
Estimating Disease-Free Life Expectancy Based on Clinical Data from the French Hospital Discharge Database

 , , and
, , and
Abstract
1. Introduction
2. Data
2.1. Description
2.2. Summary Statistics
3. Methods
3.1. Statistical Tools
- is the observed event time for the ith observation;
- is the number of non-censored events at ;
- is the number of individuals at risk just before .
3.2. Statistical Modeling
3.3. Whole-Population Adjustment
- The population included in the PMSI is, on average, in worse health than the general population since they required hospitalization;
- Exclusions applied to the original PMSI data should result in a study population that is healthier than the PMSI population.
4. Results
4.1. Dis-FLE and Comparison to Eurostat’s HLY
4.2. Cox Model Inferences
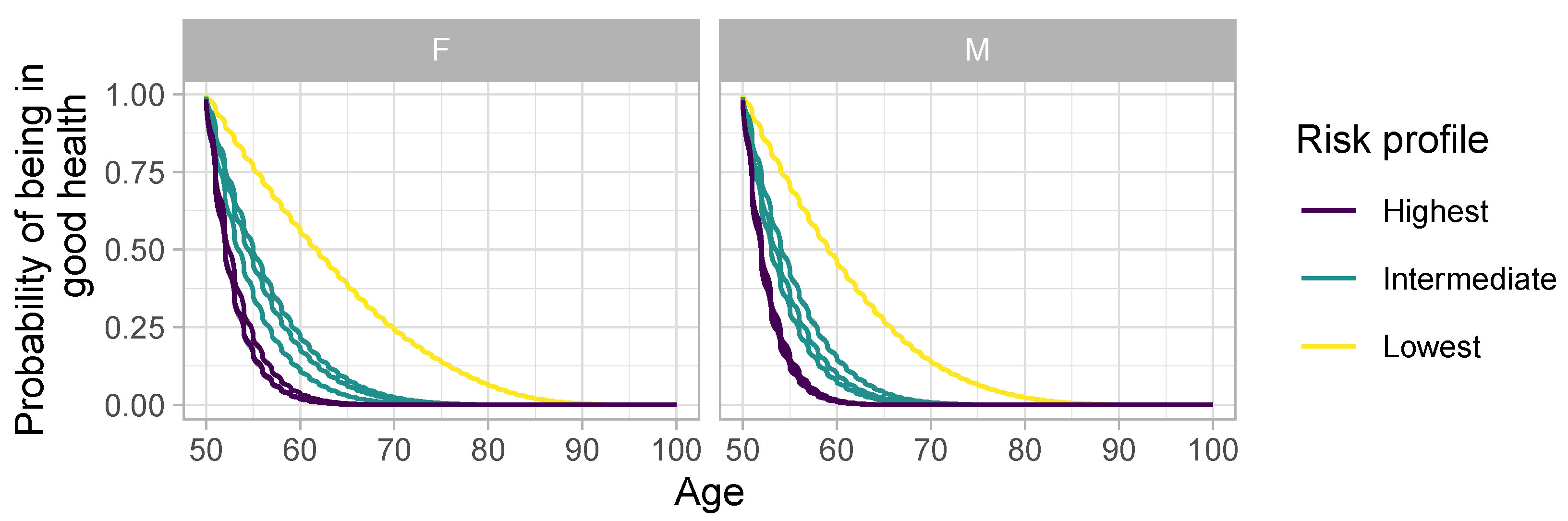
4.2.1. Risk Profiles
- The “Lowest” risk profile, representing individuals without any risk factors.
- The “Intermediate” risk profile, involving one risk-increasing behavior.
- The “Highest” risk profile, featuring two risk-increasing behaviors.
4.2.2. Sex
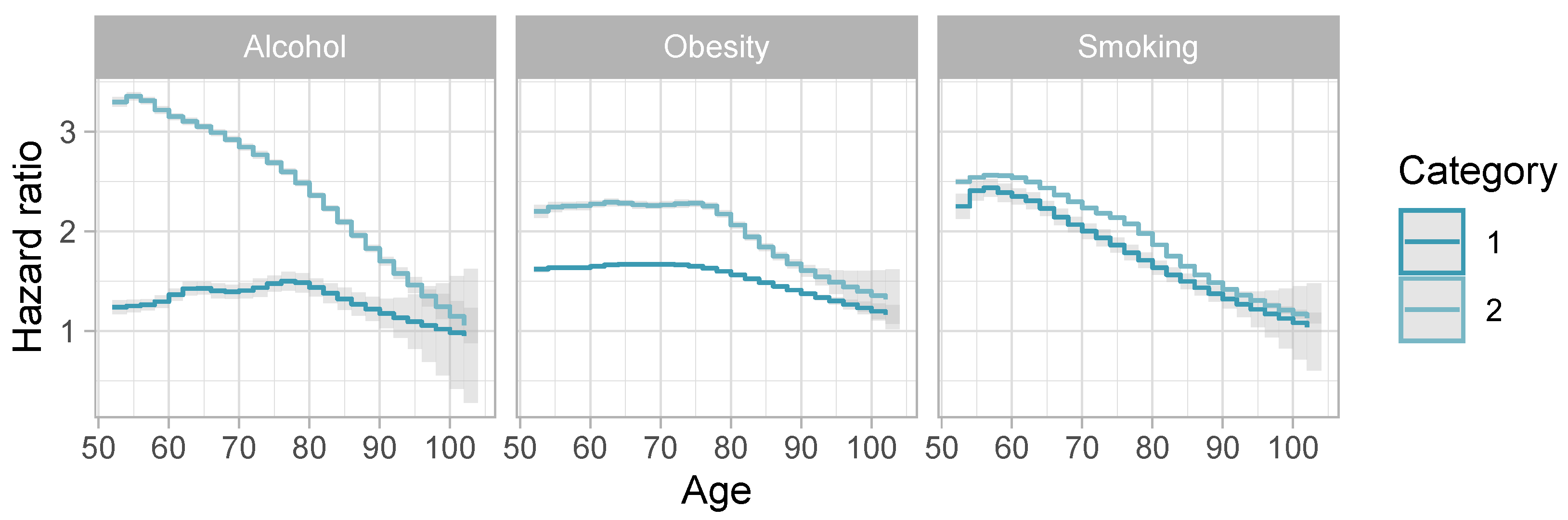
4.2.3. Behavioral Risk Factors
- Tobacco consumption;
- Alcohol consumption;
- Obesity.
4.2.4. Multiple Behavioral Risk Factors
- The main effects;
- The naive combined effect of two risk factors (calculated by multiplying the hazard ratios of the main effects without considering the interaction term);
- The estimated effect that accounts for the interaction term.
4.2.5. Behavioral Risk Factors Conditional on Sex
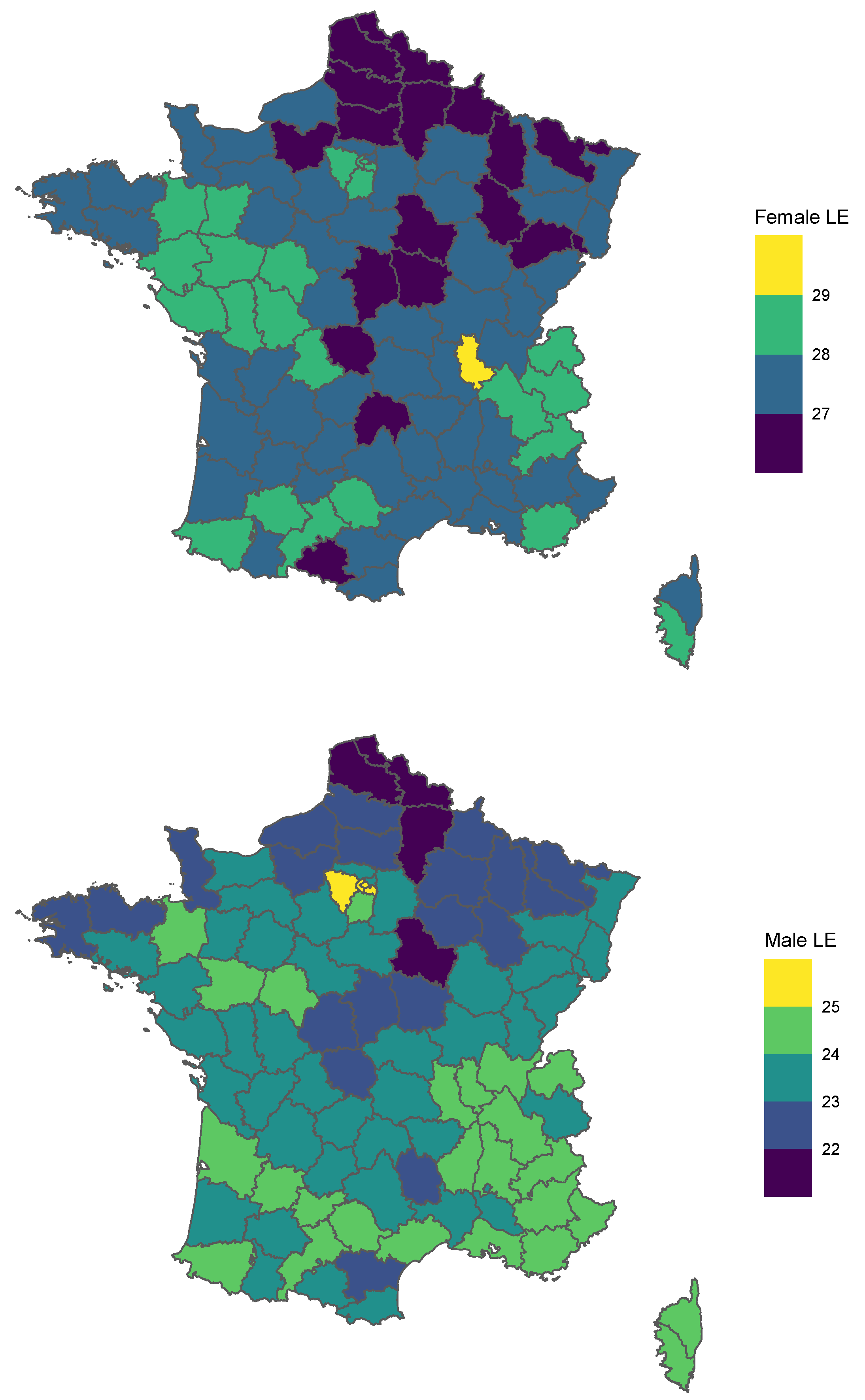
4.2.6. Geographical
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Exclusion Criteria

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Years | Pop. Size | % of Total Pop. |
|---|---|---|---|
| Hospitalized population, aged 50 and up | 2008–2013 | 18,440,022 | 100.0% |
| Exclusion criterion 1: severe conditions under study observed in 2008–2009 | 2008, 2009 | 4,730,651 | 25.7% |
| Alzheimer’s disease | 508,575 | 2.8% | |
| Other severe conditions | 4,554,010 | 24.7% | |
| Total loss of autonomy, cognitive or physical | 205,681 | 1.1% | |
| Death observed in a hospital | 572 454 | 3.1% | |
| Death outside of hospital (imputed from other data) | 272 742 | 1.5% | |
| Exclusion criterion 2: other conditions not covered by dependence insurance | 914,595 | 5.0% | |
| Major neurological disorder | 2008, 2009 | ||
| Paralysis | 197,096 | 1.1% | |
| Coma | 97,476 | 0.5% | |
| Transplant recipients (of an organ or of bone marrow) | 2008, 2009 | 36,593 | 0.2% |
| Birth defects and genetic disorders | 2008–2013 | ||
| Birth defect or chromosome abnormality (including trisomy 21) | 272,887 | 1.5% | |
| Primary immunodeficiency | 37,101 | 0.2% | |
| Thalassemia, sickle cell disease, and other blood disorders | 16,200 | 0.1% | |
| Hemophilia and other bleeding disorders | 16,600 | 0.1% | |
| Inborn errors of metabolism (including hemochromatosis and cystic fibrosis) | 210,176 | 1.1% | |
| Cerebral palsy and genetic neuromuscular disorders (including myopathy) | 70,587 | 0.4% | |
| Other genetic disorders (including Alport syndrome) | 2252 | 0.0% | |
| Infections | 2008–2013 | ||
| Human immunodeficiency viruses (HIV) | 43,734 | 0.2% | |
| Infectious diseases (including tuberculosis and encephalitis) | 49,524 | 0.3% | |
| Mental disorders | 2008–2013 | ||
| Schizophrenia and others delusional disorders | 175,527 | 1.0% | |
| Intellectual disability | 44,936 | 0.2% | |
| Hospitalized population, aged 50 and up in good health on the 1st of January 2010 (selected after exclusion criteria 1 and 2) | 2010–2013 | 13,170,355 | 71.4% |
| Data preparation for analysis | 2008, 2009 | 2,559,726 | 13.9% |
| Censored before 1 January 2010 | 2,012,815 | 10.9% | |
| End of observation period ends before 50 | 896,111 | 4.9% | |
| Population included in study | 2010–2013 | 10,610,629 | 57.5% |
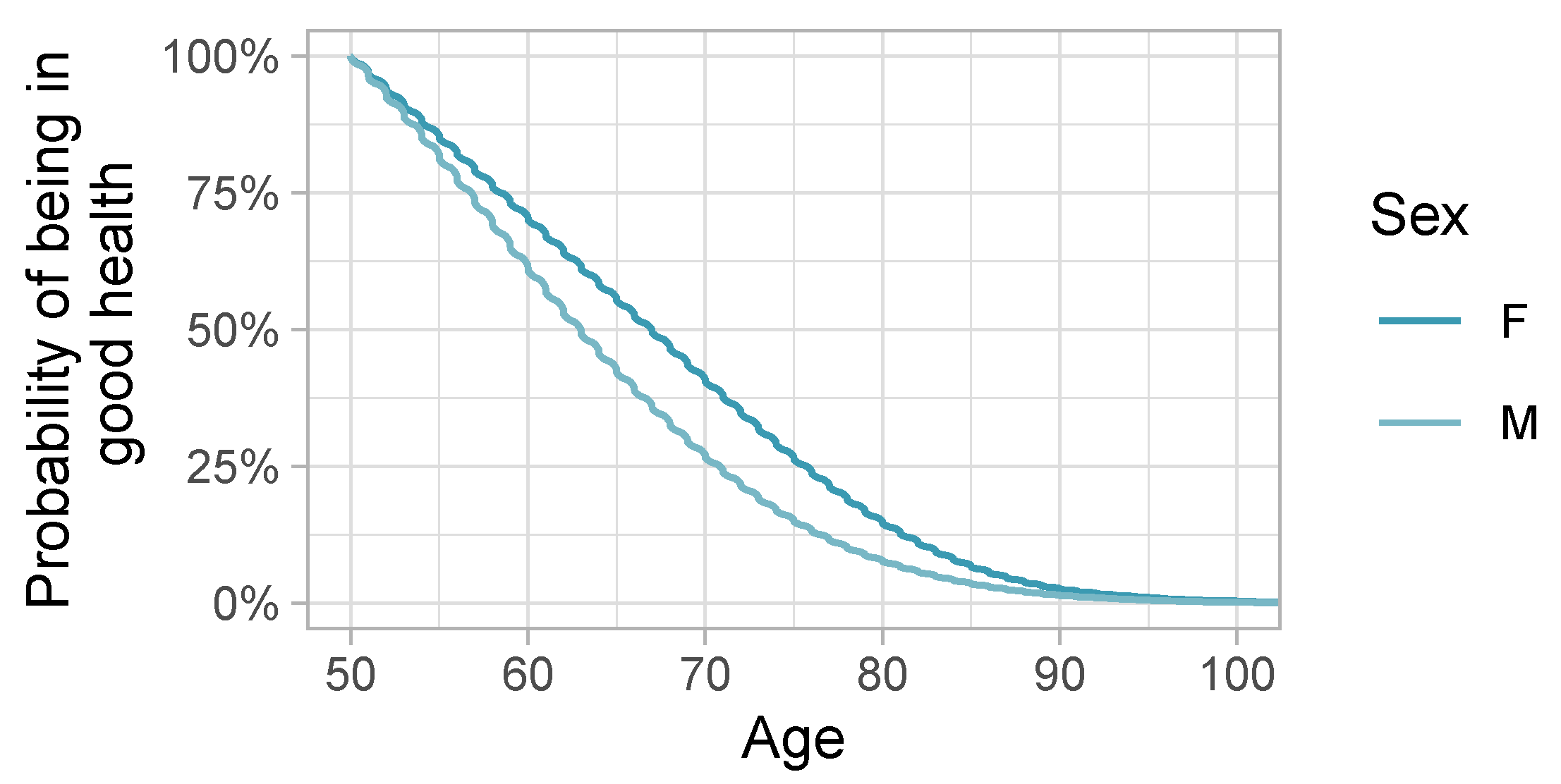
Appendix B. Sex-Specific Survival Curves without Adjustment
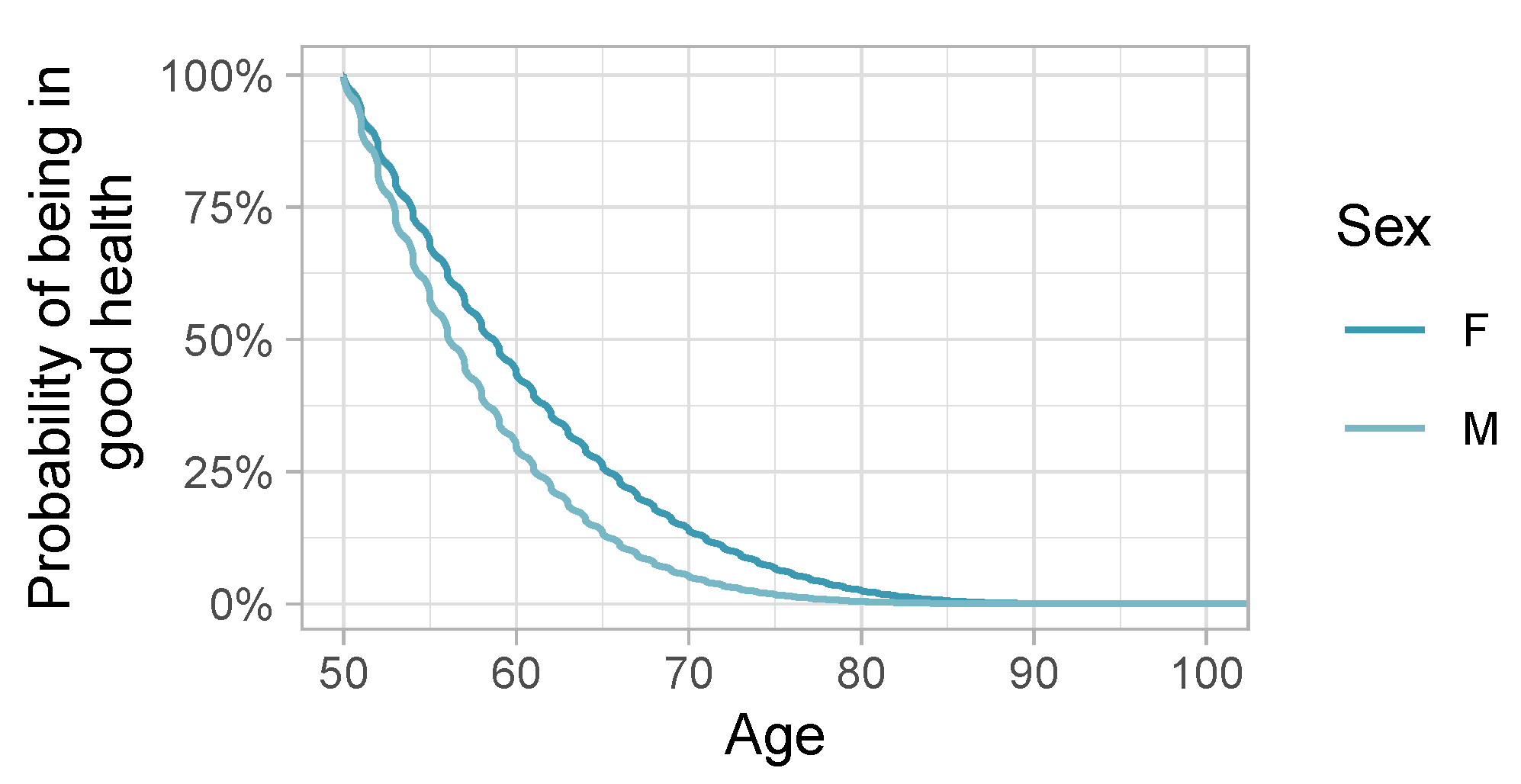
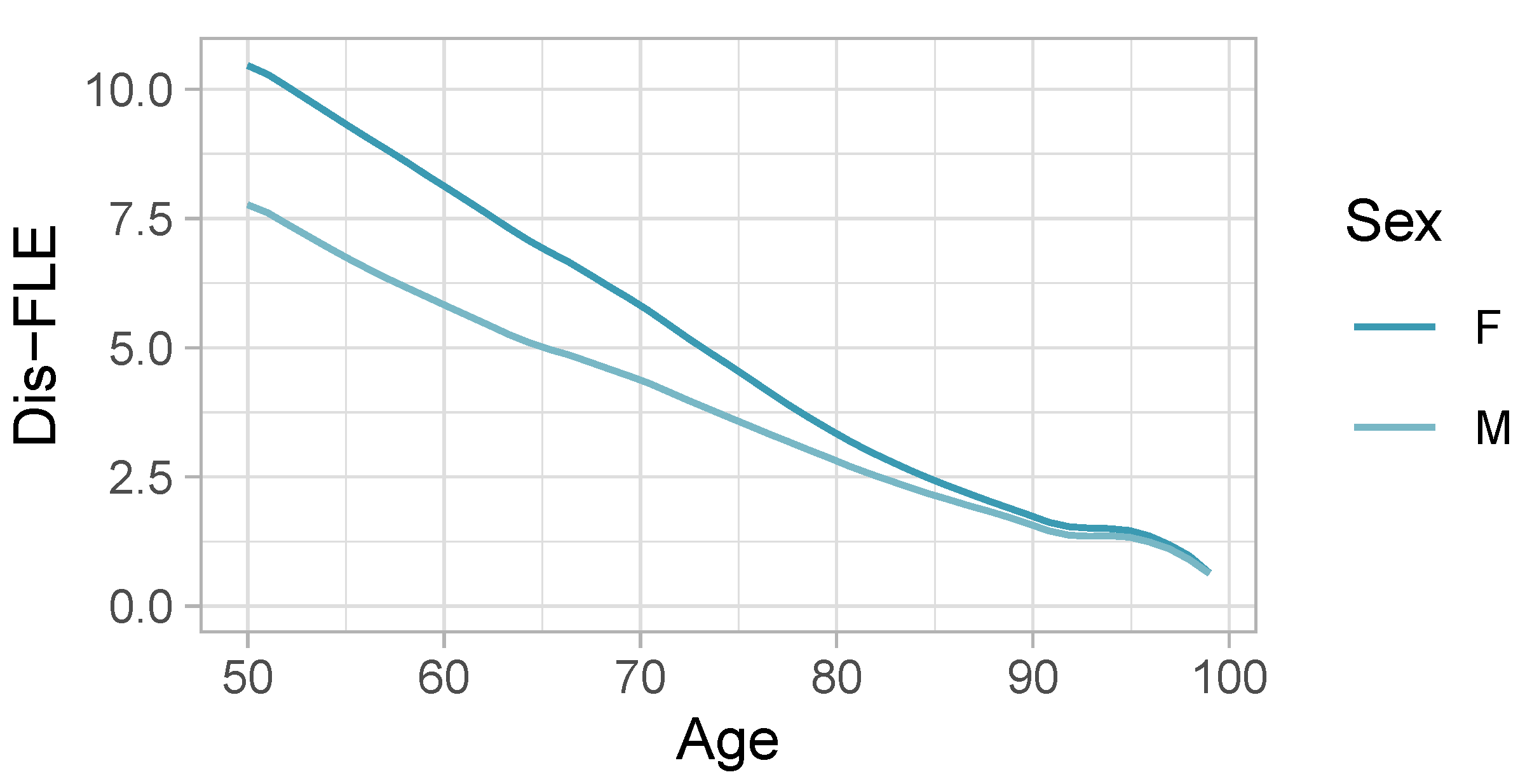
Appendix C. Model Diagnostics

Appendix D. All Cox Model Coefficients
| Term | Hazard Ratio | Std. Err. | p-Value |
|---|---|---|---|
| Obesity, cat. 1 | 1.62 | 0.01 | 0.00 |
| Obesity, cat. 2 | 2.20 | 0.02 | 0.00 |
| Alcohol, cat. 1 | 1.24 | 0.03 | 0.00 |
| Alcohol, cat. 2 | 3.30 | 0.01 | 0.00 |
| Smoking, cat. 1 | 2.25 | 0.04 | 0.00 |
| Smoking, cat. 2 | 2.50 | 0.01 | 0.00 |
| Sex: M | 1.28 | 0.01 | 0.00 |
| Department of residence: 02 | 1.07 | 0.01 | 0.00 |
| Department of residence: 03 | 1.05 | 0.01 | 0.00 |
| Department of residence: 04 | 0.95 | 0.01 | 0.00 |
| Department of residence: 05 | 1.02 | 0.02 | 0.16 |
| Department of residence: 06 | 0.91 | 0.01 | 0.00 |
| Department of residence: 07 | 1.03 | 0.01 | 0.01 |
| Department of residence: 08 | 1.20 | 0.01 | 0.00 |
| Department of residence: 09 | 1.06 | 0.01 | 0.00 |
| Department of residence: 10 | 1.00 | 0.01 | 0.83 |
| Department of residence: 11 | 1.07 | 0.01 | 0.00 |
| Department of residence: 12 | 1.04 | 0.01 | 0.00 |
| Department of residence: 13 | 0.95 | 0.01 | 0.00 |
| Department of residence: 14 | 1.09 | 0.01 | 0.00 |
| Department of residence: 15 | 1.03 | 0.01 | 0.02 |
| Department of residence: 16 | 0.96 | 0.01 | 0.00 |
| Department of residence: 17 | 1.06 | 0.01 | 0.00 |
| Department of residence: 18 | 1.08 | 0.01 | 0.00 |
| Department of residence: 19 | 1.10 | 0.01 | 0.00 |
| Department of residence: 21 | 1.03 | 0.01 | 0.00 |
| Department of residence: 22 | 1.08 | 0.01 | 0.00 |
| Department of residence: 23 | 1.09 | 0.01 | 0.00 |
| Department of residence: 24 | 1.05 | 0.01 | 0.00 |
| Department of residence: 25 | 1.06 | 0.01 | 0.00 |
| Department of residence: 26 | 1.01 | 0.01 | 0.59 |
| Department of residence: 27 | 1.04 | 0.01 | 0.00 |
| Department of residence: 28 | 1.04 | 0.01 | 0.00 |
| Department of residence: 29 | 1.03 | 0.01 | 0.00 |
| Department of residence: 2A | 1.03 | 0.01 | 0.06 |
| Department of residence: 2B | 0.99 | 0.01 | 0.46 |
| Department of residence: 30 | 0.98 | 0.01 | 0.01 |
| Department of residence: 31 | 1.01 | 0.01 | 0.33 |
| Department of residence: 32 | 1.06 | 0.01 | 0.00 |
| Department of residence: 33 | 1.02 | 0.01 | 0.04 |
| Department of residence: 34 | 1.00 | 0.01 | 0.97 |
| Department of residence: 35 | 0.98 | 0.01 | 0.05 |
| Department of residence: 36 | 1.03 | 0.01 | 0.01 |
| Department of residence: 37 | 0.98 | 0.01 | 0.05 |
| Department of residence: 38 | 1.00 | 0.01 | 0.64 |
| Department of residence: 39 | 1.02 | 0.01 | 0.14 |
| Department of residence: 40 | 1.03 | 0.01 | 0.01 |
| Department of residence: 41 | 0.98 | 0.01 | 0.04 |
| Department of residence: 42 | 0.98 | 0.01 | 0.06 |
| Department of residence: 43 | 1.01 | 0.01 | 0.27 |
| Department of residence: 44 | 1.03 | 0.01 | 0.00 |
| Department of residence: 45 | 1.01 | 0.01 | 0.14 |
| Department of residence: 46 | 1.04 | 0.01 | 0.00 |
| Department of residence: 47 | 0.97 | 0.01 | 0.00 |
| Department of residence: 48 | 1.11 | 0.02 | 0.00 |
| Department of residence: 49 | 0.94 | 0.01 | 0.00 |
| Department of residence: 50 | 1.07 | 0.01 | 0.00 |
| Department of residence: 51 | 1.03 | 0.01 | 0.00 |
| Department of residence: 52 | 1.13 | 0.01 | 0.00 |
| Department of residence: 53 | 0.93 | 0.01 | 0.00 |
| Department of residence: 54 | 1.05 | 0.01 | 0.00 |
| Department of residence: 55 | 1.13 | 0.01 | 0.00 |
| Department of residence: 56 | 1.07 | 0.01 | 0.00 |
| Department of residence: 57 | 1.14 | 0.01 | 0.00 |
| Department of residence: 58 | 1.10 | 0.01 | 0.00 |
| Department of residence: 59 | 1.10 | 0.01 | 0.00 |
| Department of residence: 60 | 1.04 | 0.01 | 0.00 |
| Department of residence: 61 | 1.09 | 0.01 | 0.00 |
| Department of residence: 62 | 1.12 | 0.01 | 0.00 |
| Department of residence: 63 | 1.08 | 0.01 | 0.00 |
| Department of residence: 64 | 1.08 | 0.01 | 0.00 |
| Department of residence: 65 | 1.09 | 0.01 | 0.00 |
| Department of residence: 66 | 0.96 | 0.01 | 0.00 |
| Department of residence: 67 | 1.05 | 0.01 | 0.00 |
| Department of residence: 68 | 1.04 | 0.01 | 0.00 |
| Department of residence: 69 | 1.02 | 0.01 | 0.06 |
| Department of residence: 70 | 1.09 | 0.01 | 0.00 |
| Department of residence: 71 | 1.02 | 0.01 | 0.02 |
| Department of residence: 72 | 1.00 | 0.01 | 0.86 |
| Department of residence: 73 | 1.02 | 0.01 | 0.07 |
| Department of residence: 74 | 1.02 | 0.01 | 0.02 |
| Department of residence: 75 | 1.03 | 0.01 | 0.00 |
| Department of residence: 76 | 1.01 | 0.01 | 0.11 |
| Department of residence: 77 | 1.05 | 0.01 | 0.00 |
| Department of residence: 78 | 0.98 | 0.01 | 0.08 |
| Department of residence: 79 | 0.96 | 0.01 | 0.00 |
| Department of residence: 80 | 1.08 | 0.01 | 0.00 |
| Department of residence: 81 | 1.06 | 0.01 | 0.00 |
| Department of residence: 82 | 0.98 | 0.01 | 0.05 |
| Department of residence: 83 | 0.99 | 0.01 | 0.20 |
| Department of residence: 84 | 0.94 | 0.01 | 0.00 |
| Department of residence: 85 | 1.00 | 0.01 | 0.91 |
| Department of residence: 86 | 1.03 | 0.01 | 0.00 |
| Department of residence: 87 | 1.07 | 0.01 | 0.00 |
| Department of residence: 88 | 1.03 | 0.01 | 0.00 |
| Department of residence: 89 | 1.07 | 0.01 | 0.00 |
| Department of residence: 90 | 1.09 | 0.02 | 0.00 |
| Department of residence: 91 | 1.02 | 0.01 | 0.01 |
| Department of residence: 92 | 1.03 | 0.01 | 0.00 |
| Department of residence: 93 | 1.07 | 0.01 | 0.00 |
| Department of residence: 94 | 1.04 | 0.01 | 0.00 |
| Department of residence: 95 | 1.04 | 0.01 | 0.00 |
| Immigration: Q1 | 1.00 | 0.00 | 0.25 |
| Immigration: Q2 | 1.01 | 0.00 | 0.00 |
| Immigration: Q3 | 1.01 | 0.00 | 0.00 |
| Education: Q1 | 1.03 | 0.00 | 0.00 |
| Education: Q2 | 1.05 | 0.00 | 0.00 |
| Education: Q3 | 1.07 | 0.00 | 0.00 |
| Obesity, cat. 1 × Alcohol, cat. 1 | 0.84 | 0.03 | 0.00 |
| Obesity, cat. 2 × alcohol, cat. 1 | 0.88 | 0.06 | 0.03 |
| Obesity, cat. 1 × alcohol, cat. 2 | 0.76 | 0.01 | 0.00 |
| Obesity, cat. 2 × alcohol, cat. 2 | 0.69 | 0.02 | 0.00 |
| Obesity, cat. 1 × smoking, cat. 1 | 0.68 | 0.02 | 0.00 |
| Obesity, cat. 2 × smoking, cat. 1 | 0.64 | 0.05 | 0.00 |
| Obesity, cat. 1 × smoking, cat. 2 | 0.77 | 0.01 | 0.00 |
| Obesity, cat. 2 × smoking, cat. 2 | 0.75 | 0.01 | 0.00 |
| Obesity, cat. 1 × sex: M | 0.98 | 0.00 | 0.00 |
| Obesity, cat. 2 × sex: M | 0.93 | 0.01 | 0.00 |
| Alcohol, cat. 1 × smoking, cat. 1 | 0.78 | 0.04 | 0.00 |
| Alcohol, cat. 2 × smoking, cat. 1 | 0.53 | 0.03 | 0.00 |
| Alcohol, cat. 1 × smoking, cat. 2 | 0.67 | 0.02 | 0.00 |
| Alcohol, cat. 2 × smoking, cat. 2 | 0.60 | 0.01 | 0.00 |
| Alcohol, cat. 1 × sex: M | 1.01 | 0.02 | 0.63 |
| Alcohol, cat. 2 × sex: M | 0.88 | 0.01 | 0.00 |
| Smoking, cat. 1 × sex: M | 0.92 | 0.02 | 0.00 |
| Smoking, cat. 2 × sex: M | 1.01 | 0.00 | 0.02 |
| Obesity, cat. 1 × spline (age): knot 1 | 1.01 | 0.01 | 0.48 |
| Obesity, cat. 2 × spline (age): knot 1 | 1.02 | 0.03 | 0.46 |
| Obesity, cat. 1 × spline (age): knot 2 | 1.01 | 0.01 | 0.49 |
| Obesity, cat. 2 × spline (age): knot 2 | 1.02 | 0.03 | 0.34 |
| Obesity, cat. 1 × spline (age): knot 3 | 1.03 | 0.01 | 0.05 |
| Obesity, cat. 2 × spline (age): knot 3 | 1.04 | 0.03 | 0.12 |
| Obesity, cat. 1 × spline (age): knot 4 | 1.03 | 0.01 | 0.02 |
| Obesity, cat. 2 × spline (age): knot 4 | 1.03 | 0.02 | 0.25 |
| Obesity, cat. 1 × spline (age): knot 5 | 1.03 | 0.01 | 0.05 |
| Obesity, cat. 2 × spline (age): knot 5 | 1.03 | 0.03 | 0.19 |
| Obesity, cat. 1 × spline (age): knot 6 | 1.01 | 0.01 | 0.66 |
| Obesity, cat. 2 × spline (age): knot 6 | 1.02 | 0.03 | 0.35 |
| Obesity, cat. 1 × spline (age): knot 7 | 0.94 | 0.01 | 0.00 |
| Obesity, cat. 2 × spline (age): knot 7 | 0.88 | 0.03 | 0.00 |
| Obesity, cat. 1 × spline (age): knot 8 | 0.70 | 0.05 | 0.00 |
| Obesity, cat. 2 × spline (age): knot 8 | 0.58 | 0.16 | 0.00 |
| Alcohol, cat. 1 × spline (age): knot 1 | 1.01 | 0.03 | 0.76 |
| Alcohol, cat. 2 × spline (age): knot 1 | 1.02 | 0.01 | 0.25 |
| Alcohol, cat. 1 × spline (age): knot 2 | 1.04 | 0.03 | 0.18 |
| Alcohol, cat. 2 × spline (age): knot 2 | 0.98 | 0.01 | 0.10 |
| Alcohol, cat. 1 × spline (age): knot 3 | 1.15 | 0.04 | 0.00 |
| Alcohol, cat. 2 × spline (age): knot 3 | 0.94 | 0.02 | 0.00 |
| Alcohol, cat. 1 × spline (age): knot 4 | 1.13 | 0.04 | 0.00 |
| Alcohol, cat. 2 × spline (age): knot 4 | 0.91 | 0.01 | 0.00 |
| Alcohol, cat. 1 × spline (age): knot 5 | 1.16 | 0.04 | 0.00 |
| Alcohol, cat. 2 × spline (age): knot 5 | 0.84 | 0.02 | 0.00 |
| Alcohol, cat. 1 × spline (age): knot 6 | 1.21 | 0.05 | 0.00 |
| Alcohol, cat. 2 × spline (age): knot 6 | 0.79 | 0.02 | 0.00 |
| Alcohol, cat. 1 × spline (age): knot 7 | 1.11 | 0.05 | 0.03 |
| Alcohol, cat. 2 × spline (age): knot 7 | 0.68 | 0.02 | 0.00 |
| Alcohol, cat. 1 × spline (age): knot 8 | 0.74 | 0.41 | 0.47 |
| Alcohol, cat. 2 × spline (age): knot 8 | 0.29 | 0.10 | 0.00 |
| Smoking, cat. 1 × spline (age): knot 1 | 1.07 | 0.05 | 0.14 |
| Smoking, cat. 2 × spline (age): knot 1 | 1.02 | 0.01 | 0.11 |
| Smoking, cat. 1 × spline (age): knot 2 | 1.06 | 0.05 | 0.20 |
| Smoking, cat. 2 × spline (age): knot 2 | 1.02 | 0.01 | 0.03 |
| Smoking, cat. 1 × spline (age): knot 3 | 1.02 | 0.05 | 0.60 |
| Smoking, cat. 2 × spline (age): knot 3 | 1.00 | 0.01 | 0.96 |
| Smoking, cat. 1 × spline (age): knot 4 | 0.95 | 0.05 | 0.28 |
| Smoking, cat. 2 × spline (age): knot 4 | 0.95 | 0.01 | 0.00 |
| Smoking, cat. 1 × spline (age): knot 5 | 0.86 | 0.05 | 0.00 |
| Smoking, cat. 2 × spline (age): knot 5 | 0.87 | 0.01 | 0.00 |
| Smoking, cat. 1 × spline (age): knot 6 | 0.79 | 0.05 | 0.00 |
| Smoking, cat. 2 × spline (age): knot 6 | 0.83 | 0.01 | 0.00 |
| Smoking, cat. 1 × spline (age): knot 7 | 0.69 | 0.05 | 0.00 |
| Smoking, cat. 2 × spline (age): knot 7 | 0.70 | 0.01 | 0.00 |
| Smoking, cat. 1 × spline (age): knot 8 | 0.44 | 0.26 | 0.00 |
| Smoking, cat. 2 × spline (age): knot 8 | 0.44 | 0.03 | 0.00 |
| Sex: M × spline (age): knot 1 | 1.02 | 0.01 | 0.01 |
| Sex: M × spline (age): knot 2 | 1.07 | 0.01 | 0.00 |
| Sex: M × spline (age): knot 3 | 1.10 | 0.01 | 0.00 |
| Sex: M × spline (age): knot 4 | 1.12 | 0.01 | 0.00 |
| Sex: M × spline (age): knot 5 | 1.10 | 0.01 | 0.00 |
| Sex: M × spline (age): knot 6 | 1.05 | 0.01 | 0.00 |
| Sex: M × spline (age): knot 7 | 0.94 | 0.01 | 0.00 |
| Sex: M × spline (age): knot 8 | 0.84 | 0.02 | 0.00 |
References
- Abe, Shinzo. 2013. Japan’s strategy for global health diplomacy: Why it matters. The Lancet 382: 915–16. [Google Scholar] [CrossRef] [PubMed]
- Bogaert, Petronille, Herman Van Oyen, Isabelle Beluche, Emmanuelle Cambois, and Jean-Marie Robine. 2018. The use of the global activity limitation Indicator and healthy life years by member states and the European Commission. Archives of Public Health 76: 30. [Google Scholar] [CrossRef] [PubMed]
- Euro-REVES, Carol Jagger, Viviana Egidi, and Jean Marie Robine. 2000. Selection of a Coherent Set of Health Indicators. Final Draft, Euro-REVES. Available online: https://ec.europa.eu/health/ph_projects/1998/monitoring/fp_monitoring_1998_frep_03_en.pdf (accessed on 16 June 2023).
- Eurostat. 2020. Healthy Life Years by Sex (from 2004 Onwards) (hlth_hlye). Eurostat Database. Available online: https://ec.europa.eu/eurostat/databrowser/view/HLTH_HLYE/default/table?lang=en (accessed on 16 May 2023).
- Fries, James F. 1980. Aging, Natural Death, and the Compression of Morbidity. New England Journal of Medicine 303: 130–35. [Google Scholar] [CrossRef] [PubMed]
- Gruenberg, Ernest M. 2005. The Failures of Success. Milbank Quarterly 83: 779–800. [Google Scholar] [CrossRef] [PubMed]
- Guibert, Quentin, Frédéric Planchet, and Michaël Schwarzinger. 2018a. Mesure de l’espérance de vie sans dépendance totale en France métropolitaine. Bulletin Français d’Actuariat 18: 85–109. [Google Scholar]
- Guibert, Quentin, Frédéric Planchet, and Michaël Schwarzinger. 2018b. Mesure du risque de perte d’autonomie totale en France métropolitaine. Bulletin Français d’Actuariat 18: 133–59. [Google Scholar]
- Head, Jenny, Holendro Singh Chungkham, Martin Hyde, Paola Zaninotto, Kristina Alexanderson, Sari Stenholm, Paula Salo, Mika Kivimäki, Marcel Goldberg, Marie Zins, and et al. 2019. Socioeconomic differences in healthy and disease-free life expectancy between ages 50 and 75: A multi-cohort study. European Journal of Public Health 29: 267–72. [Google Scholar] [CrossRef] [PubMed]
- INSEE. 2022. La situation démographique en 2020. INSEE Reports. Available online: https://www.insee.fr/fr/statistiques/6327226?sommaire=6327254 (accessed on 15 May 2023).
- INSEE. 2023. Espérances de vie à différents âges. INSEE Reports. Available online: https://www.insee.fr/fr/outil-interactif/6794598/EVDA/DEPARTMENTS (accessed on 19 April 2024).
- Jagger, Carol, Eileen M. Crimmins, Yasuhiko Saito, Renata Tiene De Carvalho Yokota, Herman Van Oyen, and Jean-Marie Robine, eds. 2020. International Handbook of Health Expectancies. Volume 9 of International Handbooks of Population. Cham: Springer International Publishing. [Google Scholar] [CrossRef]
- Kempen, Gertrudis I. J. M., Nardi Steverink, Johan Ormel, and Dorly J. H. Deeg. 1996. The Assessment of ADL among Frail Elderly in an Interview Survey: Self-Report versus Performance-Based Tests and Determinants of Discrepancies. The Journals of Gerontology Series B: Psychological Sciences and Social Sciences 51B: P254–P260. [Google Scholar] [CrossRef] [PubMed]
- Kim, Young-Eun, Yoon-Sun Jung, Minsu Ock, and Seok-Jun Yoon. 2022. A Review of the Types and Characteristics of Healthy Life Expectancy and Methodological Issues. Journal of Preventive Medicine and Public Health 55: 1–9. [Google Scholar] [CrossRef] [PubMed]
- Klein, John P., Hans C. Van Houwelingen, Joseph G. Ibrahim, and Thomas H. Scheike, eds. 2016. Handbook of Survival Analysis. Boca Raton: Chapman and Hall/CRC. [Google Scholar] [CrossRef]
- Krause, Neal M., and Gina M. Jay. 1994. What Do Global Self-Rated Health Items Measure? Medical Care 32: 930–42. [Google Scholar] [CrossRef] [PubMed]
- Lagström, Hanna, Sari Stenholm, Tasnime Akbaraly, Jaana Pentti, Jussi Vahtera, Mika Kivimäki, and Jenny Head. 2020. Diet quality as a predictor of cardiometabolic disease–free life expectancy: The Whitehall II cohort study. The American Journal of Clinical Nutrition 111: 787–94. [Google Scholar] [CrossRef] [PubMed]
- Martinussen, Torben, and Thomas H. Scheike. 2006. Dynamic Regression Models for Survival Data. Statistics for Biology and Health. New York: Springer. [Google Scholar]
- Peersman, Wim, Dirk Cambier, Jan De Maeseneer, and Sara Willems. 2012. Gender, educational and age differences in meanings that underlie global self-rated health. International Journal of Public Health 57: 513–23. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. 2022. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. [Google Scholar]
- Robine, Jean-Marie. 2003. Creating a coherent set of indicators to monitor health across Europe: The Euro-REVES 2 project. The European Journal of Public Health 13: 6–14. [Google Scholar] [CrossRef] [PubMed]
- Sanders, Barkev S. 1964. Measuring community health levels. American Journal of Public Health and the Nation’s Health 54: 1063–70. [Google Scholar] [CrossRef] [PubMed]
- Schwarzinger, Michaël. 2018. Etude QalyDays: Données source et retraitements pour l’étude du risque perte d’autonomie. Bulletin Français d’Actuariat 18: 57–81. [Google Scholar]
- Schwarzinger, Michaël, Bruce G. Pollock, Omer S. M. Hasan, Carole Dufouil, Jürgen Rehm, and QalyDays Study Group. 2018. Contribution of alcohol use disorders to the burden of dementia in France 2008–13: A nationwide retrospective cohort study. The Lancet Public Health 3: e124–e132. [Google Scholar] [CrossRef] [PubMed]
- Stenholm, Sari, Jenny Head, Ville Aalto, Mika Kivimäki, Ichiro Kawachi, Marie Zins, Marcel Goldberg, Loretta G. Platts, Paola Zaninotto, Linda L. Magnusson Hanson, and et al. 2017. Body mass index as a predictor of healthy and disease-free life expectancy between ages 50 and 75: A multicohort study. International Journal of Obesity 41: 769–75. [Google Scholar] [CrossRef] [PubMed]
- Therneau, Terry M. 2023. A Package for Survival Analysis in R. R Package Version 3.6-4. Available online: https://CRAN.R-project.org/package=survival (accessed on 1 January 2024).
- WHO. 2023. World Health Statistics: Monitoring Health for the SGDs, Sustainable Development Goals. Technical Report. Geneva: World Health Organization. [Google Scholar]
- World Health Organization. 2015. International Statistical Classification of Diseases and Related Health Problems. 10th Revision (Fifth edition). Technical Report. Geneva: World Health Organization. ISBN 9789241549165. [Google Scholar]
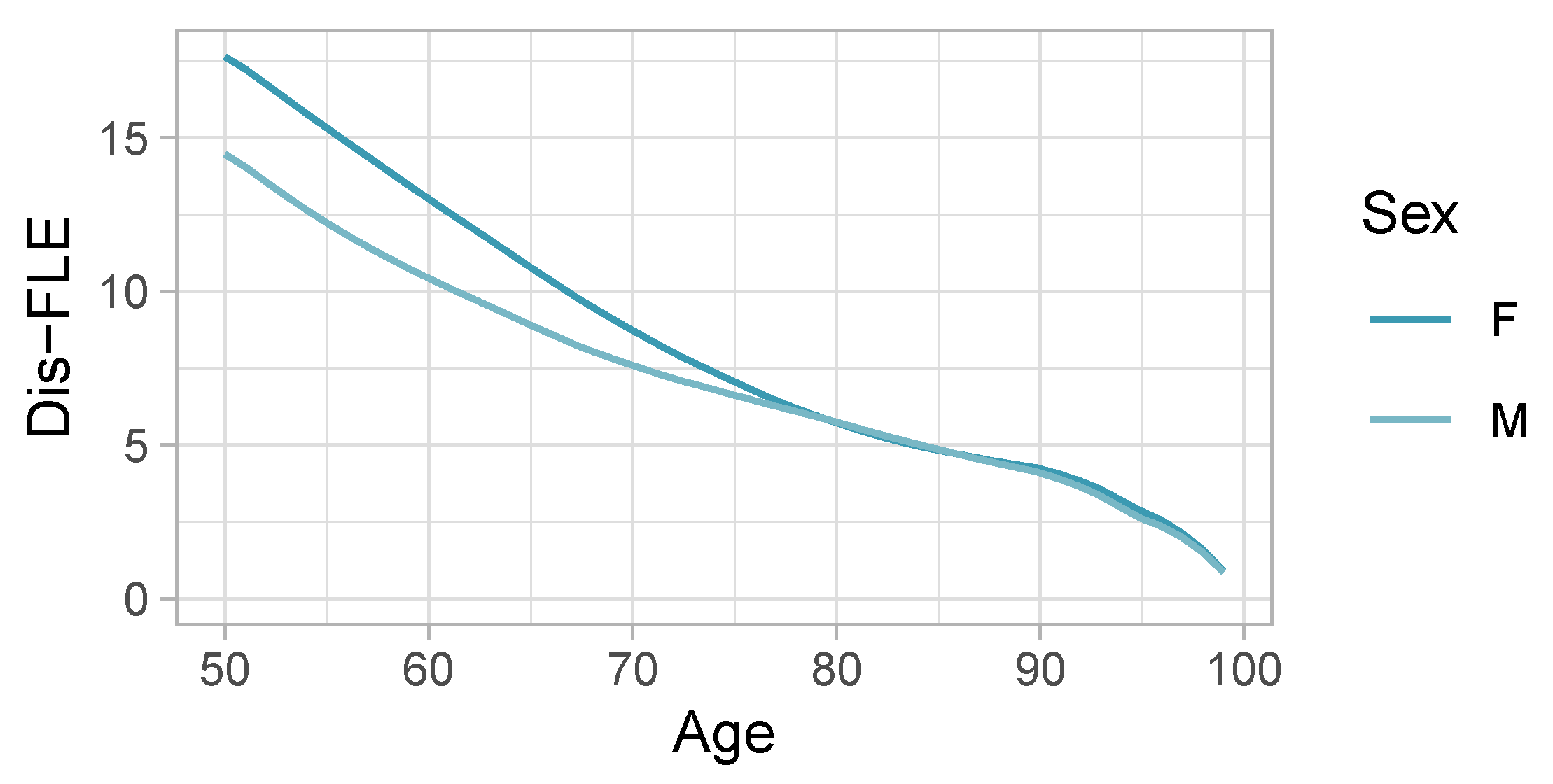




| Column | Precision | Possible Values | Description |
|---|---|---|---|
| ID | Individual | Positive integers | Anonymized identifier |
| Alcohol | Individual | 0, 1, 2 | Alcohol use disorder, grouped into three classes in increasing order: “0” for the absence of alcohol use disorder, “1” for mental and behavioral disorders due to former or current chronic harmful use of alcohol (ICD-10: F10.1–F10.9, Z50.2) including alcohol abstinence (ICD-10: F10.20–F10.23), “2” chronic diseases attributable to alcohol use disorders (e.g., Wernicke–Korsakoff syndrome, end-stage liver disease and other forms of liver cirrhosis, epilepsy, and head injury) |
| Obesity | Individual | 0, 1, 2 | Obesity, grouped into three classes in increasing order: “0” body mass < 30 kg/m2, “1” body mass ≥ 30 kg/m2 and <40 kg/m2, “2” body mass > 40 kg/m2. |
| Smoker | Individual | 0, 1, 2 | Smoking, grouped into three classes in increasing order: “0”: no disorder due to tobacco use recorded, “1”: mental and behavioral disorders due to tobacco use (ICD-10: F17), “2”: mental and behavioral disorders due to tobacco use (ICD-10: F17) and Chronic Obstructive Pulmonary Disease (ICD-10: J44.9). |
| Department | Individual | “01” to “96” | Department of residence (Metropolitan France) |
| Immigration | postal code | 0, 1, 2, 3 | Proportion of foreign nationals, grouped into quartiles, proxy for immigration status |
| Education | postal-code | 0, 1, 2, 3 | Proportion of population with higher education, grouped into quartiles, proxy for education |
| Sex | Individual | “M” or “F” | M: male, F: female |
| Year of birth | Individual | integer | Year of birth |
| Event Description | Number of Events Observed |
|---|---|
| Heart failure (including cardiac arrest) | 967,187 |
| Rhythm disorder: 1 atrial fibrillation | 705,528 |
| Peripheral arterial disease (aorta, digestive system, kidney, amputation) | 531,657 |
| Anemia: 1 blood transfusion | 502,472 |
| Chronic kidney disease | 335,038 |
| Digestive complication: 1 hemorrhage (any cause) | 333,720 |
| Septicemia (any cause) | 270,932 |
| Thromboembolic disease | 265,323 |
| Acute respiratory failure | 235,699 |
| Digestive complication: 1 obstruction (any cause) | 231,039 |
| Stroke: 1 ischemic (less severe) | 222,098 |
| Acute kidney failure | 220,118 |
| Breast cancer | 205,026 |
| Metabolic disease (other than diabetes, dyslipidemia) | 201,431 |
| Lung cancer | 194,172 |
| Chronic respiratory failure (including respiratory arrest) | 185,282 |
| Prostate cancer | 184,291 |
| Severe dementia | 178,670 |
| Cancer with poor prognosis | 161,046 |
| Ischemic heart disease: 1 heart attack (stent, surgery) | 160,190 |
| Trauma: 1 skull | 159,856 |
| Colorectal cancer | 151,427 |
| Epilepsy (and other convulsions) | 131,300 |
| Hemopathy (lymphoma) | 130,476 |
| Parkinson’s disease (and other extrapyramidal syndromes) | 128,533 |
| Endocrine disease (other than thyroid) | 111,232 |
| Digestive complication: 1 peritonitis (any cause) | 103,674 |
| Cancer with good prognosis | 99,185 |
| Digestive complication: 1 stoma (any cause) | 89,719 |
| Cirrhosis: 1 decompensated | 89,701 |
| Physical dependence (bedridden state without dementia) | 87,736 |
| Stroke: 1 hemorrhagic (more severe) | 79,028 |
| ORL esophageal cancer | 72,482 |
| Trauma: 2 severe (non-skull) | 69,537 |
| Other neurological disease | 57,739 |
| Rare diseases at risk of dementia (multiple sclerosis, normal-pressure hydrocephalus, encephalitis) | 45,083 |
| Death from any cause | 569,941 |
| Sex | |||
|---|---|---|---|
| Female | Male | Entire Population | |
| Number of indiduals | |||
| n | 5,849,485 | 4,761,144 | 10,610,629 |
| Age at start of exposure | |||
| Median (IQR) | 64.9 (56.3–76.2) | 62.2 (55.3–72.1) | 63.5 (55.8–74.4) |
| Exposure (years) | |||
| Median (IQR) | 2.1 (1.1–3.1) | 2.1 (1.0–3.1) | 2.1 (1.0–3.1) |
| Obesity | |||
| Category 0 (% of pop.) | 5,333,571 (91.2%) | 4,375,255 (91.9%) | 9,708,826 (91.5%) |
| Category 1 (% of pop.) | 420,360 (7.2%) | 338,803 (7.1%) | 759,163 (7.2%) |
| Category 2 (% of pop.) | 95,554 (1.6%) | 47,086 (1.0%) | 142,640 (1.3%) |
| Alcohol | |||
| Category 0 (% of pop.) | 5,762,344 (98.5%) | 4,520,484 (94.9%) | 10,282,828 (96.9%) |
| Category 1 (% of pop.) | 17,370 (0.3%) | 38,044 (0.8%) | 55,414 (0.5%) |
| Category 2 (% of pop.) | 69,771 (1.2%) | 202,616 (4.3%) | 272,387 (2.6%) |
| Smoking | |||
| Category 0 (% of pop.) | 5,559,858 (95.0%) | 4,224,623 (88.7%) | 9,784,481 (92.2%) |
| Category 1 (% of pop.) | 9817 (0.2%) | 29,173 (0.6%) | 38,990 (0.4%) |
| Category 2 (% of pop.) | 279,810 (4.8%) | 507,348 (10.7%) | 787,158 (7.4%) |
| Immigration | |||
| Quartile 0 (% of pop.) | 888,302 (15.2%) | 738,362 (15.5%) | 1,626,664 (15.3%) |
| Quartile 1 (% of pop.) | 1,234,883 (21.1%) | 945,294 (19.9%) | 2,180,177 (20.5%) |
| Quartile 2 (% of pop.) | 1,613,637 (27.6%) | 1,249,331 (26.2%) | 2,862,968 (27.0%) |
| Quartile 3 (% of pop.) | 2,112,663 (36.1%) | 1,828,157 (38.4%) | 3,940,820 (37.1%) |
| Education | |||
| Quartile 0 (% of pop.) | 1,397,459 (23.9%) | 1,126,502 (23.7%) | 2,523,961 (23.8%) |
| Quartile 1 (% of pop.) | 1,563,617 (26.7%) | 1,243,339 (26.1%) | 2,806,956 (26.5%) |
| Quartile 2 (% of pop.) | 1,472,192 (25.2%) | 1,182,230 (24.8%) | 2,654,422 (25.0%) |
| Quartile 3 (% of pop.) | 1,416,217 (24.2%) | 1,209,073 (25.4%) | 2,625,290 (24.7%) |
| Education | Immigration | Obesity | Smoking | |
|---|---|---|---|---|
| Alcohol | 0.02 | 0.01 | 0.03 | 0.22 |
| Education | 0.24 | 0.04 | 0.03 | |
| Immigration | 0.00 | 0.01 | ||
| Obesity | 0.09 |
| Term | Dependence on Age | Reference Value |
|---|---|---|
| Main effect | ||
| Obesity | Natural spline | Category 0 |
| Alcohol | Natural spline | Category 0 |
| Tobacco | Natural spline | Category 0 |
| Sex | Natural spline | Female |
| Department of residence | Constant | 78—Yvelines |
| Immigration level | Constant | 1st quantile (lowest) |
| Education level | Constant | 1st quantile (lowest) |
| Interaction | ||
| Obesity × Alcohol | Constant | Both categories 0 |
| Obesity × tobacco | Constant | Both categories 0 |
| Alcohol × tobacco | Constant | Both categories 0 |
| Sex × obesity | Constant | Female, category 0 |
| Sex × alcohol | Constant | Female, category 0 |
| Sex × tobacco | Constant | Female, category 0 |
| Age | Sex | Dis-FLE | HLY |
|---|---|---|---|
| 50 | Men | 14.5 | 18.8 |
| 50 | Women | 17.6 | 19.9 |
| 65 | Men | 8.9 | 9.5 |
| 65 | Women | 10.8 | 10.2 |
| Risk Factor (Cat. 2) | Hazard Ratio | Std. Error | p-Value |
|---|---|---|---|
| Obesity | 0.934 | 0.010 | 0.000 |
| Alcohol | 0.882 | 0.007 | 0.000 |
| Smoking | 1.010 | 0.004 | 0.022 |
| Quartile | Hazard Ratio | Std. Error | p-Value |
|---|---|---|---|
| Immigration | |||
| 1 | 1.003 | 0.002 | 0.250 |
| 2 | 1.006 | 0.002 | 0.004 |
| 3 | 1.008 | 0.002 | 0.001 |
| Education | |||
| 1 | 1.029 | 0.002 | 0.000 |
| 2 | 1.051 | 0.002 | 0.000 |
| 3 | 1.071 | 0.002 | 0.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sorochynskyi, O.; Guibert, Q.; Planchet, F.; Schwarzinger, M. Estimating Disease-Free Life Expectancy Based on Clinical Data from the French Hospital Discharge Database. Risks 2024, 12, 92. https://doi.org/10.3390/risks12060092
Sorochynskyi O, Guibert Q, Planchet F, Schwarzinger M. Estimating Disease-Free Life Expectancy Based on Clinical Data from the French Hospital Discharge Database. Risks. 2024; 12(6):92. https://doi.org/10.3390/risks12060092
Chicago/Turabian StyleSorochynskyi, Oleksandr, Quentin Guibert, Frédéric Planchet, and Michaël Schwarzinger. 2024. "Estimating Disease-Free Life Expectancy Based on Clinical Data from the French Hospital Discharge Database" Risks 12, no. 6: 92. https://doi.org/10.3390/risks12060092
APA StyleSorochynskyi, O., Guibert, Q., Planchet, F., & Schwarzinger, M. (2024). Estimating Disease-Free Life Expectancy Based on Clinical Data from the French Hospital Discharge Database. Risks, 12(6), 92. https://doi.org/10.3390/risks12060092