In this section, we explain several methods to simulate the ruin probabilities for our model. Initially, we tried the crude Monte Carlo simulation, but as in the classical case, several issues arise, including determining a time range large enough so that it approximates an infinite time ruin probability. Then, we employed the importance sampling technique, which allows us to simulate ruin probabilities under a new measure where ruin certainly happens. However, this does not give us the ruin probability defined in our original problem. Hence, after a deeper analysis, the construction of a Markov additive process assists in developing a more sophisticated importance sampling technique for our model when the inter-claim times, as well as claims are exponentially distributed. Using this Markov additive method, sample paths have been simulated according to the process given by Equation (
42) from which ruin probabilities can be derived. At the end of this section, we present a case study using the crude Monte Carlo simulation where ruin probabilities for our model are compared to the ones under a classical setting, aiming at answering the question of whether the introduction of the dependence structure reduces risks, which originated this work. We also investigate the influence of the two different claim distributions on simulated ruin probabilities.
4.1. Importance Sampling and Change of Measure
One cause of drawbacks when using the crude Monte Carlo simulation is that ruin probabilities are inefficient, i.e., the ruin probability tends to zero very quickly, when the initial reserve u is large. This can be explained by the Cramér–Lundberg asymptotic formula, namely, asymptotically, the ruin probability has an exponentially decay with respect to u. The other reason for not simply adopting a crude Monte Carlo simulation is the fact that we are trying to simulate an infinite time ruin probability under a finite time horizon. In order to overcome this problem, the importance sampling technique has been brought in. The key idea behind it is to find an equivalent probability measure under which the process has a probability of ruin equal to one.
Let us start from something trivial. For the moment, we only consider the “ruin probability” when the time between regenerative epochs is ignored. In other words, we now look at our process from a macro perspective. Since it is a renewal process at each regenerative time epoch, we may omit the situations where ruin happens within these intervals. We refer to it as the “macro” process and its corresponding ruin probability as the “macro” ruin probability in the sequel. We can then define the macro ruin time as:
Consequently, the macro ruin probability denoted by should be smaller than or equal to the ruin probability associated with our actual risk process . However, for illustration purposes, it is worth covering the nature of change of measure under the framework of this macro process first before we dig into more complex details.
Theorem 5.
Assume that there exists a κ, such that . Consider a new measure , such that:with and defined in a similar way. Then, we could establish the same relation as in the classical case for the moment generating function ϕ of , if it exists, Proof.
Rewriting Equation (
25), we derive:
Thus, for
and
, given by Equations (
32) and (
33), respectively,
Note that
have the same form. Then, Equation (
35) can be modified into:
To analyse Equation (
34) further,
can be seen as
shifting to the left by
κ. We know that the NPC for the macro process requires
,
i.e.,
. Additionally, Equation (
23) should have a positive root
κ if the tail of the claims distribution is exponentially bounded. That is to say,
would result in a positive drift of the macro claim surplus process and then cause a macro ruin to happen with certainty. The new m.g.f.
verifies the statement. Hence, we can write a macro ruin probability as:
with
. For a strict and detailed proof, please refer to Asmussen and Albrecher [
15] (Chapter IV, Theorem 4.3). Moreover, from Equation (
34), it follows that:
where
is absolutely continuous with respect to
(up to time
n) with a likelihood ratio,
Define a new stopping time
. Note that the event
is equivalent to
. From the optional stopping theorem, it follows that for any set
, we have:
See ([
15] Chapter III, Theorem 1.3) for more details.
This means that we could simulate macro ruin probabilities under the new measure
where the ruin happens with probability one. We do it using the new law of
given in Equation (
40). To each ruin event, we add weight
where
is the observed macro ruin time. Summing up all events with weights, we derive the ruin probability
. In this way, we can avoid infinite time simulations. For the case where everything is exponentially distributed, as was considered in Example 1, we have that under
, the simulation should be made according to new parameters:
In this case,
has the law of:
where
and
.
4.2. Embedded Markov Additive Process
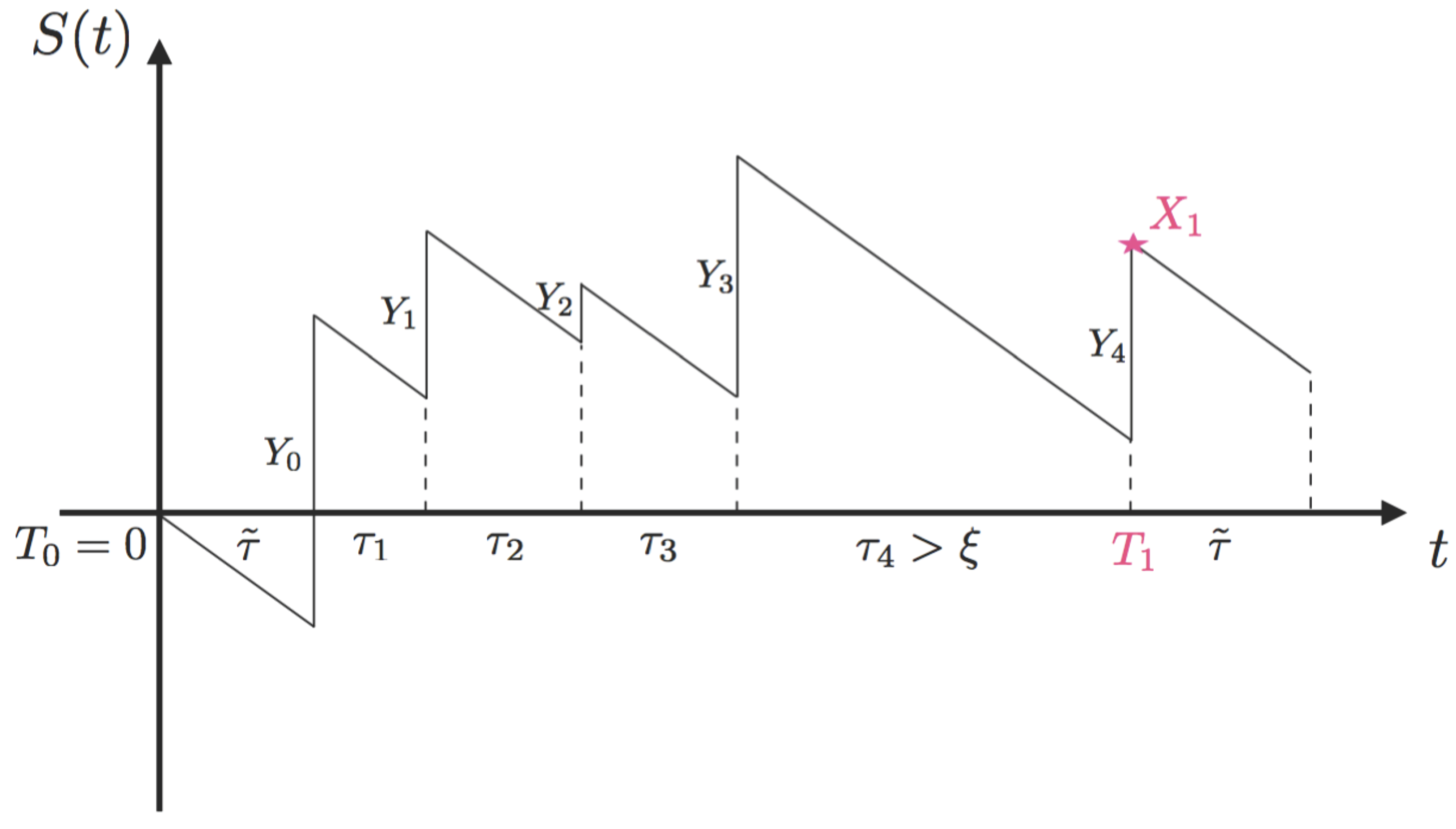
To get more precise simulation results than the macro ruin probability since they are giving a lower estimate only, we have to understand the structure of our process better. To implement this, we will use the theory of discrete-time Markov additive processes. For simplicity, we assume everything to be exponentially distributed with , and , respectively.
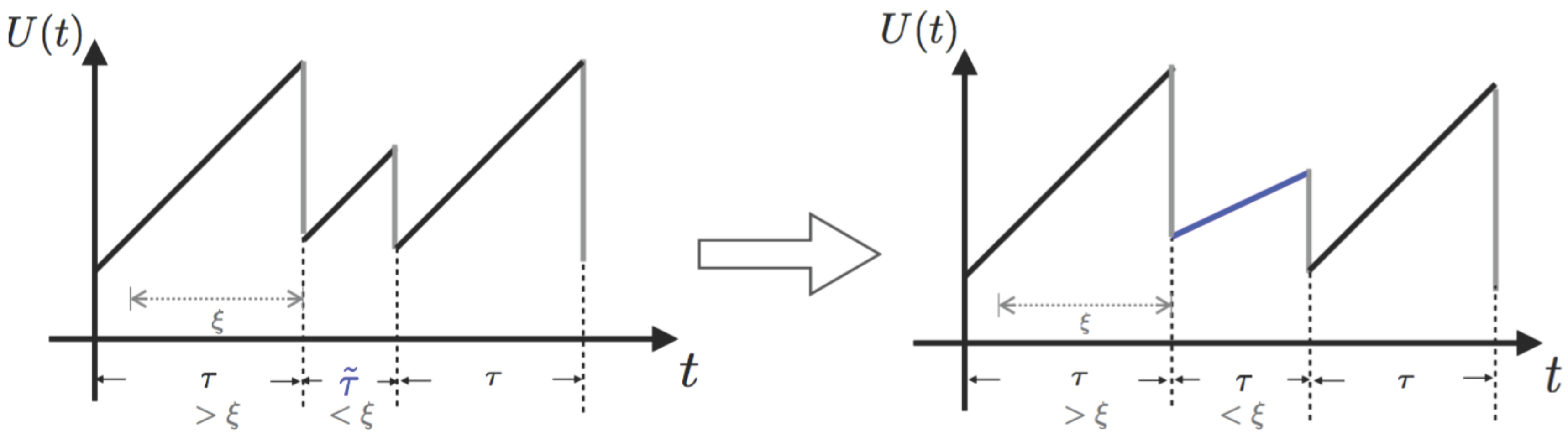
Recall our process as described by Equation (
2) and note that ruin happens only at claim arrivals
for
and
. From time
to
, the distribution of the increment
only depends on the relation between
and
ξ. Hence, we could discretize
given in Equation (
2) to
and, thus, transfer the model into a new one
(
) by adding a Markov state process
defined on
. The index
represents the occupying state of
at time
. For instance, State 1 describes a status where the current inter-arrival time is less than or equal to
ξ, while State 2 refers to the opposite situation. For convenience, we construct
based on the choice of
:
implies
, and
otherwise. Note that the two-state Markov chain
has a transition probability matrix with the
-th element being
, as follows:
where
and
. We also define a new process
whose increment
is governed by
. More specifically, two scenarios could be analysed to explain this process. Given
, Scenario 1 is when
,
i.e.,
and
. Then, comparing
τ with
ξ, there is a chance
q of obtaining
given
and
p having
given
, with the corresponding increment being
and
, respectively. On the contrary, Scenario 2 represents the situation where the current state is
,
i.e.,
and
. Thus, all of the variables above are presented in the same way only with a tilde sign added on
τ,
p and
q.
is a discrete time bivariate Markov process also referred to as a discrete-time Markov additive process (MAP). The moment of ruin is the first passage time of
over level
, defined by:
Without loss of generality, assume that
. Then, the event
is equivalent to
. This implies that:
To perform the simulation, we will derive now the special representation of the underlying ruin probability using a new change of measure. We start from identifying a kernel matrix
with the
-th entry given by
. Here,
and
denote the probability measure conditional on the event
and its corresponding expectation, respectively. Then, for
, an m.g.f of the measure
is
with:
Additionally, based on the additive structure of the process
for
we have,
We will now present a few facts that will be used in the main construction.
Lemma 6.
We have,where is the eigenvalue of and is the corresponding right eigenvector. Proof.
Note that:
where
is a standard basis vector. This completes the proof. ☐
Lemma 7.
The following sequence:is a discrete-time martingale. Proof.
Let
Then,
which gives the assertion of the lemma. ☐
Define now a new conditional probability measure
using the Radon–Nikodym derivative as follows:
Lemma 8.
Under the new measure , process is again MAP specified by the Laplace transform of its kernel in the following way:where is a diagonal matrix with on the diagonal. Proof.
Note that the kernel
of
can be written as:
This shows that the new measure is exponentially proportional to the old one, which ensures that is absolutely continuous with respect to . Further transferring it into the matrix m.g.f. form yields the desired result. ☐
Corollary 9.
Under the new measure , the MAP consists of a Markov state process , which has a transition probability matrix:where:and an additive component with random variables with laws given in Theorem 5 where θ should be chosen everywhere instead of κ. In fact, when
,
coincides with
defined by Theorem 5. Recall
from Equation (
31) and
. Since
, then
implies
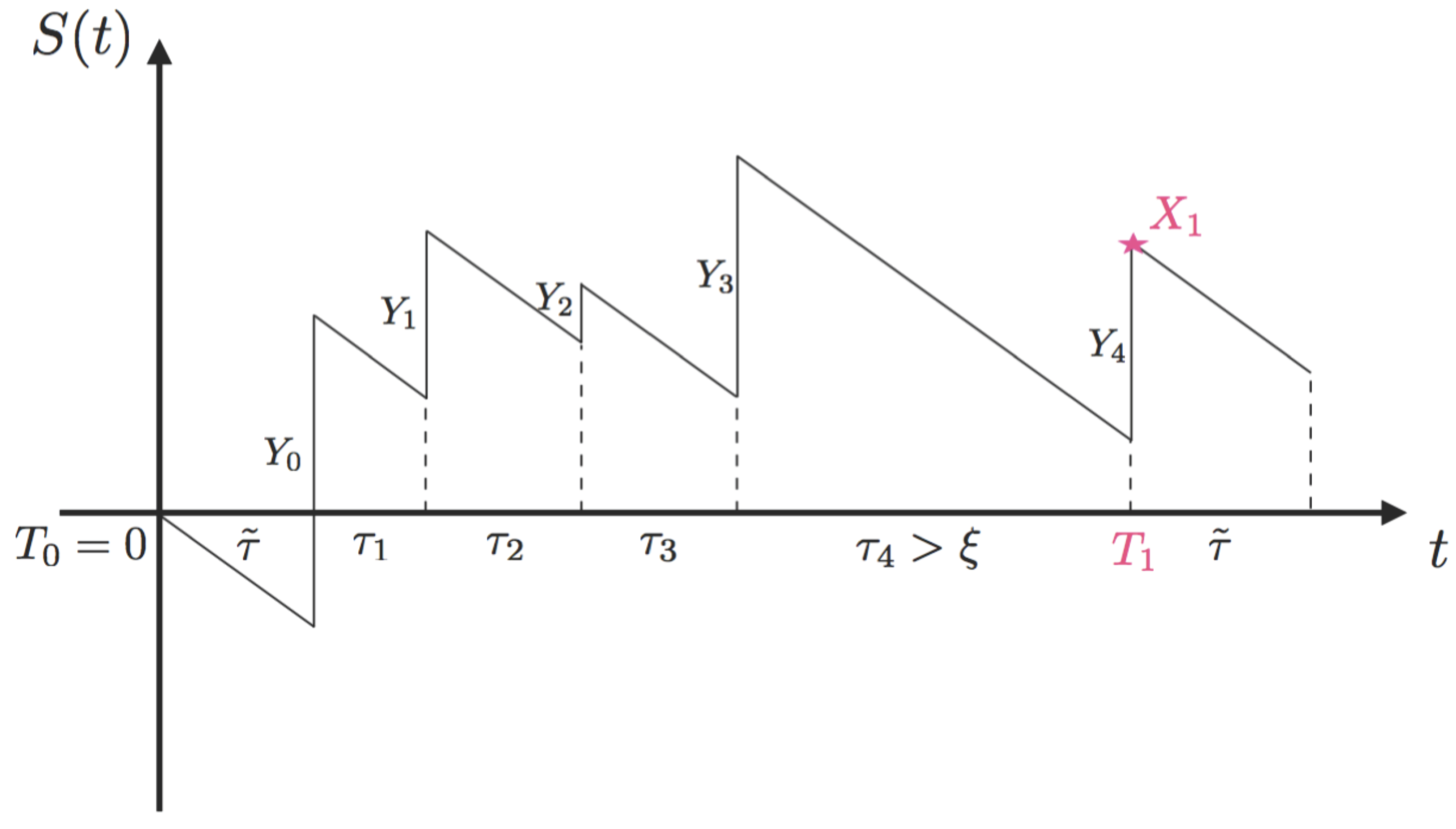
. Now, the main representation used in simulations follows straightforwardly from the above lemmas and the optional stopping theorem, as was already done in the previous section, and it is given in the next theorem.
Theorem 10.
The ruin probability for the underlying process Equation (
2)
equals:where denotes the overshoot at the time of ruin . Proof.
The result follows straight from Lemma 8 and Corollary 9 using the same reasoning as introduced in
Section 4.1. ☐
Now, we will simulate ruin events using new parameters of the model identified in Corollary 9. We start from State 2 of
. We will run our risk process until a ruin event. With each ruin event, we will associate its weight by:
Summing and averaging all weights gives the estimate of the ruin probability .
Remark 3.
In addition, it has been discovered that
has an eigenvalue equal to one and:
is the corresponding right eigenvector. ☐
Proof.
Indeed, let
λ denote the eigenvalue of
. Thus, we can write,
Recall Equation (
22); clearly,
is a solution to the above equation. That directly leads to
, and one can obtain:
Plugging in the parameters completes the proof. ☐
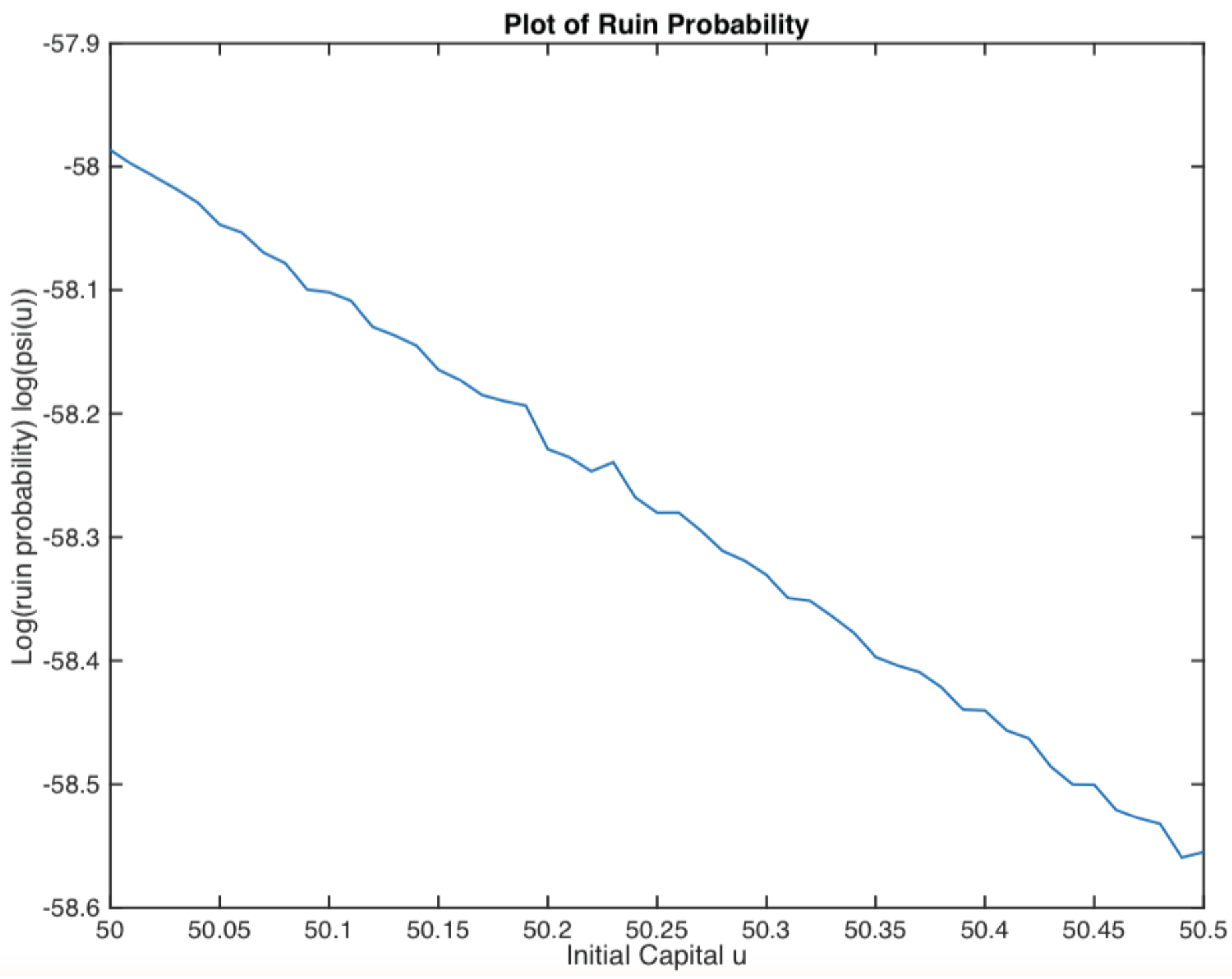
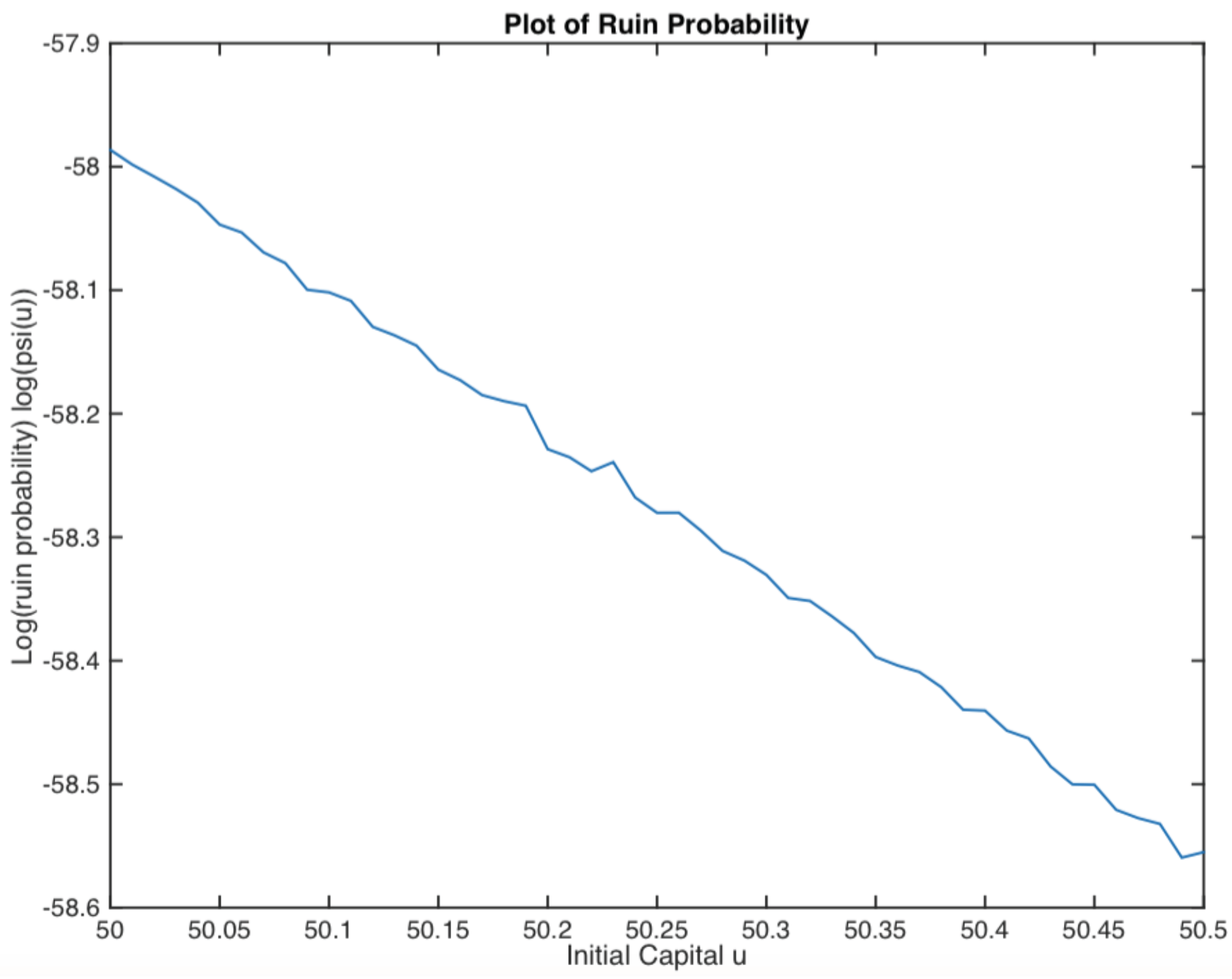
Example 2.
Assume that
Y,
τ and
have exponential distributions with parameters
,
and
, respectively. The smallest positive real root of Equation (
25) is calculated for
, and its corresponding right eigenvector is
. Then, the ruin probability is plotted in
Figure 4. It displays an exponential decay, as we expected.
4.3. Case Study
In this subsection, we derive a few results via a crude Monte Carlo simulation method. The key idea is to simulate the process according to the model setting and simply count the number of paths that get to ruin. Due to the nature of this approach, a ‘maximum’ time should be set beforehand, which means we are in fact simulating a finite time ruin probability. However, this drawback may be ignored as long as we are not getting a lot of zeros.
Our task is to compare the simulated results with a classical analytical ruin function when exponential claims are considered.
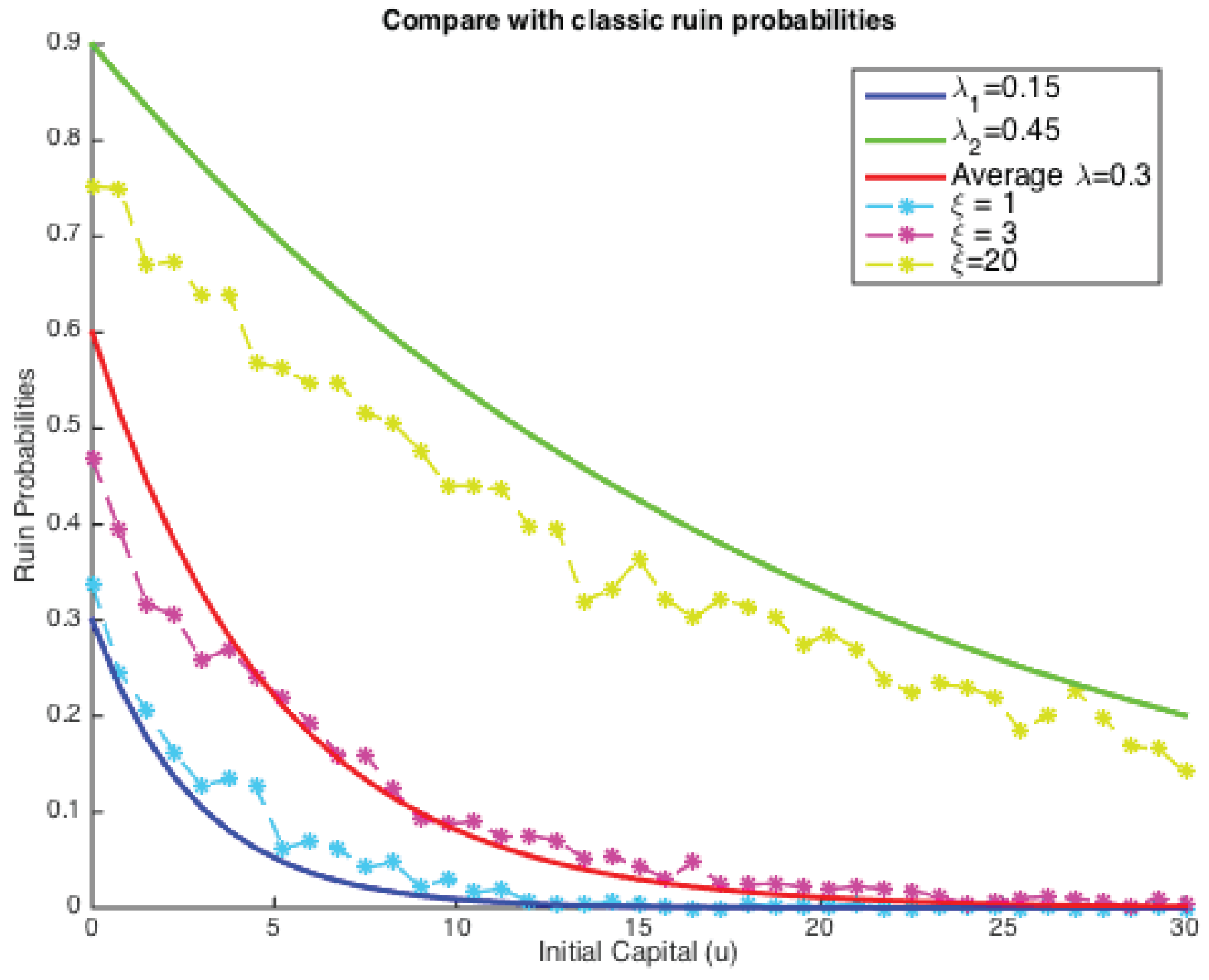
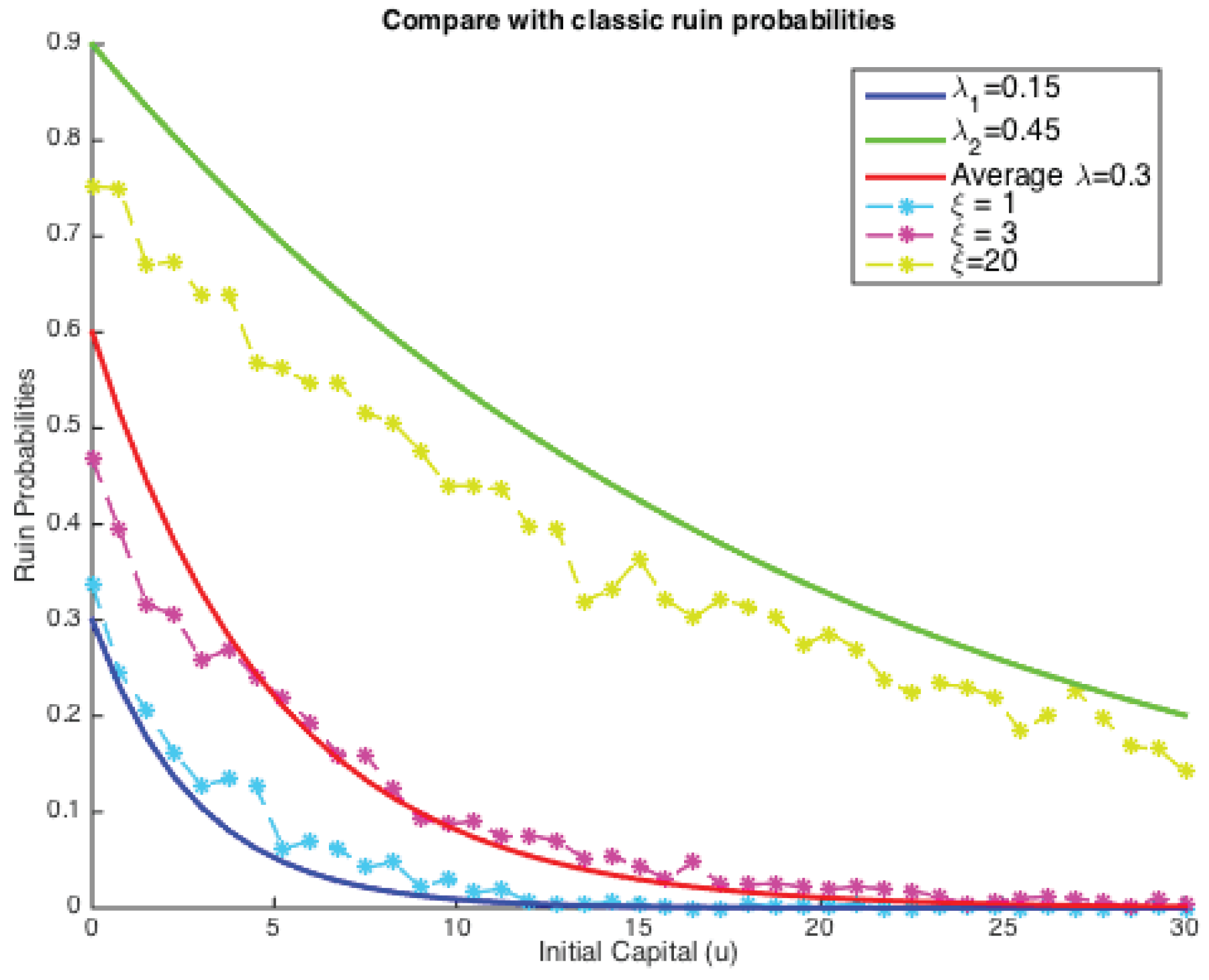
Hence, for the simplest case of exponentially-distributed claim costs, we plotted both the classic ruin probabilities and our simulated ones on the same graph, as shown below (see
Figure 5).
It could be concluded that under two given parameters for Poisson intensity, simulated finite ruin probabilities in our model lie between two extremes, but have many possibilities in between. The comparison depends extensively on the value of ξ. These results also confirmed Theorem 4 that the tail of the ruin function in our case still has an exponential decay, and ξ is strongly related to the solution for κ. In other words, when the dependence is introduced, it is not clear that ruin probabilities would see an improvement.
More precisely, solid lines show classical ruin probabilities (infinite time) as a function of the initial reserve
u, and each of them denotes an individual choice of Poisson parameters (
,
) with the middle one being the average of the other two (
). It is clear that the larger the Poisson parameter, the higher is the ruin probability. On the other hand, those dotted lines are the simulated results from our risk model with dependence for the same given pair of Poisson parameters
and
. The four layers here correspond to four different choices of values for
ξ,
i.e.,
. If
, the simulated ruin probability (in fact finite-time) tends to a classical case with the lower claim arrival intensities (
here), which explains the blue dotted line lying around the dark blue solid line. On the contrary, when
, the simulated ruin probabilities approach the other end. This then triggered us to search for a
ξ, such that the simulated ruin probability coincides with a classical one. Let us see an example here, if:
based on the parameters we chose in
Figure 5. That implies the choice of our fixed window is the average length of these two kinds of inter-arrival times. However, as can be seen from
Figure 5, the dotted line with
lies closer than the one with
to the red solid line. This suggests that the choice of
ξ will influence the simulated ruin probabilities and, thus, the comparison with a classical one. It is also very likely that there exists a
ξ, such that our simulated ruin probabilities concur with the classic ones.
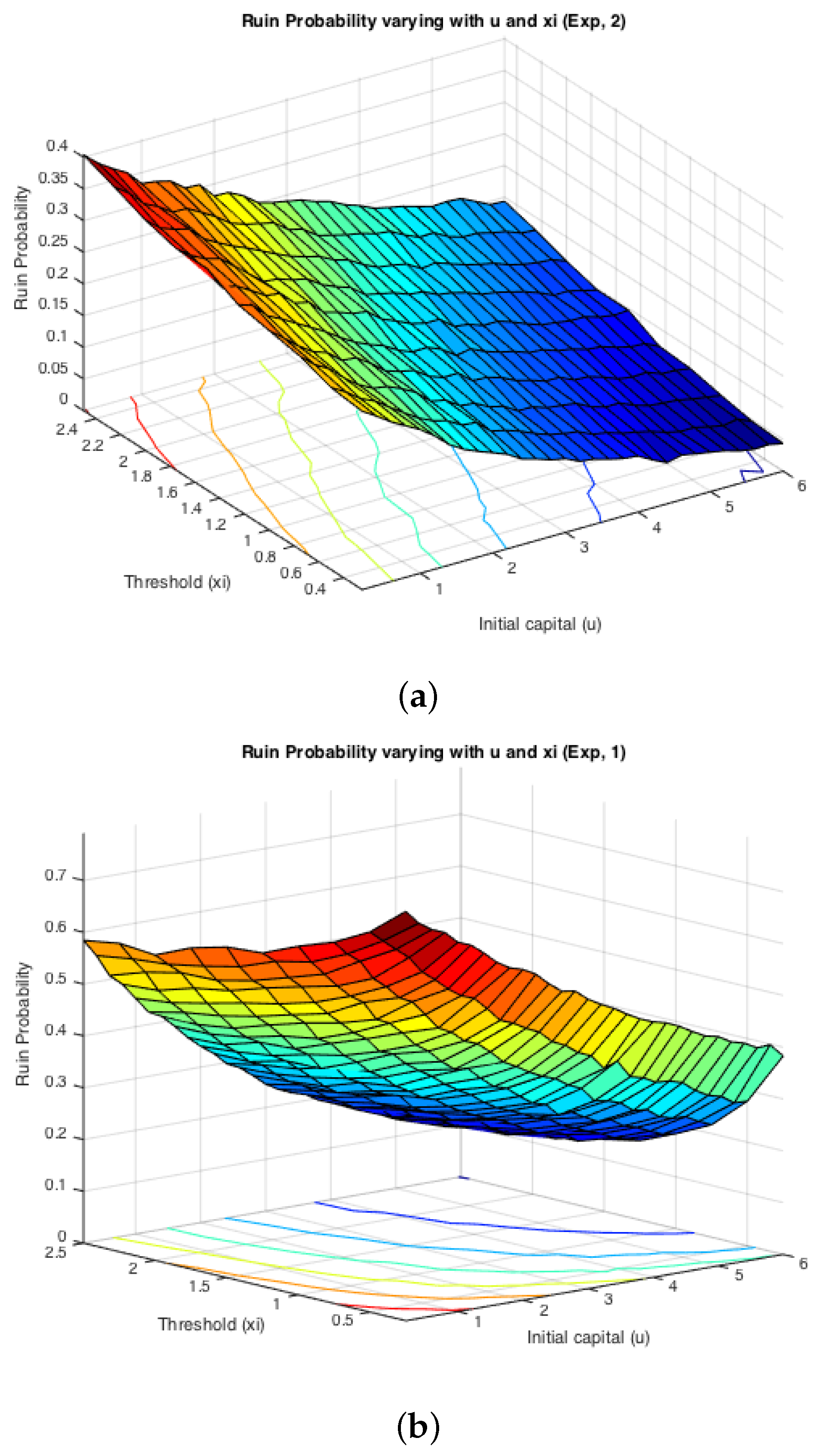
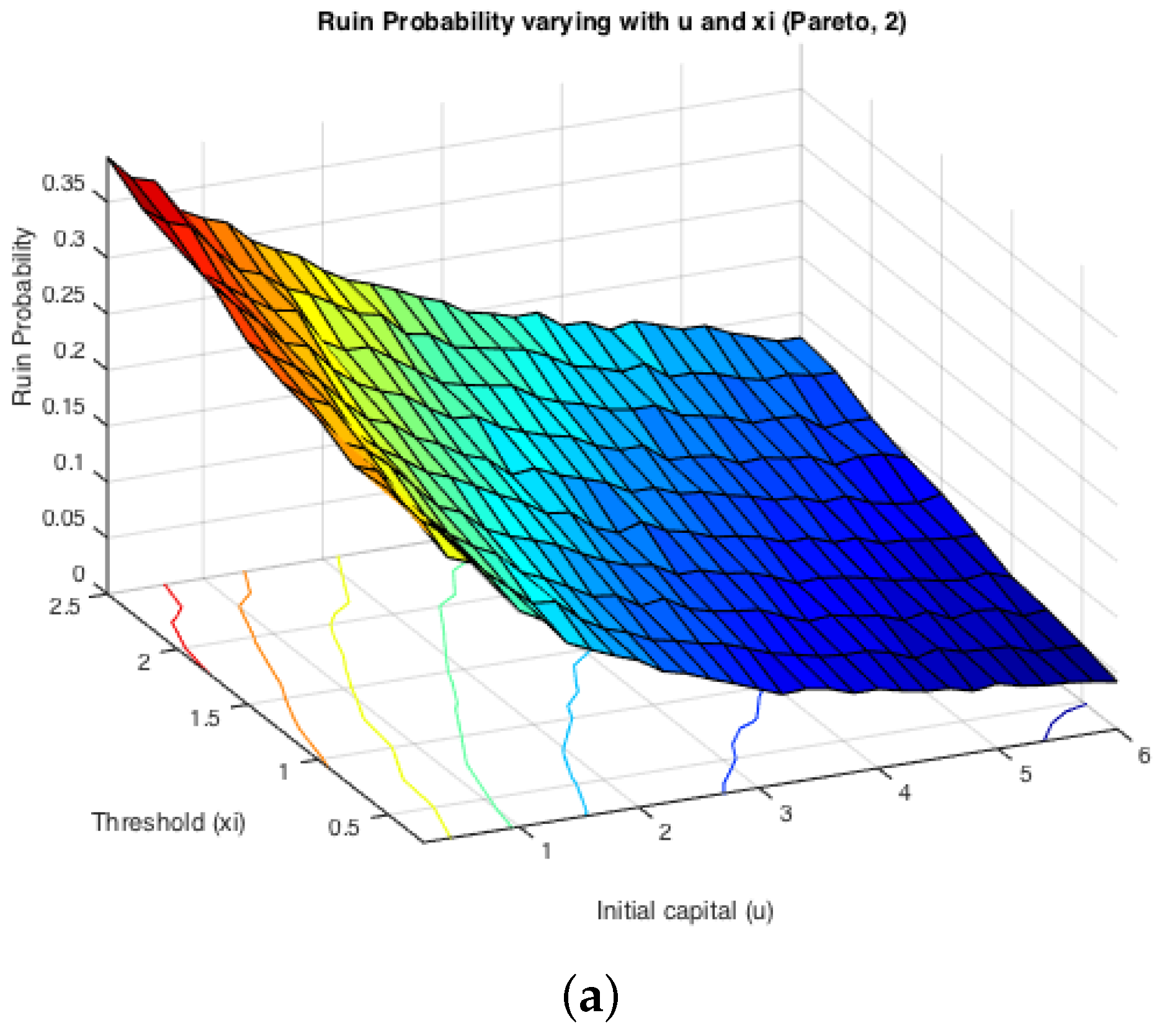
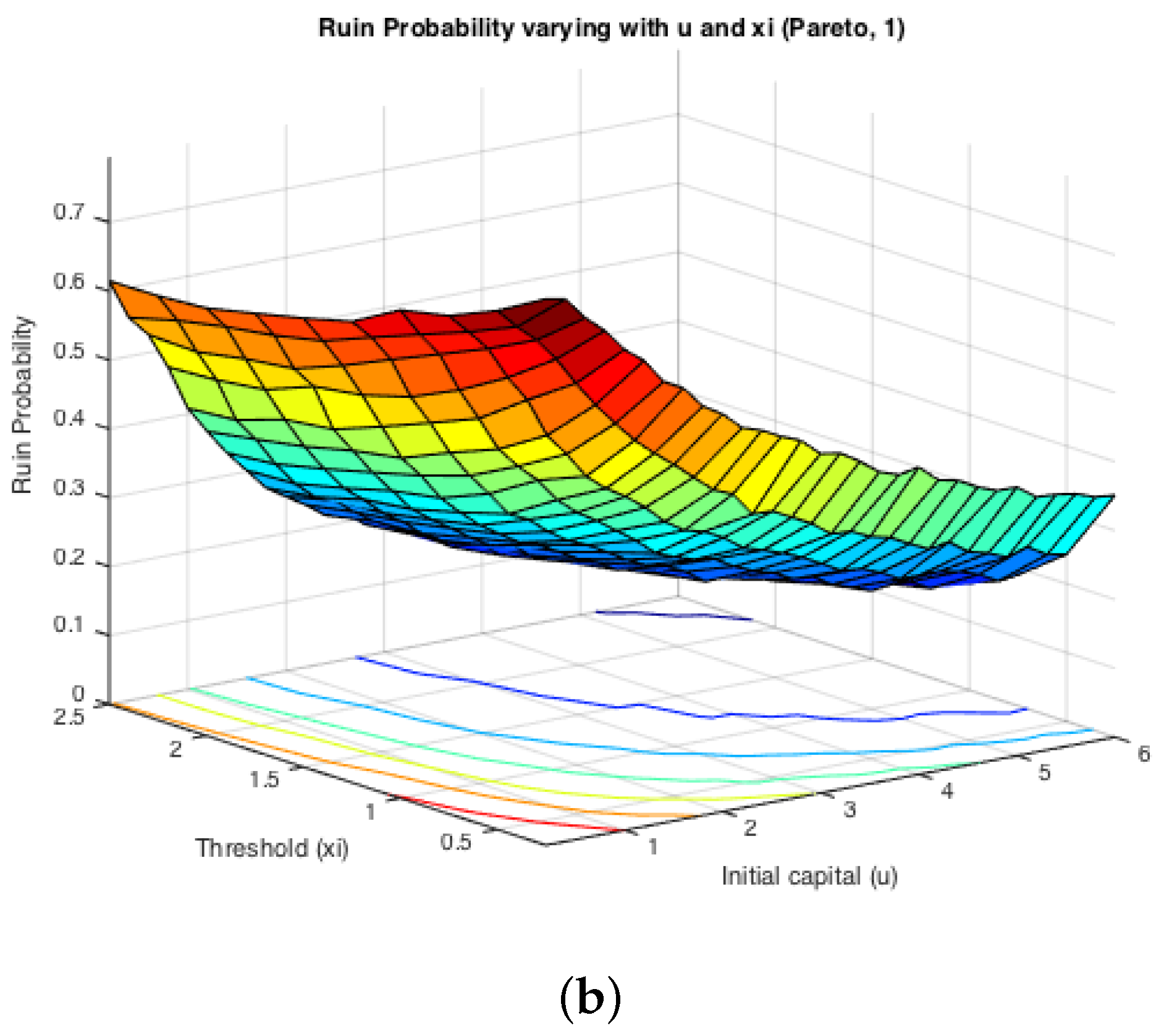
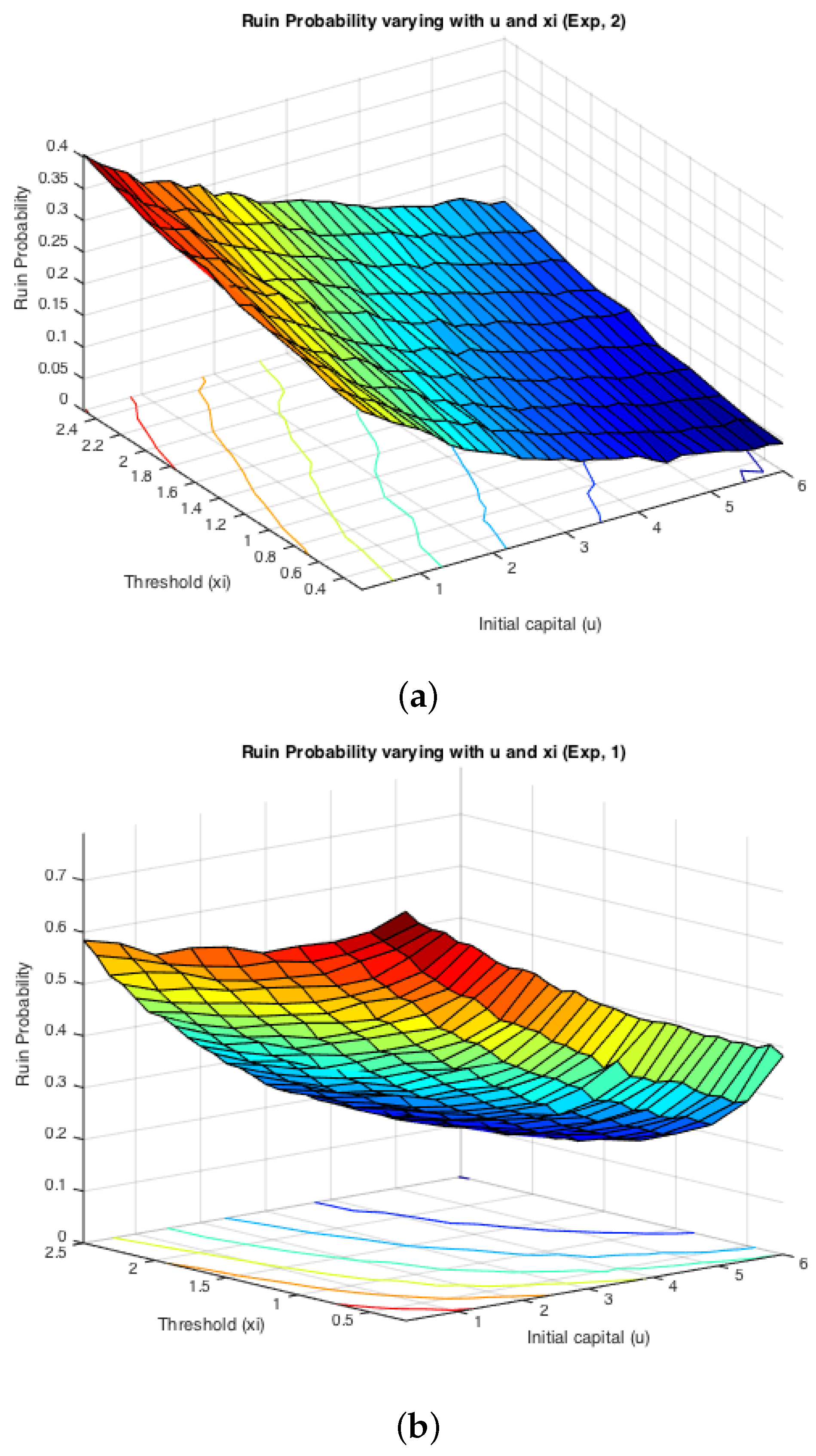
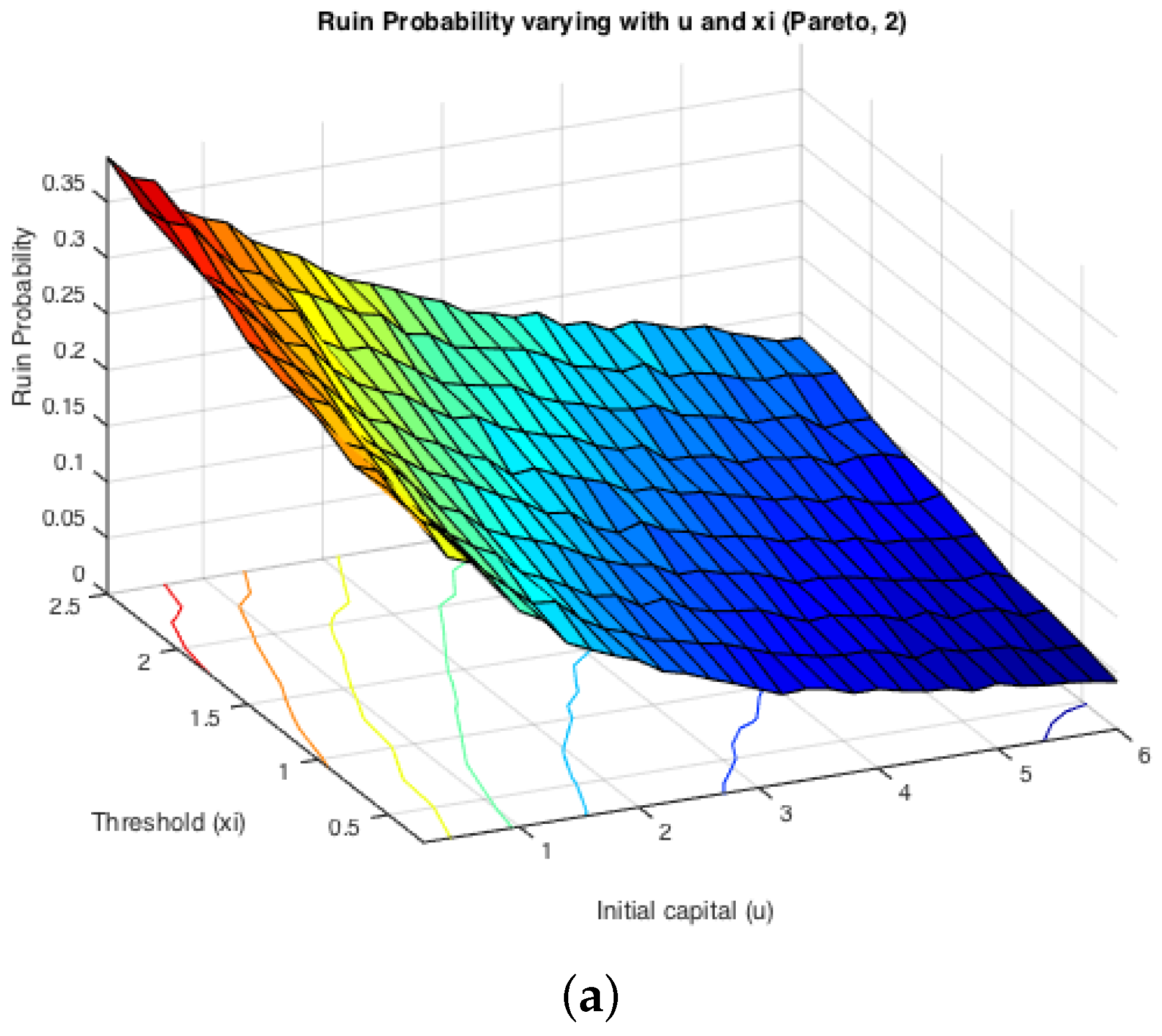
While the first half of the Monte Carlo simulation looked at the influence of ξ on the simulated ruin probabilities, the second step is to see the effects of claim sizes. The typical representations of light-tailed and heavy-tailed distributions, exponential and Pareto, were assumed for claim severities. The inter-arrival times were switching between two different exponentially-distributed random variables with parameters and . Two cases were simulated: either or . It is expected that the effects from claim severity distributions on infinite time ruin probabilities would be tiny, as they normally affect more severely the deficit at ruin. Here, since we actually simulate finite-time ruin probabilities, we are curious whether the same conclusion can be drawn.
Figure 6 displays the two cases for exponential claims, while
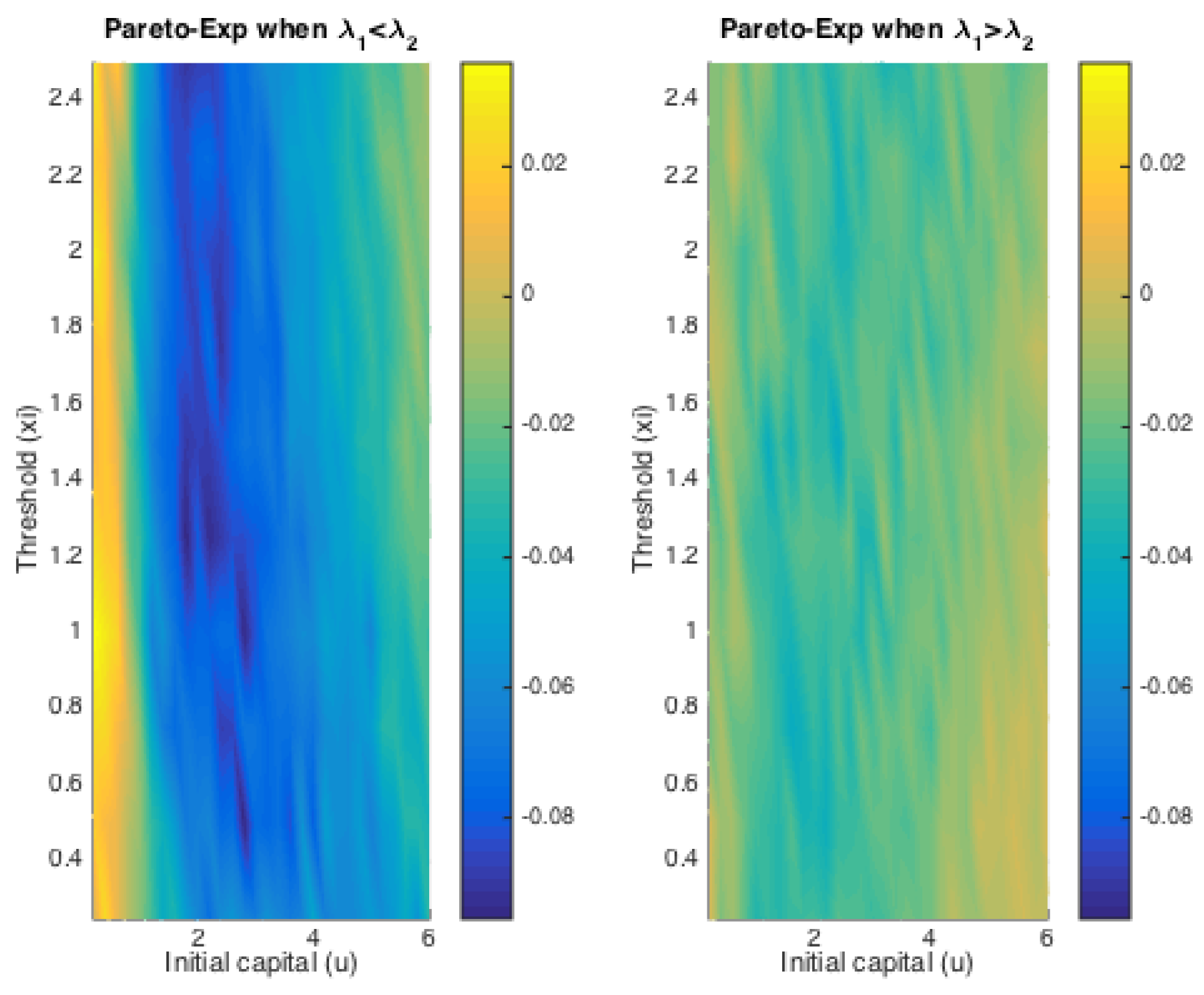
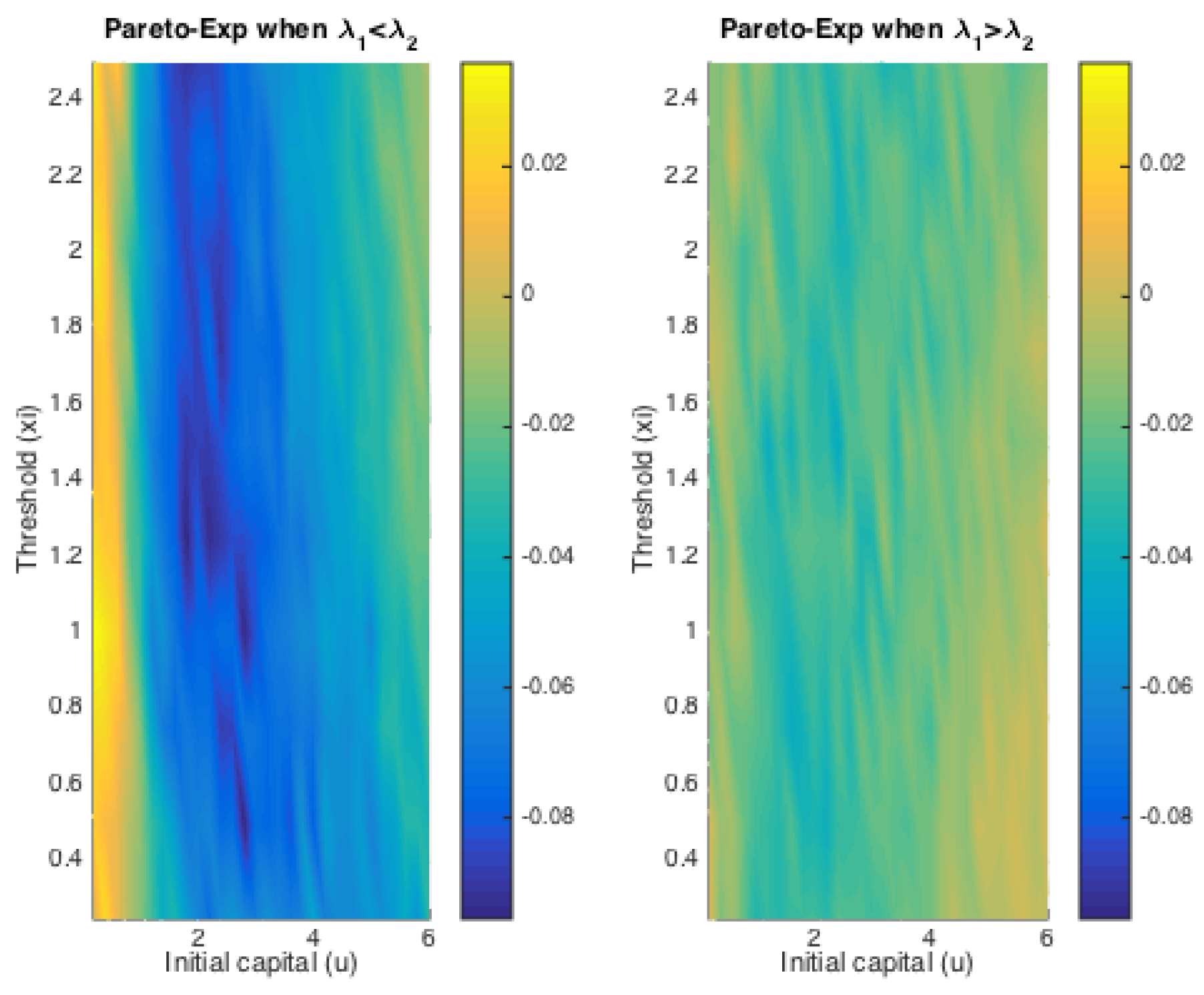
Figure 7 does that for Pareto claims. All of these four graphs demonstrate a decreasing trend for simulated finite-time ruin probabilities over the amount of initial surplus, which is as expected. In general, the differences between ruin probabilities for exponentially-distributed claim costs and those for Pareto ones are not significant. To be more precise, the exact values of these disparities are plotted in
Figure 8. The color bar shows the scale of the graph, and yellow represents values around zero. Indeed, the differences are very small. Furthermore, it can be seen that the disparities behave differently when
and when
. For the former case, ruin probabilities for Pareto claims tend to be smaller than those for exponential claims when the initial reserve is not little, whereas there seems to be no distinction between the two claim distributions in the latter case. One way to explain this is that claim distributions would have more impact on the deficit at ruin, because the claim frequency is not affected, as in an infinite-time ruin case. However, this is just a sample simulated result from which we cannot draw a general conclusion.
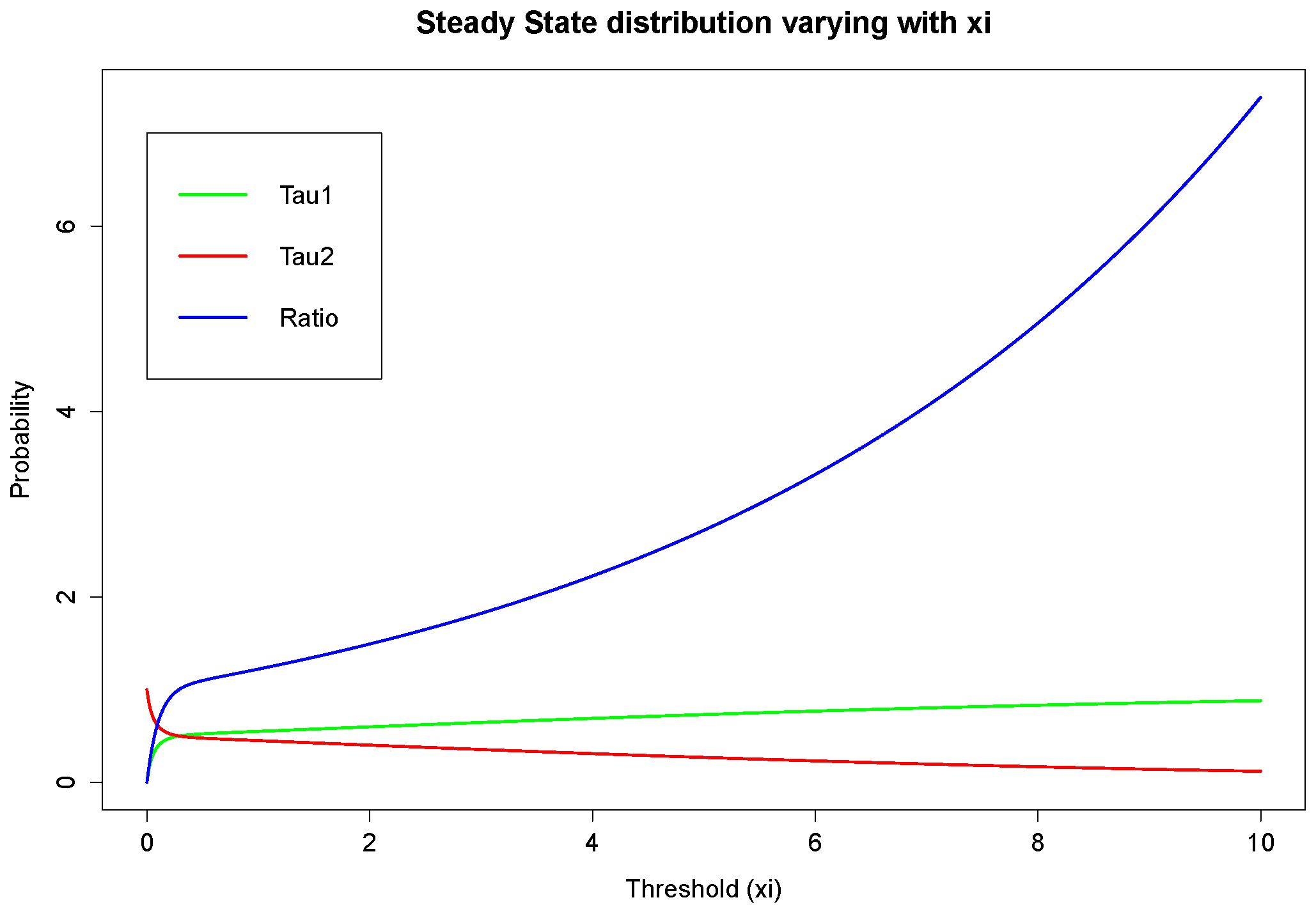
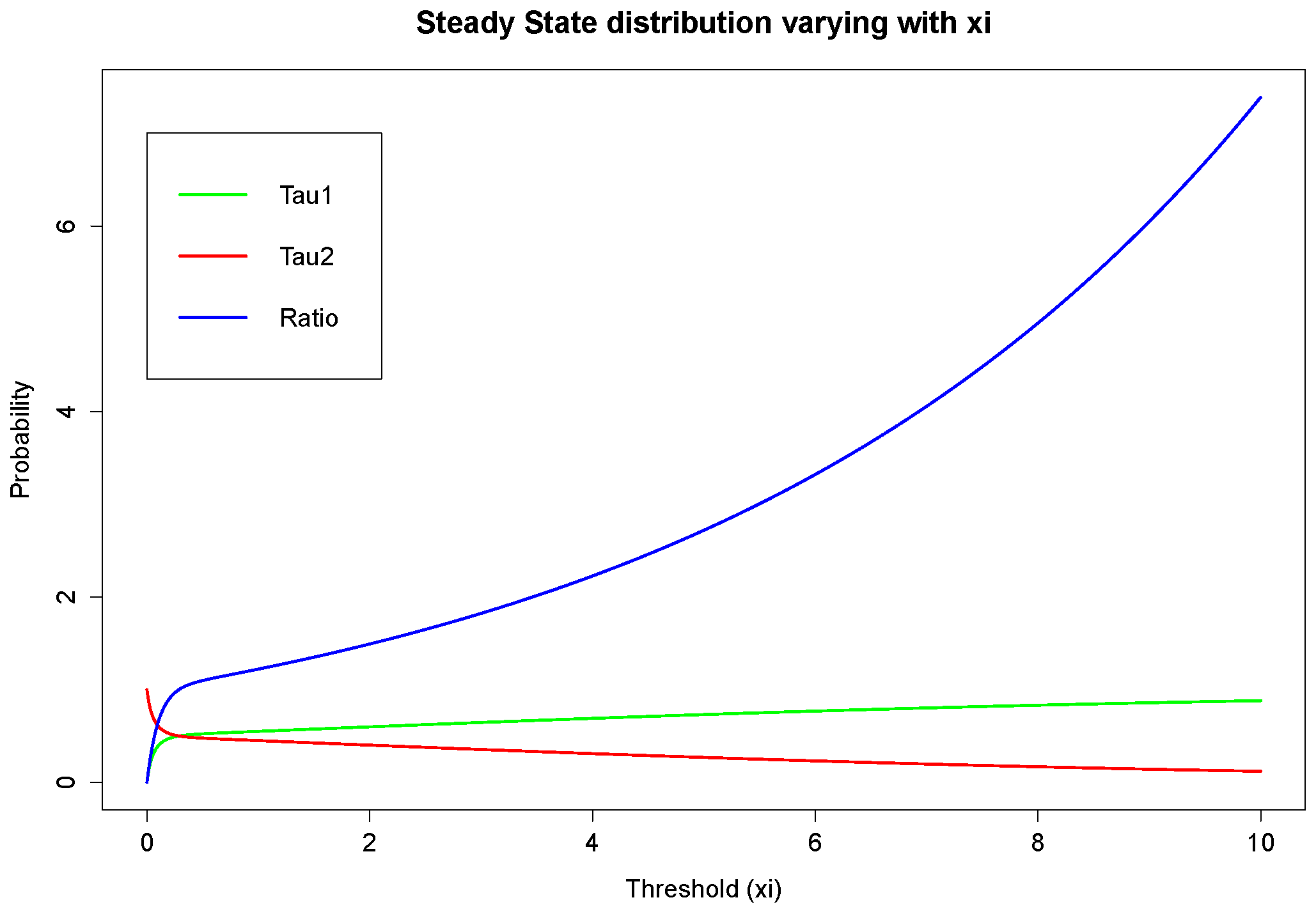
On the other hand, it can be seen from the projections on the
plane that the magnitude of
and
causes different monotonicity of ruin probabilities with respect to the fixed window
ξ. If
, the probability of ruin is monotonically increasing with the increase of
ξ. If
, it appears to be monotonically decreasing with the rise of
ξ. This conclusion for monotonicity is true for both models with heavy-tailed claims and those with light-tailed ones. Such behaviour could also be theoretically verified if we look at the stationary distribution of the Markov Chain created by the exchange of inter-claim times given by Equations (
29) and (
30). The increase of
ξ will raise the probability of getting an inter-claim time smaller than
ξ at steady state,
i.e.,
Then, that directly leads to an increasing number of
τ. Furthermore, the ruin probability is associated with:
for any fixed time
T, where
and
denote the number of times
τ and
appearing in the process. Notice that
stays the same, even though the value of
ξ alters. Therefore, now, the magnitude of
depends only on
and the distribution of i.i.d
. The change of
ξ alters only the former value. Intuitively, a rise in
indicates an increase in
and a decrease in
, whose amount is denoted by
and
, respectively. Since the sum of
τs and
s is kept constant, we have:
If
, then
, which implies
. That is to say, the increase of
is more than the drop in
, so that
sees a rise in the end. Thus, it leads to a higher ruin probability. On the contrary, when
,
i.e.,
, as
ξ goes up, ruin probabilities would experience a monotone decay. This reasoning is visually reflected in
Figure 6 and
Figure 7 shown above, and it could also be noticed that the distribution of claims does not affect such monotonicity.
Therefore, by observation, these results suggest that when
, the larger the choice of the fixed window
ξ, the smaller the ruin probability will be, and
vice versa. On the contrary, when
, the larger the choice of the fixed window
ξ, the larger the ruin probability will be, and
vice versa. In fact,
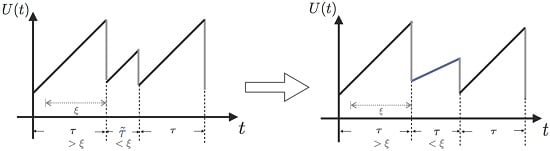
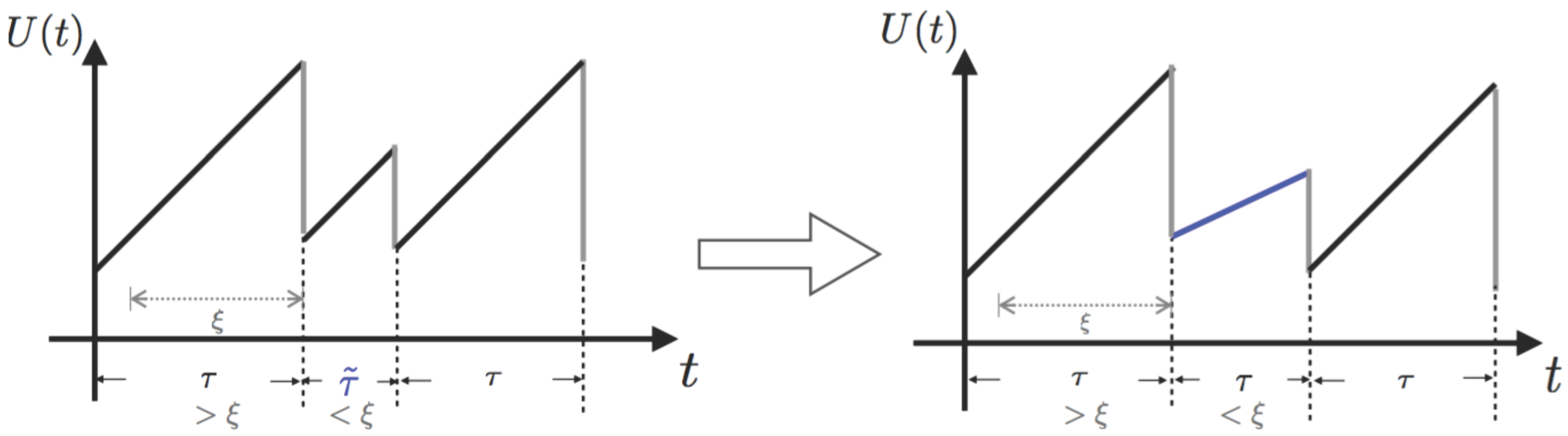
was mentioned in the Introduction (
Figure 1) to be an assumption for a premium discount process, which resembles a bonus system. Such an observation suggests that if the insurer opts to investigate claims histories less frequently,
i.e., choosing a larger
ξ, the ruin probability tends to be smaller. This potentially implies a smaller ruin probability if no premium discount is offered to policyholders. It seems that to minimise an insurer’s probability of ruin probably relies more on premium incomes. The use of bonus systems may not help in decreasing such probabilities. The case of
suggests an opposite conclusion for conservative insurers. This again addresses the significance of premium income to an insurer. In this situation, the ruin probability could be reduced if the insurer reviews the policyholders’ behaviours more frequently, indicating more premium incomes.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}