1. Introduction
The purpose of the present paper is to describe how the cost-of-capital approach from
Engsner et al. (
2017), which builds on the approach to market-consistent liability valuation from
Möhr (
2011), may be implemented using non-life claims triangle data covering both premium and reserve risk. In
Engsner et al. (
2017), general formulas for cost-of-capital valuation of liability cash flows are provided. For this to become practically relevant in a non-life insurance context, we need to define cash flow dynamics that are consistent with those seen in actual non-life insurance applications.
The undoubtedly most common claims triangle reserving method used in practice is the (distribution-free) chain-ladder method defined in
Mack (
1993a). This is a pure reserving method, and there is from that perspective no need to define how the model is initiated, since reserving amounts to estimating outstanding costs for already incurred claims. This is in contrast to premium risk, where there is a need to describe how not yet incurred claims will generate future payments. Further, the pan-European insurance regulation Solvency II is constructed to measure, amongst other things, non-life insurance risk expressed in terms of premium and reserve risk. Concerning reserve risk, the Solvency II regulation’s so-called standard formula is based on a one-year re-reserving risk based on a time series version of the classical chain-ladder method; see
Merz and Wüthrich (
2008). Regarding premium risk, there is no single standard method; for more on this, see, e.g.,
Gisler (
2009);
Ohlsson and Lauzeningks (
2009). One can here note that these methods do not necessarily have a one-to-one correspondence with the assumptions underlying, e.g., the standard chain-ladder method. We can also remark that there are connections between the consistent multi-period valuation approach from
Engsner et al. (
2017) and the simplified inconsistent multi-period valuation approach provided by EIOPA; see the definition of the so-called “risk margin” in (
European Commission 2015, Article 37).
Moreover, the valuation formulas from
Engsner et al. (
2017) are based on the payment process dynamics and the resulting capital costs from repeated capital requirements. In practice, we need to define a specific model, estimate parameters and assess both process and estimation uncertainty. Further, in
Engsner et al. (
2017), it is shown that the general cost-of-capital valuation formulas become analytically tractable when the underlying class of models describing the payment dynamics are Gaussian. Due to this, we give two examples of Gaussian time series payment process models. These claims’ payment generating processes will, in turn, induce natural predictors for outstanding costs stemming from incurred, as well as not incurred claims. The Gaussian models introduced in
Section 4 are merely two examples of reasonable models, which in many aspects are similar to the standard chain-ladder method, but which allow for premium risk calculations. For more on time series versions of the chain-ladder method, see, e.g.,
Buchwalder et al. (
2006);
Kremer (
1984) and (
Wüthrich and Merz 2008, chp. 3) and the references therein. Furthermore, for the models introduced in
Section 4, we derive parameter estimators using conditional weighted least squares and show that the natural predictors for outstanding payments using plug-in estimation are unbiased. Since the valuation formulas are non-linear functions of the model parameters, plug-in estimators of liability values will be biased. As a consequence of this, we derive an approximate plug-in bias correction for the valuation formulas, and based on that, we approximate the parameter uncertainty using a type of resampled pseudo estimator; see
Section 3. These pseudo estimators share many features with the approach to approximate prediction uncertainty in
Mack (
1993a) and
Buchwalder et al. (
2006). One can also note that the Gaussian payment processes introduced in
Section 4 will induce claims reserving methods. By using the idea of resampled pseudo estimators, we may calculate a type of mean squared error of prediction (MSEP) for the induced reserve estimators, which are consistent with the plug-in bias correction for the valuation formula. In fact, in
Lindholm et al. (
2017), it is shown that the idea of using resampled pseudo estimators may be used to retrieve the standard MSEP approximation for the chain-ladder method derived in
Mack (
1993a).
Examples of papers relating to risk-margin-like calculations, apart from the ones mentioned above, are
Salzmann and Wüthrich (
2010),
Wüthrich et al. (
2011) and
Ferriero (
2016). It is demonstrated in
Salzmann and Wüthrich (
2010) and commented on in
Wüthrich et al. (
2011) that a cost-of-capital approach to risk-margin calculations leads to evaluations of path-dependent multi-period risk measures that in most cases can neither analytically, nor numerically be calculated. Various proxies are presented in
Salzmann and Wüthrich (
2010). In
Wüthrich et al. (
2011), an alternative, computationally more attractive risk margin is defined as the difference between a risk-adjusted reserve and a classical reserve and analyzed using probability-distortion techniques and a Bayesian chain-ladder method. In
Ferriero (
2016), reserve losses are modeled directly using a stochastic process designed to replicate actuary behavior in repeated re-estimation of reserves. An approximation is made in
Ferriero (
2016) that allows the risk margin to be approximated without having to solve a backward recursion. In the current paper, we define the risk margin using the multi-period cost-of-capital approach presented in
Engsner et al. (
2017), in line with how it is defined in
Möhr (
2011) and
Salzmann and Wüthrich (
2010). However, by assuming that aggregate paid amounts for different accident and development periods have Gaussian joint distributions, we are in the exceptional situation where the risk margin can be calculated analytically as a solution to a backward recursion. As with any model assumptions, the extent to which specific claims triangle data are consistent with Gaussian model assumptions should be assessed. See
Section 5 for further details. In situations where it is likely that aggregate paid amounts are essentially due to a few large claims, Gaussian model assumptions are not suitable.
To conclude, we provide a detailed procedure for how to carry out a consistent multi-period cost-of-capital liability valuation based on claims triangles. This is done for two Gaussian cash flow models including parameter estimators, assessment of parameter uncertainty and a full description of the underlying claims reserving method, which is implied by the cash flow model.
The paper is organized as follows: general results on cost-of-capital valuation for Gaussian cash flows are given in
Section 2, which is followed by
Section 3, where necessary results on estimation and methods to deal with parameter uncertainty are described. In
Section 4, two specific Gaussian cash flow models are introduced and analyzed in detail, and we conclude with a short section on model evaluation (see
Section 5), together with numerical illustrations (see
Section 6). In order to make the exposition more comprehensive, all proofs are collected in the
Appendix.
2. Valuation of Non-Life Insurance Cash Flows
In order to present our approach to the valuation of non-life insurance liabilities, we first need to define the liability cash flows as stochastic processes of a certain kind. We take a rolling one-year risk-free bond as the basis for the numéraire process with value one at the current time. In what follows, unless stated otherwise, all future cash flows are discounted by this numéraire or, equivalently, denoted in units of the numéraire process. Similarly, using historic one-year discount factors from data on one-year risk-free bonds, we may adjust historic cash flow data to be expressed in units of the numéraire process. This data adjustment implies that predictions based on historic payment data are predictions adjusted for the time-value of money. Other choices of traded numéraire processes are possible.
Consider
K lines of business providing one-year insurance products: the buyer of the insurance product is not entitled to economic compensation for accidents later than twelve months from the time the product is purchased. For
, let
denote the incremental claims payment during development year
, and let
denote the cumulative payments during development years
from accidents during accident year
, where
. For
, let:
denote the data from business line
k that are known at time
t. Calendar year
corresponds to the current time. Such a dataset is commonly referred to as a claims triangle, although claims trapezium may be more appropriate. Notice that accident years
are fully developed. Notice also that accidents during accident year
have not yet occurred. Including accident year
in the setup allows for so-called premium risk. Omitting accident year
implies that only so-called reserve risk can be studied in the setup. Let:
where we set:
The overall aim is to assign a value to the future liability cash flow from both active contracts (non-incurred claims) and claims from contracts that may still generate claims (incurred, but not reported and reported, but not settled claims). Set
and:
Notice that
corresponds to non-incurred claims from still active contracts. Further, note that
corresponds to the payments during a specific year for all accident years simultaneously, i.e.,
corresponds to a diagonal in an incremental claims payment triangle. Furthermore, set:
For each k, if accident year is omitted, then is the classical claims reserve. If accident year is included, then the setting allows for analysis of both so-called reserve risk and premium risk.
Let
and
denote the column vectors with components
and
, respectively. The value of the liability cash flow
will be defined as the value of a static replicating portfolio and the value of a position in the numéraire (one-year bond) needed to handle the residual liability cash flow from imperfect replication by the static replicating portfolio. In general, the choice of replicating portfolio depends on whether the liability cash flow depends on values or cash flows from traded financial assets. For the liability cash flows considered here, we assume that there are no clear dependencies on financial asset values. We choose the replicating portfolio as the one generating the deterministic cash flow
. This cash flow is obtained by, for each
, buying
units of the numéraire (one-year bonds that are rolled forward) at Time 0 and then selling them at time
t. The market price of the static replicating portfolio is:
Let be the residual cash flow from imperfect replication. Given a risk-based regulatory framework, such as the one currently in place, the residual cash flow X will give rise to capital requirements. From the costs associated with meeting these capital requirements, a value at Time 0 will be assigned to X. The basis for determining is to consider a hypothetical transfer of the liability cash flow and the replicating portfolio to a separate entity, a so-called reference undertaking, whose sole purpose is the handle the runoff of the liability cash flow. The procedure for determining is as follows.
Let be the value of the residual cash flow from time to time T as seen from Time 0. In particular, since there is no cash flow beyond time T. At time t, the reference undertaking is required to hold the solvency capital , where is the conditional monetary risk measure value-at-risk or expected shortfall , conditional on . Conditioning on means that we only consider information from payment data. The reason for this choice is that we aim for a non-life valuation method that can be easily applied by anyone having access to yearly aggregated claims payment triangle data.
At time
t, the reference undertaking has capital
that equals the value of the residual cash flow
and asks a capital provider, with limited liability, to provide the capital
ensuring solvency at time
t. Upon providing the capital
at time
t, the capital provider receives any surplus
at time
. However, capital is only provided if the expected return is good enough, if:
The value is defined as the value for which capital is provided, but such that capital providers do not obtain better-than-required expected returns. That is, the inequality above is replaced by an equality. In general, is -measurable. Here, in order to derive closed-form valuation formulas, we assume that is -measurable. That is, we assume that future requirements on the expected return on capital from capital providers are known at present time.
From Propositions 1 and 4 and Remark 5 in
Engsner et al. (
2017), it follows that:
where ○ denotes composition and:
With
denoting the space of
-measurable random variables
Y with
,
is a mapping satisfying:
properties that are inherited from the risk measure
.
Definition 1. The value of the non-life insurance liability cash flow is:where is given by Equations (
2)
and (
3).
Notice that
and
are conceptually-consistent alternatives to the ill-defined Solvency II quantities risk margin (see (
European Commission 2015, Article 37)) and technical provisions, respectively. Thus,
corresponds to the Solvency II best estimate (BE). We want to emphasize that the Solvency II risk margin is not properly defined mathematically. For further details, see, e.g., p. 316 in
Möhr (
2011).
Notice that the definition of the value of the liability cash flow is intimately connected to the particular choice of static replicating portfolio considered here. The procedure for determining is independent of the choice of replicating portfolio, although the value of depends on the replicating portfolio via the residual cash flow X.
In general, no explicit expression can be derived for
. However, one important exception is when all cash flows are jointly Gaussian and the cost-of-capital rates
are
-measurable.
Proposition 1. Assume that the joint distribution of the random variables:is Gaussian and, for all t,
is
-
measurable. Then:where:with:where and are defined in Remark 1. Notice that Equation (
5) makes sense due to the Gaussian model assumption:
is a constant and therefore measurable with respect to the trivial
-field, which is a subset of
.
Remark 1. The choices and correspond to choices made in the Solvency II regulation, whereas correspond to the Swiss Solvency Test. For an -
measurable (discounted) value Z, the conditional monetary risk measures and are defined in terms of the conditional distribution function and quantile function as: Remark 2. From the variance decomposition formula,With and since is independent of under the Gaussian model assumption,Hence, Equation (
4)
can be expressed as: If we have a Gaussian model for the cash flow
, then its value
is determined by Equation (
5) and can be estimated based on suitable estimates of the mean vector and covariance matrix of
.
However, the typical situations for the valuation of an aggregate cash flow are models, or at least reserving methods, for the cash flows
,
. The dependence between the cash flows
for different business lines is not well-understood, and independence is often assumed.
Proposition 2. Suppose the assumptions of Proposition 1 hold and, for ,
that .
Then:where:In particular, if for all t, then .
The proof of Proposition 2 is given in the
Appendix.
The natural application of Proposition 2 is conservative estimation of the value
of the residual liability cash flow in the case of only partial information. Conservative estimates of the conditional variances
may be given by the estimates of conditional mean-squared errors of predictions (MSEPs):
Estimation of MSEP is discussed in detail in later sections. The correlations cannot be reliably estimated based on claims triangle data. Proposition 2 provides a flexible tool for assessing the effect of dependence between claims triangles in terms of exogenously-given correlations in line with standard formulas found in regulatory frameworks.
5. Some Comments on Model Validation: In-Sample and Out-Of-Sample Performance
The focus of the present paper is to describe how to carry out a fully-data-driven cost-of-capital valuation based on claims triangles. Above, we have introduced two Gaussian models for which explicit calculations are possible including estimation and treating parameter uncertainty. Due to that, we have introduced two different models with different (maximal) numbers of parameters; there is a need to assess both the in-sample and the out-of-sample performance of the models.
As commented upon above, both models may be treated as a series of Gaussian linear models. Thus, it is recommended to carry out standard statistical residual analysis and tests of model assumptions for linear models. A detailed description on how this analysis may be implemented for the chain-ladder method is described in
Mack (
1993b); see also (
Wüthrich and Merz 2008, chp. 11).
Further, regarding model selection, including significance tests for parameters, one can note that the two model classes are nested in the classical sense, which means that it is possible to carry out standard likelihood ratio tests (LRT), but other metrics such as AIC/BIC may be considered. Due to that, the models studied in the present paper are Gaussian, and there are no difficulties in determining (conditional) likelihoods. Given this, it is possible to analyze, e.g., LRT and AIC/BIC.
Moreover, since the models’ actual purpose is to be used for out-of-sample prediction, it is reasonable to try to assess the out-of-sample performance. A straight forward out-of-sample performance is to exclude one or two observed diagonals and analyze the corresponding out-of-sample prediction performance. In general, it often is not recommended to exclude more than one or two years of data due to the lack of representative yearly data.
6. Numerical Example
In this section, we illustrate the incremental model in Equation (
18) and the cumulative model in Equation (
20) and demonstrate the implementation of the results in this paper.
Recall from
Section 2 that the models and methods presented assume that historical data and future cash flows are adjusted for the time value of money. The aim of the numerical example in this section is simply to clarify and demonstrate the use of the framework presented earlier. In order to keep the numerical example brief and focus on methodological aspects, we ignore discounting and preprocessing of historical data here.
The data we use are the run-off triangle from Table 1 in
Mack (
1993a). In order to be able to use the unbiased estimators of the
, we remove the last two columns of this triangle. We could use maximum likelihood estimation or some form of extrapolation of the
, but the purpose here is not to compare methods for estimating the tail variances; we thus simply remove the last two columns. The data are fairly similar between accident years, and for illustrative purposes, it should suffice to set the weights equal to one for all accident years.
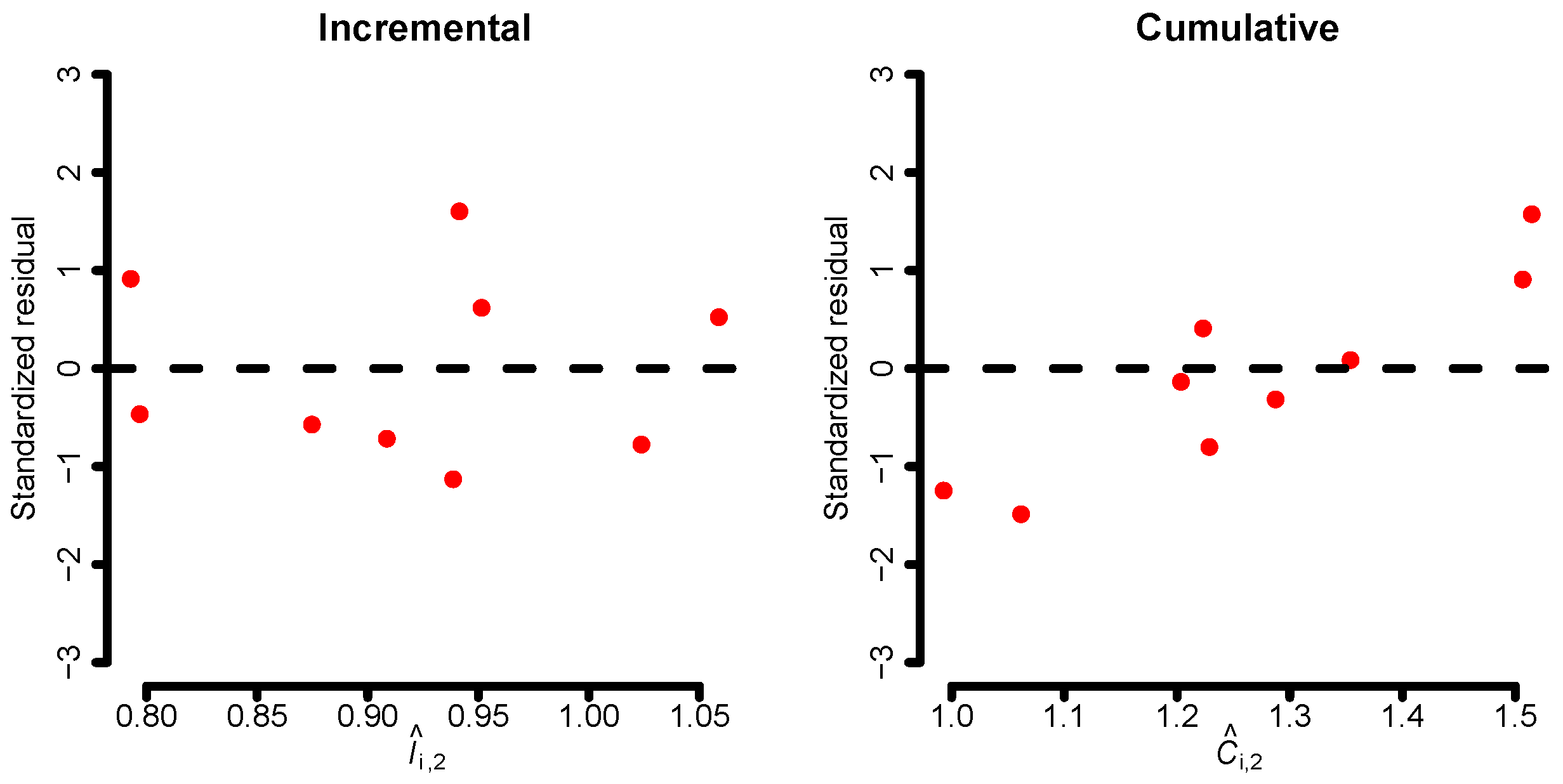
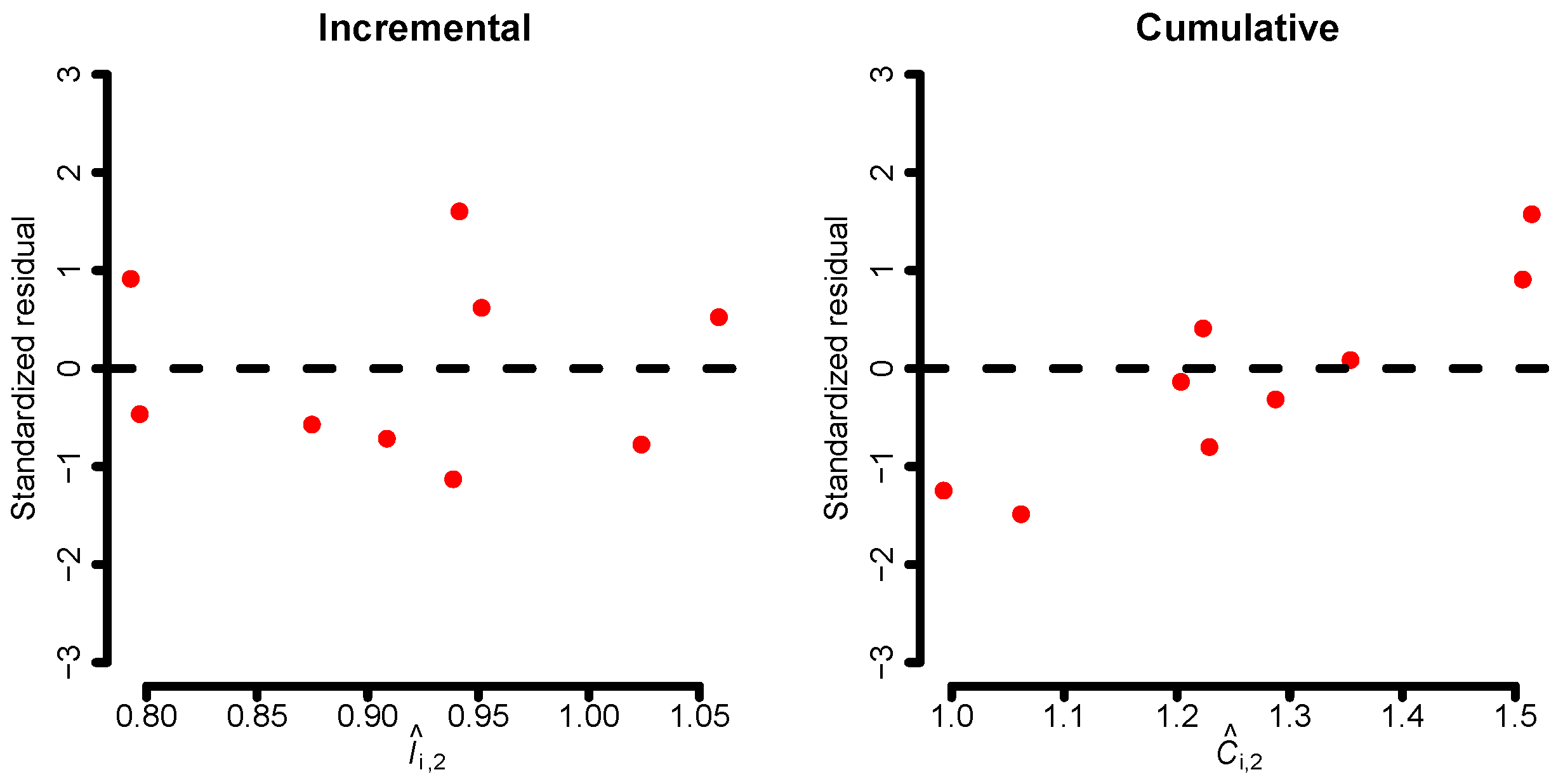
If we fit the incremental and cumulative models to the data, it is recommended to analyze standardized residuals and linearity for each development year and model. This is illustrated in
Figure 1, where the standardized residuals for the second development year are shown for both models. There, we see that the residuals of the cumulative model have a systematic pattern implying that the cumulative linear structure defined by the model in Equation (
20) does not capture the dynamics of the data well. This is an artifact of the lack of an intercept. However, the small sample size hinders us from making any definitive claims.
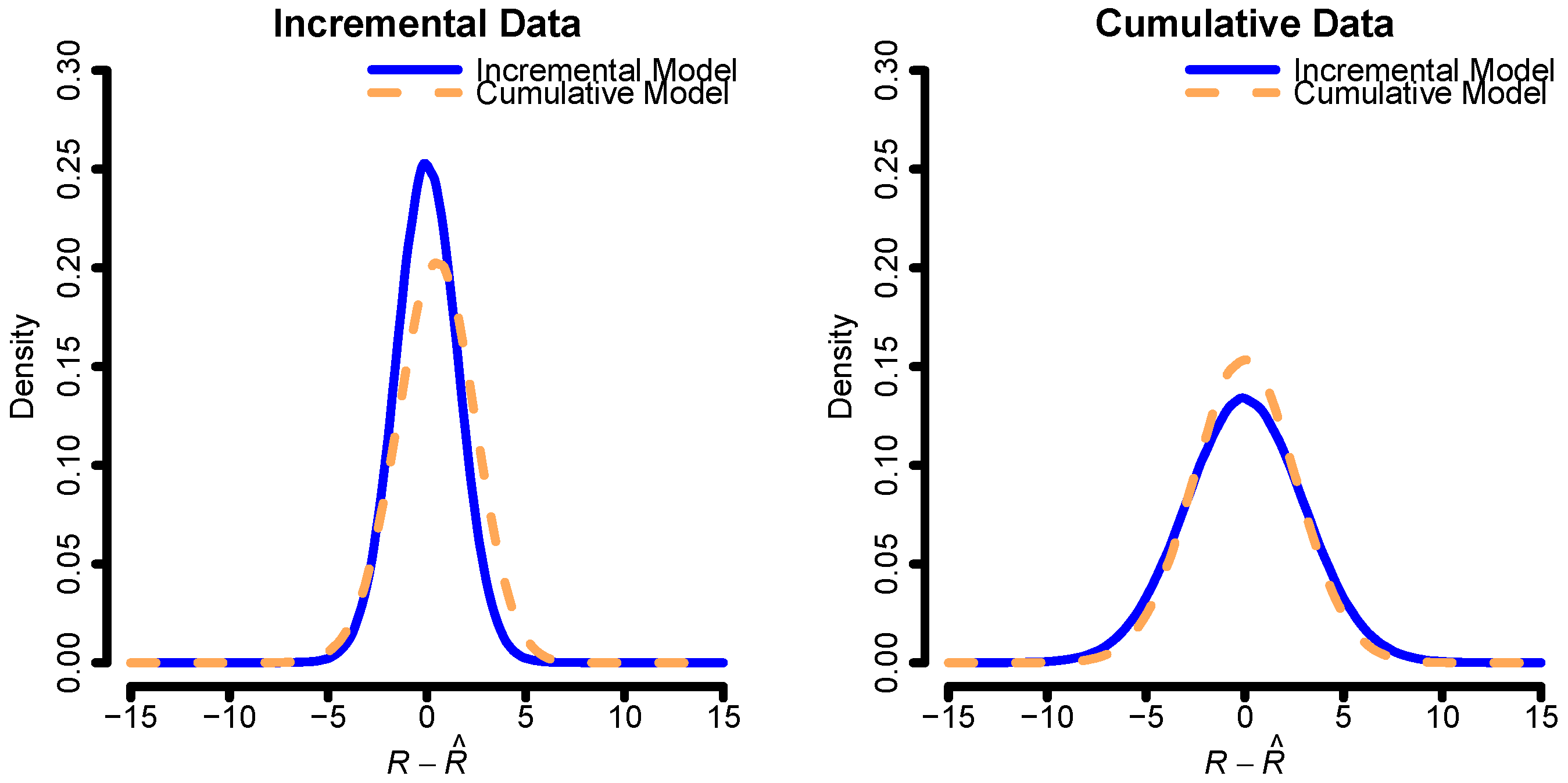
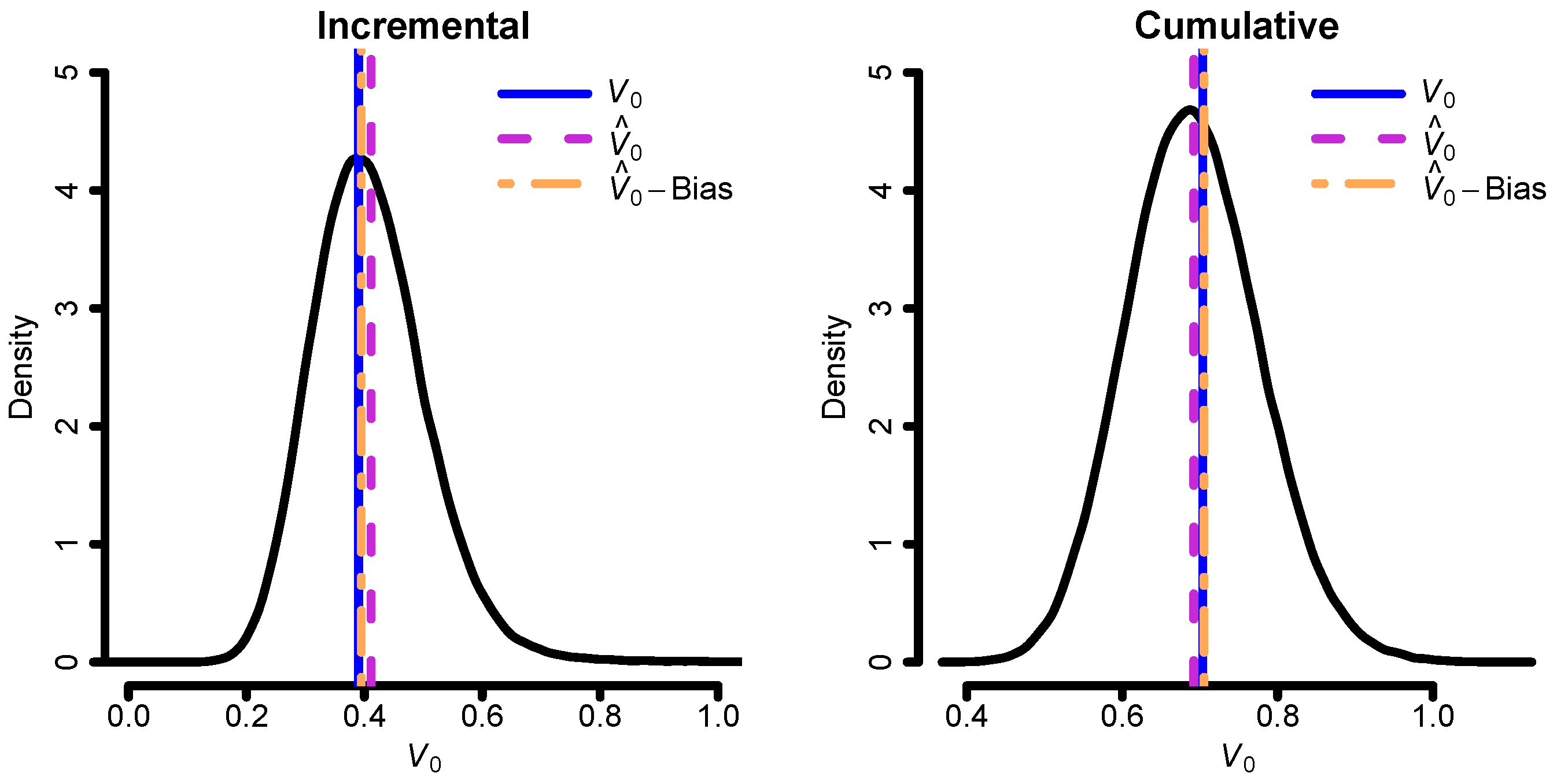
Before we proceed with calculating the cost-of-capital margin, etc., we make a brief assessment of the model performance given ideal circumstances. This is done by fitting the incremental and cumulative models to the data, considering these fits as the true models. Given the fitted parameters, we then simulate complete rectangles of data on which we re-fit the two models and plot
. The result of this can be seen in
Figure 2. Both models seem to be performing similarly regardless of which model is simulated.
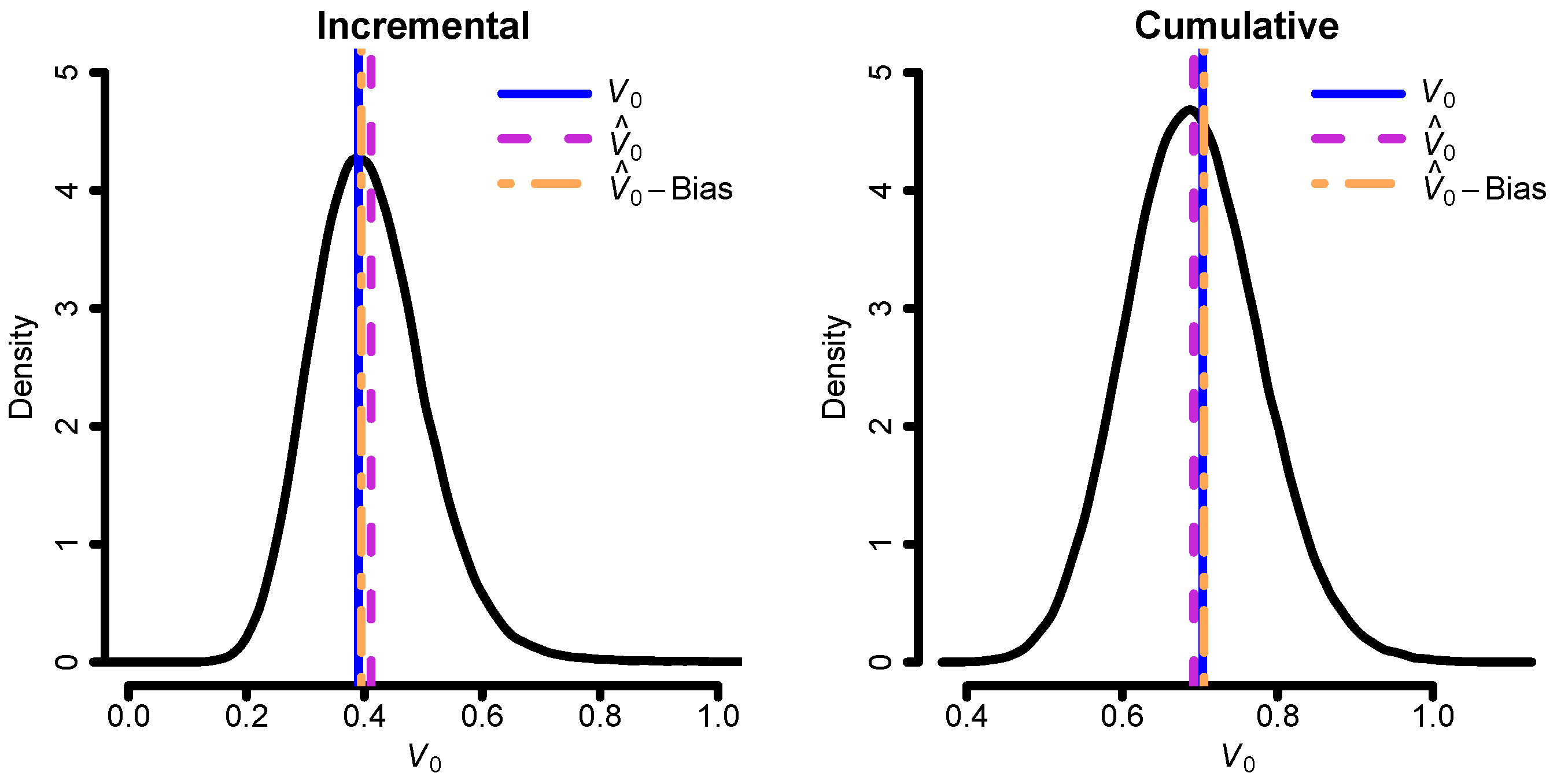
With the aim of illustrating the bias correction of the cost-of-capital margin, we next simulate new triangles from the “true” models and fit the correctly specified model to each. That is, the incremental model is fitted to data simulated from the incremental model, and the cumulative model is fitted to data simulated from the cumulative model. Then, we estimate the cost-of-capital margin
(see Equation (
5)) and its bias correction for each simulated triangle using the cost-of-capital rate
, which is in alignment with the current Solvency II directive. This can then be compared to the true cost-of-capital margin, which we assume known since we consider the models fitted to the original data to be the true models. The results can be seen in
Figure 3. The bias correction does seem to work quite well. It should be noted that the expectation part of the liability value
, i.e., the best estimate (BE), in the current example is much larger than the cost-of-capital margin. Thus, the bias correction will, in this situation, have a small impact on the estimated liability value; see
Table 1.
Proposition 2 provides an upper bound on
, denoted
; see Equation (
6). Moreover, as commented on in
Section 2, the cost-of-capital margin is related to the Solvency II Risk-Margin (RM). In (
EIOPA 2015, Guideline 61), the following approximation of RM is suggested:
where
in our setting. The Solvency II regulation provides one-year non-life insurance risk standard deviations in the range of 10–20%, depending on the line of business, which form the basis for the SCRcalculations. For the dataset from
Mack (
1993a), it is not clear from which line of business the data stem. Thus, we use:
Note however that the
calculations are based on the standard deviations of the one-year claims development results, which are roughly 4% and 8% of the BE for the incremental and cumulative models, respectively. These values should be compared to the ones above, which are in the range of 10–20%. Consequently, we expect
and RM to be considerably lower than the corresponding standard formula results. In
Table 1, we have summarized
,
and RM. Furthermore, the table also includes
, BE,
and RMSEP. Notice that when including premium risk, we cannot calculate the Solvency II RM without making further assumptions on premium volumes. For the part of
Table 1 with premium risk, we have set premium volumes consistent with weights equal to one. Furthermore, note that the cost-of-capital margin cannot be calculated for the chain-ladder model, nor can we calculate any quantity involving premium risk since there is no initiation in the first column. The RMSEP for the chain-ladder model is calculated according to
Mack (
1993a), and
is calculated according to
Merz and Wüthrich (
2008). Hence, it is possible to calculate RM for the chain-ladder model without premium risk. Turning to the results, from
Table 1, it is seen that
and
are of comparable order and that the corresponding RM values are lower than
and of a size comparable to
. The cumulative model has almost double the cost-of-capital margin compared to the incremental model. This can most likely be explained by the fact that the intercepts in the incremental model catch some of the variation that is put into the variance parameters of the cumulative model. This is also seen in
and RMSEP.
To conclude, we have analyzed the methods presented in the current paper based on data from
Mack (
1993a), which illustrate that the current valuation framework will result in comparable results with the formalism of the Solvency II directive and that the introduced models seem appropriate.




{kind=link}
{kind=link}
{kind=link}