3.1. Nonlinear Time Series Analysis
A summary of the results of applying the various nonlinear models to the US dollar to Euro exchange rate returns is shown in
Table 4. It can be seen that none of the models is particularly effective. The additive autoregressive model for the US dollar Euro exchange rate returns, the results for which are shown in the top row of
Table 4, produced an AIC value of −2444, a Mean Average Percentage error (MAPE) of 104.5% and an adjusted R-squared value of less than 1%. The MAPE values are based on 20 day out of sample forecasts.
The two-regime SETAR model for the Euro fared slightly better in terms of AIC, with a value of −2258, but had a worse MAPE of 106.1%. Two coefficients in the high regime, which accounted for 15.6% of the total values were significant. The neural net 2-3-1 network with 13 weights faired the best with an AIC of −2317, and the lowest MAPE of 102.9%. The LSTAR model for the Euro also performed relatively poorly, with an AIC of −2259 and a MAPE of 106%.
We also report the results of running the forecast of the exchange rate change as a strict simple random walk with no drift. In this model, the prediction of the next return is the current return, which produces a MAPE for the EURO of 118% when using a one-step ahead forecast. When it was fitted as a simple linear regression, the coefficients are insignificant, and the adjusted R squared is zero. However, the time series models were used to make 20-period forecasts, which based on the random walk model, produces a MAPE of 108%, which is worse than for the time series models.
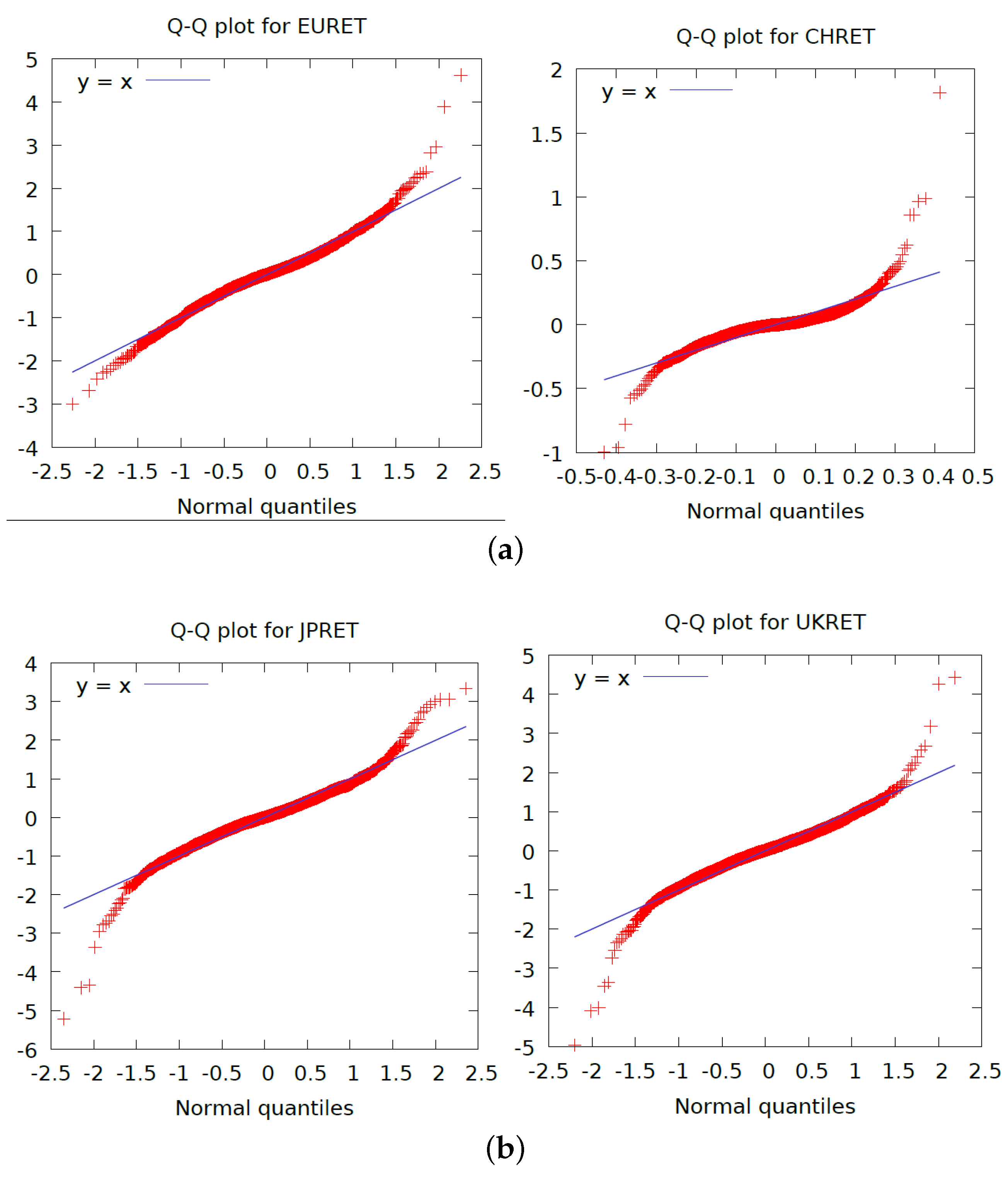
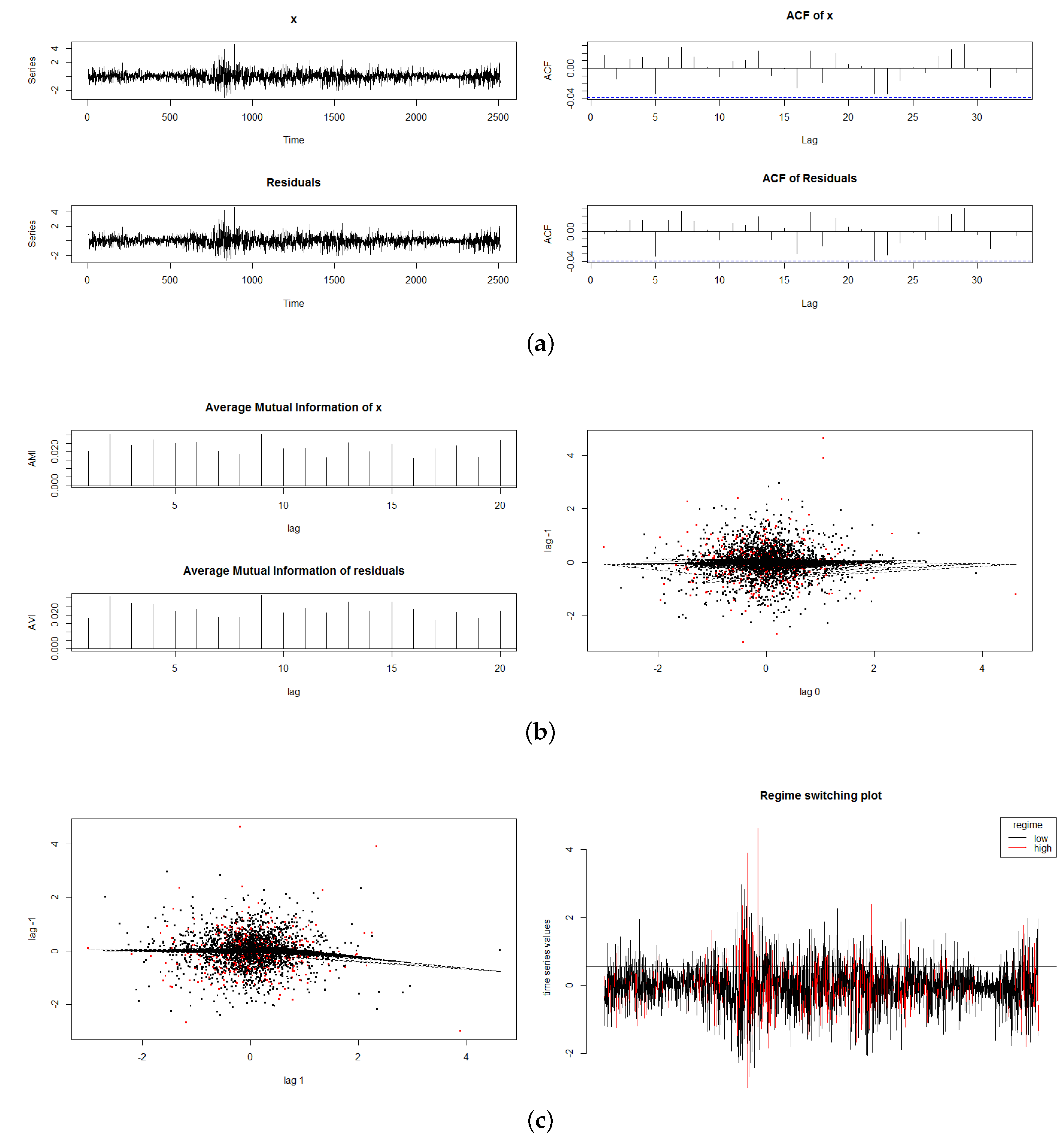
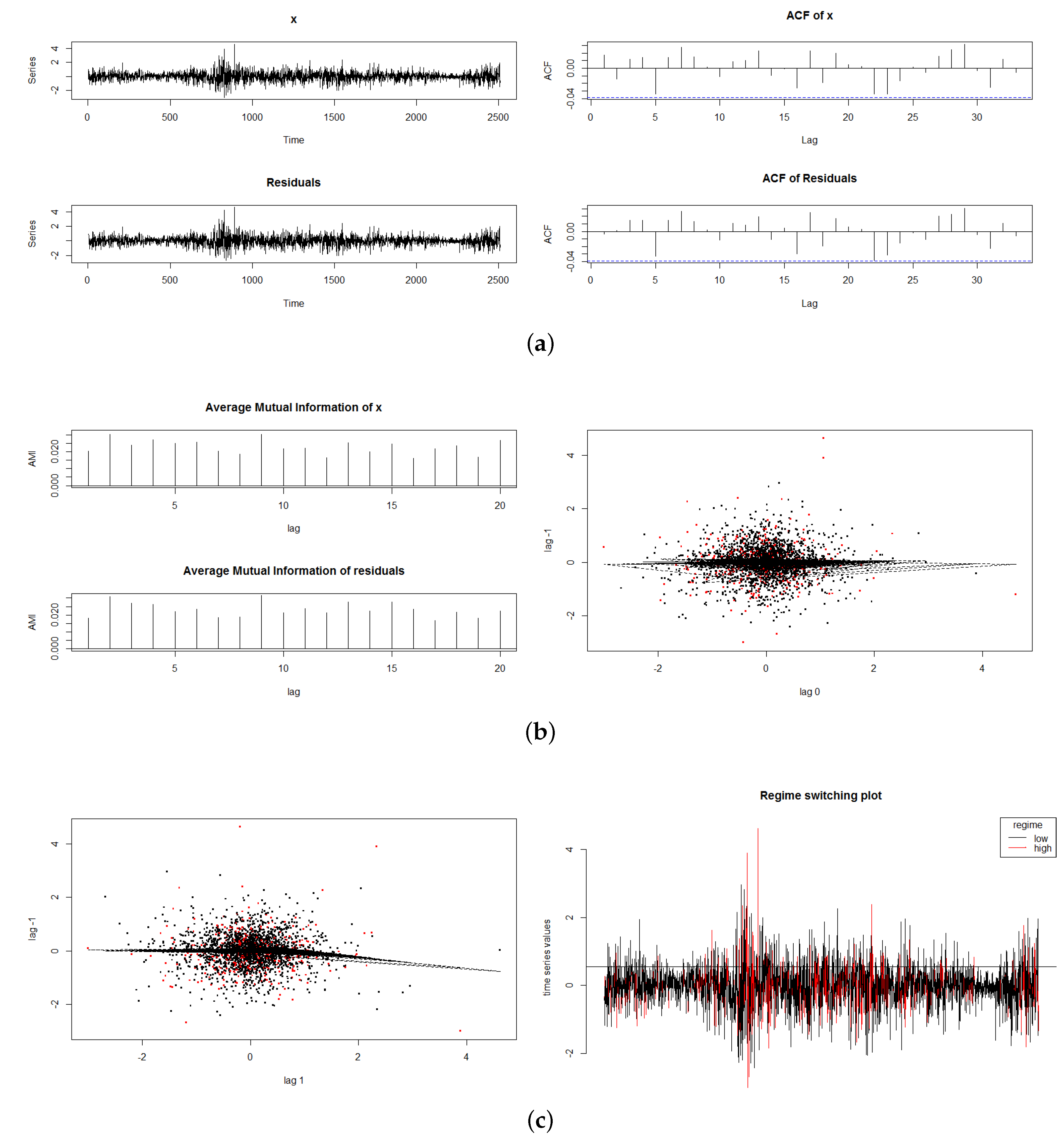
We examined various graphical analyses. Some of the results relating to the SETAR model are shown in
Figure 3. In Sub-
Figure 3a, we plot the original US$ Euro exchange rate return series and the residuals from the SETAR analysis, in the top of the panel, and below it in Sub-
Figure 3a, we plot the autocorrelation function of the original series and that of the residuals. In Sub-
Figure 3b, we plot the mutual information (MI) series and one of the lag relationships (lag −1, 0). In Sub-
Figure 3c we plot lag (−1,1) plus a regime switching plot.
The results for the Chinese exchange rate with the US $ returns are shown in
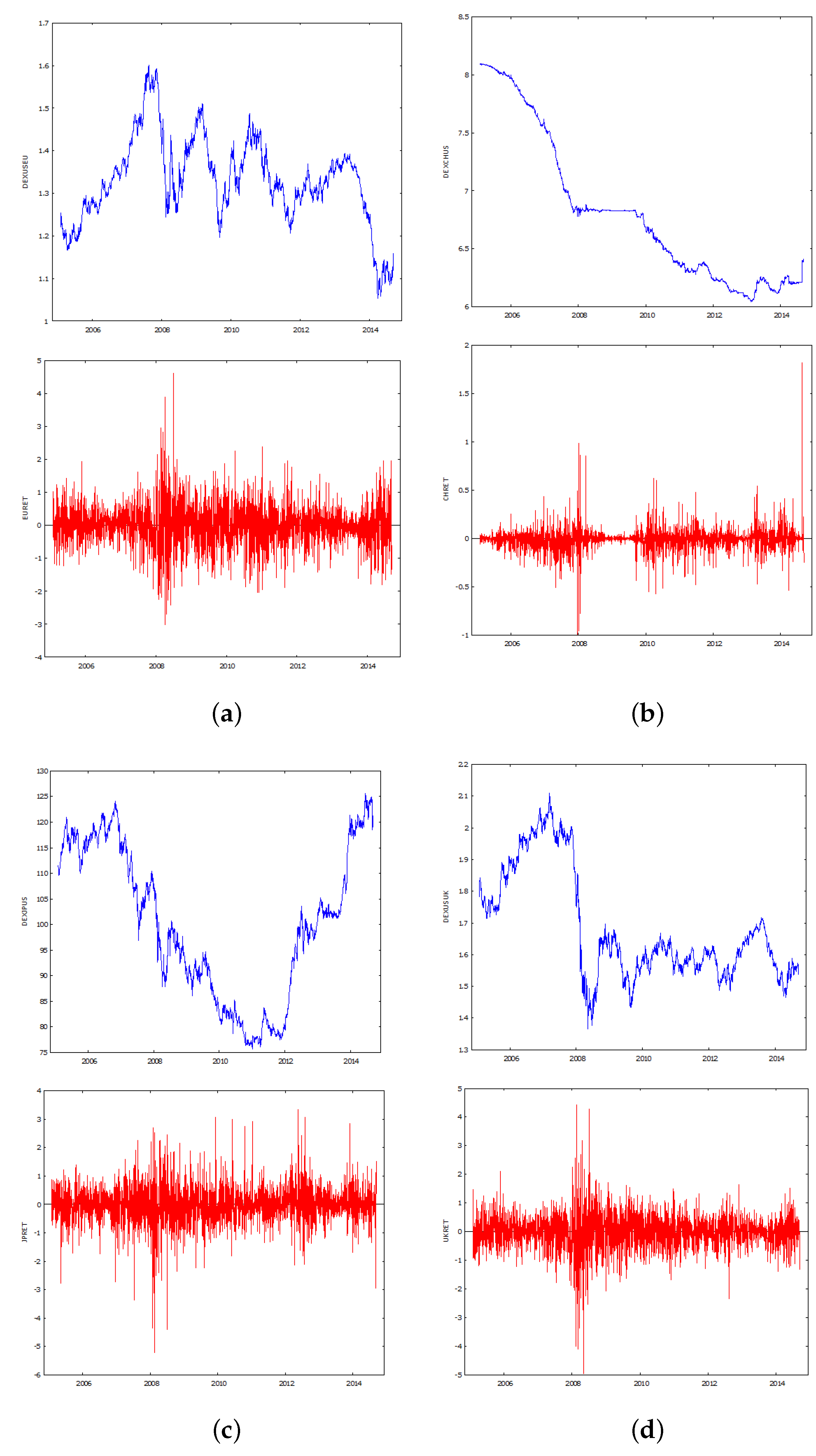
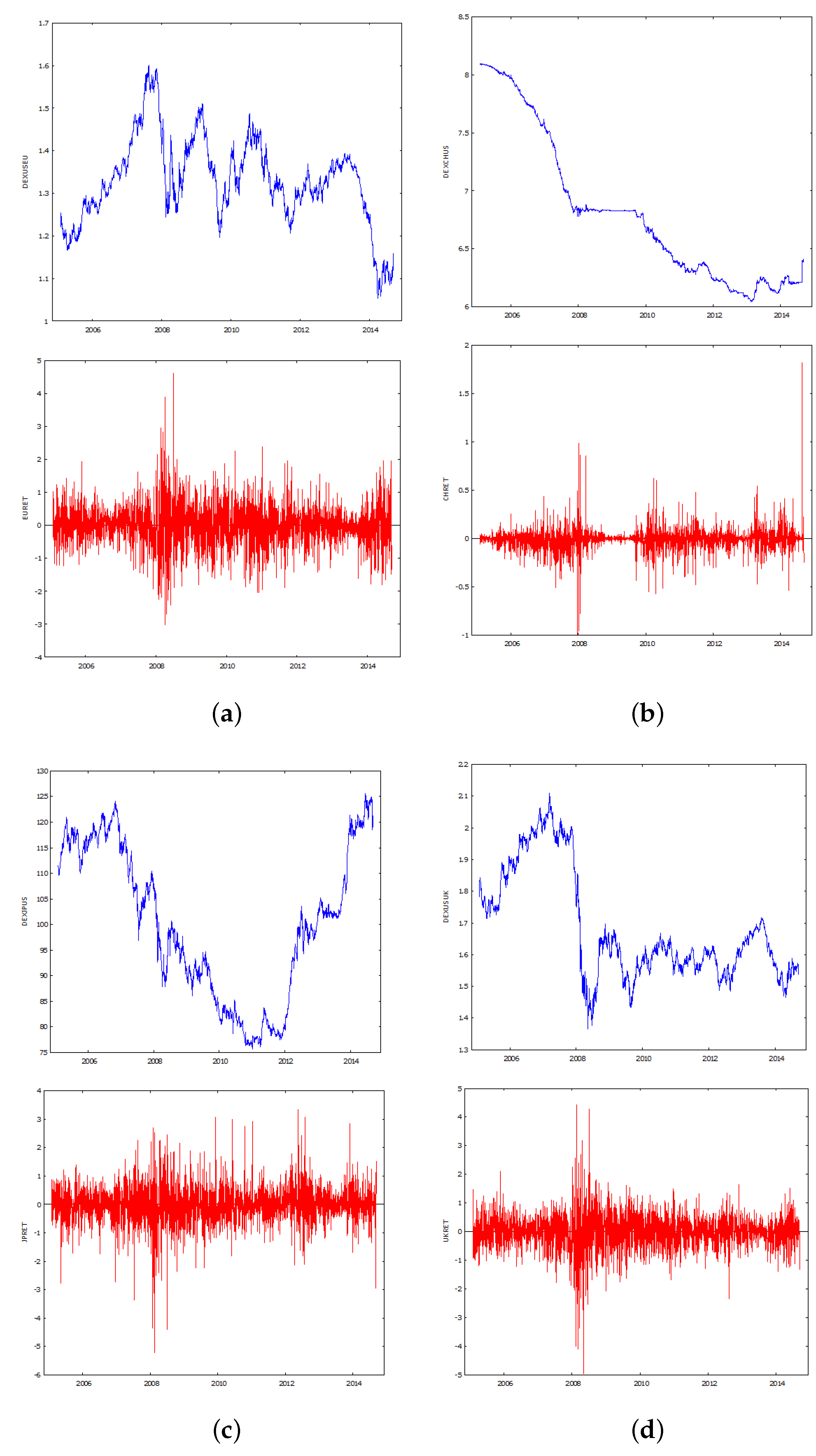
Table 5. The plots of the exchange rate series in
Figure 1, Sub-
Figure 1b, reveal that the Chinese exchange rate with the US $ behaves differently, is smoother, and shows evidence of exchange rate management.
However, this has not translated into a greater ease of forecasting Chinese currency exchange rate return changes. The Mean Average Percentage Errors (MAPE) range from 116% to 122%. The AIC again suggests the NNET approach is preferred, though this approach has a relatively high MAPE of 121.8%. A regression of the current return on the previous return, as discussed above, produces a statistically significant slope coefficent. However, the use of a strict random walk model to forecast the series, in a one-step ahead process, produces the lowest MAPE of 100.2%, but a 20-period forecast has a MAPE of 121.38%, which is worse than some of the time series models, for 20-period forecasts.
The results for Japan are quite clear cut. The NNET model has the highest AIC score (in absolute) terms, and the lowest MAPE, shown in
Table 6, of the nonlinear methods. The results of the random walk regression are insignificant, but use of the random walk model for forecasting purposes, with one lag, produces the lowest MAPE of 88.92%, but 20 lags produce a MAPE of 104.44%. This is comparable with the time series models.
The UK results, shown in
Table 7, are similar. The NNET model produces the highest absolute value of AIC, but its MAPE is 106.2%. All the other nonlinear models produce inferior results. The UK random walk regression is insignificant, with a slope coefficient close to zero, but use of a strict random walk model, or naive no change model, for forecasting purposes, for one lag, yields the lowest MAPE of 89.29%. In order to be strictly comparable with the time series models, which used 20 period forecasts, the MAPE is 110.28%, which is inferior to the time series results.
Given that neural network analysis seemed to perform relatively well in these analyses, it was decided to extend the analysis applying non-linear neural net estimation procedures in a regression context.
3.2. Further Analysis Using Neural Nets
Regression analyses using higher order polynomials produced the models shown in
Table 8. In all cases where one individul currency exchange rate return was the dependent variable in the regression analysis, only lagged terms of the other exchange rates were used. The neural network analysis produced quite complex models, with higher order terms and new variables that were complex weights of existing variables. For example, in Euro model 2, the new variable N9 is a combination of lagged observations of the Euro exchange rate return, combined with lagged observations of the Chinese exchange rate return. The neural nets were trained on 80% of the available time series observations, and the forecasts were run on the remaining 20% of observations.
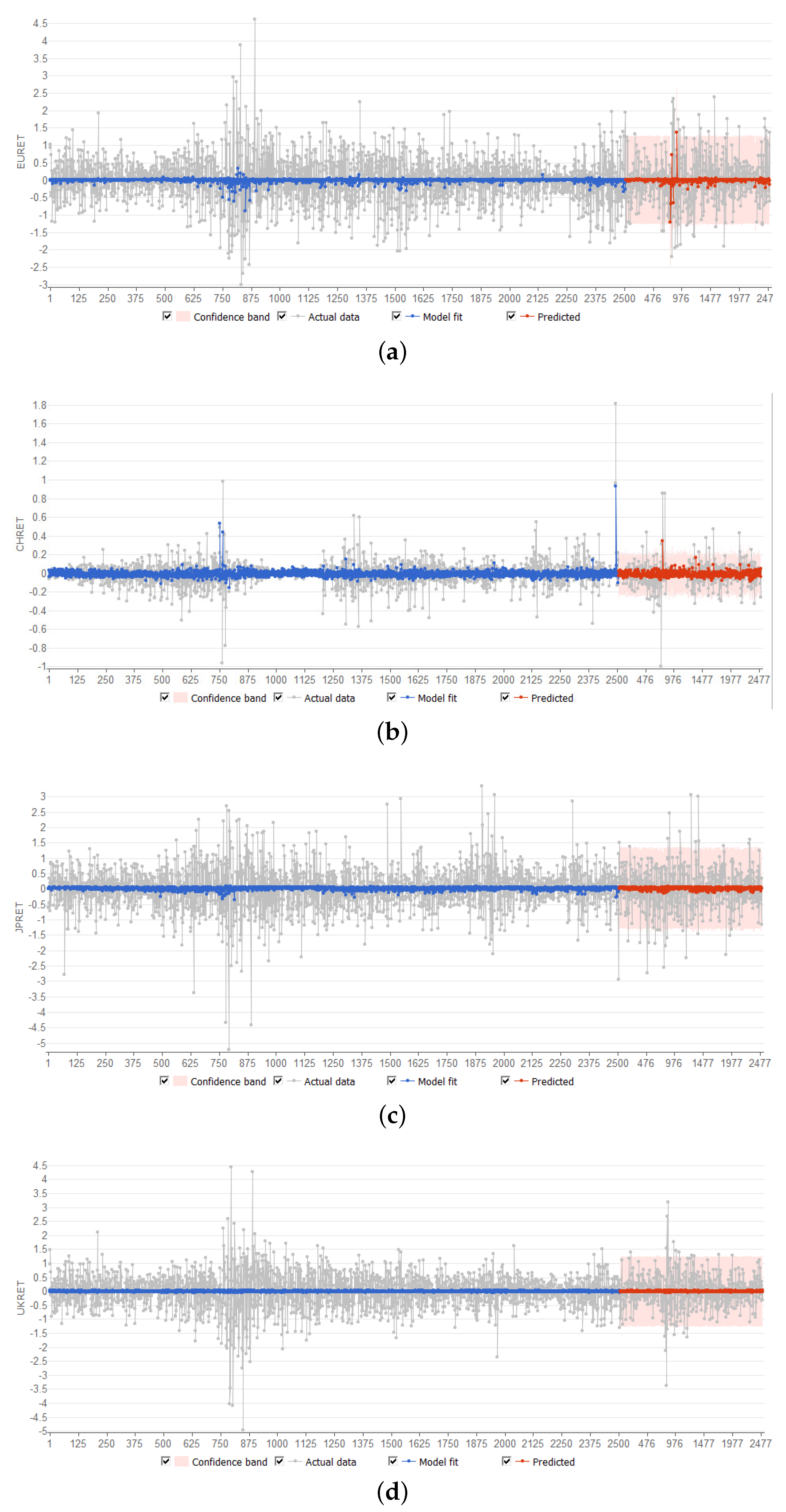
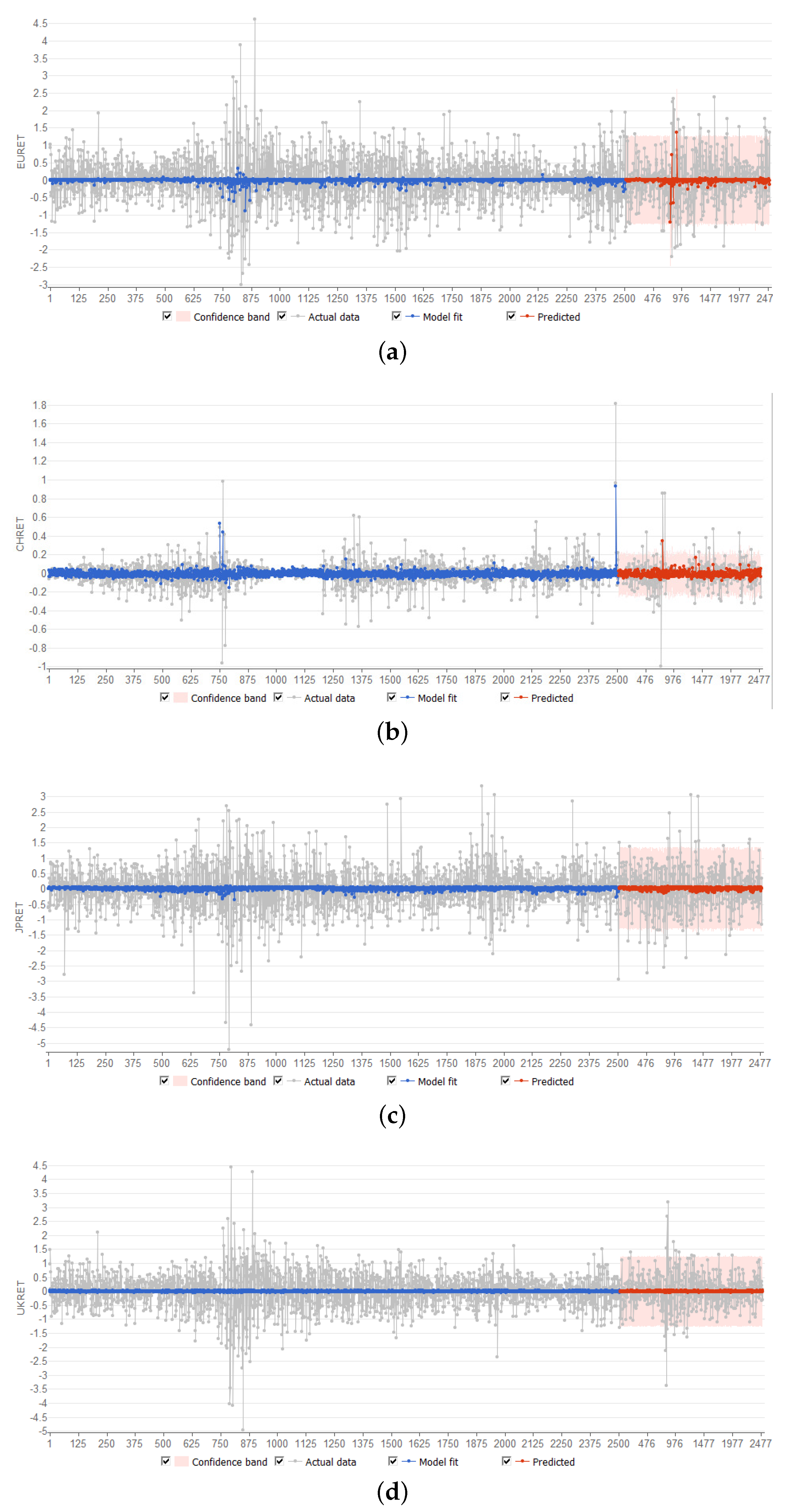
Plots of the neural net model forecasts are shown in
Figure 4. It is apparent that the neural net based regression models capture only a small proportion of the volatile changes in currency rate of return movements. The results for fluctuations in China appear to be better than for the other three currencies.
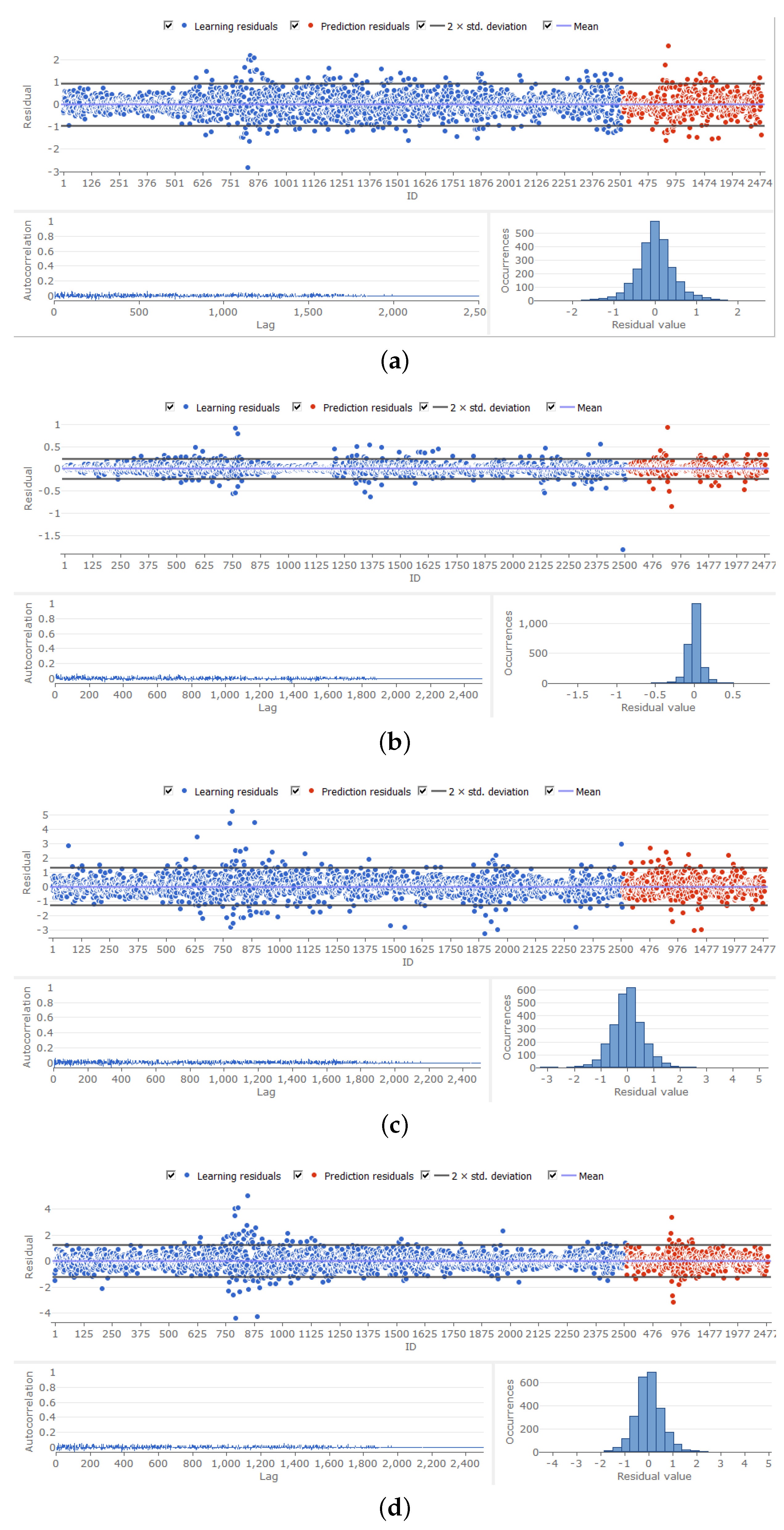
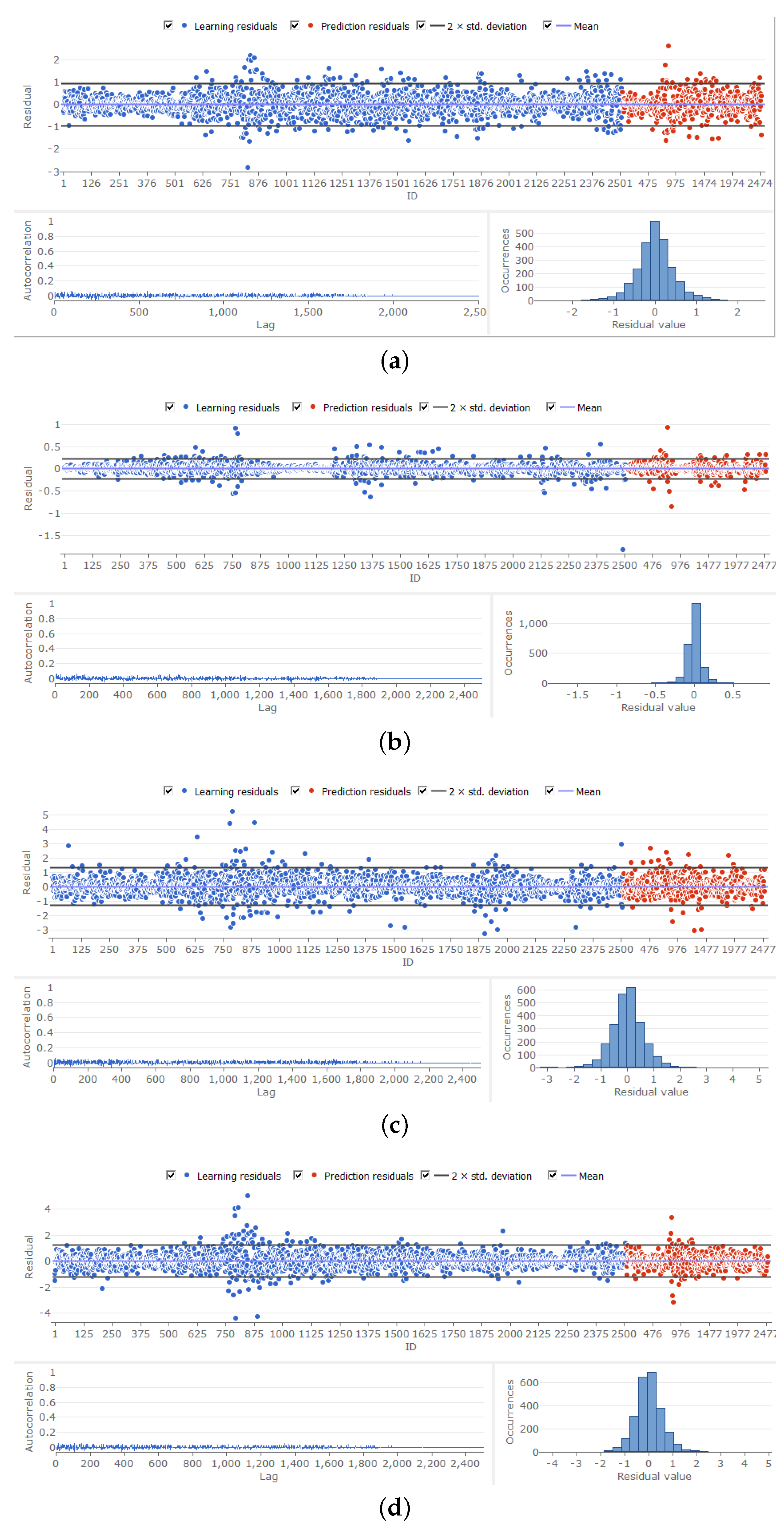
Plots of the residuals are shown in
Figure 5. These reveal that the models behave reasonably well, in that the autocorrelation of residuals is of a low order, and the histograms of the residuals are unimodal. There is a clustering of observations in excess of two standard errors from the model fit, in the case of both the training and forecast periods.This is consistent with the existence of volatility clustering, and will be explored further in a subsequent paper.
The error metrics from the neural net regressions are shown in
Table 9. The most successful model is for China, which has the lowest mean absolute errors of 0.067 and 0.07 for model fit and predictions, respectively, and similarly root mean square errors of 0.11 and 0.11 for model fit and predictions. The coefficient of determination is 0.10 for model fit and 0.11 for predictions, respectively. The next best model is that for the UK, with a mean absolute error of 0.44, a root mean square error of 0.62, and a coefficient of determination of 0.0011 for model fit. Its errors are lower than those for the Euro, but its coefficient of determination for model fit is lower than for the Euro 0.0068. However, the metrics for the UK predictions are better than those for the Euro. The metrics for Japan for both model fit and for predictions are relatively weak. Clearly, the managed nature of the Chinese currency makes it much easier to forecast than the other three more freely floating currencies. It appears that the neural network regression techniques, particularly in the case of China, work better than the non-linear time series regression models.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}