
Choosing Markovian Credit Migration Matrices by Nonlinear Optimization


Abstract
:
1. Introduction
2. Transition Matrix Analysis
3. Optimization Problems
3.1. Constraints
- 1
- is a nondecreasing function of i for every fixed k and
- 2
- for all i, k such that .
3.2. Best Approximation of the Annual Transition Matrix
3.3. Quasi-Optimization of the Generator
4. Optimization Application
4.1. Regularization Comparison
4.2. Towards Global Optimization
- A homogenization approach is solved iteratively, where and the interval is discretized, for example, into steps of , thus moving from Problem 2 to Problem 1, where in each step, the start matrix is replaced by the optimal solution of the previous step. This way, a more robust procedure is obtained as the simpler (as convex problem) QOG is utilized for generating better start matrices, accordingly gaining accuracy in each iteration. More precisely, we find a generator matrix that, when exponentiated (by the matrix exponential), most closely matches the annual transition matrix , with:where denotes the Frobenius norm. Equivalently, as in Problems 2 and 1, the sets (Definition 4) and (Definition 5) can easily be included. Set (Definition 3), on the other hand, also needs to be homogenized, as well.
- Global solutions in combination with MATLAB’s local solver fmincon() with multiple start points.
- -
- ‘MultiStart’ (MS)
- -
- ‘GlobalSearch’ (GS)
4.3. Constraints Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| BAM | best approximation of the transition matrix |
| DA | diagonal adjustment |
| DMPG | distance minimization problem for the generator matrix |
| GS | global search |
| Homogen | homogenization |
| MCMC | Markov chain Monte Carlo |
| MS | multi-start |
| QOG | quasi-optimization of the generator |
| WA | weighted adjustment |
Appendix

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AAA | AA | A | BBB | BB | B | CCC-C | D | |
|---|---|---|---|---|---|---|---|---|
| AAA | 0.9193 | 0.0746 | 0.0048 | 0.0008 | 0.0004 | 0.0000 | 0.0000 | 0.0000 |
| AA | 0.0064 | 0.9180 | 0.0676 | 0.0060 | 0.0006 | 0.0011 | 0.0003 | 0.0000 |
| A | 0.0007 | 0.0227 | 0.9168 | 0.0512 | 0.0056 | 0.0025 | 0.0001 | 0.0004 |
| BBB | 0.0004 | 0.0027 | 0.0556 | 0.8789 | 0.0483 | 0.0102 | 0.0017 | 0.0023 |
| BB | 0.0004 | 0.0010 | 0.0061 | 0.0775 | 0.8148 | 0.0789 | 0.0111 | 0.0101 |
| B | 0.0000 | 0.0010 | 0.0028 | 0.0046 | 0.0695 | 0.8280 | 0.0396 | 0.0546 |
| CCC-C | 0.0019 | 0.0000 | 0.0037 | 0.0074 | 0.0243 | 0.1212 | 0.6046 | 0.2370 |
| D | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 |
| Aaa | Aa | A | Baa | Ba | B | Caa-C | D | |
| Aaa | 0.8866 | 0.1030 | 0.0102 | 0.0000 | 0.0003 | 0.0000 | 0.0000 | 0.0000 |
| Aa | 0.0108 | 0.8870 | 0.0955 | 0.0034 | 0.0015 | 0.0015 | 0.0000 | 0.0003 |
| A | 0.0006 | 0.0288 | 0.9021 | 0.0592 | 0.0074 | 0.0018 | 0.0001 | 0.0001 |
| Baa | 0.0005 | 0.0034 | 0.0707 | 0.8523 | 0.0605 | 0.0101 | 0.0008 | 0.0016 |
| Ba | 0.0003 | 0.0008 | 0.0056 | 0.0568 | 0.8358 | 0.0808 | 0.0053 | 0.0146 |
| B | 0.0001 | 0.0004 | 0.0017 | 0.0065 | 0.0660 | 0.8270 | 0.0276 | 0.0706 |
| Caa-C | 0.0000 | 0.0000 | 0.0066 | 0.0105 | 0.0305 | 0.0611 | 0.6297 | 0.2616 |
| D | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 |
| Aaa | Aa | A | Baa | Ba | B | Caa-C | D | |
|---|---|---|---|---|---|---|---|---|
| Aaa | −0.1212 | 0.1160 | 0.0051 | 0.0000 | 0.0001 | 0.0000 | 0.0000 | 0.0000 |
| Aa | 0.0121 | −0.1223 | 0.1069 | 0.0002 | 0.0012 | 0.0015 | 0.0000 | 0.0003 |
| A | 0.0005 | 0.0321 | −0.1075 | 0.0674 | 0.0061 | 0.0014 | 0.0000 | 0.0000 |
| Baa | 0.0006 | 0.0025 | 0.0805 | −0.1650 | 0.0713 | 0.0085 | 0.0008 | 0.0008 |
| Ba | 0.0003 | 0.0007 | 0.0036 | 0.0671 | −0.1857 | 0.0970 | 0.0054 | 0.0116 |
| B | 0.0001 | 0.0004 | 0.0014 | 0.0049 | 0.0787 | −0.1952 | 0.0380 | 0.0717 |
| Caa-C | 0.0000 | 0.0000 | 0.0080 | 0.0124 | 0.0380 | 0.0825 | −0.4644 | 0.3236 |
| D | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
References
- A. Kreinin, and M. Sidelnikova. “Regularization Algorithms for Transition Matrices.” Algo Res. Q. 4 (2001): 23–40. [Google Scholar]
- E. Davies. “Embeddable Markov Matrices.” Electron. J. Probab. 15 (2010): 1474–1486. [Google Scholar] [CrossRef]
- W. Stromquist. Roots of Transition Matrices. Practical Paper; Exton, PA, USA: Daniel H. Wagner Associates, 1996. [Google Scholar]
- M. Araten, and L. Angbazo. Roots of Transition Matrices: Application to Settlement Risk. Practical Paper; New York, NY, USA: Chase Manhattan Bank (JPMorgan Chase & Co.), 1997. [Google Scholar]
- N.J. Higham, and L. Lin. “On pth Roots of Stochastic Matrices.” Linear Algebra Appl. 435 (2011): 448–463. [Google Scholar] [CrossRef]
- L. Lin. “Roots of Stochastic Matrices and Fractional Matrix Powers.” Ph.D. Thesis, University of Manchester, Manchester, UK, 2011. [Google Scholar]
- T. Charitos, P.R. de Waal, and L.C. van der Gaag. “Computing Short-Interval Transition Matrices of a Discrete-Time Markov Chain from Partially Observed Data.” Stat. Med. 27 (2008): 905–921. [Google Scholar] [CrossRef] [PubMed]
- Y. Inamura. Estimating Continuous Time Transition Matrices from Discretely Observed Data. Working Paper; Financial Systems and Bank Examination Department: Tokyo, Japan: Bank of Japan, 2006. [Google Scholar]
- J.R. Norris. Markov Chains. Number 2008 in Cambridge Series in Statistical and Probabilistic Mathematics; Cambridge, United Kingdom: Cambridge University Press, 1998. [Google Scholar]
- S. Asmussen. “Stochastic Modelling and Applied Probability.” In Applied Probability and Queues. New York, NY, USA: Springer, 2008. [Google Scholar]
- T. Bielecki, and M. Rutkowski. Credit Risk: Modeling, Valuation and Hedging. Berlin, Germany: Springer Finance; Springer, 2013. [Google Scholar]
- W.J. Culver. “On the Existence and Uniqueness of the Real Logarithm of a Matrix.” Proc. Am. Math. Soc. 17 (1966): 1146–1151. [Google Scholar] [CrossRef]
- B. Singer, and S. Spilerman. “The Representation of Social Processes by Markov Models.” Am. J. Sociol. 82 (1976): 1–54. [Google Scholar] [CrossRef]
- R.B. Israel, J.S. Rosenthal, and J.Z. Wei. “Finding Generators for Markov Chains via Empirical Transition Matrices, with Applications to Credit Ratings.” Math. Financ. 11 (2001): 245–265. [Google Scholar] [CrossRef]
- G. Elfving. “Zur Theorie der Markoffschen Ketten.” Acta Soc. Sci. Fenn. 8 (1937): 1–17. [Google Scholar]
- J.F.C. Kingman. “The Imbedding Problem for Finite Markov Chains.” Z. Wahrscheinlichkeitstheorie Verwandte Geb. 1 (1962): 14–24. [Google Scholar] [CrossRef]
- M.A. Guerry. “On the Embedding Problem for Discrete-Time Markov Chains.” J. Appl. Probab. 50 (2013): 918–930. [Google Scholar] [CrossRef]
- J. Cuthbert. “The Logarithmic Function for Finite-State Markov Semi-Groups.” J. Lond. Math. Soc. 6 (1973): 524–532. [Google Scholar] [CrossRef]
- S. Johansen. “Some Results on the Imbedding Problem for Finite Markov Chains.” J. Lond. Math. Soc. 2 (1974): 345–351. [Google Scholar] [CrossRef]
- H. Frydman. “The Embedding Problem for Markov Chains with Three States.” Math. Proc. Camb. Philos. Soc. 87 (1980): 285–294. [Google Scholar] [CrossRef]
- P. Carette. “Characterizations of Embeddable 3 × 3 Stochastic Matrices with a Negative Eigenvalue.” N. Y. J. Math. 1 (1995): 120–129. [Google Scholar]
- M.A. Guerry. “On the Embedding Problem for Three-State Markov Chains.” In Proceedings of the World Congress on Engineering 2014, London, UK, 2–4 July 2014; Volume II.
- K. Chung. Markov Chains with Stationary Transition Probabilities. Die Grundlehren der mathematischen Wissenschaften; Berlin, Germany: Springer, 1960. [Google Scholar]
- G. Grimmett, and D. Stirzaker. “Probability and random processes.” In Probability and Random Processes. Oxford, UK: OUP Oxford, 2001. [Google Scholar]
- G.S. Goodman. “An Intrinsic Time for Non-Stationary Finite Markov Chains.” Z. Wahrscheinlichkeitstheorie Verwandte Geb. 16 (1970): 165–180. [Google Scholar] [CrossRef]
- R.A. Jarrow, D. Lando, and S.M. Turnbull. “A Markov Model for the Term Structure of Credit Risk Spreads.” Rev. Financ. Stud. 10 (1997): 481–523. [Google Scholar] [CrossRef]
- W. Anderson. Continuous-Time Markov Chains: An Applications-Oriented Approach. New York, NY, USA: Springer, 2012. [Google Scholar]
- A. Metz, and R. Cantor. “Moody’s Credit Policy—Introducing Moody’s Credit Transition Model.” Available online: http://www.moodysanalytics.com/ /media/Brochures/Credit-Research-Risk-Measurement/Quantative-Insight/Credit-Transition-Model/Introductory-Article-Credit-Transition-Model.pdf (accessed on 29 August 2016).
| Constraints | Method | Start Matrix | |||
|---|---|---|---|---|---|
| (G1), (G2) | DA | ||||
| WA | |||||
| DMPG | |||||
| QOG | |||||
| (0.21 s) | (7.18 s) | (10.70 s) | |||
| (0.38 s) | (9.91 s) | (21.06 s) | |||
| (0.14 s) | (4.02 s) | (4.60 s) | |||
| BAM | |||||
| (0.16 s) | (1.92 s) | (17.33 s) | |||
| (0.17 s) | (2.22 s) | (27.07 s) | |||
| (0.16 s) | (3.41 s) | (18.26 s) | |||
| (0.20 s) | (4.24 s) | (23.72 s) |
| Constraints | Method | |||
|---|---|---|---|---|
| (G1), (G2) | Homogen | |||
| (24.95 s) | (718.74 s) | (1938.16 s) | ||
| MS | ||||
| (32.67 s) | (1353.93 s) | (12509.95 s) | ||
| GS | ||||
| (2.77 s) | (18.01 s) | (9447.82 s) |
| Constraints | Method | |||
|---|---|---|---|---|
| (G1), (G2), (D1) | QOG | |||
| (0.62 s) | (11.13 s) | (22.70 s) | ||
| BAM | ||||
| (0.31 s) | (3.31 s) | (26.25 s) | ||
| (G1), (G2), (D2) | QOG | |||
| (0.66 s) | (18.21 s) | (4.65 s) | ||
| BAM | ||||
| (0.31 s) | (6.32 s) | (26.36 s) | ||
| (G1), (G2), (D1), (D2) | QOG | |||
| (0.49 s) | (16.07 s) | (22.44 s) | ||
| BAM | ||||
| (0.31 s) | (3.93 s) | (27.44 s) | ||
| (G1), (G2), (M1), (M2) | QOG | |||
| (0.22 s) | (13.97 s) | (22.26 s) | ||
| BAM | ||||
| (0.28 s) | (5.46 s) | (114.72 s) | ||
| (G1), (G2), (R1) | QOG | |||
| (0.42 s) | (14.91 s) | (78.80 s) | ||
| BAM | ||||
| (0.33 s) | (4.30 s) | (32.88 s) | ||
| All | QOG | |||
| (0.42 s) | (15.95 s) | (38.06 s) | ||
| BAM | ||||
| (0.51 s) | (6.41 s) | (51.18 s) |
| One Year () | Five Year () | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Constraints | Method | Aaa | Aa | A | Baa | Aaa | Aa | A | Baa |
| Original | 0.00 | 3.11 | 1.04 | 15.87 | 5.01 | 28.85 | 47.69 | 231.67 | |
| (G1), (D2) | QOG | 0.17 | 3.12 | 1.42 | 15.89 | 6.35 | 29.69 | 49.17 | 231.92 |
| BAM | 0.17 | 3.05 | 1.40 | 15.86 | 6.20 | 29.32 | 48.94 | 231.82 | |
| (G1), (G2), (D1) | QOG | 3.00 | 3.49 | 3.00 | 16.01 | 18.04 | 32.56 | 55.81 | 233.29 |
| BAM | 3.00 | 3.12 | 3.00 | 15.87 | 17.65 | 30.99 | 55.19 | 232.73 | |
| (G1), (G2), (D2) | QOG | 0.12 | 2.08 | 2.08 | 15.95 | 5.39 | 26.11 | 51.73 | 232.46 |
| BAM | 0.12 | 2.06 | 2.06 | 15.87 | 5.29 | 25.96 | 51.35 | 232.17 | |
| (G1), (G2), (D1), (D2) | QOG | 3.00 | 3.00 | 3.00 | 16.01 | 17.65 | 30.66 | 55.70 | 233.26 |
| BAM | 3.00 | 3.00 | 3.00 | 15.87 | 17.55 | 30.52 | 55.16 | 232.73 | |
| (G1), (G2), (M1), (M2) | QOG | 0.16 | 2.93 | 1.41 | 15.89 | 5.36 | 25.88 | 48.97 | 231.88 |
| BAM | 0.17 | 3.08 | 1.41 | 15.86 | 5.52 | 26.51 | 49.06 | 231.82 | |
| (G1), (G2), (R1) | QOG | 0.07 | 1.28 | 1.99 | 15.09 | 4.36 | 21.77 | 49.44 | 222.44 |
| BAM | 0.08 | 1.47 | 2.19 | 15.57 | 4.59 | 22.98 | 51.09 | 227.43 | |
| All | QOG | 3.00 | 3.41 | 4.08 | 15.17 | 17.41 | 29.36 | 56.96 | 223.86 |
| BAM | 3.00 | 3.42 | 4.12 | 15.50 | 17.46 | 29.70 | 58.22 | 228.29 | |
| Constraints | Method | |||
|---|---|---|---|---|
| (G1), (G2), (M1), (M2) | Original | 0.0440 | 0.0838 | 0.1735 |
| QOG | 0.0638 | 0.0638 | 0.1721 | |
| BAM | 0.0641 | 0.0641 | 0.1734 |
| Constraints | Method | |||
|---|---|---|---|---|
| (G1), (G2), (R1) | Original | −0.0059 | −0.0173 | 0.0931 |
| QOG | −0.0189 | −0.0189 | 0.0904 | |
| BAM | −0.0163 | −0.0163 | 0.0917 |
- 2.Version 8.4.0 (R2014b), The MathWorks Inc., Natick, MA, USA.
- 3.We distinguish between general transition matrices in theory, denoted by , and given transition matrices by rating agencies, denoted by , if not stated otherwise.
- 4.Each single additional constraint can be switched on or off according to the user’s preferences. Further extensions are conceivable.
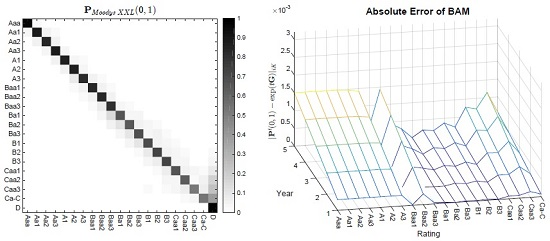
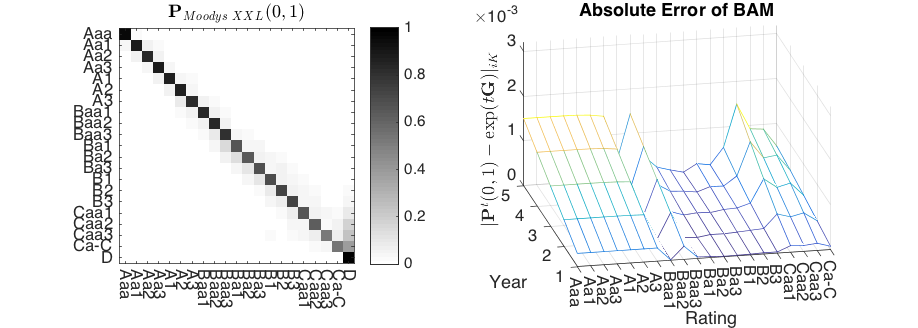
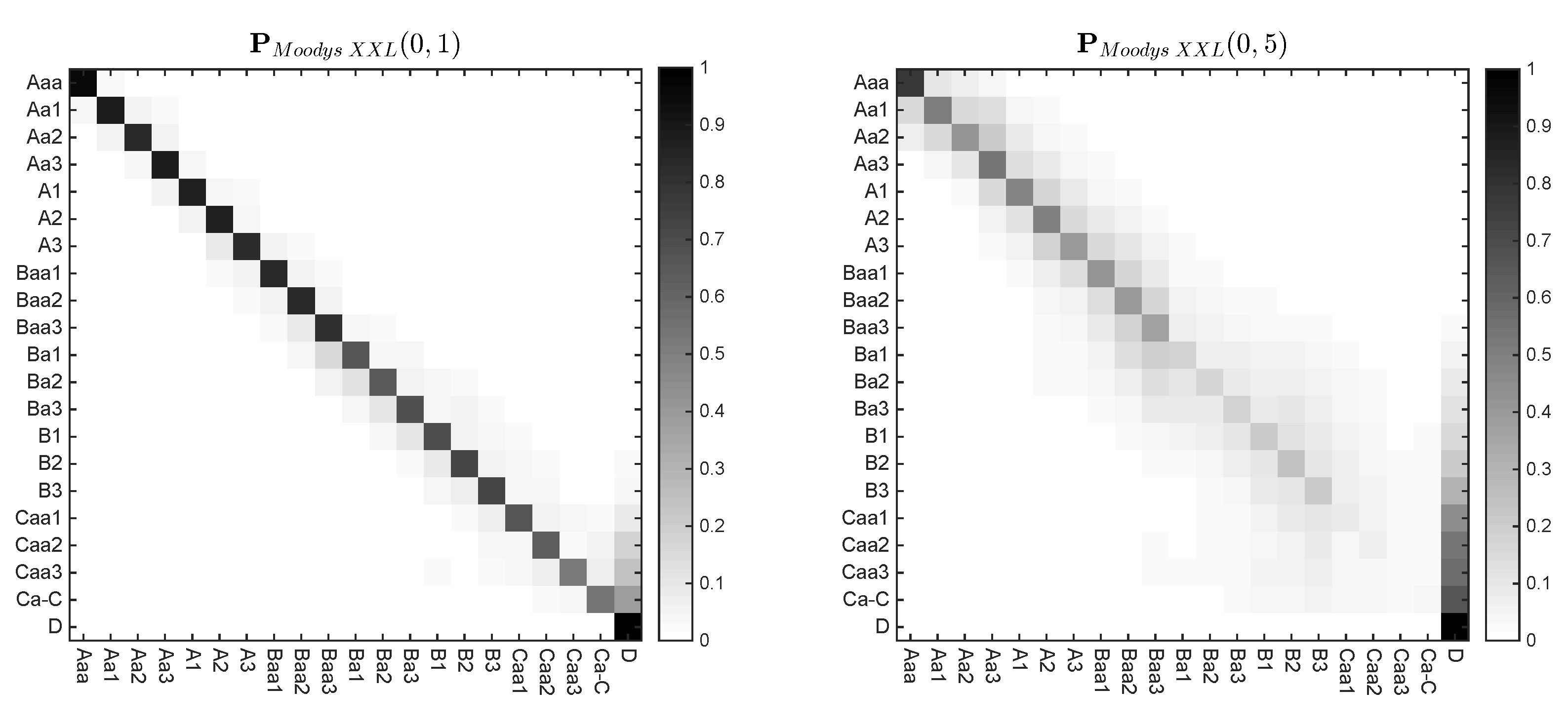
- 5.As can be seen on the right picture of Table A1, the majority of probability mass for lower ratings is shifted from the main diagonal to the default column, revealing a rather atypical transition matrix.
- 6.The principal logarithm of has the nearest negative off-diagonal entry to zero. This also applies to .
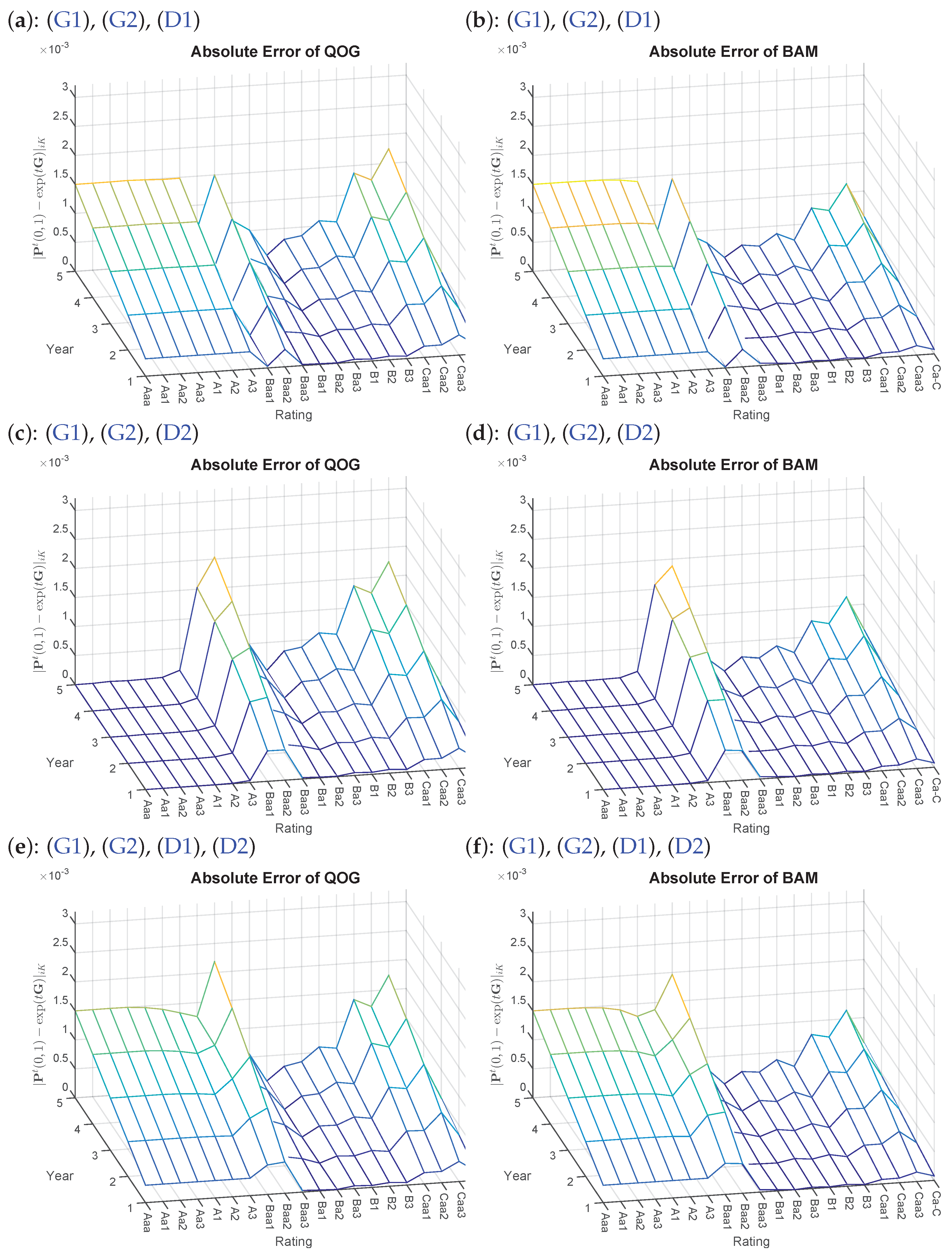
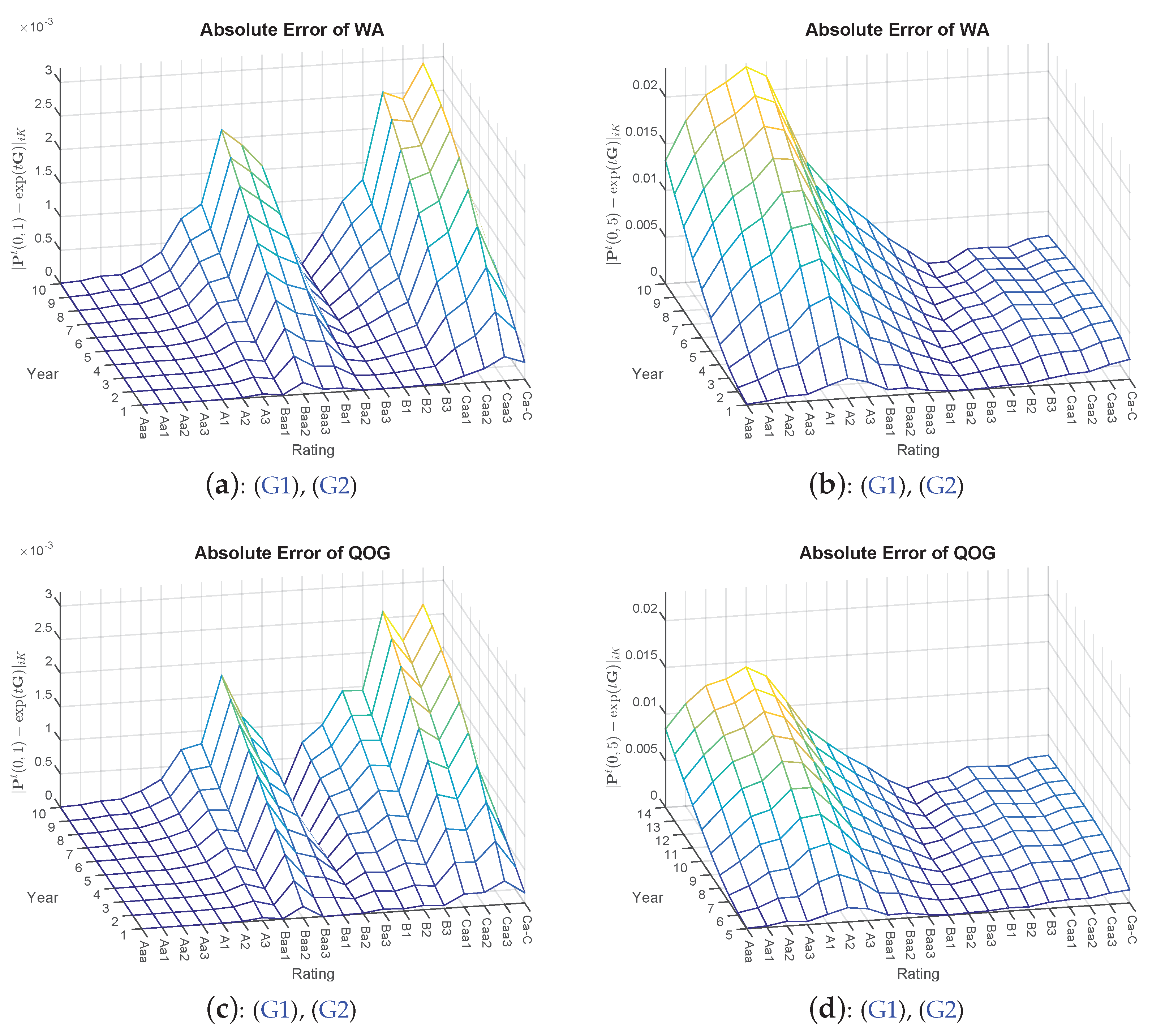
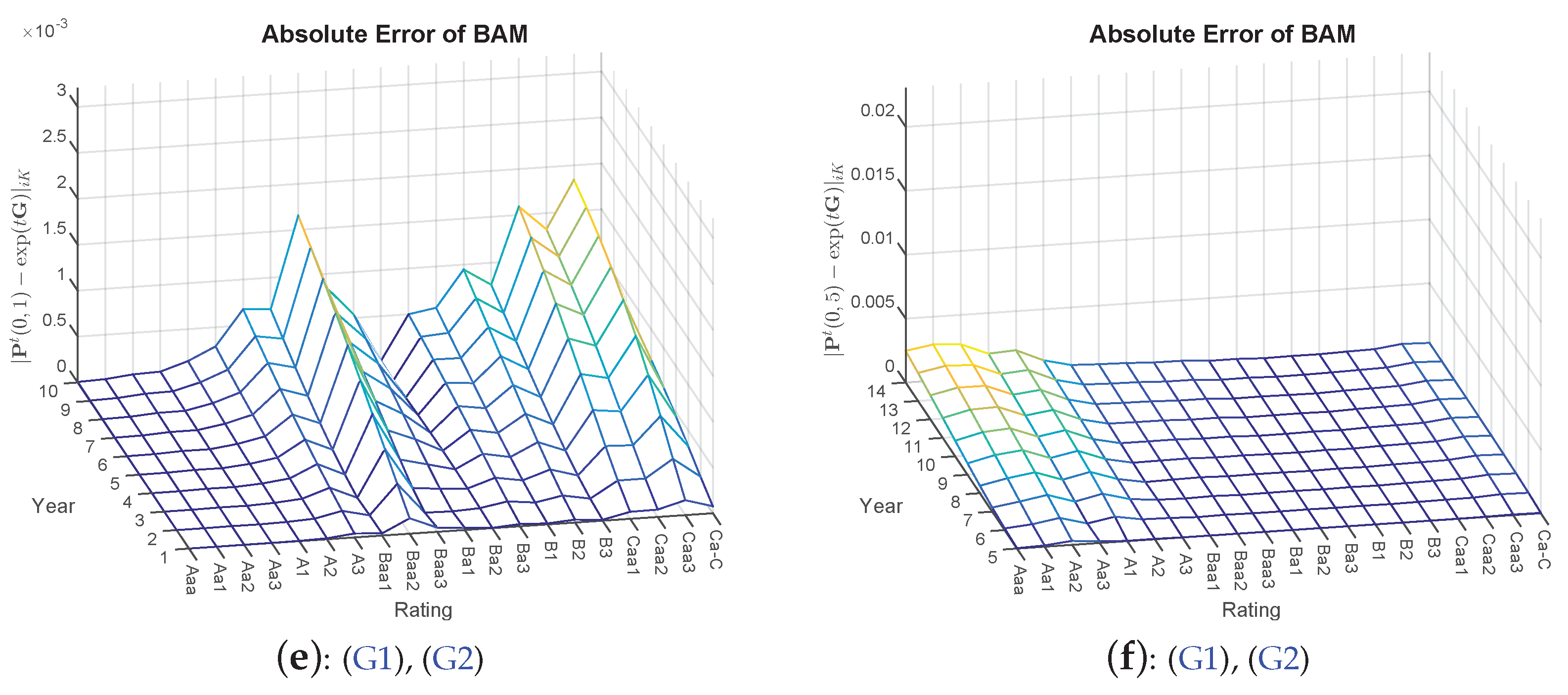
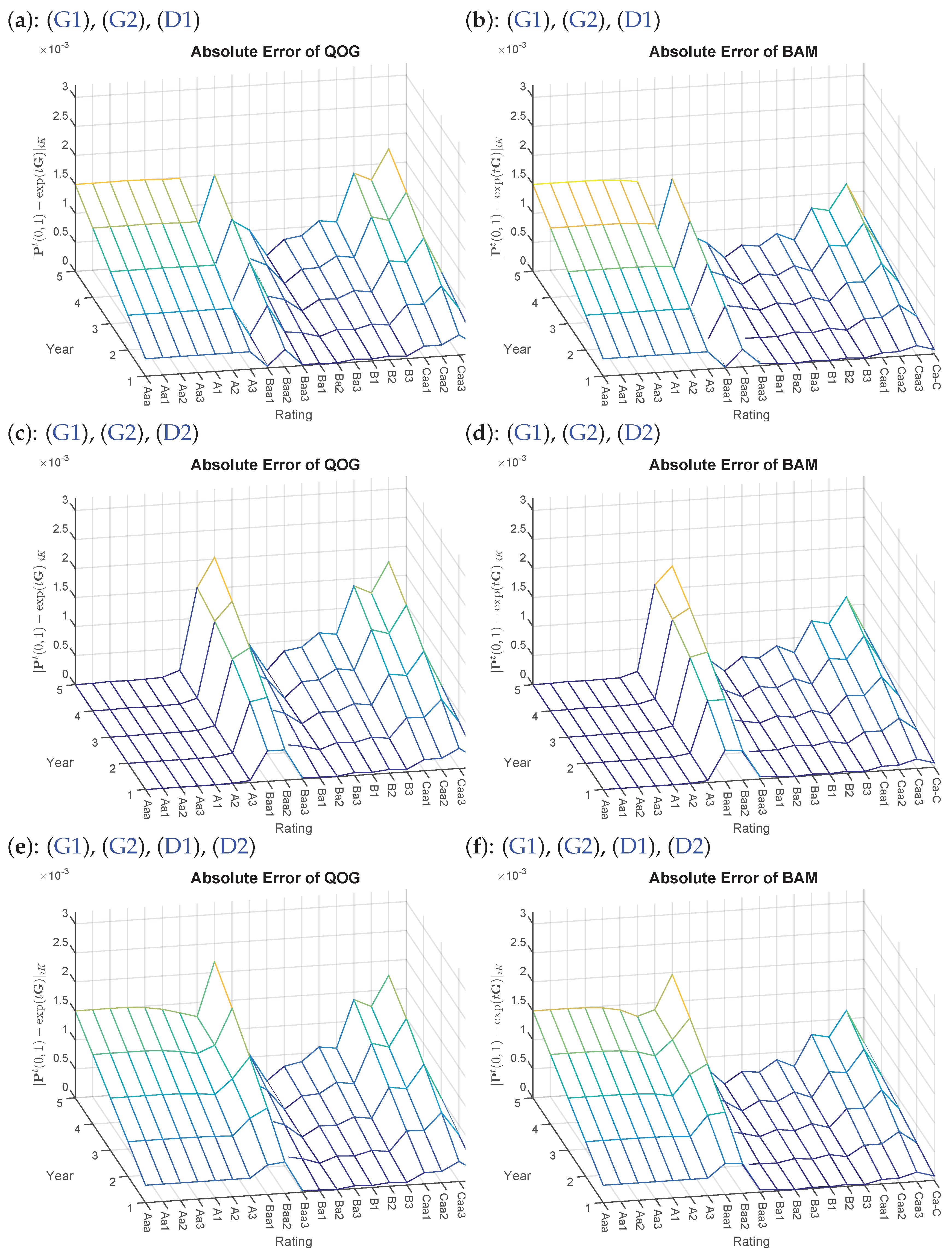
- 7.DA and DMPG are deliberately omitted at this point due to the results in Table 1. Furthermore, the visual depiction of is spared due to too small differences.
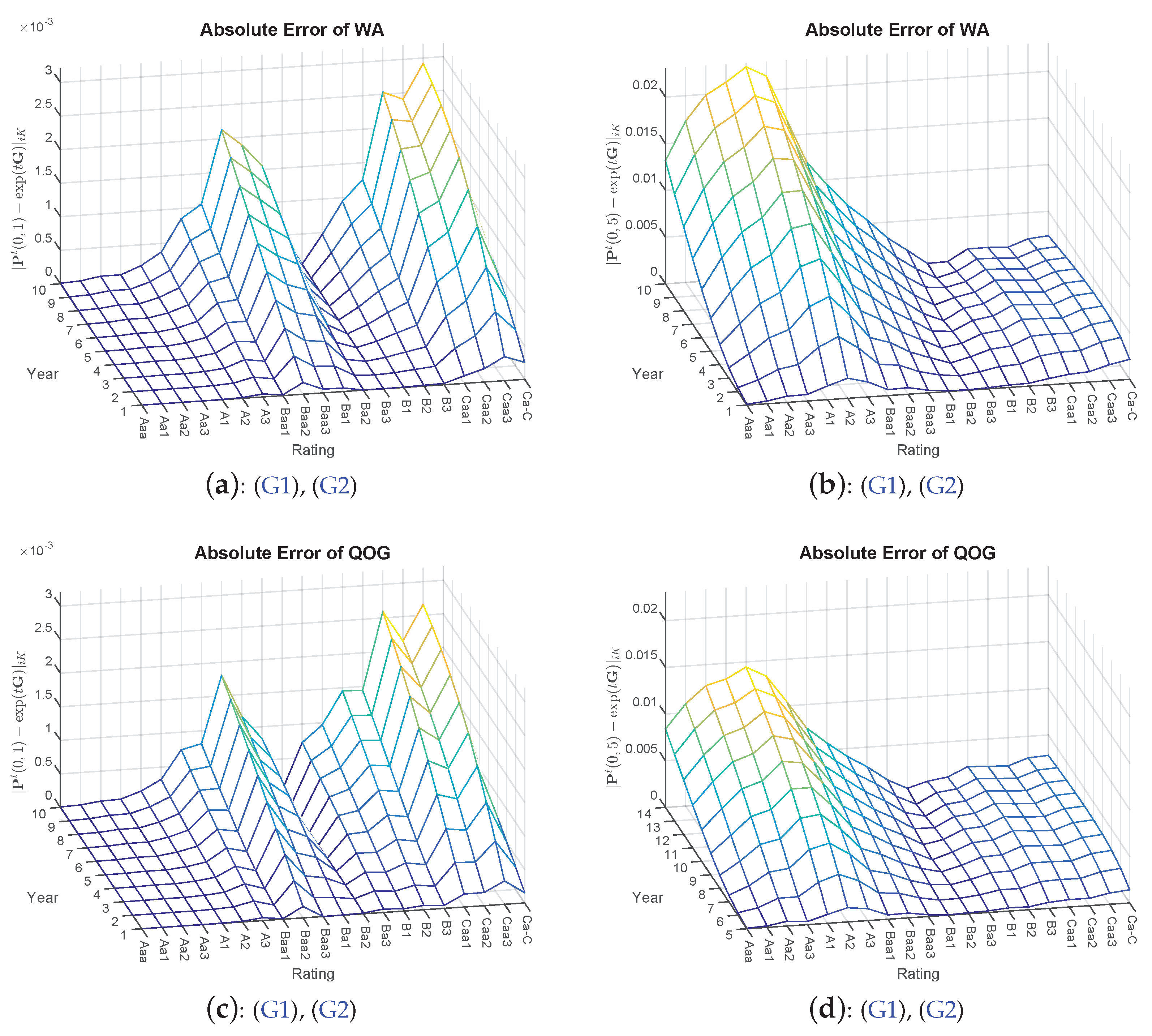
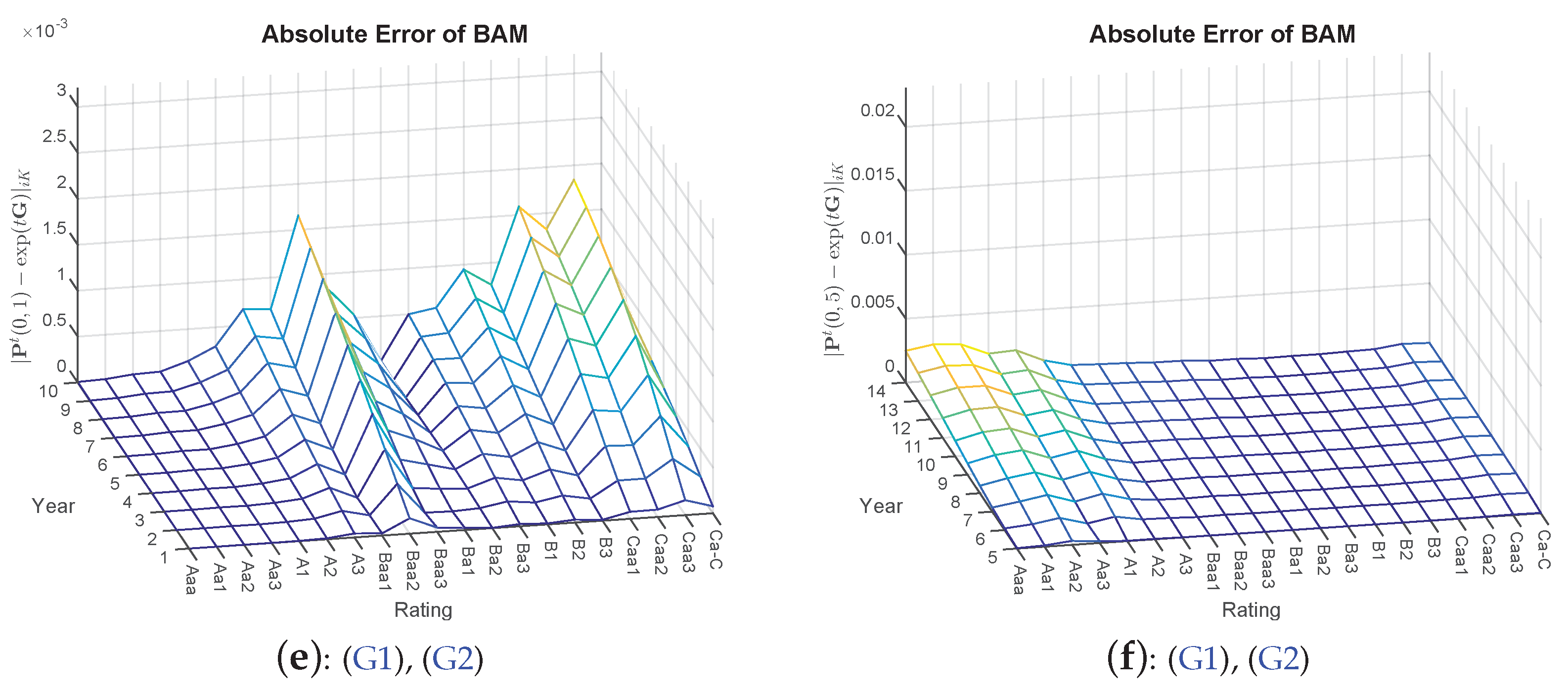
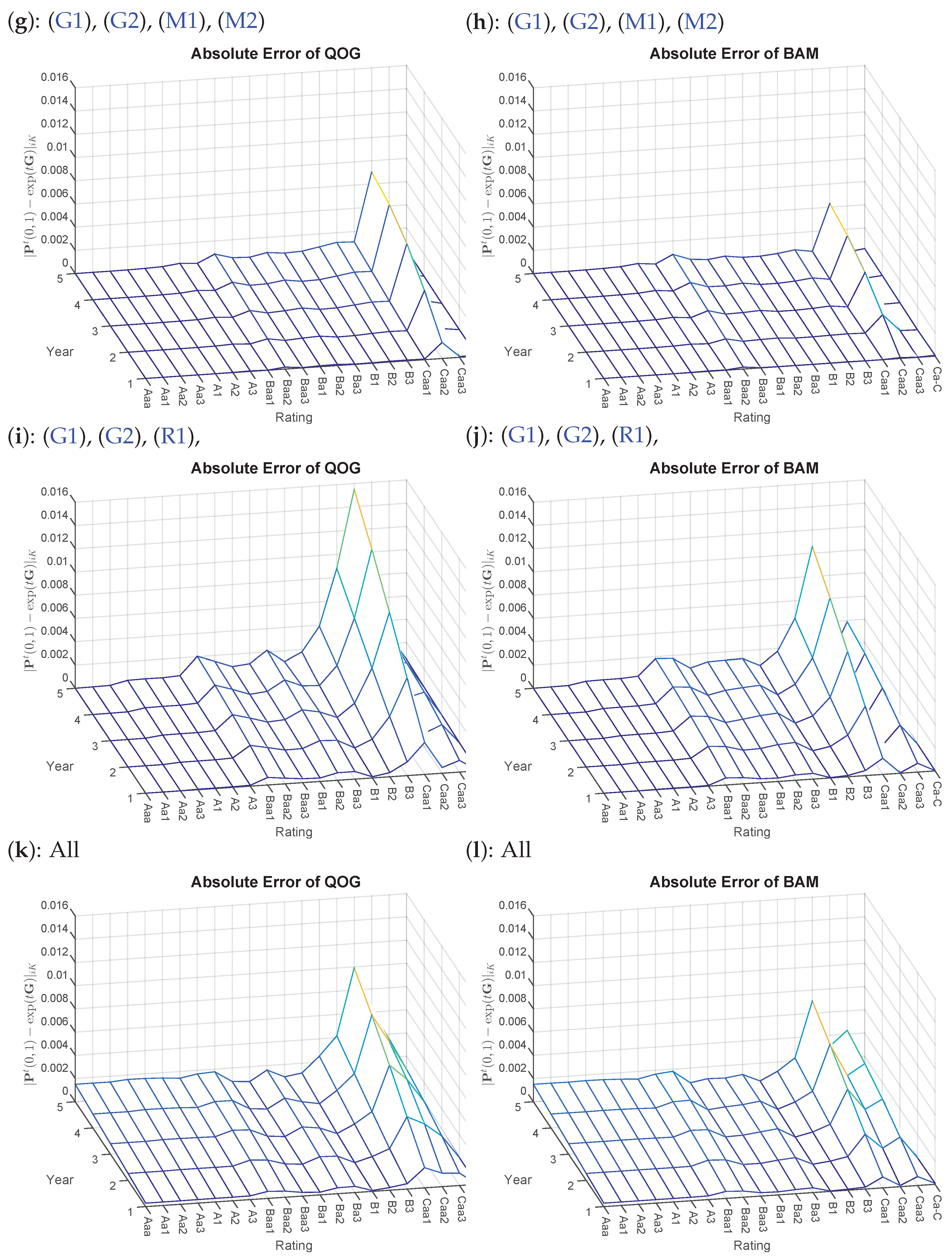
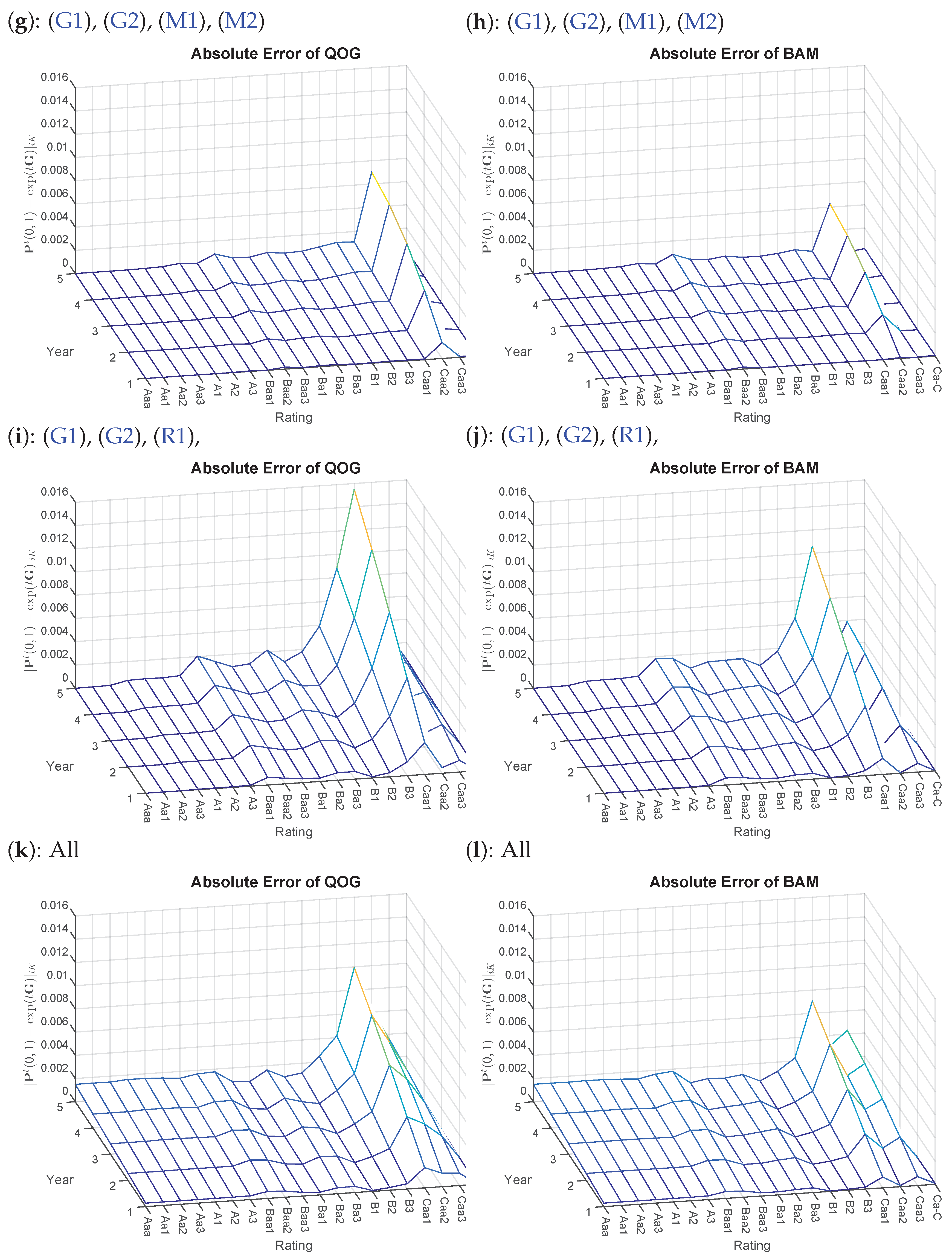
- 8.Again, is omitted, yielding too close results where detecting differences visually is not feasible. Furthermore, is not included, as some of the probability mass has already migrated to the default state; thus, visually, there is not much insight to gain.
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hughes, M.; Werner, R. Choosing Markovian Credit Migration Matrices by Nonlinear Optimization. Risks 2016, 4, 31. https://doi.org/10.3390/risks4030031
Hughes M, Werner R. Choosing Markovian Credit Migration Matrices by Nonlinear Optimization. Risks. 2016; 4(3):31. https://doi.org/10.3390/risks4030031
Chicago/Turabian StyleHughes, Maximilian, and Ralf Werner. 2016. "Choosing Markovian Credit Migration Matrices by Nonlinear Optimization" Risks 4, no. 3: 31. https://doi.org/10.3390/risks4030031
APA StyleHughes, M., & Werner, R. (2016). Choosing Markovian Credit Migration Matrices by Nonlinear Optimization. Risks, 4(3), 31. https://doi.org/10.3390/risks4030031