1. Introduction
Most countries around the world have seen steady decreases in mortality rates in recent years, which also come with aging populations. Policy makers from both insurance companies and government departments seek more accurate modeling and forecasting of the mortality rates. The renowned Lee–Carter model [
1] is a benchmark in mortality modeling. Their model was the first to decompose mortality rates into one component, age, and the other component, time, using singular value decomposition. Since then, many extensions have been made based on the Lee–Carter model. For instance, Booth et al. [
2] address the non-linearity problem in the time component. Koissi et al. [
3] propose a bootstrapped confidence interval for forecasts. Renshaw and Haberman [
4] introduce the age-period-cohort model that incorporates the cohort effect in mortality modeling. Other than the Lee–Carter model, Cairns et al. [
5] propose the Cairns–Blake–Dowd (CBD) model that satisfies the new-data-invariant property. Chan et al. [
6] use a vector autoregressive integrated moving average (VARIMA) model for the joint forecast of CBD model parameters.
Mortality trends in two or more populations may be correlated, especially between sub-populations in a given population, such as females and males. This calls for a model that makes predictions in several populations simultaneously. We would also expect that the forecasts of similar populations do not diverge over the long run, so coherence between forecasts is a desired property. Carter and Lee [
7] examine how mortality rates of female and male populations can be forecast together using only one time-varying component. Li and Lee [
8] propose a model with a common factor and a population-specific factor to achieve coherence. Yang and Wang [
9] use a vector error correction model (VECM) to model the time-varying factors in multi-populations. Zhou et al. [
10] argue that the VECM performs better than the original Lee–Carter and vector autoregressive (VAR) models, and that the assumption of a dominant population is not needed. Danesi et al. [
11] compare several multi-population forecasting models and show that the preferred models are those providing a balance between model parsimony and flexibility. These mentioned approaches model mortality rates using raw data without smoothing techniques. In this paper, we propose a model under the functional data analysis (FDA) framework.
In functional data analysis settings (see Ramsay and Silverman [
12] for a comprehensive Introduction to FDA), it is assumed that there is an underlying smooth function of age as the mortality rate in each year. Since mortality rates are collected sequentially over time, we use the term functional time series for the data. Let
denote the log of the observed mortality rate of age
x at year
t. Suppose
is a underlying smooth function, where
represents the age continuum defined on a finite interval. In practice, we can only observe functional data on a set of grid points and the data are often contaminated by random noise:
where
n denotes the number of years and
p denotes the number of discrete data points of age observed for each function. The errors
are independent and identically distributed (iid) random variables with mean zero and variances
. Smoothing techniques are thus needed to obtain each function
from a set of realizations. Among many others, localized least squares and spline-based smoothing are two of the approaches frequently used (see, for example, [
13,
14]). We are not the first to use the functional data approach to model mortality rates. Hyndman and Ullah [
15] propose a model under the FDA framework, which is robust to outlying years. Chiou and Müller [
16] introduce a time-varying eigenfunction to address the cohort effect. Hyndman et al. [
17] propose a product–ratio model to achieve coherency in the forecasts of multiple populations.
Our proposed method is illustrated in
Section 2 and the Appendices. It can be summarized in four steps:
- 1)
smooth the observed data in each population;
- 2)
reduce the dimension of the functions in each population using functional principal component analysis (FPCA) separately;
- 3)
fit the first set of principal component scores from all populations with VECM. Then, fit the second set of principal component scores with another VECM and so on. Produce forecasts using the fitted VECMs; and
- 4)
produce forecasts of mortality curves.
Yang and Wang [
9] and Zhou et al. [
10] also use VECM to model the time-varying factor, namely, the first set of principal component scores. Our model is different in the following three ways. First, the studied object is in an FDA setting. Nonparametric smoothing techniques are used to eliminate extraneous variations or noise in the observed data. Second, as with other Lee–Carter based models, only the first set of principal component scores are used for prediction in [
9,
10]. For most countries, the fraction of variance explained is not high enough for one time-varying factor to adequately explain the mortality change. Our approach uses more than one set of principal component scores, and we review some of the ways to choose the optimal number of principal component scores. Third, in their previous papers, only point forecasts are calculated, while we use a bootstrap algorithm for constructing interval forecasts. Point and interval forecast accuracies are both considered.
The article is organized as follows: in
Section 2, we revisit the existing functional time series models and put forward a new functional time series method using a VECM. In
Section 3, we illustrate how the forecast results are evaluated. Simulation experiments are shown in
Section 4. In
Section 5, real data analyses are conducted using age-and sex-specific mortality rates in Switzerland and the Czech Republic. Concluding remarks are given in
Section 6, along with reflections on how the methods presented here can be further extended.
2. Forecasting Models
Let us consider the simultaneous prediction of multivariate functional time series. Consider two populations as an example:
are the smoothed log mortality rates of each population. According to (
A1) in the Appendices, for a sequence of functional time series
, each element can be decomposed as:
where
denotes the model truncation error function that captures the remaining terms. Thus, with functional principal component (FPC) regression, each series of functions are projected onto a
-dimension space.
The functional time series curves are characterized by the corresponding principal component scores that form a time series of vectors with the dimension
:
. To construct
h-step-ahead predictions
of the curve, we need to construct predictions for the
-dimension vectors of the principal component scores; namely,
with techniques from multivariate time series using covariance structures between multiple populations (see also [
18]). The
h-step-ahead prediction for
can then be constructed by forward projection
In the following material, we consider four methods for modeling and predicting the principal component scores , where h denotes a forecast horizon.
2.1. Univariate Autoregressive Integrated Moving Average Model
The FPC scores can be modeled separately as univariate time series using the autoregressive integrated moving average (ARIMA(
)) model:
where
B denotes the lag operator, and
is the white noise.
denotes the autoregressive part and
denotes the moving average part. The orders
can be determined automatically according to either the Akaike information criterion or the Bayesian information criterion value [
19]. Then, the maximum likelihood method can be used to estimate the parameters.
This prediction model is efficient in some cases. However, Aue et al. [
18] argue that, although the FPC scores have no instantaneous correlation, there may be autocovariance at lags greater than zero. The following model addresses this problem by using a vector time series model for the prediction of each series of FPC scores.
2.2. Vector Autoregressive Model
2.2.1. Model Structure
Now that each function
is characterized by a
-dimension vector
, we can model the
s using a VAR(
p) model:
where
are fixed
coefficient matrices and
form a sequence of iid random
-vectors with a zero mean vector. There are many approaches to estimating the VAR model parameters in [
20] including multivariate least squares estimation, Yule–Walker estimation and maximum likelihood estimation.
The VAR model seeks to make use of the valuable information hidden in the data that may have been lost by depending only on univariate models. However, the model does not fully take into account the common covariance structures between the populations.
2.2.2. Relationship between the Functional Autoregressive and Vector Autoregressive Models
As mentioned in the Introduction, Bosq [
21] proposes functional autoregressive (FAR) models for functional time series data. Although the computations for FAR(
p) models are challenging, if not unfeasible, one exception is FAR(1), which takes the form of:
where
is a bounded linear operator. However, it can be proven that if a FAR(
p) structure is indeed imposed on (
), then the empirical principal component scores
should approximately follow a VAR(
p) model. Let us consider FAR(1) as an example. Apply
to both sides of Equation (
1) to obtain:
with remainder terms
, where
.
With matrix notation, we get
, for
where
. This is a VAR(1) model for the estimated principal component scores. In fact, it can be proved that the two models make asymptotically equivalent predictions [
18].
2.3. Vector Error Correction Model
The VAR model relies on the assumption of stationarity; however, in many cases, that assumption does not stand. For instance, age-and sex-specific mortality rates over a number of years show persistently varying mean functions. The extension we suggest here uses the VECMs to fit pairs of principal component scores of the two populations. In a VECM, each variable in the vector is non-stationary, but there is some linear combination between the variables that is stationary in the long run. Integrated variables with this property are called co-integrated variables, and the process involving co-integrated variables is called a co-integration process. For more details on VECMs, consult [
20].
2.3.1. Fitting a Vector Error Correction Model to Principal Component Scores
For the
kth principal component score in the two populations, suppose the two are both first integrated and have a relationship of long-term equilibrium:
where
is a constant and
is a stable process. According to Granger’s Representation Theorem, the following VECM specifications exist for
and
:
where
, and
are the coefficients,
and
are innovations. Note that further lags of
’s may also be included.
2.3.2. Estimation
Let us consider the VECM(
p) without the deterministic term written in a more compact matrix form:
where
With this simple form, least squares, generalized least squares and maximum likelihood estimation approaches can be applied. The computation of the model with deterministic terms is equally easy, requiring only minor modifications. Moreover, the asymptotic properties of the parameter estimators are essentially unchanged. For further details, refer to [
20]. There is a sequence of tests to determine the lag order, such as the likelihood ratio test. Since our purpose is to make predictions, a selection scheme based on minimizing the forecast mean squared error can be considered.
2.3.3. Expressing a Vector Error Correction Model in a Vector Autoregressive Form
In a matrix notation, the model in Equation (
2) can be written as:
or
where
Rearranging the terms in Equation (
3) gives the VAR(2) representation:
Thus, a VECM(1) can be written in a VAR(2) form. When forecasting the scores, it is quite convenient to write the VECM process in the VAR form. The optimal h-step-ahead forecast with a minimal mean squared error is given by the conditional expectation.
2.4. Product–Ratio Model
Coherent forecasting refers to non-divergent forecasting for related populations [
8]. It aims to maintain certain structural relationships between the forecasts of related populations. When we model two or more populations, joint modeling plays a very important role in terms of achieving coherency. When modeled separately, forecast functions tend to diverge in the long run. The product–ratio model forecasts the population functions by modeling and forecasting the ratio and product of the populations. Coherence is imposed by constraining the forecast ratio function to stationary time series models. Suppose
and
are the smoothed functions from the two populations to be modeled together, we compute the products and ratios by:
The product
and ratio
functions are then decomposed using FPCA and the scores can be modeled separately with a stationary autoregressive moving average (ARMA)(
) [
22] in the product functions or an autoregressive fractionally integrated moving average (ARFIMA)(
) process [
23,
24] in the ratio functions, respectively. With the
h-step-ahead forecast values for
and
, the
h-step-ahead forecast values for
and
can be derived by
2.5. Bootstrap Prediction Interval
The point forecast itself does not provide information about the uncertainty of prediction. Constructing a prediction interval is an important part of evaluating forecast uncertainty when the full predictive distribution is hard to specify.
The univariate model proposed by [
15], discussed in
Section 2.1, computes the variance of the predicted function by adding up the variance of each component as well as the estimated error variance. The
prediction interval is then constructed under the assumption of normality, where
denotes the level of significance. The same approach is used in the product–ratio model; however, when the normality assumption is violated, alternative approaches may be used.
Bootstrapping is used to construct prediction interval in the functional VECM that we propose. There are three sources of uncertainties in the prediction. The first is from the smoothing process. The second is from the remaining terms after the cut-off at
K in the principal component regression:
. If the correct number of dimensions of
K is picked, the residuals can be regarded as independent. The last source of uncertainty is from the prediction of scores. The smoothing errors are generated under the assumption of normality and the other two kinds of errors are bootstrapped. All three uncertainties are added up to construct bootstrapped prediction functions. The steps are summarized in the following algorithm:
- 1)
Smooth the functions with , where is the smoothing error with mean zero and estimated variance .
- 2)
Perform FPCA on the smoothed functions and separately, and obtain K pairs of principal component scores .
- 3)
Fit K VECM models to the principal component scores. From the fitted scores , for and , obtain the fitted functions .
- 4)
Obtain residuals from .
- 5)
Express the estimated VECM from step 3 in its VAR form: and . Construct K sets of bootstrap principal component scores time series , where the error term is re-sampled with replacement from .
- 6)
Refit a VECM with and make h-step-ahead predictions and hence a predicted function .
- 7)
Construct a bootstrapped
h-step-ahead prediction for the function by
where
is a re-sampled version of
from step 4 and
are generated from a normal distribution with mean
and variance
, where
is re-sampled from
from step 1).
- 8)
Repeat steps 5 to 7 many times.
- 9)
The point-wise prediction intervals can be constructed by taking the and quantiles of the bootstrapped samples.
Koissi et al. [
3] extend the Lee–Carter model with a bootstrap prediction interval. The prediction interval we suggest in this paper is different from their method. First, we work under a functional framework. This means that there is extra uncertainty from the smoothing step. Second, in both approaches, errors caused by dimension reduction are bootstrapped. Third, after dimension reduction, their paper uses an ARIMA(0, 1, 0) model to fit the time-varying component. There is no need to consider forecast uncertainty since the parameters of the time series are fixed. In our approach, parameters are estimated using the data. We adopt similar ideas from the early work of Masarotto [
25] for the bootstrap of the autoregression process. This step can also be further extended to a bootstrap-after-bootstrap prediction interval [
26]. To summarize, we incorporate three sources of uncertainties in our prediction interval, whereas Koissi et al. [
3] only considers one due to the simplicity of the Lee–Carter model.
3. Forecast Evaluation
We split the data set into a training set and a testing set. The four models are fitted to the data in the training set and predictions are made. The data in the testing set is then used for forecast evaluation. Following the early work by [
27], we allocate the first two-thirds of the observations into the training set and the last one-third into the testing set.
We use an expanding window approach. Suppose the size of the full data set is 60. The first 40 functions are modeled and one to 20-step-ahead forecasts are produced. Then, the first 41 functions are used to make one to 19-step-ahead forecasts. The process is iterated by increasing the sample size by one until reaching the end of the data. This produces 20 one-step-ahead forecasts, 19 two-step-ahead forecasts, … and, finally, one 20-step-ahead forecast. The forecast values are compared with the true values of the last 20 functions. Mean absolute prediction errors (MAPE) and mean squared prediction errors (MSPE) are used as measures of point forecast accuracy [
11]. For each population, MAPE and MSPE can be calculated as:
where
represents the
h-step-ahead prediction using the first
years fitted in the model, and
denotes the true value.
For the interval forecast, coverage rate is a commonly used evaluation standard. However, coverage rate alone does not take into account the width of the prediction interval. Instead, the interval score is an appealing method that combines both a measure of the coverage rate and the width of the prediction interval [
28]. If
and
are the upper and lower
prediction bounds, and
is the realized value, the interval score at point
is:
where
is the level of significance, and
is an indicator function. According to this standard, the best predicted interval is the one that gives the smallest interval score. In the functional case here, the point-wise interval scores are computed and the mean over the discretized ages is taken as a score for the whole curve. Then, the score values are averaged across the forecast horizon to get a mean interval score at horizon
h:
where
p denotes the number of age groups and
h denotes the forecast horizons.
4. Simulation Studies
In this section, we report the results from the prediction of simulated non-stationary functional time series using the models discussed in
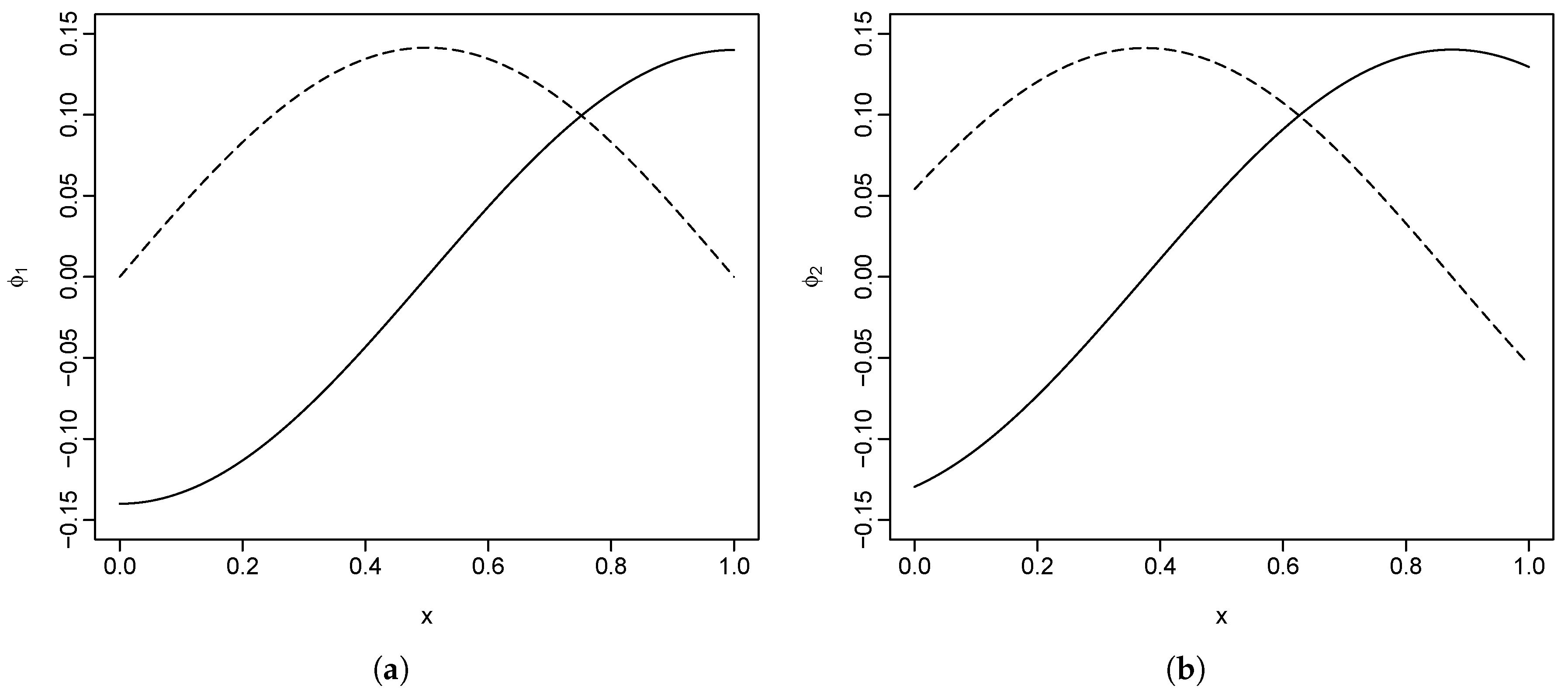
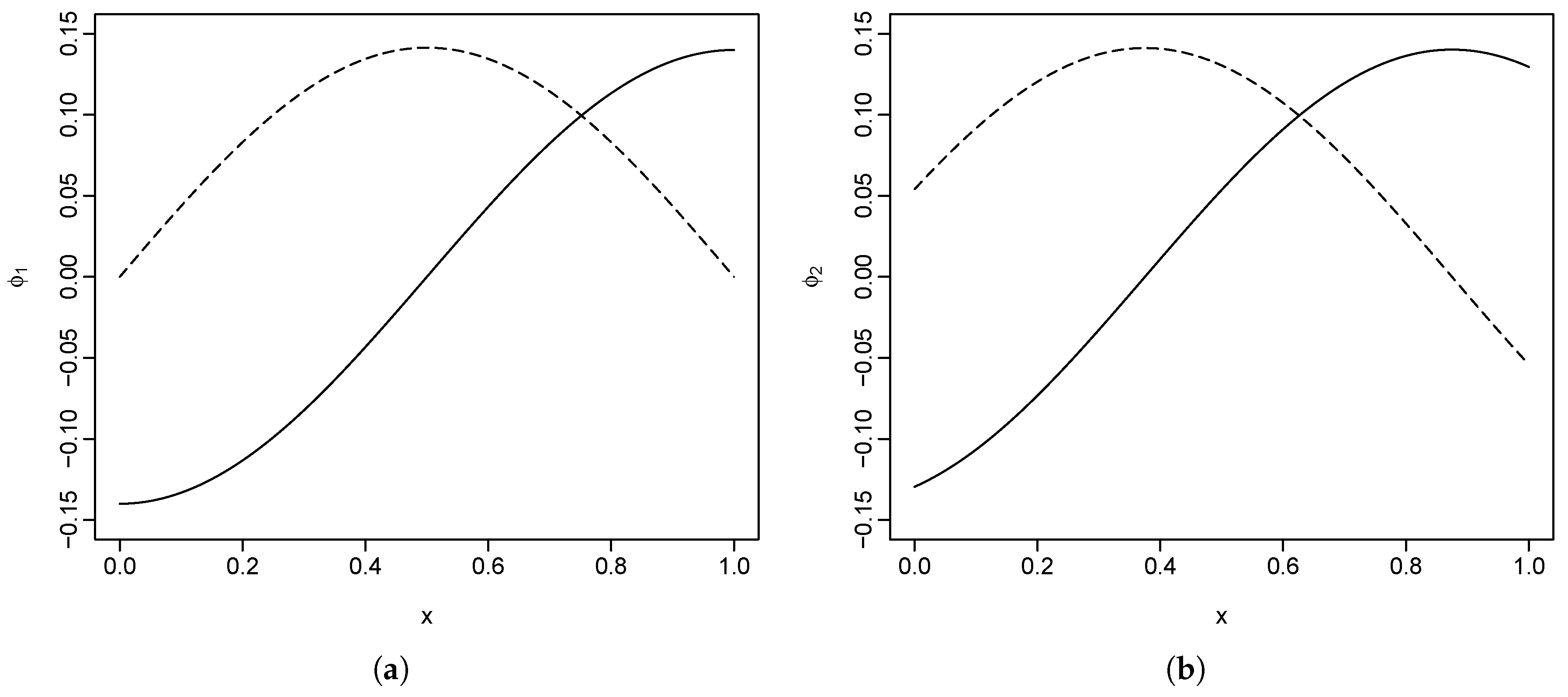
Section 2. We generated two series of correlated populations, each with two orthogonal basis functions. The simulated functions are constructed by
The construction of the basis functions is arbitrary, with the only restriction being that of orthogonality. The two basis functions for the first population we used are
and
, and, for the second population, these are
and
, where
. Here, we are using
discrete data points for each function. As shown in
Figure 1, the basis functions are scaled so that they have an
norm of 1.
The principal component scores, or coefficients
, are generated with non-stationary time series models and centered to have a mean of zero. In
Section 4.1, we consider the case with co-integration, and, in
Section 4.2, we consider the case without co-integration.
4.1. With Co-Integration
We first considered the case where there is a co-integration relationship between the scores of the two populations. Assuming that the principal component scores are first integrated, the two pairs of scores are generated with the following two models:
where
are innovations that follow a Gaussian distribution with mean zero and variance
. To satisfy the condition of decreasing eigenvalues:
, we used
and
.
It can easily be seen that the long-term equilibrium for the first pair of scores is and, for the second pair of scores, it is .
4.2. Without Co-Integration
When co-integration does not exist, there is no long-term equilibrium between the two sets of scores, but they are still correlated through the coefficient matrix. We assumed that the first integrated scores follow a stable VAR(1) model:
For a VAR(1) model to be stable, it is required that should have all roots outside the unit circle.
4.3. Results
The principal component scores are generated using the aforementioned two models for observations
. Two sets of simulated functions are generated using Equation (
7). We performed an FPCA on the two populations separately. The estimated principal component scores are then modeled using the univariate model, the VAR model and the VECM.
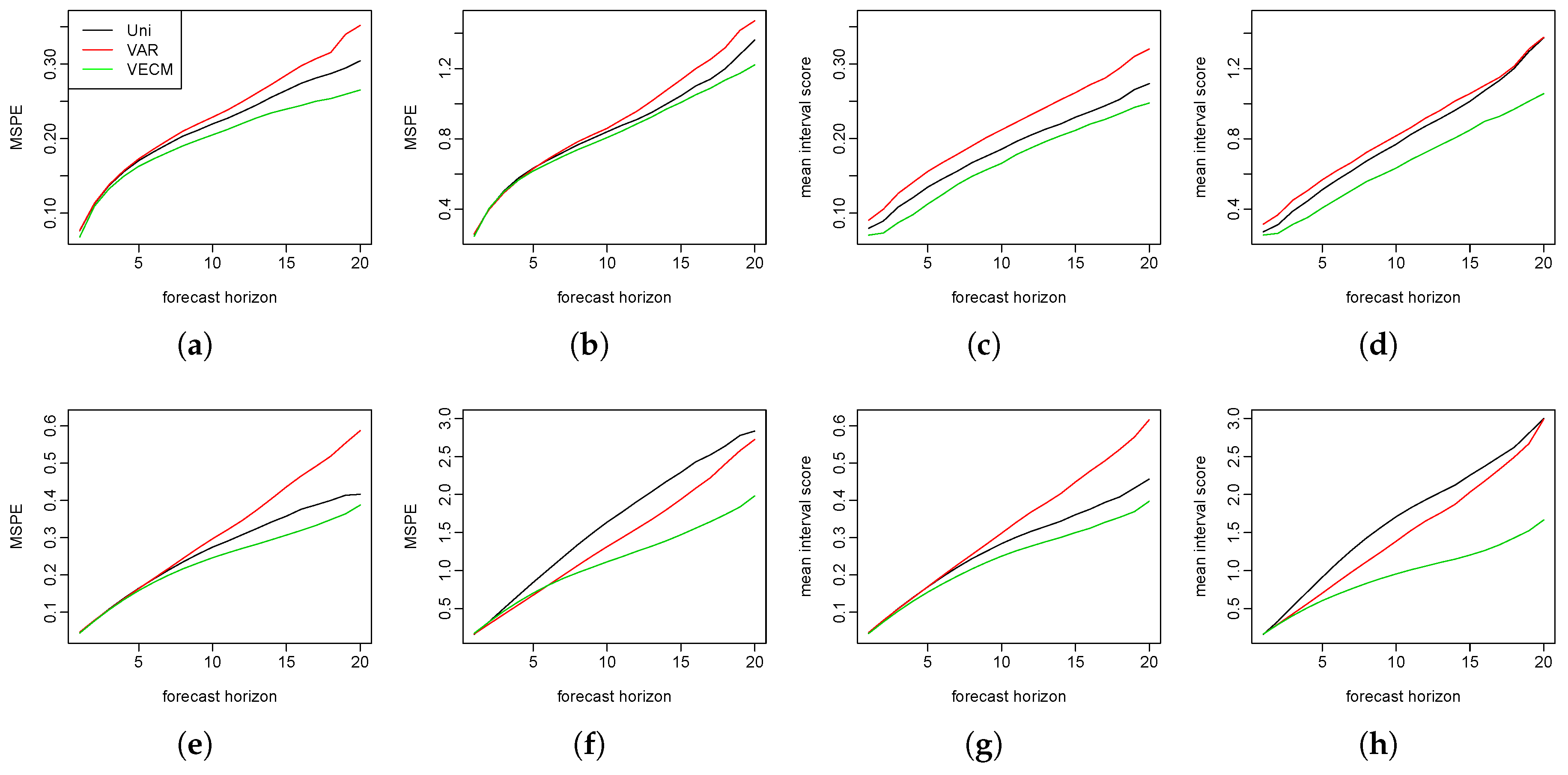
We repeated the simulation procedures 150 times. In each simulation, 500 bootstrap samples are generated to calculate the prediction intervals. We show the MSPE and the mean interval scores at each forecast horizon in
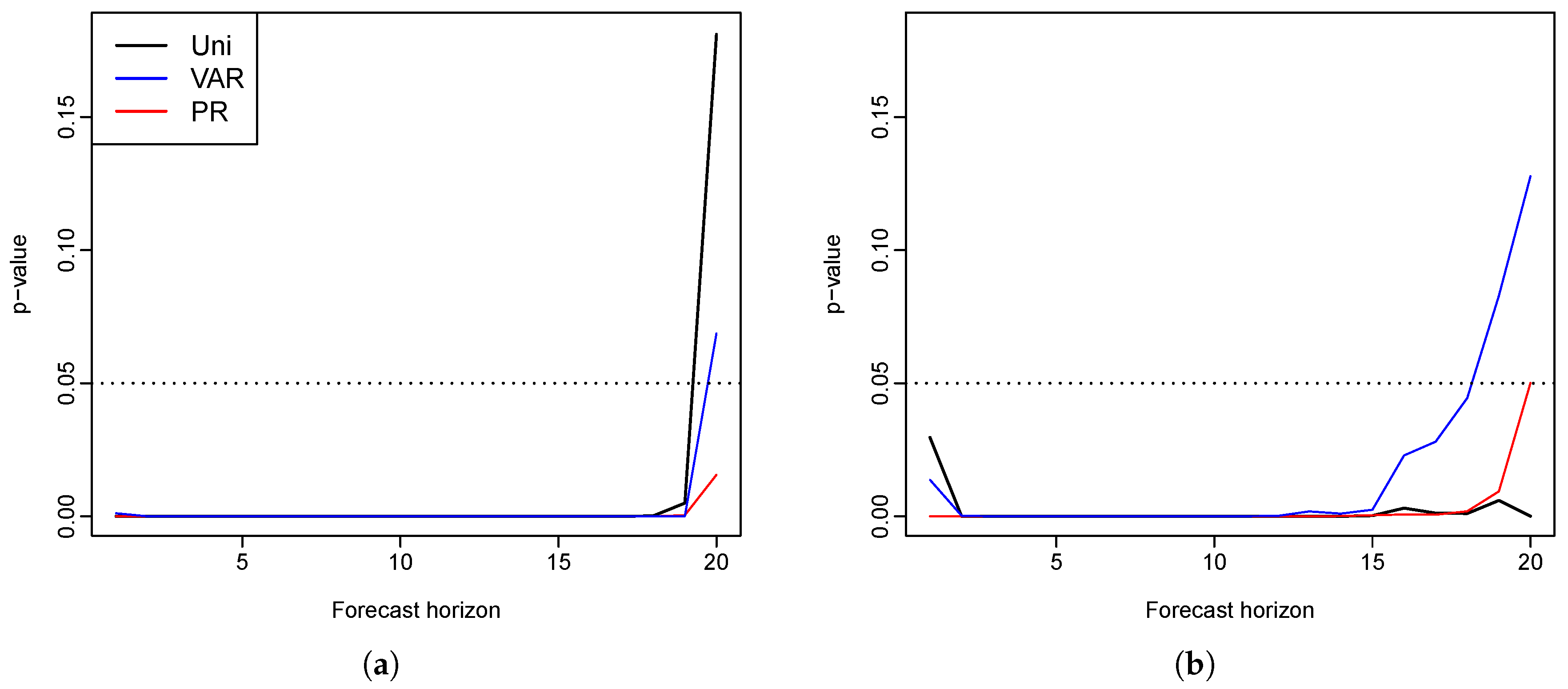
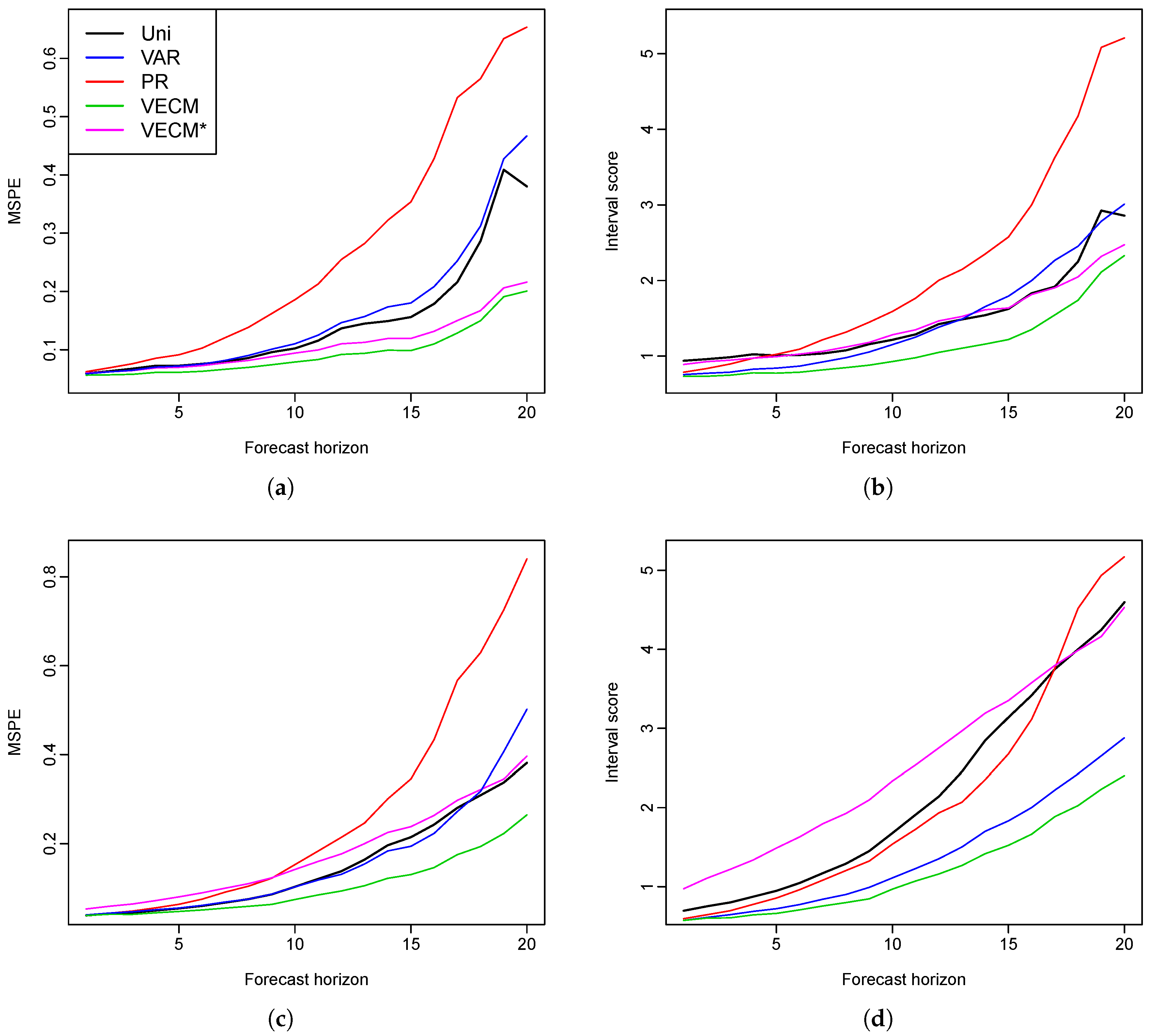
Figure 2. The three models performed almost equally well in the short-term forecasts. In the long run, however, the functional VECM produced better predictions than the other two models. This advantage grew bigger as the forecast horizons increased.
6. Conclusions
We have extended the existing models and introduced a functional VECM for the prediction of multivariate functional time series. Compared to the current forecasting approaches, the proposed method performs well in both simulations and in empirical analyses. An algorithm to generate bootstrap prediction intervals is proposed and the results give superior interval forecasts. The advantage of our method is the result of several factors: (1) the functional VECM model considers the covariance between different groups, rather than modeling the populations separately; (2) it can cope with data where the assumption of stationarity does not hold; (3) the forecast intervals using the proposed algorithm combine three sources of uncertainties. Bootstrapping is used to avoid the assumption of the distribution of the data.
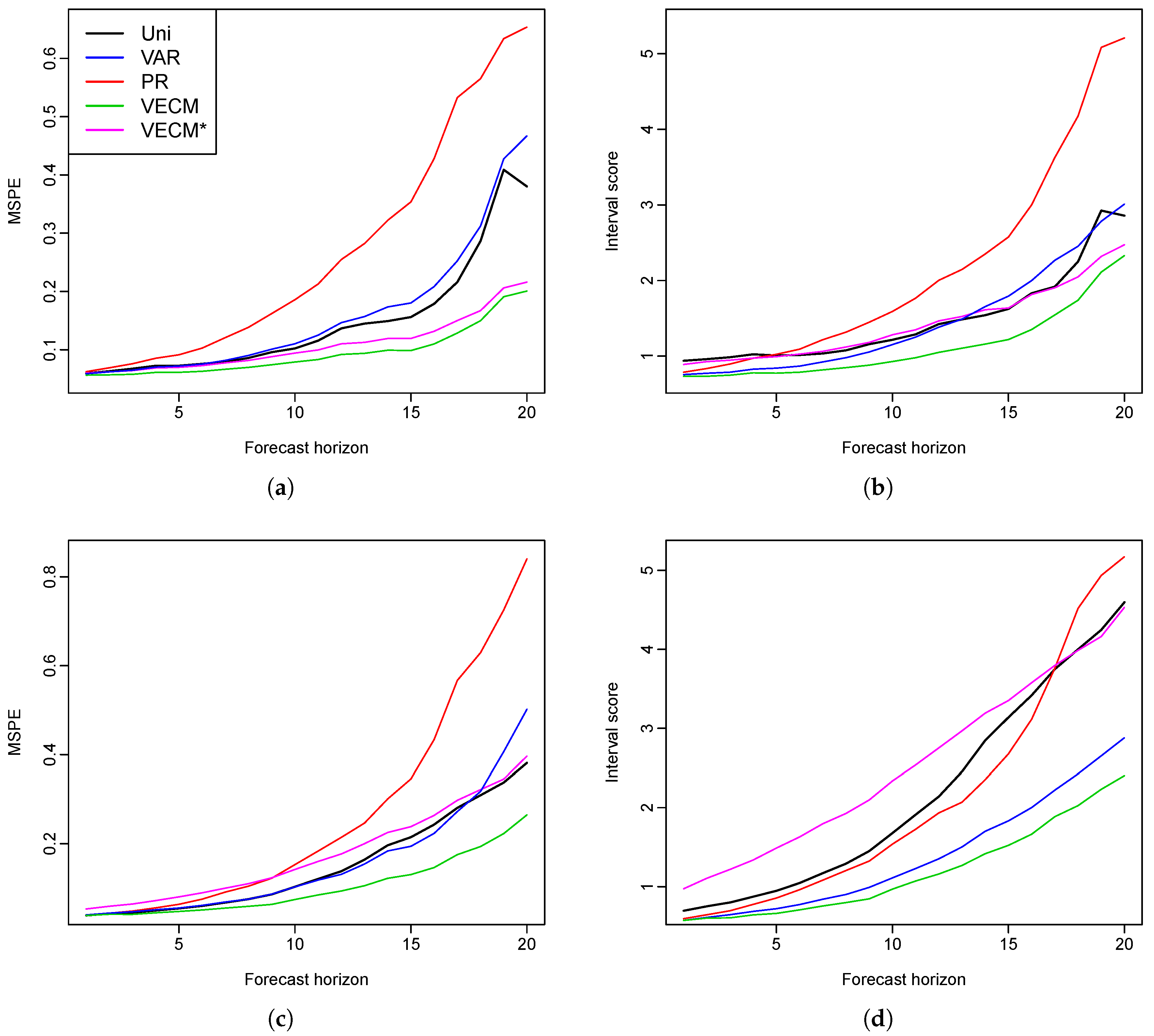
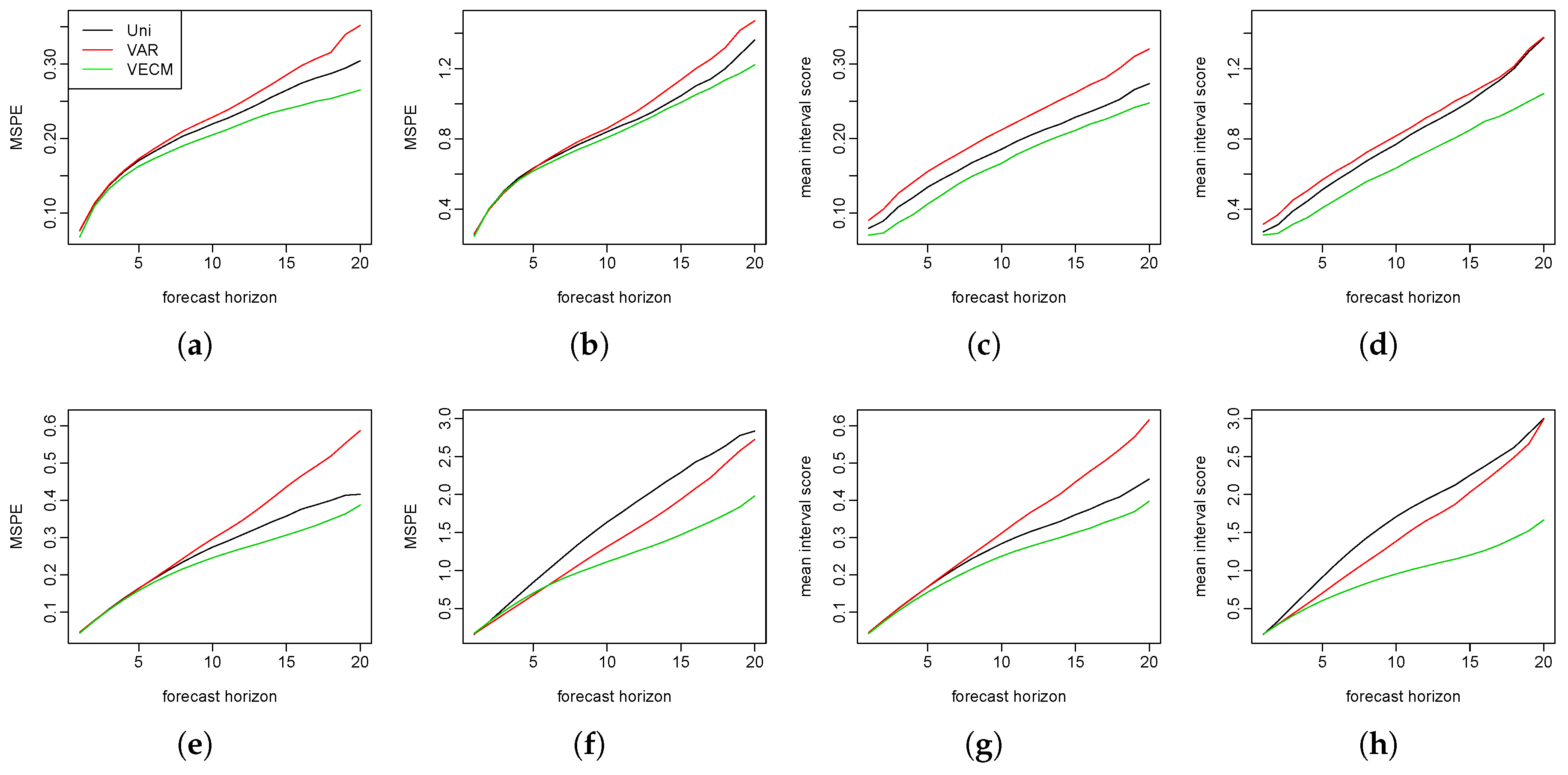
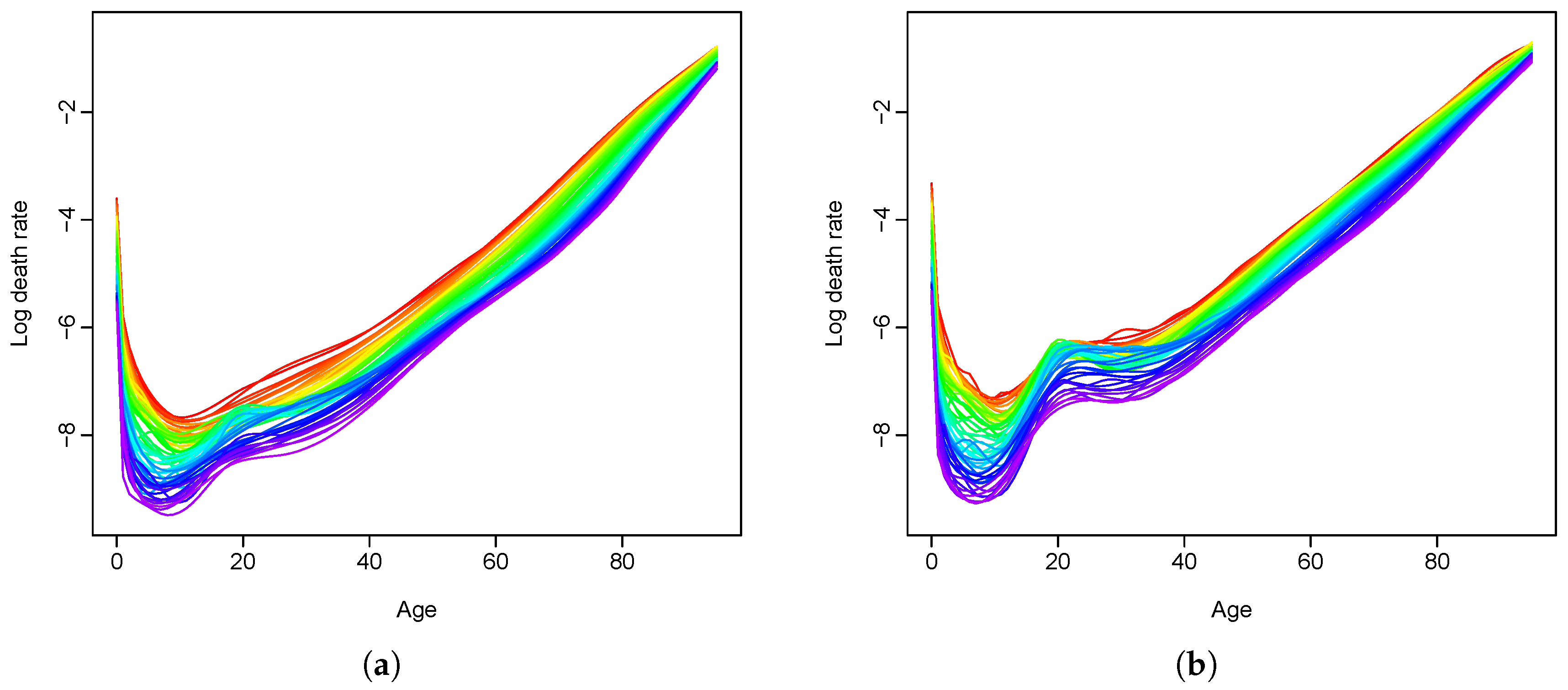
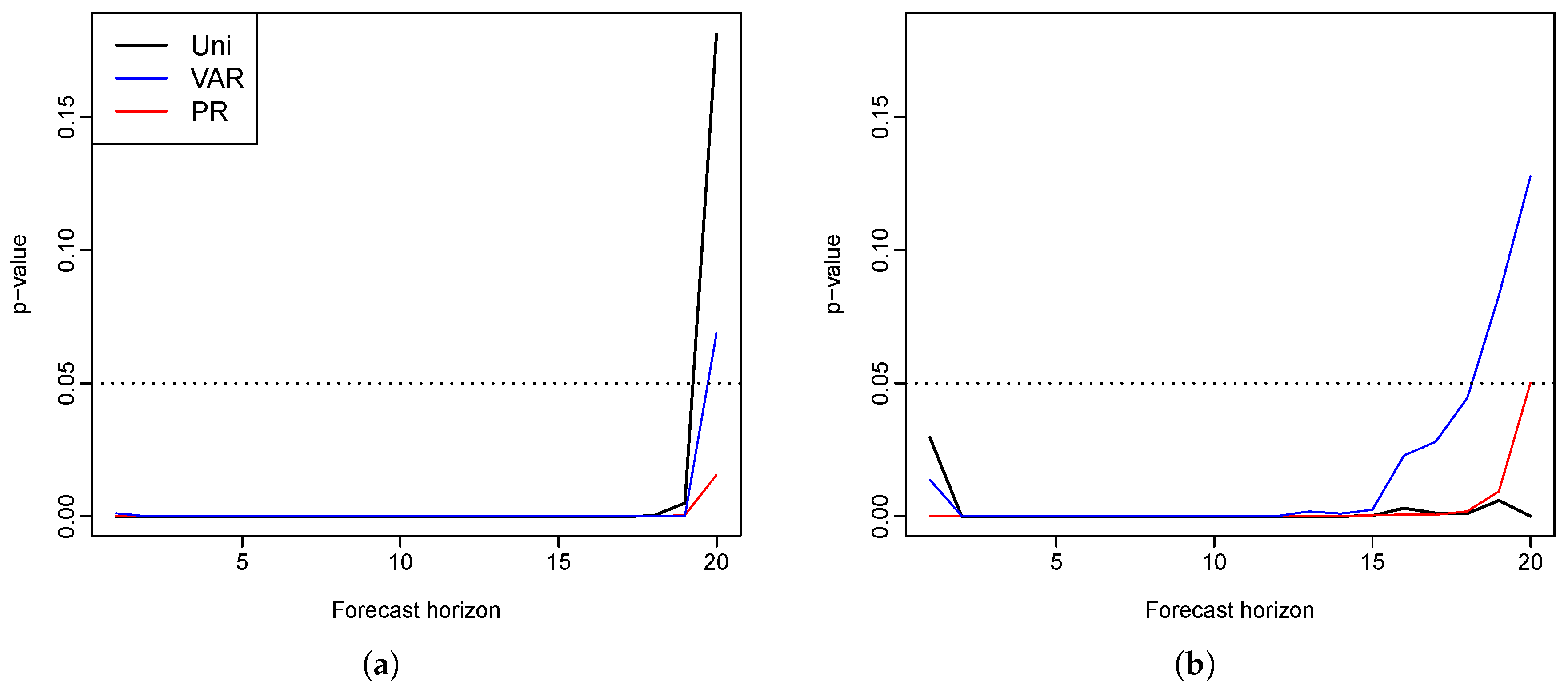
We apply the proposed method as well as the existing methods to the male and female mortality rates in Switzerland and the Czech Republic. The empirical studies provide evidence of the superiority of the functional VECM approach in both the point and interval forecasts, which are evaluated by MAPE, MSPE and interval scores, respectively. Diebold–Mariano test results also show significantly improved forecast accuracy of our model. In most cases, when there is a long-run coherent structure in the male and female mortality rates, functional VECM is preferable. The long-term equilibrium constraint in the functional VECM ensures that divergence does not emerge.
While we use two populations for the illustration of the model and in the empirical analysis, functional VECM can easily be applied to populations with more than two groups. A higher rank of co-integration order may need to be considered and the Johansen test can then be used to determine the rank [
35].
In this paper, we have focused on comparing our model with others within functional time series frameworks. There are numerous other mortality models in the literature, and many of them try to deal with multiple populations. Further research is needed to evaluate our model against the performance of these models.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}