk (TR) space as a random set X of any risk events and a family of subsets of that satisfies:
- (a)
where ∅ is the empty set.
- (b)
If is a collection of sets such that for any then also and if is a finite collection of sets such that for any then .
- (c)
For any TR random set X, there exists a TR set-valued measure ϱ that quantifies the amount of loss expected from the risk, and it is defined by that is a d-dimensional risk measure.
- (d)
Uncertainty. Any topological risk posses an uncertainty distance on X such that is a random metric on where is a d-dimensional random vector on the set X. The distance metric d quantifies the variation of the risk with its risk measure. To quantify the uncertainty measure, we take its expectation .
We then call a topological risk (TR) on and sets in are called open sets in .
The acceptance set of TR consists of a distance measure, which we call it the uncertainty distance on X such that is a random metric on . is the distance from the point x to the set . For example, the Euclidean distance is .
The distance metric
d quantifies the variation of the risk with its associated risk measure and is defined as follows:
for some threshold level of uncertainty
. We would like to remark that, for a pair of TRs
, if
, then it does not hold, in general, that
for any type of equality (i.e., almost surely, in distribution, etc.).
In the next section, we show how diversifiable and non-diversifiable risks can be characterized explicitly by the topological risk measures. We also provide some basic properties of the proposed topological risks.
Section 3 deals with the pair
as a full characterization of the risks, and examines different special cases.
Section 4 proposes a conclusion to the paper.
2. Main Results
We now present a special type of set-valued risk measures that classifies these two types using concepts from general topology. The condition in the theorem is a sufficient condition, and not a necessary condition.
Theorem 1. Diversifiable topological risks are topologies followed by a connected set, and non-diversifiable topological risks followed by a non-connected set.
Proof. In general topology, we say that a set is connected if there are no sets
that are closed, non-empty and disjoint such that
(
Engelking 1977). For TR that has a connected set, there is no, in general,
such that their union is
and thus
which implies that such TR is not diversifiable. Finally, the diversifiable topological risks possess a non-connected set, which means that there exist such
in which
. □
An important property of risk measures is called the subadditivity property which states that holding risks simultaneously in a single portfolio is better than dealing with them separately (
Jouini et al. 2004;
Danielsson et al. 2005;
Song and Yan 2009;
Cai et al. 2017). Similar to the standard risk measure
, the TR measure can also be a subadditive measure. For a diversifiable TR, there exists a measure
, such that for any
,
, we have
which means that there must be some gain when combining the topological risks.
Let us now present some straightforward properties involving the union of diversifiable and non-diversifiable topological risks.
Theorem 2. The union of a pair of disjoint diversifiable topological risks is also diversifiable.
Proof. Since both
are diversifiable sets, they are not connected sets, and thus their union
is also not a connected set (see,
Engelking 1977;
Kelley 2017), i.e., their union is a diversifiable set. □
The Euler characteristic is an important property of a topological space that is invariant under homeomorphisms, i.e., it describes the shape of a topological space regardless of the way it is bent. This measure is denoted by
of some set
, where
is the set of all outcomes (
Harer and Zagier 1986;
Taylor and Adler 2003;
Adler and Taylor 2009;
Estrade and León 2014). The Euler characteristic quantifies an inherent property of the topological risk that does not change under continuous transformations, which is close to the homogeneity property of risk measures, such as tail value-at-risk. Another characteristics are the Euler integrals which are defined by the weighted-sum of Euler characteristics, we define the Euler integral, as follows:
where
are integers,
f is a real function of
, and
are
m different topological risks.
For topological risks, the Euler characteristic becomes a random variable, and thus it has to be considered in a statistical framework (for random Euler characteristic, see, for example,
Cheng and Xiao 2016). Suppose that we have a portfolio of
topological risks that are defined by their topological representation
. Then, we define the portfolio characteristic by the following Euler integral,
where
denotes the collection of the TR random sets
,
,
is a real continuous function
that quantifies the loss of the portfolio subject to the parameter
, and
is a real value constant
,
,
, such that
, which are the weights for each topological risk.
If one wishes to get the Euler characteristic, then one should take the TR sets
for all
and
. Thus, the sum in Equation (
4) reduces to
Theorem 3. The portfolio characteristic satisfies the following properties:
- 1.
For sets and , the following additivity property holds - 2.
For empty sets the portfolio characteristic Ξ is zero.
- 3.
can be written as the sum of Betti numbers
The Betti number, , is defined as a characteristic of k-dimensional connectivity of the topological space, it is the number of holes on a k-dimensional topological surface, and it is a random variable for topological risks.
Proof. The additivity property is one of the main features of Euler characteristic
. This property is also preserved in
for sets
A and
BThe Euler characteristic of an empty space is zero, and thus,
In
Taylor and Adler (
2003), it was proved that the Euler characteristic can be defined as the summation of Betti numbers
Thus,
also can be defined through Betti numbers by the double summation
where
is the
Betti number. □
The Lipschitz–Killing curvatures
are another important characteristics of the topological space. Since the topological risks are random, their Lipschitz–Killing curvatures are random variables of the excursion sets (see, again,
Adler and Taylor 2009) with
where
M and
X are a
stratified manifold in
and
respectively. We note that a stratified manifold is a set that can be partitioned into a union of disjoint manifolds, which can be written, as follows:
For every index
provides a different characteristic of the field
for instance,
is the Euler characteristic
. The expectation of
over a stratified manifold was shown in
Taylor and Adler (
2003) in the following form
Using the Lipschitz–Killing curvatures, we now present the expectation and variance of the portfolio characteristic .
Theorem 4. The expectation and variance of for stratified manifolds are, respectively,and Here, and Proof. By substituting (
6) into the expectation of
, we obtain the following linear form
Furthermore, the variance of
can also be computed straightforwardly,
□
Following the above properties of the portfolio Euler characteristic, we are able to calculate a stochastic upper bound to that does not depend on the weights .
Theorem 5. Suppose is the Euler characteristic functional (Equation (
4)
) with weights and non-negative values of the Euler characteristics . Thenwhere means that is stochastically greater than , i.e., for all . Proof. From the Cauchy–Schwarz inequality, we know that for real
and
therefore for the Euler characteristic functional
the following stochastic inequality holds
thus for
, we conclude that
, observing that
, we finally conclude that
□
3. From Topological Risks to Risk Space
In modern portfolio theory, is the expected portfolio return and is the standard derivation of the portfolio return, gives the uncertainty about the risk. Here, we generalize this concept into the topological framework, where is the risk measure which gives the predicted risk, and , , is the random distance metric which quantifies the uncertainty of the risk. Since d is stochastic, we naturally consider its expected value, .
Here are some special cases of the measure for the dispersion of the topological risks.
Example 1. For a sample of m observations and a sample mean , we can define a quadratic distance measure d as a distance between a vector of m observations and their sample mean to get the sample variance A risk measure is said to be conservative with respect to iff . A famous example is the tail value-at-risk (TVaR) which is conservative with respect to VaR, since for any random variable Z and any quantile .
The sample variance is proportional to the quadratic sum of each observer minus the sample mean. Using the concept of distance metric as a dispersion quantity, we allow building a dispersion value that is more conservative than the sample variance. Instead of taking the same variance, one can take the maximum difference between an observation and the sample mean instead of each component of the same variance, i.e.,
. Then, we define the following quantity
which is, of course, greater or equal to the sample variance, i.e.,
.
The Riemannian distance metric is symmetric, i.e., . Recall that we do not restrict ourselves to the Riemannian metric, and thus, this equality does not hold in general. In the following example, we give a dispersion measure of a risk X with sample , around the mean of other risk Y with sample . This measure quantifies the differences between each observation to the mean of an associated , which is relevant when we need to choose between the risk that we hold , in which we have its sample data, and a risk , where we only have its sample mean .
Example 2. Non-symmetric dispersion measure. The following gives a dispersion measure for observations , of a risk X around the sample mean, , of another risk Y with observations ,where and is vector. In general, so this is a pseudo-Riemannian distance. It is not hard to prove that, if , then it is also true that is the sample variance of . Particularly, this can be proved by observing that for , since every component of the sum is non-negative, for any , and therefore, . Finally, substituting instead of in , the result is then obtained. Example 3. Using the concept of topological risks, we can define the topological value-at-risk (VaR) as a measure of a random variable X with a pdf , with the addition of a distance measure that quantifies the dispersion of the risk to some risk measure , as follows:for the α-th percentile and a parameter . Notice that is it possible that there will be no such a point such that both conditions and will be satisfied for some constants α and . Unlike the standard VaR measure, we also included the condition which means that the uncertainty of the risk to its measure is less than or equal to some chosen parameter , which allows controlling the uncertainty regarding the risk. The is different from VaR and does not claim to be a better risk measure; it merely takes into account other information about the uncertainty of the risk compared to an associated risk measure . For different investors, we have different values of β which is the upper bound for the uncertainty . In particular, for more riskier investors, we would have a higher value of . Similar to TVaR, which is an upper bound for the VaR, we can derive a topological tail VaR which also gives an upper bound for the topological VaR . This measure is given by for some random variable X with pdf . From the monotonicity of the expectation measure, it can be easily proved that . Example 4. The mean-variance (MV) model aims to find the best portfolio selection one should invest in order to get the maximum expected portfolio return under a certain level of risk, or to minimize the risk under a certain amount of expected return (see, for example, Ziemba and Mulvey 1998; Markowitz et al. 2000; Zenios 2002; Landsman et al. 2018a). In the MV model, one considers the following measure where and are the expected portfolio return and variance portfolio return, respectively, and is the risk aversion parameter. Using the topological risk formulation, we are able to generalize the celebrated mean-variance measure in a natural way. Let be the TR of a portfolio of risks such that is the portfolio return measure with and an vector of weights and the collection of topological risks, respectively, where each TR has the weight , . By taking instead of the portfolio expectation and instead of the variance of the portfolio, the following measure is then obtained,where is a set-valued risk measure from to the real line, : . Numerical Illustration
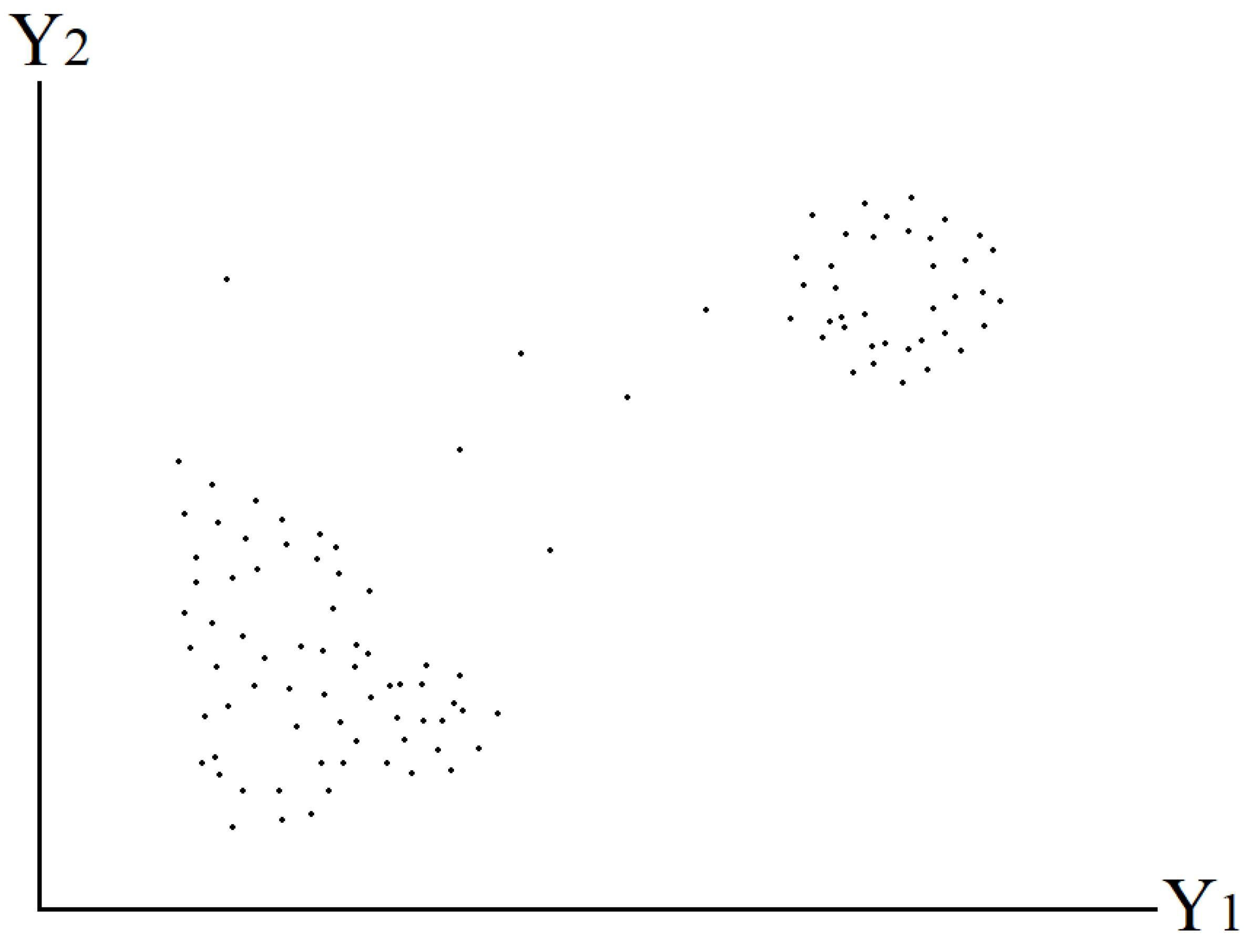
Using the following numerical illustration, we show how one can use the theory of TR in practice. Suppose that we have two risks, denoted by , with historical data . Then, we can plot the collected historical data .
In
Figure 1, we observe that, in such example, the data are mainly divided by two different clusters. To build a regression model, one may use linear or nonlinear regression models, but such models must take into account that the data are of two separated clusters, and thus, for example, a linear regression would not provide a good predictive model for the data. Furthermore, the topological structure of the two clusters should also be considered. The following figure shows the topological structures of the data set, showing a two topological structure.
Figure 2 shows two topological risks for the two clusters of the dataset. As can be seen, the below-left cluster is illustrated by a genus-2 topological surface and the above-right cluster is illustrated by a torus. These two topologies construct the set of predicted outcomes for the pair
. Thus, any regression model for the risks should take into account such inner structure of the clusters. Furthermore, any risk measure
would be on the domain of the topological risks. For example, the following topological-based risk measure can be obtained by taking the conditional expectation of the risks
as follows:
where Top
is the topological structure of the data; in our example, it is the orange area in
Figure 2 with a torus and genus-2 structures.
4. Discussion
In this paper, we have investigated the use of topology for studying risks. We have shown how topological risks can be divided into two general classes of risks, namely, diversifiable and non-diversifiable risks, and we have presented a rigorous foundation for the topological risk theory. Although it is an intuitive result, using the theory provided here, we have shown that combining a pair of disjoint diversifiable topological risks into a single topological risk is also diversifiable. Furthermore, we have investigated the Euler characteristic for a portfolio of topological risks with applications in the theory of risks and provided some of its fundamental properties. We then presented some special dispersion measures that are based on the concept of a distance metric of the topological sets. The presented theory of topological risks provides a new formalism in risk measurement that has the potential for a future research.


{kind=link}
{kind=link}