Abstract
In the aftermath of the financial crisis, it was realized that the mathematical models used for the valuation of financial instruments and the quantification of risk inherent in portfolios consisting of these financial instruments exhibit a substantial model risk. Consequently, regulators and other stakeholders have started to require that the internal models used by financial institutions are robust. We present an approach to consistently incorporate the robustness requirements into the quantitative risk management process of a financial institution, with a special focus on insurance. We advocate the Wasserstein metric as the canonical metric for approximations in robust risk management and present supporting arguments. Representing risk measures as statistical functionals, we relate risk measures with the concept of robustness and hence continuity with respect to the Wasserstein metric. This allows us to use results from robust statistics concerning continuity and differentiability of functionals. Finally, we illustrate our approach via practical applications.
MSC:
91B30; 62G35; 60B10; 60F05
1. Introduction
In the aftermath of the financial crisis, it was realized that the mathematical models for financial markets carry a substantial amount of model risk. Ref. [1], with a discussion from a banking point of view, and [2], who provide an overview with a focus on systemic risk, investigate various aspects of model risk, while [3,4] give some early examples. Accounting for model risk is particularly important for the forecast of risk inherent to portfolios consisting of financial instruments as this forecast is used to calculate economic and regulatory capital within financial institutions. Hence, it is no surprise that if a financial institution opts (e.g., under Solvency II or Basel III) for an application of an internal model, its stakeholders, such as regulators and rating agencies, require that such internal models are reliable. For that reason, the EU directive for Solvency II imposes explicitly that internal models have to meet statistical quality, calibration, and validation standards and have to pass the use test (see Articles 120, 121, 122 and 124, respectively, of the Solvency II directive [5]). By means of these quantitative and qualitative requirements, it is intended to achieve a high level of comfort with respect to the reliability of internal models. Furthermore, regulators require explicitly the robustness of a model as an overarching modelling principle (see [6]). This is especially important because both internal and external model users, who include the results of the models in their decision-making process, are often non-experts in stochastic models. In this respect, robustness of models is a necessary condition to introduce a sustainable risk culture.
Motivated by the above, we pose the problem of a consistent robust modeling approach by considering an axiomatic setting for monetary risk measures that ensures robustness on the one hand and emphasizes the approximative nature of internal models on the other hand by making the need for formulating a suitable distance explicit. Thus, we focus on the statistical robustness of the risk measurement procedure and in doing so complement recent approaches to evaluate model risk as in [7] or to use statistical concepts to evaluate the performance of risk measures as suggested in e.g., [8] or [9].
Within our approach, we consider risk functionals, which treat risk measures on the level of distributions, and allow so to exploit established statistical theory. Risk functionals are typically not continuous with respect to the weak topology as this topology ignores the tails of the distribution. Ref. [10] pointed out this fact and suggested to use a stronger topology. We will thus use robustness in the sense of continuity with respect to an appropriate metric, namely the Wasserstein metric, which was introduced in a general setting in [11] and in the financial context in [12] (p. 79), as the uniform metric between inverse distribution functions. Our approach is in line with [13,14], who provide extensions and introduce an index of qualitative robustness, and the approaches suggested by [15], who prefer robust methods for estimating parameters (Value-at-Risk, expectations, etc.) of forecast distributions. Our framework allows for utilisation of several results that have been established recently in [16].
In addition, we provide various real-life examples to support and to emphasise the applicability of our results. We thus extend and clarify results in [17], who provide real-life examples that highlight the need for robust models for both valuation and calculation of risk in order to control model risk. In addition, in an insurance context [18] recently, applied robust methods to the estimation of loss triangles.
2. A Suitable Distance for Risk Management
We consider monetary risk measures that are related to capital requirements. These risk measures, ρ, are typically introduced for (random) financial positions X defined on an appropriate probability space by
where denotes the space of real valued bounded functions.
We refer the reader for definitions and the various variants of monetary risk measures to [19,20]. Important for us is the contribution by [21], who introduced natural risk statistics. This concept bridges the gap between risk measures and statistics by defining natural risk statistics on a sample space in contrast to the definition of risk measures on a probability space (1).
In situations when we are dealing with possibly unbounded financial positions X, the space is not suitable. Following the observation of [22] that Orlicz spaces or Orlicz hearts (see Proposition 2 below) are appropriate in this case, [16] show that for is an Orlicz heart and thus can serve as a space of financial positions. In fact, based on [23], Theorem 2.10 of [16] shows that law-invariant convex risk measures on has a unique extension to (convex, monotone, and lower semicontinuous with respect to the -norm), which inherits continuity properties.
In order to discuss the robustness (estimation) of risk measures, we need the following concept:
Definition 1.
Statistical functional. Let denote the set of all cumulative distribution functions on and an appropriate subset. We consider maps
Now, let be a sample from a population with distribution function and empirical distribution . If a statistic can be written as a functional T of , say , then we will call T a statistical functional.
This is particularly important as we assess the risk of a financial position X with distribution function F. Typically, we will use a Monte Carlo simulation or a sequence of historical data. For law-invariant ρ, a natural estimate of is , where is the empirical distribution function and
Now, robustness of the risk measure ρ can be related to continuity of . Here, robustness refers to a certain insensitivity of ρ to variations in the approximating distribution for F. For this, the concept of continuity is crucial.
Note that any statistical functional can be approximated with , provided that is in a neighborhood of F and the functional T is sufficiently well behaved. This leads us to consider F as a “point” in and to investigate continuity, differentiability and other regularity properties for functionals defined on (subsets of) .
In order to define these concepts properly, we need to introduce:
Definition 2.
Simple probability metric. Let be a convex class of distribution functions on containing all degenerate distributions. A mapping
is called a simple probability metric (or distance) if
- 1.
- ,
- 2.
- ,
- 3.
- .
Unfortunately, there are plenty of possible metrics to choose. In order to select a specific metric as a preferable one from a practitioner’s point of view, two questions have to be answered:
- Does the chosen metric fit well in the context of application, i.e., has the chosen metric a natural interpretation? Is it perhaps the canonical metric for a particular field of application?
- Is the metric not too strong? This means—do we have a sufficiently rich set of continuous objects?
The following example lists very common risk measures that should fit into the risk measurement framework from a practitioner’s point of view.
Example 1.
Examples of statistical functionals and risk measures: The central piece of many (internal) risk management models is risk measures such a Value-at-Risk (VaR) and Tail-VaR (TVaR). We give representations of these important risk measures as statistical functionals. Let be the empirical distribution function related to a given data set. In addition, recall that, for a cumulative distribution function F, the (upper) quantile of order is defined as .
- Value-at-Risk. For a fixed (usually ), we define the Value-at-Risk at level α (VaR) asThe statistical functional for estimating Value-at-Risk is thenwhere puts mass one to .
If we substitute F for in the examples above, we obtain the associated risk measures. In particular, any law-invariant2 risk measure can be written as a statistical functional (see [19] for further discussion). For the VaR, this yields . From (4) and (5), we conclude the important role of the empirical distribution for determining risk measures. Hence, a metric for risk management should be based on the whole cumulative distribution function.
We now turn to the question of robustness of risk measures in more detail. Given that we want to use the empirical distribution in praxis, we need to specify how to quantify the effect of a small deviation from the true distribution on the risk measure. We need the following definition:
Definition 3.
Continuity of statistical functionals. Let be a convex class of distribution functions on containing all degenerate distributions. A functional T defined on is continuous at if
where denotes a distance of two distribution G and F.
In the axiomatic approach of [24], the continuity of a risk measure is not required. Consequently, the class of coherent risk measures includes discontinuous risk measures such as the TVaR. Given the approximative character of stochastic models, we think that continuity, and, hence, robustness, are, from a practitioner’s point of view, even more important than subadditivity.
Example 2.
TVaR is not continuous w.r.t. the weak topology: Consider the sequence
where denotes the uniform distribution on and puts its mass one to , . Obviously, converges weakly to :
However, the associated TVaRs do not. For all α, we have:
whereas
is finite.
The above example clearly highlights the fact that risk measures, which put emphasis on the tail of a distribution cannot be expected to be continuous with respect to topologies that ignore the tails of distributions. In contrast, it can be shown that the VaR at level α is continuous w.r.t the weak topology (see Theorem 3.7 in [25]) at if is continuous at α. Given that VaR and TVaR are the risk measures that are of overwhelming importance in practice, we suggest using a metric that implies the continuity of the associated functionals.
We will now discuss properties of a metric that are particularly useful for the risk management process. In terms of practical applications, it is important to strike a balance between properties in the centre of a distribution and its tail behaviour. Thus, as outlined in Example 1, the following requirements are natural in order that the statistical functionals allow for estimating all of the risk measures given in Example 1 consistently:
for some and . Note that the linear functional is now continous in F w.r.t. a given metric. For applications in risk management, the cases and are of particular importance. Thus, we are looking for a metric that combines these two properties.
We will show that with the Wasserstein metric (especially, the case ), both types of risk measures are considered: one-tail measures (such as VaR) and two-tail measures (such as volatility). Hence, this approach comprises both concepts.
We will only need the Wasserstein metric for two distributions on the real line.
Definition 4.
Wasserstein Metric. Let random variables with their corresponding distribution functions. The Wasserstein distance, for two distributions is given by:
For a general definition of the Wasserstein metric in Banach spaces, the reader will find appropriate definitions in [11]. Refs. [26,27] show the equivalence of the above definition with the general case. An example for the use of the Wasserstein metric in the context of investments is [28].
Proposition 1.
Properties of Wasserstein Metric. The Wasserstein metric has the following properties:
- 1.
- For random variables we have the following scaling properties of :The scaling property (8) is important for risk management because it allows the change of numéraire, e.g., change of home currency.
- 2.
- For in andIf and , then we have the regularity property:
- 3.
- Let be independent and assume that the laws are in . Then,This property is key to proving the consistency for bootstrapping mean statistics (see [11]).
- 4.
- The Wasserstein metric is a one-ideal metric (see the Appendix A for a definition of one- ideal).
Example 3.

Wasserstein and distance: For distribution functions, the -distance, is defines as:
We compare this distance with the Wasserstein metric for a standard normal distribution Φ, which we perturbate such that there is a difference in the right tail. Thus, let
where is an exponential distribution. Table 1 shows that the Wasserstein distance increases in p while the distance decreases. Thus, the weighting of differences in the tail increase for the Wasserstein metric in p, while it decreases for .
Table 1.
Wasserstein and distance, .
The convexity properties are closely related to the independence axiom of the Von–Neumann–Morgenstern approach to utility theory. Therefore, the Wasserstein metric fits smoothly into this framework. As the results of the risk measuring exercise need to have an impact on decisions within the company (the use test in Solvency II) and as utility theory is widely used in this context, this is a very desirable property.
Recently, [16] have investigated the robustness properties of convex risk measures, in particular regarding the Wasserstein metric.
Proposition 2.
[16] (Theorems 2.5 & 2.7). Let be a stationary and ergodic sequence of random variables with the same law as 3 with
Then, for a law-invariant convex risk measure ρ with corresponding statistical functional , the estimator
is consistent, that is, as a.s., and continuous with respect to the p-Wasserstein metric4.
The proposition implies, for instance, the continuity of the TVaR w.r.t. the Wasserstein metric.
Many statistical functionals are so-called L - functionals (see [21] for a discussion of the role of L-statistics in terms of natural risk measures). We can relate them to the Wasserstein-metric with the following:
Theorem 1.
Continuity of L-statistical functional w.r.t the Wasserstein metric. Let T be an L-statistical functional of the form
for , , and J a weights generating function bounded on [0,1]. Then, T is continuous w.r.t to Wasserstein metric .
Proof.
The claim follows as a special case from [16], Proposition 2.22. We provide an independent proof in the Appendix B. □
Theorem 1 implies the continuity of mean, trimmed mean, and TVaR w.r.t. the Wasserstein metric. □
As we discussed above, we extended the classical concept of qualitative robustness, which is based on the weak topology, by using a more suitable topology, and therefore we made it useful for tail sensitive functionals such as most risk measures. Ref. [16] propose the alternative notion of ψ-robustness. Here, is a left-continuous, nondecreasing convex (Young) function, which we call weight function in the following. We denote by the set of all probability measures5 on and by the set of all probability measures μ on with . Additionally, we have to impose a product structure on the underlying probability space, setting , for , , and, for , .
Definition 5.
Qualitative robustness and ψ-robustness. Let , and let and be metrics on and , respectively. The functional is called (qualitatively) -robust with respect to and , if for all and , there exist and such that
Let ψ be a weight function. A risk functional is called ψ-robust on if is robust with respect to and on all subsets , which are uniformly integrating, that is
The key inside (already pointed out in [10]) is that, when insisting on distances that generate the usual weak topology of measures, one can have distributions that are rather close in the weak topology but will have completely different tail behaviour. Thus, the notion of robustness should allow an insensitivity with respect to tail behaviour. As [16] point out, the Prohorov distance
and the Prohorov metric
are appropriate choices. Ref. [16] (Theorem. 2.14 rso Theorem 2.25) characterize robust risk measures rsp. show that it is sufficient to study law-invariant convex risk measures on .
A special case for , the function that is also implicitly used in Proposition 2, allows for stating the result for the p- Wasserstein metric.
Proposition 3.
Every law-invariant convex risk measure , is -robust with respect to the p-Wasserstein metric.
In particular, the proposition shows that the TVaR is -robust for any . The value at risk is qualitatively robust even in the classical sense, that is, with and equal to the Prohorov metric and (see ([14], Example 4.3 )).
Example 4.
Wasserstein metric for p=1: for heavy tailed distributions as they appear in finance, the mean absolute deviation is preferable, due to its robustness properties. Hence,
where denotes the median, is a suitable substitute for , and thus for volatility-sensitive risk measures, in (6) which is much more in line with our overall robustness approach. In requiring
We are in the setting of the Wasserstein framework. Note that for the case, we have:
This may be used with advantage, when we consider Fréchet differentiable functions. Following [29], we consider the following norms:
For , this means that if a statistical functional is strongly differentiable w.r.t supremum norm, then it is automatically differentiable with respect to the sum of the Wasserstein and supremum norm.
This norm implies, for statistical functionals which satisfy a Fréchet differentiability condition, that jackknifing and bootstraps yield consistent estimators.
3. Application of the Wasserstein Metric in Risk Management
This section is devoted to exemplifying the importance of the Wasserstein Metric by analyzing application from real-life risk management.
Example 5.
Consistency of summary statistics and estimated capital requirement: nearly any statistical analysis starts with the computation of a table of summary statistics comprising means such as the expectation, standard deviation, skewness and kurtosis, and quantiles such as the interquantile range and other characteristics.
Of course, the minimum requirements for interpreting these statistics would be that the statistics are consistent estimators for the associated parameter. Obviously, for means and quantile types of statistics, a convergence with respect to the Wasserstein distance would imply consistency. Hence, also for statistical analysis, the Wasserstein metric is quite natural for bridging the gap between descriptive statistics and inferential type approaches. This is very much in line with the approach advocated by [30].
To see the importance of consistency in regulation, we consider an important risk measure under Solvency II: the Solvency Capital Required, denoted by . Note that is defined by a difference6 of a quantile and an expectation, which we can write as a difference of statistical functionals i.e.,
In the light of (19), the Wasserstein Metric for is sufficient to ensure the continuity of the functional S at F:
if
Example 6.
Robustness and materiality: the implementation of internal models calls for a concept of materiality that allows for working with various proxies. In light of Example 2, the sequence of distributions seems to provide a good approximation for the uniform distribution U, due to the fact that
w.r.t. the weak topology; roughly speaking: the error is arbitrarily small, hence immaterial. However, neither the TVaR nor the expectation is a continuous functional at U with respect to the weak convergence. If the SCR is based on (19)—or if we substitute by , as it is proposed under Basel III—the SCR is difficult to be used as a yardstick to gauge the materiality of proxies, if the considered risk functional is not continuous or respectively robust. However, the choice of the Wasserstein metric for allows for judging the materiality of the error. Note that from a mathematical point of view, materiality is closely related to robustness and continuity.
Example 7.
Test statistic consistently chosen to the natural distance: in light of the previous examples, it is natural to use the Wasserstein Metric for in the context of risk management. In the process of the application of an internal model, a number of statistical analyses are necessary, especially in the validation process (see Article 124 of the Solvency Directive [5]).
Due to simplicity in practical risk management applications, tools in software packages available are often applied for statistical tests. A point in case is the application of the Kolmogoroff–Smirnow test statistic, which is based on the Kolmogoroff–Smirnow distance as defined in (25):
However, from a principal point of view, it might be questioned whether this is a suitable test statistic for a given problem at hand.
Again, we advocate the application of the Wasserstein distance () as a test statistic. The distribution function of this test may be determined by the application of the bootstrap. For a sample of size , Table 2 contains the distances
between the empirical distribution function, , and some estimated parametric models , namely the Normal, Gamma and Generalized Extreme Value distribution.
Table 2.
Wasserstein metric, multiplied by 100.
Real life examples have shown that results based on the application of the Kolmogoroff–Smirnow test yield very different results comparable to those based on the Wasserstein Metric. Due to the lengthy exposition, however, we omitted these examples in this exposition.
Instead, we consider in the following situation only the output of a Monte-Carlo simulation from an internal model in terms of the Wasserstein metric. Though Monte-Carlo simulations have a number of advantages, it is often very cumbersome to figure out relationships. For that reason, we approximate the output by some parametric densities. Table 2 shows for various companies (denoted by ) the Wasserstein distance between the empirical distribution function and fitted parametric models as outlined above. From this table, we may conclude which parametric model might be chosen per company.
This table may be understood in analogy to those cases where the well-known Kolmogoroff distance is applied and used as a test statistic. From Table 2, we might conclude that the Normal distribution as a simple fitting does not perform badly from an overall perspective. Of course, the Gamma distribution seems to be preferable; however, it has more parameters than the Normal distribution. The performance of the Generalized Extreme Value (GEV) distribution is very volatile; it performs well in some cases, very badly in others. Of course, it would be possible to support these judgements by some formal tests by bootstrapping the Wasserstein distance. However, given the case that the simulation is based on 10,000 scenarios, the result is quite clear.
Example 8.
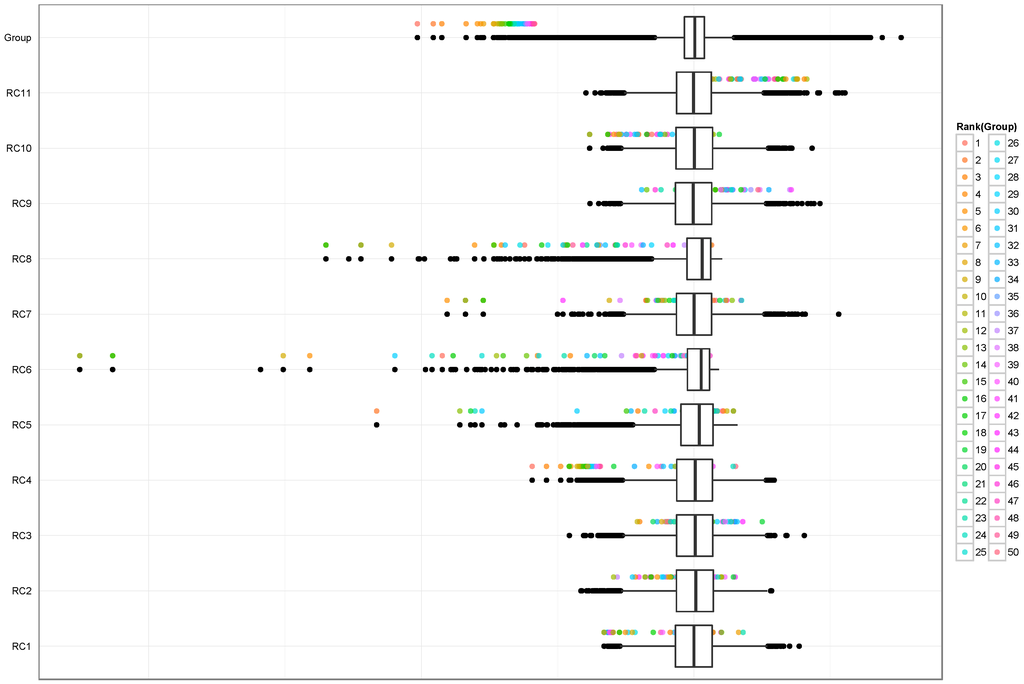
Is the focus of risk management just on the tails? Typically, risk management is focused very much on the tails of distributions, where very adverse events are modeled. The risk measures , and all the progress made in the application of Extreme Value Theory over the last decade confirms this attitude. We think this is completely right; however, the following real-life example highlights that tails alone do not tell the whole story.
This example is taken from the aggregation of risks. Aggregation in itself is of highest importance due to the measurement of the amount of diversification induced by the considered method of aggregation.
The aggregation considered in Figure 1 is based on a so-called factor approach. In this framework, n scenarios of a common set of risk factors related to a number of risk categories are simulated. The result is a matrix. For each column, the portfolio is evaluated and yields n potential changes of the considered portfolio.
Figure 1.
The sequence of box plots and related outliers represent distributions from eleven risk categories that are aggregated and displayed in the first box plot from above. The coloured points above the box plot for the aggregate depict the fifty worst case scenarios. These worst case scenarios are traced back to the risk categories by coloured dots. As the graphs show, these fifty worst cases for the aggregate are not necessarily located in the tail for the contributing risk categories. Hence, the risk management cannot only focus on the tails but on the whole distribution function. The Wasserstein distance fits to this need in a very particular way.
The first box plot of Figure 1 is related to an insurance company, whereas the other eleven ones belong to risk categories such as market risk, natural catastrophes and others. With coloured points, the fifty most adverse scenarios or events are depicted. It is important to note that, for the risk categories, these fifty scenarios are related to realizations that are not necessarily located in the tail. It is interesting to see that these fifty scenarios are spread across the whole body of the distributions involved. In order to build an adequate risk model, it is of crucial importance to ensure that the whole distribution function is correctly specified and not only their tails. The Wasserstein distance fits very well to these needs because it averages the quantiles of a distribution as given in (4).
Example 9.
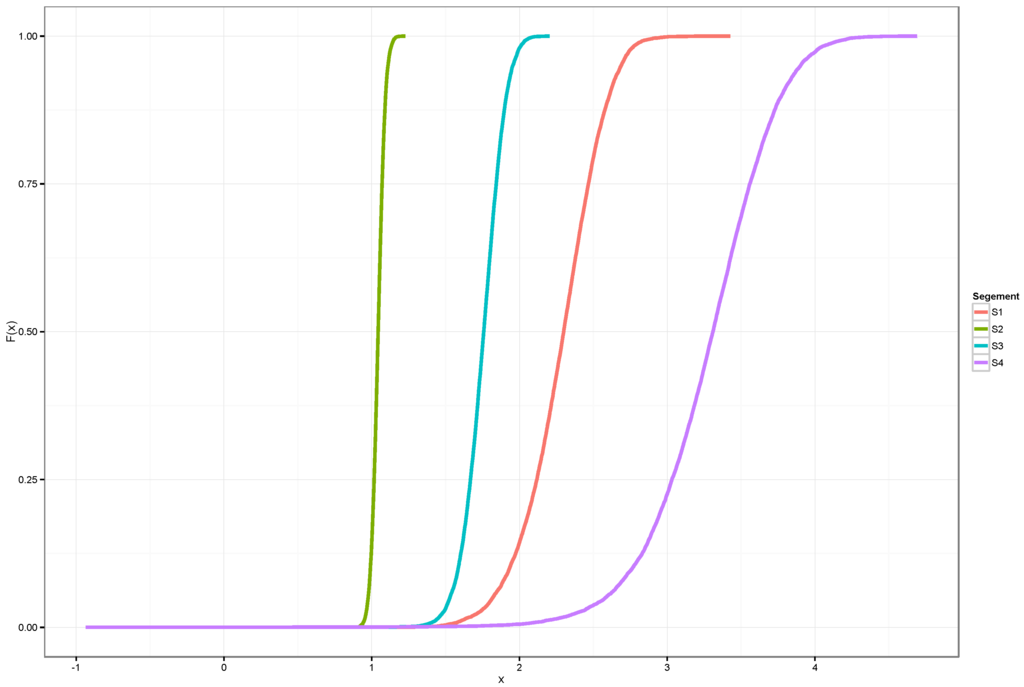
Ranking opportunities: in financial applications, one is often requested to choose one investment out of several ones. This might be achieved by the means a stochastic ordering of the random variables associated with the investment possibilities.
An important approach for ordering is stochastic dominance. Let X and Y be random variables with distribution functions and . Then, X is said to be stochastically dominated by Y, denoted by , if
for all . In many practical circumstances, especially in capital allocation, the random variables involved are stochastically ordered by .
Figure 2 contains such a real-life situation, where the random variables represent divisions of an insurance group. In this situation, the Wasserstein Metric can be easily calculated, if stochastic dominance, can be assumed, then:
Figure 2.
The graph depicts distribution functions that follow a stochastic dominance ordering. The distribution functions may be interpreted as those functions that describe the risk of particular portfolios or segments.
Again, in this situation, the Wasserstein Metric is easily interpreted and calculated.
4. Conclusions
In this paper, we provide a consistent framework for a robust, quantitative risk management process. We argue that various approximations take place in this process and that we can take this into account by using a suitable metric throughout. The Wasserstein metric has convenient properties for applications in risk management, especially its focus on the tails of the distributions. It also features in recent work on the robustness of statistical functionals such as [14,16]. This strengthens our case for the Wasserstein metric as the canonical distance for risk management. The robustness results allow us—together with the concept of natural risk statistics—to recognize the approximative nature of the risk management process in the risk estimation step. We combine these results into the risk management space, adding an ordering to facilitate decision making based on the risk measurements. Several examples show how the process can be applied in practice and provide evidence for the use of the Wasserstein metric in a number of applications within a financial institution.
Acknowledgments
Robin Rühlicke is grateful for partial financial support by Talanx AG.
Author Contributions
G.S., J.Z. and R.R. conceived and designed the experiments; J.Z. and R.R. performed the experiments; G.S., R.R and R.K. worked on the theoretical contributions, G.S. and R.K. structured the results, G.S. and R.K. wrote the final version paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A Ideal Metric
We start our introduction of such a metric by recalling the definition of a probability metric.
Ideal metrics are used in the context of central limit theorems, but their properties are also desirable in financial applications. For example, when comparing portfolios, the regularity property states that adding an independent common subportfolio to two portfolios does not increase their distance (see Chapter 9.3 in [12] for this and other examples).
Definition A1 (s-ideal metric).
Let d be a metric on . For any random variables such that their distribution functions , respectively, are in , d induces a metric
Such a metric is called s-ideal if
- 1.
- for any rvs with , X and Y independent of Z,
- 2.
- for any rvs with and , it holds that
Appendix B Proof of Theorem 1
Let T be defined in (13) with a function J bounded on [0,1]:
then
where . According to Hölder’s inequality,
Let S be the [0,1], , and , then we have
In summary, we can have . Therefore, we can have as .
References
- M. Morini. Understanding and Managing Model Risk: A Practical Guide for Quants, Traders and Validators. New York, NY, USA: Wiley, 2011. [Google Scholar]
- J. Fouque, and J. Langsam. Handbook on Systemic Risk. Cambridge, UK: Cambridge University Press, 2013. [Google Scholar]
- P. Jorion. “Risk Management Lessons from the Credit Crisis.” Eur. Financ. Manag. 15 (2009): 923–933. [Google Scholar] [CrossRef]
- J.C. Hull. “The Credit Crunch of 2007: What Went Wrong? Why? What Lessons Can Be Learned? ” J. Credit Risk 5 (2009): 3–18. [Google Scholar] [CrossRef]
- European Parliament and Council of the European Union. “Directive 2009/138/EC of the European Parliament and of the Council of 25 November 2009 on the taking-up and pursuit of the business of Insurance and Reinsurance.” Off. J. Eur. Union 20 (2009): 7–25. [Google Scholar]
- Committee of European Insurance and Occupational Pensions Supervisors (CEIOPS). CEIOPS’ Advice for Level 2 Implementing Measures on Solvency II: Articles 120 to 126 Tests and Standards for Internal Model Approval. Frankfurt am Main, Germany: CEIOPS, 2009. [Google Scholar]
- P. Barrieu, and G. Scandolo. “Assessing financial model risk.” Eur. J. Oper. Res. 242 (2014): 546–556. [Google Scholar] [CrossRef]
- T. Gneiting. “Making and evaluating point forecasts.” J. Am. Stat. Assoc. 106 (2011): 746–762. [Google Scholar] [CrossRef]
- J. Ziegel. “Coherence and elicitability.” Math. Financ., 2013. [Google Scholar] [CrossRef]
- S. Weber. “Distribution-invariant risk measures, information and dynamic consistency.” Math. Financ. 16 (2006): 419–441. [Google Scholar] [CrossRef]
- P. Bickel, and D. Freedman. “Some asymptotic theory for the bootstrap.” Ann. Stat. 9 (1981): 1196–1217. [Google Scholar] [CrossRef]
- S. Rachev, S. Stoyanov, and F. Fabozzi. Advanced Stochastic Models, Risk Assessment, and Portfolio Optimization. New York, NY, USA: John Wiley & Sons, 2008. [Google Scholar]
- V. Krätschmer, A. Schied, and H. Zähle. “Sensitivity of risk measures with respect to the normal approximation of total claim distributions.” Insur. Math. Econ. 49 (2011): 335–344. [Google Scholar] [CrossRef]
- V. Krätschmer, A. Schied, and H. Zähle. “Qualitative and infinitesimal robustness of tail- dependent statistical functionals.” J. Multivar. Anal. 103 (2012): 35–47. [Google Scholar] [CrossRef]
- R. Cont, R. Deguest, and G. Scandolo. “Robustness and sensitivity analysis of risk measurement procedures.” Quant. Financ. 10 (2010): 593–606. [Google Scholar] [CrossRef]
- V. Krätschmer, A. Schied, and H. Zähle. “Comparative and qualitative robustness for law-invariant risk measures.” Financ. Stoch. 18 (2014): 271–295. [Google Scholar] [CrossRef]
- P. Sibbertsen, G. Stahl, and C. Luedtke. “Measuring model risk.” J. Risk Model Valid. 2 (2008): 65–81. [Google Scholar]
- M. Busse, U. Müller, and M. Dacorogna. “Robust Estimation of Reserve Risk.” ASTIN Bull. 40 (2010): 453–489. [Google Scholar]
- H. Föllmer, and T. Knipsel. “Convex Risk Measures: Basic Facts, Law-invariance and beyond, Asymptotics for Large Portfolios.” In Handbook of the Fundamentals of Financial Decision Making. Edited by L. MacLean and W. Ziemba. Singapore: World Scientific, 2013, Volume II, pp. 507–554. [Google Scholar]
- R. Cont, R. Deguest, and X. He. “Loss-based risk measures.” Stat. Decis. 30 (2013): 133–167. [Google Scholar] [CrossRef]
- C. Heyde, S. Kou, and X. Peng. What Is a Good External Risk Measure: Bridging the Gaps between Robustness, Subadditivity, and Insurance Risk Measures. New York, NY, USA: Columbia University, 2007. [Google Scholar]
- P. Cheridito, and T. Li. “Risk measures on Orlicz hearts.” Math. Financ. 19 (2009): 189–214. [Google Scholar] [CrossRef]
- D. Filipovic, and G. Svindland. “The canonical model space for law-invariant risk measures is L1.” Math. Financ. 22 (2012): 585–589. [Google Scholar] [CrossRef]
- P. Artzner, F. Delbaen, J. Eber, and D. Heath. “Coherent Measures of risk.” Math. Financ. 9 (1999): 203–228. [Google Scholar] [CrossRef]
- P.J. Huber, and E.M. Ronchetti. Robust Statistics, 2nd ed. New York, NY, USA: Wiley, 2009. [Google Scholar]
- G. Dall’Aglio. “Sugli estremi dei momenti delle funzioni di ripartizione doppia.” Ann. Sc. Norm. Super. Pisa 3 (1956): 35–74. [Google Scholar]
- C.L. Mallows. “A Note on Asymptotic Joint Normality.” Ann. Math. Stat. 43 (1972): 508–515. [Google Scholar] [CrossRef]
- G. Pflug, A. Pichler, and D. Wozabal. “The 1/N investment strategy is optimal under high model ambiguity.” J. Bank. Financ. 36 (2012): 410–417. [Google Scholar] [CrossRef]
- B.R. Clarke. “A Review of Differentiability in Relation to Robustness with an Application to Seismic Data Analysis.” Proc. Indian Natl. Sic. Acad. 66 (2000): 467–482. [Google Scholar]
- P. Davies. “Approximating Data.” J. Korean Stat. Soc. 37 (2008): 191–211. [Google Scholar] [CrossRef]
- Sample Availability: Samples of the compounds are available from the authors.
- 1.TVaR is also referred to as Expected Shortfall (ES)
- 2.[15] calls them distribution-free
- 3.The space is called Orlicz heart, see [22]. Actually, as the so-called condition is satisfied, the Orlicz heart coincides with in the current setting.
- 4.This is a consequence of the fact that the condition is satisfied, see [16].
- 5.We restrict ourselves to measures on the real line.
- 6.of course this is due to the fact that we consider the loss in the VaR definition.
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).