
Stress Testing German Industry Sectors: Results from a Vine Copula Based Quantile Regression

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Motivation
2. A Short Review on D-Vines and D-Vine Copula Based Quantile Regression
3. Data Description and Empirical Results
3.1. Original Data Set
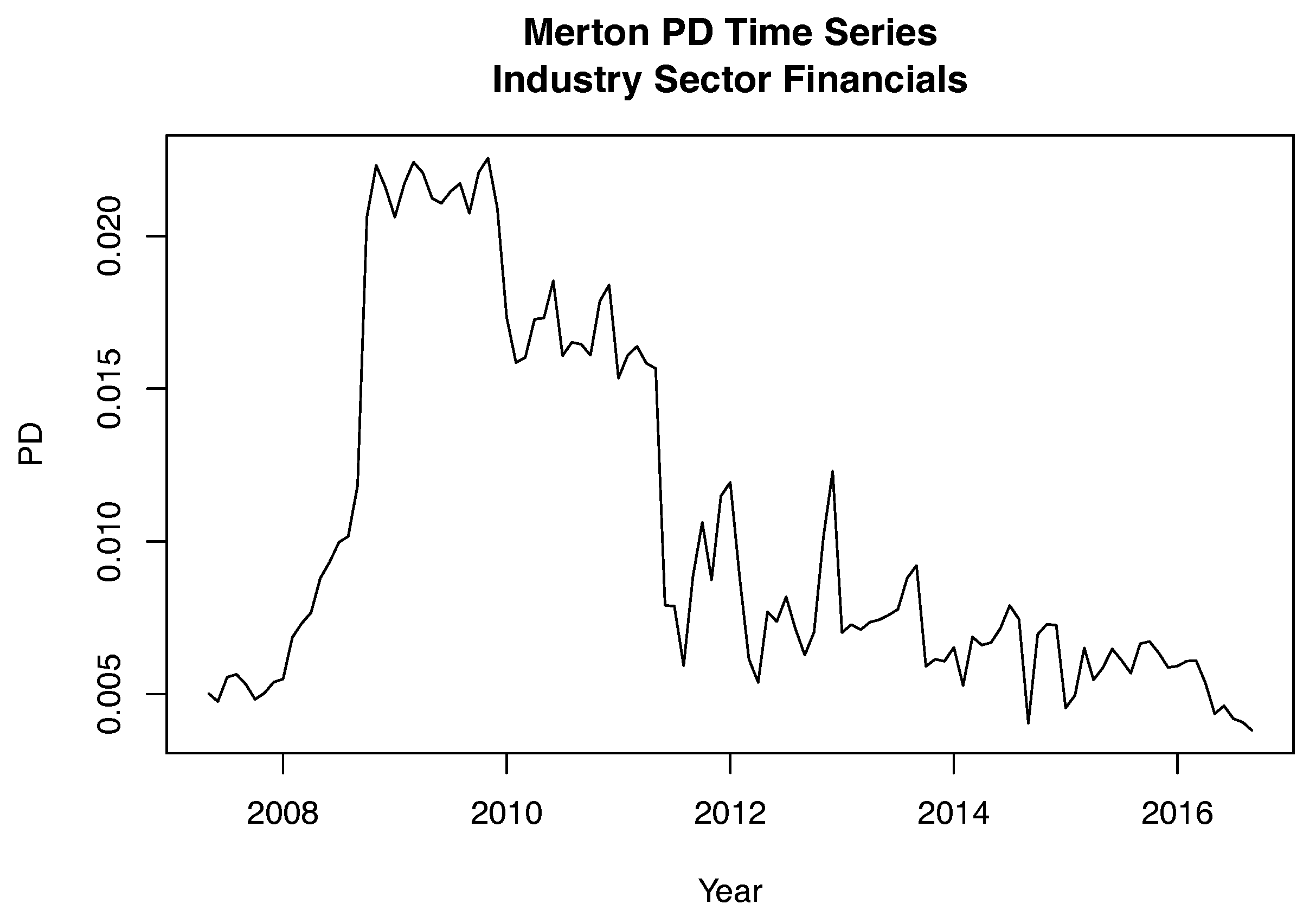
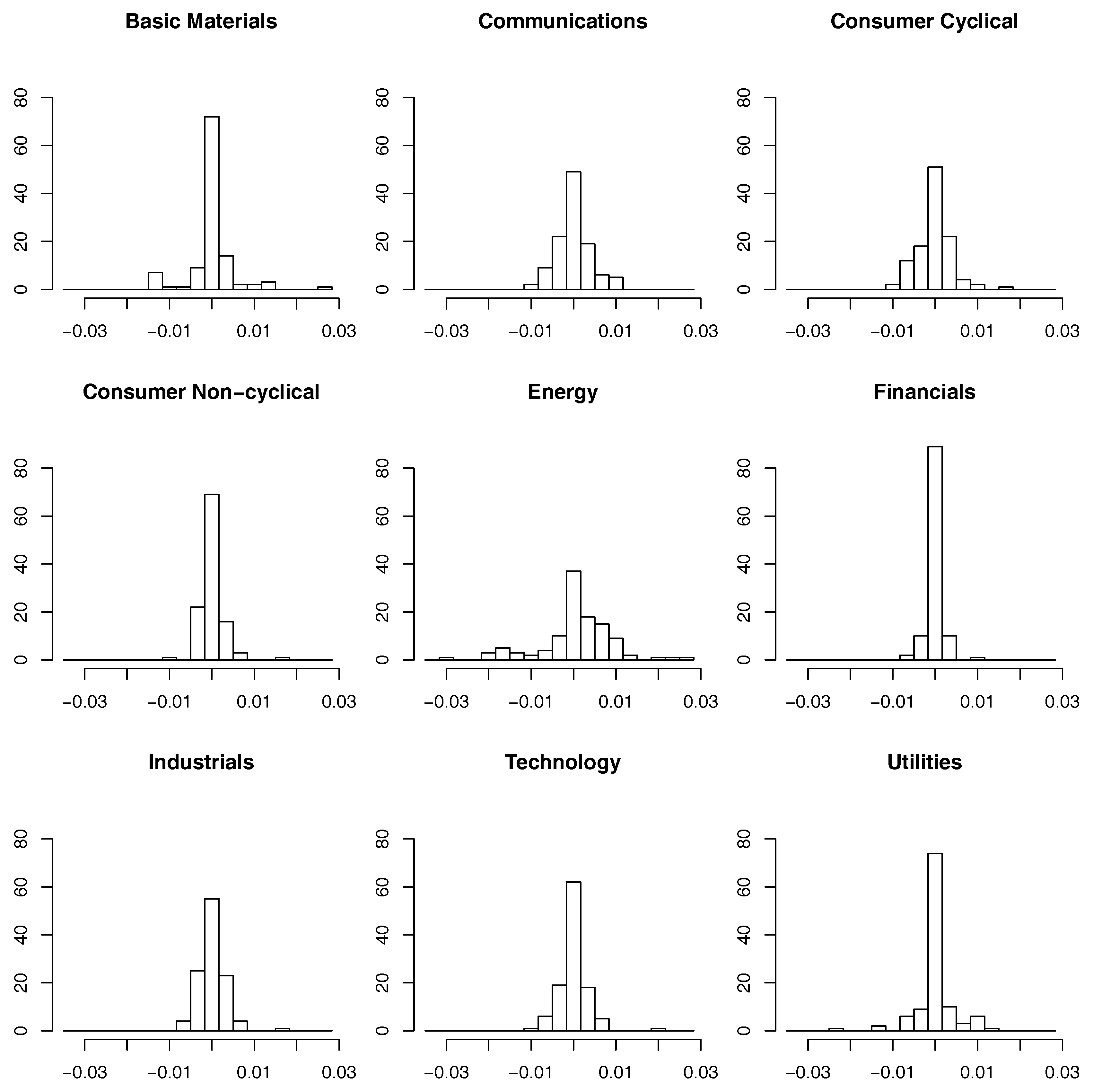
3.2. Time Dependencies and Transformation to Copula Scale
3.3. Selected Results of the D-Vine Copula Based Quantile Regression
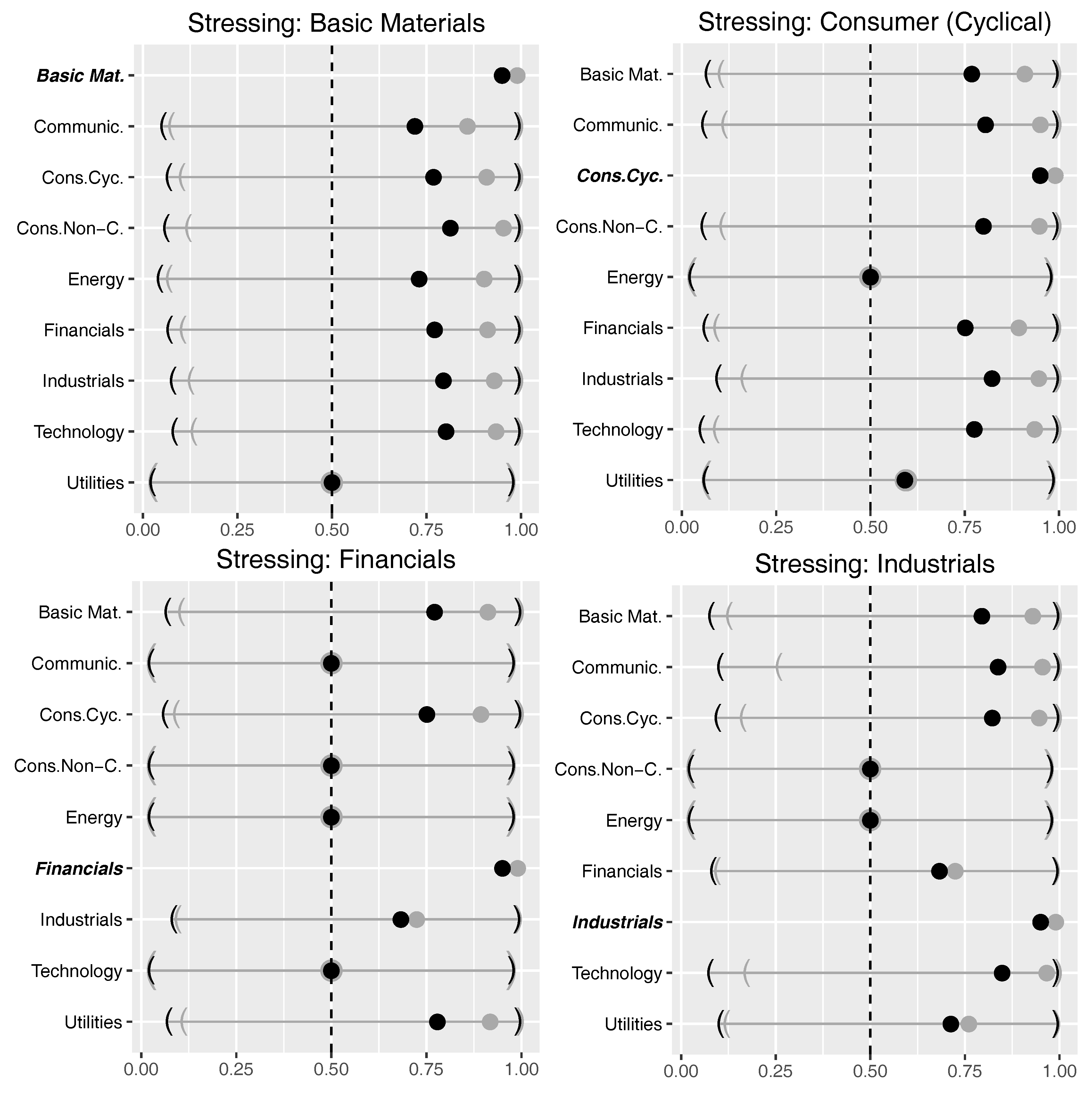
3.3.1. The Stress Scenario
3.3.2. Results for Stressing at 95% and 99% on Aggregated Data
3.3.3. Selected Scenarios on Detailed Level
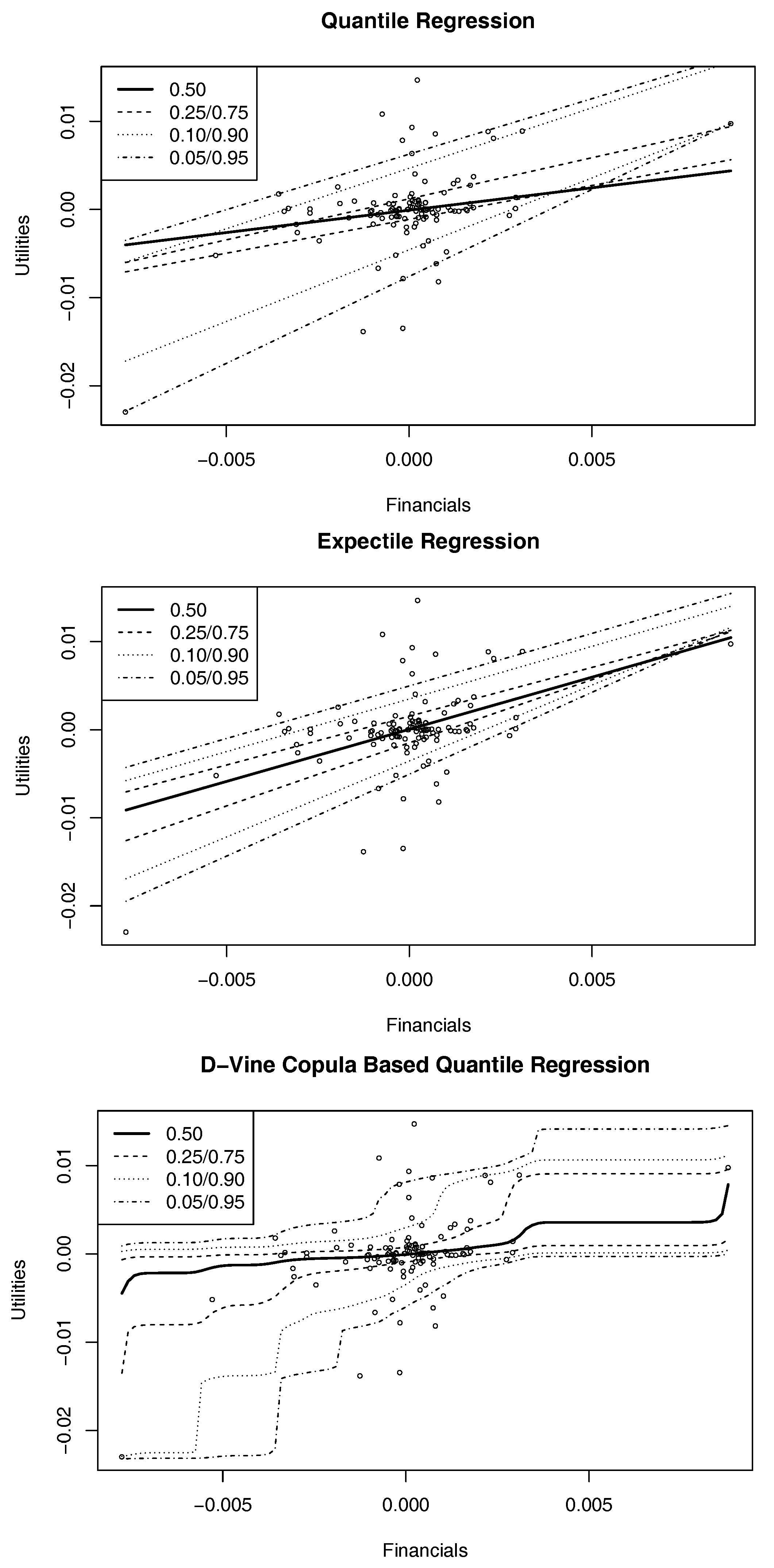
3.4. Results from Alternative Approaches
4. Summary and Outlook
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Aas, Kjersti, Claudia Czado, Arnoldo Frigessi, and Henrik Bakken. 2009. Pair-copula constructions of multiple dependence. Insurance, Mathematics and Economics 44: 182–98. [Google Scholar]
- Bedford, Tim, and Roger M. Cooke. 2002. Vines: A new graphical model for dependent random variables. Annals of Statistics 30: 1031–68. [Google Scholar] [CrossRef]
- Bernard, Carole, and Claudia Czado. 2015. Conditional quantiles and tail dependence. Journal of Multivariate Analysis 138: 104–26. [Google Scholar] [CrossRef]
- Bondell, Howard D., Brian J. Reich, and Huixia Wang. 2010. Noncrossing quantile regression curve estimation. Biometrika 97: 825–38. [Google Scholar] [CrossRef] [PubMed]
- Chernozhukov, Victor. 2005. Extremal quantile regression. Annals of Statistics 33: 806–39. [Google Scholar] [CrossRef]
- Chernozhukov, Victor, Iván Fernández-Val, and Tetsuya Kaji. 2017. Extremal quantile regression: An overview. In Handbook of Quantile Regression. Edited by Victor Chernozhukov, Roger Koenker, Xuming He and Limin Peng. London: Chapman & Hall/CRC. [Google Scholar]
- Covas, Francisco B., Ben Rump, and Egon Zakrajšek. 2014. Stress-testing US bank holding companies: A dynamic panel quantile regression approach. International Journal of Forecasting 30: 691–713. [Google Scholar] [CrossRef]
- Dette, Holger, and Stanislav Volgushev. 2008. Non-crossing non-parametric estimates of quantile curves. Journal of the Royal Statistical Society: Series B 70: 609–27. [Google Scholar]
- Fischer, Matthias, Christian Köck, Stephan Schlüter, and Florian Weigert. 2009. An empirical analysis of multivariate copula models. Quantitative Finance 9: 839–54. [Google Scholar] [CrossRef]
- Frahm, Gabriel, Markus Junker, and Alexander Szimayer. 2003. Elliptical copulas: Applicability and limitations. Statistics & Probability Letters 63: 275–86. [Google Scholar]
- He, Xuming. 1997. Quantile curves without crossing. The American Statistician 51: 186–92. [Google Scholar]
- Hobæk Haff, Ingrid, Kjersti Aas, and Arnonldo Frigessi. 2010. On the simplified pair-copula construction—Simply useful or too simplistic? Journal of Multivariate Analysis 101: 1296–310. [Google Scholar] [CrossRef]
- Joe, Harry. 1997. Multivariate Models and Multivariate Dependence Concepts. Boca Raton: CRC Press. [Google Scholar]
- Killiches, Matthias, Daniel Kraus, and Claudia Czado. 2017. Examination and visualisation of the simplifying assumption for vine copulas in three dimensions. Australian & New Zealand Journal of Statistics 59: 95–117. [Google Scholar]
- Koenker, Roger. 2006. Quantile regresssion. Encyclopedia of Environmetrics. [Google Scholar] [CrossRef]
- Koenker, Roger, and Zhijie Xiao. 2002. Inference on the quantile regression process. Econometrica 70: 1583–612. [Google Scholar] [CrossRef]
- Kraus, Daniel, and Claudia Czado. 2017a. D-vine copula based quantile regression. Computational Statistics and Data Analysis 110C: 1–18. [Google Scholar]
- Kraus, Daniel, and Claudia Czado. 2017b. Growing simplified vine copula trees: Improving Dißmann’s algorithm. arXiv, arXiv:arXiv:1703.05203. [Google Scholar]
- McNeil, Alexander J., and Johanna Nešlehová. 2009. Multivariate archimedean copulas, d-monotone functions and l-norm symmetric distributions. The Annals of Statistics 37: 3059–97. [Google Scholar] [CrossRef]
- Merton, Robert C. 1974. On the pricing of corporate debt: The risk structure of interest rates. The Journal of Finance 29: 449–70. [Google Scholar]
- Nelsen, Roger B. 2006. An Introduction to Copulas, 2nd ed. New York: Springer Science + Business Media. [Google Scholar]
- Ong, Ms Li L. 2014. A Guide to IMF Stress Testing: Methods and Models. Washington: International Monetary Fund. [Google Scholar]
- Schechtman, Ricardo, and Wagner Piazza Gaglianone. 2012. Macro stress testing of credit risk focused on the tails. Journal of Financial Stability 8: 174–92. [Google Scholar] [CrossRef]
- Schnabel, S.K. 2011. Expectile Smoothing: New Perspectives on Asymmetric Least Squares. An Application to Life Expectancy. Ph. D. thesis, Utrecht University, Utrecht, The Netherlands. [Google Scholar]
- Sklar, A. 1959. Fonctions dé repartition á n dimensions et leurs marges. Publications de l’Institut de Statistique de l’Université de Paris 8: 229–31. [Google Scholar]
- Spanhel, Fabian, and Malte S. Kurz. 2015. Simplified vine copula models: Approximations based on the simplifying assumption. arXiv, arXiv:arXiv:1510.06971. [Google Scholar]
- Stöber, Jakob, Harry Joe, and Claudia Czado. 2013. Simplified pair copula constructions—Limitations and extensions. Journal of Multivariate Analysis 119: 101–18. [Google Scholar] [CrossRef]
- Waltrup, Linda Schulze, Fabian Sobotka, Thomas Kneib, and Goran Kauermann. 2015. Expectile and quantile regression—David and Goliath? Statistical Modelling 15: 433–56. [Google Scholar] [CrossRef]






© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fischer, M.; Kraus, D.; Pfeuffer, M.; Czado, C. Stress Testing German Industry Sectors: Results from a Vine Copula Based Quantile Regression. Risks 2017, 5, 38. https://doi.org/10.3390/risks5030038
Fischer M, Kraus D, Pfeuffer M, Czado C. Stress Testing German Industry Sectors: Results from a Vine Copula Based Quantile Regression. Risks. 2017; 5(3):38. https://doi.org/10.3390/risks5030038
Chicago/Turabian StyleFischer, Matthias, Daniel Kraus, Marius Pfeuffer, and Claudia Czado. 2017. "Stress Testing German Industry Sectors: Results from a Vine Copula Based Quantile Regression" Risks 5, no. 3: 38. https://doi.org/10.3390/risks5030038
APA StyleFischer, M., Kraus, D., Pfeuffer, M., & Czado, C. (2017). Stress Testing German Industry Sectors: Results from a Vine Copula Based Quantile Regression. Risks, 5(3), 38. https://doi.org/10.3390/risks5030038