1. Introduction
This paper explores the calibration of pricing spread options in a finite liquidity market model. Following
Pirvu and Zhang (
2024), a Black Scholes model is considered with liquidity costs on the trading of one risky asset, and the delta hedging of a large trader is the cause of the liquidity costs. A spread option is a financial derivative that gives the holder rights to exchange one risky asset for another and a fixed amount (the strike). This financial derivative is common in commodity markets, such as the oil market.
The work
Pirvu and Zhang (
2024) uses the Kirk approximation in conjunction with Monte Carlo simulations. The risk neutral pricing formula renders the computation of the spread option price possible by means of Monte Carlo simulations; the illiquid asset price is simulated throughout time and this can be done through Euler Maruyama scheme. The paper
Pirvu and Zhang (
2025) realizes a first calibration of these model; in the first step, a data base of prices is obtained through Monte Carlo simulations as in
Pirvu and Zhang (
2024) and are fitted through a non-linear regression; in the second step, the model coefficients are obtained through minimizing the Sum of Squared Errors (SSE) when the non-linear regression is benchmarked against synthetic data. We refer the reader to
Assefa et al. (
2020) and
Tkachenko (
2024) for the rationale of using synthetic data in finance.
The present paper improves the calibration procedure of
Pirvu and Zhang (
2025). This is done by replacing the non-linear regression with Chebyshev interpolation; the improvement is due to the fact that this interpolation techinque has its error decays exponentially. A recent paper on this topic is
Gaß et al. (
2018). The parameters calibrated via this method are similar to those obtained through the non-linear regression in
Pirvu and Zhang (
2025). Numerical experiments reveal the superiority of the fit achieved by this paper compared to
Pirvu and Zhang (
2025). The merit of our work is on constructing a calibration tool which takes as input data and it produces model parameters.
Let us present the contributions of this work. The existing literature on pricing options in illiquid markets does not address the issue of parameters estimation and calibration; they are exogenously given. Our paper comes fill this gap; not only we present a calibration procedure but also we make use of the powerful Chebyshev interpolation, which is quite new in the quantitative finance. The output is an efficient calibration methodology, and, on the practical side, it carries implications for spread option prices.
The remainder of this paper is organized as follows:
Section 2 presents the model and
Section 3 the calibration procedure.
Section 4 presents the enhanced calibration through Chebyshev Polynomials, and
Section 5 concludes the paper.
2. Spread Options
Spread options are derivative securities yielding the owner the right but not the obligation to swap assets for a pre-determined amount known as the strike price. Spread options are very common in commodity markets. Let us give as an example the crack spread option; the underlying assets are gasoline and crude oil. The incentive to acquire this contract is to hedge the differential between crude oil cost (as input costs) and gasoline price (as output price). The importance of spread options in commodity markets is shown by this example of the crack spreads.
2.1. The Model
The presentation here follows
Pirvu and Zhang (
2024). There are two risky assets, one liquid and one illiquid. The liquidity impact on the second asset is introduced through the stochastic differential equations (SDEs) governing the price dynamics of underlying assets. Given two independent Brownian motions
the differentials of the two asset prices are
and
Here K is strike, is time to maturity, and is a correlation coefficient.
Following
Pirvu and Zhang (
2024), one will get the following SDEs under the risk neutral (martingale) measure:
The choice of adjustment factor function
comes from
Liu and Yong (
2005) (see p. 2316).
2.2. Kirk Approximation of the Spread Option
The payoff of a European-style spread option is with being the strike price; it pays the holder asset one in exchange of asset two and In a continuous paradigm. It turns out that finding an analytical solution for the spread option is not possible, even in the full liquidity model, since the linear combination of log-normal processes (sum of GBMs) is not log-normally distributed.
Fortunately, there are several ways to approximate the price of a spread option; in this paper, we adopt Kirk approximation (see
Kirk (
1995)). The presentation here follows
Pirvu and Zhang (
2024). Given that the two risky assets
are modelled as correlated geometric Brownian motions (GBMs), the price at time
given
denoted by
, has the following Kirk approximation:
This approximation yields an analytical formula of the value of the spread option price, and this makes it possible to calculate the corresponding sensitivities (the Greeks); the later yields and the formulas of the previous subsection.
The risk neutral pricing formula renders the computation of the spread option price as an expectation under the martingale (risk neutral) measure of the discounted payoff. The later is obtained via Monte Carlo simulations, (see the Euler Maruyama scheme in
Pirvu and Zhang (
2024)).
3. Model Calibration
The model parameters to be calibrated are
and
We take
as the range of liquidity impact, and
with
Let us provide a rational for the choice of these ranges. Since
and
the range
is explained by the fact that none of the simulated values of
lies outside this interval. The ranges for
and
are inspired by
Liu and Yong (
2005) (see p. 2136).
Following
Pirvu and Zhang (
2025), the training data for fitting the curve are generated by a large dataset of Monte Carlo results with the selected ranges of the following four parameters:
Calibrating by Min SSE
Synthetic data are obtained as the Kirk approximation price plus normally distributed noise. Our methodology would work the same with observed market data. We provide a calibration tool which inputs data and outputs numerical values for the parameters; the scholarly merit is not in the choice of data but rather in building this calibration tool.
The real data for financial products are limited and sometimes there are proprietary issues involved. Thus, it is of paramount importance to come up with procedures for synthesising financial datasets that resemble the real data, as per
Assefa et al. (
2020). The aforementioned paper details on the growing need for synthetic data generation in finance. Synthetic data are regarded as a paradigm shift in quantitative finance, as per
Tkachenko (
2024). One of their supporting arguments is that over-reliance on historical data to predict future trends are the unprecedented events like the 2008 financial crisis or the COVID-19 pandemic.
The constants
and
are obtained by minimizing the sum of square error between the synthetic data price and the model price as follows:
4. Enhanced Calibration Through Chebyshev Polynomials
The goal of the paper is provide a more efficient calibration, and this is achieved via Chebyshev polynomial interpolation (rather than through the non-linear regression of
Pirvu and Zhang (
2025)). In the next subsection we provide more detail on this.
4.1. One Dimensional Chebyshev Interpolation
Chebyshev interpolation is a method used in numerical analysis to approximate a function by a polynomial over a given set of constraints. This method leverages Chebyshev polynomials, which are a sequence of orthogonal polynomials with specific properties that makes them useful for approximation purposes.
Consider a continous funtion
where
then the Chebyshev interpolation of degree
n of this function is as follows:
Chebyshev polynomials of the first kind, denoted as
are a sequence of orthogonal polynomials in a recursive form, as follows:
Consider an interpolation problem; there are some data points for some unknown function so one can represent those data points by a polynomial of degree n such that The aim is to strategically select a set of numbers of and compute the associated coefficients in a manner that minimizes the resulting interpolation error.
The
n Chebyshev nodes of the first kind are given by the following:
These points are the result of projecting equidistant points on the upper half of the unitary circle of the complex plane onto the real line, and they are also the roots of
One can show that if
are chosen as the roots of Chebyshev polynomial
then the error is minimized and bounded by the following equation:
This interpolation technique has the following two benefits: firstly, the error decays exponentially; secondly, it overcomes the Runge phenomenon, where the Chebyshev nodes concentrate more on the tail of the interval instead of equally spaced over the interval (refer to Chapters 3 to 6 of
Mason and Handscomb (
2002) and Chapter 10 of
Trefethen (
2013) for more details). The coefficient
in (
6) is defined by the following:
where
is the equivalent Chebyshev node in
of
in
is the number of Chebyshev nodes.
In the general case, we perform the following linear transformation:
4.2. Multi-Dimensional Chebyshev Interpolation
The Multi-dimensional Chebyshev interpolation can be reduced to the one-dimensional case. In this section we perform the dimension reduction method which was introduced in
Zeron and Ruiz (
2020) to simplify the higher-dimensional Chebyshev interpolation which involves several variables. The intuition is that one can employ one-dimensional projections for the multidimensional coordinates. Let us explain how it works; start with the two-dimensional case
with strike
K and time to maturity
and then proceed to the higher dimensions with
Firstly construct a two-dimensional grid of Chebyshev nodes
such that it has the following shape
, where
is the number of Chebyshev nodes selected for each parameter; any pair
has the following form:
where strikes
and time to maturity
Next let
be the set of
, and
the set of
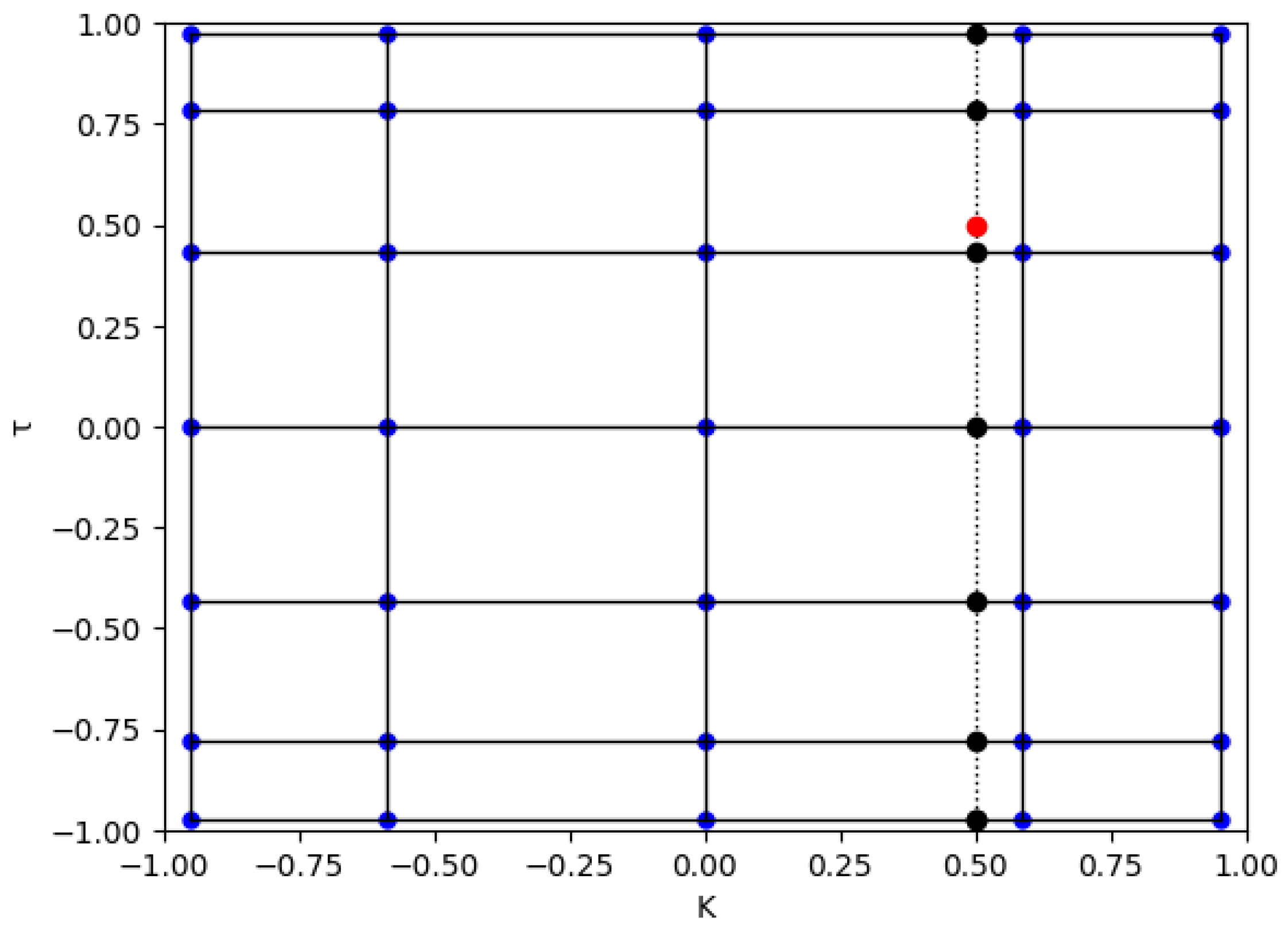
The grid is shown in
Figure 1, where the Chebyshev node pairs are represented by those blue dots. In this plot, recall the one-dimensional case, so one can visualize this two-dimensional case as a stack of one-dimensional cases. Each horizontal (vertical) solid black line stacks vertically (horizontally) from this two-dimensional grid.
Suppose we wish to evaluate the function at a random point , as follows:
otherwise,
is not on the grid, shown as the red dot in
Figure 1:
Next, let us consider the three-dimensional case (
), and the goal is to evaluate the function at a random point
Next, construct a three-dimensional grid of Chebyshev nodes
as shown in
Figure 2 such that it has the following shape
), where
is the number of Chebyshev nodes selected for each parameter. Every pair in
has the following form:
where k = 1…
, t = 1…
, and g = 1…
Let
be the set of
,
be set of
, and
be set of
. One can visualize this three-dimensional grid as several two-dimensional grids stacked vertically, and then one can evaluate the function value for each red dot
on those two-dimensional grids, thus creating a red line connecting those red dots (based on formula of (
9) and (
10)) to perform a one-dimensional Chebyshev interpolation; this is done similarly to the two-dimensional case (it evaluates the random point shown as the green dot in
Figure 2.
Any random point
which is not on the three-dimensional grid is shown as the green dot in
Figure 1. The algorithm then works as follows:
For the four-dimensional case, as in the three-dimensional case, one can visualize the four-dimensional grid as several three-dimensional grid stacked together; the method is now clear and as such the details are omitted.
4.3. Calibration Result and Error Analysis
The calibration uses the same criteria and synthetic data of
Section 3. Consider the finite liquidity price of an European Call Spread with four input variables—
. We first set up a four-dimensional Chebyshev grid and determine its shape (see
Table 1).
Next, we employ Monte Carlo simulation to compute the spread option prices corresponding to the Chebyshev nodes, as summarized in
Table 2, resulting in a dataset of 7986 price points. The parameter boundaries chosen for this simulation are intended solely for illustrative purposes. In practical applications, these ranges should be adjusted dynamically to reflect prevailing market conditions. For instance, the time to maturity
may extend beyond one year, and
may assume larger values in environments characterized by heightened illiquidity.
The number of Chebyshev nodes can also be adjusted according to the desired interpolation accuracy. Increasing the number of nodes per dimension enhances the precision of the interpolated pricing function. However, this improvement comes at the cost of a significantly higher computational burden, as the total number of required training points grows exponentially with dimensionality. This trade-off between accuracy and computational cost is examined in greater detail (see
Section 4.3.1).
The following calibration result in
Table 3 is obtained by applying the method of
Section 4.2.
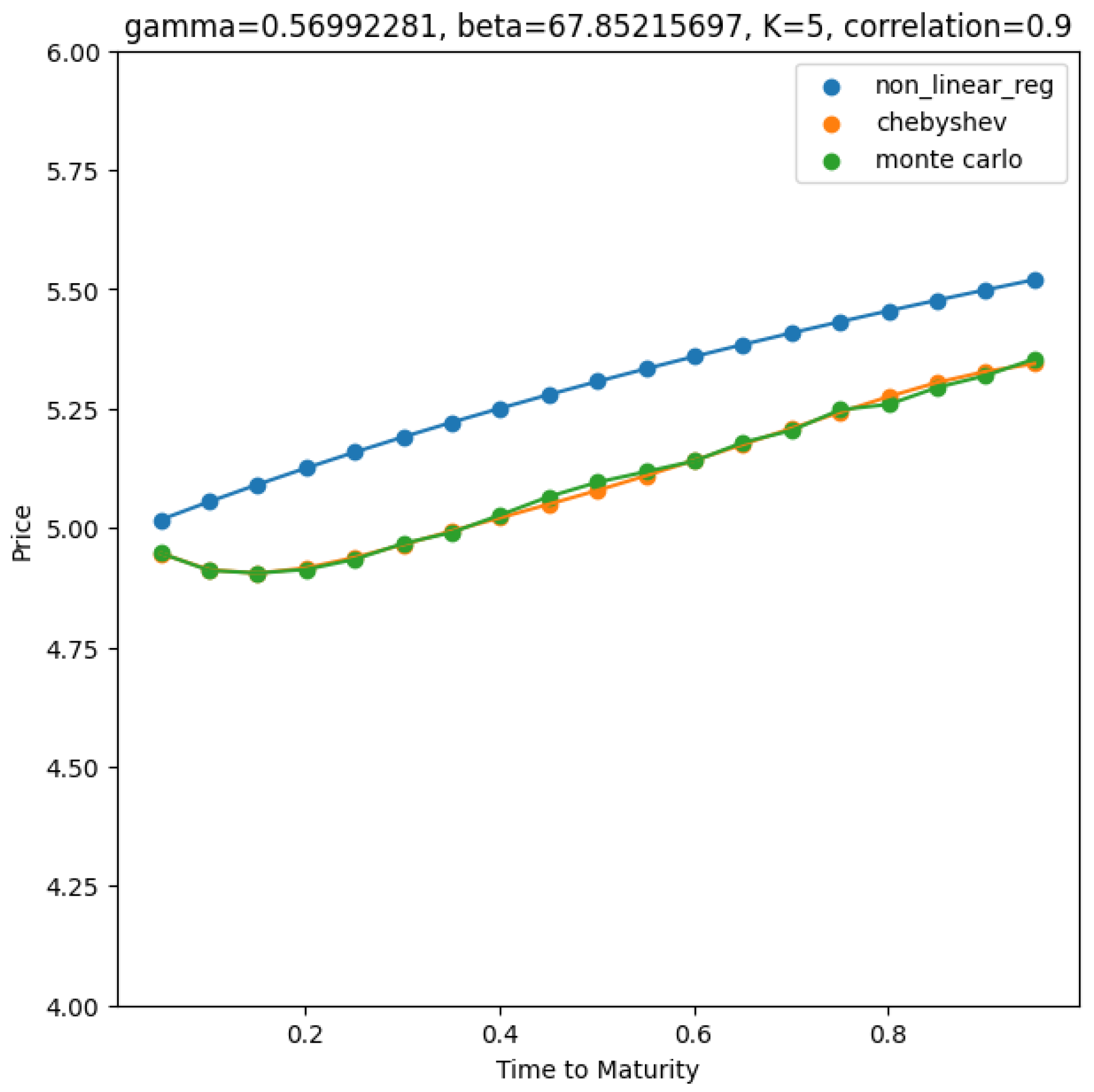
Both methods yield similar results for calibrated parameters, with Chebyshev interpolation giving a lower SSE (SSE between Chebyshev estimated price and synthetic price), thus providing a more accurate calibration result to exogeneous data. A comparison of non-linear regression and Chebyshev interpolation results against the Monte Carlo price (with same model parameter) is displayed in
Figure 3, and this is further discussed in
Section 4.3.2.
4.3.1. Trade-Off Between Accuracy and Training Cost for Chebyshev Interpolation
As illustrated in the previous section, Chebyshev interpolation requires evaluating the option price at each Chebyshev node. In our case, this results in 7986 computations using Antithetic Monte Carlo simulation, with each simulation involving 30,000 correlated stock price paths. The total computational time for this process is approximately six hours. We selected six nodes for the parameter
as it is not a primary driver of the pricing function. As seen in Equation (
1),
primarily governs the rate at which the intensity function
approaches its maximum value
over the time horizon. This observation is supported by numerical evidence from
Pirvu and Zhang (
2024), where similar conclusions were drawn. Therefore, a lower number of interpolation nodes for
is sufficient, and we will examine the impact of this choice in subsequent analysis.
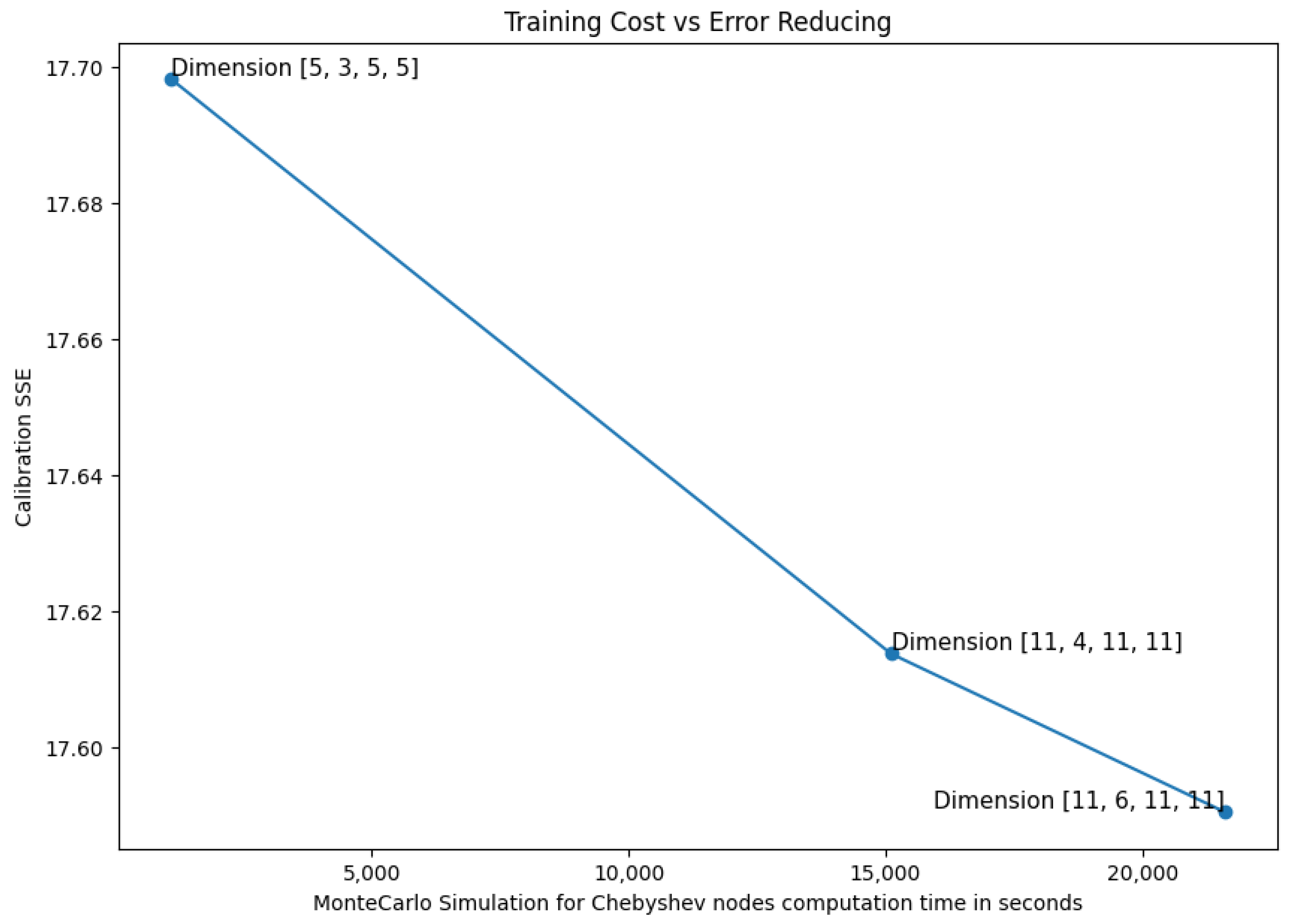
We constructed three four-dimensional Chebyshev grids with varying configurations of interpolation nodes across the parameters [
,
, Strike,
], as detailed in
Table 4 to examine the trade-off between interpolation accuracy and training cost in the Chebyshev framework. The corresponding computational times for generating each grid were also recorded. Subsequently, we performed parameter calibration using each of the three grids, and the resulting outcomes are presented in
Table 4. Let us point out a marginally lower SSE for the grid with a higher number of Chebyshev nodes. Moreover, each grid results in similar calibrated parameters. However, the improvement in accuracy is relatively limited, while the associated computational time increases substantially. This diminishing return is illustrated in
Figure 4.
4.3.2. Calibration Error Analysis
In this section, we conduct a more detailed examination and visualization of the performance of the two estimation methods in replicating the prices obtained by Monte Carlo simulation. To further evaluate the validity of our calibration approach, we apply the two-sample t-test, and the Kolmogorov-Smirnov (KS) test to statistically compare the distributions of the estimated/interpolated prices and the Monte Carlo simulated prices.
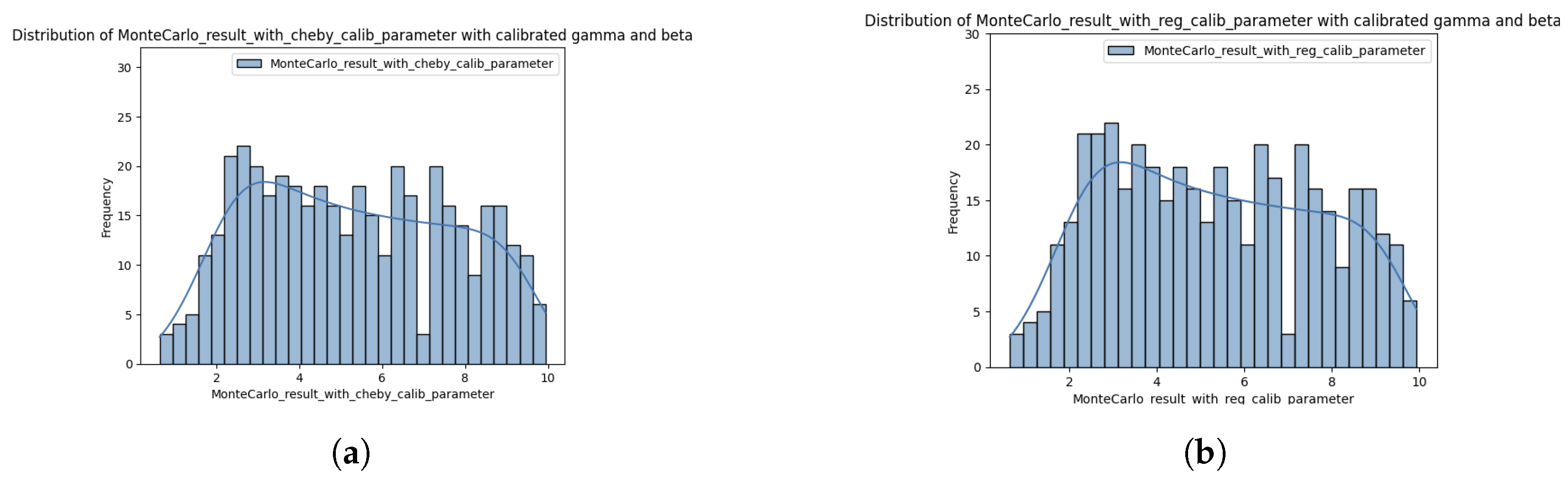
Let us begin by presenting the distribution of Monte Carlo simulated prices generated by the calibrated parameters obtained by the two calibration methods (see
Figure 5).
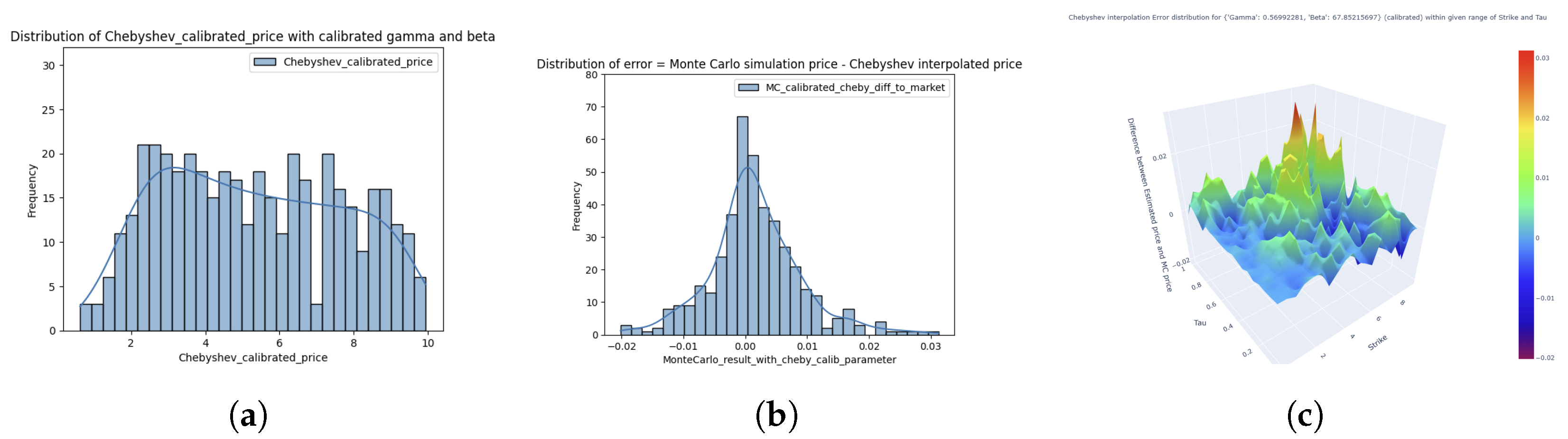
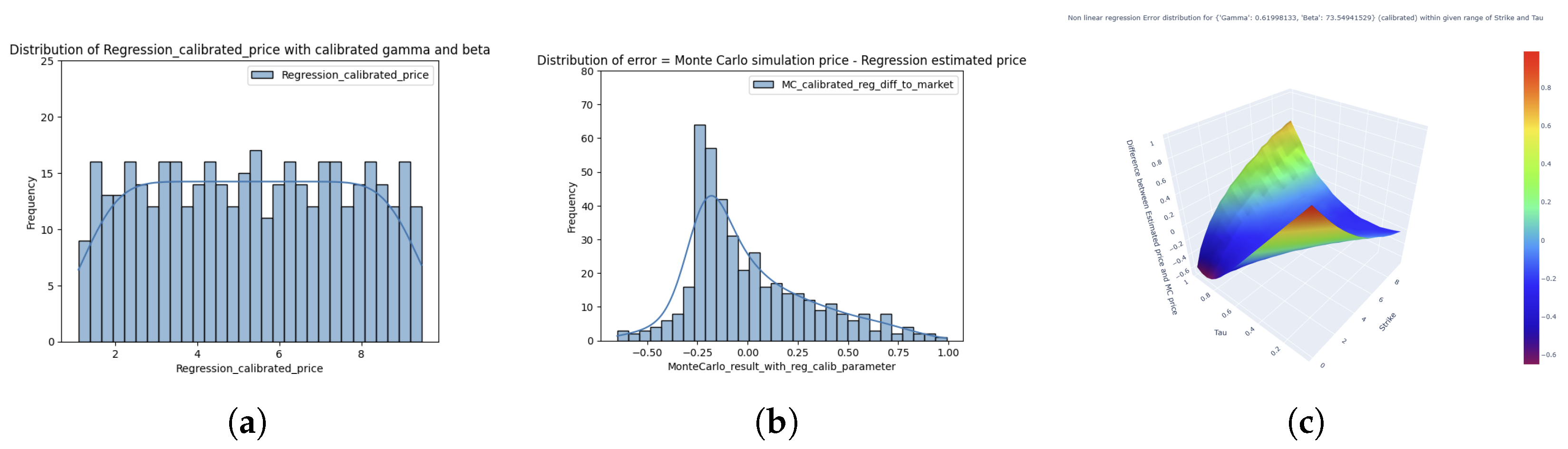
Figure 6 presents the distribution of the prices produced by Chebyshev interpolation along with their deviations from the Monte Carlo simulated prices. In parallel,
Figure 7 illustrates the regression-based estimates and the corresponding error distribution. The Chebyshev interpolation method exhibits a notably narrower error distribution with reduced tail behavior, and more uniform spread of error across the pricing surface. In contrast, the regression-based errors are more dispersed in the right tail, indicating higher localized discrepancies, especially in the extreme ends of the parameter domain. Furthermore, the distribution of estimated values from both methods highlights the superior accuracy of Chebyshev interpolation, which more closely replicates the Monte Carlo simulated prices when compared to the regression-based approach.
The results of the two statistical tests are shown in
Table 5, and the corresponding cumulative distribution functions (CDF) are depicted in
Figure 8. These results support the conclusions drawn in the preceding analysis. While the two methods yield comparable
t-test statistics, the Chebyshev interpolation demonstrates superior performance in the Kolmogorov-Smirnov (KS) test. Specifically, the CDF of prices estimated via Chebyshev interpolation closely aligns with that of the Monte Carlo simulation, indicating a more accurate overall distributional match.
4.4. Practical Implications
As a practical implication we report on the liquidity value adjustment (LVA) of our model. The impact of calibrated parameters on the price of spread option across various combinations of strike price and time to maturity (
) is explored; the initial stock values are
and
The results reveal that the liquidity adjustment becomes more pronounced for out-of-the-money options than in the money option. This effect is explained by the additional drift term introduced in the stochastic differential equation governing
which increases the likelihood of the option ending up in the money at maturity. Consequently, the option’s fair price rises to compensate for the elevated hedging costs faced by the writer under illiquid conditions (see
Table 6,
Table 7,
Table 8 and
Table 9).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}