
A Model for Risk Adjustment (IFRS 17) for Surrender Risk in Life Insurance


{kind=link}
{kind=link}
{kind=link}
{kind=link}
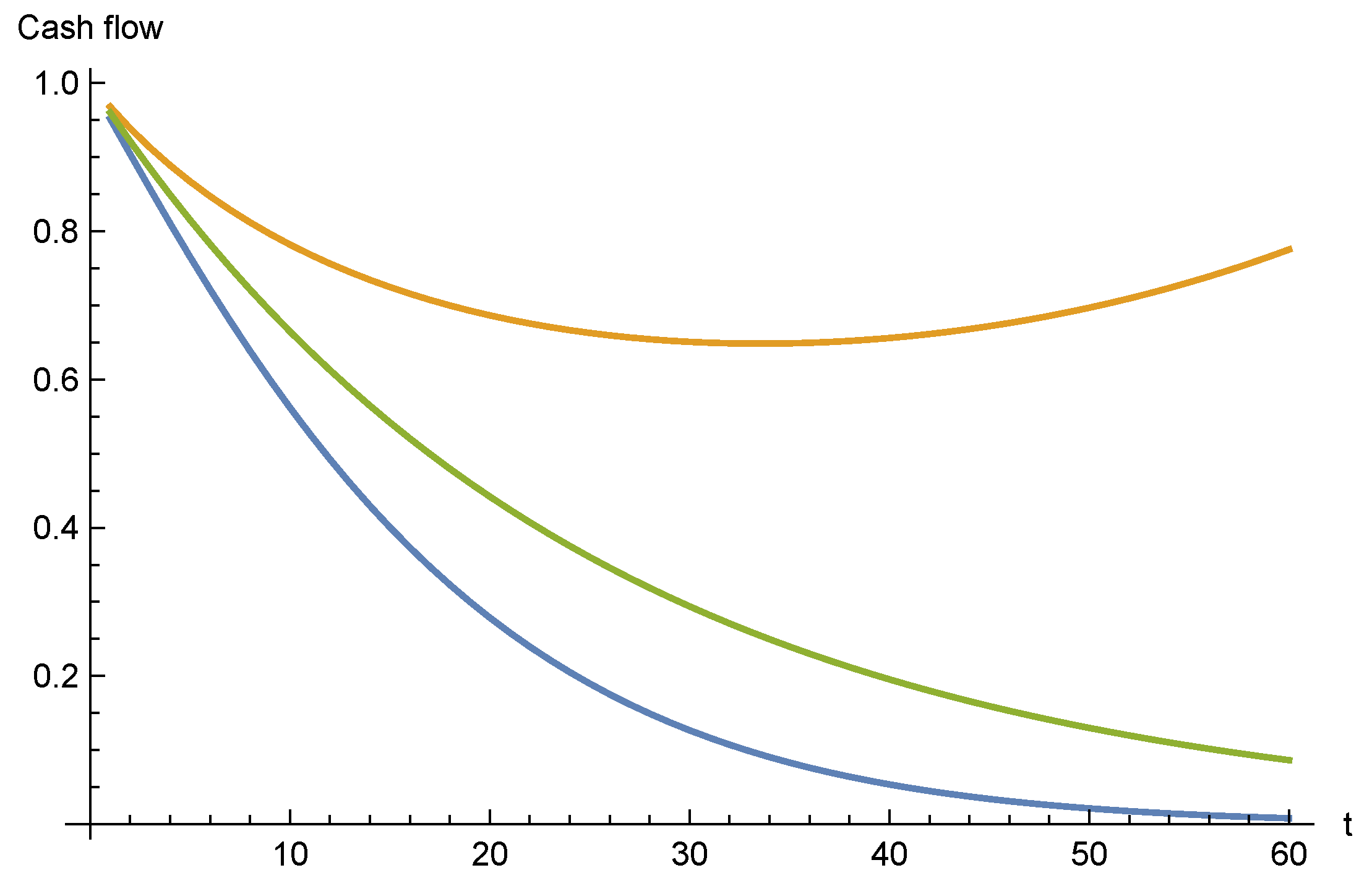{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. IFRS 17
1.2. Our Objective and Setup
1.3. Risk Measures
1.4. Outline of the Article
2. Stochastic Modelling of Surrender Rates
2.1. Introduction
2.2. The Poisson Process
2.3. Discrete Time
2.3.1. The Lognormal Model
2.3.2. The Sticky Model
2.4. Continuous Time
2.5. Term Structure of Surrender Rates
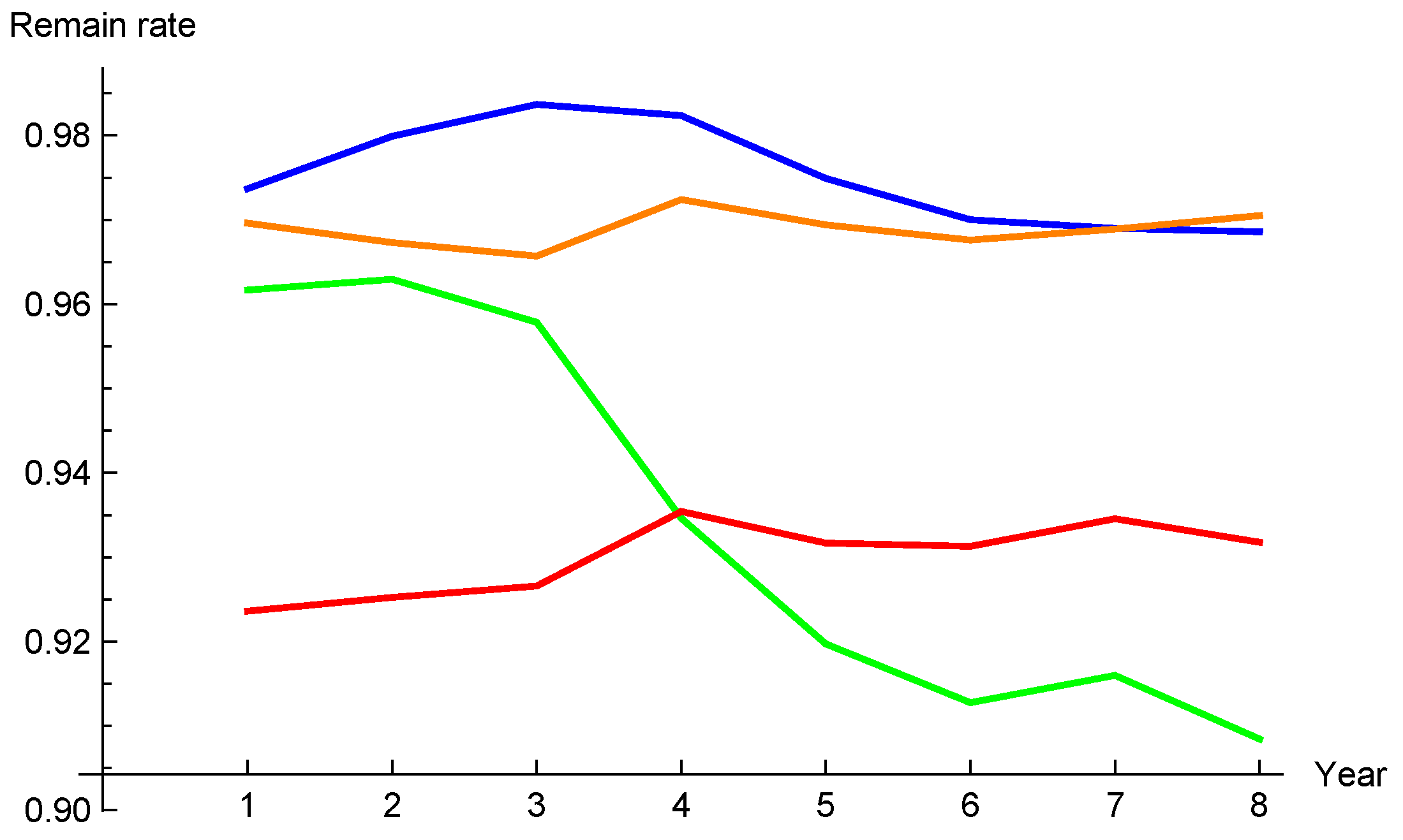
2.6. Realism of the Models
3. Convex Ordering of Random Variables and Its Applications
3.1. Definition of Convex Ordering
3.2. Comonotonicity
3.3. Convex Bounds for Sums of Random Variables
3.4. Applications to Risk Measures
3.5. Application to Sums of Lognormal Variables
4. PVFCF for the Total Portfolio
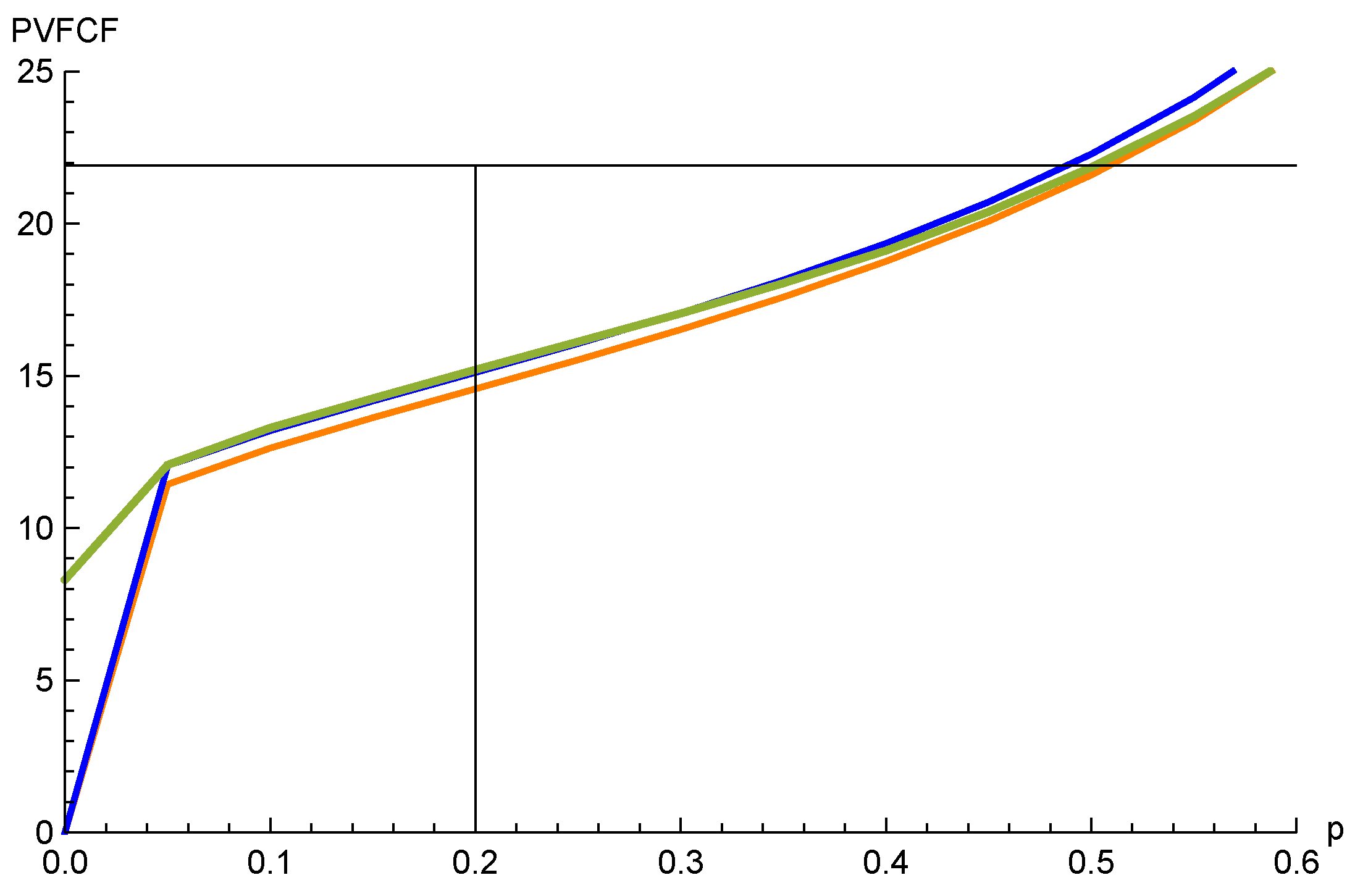
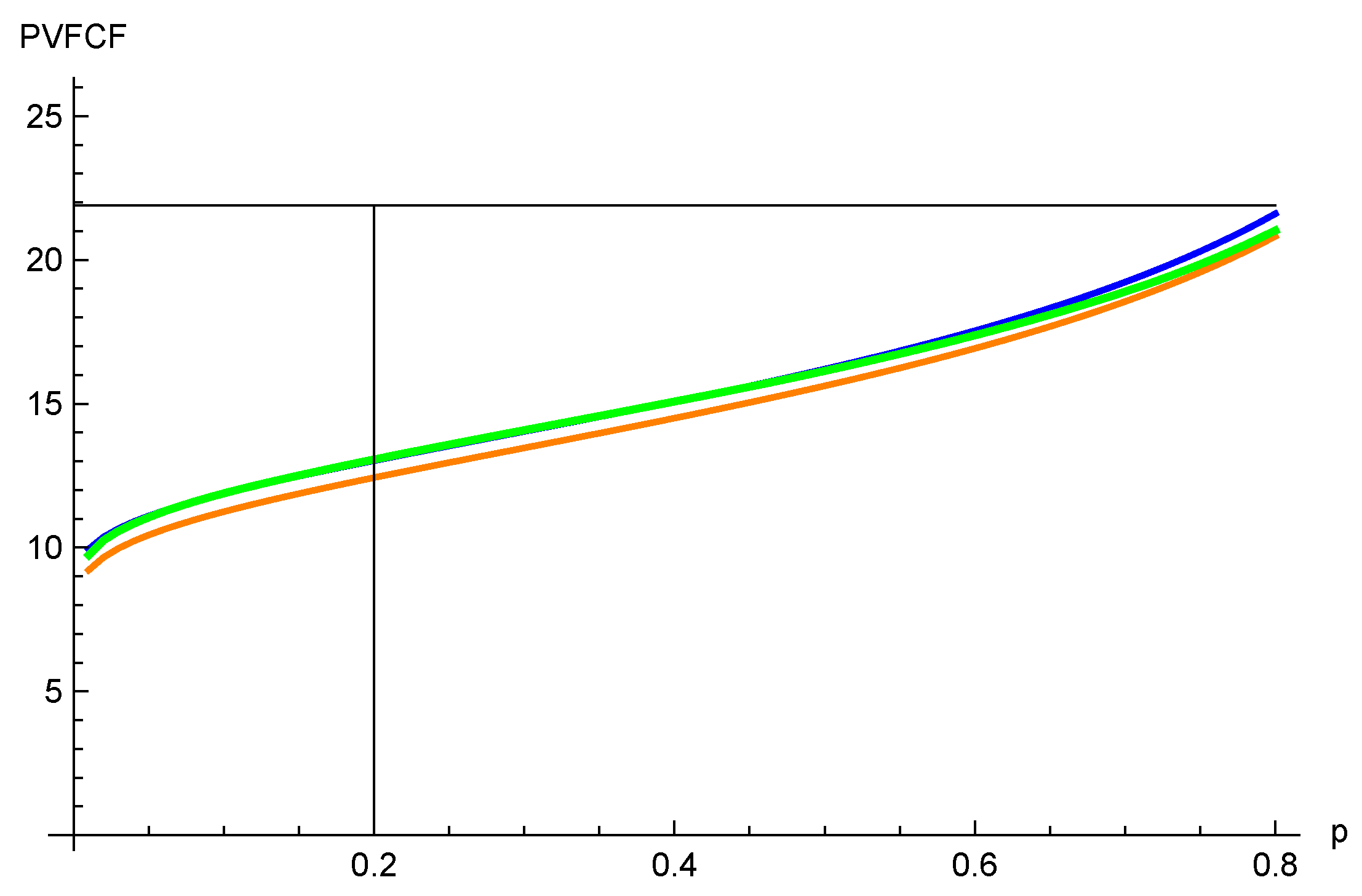
4.1. Approximations by Convex Ordering
4.1.1. The Lognormal Model
4.1.2. The Sticky Model
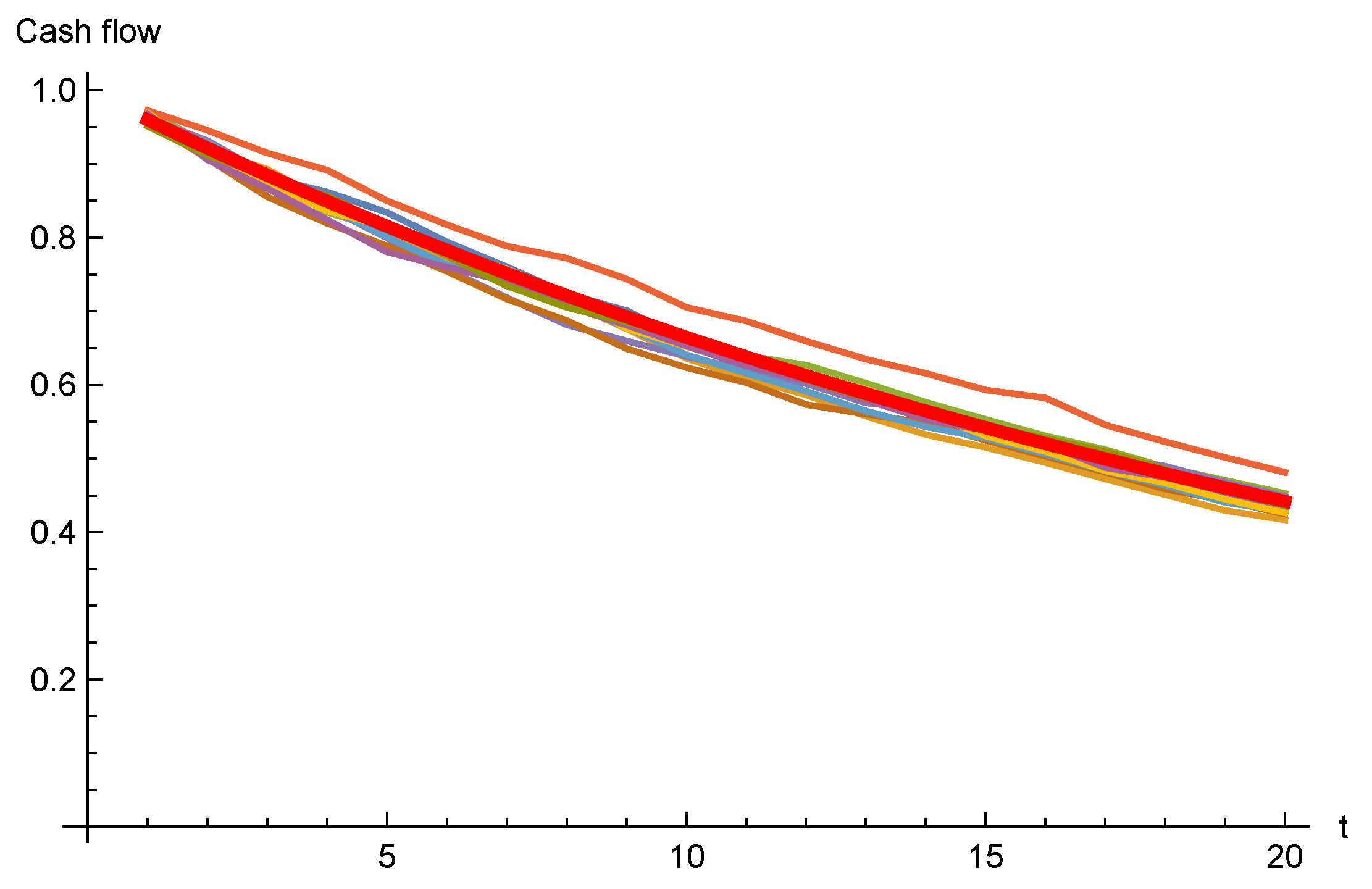
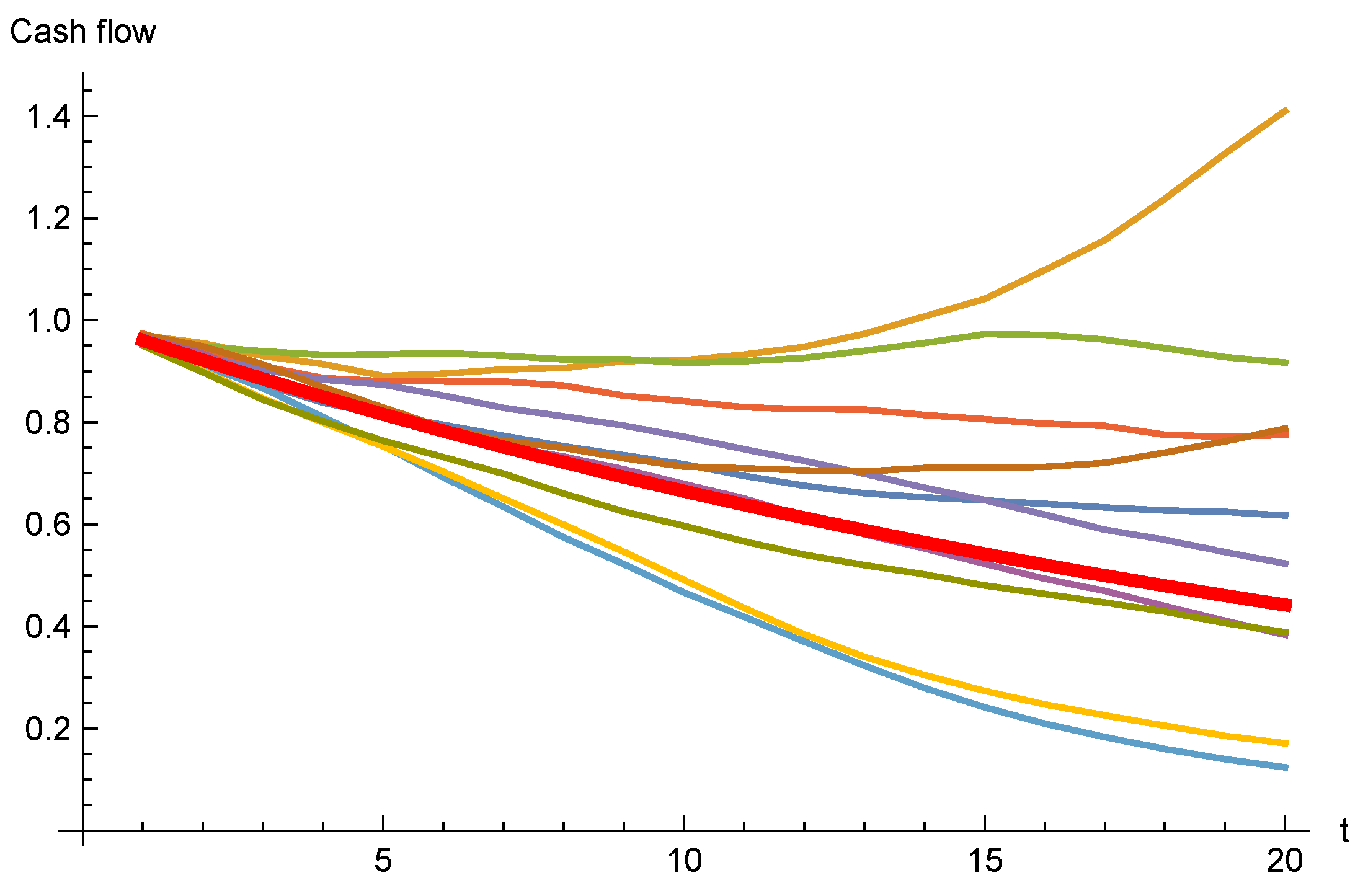
4.2. Numerical Example
4.2.1. The Lognormal Model
4.2.2. The Sticky Model
5. Implementation for Risk Adjustment
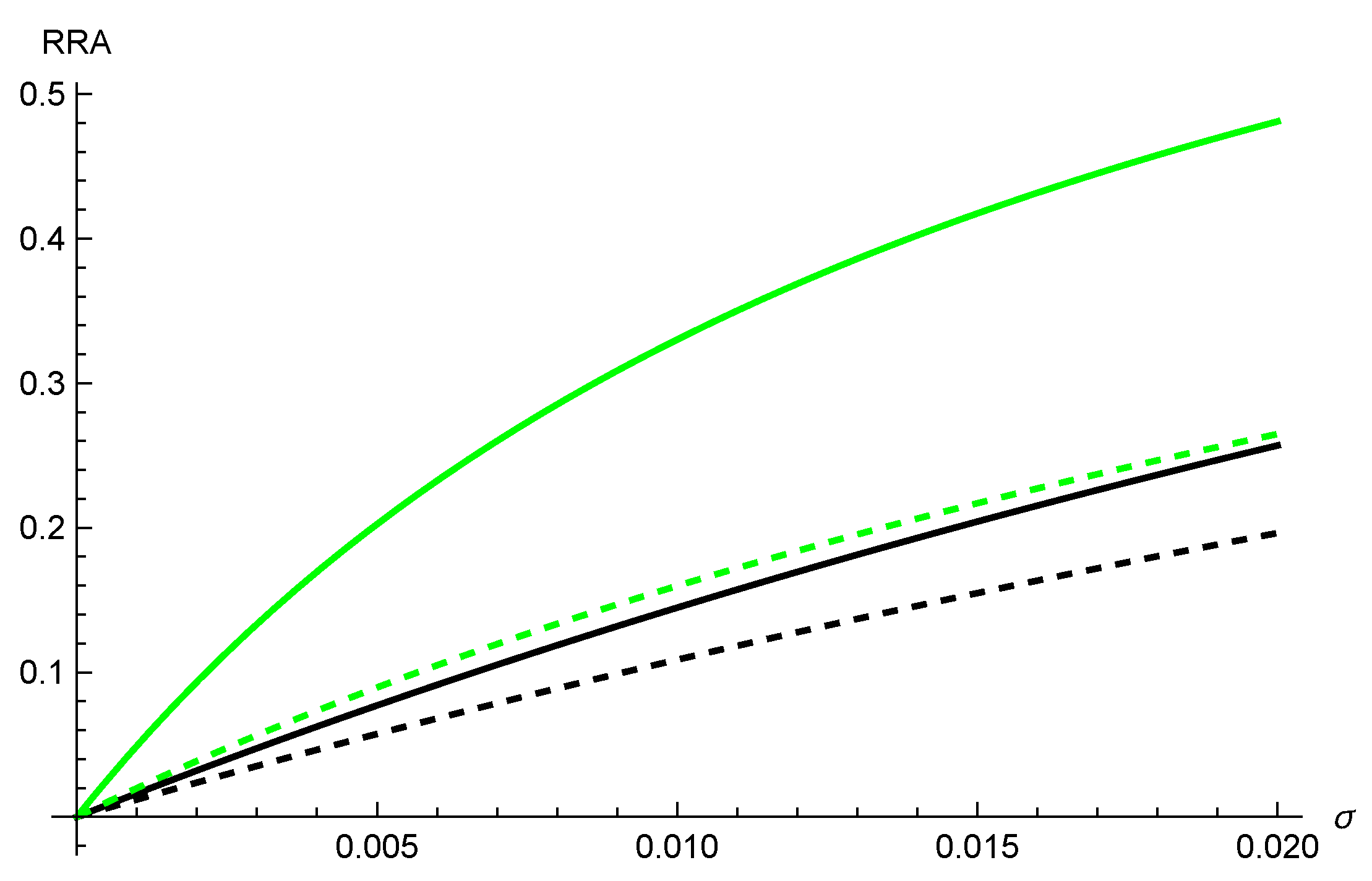
5.1. Parametrization
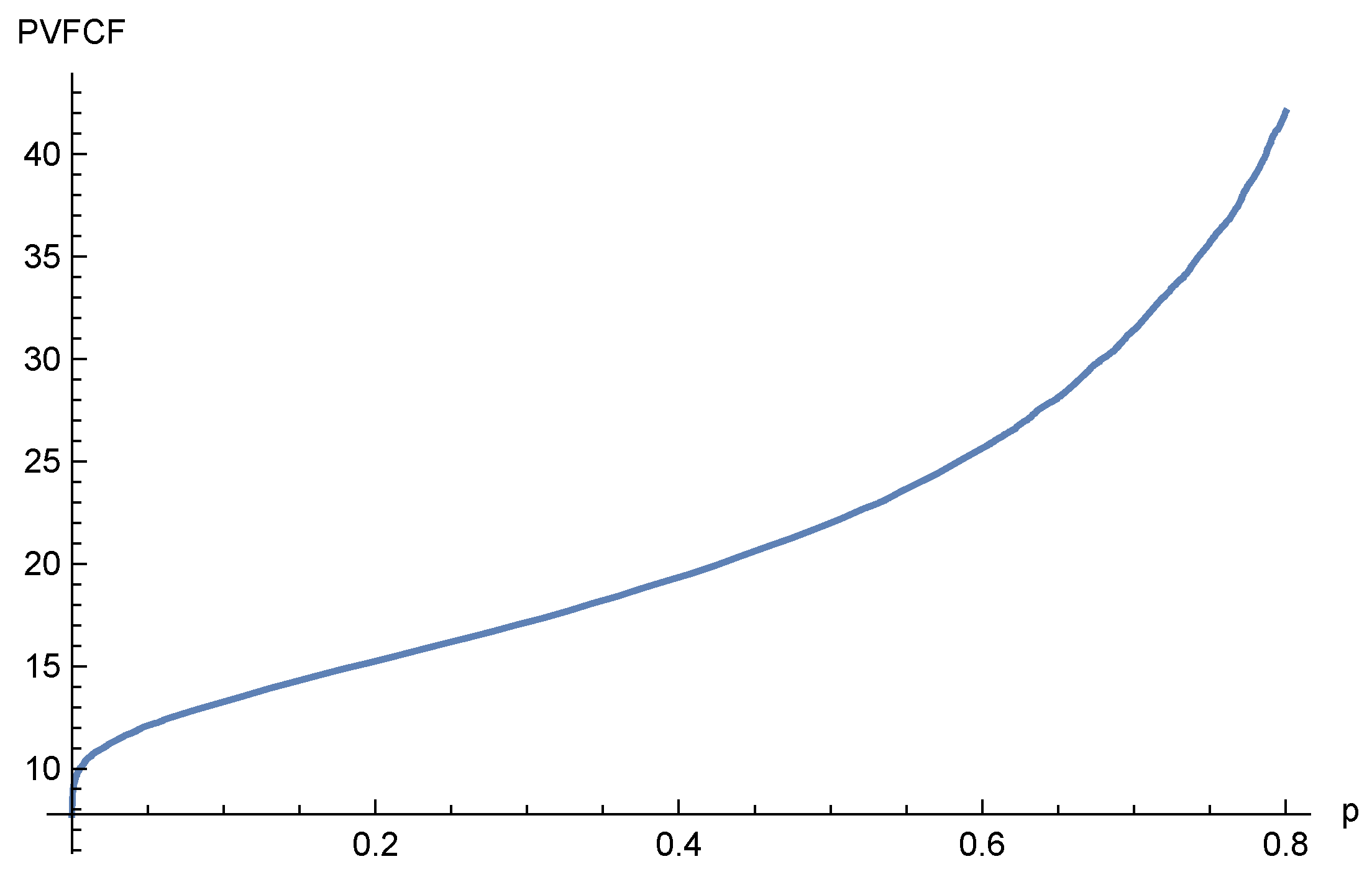
5.2. Risk Adjustment
5.3. Fulfillment of Criteria in IFRS17
- (a)
- risks with low frequency and high severity will result in higher risk adjustments for non-financial risk than risks with high frequency and low severity;
- (b)
- for similar risks, contracts with a longer duration will result in higher risk adjustments for non-financial risk than contracts with a shorter duration;
- (c)
- risks with a wider probability distribution will result in higher risk adjustments for non-financial risk than risks with a narrower distribution;
- (d)
- the less that is known about the current estimate and its trend, the higher will be the risk adjustment for non-financial risk; and
- (e)
- to the extent that emerging experience reduces uncertainty about the amount and timing of cash flows, risk adjustments for non-financial risk will decrease and vice versa.”
6. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. IFRS17 and Risk Adjustment for Non-Financial Risks
- “The key principles in IFRS 17 are that an entity:…(d) recognises and measures groups of insurance contracts at:(i) a risk-adjusted present value of the future cash flows (the fulfillment cash flows) that incorporates all of the available information about the fulfilment cash flows in a way that is consistent with observable market information; plus (if this value is a liability) or minus (if this value is an asset)(ii) an amount representing the unearned profit in the group of contracts (the contractual service margin).…”
- “...(i) estimates of future cash flows (§§ 33–35);(ii) an adjustment to reflect the time value of money and the financial risks related to the future cash flows, to the extent that the financial risks are not included in the estimates of the future cash flows (paragraph 36); and(iii) a risk adjustment for non-financial risk (§ 37).…”
| 1 | IFRS17 uses the sign convention that (discounted) claims and expenses are positive and (discounted) premiums negative. Here we reverse that, in order to look at it from the company’s point of view, and avoid a lot of minus signs. |
| 2 | For solvency purposes, more extreme events must be considered. Consequently, in Solvency II standard formula there is a capital requirement for “mass lapse” risk. |
| 3 | This subsection is courtesy of Lina Balčiūnienė. |
| 4 | For confidentiality reasons, the data has been modified. However, it has been done in a way that does not distort the statistical testing. |
| 5 | The Shapiro–Wilk test is tailored to test for normality based on the sample mean and sample variance. However, the specification of the sticky model has a fixed mean, and to be accurate, the Shapiro–Wilk test with a known mean should be used, see Hanusz et al. (2016) for details. The difference in our case is however negligible. |
| 6 | |
| 7 | For a good overview of approximation methods, see Asmussen et al. (n.d.). |
References
- Asmussen, Søren, Jens Ledet Jensen, and Leonardo Rojas-Nandayapa. n.d. A Literature Review on Log-Normal Sums. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.719.5927 (accessed on 16 March 2023).
- Barsotti, Flavia, Xavier Milhaud, and Yahia Salhi. n.d. Lapse Risk in Life Insurance: Correlation and Contagion Effects among Policyholders’ Behaviors. Available online: https://hal.archives-ouvertes.fr/hal-01282601v2 (accessed on 16 March 2023).
- Boumezoud, Alexandre, Amal Elfassihi, Cormac Gleeson, Andrew Kay, Orlaith Lehana, Bertrand Lespinasse, and Damien Louvet. 2020. IFRS 17: Deriving the Confidence Level for the Risk Adjustment: A Case Study for Life (re)Insurers. Paris: Milliman. Available online: https://www.milliman.com/en/insight/IFRS-17-Deriving-the-confidence-level-for-the-Risk-Adjustment-A-case-study-for-life-reinsurers (accessed on 16 March 2023).
- Chaoubi, Ihsan, Hélène Cossette, Simon-Pierre Gadoury, and Etienne Marceau. 2020. On sums of two counter-monotonic risks. Insurance: Mathematics and Economics 92: 47–60. [Google Scholar] [CrossRef]
- Deelstra, Griselda, Ibrahima Diallo, and Michèle Vanmaele. 2008. Bounds for Asian basket options. Journal of Computational and Applied Mathematics 218: 215–28. [Google Scholar] [CrossRef]
- Denuit, Michel, Jan Dhaene, Marc Goovaerts, and Rob Kaas. 2005. Actuarial Theory for Dependent Risk: Measures, Orders and Models. New York: Wiley. [Google Scholar]
- Dhaene, Jan, Steven Vanduffel, Marc Goovaerts, Rob Kaas, Qihe Tang, and David Vyncke. 2006. Risk measures and comonotonicity: A review. Stochastic Models 22: 573–606. [Google Scholar] [CrossRef]
- Eling, Martin, and Michael Kochanski. 2013. Research on lapse in life insurance: What has been done and what needs to be done? The Journal of Risk Finance 14: 392–413. [Google Scholar] [CrossRef]
- England, Peter D., Richard J. Verrall, and Mario Valentin Wüthrich. 2019. On the lifetime and one-year views of reserve risk, with application to IFRS 17 and Solvency II risk margins. Insurance: Mathematics and Economics 85: 74–88. [Google Scholar] [CrossRef]
- Grandell, Jan. 1991. Aspects of Risk Theory. Springer Series in Statistics. Probability and Its Applications; New York: Springer. [Google Scholar]
- Hanbali, Hamza, and Daniel Linders. 2019. American-type basket option pricing: A simple two-dimensional partial differential equation. Quantitative Finance 19: 1689–704. [Google Scholar] [CrossRef]
- Hanbali, Hamza, Daniël Linders, and Jan Dhaene. 2022. Value-at-Risk, Tail Value-at-Risk and upper tail transform of the sum of two counter-monotonic random variables. Scandinavian Actuarial Journal 2023: 219–43. [Google Scholar] [CrossRef]
- Hanusz, Zofia, Joanna Tarasinska, and Wojciech Zielinski. 2016. Shapiro–Wilk test with known mean. Revstat Statistical Journal 14: 89–100. [Google Scholar]
- Hesselager, Ole. 1993. Extensions to Ohlin’s lemma with applications to optimal reinsurance structures. Insurance: Mathematics and Economics 13: 83–97. [Google Scholar] [CrossRef]
- IAA. 2018. Risk Adjustments for Insurance Contracts under IFRS 17. Monograph. Ottawa: International Actuarial Association. [Google Scholar]
- IFRS 17 Insurance Contracts. n.d. International Accounting Standards Board. Available online: https://www.ifrs.org/issued-standards/list-of-standards/ifrs-17-insurance-contracts.html/content/dam/ifrs/publications/html-standards/english/2023/issued/ifrs17/ (accessed on 16 March 2023).
- Kaas, Rob, Jan Dhaene, and Marc J. Goovaerts. 2000. Upper and lower bounds for sums of random variables. Insurance: Mathematics and Economics 27: 151–68. [Google Scholar] [CrossRef]
- Linders, Daniël, and Ben Stassen. 2016. The multivariate Variance Gamma model: Basket option pricing and calibration. Quantitative Finance 16: 555–72. [Google Scholar] [CrossRef]
- Milhaud, Xavier, and Christophe Dutang. 2018. Lapse tables for lapse risk management in insurance: A competing risk approach. European Actuarial Journal 8: 97–126. [Google Scholar] [CrossRef]
- Ohlin, Jan. 1969. On a class of measures of dispersion with application to optimal reinsurance. Astin Bulletin 5: 249–66. [Google Scholar] [CrossRef]
- Palmborg, Lina, Mathias Lindholm, and Filip Lindskog. 2021. Financial position and performance in IFRS 17. Scandinavian Actuarial Journal 3: 171–97. [Google Scholar] [CrossRef]
- Smith, William, Jennifer Strickland, Ed Morgan, and Marcin Krzykowski. 2019. 2018 IFRS 17 Preparedness Survey. London: Milliman. Available online: https://www.milliman.com/en/insight/2018-IFRS-Preparedness-Survey (accessed on 16 March 2023).








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carlehed, M. A Model for Risk Adjustment (IFRS 17) for Surrender Risk in Life Insurance. Risks 2023, 11, 62. https://doi.org/10.3390/risks11030062
Carlehed M. A Model for Risk Adjustment (IFRS 17) for Surrender Risk in Life Insurance. Risks. 2023; 11(3):62. https://doi.org/10.3390/risks11030062
Chicago/Turabian StyleCarlehed, Magnus. 2023. "A Model for Risk Adjustment (IFRS 17) for Surrender Risk in Life Insurance" Risks 11, no. 3: 62. https://doi.org/10.3390/risks11030062
APA StyleCarlehed, M. (2023). A Model for Risk Adjustment (IFRS 17) for Surrender Risk in Life Insurance. Risks, 11(3), 62. https://doi.org/10.3390/risks11030062