1. Introduction
Basel II/III and
Solvency II are the leading international regulatory frameworks for banking and insurance industries, and mandate that financial institutions build separate capital reserves for operational risk. Within the advanced measurement approach (AMA) framework, the loss distribution approach (LDA) is the most sophisticated tool for estimating the operational risk capital. According to LDA, the risk-based capital is an extreme quantile of the annual aggregate loss distribution (e.g., the 99.9th percentile), which is called value-at-risk or VaR. Some recent discussions between the industry and the regulatory community in the United States reveal that the LDA implementation still has a number of “thorny” issues (
AMA Group 2013). One such issue is the treatment of data collection threshold. Here is what is stated on page 3 of the same document: “Although the industry generally accepts the existence of operational losses below the data collection threshold, the appropriate treatment of such losses in the context of capital estimation is still widely debated.”
Various assumptions about the data collection threshold have been considered in the existing literature: known threshold (
Baud et al. 2002;
Shevchenko and Temnov 2009), threshold as unknown parameter (
Baud et al. 2002), stochastic threshold whose distribution has to be modeled (
Baud et al. 2002;
de Fontnouvelle et al. 2006), and time varying threshold that may scale according to inflation and business factors (
Shevchenko and Temnov 2009). In this paper, we will assume that the threshold is known. Given (external) operational risk databases (which often collect losses exceeding, for example,
$1 million), such an assumption is appropriate.
Further, the annual aggregate loss variable is a combination of two variables—loss frequency and loss severity—and there are different ways to estimate risk-based capital. One way is to estimate the untruncated severity and truncation-adjusted frequency and then compute VaR. This approach follows directly from the results described by Brazauskas, Jones, and Zitikis (
Brazauskas et al. 2015). Another way is to estimate the truncated severity and unadjusted frequency to compute VaR. For a comprehensive review of analytic techniques for truncated data in the context of operational risk modeling, see Cruz, Peters, Shevchenko (
Cruz et al. 2015, sct. 7.9). Furthermore, as is known in practice, the severity distribution is a key driver of the capital estimate (
Opdyke 2014). This is the part of the aggregate model where initial assumptions about the data collection threshold are most influential. A number of authors have examined some aspects of this topic in the past (e.g.,
Cavallo et al. 2012;
Chernobai et al. 2007;
Ergashev et al. 2016;
Luo et al. 2007;
Moscadelli et al. 2005). The modeling approaches they (collectively) considered include: the empirical approach, the “naive” approach, the shifted approach, and the truncated approach. Since each approach is based on a different set of assumptions, different probability models emerge. Thus, model uncertainty arises.
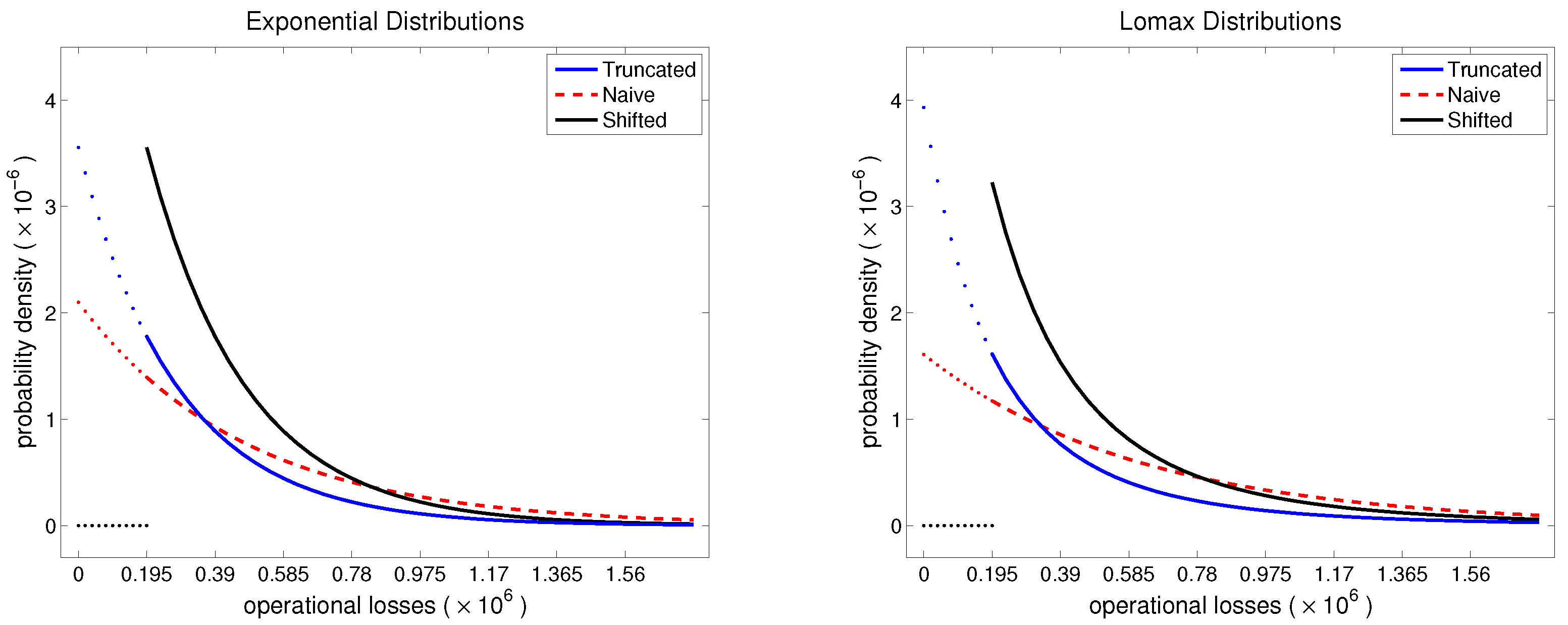
The main objective of this paper is to understand the impact of model uncertainty on risk measurements, and (hopefully) help settle the debate about the treatment of data collection threshold in the context of capital estimation. Solving such a problem under a general setup (i.e., by considering many interdependent risks and multiple stakeholders) is only possible through extensive simulations, but that would not produce much insight. Therefore, we simplify the problem by taking the bank’s perspective and by studying a single risk. Under this simplified scenario, we can solve the problem analytically (when the underlying distribution is exponential), and show that it uncovers similar patterns among VaR estimates to those based on the simulation approach (when data follow a Lomax distribution). We demonstrate that for a fixed probability distribution, the choice of the truncated approach yields lowest VaR estimates, which may be viewed as beneficial to the bank, whilst the “naive” and shifted approaches lead to higher estimates of VaR. As for the choice of severity distributions, besides the Lomax distribution (which is heavy tailed and hence appropriate in operational risk modeling), we intentionally select the light-tailed exponential distribution to show what happens to VaR estimates when incorrect assumptions are made. Moreover, our step-by-step analysis not only shows “what happens” to VaR estimates, but it helps understand the questions of “how” and “why” it happens. Additionally, perhaps surprisingly, our numerical illustrations reveal why the shifted approach is still popular. That is because it is flexible enough to pass standard model validation tests and thus cannot be discarded from practical use based on such tools alone. In summary, this paper contributes to the existing literature by performing an extensive investigation of the impact that model uncertainty has on the VaR estimators, justifies the soundness of the regulatory recommendation (i.e., use the truncated approach), and paves the way for a number of research problems in this important area.
It is worth noting here that the model uncertainty considered in this paper is an epistemic one, not a random uncertainty. It can be reduced—but not completely eliminated—by employing sound model validation tools, and in some cases (e.g., when the shifted approach is used) may require out-of-model knowledge. In a more general context, model uncertainty is an important topic within the model risk governance framework as regulated by the OCC and the Federal Reserve Bank in the U.S. and the Basel Committee on Banking Supervision for the G20 countries (e.g.,
Basel Coordination Committee 2014;
Office of the Comptroller of the Currency 2011).
The rest of the paper is structured as follows. In
Section 2, we describe how model uncertainty emerges and study its effects on VaR estimates. This is done by employing theoretical results (presented in
Appendix A) and via Monte Carlo simulations. Next, in
Section 3, these explorations are further illustrated using a real data set for legal losses in a business unit. Finally, concluding remarks are offered in
Section 4. Additionally, in
Appendix A we provide some technical tools that are essential for analytic treatment of the problem. In particular, key probabilistic features of the generalized Pareto distribution are presented, and several asymptotic theorems of mathematical statistics are specified.
3. Real-Data Example
In this section we illustrate how all the modeling approaches considered in this paper (empirical and three parametric) perform on real data. We go step-by-step through the entire modeling process, starting with model fitting and validation, continuing with VaR estimation, and completing the example with model-based predictions for quantities below the data collection threshold. Note that for the parametric approaches we employ both exponential and Lomax models, although exponential is clearly not a viable model for operational risk data (because its tail is too light for such data). However, the exponential distribution is a model for which all relevant formulas are explicit and can be easily verified by the reader. Moreover, the data analysis exercise also serves as an example of how to identify inappropriate models (e.g., exponential), and if the model validation step is ignored, to illustrate how wrong the predictions based on such models can be.
3.1. Data
We will use the data set from
Cruz (
2002, p. 57), which has 75 observations and represents the cost of legal events for a business unit. The cost is measured in U.S. dollars. To illustrate the impact of data collection threshold on the selected models, we split the data set into two parts: losses that are
at least $195,000, which will be treated as observed and used for model building and VaR estimation, and losses that are
below $195,000, which will be used at the end of the exercise to assess the quality of model-based predictions. This data-splitting scenario implies that there are 54 observed losses. A quick exploratory analysis of the observed data shows that it is right-skewed and potentially heavy-tailed, with the first quartile 248,342, median 355,000, and the third quartile 630,200; its mean is 546,021, standard deviation 602,912, and skewness 3.8.
3.2. Model Fitting
We fit exponential and Lomax models to the observed data and use three parametric approaches: truncated, naive, and shifted. The truncation threshold is
. For the exponential model, MLE formulas for
are available in
Section 2.3.1. For the Lomax distribution, we perform numerical maximization of the log-likelihoods (
3)–(
5) to compute parameter values. For the data set under consideration, the resulting MLE values are reported in
Table 4. Additionally, the corresponding estimates for parameter variances and covariances were computed using Theorem A3.
3.3. Model Validation
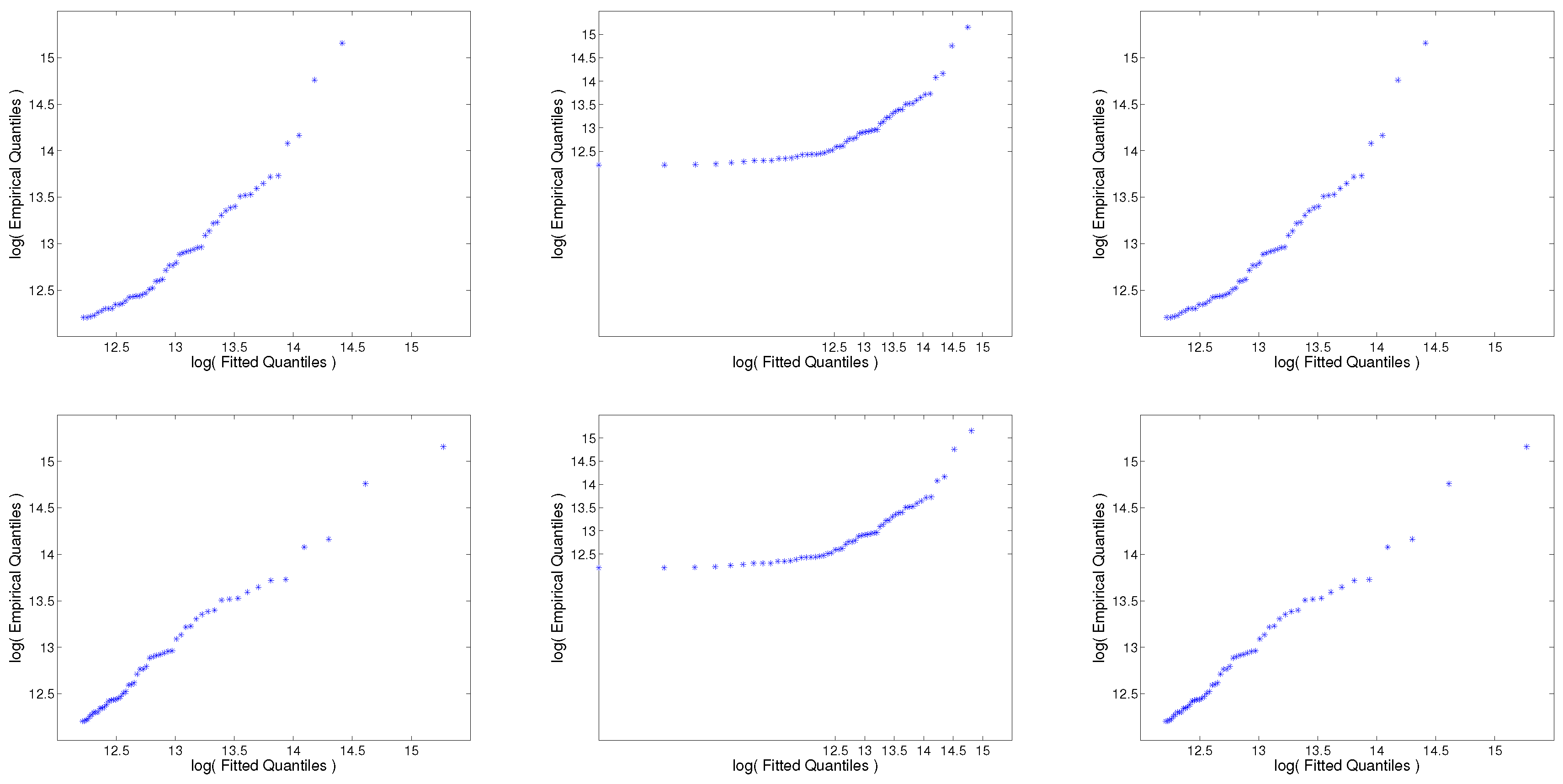
To validate the fitted models, we employ quantile–quantile plots (QQ plots) and two goodness-of-fit statistics: Kolmogorov–Smirnov (KS) and Anderson–Darling (AD).
In
Figure 2, we present plots of the fitted-versus-observed quantiles for the six models of
Section 3.2. In order to avoid visual distortions due to large spacings between the most extreme observations, both axes in all the plots are measured on a logarithmic scale. That is, the points plotted in those graphs are the following pairs:
where
is the estimated parametric qf,
denote the ordered losses, and
is the quantile level. For the truncated approach,
; for the naive approach,
; for the shifted approach,
. Additionally, the corresponding cdf and qf functions were evaluated using the MLE values from
Table 4.
We can see from
Figure 2 that Lomax models show a better overall fit than exponential models, and especially in the extreme right tail. That is, most of the points in those plots do not deviate from the
line. The naive approach seems off, but the truncated and shifted approaches do a reasonably good job for both distributions, with Lomax models exhibiting slightly better fits.
The KS and AD goodness-of-fit statistics measure, respectively, the maximum absolute distance and the cumulative weighted quadratic distance (with more weight on the tails) between the empirical cdf
and the parametrically estimated cdf
. Their respective computational formulas are given by
and
where
denote the ordered claim severities. Additionally,
for the truncated approach,
for the naive approach, and
for the shifted approach. Note that
and the corresponding cdf’s were evaluated using the MLE values from
Table 4. The
p-values of the KS and AD tests were computed using parametric bootstrap with 10,000 simulation runs. For a brief description of the parametric bootstrap procedure, see, for example,
Klugman, Panjer, and Willmot (
2012, sct. 20.4.5).
As the results of
Table 5 suggest, both naive models are strongly rejected by the KS and AD tests, which is consistent with the conclusions based on QQ-plots. The truncated and shifted exponential models are also rejected, which strengthens our “weak” decisions based on QQ-plots. Unfortunately, for this data set, neither KS nor the AD test can help us with differentiating between the truncated and shifted Lomax models, as both of them fit the data very well.
3.4. VaR Estimates
Having fitted and validated the models, we now compute several point and interval estimates of
for all six models. The purpose of calculating
estimates for all—“good” and “bad”—models is to see the impact that model fit (which is driven by the initial assumptions) has on the capital estimates. The results are summarized in
Table 6, where empirical estimates of
are also reported for completeness. The confidence intervals for the exponential models are derived using Theorem A3 and based on the variance estimates from
Table 4. For the Lomax models, the confidence intervals are obtained using parametric bootstrap with 10,000 simulation runs.
We see from the table that the estimates based on the naive approach significantly differ from the rest. The difference between truncated and shifted estimates at the exponential model is . For the Lomax model, these two approaches—which exhibited nearly perfect fits to data—produce substantially different estimates, especially at the very extreme tail. Finally, in view of such large differences between parametric estimates (which resulted from models with excellent fits), the empirical estimates do not seem completely off.
3.5. Model Predictions
As the final test of our models, we check their out-of-sample predictive power.
Table 7 provides the “unobserved” legal losses, which will be used to verify how accurate our model-based predictions are. To start with, we note that the empirical and shifted models are not able to produce meaningful predictions because they assume that such data were impossible to occur (i.e.,
for these two approaches). So, we now work only with the truncated and naive models.
Firstly, we report the estimated probabilities of losses below the data collection threshold, . For the exponential models, it is 0.300 (naive) and 0.426 (truncated). For the Lomax models, it is 0.310 (naive) and 0.794 (truncated). Secondly, using these probabilities we can estimate the total, observed, and unobserved number of losses. For the exponential models, (naive) and (truncated). For the Lomax models, (naive) and (truncated). Note how different from the rest the estimate of the truncated Lomax model is. (Recall that this model exhibited the best statistical fit for the observed data).
For predictions that are verifiable, in
Table 8 we report model-based estimates of the number of losses, the average loss, and the total loss in the interval [150,000;175,000]. We also provide the corresponding 95% confidence intervals for the predictions. The intervals were constructed by using the variance and covariance estimates of
Table 4 in conjunction with Theorem A3. Notice that by using the data points from
Table 7 it is straightforward to verify that the actual number of losses is eight, the average loss is 156,627, and the total loss is 1,253,017. We see from
Table 8 that, with the exception of the average loss measure, there are large disparities in predictions between different approaches. This mostly has to do with the quality of model fit for the given data set, which is good for the truncated Lomax model but bad for the other models and/or approaches. As a consequence, 95% confidence intervals based on the truncated Lomax model cover the actual values of two important measures—number of losses (eight) and total loss (1,253,017)—but those based on the truncated exponential model do not. Moreover, both naive models fit the data poorly and produce point and interval predictions that are even further from their respective targets than those of the truncated exponential model. In addition, if one chose to ignore the model validation step and proceeded directly to predictions based on the naive models, they would be (falsely) reassured by the consistency of such predictions (number of losses: 2.6 and 2.7; total loss: 426,197 and 441,155).
4. Concluding Remarks
In this paper, we have studied the problem of model uncertainty in operational risk modeling, which arises due to different (seemingly plausible) model assumptions. We have focused on the statistical aspects of the problem by utilizing asymptotic theorems of mathematical statistics, Monte Carlo simulations, and real-data examples. Similar to other authors who have studied some aspects of this topic before, we conclude that:
The naive and empirical approaches are inappropriate for determining VaR estimates.
The shifted approach—although fundamentally flawed (simply because it assumes that operational losses below the data collection threshold are impossible)—has the flexibility to adapt to data well and successfully pass standard model validation tests.
The truncated approach is theoretically sound when appropriate fits data well, and (in our examples) produces lower VaR-based capital estimates than those of the shifted approach.
The research presented in this paper invites follow-up studies in several directions. For example, as the first and most obvious direction, one may choose to explore these issues for other—perhaps more popular in practice—distributions such as lognormal or loggamma. If the chosen model lends itself to analytic investigations, then our Example 1 (in
Section 2.3) is a blueprint for analysis. Otherwise, one may follow our Example 2 for a simulations-based approach. Second, VaR can be replaced by a different risk measure. For instance, the Expected Shortfall (also known as Tail-VaR or Conditional Tail Expectation) has some theoretical advantages over VaR (e.g., it is a coherent risk measure), and is a recommended measure in the
Swiss Solvency Test. Third, due to the theoretical soundness of the truncated approach, one may try to develop model-selection strategies for truncated (but not necessarily nested) models. However, this line of work may be quite challenging due to the “flatness” of the truncated likelihoods—a phenomenon frequently encountered in practice (see
Cope 2011). The fourth venue of research that may also help with the latter problem is robust model fitting. There are several excellent contributions to this topic in the operational risk literature (e.g.,
Chau 2013;
Horbenko et al. 2011;
Opdyke and Cavallo 2012), but more work can be done.





{kind=link}
{kind=link}