1. Introduction
Human longevity has steadily increased over the last 150 years. During the first half of that period, improvements in life expectancy were mainly attributable to the reduction in infant mortality; in the second half, improvements have been mainly driven by a fall in the mortality rates of the elderly (
Wilmoth 2000). Increasing human longevity and ageing represent a major challenge with implications at many societal levels, including rising pressure on healthcare and welfare systems and a declining labour force relative to the overall population. In response, actuaries and demographers have paid increasing attention to the modelling and projection of mortality rates.
One of the most influential approaches to the stochastic modelling of future mortality has undoubtedly been the parametric non-linear regression model developed by
Lee and Carter (
1992). In the Lee–Carter (LC) model, the mortality rate is estimated by means of a non-linear combination of age and period parameters. Many subsequent attempts at developing mortality models have drawn inspiration from the LC model, including, but not limited to,
Brouhns et al. (
2002),
Currie et al. (
2004),
Renshaw and Haberman (
2003,
2006),
Cairns et al. (
2006) and
Plat (
2009). Following the introduction of the concept of mortality coherence by
Li and Lee (
2005) to indicate that the mortality rates of related populations should not diverge infinitely, many articles have extended the LC model to focus, specifically, on such coherence. Mortality coherence of related populations has, thus, been considered in terms of gender (
Li 2013;
Li et al. 2016,
2021;
Pitt et al. 2018;
Wong et al. 2020;
Yang et al. 2016) and the countries constituting a given region (
Biffis et al. 2017;
Chen and Millossovich 2018;
Diao et al. 2021;
Enchev et al. 2017;
Lyu et al. 2021;
Scognamiglio 2022). See
Hunt and Blake (
2021c) for a review of mortality models and
Blake et al. (
2023) for recent developments in mortality modelling.
One issue that has not received sufficient research is the impact the selection criteria might have on the model selection decision. As
Atance et al. (
2020) stress, there is no single criterion for evaluating the goodness-of-fit and the prediction accuracy of stochastic mortality models. Selection criteria frequently rely on measures based on squared errors (
Chang and Shi 2022;
Enchev et al. 2017;
Gao and Shi 2021;
Li and Lu 2017;
Li and Shi 2021), absolute errors (
Li et al. 2016,
2021), maximum likelihood (
Pitt et al. 2018;
Yang et al. 2016) or a combination of these measures (
Atance et al. 2020;
Chen and Millossovich 2018;
Huang et al. 2022;
Li 2013;
Wong et al. 2020). Additionally, even the same selection criteria measures are often defined based on either mortality rate predictions (estimates) (
Atance et al. 2020;
Chen and Millossovich 2018) or log mortality rate predictions (estimates) (
Chang and Shi 2022;
Enchev et al. 2017;
Gao and Shi 2021;
Li and Lu 2017;
Li and Shi 2021;
Li et al. 2021;
Li and Lee 2005;
Wong et al. 2020). Elsewhere, others have used a combination of measures based on mortality rates expressed on both original and log scales (
Li 2013;
Li et al. 2016). Predictive analytics, machine learning and artificial intelligence have become popular in recent years (
Chen and Khaliq 2022;
Hainaut 2018;
Li 2023;
Marino et al. 2023;
Perla et al. 2021;
Richman and Wüthrich 2021;
Wang et al. 2021) and scholars are also using different selection criteria measures to compare the mortality models. For example, on the original scale, the mean squared error is used by
Richman and Wüthrich (
2021), the mean absolute percentage error by
Wang et al. (
2021) and both measures by
Chen and Khaliq (
2022), while, on the log scale, the mean square error is used by
Hainaut (
2018).
The goal of the present article is to evaluate the implications of choosing selection criteria measures for the reference LC stochastic model based on either mortality rates or log mortality rates. The model selection measures used in this study are based on squared and absolute errors. To undertake this evaluation, we analyse the performance of stochastic reference mortality models, for a set of countries, in terms of their goodness-of-fit and prediction accuracy when the selection measures are based on either original mortality rates or log mortality rates. In doing so, we compare four alternative reference mortality models: namely, the original LC model (LC), the LC model with (log)normal distribution (LN-LC), the LC model with Poisson distribution (P-LC) and the median LC model (M-LC).
Reference stochastic mortality models are rarely compared in the literature. Claims have been made to the effect that the Poisson assumption provides a more rigorous statistical framework for analysing mortality data and that counting random variables is a more natural choice than that of modelling the death rate (
Cairns et al. 2009;
Li 2013;
Wong et al. 2020). However, Gaussian and Poisson LC models have not been compared to date in terms of their goodness-of-fit and prediction accuracy, with the exception of
Brouhns et al. (
2002), who compared the two models solely in terms of the goodness-of-fit of Belgian mortality rates, concluding that the Poisson LC model performed better for ages above 90. Here, by comparing the use of selection criteria measures based on mortality rates in either the original or log scales, we seek to determine if the preference for the Gaussian or Poisson assumption is conditional on the scale involved. While
Santolino (
2020) introduced the LC quantile stochastic model to estimate the quantiles of the log mortality rate, here, we focus our attention on the median LC model as a specific version of the LC quantile model that models the median log mortality rate (
Santolino 2021). Recall that the mean is the value that minimizes the squared error while the median minimizes the absolute error. Thus, we also seek to determine whether the median LC model is the preferred choice when absolute-error-based selection measures are used in both the log and original scales.
Finally, we also examine whether the selection of the preferred reference mortality model also depends on the interval of ages considered. In the actuarial field, the mortality patterns of greatest interest are often those that manifest at more advanced ages. Most life insurance products are defined so as to provide longevity protection, given that individuals receiving a lifetime income may live longer than accounted for in the valuation of the provision of insurer liabilities (longevity risk) (
Hunt and Blake 2021a,
2021b). Annuities are usually deferred to retirement. Pension funds and annuity providers need to effectively manage the longevity risk to which they are exposed for future improvements in mortality at the ages at which periodic payments are made (
OECD 2014). In this study, therefore, we analyse the performance of the four reference mortality models under the alternative selection criterion measures at ages both below and above 50 years old.
The main contribution of our study is that the focus is on the selection criteria measure and how it determines the choice of the optimal stochastic mortality model. In previous studies, the selection criteria measures are usually stated a priori and a set of mortality models is evaluated according to them to choose the preferred model. In those studies, the focus is on the design of a new—frequently more complex—mortality model. The aim of those studies is to prove that the new modelling approach outperforms previous mortality developments in terms of goodness-of-fit and/or prediction accuracy. Multiple selection criteria measures can be used to evaluate mortality models. To the best of our knowledge, however, the impact of the choice of the selection criteria measure on the selected mortality model has not been previously discussed in detail in the literature. In our study, four basic stochastic mortality models with equal complexity in their designs are stated and the impact of alternative selection measures on the model choice is discussed.
The rest of this article is structured as follows. In
Section 2, we introduce our notation. Our motivation for the study is provided in
Section 3. Stochastic parametric mortality models are described in
Section 4. We present an application in
Section 5. The analysis is illustrated for a population divided in age intervals in
Section 6. Finally, a discussion is provided in
Section 7.
2. Notation
Let the random variable denote the number of deaths in a population at age x and calendar year t, and . The central rate of mortality is defined as , where is the central exposure to risk at age x in year t. The estimated and predicted central rates of mortality are denoted as and , respectively.
Two measures have been preferred in the literature to compare fitted and predicted values: the sum of the squared error and the sum of the absolute percentage error (or their respective mean values). The sum of the squared error in log scale (
) is defined as
and the sum of the absolute percentage error in log scale (
) as
The out-of-sample versions of these measures can be defined to evaluate prediction accuracy as follows. Let us consider that data until the calendar year
were used to calibrate mortality models, for
. The sum of the squared predicted error in log scale (
) is defined as
and the sum of the absolute percentage predicted error in log scale (
) as
In line with
Li and Lee (
2005), who proposed the use of the explanation ratio to compare models, here, we use this ratio to evaluate the prediction accuracy of our models. If we consider that
for
, the explanation ratio in log scale
can be defined as
Equivalent measures can be derived for mortality rates in the original scale. The sum of the squared error (
) is defined as
the sum of the absolute percentage error (
) as
the sum of the squared predicted error (
) as
and the sum of the absolute percentage predicted error (
) as
Finally, the explanation ratio
R can be defined as
A review of these and other selection measures used in the literature, including the mean absolute error, is provided by
Atance et al. (
2020).
3. Motivation
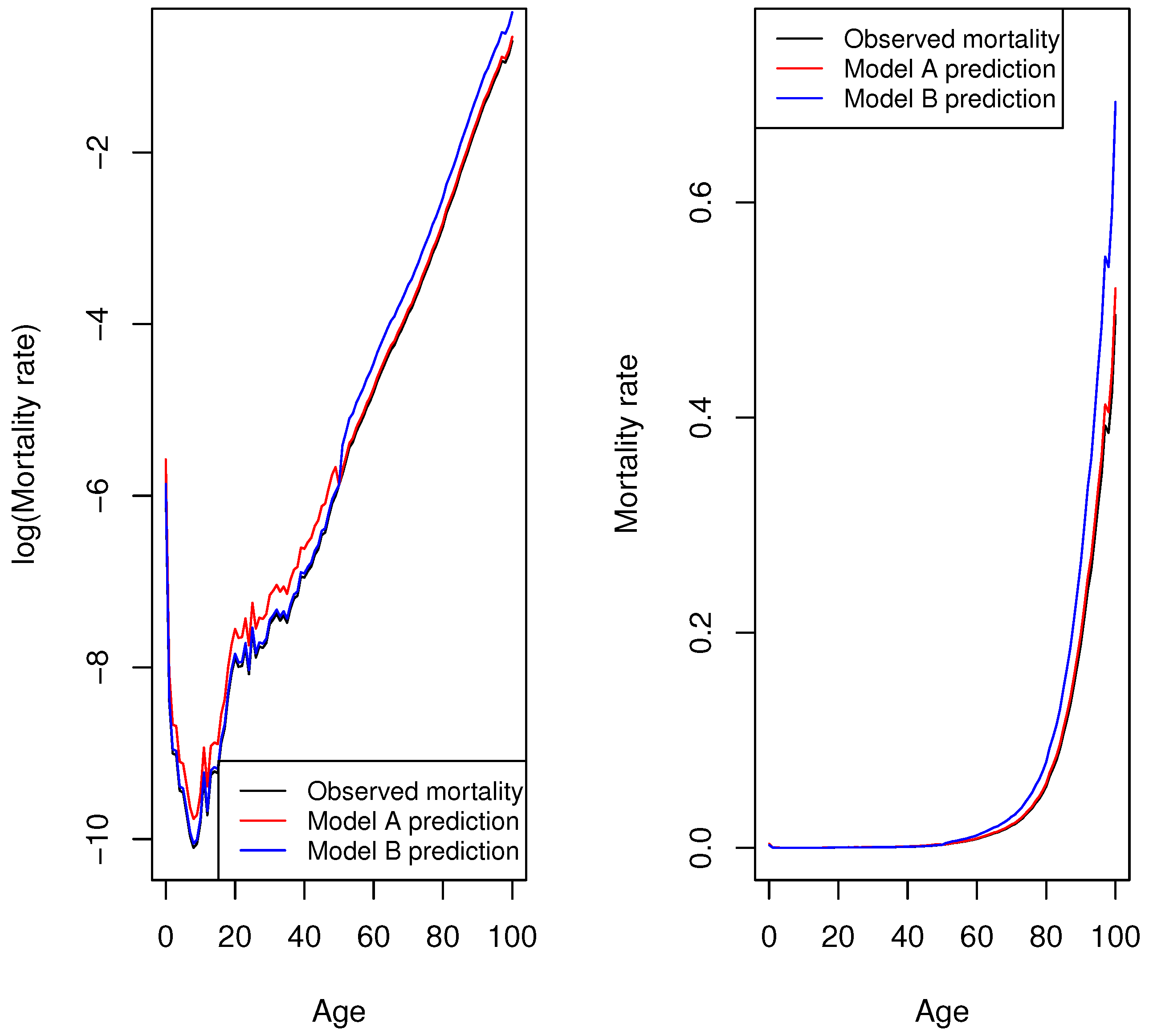
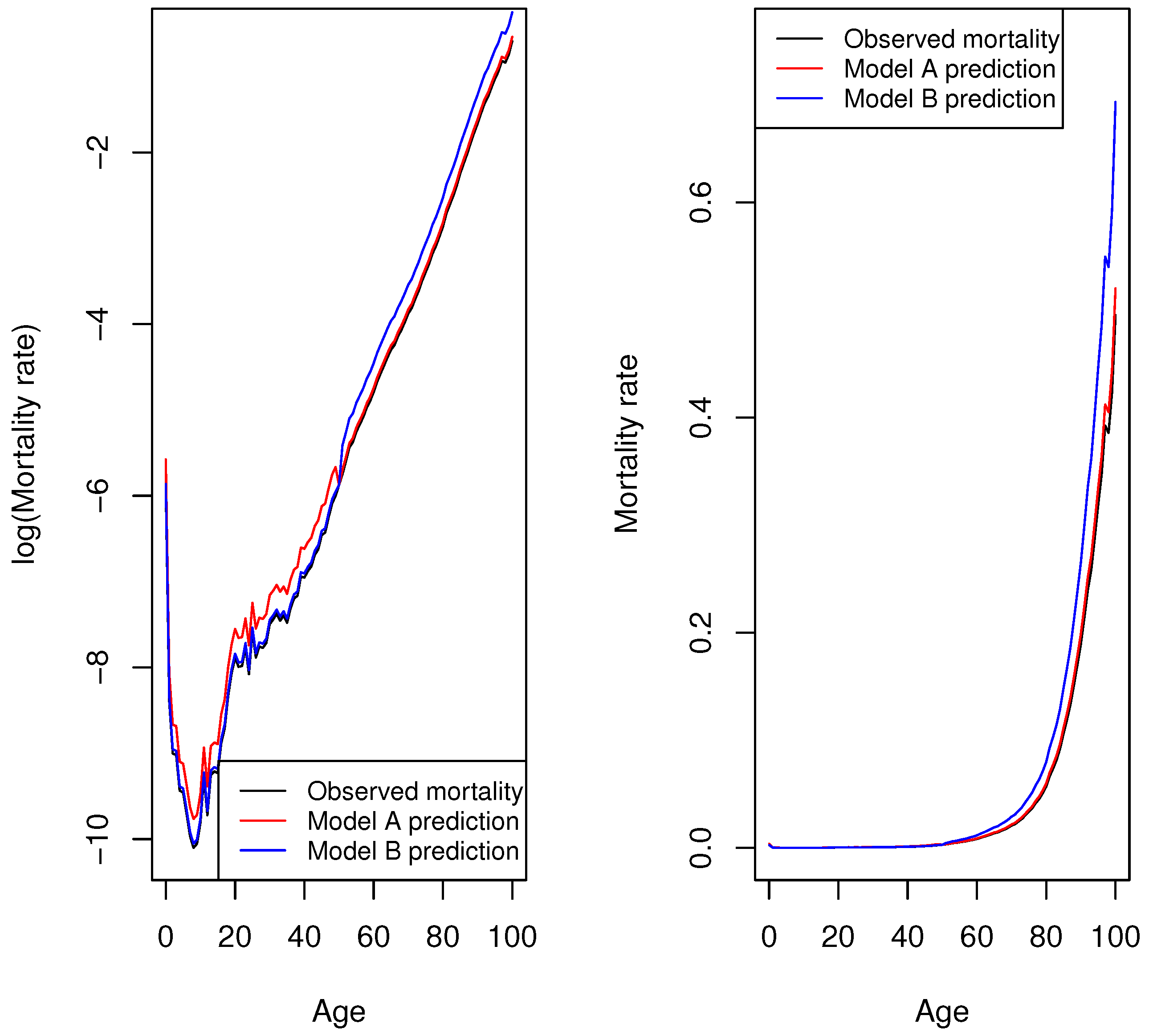
To illustrate differences in the analysis of mortality rates in log scale and in the original scale, we consider the 2020 mortality rate of the Spanish male population for ages between 0 and 100 years. Data were obtained from the Human Mortality Database (
HMD 2023). Let us assume that two stochastic mortality models were used to forecast the mortality rates for Spanish males.
Model A predicted a higher mortality rate for each age below 50 and a higher rate for each age above 50.
Model B predicted a higher mortality rate for each age below 50 and a higher mortality rate for each age above 50.
Figure 1 shows the mortality rate predictions made by the two models and the observed Spanish male mortality rate—on the left, as represented in logarithmic scale; on the right, as represented in the original scale.
Figure 1 (left) shows that both model predictions are equally acceptable; however, their prediction accuracy differs when mortality rates in the original scale are analysed (
Figure 1, right). When squared errors of the log mortality rates are compared, the
of models A and B take the same value (
); thus, the choice of model is indifferent. However, the prediction accuracy of both models differs when the sum of the squared error of mortality rates in the original scale is analysed. In this case, model A is preferred:
of model A
vs.
of model B
However, the opposite holds if the sum of the absolute percentage error is analysed. Prediction accuracy is different in log scale:
of model A
vs.
of model B
Thus, model A would be preferred. However, the choice of models is indifferent when the sum of the absolute percentage error is compared in the original scale:
of both models A and B
5. Application
To evaluate the models’ goodness-of-fit and prediction accuracy, the mortality rate of the male population in the 0–100 age range was considered for a set of countries. Data were obtained from the Human Mortality Database (
HMD 2023). In selecting the interval of years for each country, we chose the most recent period—with a minimum interval length of sixty years and a maximum of one hundred—for which complete mortality rates were available. Calendar years with null mortality rates for ages in the 0–100 range were excluded since log mortality rates cannot deal with zeros. An alternative would have been to consider null mortality rates as missing values and to use statistical techniques to impute values (
Scognamiglio 2022). However, we opted to exclude these calendar years to avoid any impact on our results attributable to the application of imputation techniques. Nine countries were compared (in parentheses is the period considered in our analysis): Austria (1922–2020), Belgium (1945–2020), Canada (1921–2020), France (1921–2020), Italy (1957–2019), Japan (1947–2021), Spain (1921–2020), UK (1922–2020) and USA (1933–2020). The rest of the countries for which information was available presented null mortality rates for ages in the 0–100 range in at least one year in the last sixty and, so, were not included in the analysis.
5.1. Goodness-of-Fit
The sum of squared errors for the nine countries when evaluating their respective mortality rates in logarithmic (
) and original scale (
) are shown in
Table 1. The stochastic mortality model providing the lowest goodness-of-fit value is highlighted in bold for each country. In the logarithmic scale, the minimum sum of squared errors is observed for the LC with lognormal distribution (LN-LC) followed by the original LC model. When the sum of squared errors is analysed in the original scale (
), the best fit is again provided by the LN-LC, but it is now followed by the P-LC and M-LC. The original LC framework would be our least preferred of the four when evaluating the sum of squared errors in the original scale.
The sum of the absolute percentage error for the nine countries when the mortality rate was evaluated in the logarithmic (
) and original scales (
) are shown in
Table 2. The lowest
value is provided by the M-LC model for six countries, so we would select this as our reference model when the minimum
criterion is applied. The other three models perform similarly in terms of
. When the minimum
criterion is applied, the M-LC model would also be selected. In this case, the second best fit is provided by the original LC modelling approach.
5.2. Prediction Accuracy
Stochastic mortality models seek to forecast future mortality; thus, their prediction accuracy is often more important than a particular model’s goodness-of-fit. The four mortality models compared herein have just one time-dependent parameter: that is, the time-varying index in the LC, LN-LC and P-LC models and in the M-LC model. In other words, the dynamics of the mortality rates are captured by the set of estimated mortality indexes and , . Time-series techniques are used to project mortality indexes. For comparative purposes, in all cases, estimated mortality indexes are assumed to follow an autoregressive integrated moving average with drift, ARIMA ().
To evaluate the models’ prediction accuracy, the following approach was followed. Model parameters were estimated with mortality data until calendar year 1990 and the model was then projected until either calendar year 2020 or the last year for which mortality data were available.
1 The sum of the squared prediction error and absolute percentage prediction error WAS computed in the logarithmic scale,
and
, and in the original scale,
and
. An additional year was then included in the model estimation, so that their parameters were estimated with mortality data until 1991. Mortality projections were made to the last year for which data were available and prediction errors were computed. The process was repeated with an additional year being included each time in the model estimation. In the last step, the parameters were estimated with mortality data up to and including the penultimate calendar year for which mortality data were available and, thus, mortality was projected one year ahead.
Table 3 displays in percentage terms the number of times that each model performed best in terms of the minimum squared prediction error and the absolute percentage prediction error in log and original scales. When prediction accuracy was evaluated in terms of the lowest squared prediction error in log scale, the LN-LC model performed best (
), followed by the LC model (
) and the M-LC model (
). However, the lowest sum of absolute prediction percentage error in log scale was most frequently obtained by the M-LC model (
), closely followed by the P-LC model (
). When prediction accuracy was evaluated in terms of the lowest sum of the squared prediction error in the original scale, the P-LC model performed best (
). The P-LC model also recorded the best performance in terms of obtaining the lowest sum of the absolute percentage prediction error, but was closely followed by the M-LC model (
and
, respectively).
Table 3 displays the average of the number of times that each model performed the best for the horizon period 1991–2020.
Appendix A shows the performance of the mortality models for different projection periods to evaluate the impact of the selected forecast horizon on the outcomes (
Table A1). The results remained quite stable for the different time horizons. A remarkable pattern is that the PLC model was preferred to the MLC model for time horizons further out in time in accordance with the absolute error measures (
and
). However, the preference was reversed when shorter-term predictions were made (time horizons of less than or equal to ten years, approximately).
While
Table 3 provides information as to just how often a model performed best in terms of the lowest selection measure value, it says nothing about how accurate the prediction was.
Table 4 addresses this by showing the average explanation ratio for the four models in the log scale
and the original scale
On average, the explanation ratio in log scale for both the LC and LN-LC models was
, followed by the M-LC (
) and, finally, the P-LC model with the lowest mean explanation ratio
. In the original scale, the order of the performance of the models is inverted. Here, the best mean explanation ratio is obtained by the P-LC model (
), followed by the M-LC model (
) and, finally, the LN-LC and LC models had the lowest mean explanation ratios (
and
, respectively).
6. Analysis by Age Interval
Actuarial practitioners are typically interested in mortality patterns in advanced ages given their impact on life insurance pricing and provisions. In addition, heterogeneity in mortality, which is due to observable and unobservable differences among individuals, increases at older ages, producing more variability in the observed deaths of old populations (
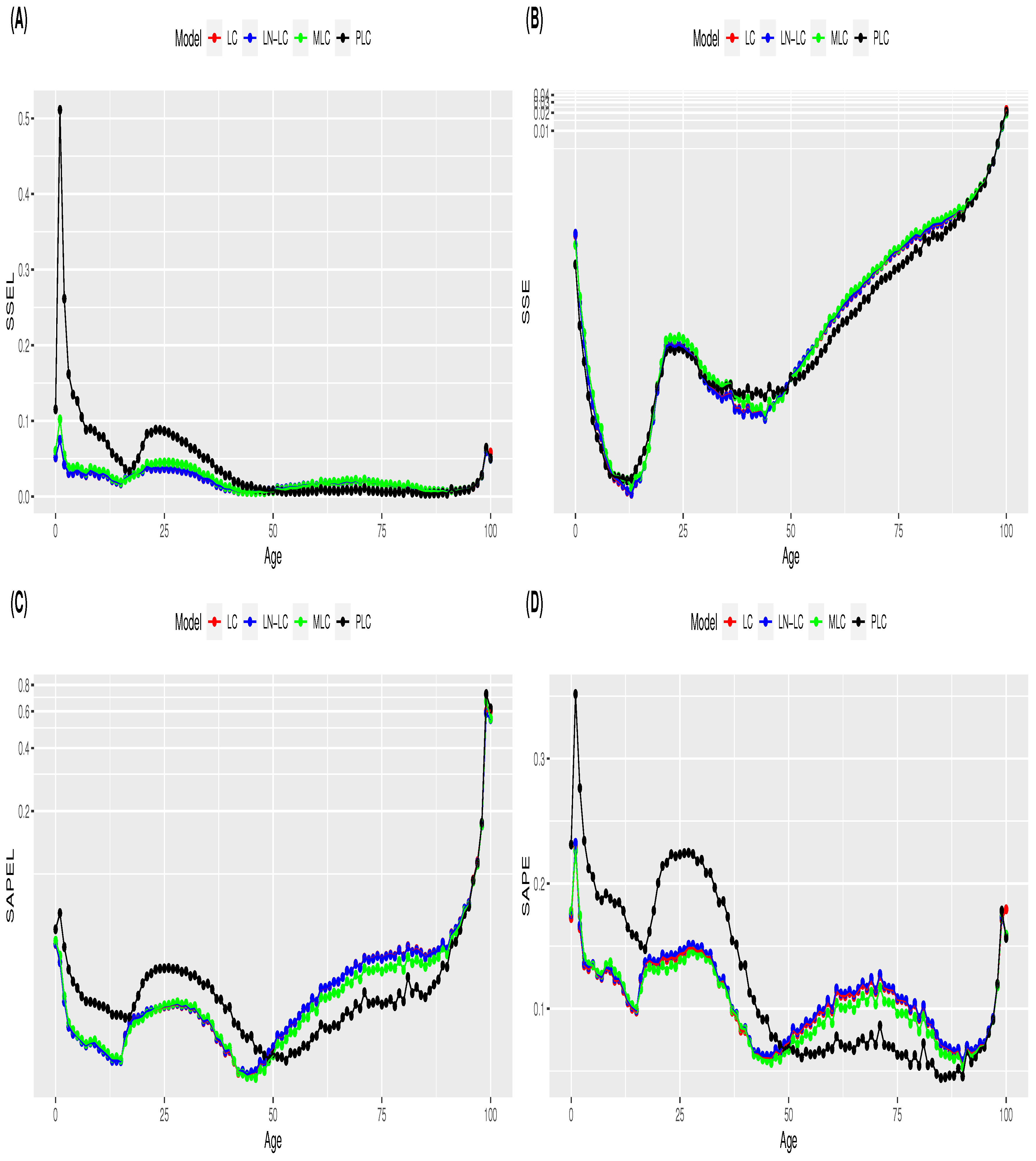
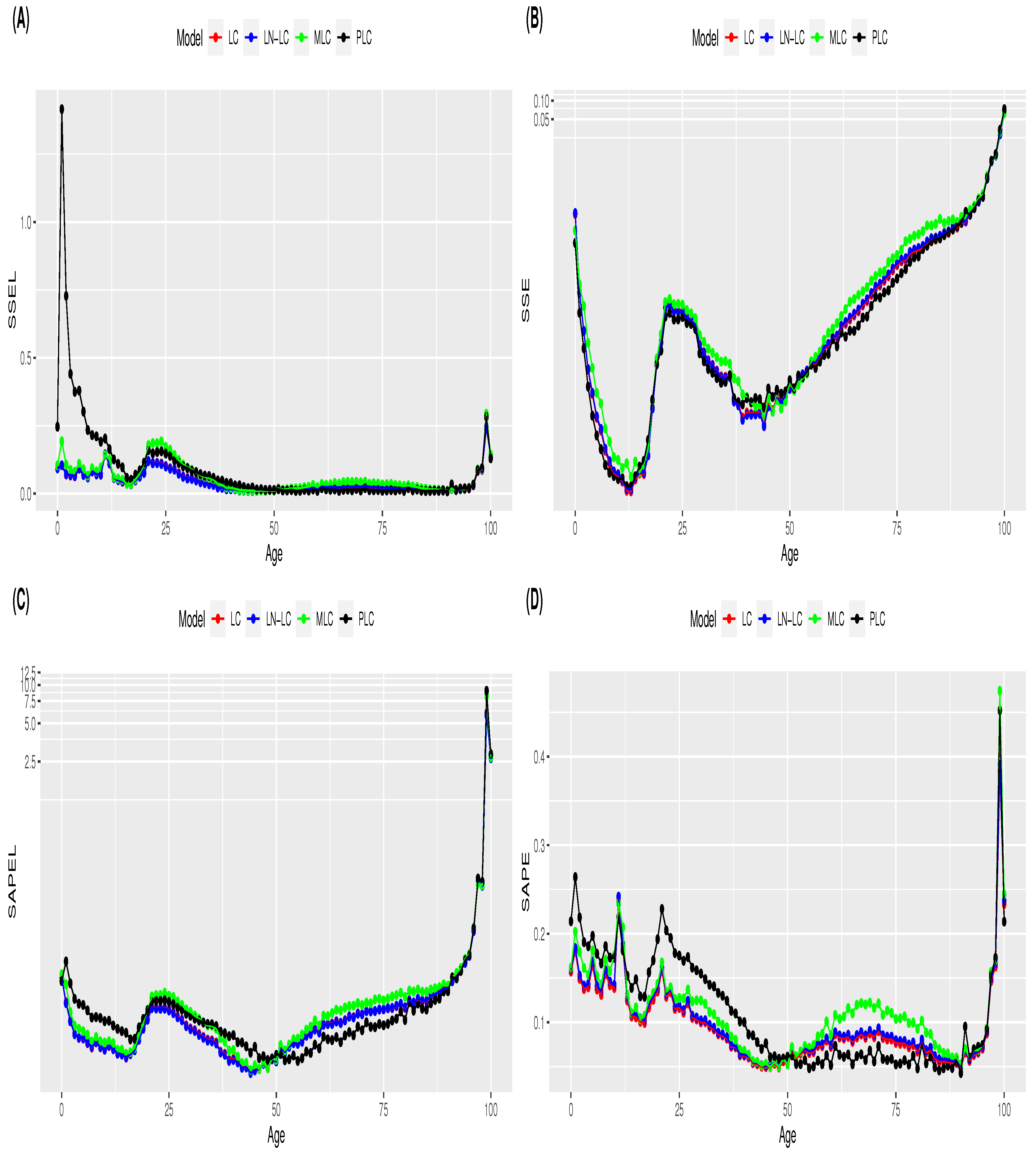
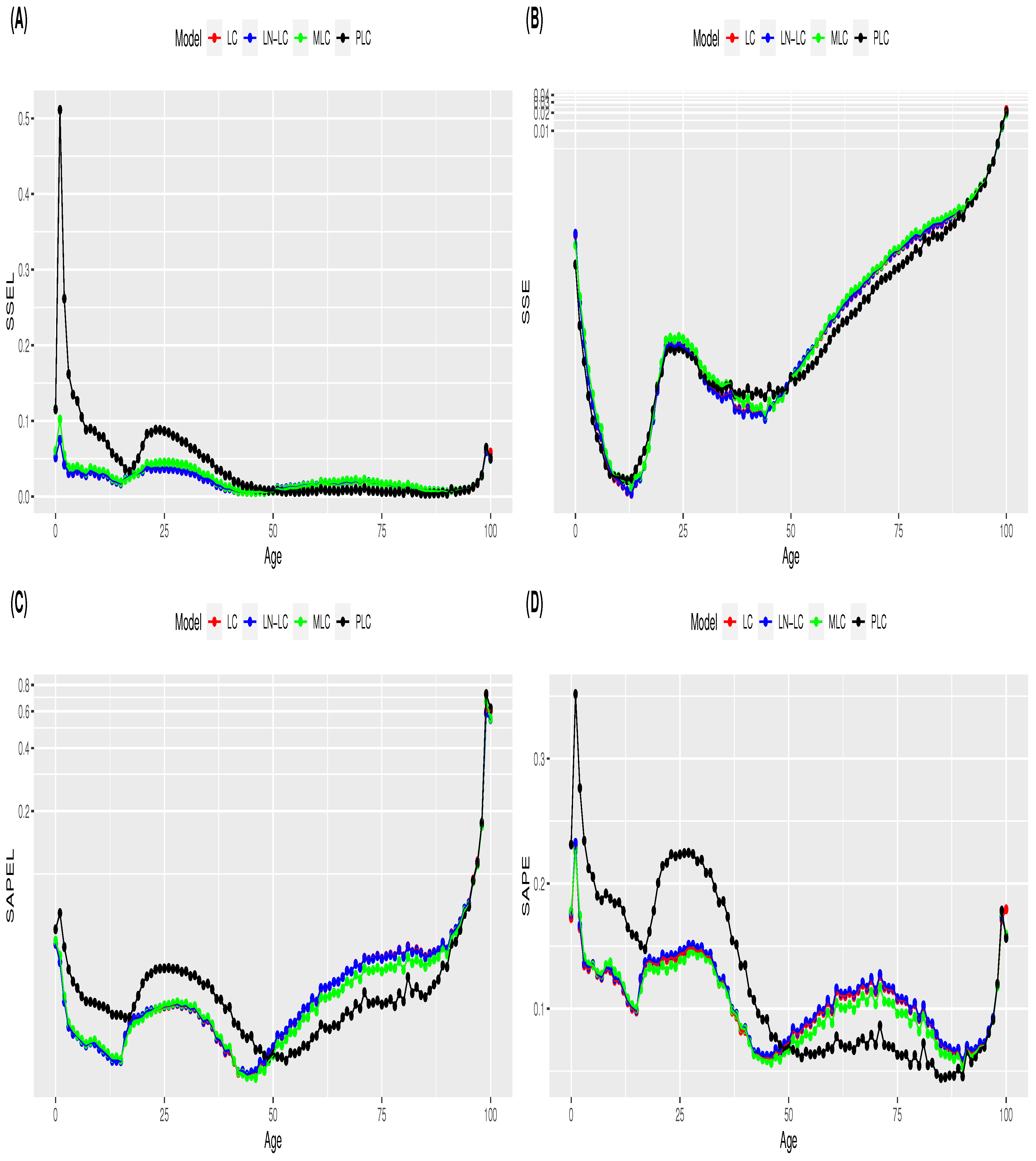
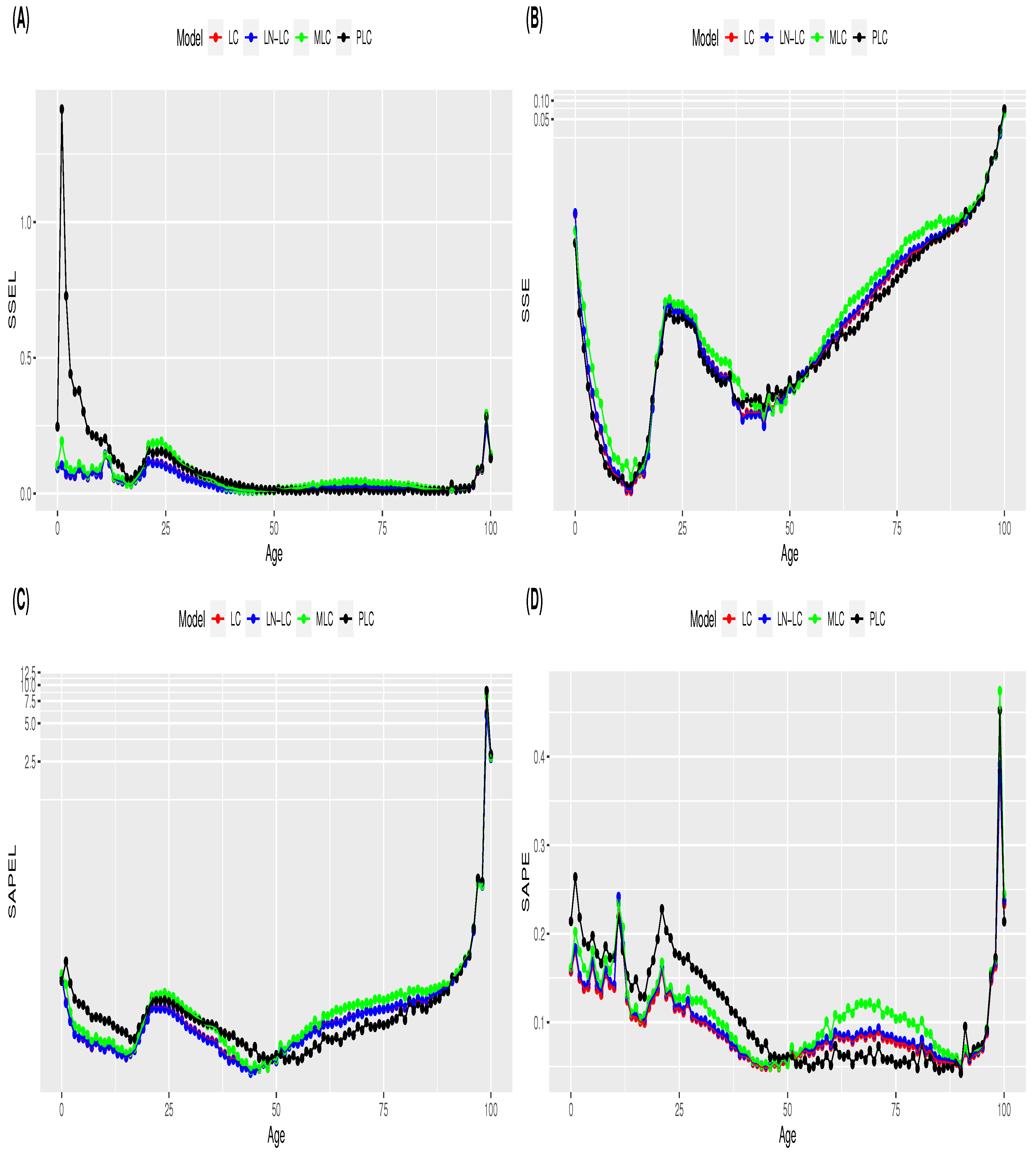
Pitacco 2019). In this section, we analyse the performance of the four reference mortality models when employing alternative selection criterion measures for young and old populations. The four goodness-of-fit selection measures were estimated by age for each mortality model. The mean and standard deviation values of the error measures by age are displayed in
Figure A1 and
Figure A2 of
Appendix B, respectively. In terms of the estimated mean error, a change in the performance behaviour of models is observed at approximately the age of 50 years for the four selection measures (
Figure A1). In terms of the standard deviation of estimated errors, as expected, higher values are observed for old ages (
Figure A2). In the case of the PLC, a high variability in the
measure is also observed for young ages (
Figure A2). Based on these results, the age of 50 years is selected as a breaking point to separate the age range between young and adult populations. Mortality models are fitted for all ages, but the computation of model selection measures is achieved by differentiating the population into two age intervals: 0–50 years (young) and 51–100 years (old). Our goal is to analyse whether model selection is dependent on the age interval considered.
Goodness-of-fit tables for the young and old populations are provided in
Appendix B. Based on the lowest sum of the squared error for the young population, the LC model for mortality rates was preferred in the log scale and the P-LC model in the original scale. However, based on the absolute percentage error for the young population, the M-LC and LC models performed best in terms of presenting the lowest
and
. In the case of the old population, the preferred model was the P-LC on the basis of the
, the
and the
goodness-of-fit measures. When considering the
, the LN-LC model was the preferred model for the old population.
Model prediction accuracy results are shown separately for the young and old populations (
Table 5 and
Table 6).
Table 5 reports in percentage terms the number of times each mortality model performed best in terms of minimum squared prediction error and absolute percentage prediction error in log and original scales, differentiating by age group. For the population under 50, the mortality model providing the best prediction most frequently was the LC model, followed closely by the LN-LC and M-LC models. In contrast, the P-LC model rarely provided the best prediction in the age range 0 to 50, regardless of the prediction measure considered. However, for the population aged 51–100, the P-LC model provided the highest degree of prediction accuracy with largely overlapping values for all prediction measures.
Finally,
Table 6 shows the average of the explanation ratio in log scale and original scale, differentiating between the young and old populations. The LC model was the model with the highest explanation ratio on average in log scale for the population aged under 50, closely followed by the LN-LC and M-LC models. In contrast, the explanation ratio of the P-LC model is notably lower
. The distance, however, is shortened when the explanation ratio is analysed in the original scale for this young population. Now, the highest mean explanation ratio is obtained by the LN-LC model
, closely followed by the LC
, M-LC
and P-LC models
.
When analysing the prediction accuracy for the population aged 51 and over, the highest explanation ratio on average was obtained by the P-LC model in both the log scale and the original scale . The performance of the other three mortality models in terms of the mean explanation ratio was notably worse in both log and original scales. In log scale, the second-best model in terms of the mean explanation ratio was the LN-LC model , followed by the LC and M-LC models . In the original scale, the second best model was the M-LC model , followed by the LN-LC and M-LC models .
Remark 2. The four reference stochastic mortality models analysed in our study are single-factor mortality models. Multiple factors may be required to capture the dynamics of mortality rates, particularly at older ages where mortality rates are higher and variability is shown to be higher. In Appendix C we provide an illustration of the performance of two-factor mortality models with lognormal and Poisson error distributions. In the case of the lognormal two-factor mortality model, the expected value of the log mortality rate is expressed as . In the case of the Poisson two-factor mortality model, the log of the expected value of the mortality rate is . The percentage of times that the two-factor models performed the best in terms of goodness-of-fit and prediction accuracy are shown in Table A6 and Table A7, respectively. The results are in line with those obtained in the case of single-factor mortality models. In terms of goodness-of-fit, the lognormal two-factor mortality model is preferred. By contrast, the Poisson two-factor model is preferred in terms of prediction accuracy. For age, the two-factor lognormal model has a better fit and better prediction for ages below 50 years, while the two-factor Poisson model has a better fit and better prediction for ages above 50 years. 7. Discussion and Concluding Remarks
7.1. Discussion
Goodness-of-fit and prediction accuracy measures are usually defined in terms of the sum of squared errors and the sum of absolute percentage errors. In the case of mortality modelling, these measures may be defined for mortality rates in log scale or in the original scale. When our primary interest lies in the performance of mortality models for age ranges that present relatively low mortality rates, selection measures need to assess relative rather than absolute variations in estimations/predictions. In this case, the selected measures should be the sum of squared errors in log scale and the sum of absolute percentage errors in the original scale. In contrast, the sum of squared errors in the original scale and the sum of absolute percentage errors in log scale should be selected when the performance of mortality models for age ranges that present relatively high mortality rates is our priority.
This distinction between selection measures defined on the basis of mortality rates in either log or original scales is relevant because of the marked differences in mortality rates with age. For instance, in 2020, in the case of the Spanish male population, the mortality rate of a 5-year-old boy was approximately 36 times lower than that of a 50-year-old male, 430 times lower than that of a 75-year-old male, and 2429 times lower than that of a 90-year-old male (
Figure 1). This means that conclusions may diverge when the analysis is conducted based on selection measures defined with mortality rates on log scale, on the one hand, and with mortality rates on the original scale, on the other.
In terms of goodness-of-fit, we conclude that the best performance is provided by the LC model with lognormal distribution when selection measures are based on squared errors, regardless of the scale of the mortality rates. In logarithmic scale, the performances of the original LC model and the LN-LC model are similar, but the latter is clearly preferred to the original LC when the squared error selection measure is based on mortality rates in the original scale. In fact, both the Poisson LC model and the median LC model are preferred to the original LC model when goodness-of-fit is evaluated based on squared errors in the original scale. The LN-LC model takes into account that the expected mortality rate is higher than the exponential of the mean of the log mortality rate. That is, the Gaussian (lognormal) error distribution for mortality rates in log (original) scale seems adequate when the purpose is to minimize squared errors. Goodness-of-fit measures are often based on the absolute percentage error (
Li et al. 2016,
2021) and, here, when the selection criterion is the minimum absolute percentage error, the best performance was obtained by the M-LC model in both log and original scales.
The parameters of the LN-LC and the P-LC models were estimated using maximum likelihood, whereas the parameters of the original LC model were estimated using least square optimization techniques and those of the M-LC model using least absolute optimization techniques. In the case of the original LC model, the conditional mean of the log mortality rate is estimated; in the case of the M-LC model, the conditional median of the log mortality rate is computed. In general, the mean of the log does not match the log of the mean; yet, the median of the log does match the log of the median. The M-LC model performs better than the original LC model in terms of goodness-of-fit when selection measures based on absolute errors are used, but also when the selection measure is the sum of squared errors in the original scale. Thus, least absolute optimization algorithms can be an interesting alternative to least square optimization algorithms to estimate the parameters of the LC model when we are interested in ages with relatively high mortality rates.
Stochastic mortality models serve to predict future mortality, hence the interest in evaluating the prediction accuracy of such models. When the models’ prediction error is considered in the original scale, the most accurate predictions are obtained most often by the P-LC model. The superior performance of the P-LC model is particularly evident when prediction accuracy is evaluated in terms of the squared prediction error. When the prediction error is evaluated in log scale, the best performance is provided by the LN-LC model in terms of the squared prediction error and the M-LC model in terms of the absolute percentage predicted error. Unlike the squared prediction error in log scale, the absolute percentage prediction error in log scale penalizes prediction errors in ages associated with high mortality rates.
Mortality patterns in advanced ages attract particular attention in actuarial research given their relevance for insurance products. When considering an old population (aged 51 and over), the best fit is provided by the P-LC model when the selection criteria are defined in log scale, but also when the criteria are based on the absolute percentage error in the original scale. This means the Poisson LC should be selected if our primary concern is goodness-of-fit for a population at advanced ages. This outcome is in line with
Brouhns et al. (
2002), who showed that the P-LC model performed better than the original LC model at the most advanced ages (over 90) in the Belgian population in terms of the proportion of the variance accounted for by the model. However, here, unlike in
Brouhns et al. (
2002), we compare the prediction accuracy for different age intervals. The preference for the Poisson model becomes more explicit when the prediction accuracy is analysed for the old population (aged 51–100). In this case, all the prediction accuracy measures considered in this study show the performance of the P-LC model to be superior to that of the other models.
In short, in terms of goodness-of-fit, mortality models that perform well in log scale also perform adequately in the original scale. In general, the LC model based on the lognormal distribution is preferred to those based on squared errors, while the M-LC model is the preferred model based on absolute errors. These two models are also preferred when prediction accuracy is analysed in log scale. However, the Poisson LC model is unreservedly the one selected when prediction accuracy is analysed in the original scale, the reason being that the P-LC model performs particularly well in terms of both goodness-of-fit and prediction accuracy in the interval of ages marked by high mortality rates (population aged over 51). Yet, for the population aged 50 and under, the P-LC model performs worse in terms of both goodness-of-fit and prediction accuracy than the other models. However, even though it is the model with the poorest prediction accuracy, its explanation ratio in the original scale for this age interval is very high (). The explanation for this lies in the fact that the Poisson model does not perform as well as the other three models at ages associated with infinitesimal mortality rates.
Summarizing, the original LC model or the LC model regression with heavy right-tailed distributed error, such as the lognormal distribution, were adequate to describe and predict the behaviour of mortality rates in log scale in terms of the minimum square error (). However, the parameters estimates of the original LC model (least square techniques) and the lognormal-error-distributed LC model (maximum likelihood) seem more sensitive to observations with low mortality rates than those parameter estimates of the median LC model (least absolute techniques) and the Poisson-error-distributed LC model (maximum likelihood). As a result, the last two modelling approaches showed a better performance in minimizing square prediction errors in the original scale () and in terms of the minimum absolute percentage prediction error in the original and log scales ( and ). Therefore, LC-based modelling approaches focused on estimating the median or assuming Poisson error distribution seem more adequate when the mortality model is designed to predict mortality rates in the original scale (or in logarithmic scale when the prediction error is measured in terms of absolute percentage deviation). When our main interest lies in predicting mortality rates in log scale and the prediction error is measured in terms of square deviation, the original LC model or the LC model with lognormal-distributed error should be preferred.
7.2. Conclusions
In this article, we have evaluated the implications of using different selection criteria measures when seeking to choose the most suitable stochastic mortality model. We show that least absolute optimization techniques constitute an interesting alternative to least square algorithms for estimating the parameters of stochastic mortality models when our interest lies in the fitting of mortality rates expressed in the original scale. We also provide solid arguments for selecting the Poisson LC model when the main concern is the prediction accuracy of mortality rates in advanced ages (51 and over). This result has important implications, since while the Poisson assumption has traditionally been considered to provide a rigorous statistical framework, the prediction accuracies of Gaussian and Poisson LC models have rarely been compared.
In general, selection criteria measures based on log scale errors yielded approximately the same modelling preferences in the fitting and forecasting domains. That is, the quadratic and absolute error measures defined on a logarithmic scale showed roughly similar results when used to rank order explanatory models intended to explain variation in historical data and to rank-order predictive models focused on forecasting error. This was not the case for selection criteria measures based on original scale errors for both squared and absolute deviations. In that case, the selected mortality models with the best fit results according to these measures were not the preferred mortality models in terms of prediction accuracy.
The aim of our study was to examine the implications of selection criteria measures for the choice of the most appropriate stochastic model. For this purpose, four alternative versions of the stochastic LC mortality model with the same design and number of parameters were selected. The rationale for this selection was that the comparison between the mortality models should be `fair’ and no other elements should influence the results except the underlying distributional assumption and the method of parameter estimation. We argue that our comparison of the reference mortality models is useful to researchers. The need for more complex developments in mortality modelling is often justified when researchers compare the performance improvement of their models with respect to a reference mortality model. Our study may be useful in selecting the benchmark stochastic model to include in that comparison. However, we recognize that the number of models compared is limited and that a more comprehensive selection of modelling approaches should be an advantage. In this regard, the comparison of the mortality models with recent machine learning extensions of the LC model is an interesting practical exercise for the future.
To conclude, this study provides an enhanced awareness of the implications of using different selection criteria measures in terms of their impact on the performance of mortality models. Indeed, we show that models that provide a good fit or a good prediction performance in log scale may well be inadequate in the original scale, and vice versa. Some measures are better suited to mortality estimations/predictions at ages with relatively low mortality rates, while others perform better at ages with relatively high mortality rates. The use of one selection measure or another ultimately depends on the preferences of the decision makers, but they must be aware that the mortality model they select might be conditioned on the measure used in conducting the evaluation.





{kind=link}
{kind=link}
{kind=link}