

Uncovering Hidden Insights with Long-Memory Process Detection: An In-Depth Overview


Abstract
1. Introduction
- When , the long-memory process is said to be weakly stationary. This means that the mean, variance, and autocovariance of the process are constant over time. Additionally, the process has an infinite moving average (MA) representation. In other words, the process can be represented as an infinite sum of past error terms, where the coefficients decay exponentially as the time lag between the error terms increases. The weakly stationary property of is desirable as it simplifies the analysis and modeling of the process.
- When , the long-memory process is invertible. This means that it can be transformed into a stationary process by applying a certain filter. In other words, the invertibility property ensures that the long-memory process can be represented as a finite sum of past error terms, where the coefficients decay exponentially as the time lag between the error terms increases. The invertibility property is useful in practical applications as it allows the analyst to transform the long-memory process into a stationary process, which is easier to analyze and model.
- When , the autocorrelation function (ACF) of the long-memory process follows a certain pattern. The ACF decays at a polynomial rate of as the lag h increases, leading to persistent patterns in the data and making the process a long-memory time series. This implies that the memory of the process decays very slowly, and the process can exhibit persistent trends and cycles that extend over long time horizons. The long-memory property of is important as it captures the long-range dependence in the data, which is often observed in financial, economic, and environmental time series. However, accurately detecting long-memory processes can be challenging, as the sample autocorrelation function may not be a reliable measure of long-range dependence.
- Maximum likelihood method: This method involves maximizing the likelihood function of the fractionally differenced model given the observed data, and then using the resulting estimates of the parameters to estimate .
- Regression method with logged periodogram at lower frequencies: This method involves regressing the log of the periodogram (a measure of the spectral density of the time series) at lower frequencies on the log of the frequency, and then using the slope of the regression line to estimate .
2. ACF and Long-Term Memory Process
2.1. Sum of the Sample Autocorrelation Function
- It does not depend on the time series length T; for . This property is interesting because it implies that the overall level of autocorrelation in a stationary time series, as measured by the sum of the ACF values, is not affected by the length of the time series. This means that even if we have a very long or a very short time series, the overall degree of temporal dependence in the data remains the same. This property can be useful in comparing the overall level of temporal dependence between different time series of varying lengths.
- The value of is equal to for any stationary time series. Thus, for example, for of any order is equal to a Gaussian white noise process and both are equal to . The second property of the theorem states that for any stationary time series, the value of is always equal to . This means that the sum of the sample ACF at each lag is always a constant, regardless of the length of the time series. For example, the sample ACF of an process of any order is equal to a Gaussian white noise process, and both have a value of for .This result has important implications for autoregressive model building and forecasting. If we use the sample ACF to detect the parameters of an autoregressive model, we might yield the improper detection of the order, since the ACF values are not informative of the order.
- The values of are linearly dependent:This equation shows that the value of can be expressed as a linear combination of the other sample ACF values, with a constant term of . In other words, the ACF values are not independent of each other, but, rather, they are related to each other in a systematic way. This property is a consequence of the fact that the ACF values depend only on the time lag between observations, and not on the specific values of the observations themselves. Therefore, once the ACF values for some lags are known, the values for other lags can be determined using this linear relationship.
- There is at least one negative for any stationary time series, even for with a positive ACF (Hassani 2010).This property states that for any stationary time series, there is at least one negative sample autocorrelation function (ACF) value, even for autoregressive (AR) models with positive ACF values.An AR model is a popular class of linear models for time series data, where the value of a variable at time t depends linearly on its own past values, up to a certain number of lagged observations (specified by the model order p). When the AR model is fitted to a stationary time series, the resulting ACF values are typically positive for the first few lags, indicating some degree of autocorrelation in the data. However, this property states that there must always be at least one negative ACF value, even for AR models with positive ACF values.This property can be understood as follows: although an AR model may capture some of the temporal dependencies in the data, it is unlikely to capture all of them perfectly. In other words, there are likely to be some patterns in the data that are not fully explained by the AR model. These unexplained patterns can lead to negative ACF values, indicating a lack of autocorrelation at certain lags. Therefore, even for stationary time series that exhibit positive autocorrelation overall, there will always be some degree of randomness or unpredictability in the data, resulting in at least one negative ACF value.
2.2. Long-Term Memory Process
3. Empirical versus Theoretical Results
3.1. Selected Long-Term Memory Models
- GARMA(p,q), which stands for Generalized Autoregressive Moving Average with Conditional Heteroscedasticity, is a type of time series model that combines the features of both the ARMA and GARCH models. This model is suitable for analyzing time series data with a non-constant mean and variance.The GARMA(p,q) model includes both autoregressive and moving average components as well as a conditional heteroscedasticity term, which captures the time-varying volatility in the data. This allows for better modeling and forecasting of time series data that exhibit changes in volatility over time.GARMA(p,q) has been applied in various fields for the modeling and forecasting of time series data with changing volatility patterns. For example, it has been used to model stock market returns, exchange rates, and weather data. The GARMA(p,q) model is defined as followswith: AR and MA component;A: the function that represents an autoregressive form;M: the function that represents a moving average form;: autoregressive parameter at j;: moving average parameter at j.The above GARMA(p,q), as defined by Equation (13), specifies a linear regression of a function on a set of predictor variables and a set of unknown parameters . The error term in Equation (13) is decomposed into an autoregressive (AR) component and a moving average (MA) component, which are specified in Equation (14).The function in Equation (14) represents the autoregressive component of the model, where is the value of the time series at lag j, and is the corresponding vector of exogenous variables. The autoregressive parameter at lag j is denoted by , which represents the impact of the lagged value of the time series on the current value, conditional on the values of the exogenous variables.The function in Equation (14) represents the moving average component of the model, where is the set of lagged moving average errors. The moving average parameter at lag j is denoted by , which represents the impact of the lagged moving average error on the current value of the time series.
- Integrated GARCH (IGARCH) is a type of time series model that is widely used to model financial and economic data. It is an extension of the GARCH model that accounts for the persistence of shocks in financial markets.In the IGARCH model, the past conditional variances of the series are included as predictors of the current conditional variance. This allows the model to capture the long-memory effect, where shocks have a persistent effect on future variance.IGARCH has been applied in various fields for the modeling and forecasting of time series data with persistence in volatility. For example, it has been used to model stock market returns, exchange rates, interest rates, and commodity prices. The IGARCH model is particularly useful for risk management, portfolio optimization, and option pricing. The IGARCH(1,1) model is given by
- ARCH(∞) is a type of time series model that extends the ARCH model to include an infinite number of lags in the conditional variance equation. This allows the model to capture long memory in the volatility of financial and economic time series data.The ARCH(∞) model is based on the idea that past shocks can have a persistent effect on the variance of the series over an infinite time horizon. The model can be estimated using maximum likelihood methods and has been shown to provide a better fit to financial data than finite-order ARCH models.The ARCH(∞) model has been applied in various fields for the modeling and forecasting of time series data with long memory in volatility. For example, it has been used to model stock market returns, exchange rates, and interest rates. The model is particularly useful in finance for risk management, portfolio optimization, and option pricing. However, the estimation of the model can be computationally intensive, and the interpretation of the infinite number of parameters can be challenging. The process is said to be an ARCH(∞), wheneverwithwhere and represents the information set of all information up to time t, i.e., .Similarly, IARCH(∞) is a type of time series model that extends the integrated GARCH (IGARCH) model to include an infinite number of lags in the conditional variance equation. This model captures the long-memory effect in the volatility of time series data and accounts for the persistence of shocks in financial markets. It should be noted that the estimation of the model can be computationally intensive, and the interpretation of the infinite number of parameters can be challenging.
- The Fractionally Integrated GARCH with a Vector of Conditional Variances (FIGARCHv) model is a type of time series model that extends the IGARCH model to allow multiple volatility series to be modeled simultaneously. This allows the model to capture the dynamics and interdependence among multiple time series, such as stock prices, exchange rates, and interest rates.In the FIGARCHv model, each series has its own IGARCH component and is modeled jointly with other series through a covariance matrix of the conditional variances. This allows the model to capture the spillover effects of volatility shocks across different time series.The FIGARCHv model has been applied in various fields for the modeling and forecasting of multiple time series data with long memory in volatility. For example, it has been used to model stock prices and exchange rates simultaneously, where the volatility of one series affects the volatility of the other series. The model is particularly useful in finance for risk management, portfolio optimization, and hedging strategies. However, the estimation of the model can be computationally intensive, and the interpretation of the multiple parameters can be challenging. The FIGARCH model is given bywhere
- LARCH(∞) and LARCH+(∞) are two types of time series models that extend the ARCH and GARCH models to allow for long memory in the conditional variance equation.LARCH(∞) is an extension of the ARCH model that includes an infinite number of lagged squared residuals in the variance equation. This allows the model to capture long memory in the volatility of time series data. LARCH+(∞) is an extension of the GARCH model that includes both an infinite number of lagged squared residuals and an infinite number of lagged conditional variances in the variance equation. This allows the model to capture long memory and the persistence of shocks in financial markets.Both LARCH(∞) and LARCH+(∞) have been applied in various fields for the modeling and forecasting of time series data with long memory in volatility. The models are particularly useful in finance for risk management, portfolio optimization, and option pricing. However, the estimation of these models can be computationally intensive, and the interpretation of the infinite number of parameters can be challenging. The LARCH model can be described aswhere are iid random variables with zero mean and unit variance.
- Stochastic volatility (SV) models are a type of time series model that allow the volatility of financial or economic time series data to vary over time in a random or stochastic manner. These models are based on the idea that the volatility itself is a random process that follows a certain distribution.In an SV model, the conditional variance of the series is modeled as a function of its past values, as well as a random process that represents the stochastic component of the volatility. This allows the model to capture the time-varying nature of the volatility in the data.SV models have been widely used in finance and economics for the modeling and forecasting of time series data with changing volatility. For example, they have been used to model stock prices, exchange rates, and interest rates, and are particularly useful for pricing options and other financial derivatives. The models are also used for risk management and portfolio optimization, as they allow for the more accurate estimation of risk measures such as the value at risk (VaR) and expected shortfall (ES). However, the estimation of SV models can be computationally intensive, and the interpretation of the random component of the volatility can be challenging. The SV model is defined as follows:where is the volatility of . The log volatility is specified by the AR(1) process with Gaussian innovation noise.
- Autoregressive Fractionally Integrated Moving Average (ARFIMA) and Generalized Autoregressive Conditional Heteroskedasticity (GARCH) are two widely used time series models in finance and economics.ARFIMA models are used to model time series data that exhibit long memory or fractional integration, meaning that the autocorrelation of the series declines very slowly. These models extend the ARIMA models by incorporating fractional differencing, which allows them to capture the long-memory effect.GARCH models, on the other hand, are used to model time series data that exhibit heteroskedasticity or volatility clustering, meaning that the variance of the series changes over time. These models extend the ARCH models by incorporating autoregressive components in the conditional variance equation, allowing them to capture the persistence of shocks in the data.Both the ARFIMA and GARCH models have various applications in finance and economics. ARFIMA models are particularly useful in the modeling and forecasting of financial and economic time series with long memory, such as stock prices, exchange rates, and interest rates. GARCH models are widely used in risk management and portfolio optimization, as they allow for the more accurate estimation of risk measures such as the value at risk (VaR) and expected shortfall (ES). They are also used in option pricing and volatility forecasting. However, the estimation of these models can be computationally intensive, and the interpretation of the parameters can be challenging.An ARFIMA process may be defined bywhere and are the autoregressive and moving average operators, respectively. is a fractional differencing operator defined by the binomial expansionwherefor , and is a white noise sequence with finite variance.
- A CAR(1) model, also known as a Conditional Autoregressive Model of Order 1, is a time series model that describes the dependence between observations in a series over time.In this model, each observation in the series is assumed to be a function of the previous observation and a random error term. The term “conditional” in CAR(1) refers to the fact that the current observation is conditional on the previous observation.The application of CAR(1) models is widely practised in econometrics, finance, and engineering for the forecasting and analysis of time series data. It is particularly useful in modeling and forecasting stock prices, exchange rates, and interest rates. It can also be used in modeling natural phenomena, such as climate patterns or population growth.The CAR model explains the observations with p fixed effects and n spatial random effects:where and are precision matrices, observations and random effects are , design matrix is , and the fixed effect regression parameter vector is .
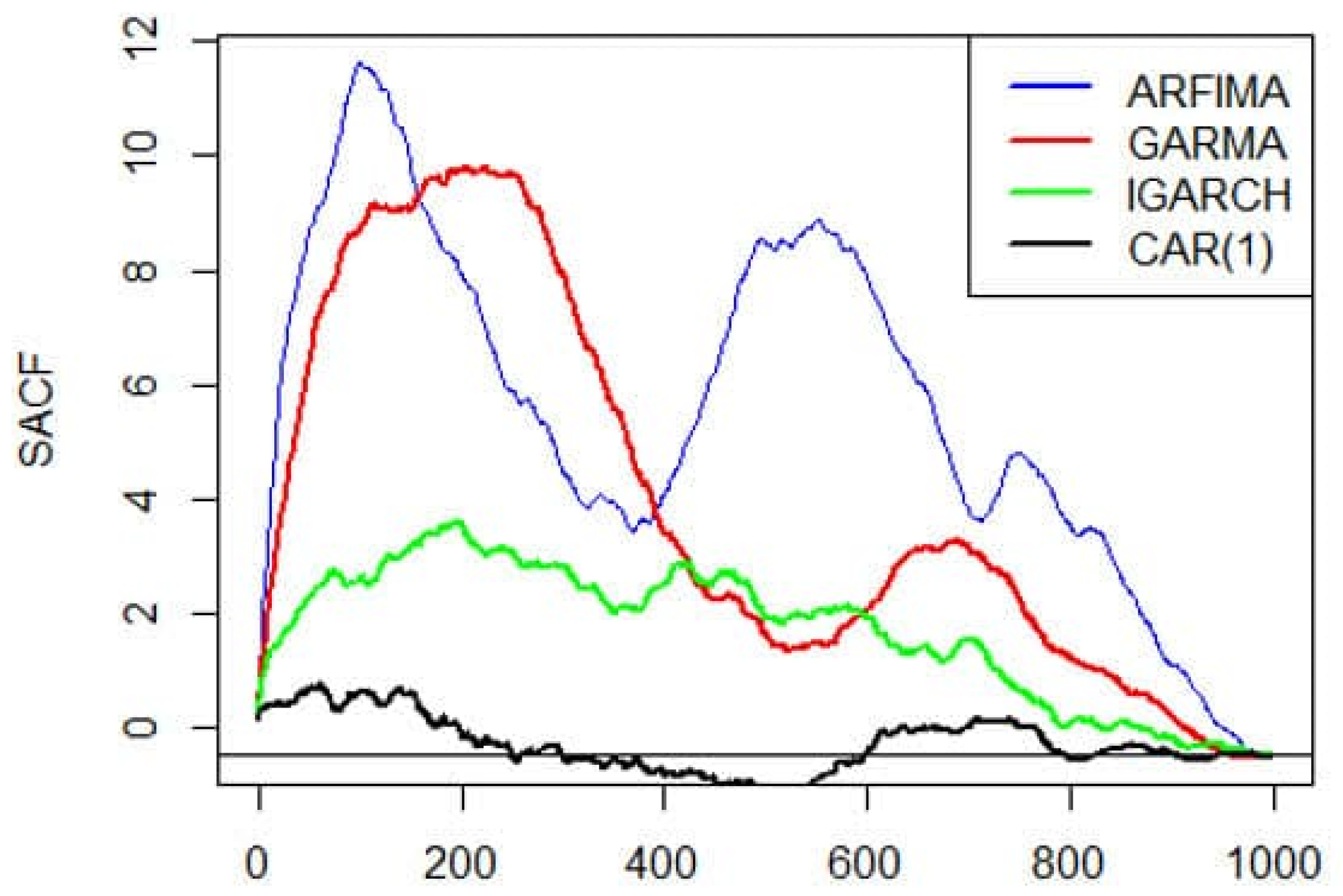
3.2. Results
4. Comparison of Parametric and Non-Parametric/Semi-Parametric Approaches for Long-Term Memory Time Series Detection
5. Discussion
6. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Barbieri, Riccardo, Enzo Pasquale Scilingo, and Gaetano Valenza. 2017. Complexity and Nonlinearity in Cardiovascular Signals. New York: Springer. [Google Scholar] [CrossRef]
- Beran, Jan. 1994. Statistics for Long-Memory Processes. London: Chapman & Hall, p. 315. Available online: https://www.routledge.com/Statistics-for-Long-Memory-Processes/Beran/p/book/9780412049019 (accessed on 30 March 2023).
- Beran, Jan, Yuanhua Feng, Sucharita Ghosh, and Rafal Kulik. 2013. Long-Memory Processes: Probabilistic, statistical, and Economic Issues. Berlin and Heidelberg: Springer Science & Business Media. [Google Scholar]
- Bertelli, Stefano, and Massimiliano Caporin. 2002. A note on calculating auto-covariances of long-memory processes. Journal of Time Series Analysis 23: 503–8. [Google Scholar] [CrossRef]
- Bertail, Patrice, Paul Doukhan, and Philippe Soulier. 2006. Dependence in Probability and Statistics. In Springer Lecture Notes on Statistics 187. New York: Springer. [Google Scholar] [CrossRef]
- Das, K.J., and Sharad Nath Bhattacharya. 2021. Detection of Long Memory in the Indian Stock Market using Fractional Integration Analysis. Business Studies 1–2: 28. Available online: https://www.caluniv.ac.in/dj/BS-Journal/vol-31-32/long_memory.pdf (accessed on 7 June 2023).
- Dedecker, Jérôme, Paul Doukhan, Gabriel Lang, León R. José Rafael, Sana Louhichi, and Clémentine Prieur. 2007. Weak dependence. In Weak Dependence: With Examples and Applications. Lecture Notes in Statistics. New York: Springer, p. 190. [Google Scholar] [CrossRef]
- Ding, Zhuanxin, Clive W. J. Granger, and Robert F. Engle. 1993. A long memory property of stock market returns and a new model. Journal of Empirical Finance 1: 83–106. [Google Scholar] [CrossRef]
- Doukhan, Paul, George Oppenheim, and Murad Taqqu. 2003. Theory and Applications of Long-Range Dependence. Boston: Birkhäuser. [Google Scholar]
- Hassani, Hossein. 2009. Sum of the sample autocorrelation function. Random Operators and Stochastic Equations 17: 125–30. [Google Scholar] [CrossRef]
- Hassani, Hossein. 2010. A note on the sum of the sample autocorrelation function. Physica A 389: 1601–6. [Google Scholar] [CrossRef]
- Hassani, Hossein, Leonenko Nikolai, and Kerry Patterson. 2012. The sample autocorrelation function and the detection of long-memory processes. Physica A: Statistical Mechanics and Its Applications 391: 6367–79. [Google Scholar] [CrossRef]
- Hassani, Hossein, and Emmanuel Sirimal Silva. 2015. A Kolmogorov-Smirnov Based Test for Comparing the Predictive Accuracy of Two Sets of Forecasts. Econometrics 3: 590–609. [Google Scholar] [CrossRef]
- Hassani, Hossein, Mohammad Reza Yeganegi, Sedigheh Zamani Mehreyan, and Abdolreza Sayyareh. 2021. On the Sample Autocorrelation Functions Absolute Summability. Fluctuation and Noise Letters 21: 2250004. [Google Scholar] [CrossRef]
- Hosking, J. R. M. 1981. Fractional differencing. Biometrika 8: 165–76. [Google Scholar] [CrossRef]
- Hurst, Harold Edwin. 1951. Long term storage capacity of reservoirs. Transactions of the American Society of Civil Engineers 116: 770–99. [Google Scholar] [CrossRef]
- Rapach, David E., Mark E. Wohar, and Hamid Beladi. 2008. Forecasting in the Presence of Structural Breaks and Model Uncertainty. Amsterdam: Elsevier Science Ltd., vol. 3, 700p, Available online: https://books.emeraldinsight.com/page/detail/Forecasting-in-the-Presence-of-Structural-Breaks-and-Model-Uncertainty/?k=9780444529428 (accessed on 30 March 2023).
- Tsay, Ruey. S. 2010. Analysis of Financial Time Series. New York: John Wiley & Sons. [Google Scholar]
- Teyssière, Gilles, and Alan Kirman. 2002. Microeconomic models for long memory in the volatility of financial time series. Physica A 370: 26–31. [Google Scholar]
- Wei, William. W. S. 2006. Time Series Analysis Univariate and Multivariate Methods, 2nd ed. New York: Addison Wesley, vol. 29, pp. 33–59. [Google Scholar]
- Zivot, Eric, and Jiahui Wang. 2013. Modeling Financial Time Series with S-PLUS®, 2nd ed. Berlin and Heidelberg: Springer. [Google Scholar]
- Zheng, Min, Liu Ruipeng, and Li Youwei. 2018. Long memory in financial markets: A heterogeneous agent model perspective. International Review of Financial Analysis 58: 38–51. [Google Scholar] [CrossRef]


{kind=link}
| Case | Models | Long-Memory Process | Empirical Results | References |
|---|---|---|---|---|
| 1 | as | (Bertelli and Caporin 2002) | ||
| 2 | as | (Rapach et al. 2008) | ||
| 3 | as | (Bertail et al. 2006) | ||
| 4 | as | (Teyssière and Kirman 2002) | ||
| 5 | v | as | (Zivot and Wang 2013) | |
| 6 | as | (Beran et al. 2013) | ||
| 7 | as | (Dedecker et al. 2007) | ||
| 8 | SV models (Stochastic Volatility) | as | (Zheng et al. 2018) | |
| 9 | as | (Barbieri 2017) | ||
| 10 | as | (Beran et al. 2013) |
| Theoretical Results | Empirical Results |
|---|---|
| as | |
| as | |
| as |
| Model | Long Memory | Stationarity | Volatility Clustering | Autocorrelation Function |
|---|---|---|---|---|
| ARFIMA | Yes | No | No | Decreases to zero |
| GARMA | Yes | No | No | Decreases to zero |
| IGARCH | No | Yes | Yes | Decreases exponentially |
| CAR(1) | No | Yes | No | Decreases exponentially |
| Methods | Parametric | Semi-Parametric | Non-Parametric |
|---|---|---|---|
| Basic assumption | Assumes specific probability distribution of errors | Allows for flexible modeling of errors | Makes no assumptions about the probability distribution of errors |
| Strengths | Accurate modeling of errors and autocorrelation function | Combines flexibility and accuracy | Robust to deviations from distribution assumptions |
| Weaknesses | Sensitive to distributional assumptions | May not fully capture complex dependencies | May be less accurate in small sample sizes |
| Examples | ARIMA, ARCH/GARCH | Fractional ARIMA, Wavelet analysis | Hurst exponent, rescaled range analysis |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassani, H.; Yarmohammadi, M.; Mashhad, L.M. Uncovering Hidden Insights with Long-Memory Process Detection: An In-Depth Overview. Risks 2023, 11, 113. https://doi.org/10.3390/risks11060113
Hassani H, Yarmohammadi M, Mashhad LM. Uncovering Hidden Insights with Long-Memory Process Detection: An In-Depth Overview. Risks. 2023; 11(6):113. https://doi.org/10.3390/risks11060113
Chicago/Turabian StyleHassani, Hossein, Masoud Yarmohammadi, and Leila Marvian Mashhad. 2023. "Uncovering Hidden Insights with Long-Memory Process Detection: An In-Depth Overview" Risks 11, no. 6: 113. https://doi.org/10.3390/risks11060113
APA StyleHassani, H., Yarmohammadi, M., & Mashhad, L. M. (2023). Uncovering Hidden Insights with Long-Memory Process Detection: An In-Depth Overview. Risks, 11(6), 113. https://doi.org/10.3390/risks11060113