Active Management of Operational Risk in the Regimes of the “Unknown”: What Can Machine Learning or Heuristics Deliver?

Abstract
:1. Introduction
In reality, the main purpose of machine learning is to predict the future. Knowing the movies you watched in the past is only a means to figuring out which ones you’d like to watch next. … If something has never happened before, its predicted probability must be zero — what else could it be?
- Is there an opportunity to apply machine learning to predict the future beyond statistical estimations of average distribution functions to support active operational risk management?
- For what regime of the “unknown”—rare events or even unforeseen event types—could machine learning be applied?
- Has machine learning always benefited compered to human heuristics when it should be implemented for fighting OpRisk events?
2. Active Operational Risk Management and the Domains of the “Unknown”
“aleatory (representing variation) and epistemic (due to lack of knowledge). For aleatory uncertainty there is broad agreement about using probabilities with a limiting relative frequency interpretation. However, for representing and expressing epistemic uncertainty, the answer is not so straightforward.”
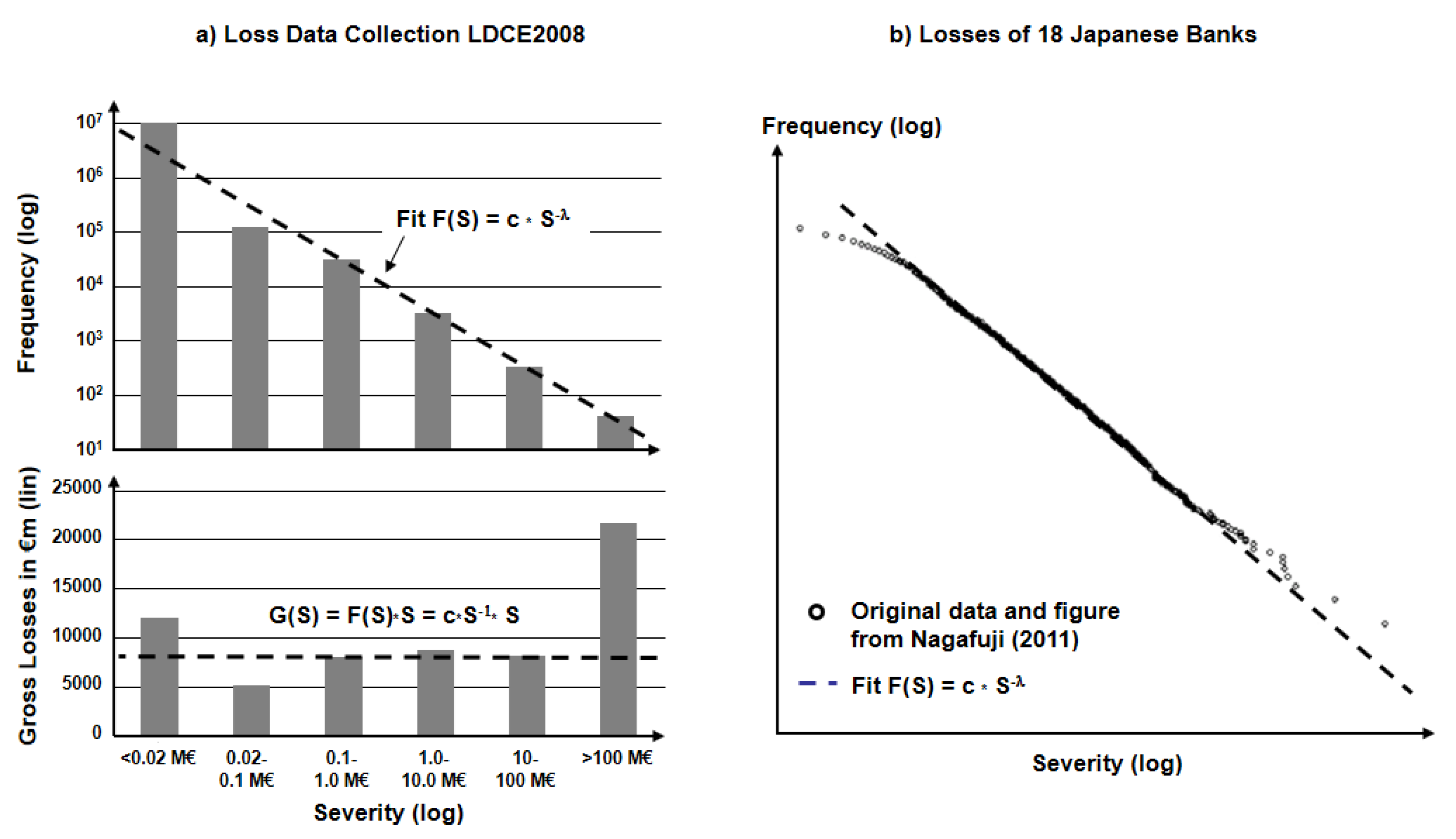
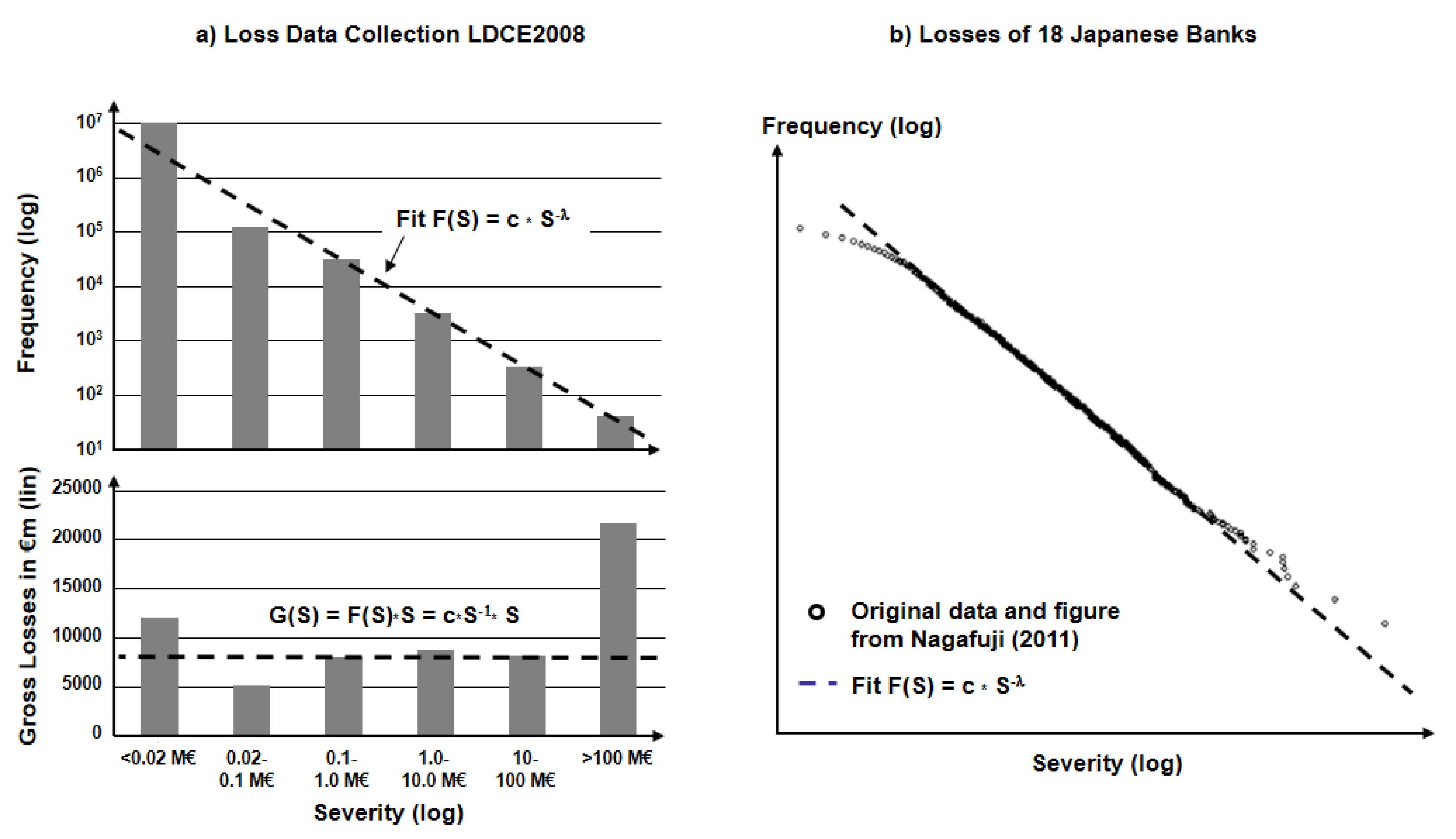
- Historical loss data with actual (equaling measured) events, defined by R0 = {E, L, N; SoK = 1} with type of OpRisk event E, loss L, recorded number of events N. For aggregated events, a statistical measurement error can be added Ri = {Ei, Li, Ni, σi; SoK = 1}.
- Operational risk R = {E, L, Ps; SoK} with a Bayesian interpretation of Ps as a subjective measure of uncertainty about the risk as seen through the eyes of the analyst and based on some assumptions and some knowledge about the “risk-generating process,” i.e., the Bayesian perspective (usually with an assumption that the underlying process is going to be repeated for an infinite number of times).
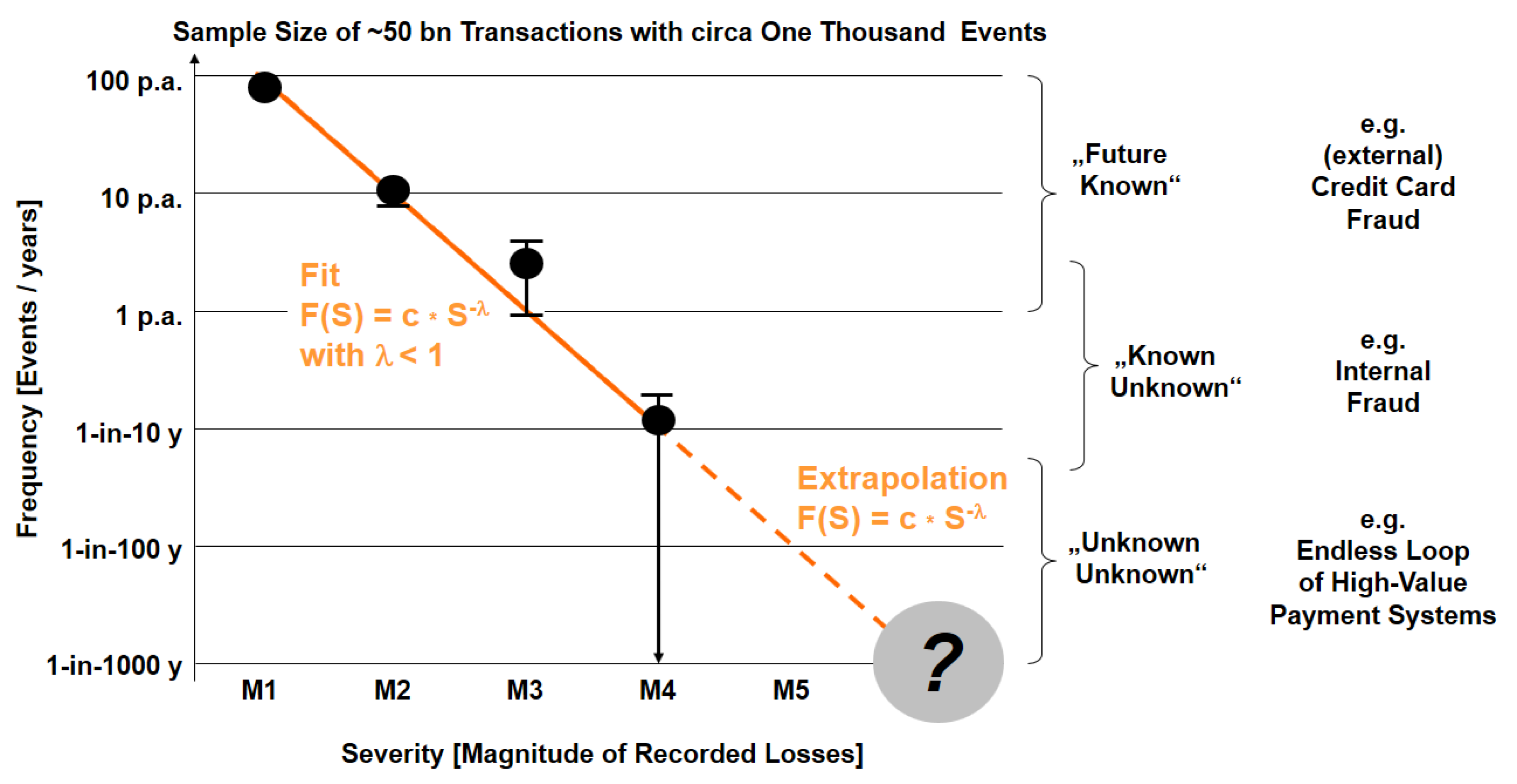
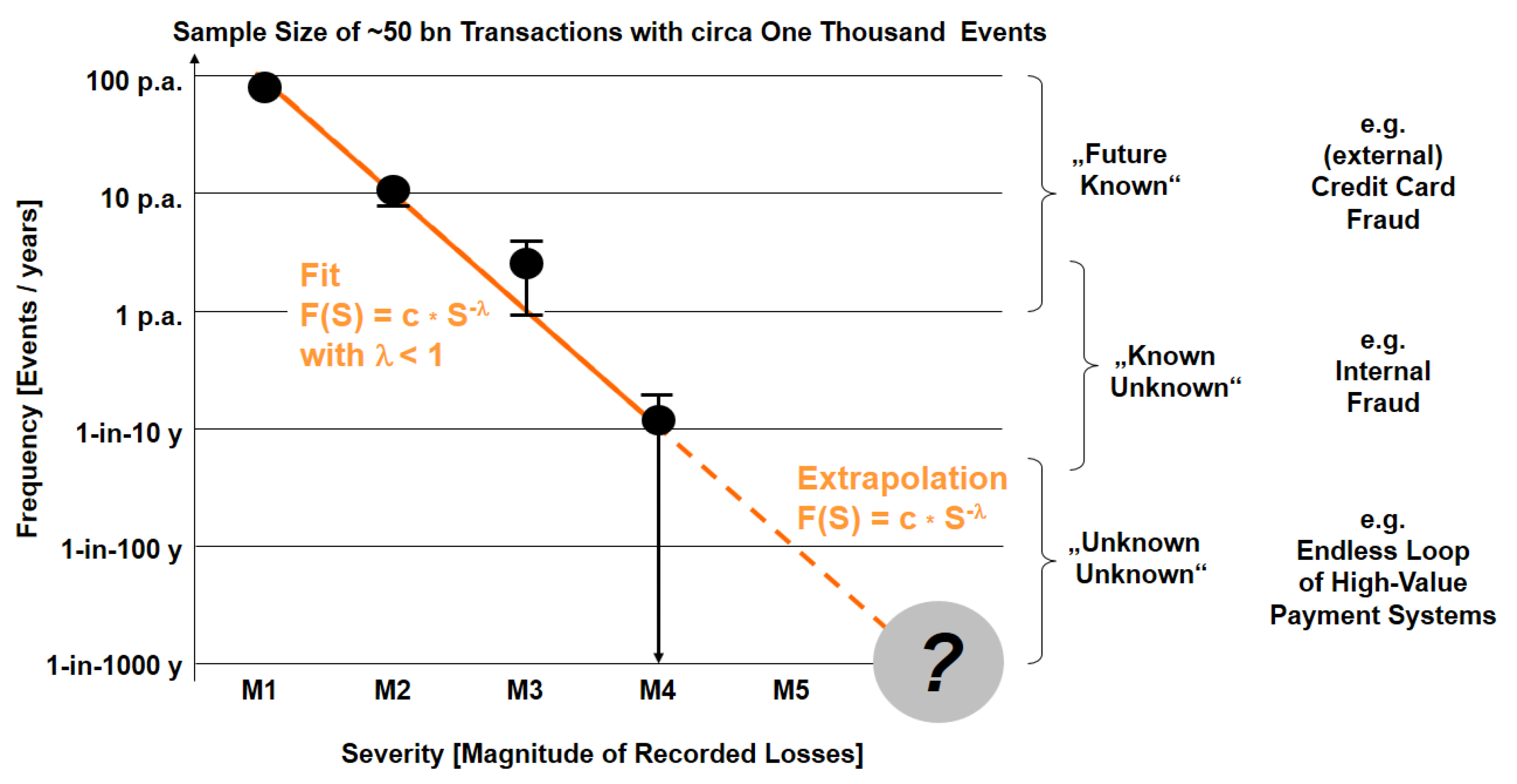
- Estimation of (future) risk R* = {E, L, Pf*, U(Pf*), SoK} while the probability Pf of the relative frequency is unknown as no empirical data are available (the “extrapolation” area for magnitudes >10 million € in Figure 2), when the risk generating process is time-dependent (i.e., nonstationary), or when assumptions for an extrapolation show large variations (e.g., in risk self-assessment). An estimation for R* includes an estimated Pf*, the uncertainty U of this probability U(Pf*), and the Strength of Knowledge SoK, on which the estimation is based.
- Uncertainty of “unknown” future with replacement of the frequency-interpreted probability Pf by the uncertainty U(SoK) itself, giving a risk perspective RU = {E, L, U(SoK)}. This is more than a simple algebraic replacement, as it shifts the concept of risk from the calculation of probabilities (with a given SoK) to the question of uncertainties of ex ante knowledge (with SoK << 1).
- The “unknown unknown”, i.e., the risk of “one-claim-causes-ruin” with no historical knowledge and low probability Pf e.g., about 1-in-10,000 years. Such events are not repeatable (as one event is, per definition, a final catastrophe), which contradicts the assumption of the probabilistic interpretation and which indicated a break from “measurable” monetary loss to “possible” disaster with no knowledge: RD = (E, Disaster, SoK ≈ 0). As an intermediate conclusion, one can ask the question whether any kind of machine learning based on measured data could handle those aspects of risk far beyond the existing data.
3. Applications of Machine Learning for the “Known”
- feature extraction about customers’ behaviour pattern to pay by card as classification criteria;
- classification of a single transaction at checkout “on the fly” with an authorization requested.
- “Machine learning relies on good input data”.6
- “Machine learning is only as good as the human data scientists behind it”.
- “Machine learning is often a black box, especially when self-learning techniques are employed. The machine can learn the wrong thing”.
- “A way to counteract the downsides of machine learning is to combine an automated machine learning system with a rules-based approach”.
“major consumer pain point of being falsely declined when trying to make a purchase”.
- There are differences of OpRisk types (e.g., credit card fraud versus delayed corporate actions), which all have to be treated differently and with different machine learning approaches.
- A combination of existing data plus ex ante knowledge (typically described by “rules”) is needed to train the learners to extract individual patterns.
- A holistic understanding of the (commercial) objectives t is required to avoid a “right” fine-tuning of the learners to the “wrong” goals. There is a meta-risk to solve a single problem (e.g., fine-tuning of fraud protection systems), but increase the holistic business risk due to inappropriate model assumptions.
4. Machine Learning and Heuristic for the “Known Unknown”
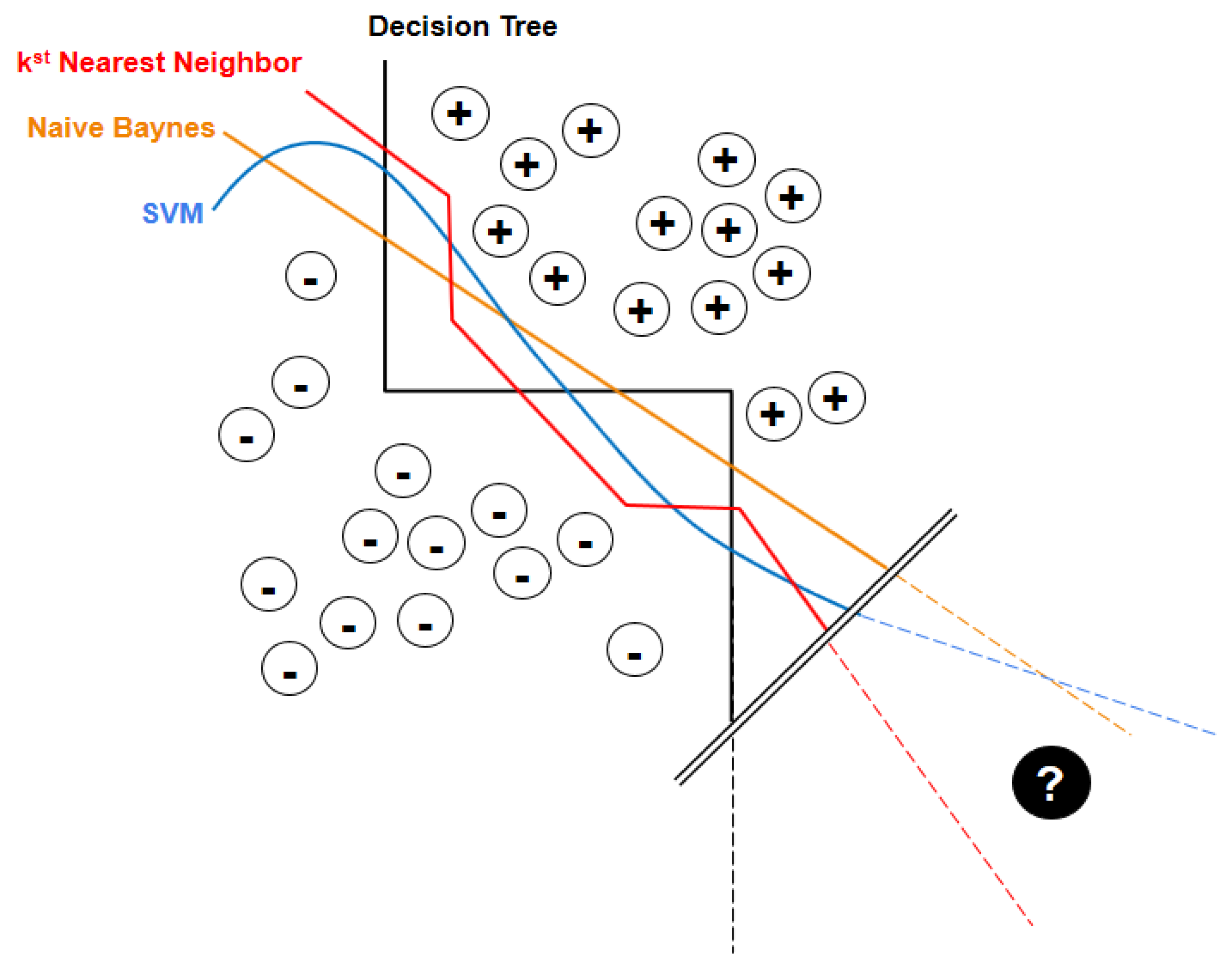
- Bias as a machine learning’s tendency to learn a wrong thing consistently (due to erroneous assumptions in the underlying learning algorithm, e.g., in linear “leaners”);
- Variance as the tendency to learn random “noise” irrespective of the real signal (e.g., in decision trees or random forests).
- In this domain, it is not possible to provide data with a “negative” label—so what should the learner learn?
- If we add some known rules of the game (only darts on the target are “OK”), we already have a classifier (in the sense of “x2 + y2 < r2”), which does not require any learner.
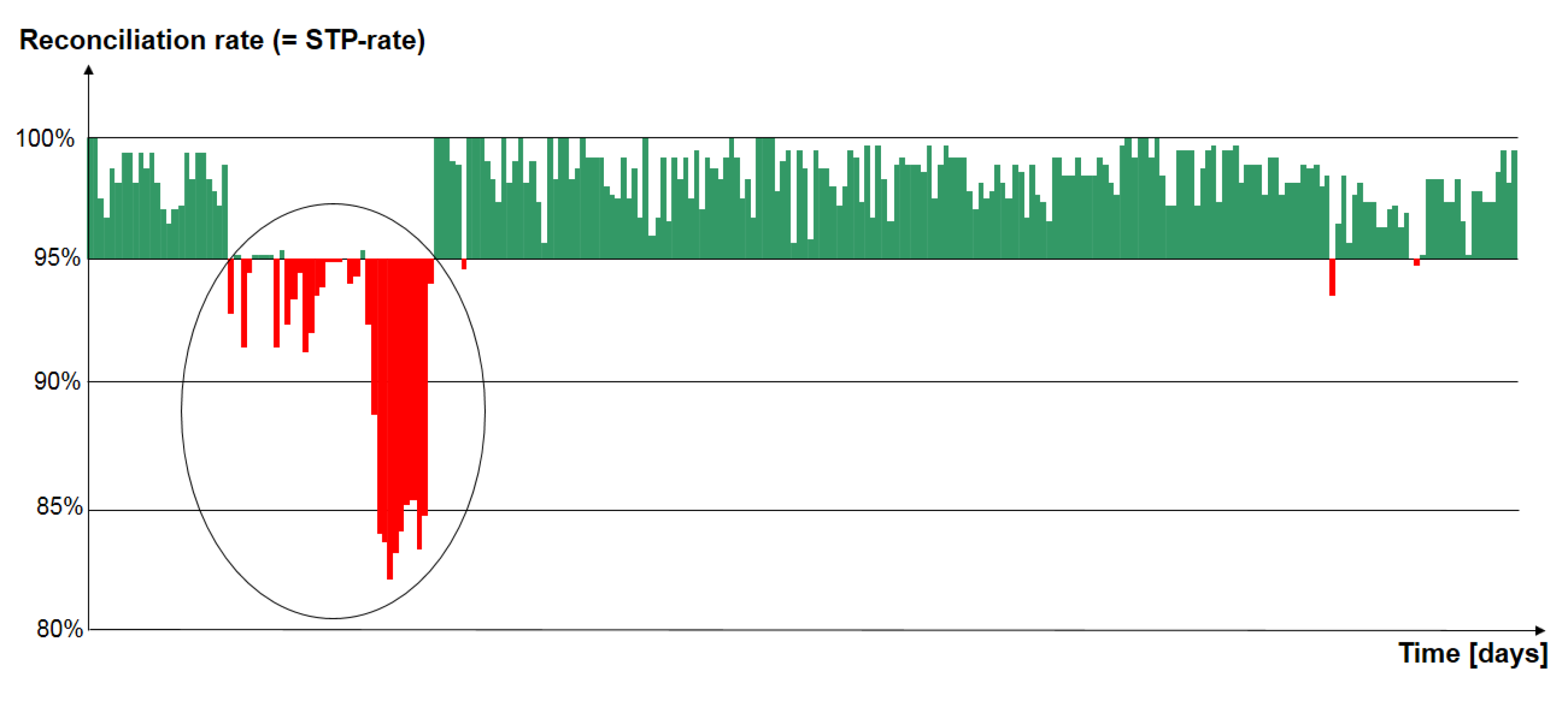
- The challenge of active risk management in the first line of defence would be to “predict” a trend, which could possibly lead to an OpRisk event—but ex ante.
- shift of the barycentre of the fifth series (by chance);
- literally “moving target” due to a drift of the dart board;
- constant drift of the barycentre of the series;
- singular “lemons” (e.g., the first try in a series or, literally, the first cars produced on Mondays).
5. Machine Learning It the “Unknown Unknown”
“German state bank Kfw accidentally transferred 7.6 billion euros ($8.2 billion) to four other banks but got the money back, incurring costs of 25,000 euros, executive board member Guenther Braeunig said on Wednesday.”
“In the afternoon of 20 February 2017, a mistake in configuration works performed by an experienced IT programmer of KfW caused a temporary system bug in a payment transaction software. This led to multiple payments being made by KfW to four banks.”
- A gap between actual financial losses (reported data for the event including applied measures to contain the loss) and potential “worst case” scenarios (for a situation that never happened before in reality);
- Complexity of the root cause, which is typically a coincidence of many “elementary” causes.
- In the SOC framework, one would imagine an area, where trees are naturally and randomly growing with occasional lightning strikes that could cause a fire. Over longer time, the forest will “organise” itself (internally) into a meta-stable state: most of the time, fires are small and contained, but on rare occasions, a random lightning strike can cause the forest to be lost.
- In the HOT framework, the forest is not “self-organising,” but a (human) forester takes concern for the expected yield of the forest with a trade-off: a more densely filled forest makes for superior expected yield, but it also exposes the forest to higher fire risk. The human (external) response is to build firebreaks: larger in number where lightning strikes, fewer where they are rare. This arrangement maximises expected yield. However, it will also result in occasional “systemic” forest fires (as, e.g., scrub will be removed, which typically leads to small fires in free nature, which “clean” the forest).
6. Outlook: Fighting Risk with Machine Reasoning
- Knowledge Items (KI) as atomic pieces of experts’ knowledge about OpRisk management and possible action in the first line of business to react;
- Knowledge Core (KC) as accessible semantic map of an organization’s data based on KIs plus information about the structure of an organization;
- Machine Reasoning (MR) to solve ambiguous and complex problems.
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Aven, Terje. 2011. Quantitative Risk Assessment. Cambridge: Cambridge University Press. [Google Scholar]
- Aven, Terje. 2016. Risk assessment and risk management: Review of recent advances on their foundation. European Journal of Operational Research 253: 1–13. [Google Scholar] [CrossRef]
- Bak, Peter, Chao Tang, and Kurt Wiesenfeld. 1987. Self-organized criticality: An explanation of the 1/f noise. Physical Review Letters 59: 381–84. [Google Scholar] [CrossRef] [PubMed]
- Basel Committee on Banking Supervision (BCBS). 2009. Results from the 2008 Loss Data Collection Exercise for Operational Risk. LDCE2008. Basel: Bank for International Settlement. [Google Scholar]
- Basel Committee on Banking Supervision (BCBS). 2017a. Basel III: Finalising Post-Crisis Reforms. Basel: BCBS. [Google Scholar]
- Basel Committee on Banking Supervision (BCBS). 2017b. High-Level Summary of Basel III Reforms. Basel: BCBS. [Google Scholar]
- Bhalla, Ajay. 2016. Quote in: Mastercard Rolls Out Artificial Intelligence Across its Global Network. Press Release. Purchase: Mastercard, November 30, Available online: newsroom.mastercard.com/press-releases/mastercard-rolls-out-artificial-intelligence-across-its-global-network/ (accessed on 18 July 2017).
- Bott, Jürgen, and Udo Milkau. 2015. Outsourcing risk: A separate operational risk category? Journal of Operational Risk 10: 1–29. [Google Scholar] [CrossRef]
- Bottou, Léon. 2014. From machine learning to machine reasoning. Machine Learning 94: 133–49. [Google Scholar] [CrossRef]
- Boos, Hans-Christian. 2017. AI is about Machine Reasoning—Or when Machine Learning is just a fancy plugin. Personal communication. [Google Scholar]
- Carlson, Jean M., and John Doyle. 2002. Complexity and robustness. Proceedings of the National Academy of Sciences USA 99: 2538–45. [Google Scholar] [CrossRef] [PubMed]
- Chavez-Demoulin, Valerie, Paul Embrechts, and Johana Neslehova. 2006. Quantitative models for operational risk: extremes, dependence and aggregation. Journal of Banking and Finance 30: 2635–58. [Google Scholar] [CrossRef]
- Clauset, Aaron, Cosma Rohilla Shalizi, and Mark E. J. Newman. 2009. Power-law distributions in empirical data. SIAM Review 51: 661–703. [Google Scholar] [CrossRef]
- Conneau, Alexis, Holger Schwenk, Loïc Barrault, and Yann Lecun. 2017. Very Deep Convolutional Networks for Text Classification. Available online: arxiv.org/abs/1606.01781 (accessed on 14 July 2017).
- Cruz, Marcelo G. 2002. Modeling, Measuring and Hedging Operational Risk. Chichester: John Wiley & Sons. [Google Scholar]
- Cser, Andras. 2017. The Forrester Wave™: Risk-Based Authentication, Q3 2017. Cambridge: Forrester Research. [Google Scholar]
- CyberSource. 2016. The Role of Machine Learning in Fraud Management. Foster City: CyberSource Corporation, Available online: www.cybersource.com/content/dam/cybersource/NA_Machine_Learning_Whitepaper.pdf (accessed on 23 July 2017).
- De Fontnouvelle, Patrick, Eric. S. Rosengren, and John S. Jordan. 2005. Implications of Alternative Operation-al Risk Modeling Techniques. NBER Working Paper No. w11103. Chicago: University of Chicago Press. [Google Scholar]
- Degen, Matthias, Paul Embrechts, and Dominik D. Lambrigger. 2007. The quantitative modeling of operational risk: Between g-and-h and EVT. Astin Bulletin 37: 265–91. [Google Scholar] [CrossRef]
- Dietvorst, Berkeley J., Joseph P. Simmons, and Cade Massey. 2015. Algorithm aversion: People erroneously avoid algorithms after seeing them err. Journal of Experimental Psychology: General 144: 114–26. [Google Scholar] [CrossRef] [PubMed]
- Dietvorst, Berkeley J., Joseph P. Simmons, and Cade Massey. 2016. Overcoming Algorithm Aversion: People Will Use Imperfect Algorithms If They Can (Even Slightly) Modify Them. Management Science 64: 1155–70. [Google Scholar] [CrossRef]
- Domingos, Pedro. 2012. A few useful things to know about machine learning. Communications of the ACM 55: 78–87. [Google Scholar] [CrossRef]
- Domingos, Pedro. 2016. Available online: Ten Myths about Machine Learning. Available online: https://medium.com/@pedromdd/ten-myths-about-machine-learning-d888b48334a3 (accessed on 12 July 2017).
- Ehramikar, Soheila. 2000. The Enhancemeat of Credit Card Fraud Detectioa Systems Using Machine Learning Methodology, University of Toronto. Available online: www.collectionscanada.ca/obj/s4/f2/dsk1/tape3/PQDD_0023/MQ50338.pdf (accessed on 23 July 2017).
- Ferreira, Ana, and Laurens de Haan. 2014. The generalized Pareto process; with a view towards application and simulation. Bernoulli 20: 1717–37. [Google Scholar] [CrossRef]
- Ferreira, Marta, and Helena Ferreira. 2017. Analyzing the Gaver—Lewis Pareto Process under an Extremal Perspective. Risks 5: 33. [Google Scholar] [CrossRef]
- Fukushima, Kunihiko. 1980. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics 36: 93–202. [Google Scholar] [CrossRef]
- Giacometti, Rosaella, Svetlozar Rachev, Anna Chernobai, Marida Bertocchi, and Giorgio Consigli. 2007. Heavy-tailed distributional model for operational losses. Journal of Operational Risk 2: 55–90. [Google Scholar] [CrossRef]
- Gigerenzer, Gerd, and Henry Brighton. 2009. Homo Heuristicus: Why Biased Minds Make Better Infer-ences. Topics in Cognitive Science 1: 107–43. [Google Scholar] [CrossRef] [PubMed]
- Gigerenzer, Gerd, Ralph Hertwig, and Thorsten Pachur. 2011. Heuristics: The Foundations of Adaptive Behavior. Oxford: Oxford University Press. [Google Scholar]
- Gigerenzer, Gerd, and Wolfgang Gaissmaier. 2011. Heuristic Decision Making. Annual Review of Psychology 62: 451–82. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, Ian J., Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative Adversarial Networks. Available online: arxiv.org/abs/1406.2661 (accessed on 14 July 2017).
- Ghosh, Sushmito, and Douglas L. Reilly. 1994. Credit Card Fraud Detection with a Neural-Network. Paper presented at Twenty-Seventh Annual Hawaii International Conference on System Sciences, Wailea, HI, USA, January 4–7; Washington, DC: IEEE, vol. 2, pp. 621–30. [Google Scholar]
- Haldane, Andrew. 2012. Tails of the unexpected. Paper presented at The Credit Crisis Five Years on: Unpacking the Crisis Conference, Edinburgh, UK, June 8–9. [Google Scholar]
- Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2009. The Elements of Statistical Learning. New York: Springer Science + Business Media, Second Edition, 2013. [Google Scholar]
- Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. Long Short-term Memory. Neural Computation 9: 1735–80. [Google Scholar] [CrossRef] [PubMed]
- Institute of Internal Auditors (IIA). 2013. The Three Lines of Defense in Effective Risk Management and Control. Position Paper. Lake Mary: IIA. [Google Scholar]
- Jones, Nicola. 2017. How machine learning could help to improve climate forecasts. Nature News, August 23. [Google Scholar]
- KFW. 2017. Payment Transactions of KfW—What Has Happened? KfW Press Release, Undated. Available online: www.kfw.de/KfW-Group/Newsroom/Aktuelles/Zahlungsverkehr-der-KfW.html (accessed on 2 April 2017).
- Knight, Frank H. 1921. Risk, Uncertainty, and Profit. New York: Harper. [Google Scholar]
- Kwakkel, Jan H., and Erik Pruyt. 2011. Exploratory Modelling and Analysis, an approach for model-based foresight under deep uncertainty. Paper presented at 4th International Seville Conference on Future-Oriented Technology Analysis, Sevilla, Spain, May 12–13; Edited by Effie Amanatidou. Sevilla: FTA, pp. 1–20. [Google Scholar]
- Lapuschkin, Sebastian, Alexander Binder, Grégoire Montavona, Klaus-Robert Muller, and Wojciech Samek. 2016. Analyzing Classifiers: Fisher Vectors and Deep Neural Networks. Paper presented at 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, June 26–July 1; Piscataway: IEEE. [Google Scholar]
- LeCun, Yann, Patrick Haffner, Léon Bottou, and Yoshua Bengio. 1999. Object Recognition with Gradient Based Learning. In Shape, Contour and Grouping in Computer Vision. Lecture Notes in Computer Science Book Series (LNCS). Berlin: Springer, vol. 1681, pp. 319–45. [Google Scholar]
- Liu, Yunjie, Evan Racah, Prabhat, Joaquin Correa, Amir Khosrowshahi, David Lavers, Kenneth Kunkel, Michael Wehner, and William Collins. 2016. Application of Deep Convolutional Neural Networks for Detecting Extreme Weather in Climate Datasets. Available online: arXiv:1605.01156v1 (accessed on 24 August 2017).
- Marković, Dimitrije, and Claudius Gros. 2014. Power laws and self-organized criticality in theory and nature. Physics Reports 536: 41–74. [Google Scholar] [CrossRef]
- McCormick, Roger, and Chris Stears. 2016. Conduct Costs Project Report 2016. Surrey: CCP Research Foundation CIC, Available online: http://conductcosts.ccpresearchfoundation.com/conduct-costs-results (accessed on 29 July 2017).
- Milkau, Udo. 2012. Adequate Communication about Operational Risk in the Business Line. Journal of Operational Risk 8: 35–57. [Google Scholar] [CrossRef]
- Milkau, Udo, and Frank Neumann. 2012. The first line of defence in operational risk management—The perspective of the business line. Journal of Financial Transformation 34: 155–64. [Google Scholar]
- Mohri, Mehryar, Afshin Rostamizadeh, and Ameet Talwalkar. 2012. Foundations of Machine Learning. Cambridge: MIT Press. [Google Scholar]
- Moscadelli, Marco. 2004. The Modelling of Operational Risk: Experience with the Analysis of the Data Collected by the Basel Committee. Bank of Italy Working Papers Series Number 517; Rome: Bank of Italy. [Google Scholar]
- Motet, Gilles, and Corinne Bieder. 2017. The Illusion of Risk Control—What Does It Take to Live With Uncertainty? Berlin: Springer. [Google Scholar]
- Nagafuji, Tsuyoshi, Takayuki Nakata, and Yugo Kanzaki. 2011. A Simple Formula for Operational Risk Capital: A Proposal Based on the Similarity of Loss Severity Distributions Observed among 18 Japanese Banks. Available online: https://www.fsa.go.jp/frtc/english/seika/perspectives/2011/20110520.pdf (accessed on 12 November 2012).
- Nešlehová, Johana, Paulk Embrechts, and Valerie Chavez-Demoulin. 2006. Infinite-mean models and the LDA for operational risk. The Journal of Operational Risk 1: 3–25. [Google Scholar] [CrossRef]
- PRNewswire. 1993. Visa and Hnc Inc. Develop Neural Network as a Weapon to Fight Fraud. TM-SF007-1246 08/10/93. Available online: www.thefreelibrary.com (accessed on 14 July 2017).
- Pun, Joseph King-Fung. 2011. Improving Credit Card Fraud Detection using a Meta-Learning Strategy. Ph.D. thesis, University of Toronto, Toronto, ON, Canada. Available online: tspace.library.utoronto.ca/bitstream/1807/31396/3/Pun_Joseph_KF_201111_MASc_thesis.pdf (accessed on 23 July 2017).
- Purdy, Grant. 2010. ISO 31000:2009—Setting a New Standard for Risk Management. Risk Analysis 30: 881–86. [Google Scholar] [CrossRef] [PubMed]
- Reuters. 2017. German State Bank KfW Accidentally Transferred 7.6 billion euros. Reuters. March 29. Available online: http://www.reuters.com/article/us-kfw-mistrade-idUSKBN1700W8 (accessed on 29 July 2017).
- Samson, Sundeep, James A. Reneke, and Margaret M. Wiecek. 2009. A review of different perspectives on uncertainty and risk and an alternative modeling paradigm. Reliability Engineering & System Safety 94: 558–67. [Google Scholar]
- Santoro, Adam, David Raposo, David G. T. Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Timothy Lillicrap. 2017. A Simple Neural Network Module for Relational Reasoning. Available online: arxiv.org/abs/1706.01427 (accessed on 14 July 2017).
- Schmidhuber, Jürgen. 2015. Deep learning in neural networks: An overview. Neural Networks 61: 85–117. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, Jürgen. 2017. Künstliche Intelligenz wird alles ändern. Talk given at Petersberger Gespräche, September 16, Bonn, Germany. [Google Scholar]
- Shalev-Shwartz, Shai, and Shai Ben-David. 2014. Understanding Machine Learning: From Theory to Algorithms. New York: Cambridge University Press. [Google Scholar]
- Spielkamp, Matthias. 2017. Inspecting Algorithms for Bias. MIT Technology Review. June 12. Available online: https://www.technologyreview.com/s/607955/inspecting-algorithms-for-bias/ (accessed on 23 July 2017).
- Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. 2015. Going deeper with convolutions. Paper presented at IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, June 7–12. [Google Scholar]
- Trautmann, Wolfgang, Udo Milkau, Uli Lynen, and Josef Pochodzalla. 1993. Systematics of the power law parameter and minimum angular momenta for fragment production. Zeitschrift für Physik A Hadrons and Nuclei 344: 447–54. [Google Scholar] [CrossRef]
- Vocalink. 2018. Available online: http://connect.vocalink.com/2018/april/natwest-teams-up-with-vocalink-analytics-to-protect-corporate-customers-from-fraud/ (accessed on 5 April 2018).
| 1 | For the scope of this paper and the discussion about the tail of the distribution, this simplification on “power law” (or Pareto distributions) is sufficient. For further discussion such as generalized Pareto distributions or g-and-h distribution, the reader is referred to the literature (see e.g., Degen et al. 2017). |
| 2 | Sometimes also called “probability-impact diagrams.” |
| 3 | The concept of the “Strength of Knowledge” emerges on the borderline of statistics and didactical communication about statistical results. As Figure 2 will show later in this paper, all information is contained in the data and in the description about the conditions how the data was taken. Usually, one would assume that the Frequency of events and the Time of the measurement follow the inequation 1/F << T to avoid nonsignificant data set. However, in the case of “very fat tails” like in power-law distributions, one also has to deal with situations 1/F > T, i.e., extrapolations to very rare event types. |
| 4 | It has to be noted that in context of machine learning there is also a definition of “risk” for the empirical error, i.e., the error a classifier incurs over the training sample (see Shalev-Shwartz and Ben-David 2014). From an OpRisk perspective, this would be a model risk. |
| 5 | Another example is Risk-Based Authentication for online banking access (see Cser 2017). |
| 6 | This apparently simple requirement could be challenging with real-world training data sets, as recently shown with an intriguing example by Lapuschkin et al. (2016) that learners could “learn” artefacts, which were correlated with the real content by chance and were not detected beforehand. |
| 7 | Recently Jürgen Schmidhuber (2017) discussed ideas how AI-powered robots can be provided with “artificial curiosity,” which is one way to find new solutions in situation with limited resources including social cooperation. If overall profitability is treaded as a limited resource, there can be a way for AI to learn to achieve holistic benefits, even without explicit training. |
| 8 | It should be noted that this situation resamples similar problems in other fields of machine learning such as, e.g., autonomous vehicles. For many extreme situations, especially situations leading to accidents, the initial models are trained with few data points, which often do not generalize well. To learn dangerous situations, recorded video data have to be combined with synthetic, computer generated video, e.g., for a tree falling on a street due to a storm. This combination of actual data with synthetic data based on heuristics and learning in case of very limited data requires more research about machine learning and models for the handling extremes events. |
| 9 | In principle, the simplest “learners” are rule-based “Key Risk Indicators” (KRI). Typical KRIs in banking are, e.g., “continuous days of vacation <10” or “cancelled trades.” In the first case, there is a heuristics based on the well-known “rouge trader” events that traders should take a fortnight of vacation once a year with somebody else taking over the responsibility for their portfolios. In the second one, some pattern of “cancelled trades” (from a simple monitoring of enhanced numbers to derivation over time from a “normal” pattern) can be an indication, but usually there are no or not enough right positive cases to learn from with some significant statistics. |
| 10 | A similar approach was reported recently by Liu et al. (2016); Jones (2017) for a total different field of research, i.e., detecting extreme weather in climate data sets, with Convolutional Neural Network (CNN) classification system and Deep Learning technique for tackling climate pattern detection problems. |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Regime of Frequent “Known” Events | Regime of Rare “Unknown” Events | Regime of the “Unknown Unknown” | |
|---|---|---|---|
| Statistics of own risk event data | Power Law or GPD | Extreme Value Theory (with Limitations) | |
| Use of external “public” data | Problem of unknown assumptions and methodologies | ||
| OpRisk Self-Assessment | Quantitative Enhancement | ||
| Key Risk Indicators (KRI) | Possibility for (delayed) Forecast | ||
| Heuristics (in FLD) | Danger of Bias | Heuristics for ad-hoc actions | Heuristics for best guesses |
| Machine Learning (stat. Methods) | Pattern Recognition | Problem of Sensitivity/Dependence | |
| Machine Learning (ANN) | Enhanced Pattern Recognition | ||
| Machine Learning + Heuristics | Complex Patterns e.g., f. Fraud Mgmt. | ||
| Machine Learning + Scenarios | Example e.g., Autonomous Cars | ||
| Reinforced Machine Learning | e.g., Google AlphaGo | e.g., Google AlphaGo Zero | |
| Machine Reasoning (i. Heuristics) | Problem Solving | Dynamic Problem Solving | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Milkau, U.; Bott, J. Active Management of Operational Risk in the Regimes of the “Unknown”: What Can Machine Learning or Heuristics Deliver? Risks 2018, 6, 41. https://doi.org/10.3390/risks6020041
Milkau U, Bott J. Active Management of Operational Risk in the Regimes of the “Unknown”: What Can Machine Learning or Heuristics Deliver? Risks. 2018; 6(2):41. https://doi.org/10.3390/risks6020041
Chicago/Turabian StyleMilkau, Udo, and Jürgen Bott. 2018. "Active Management of Operational Risk in the Regimes of the “Unknown”: What Can Machine Learning or Heuristics Deliver?" Risks 6, no. 2: 41. https://doi.org/10.3390/risks6020041
APA StyleMilkau, U., & Bott, J. (2018). Active Management of Operational Risk in the Regimes of the “Unknown”: What Can Machine Learning or Heuristics Deliver? Risks, 6(2), 41. https://doi.org/10.3390/risks6020041