
A New Class of Counting Distributions Embedded in the Lee–Carter Model for Mortality Projections: A Bayesian Approach



{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. A New Class of Counting Distributions on the Set of Nonnegative Integers
2.1. NEFs—Some Preliminaries
2.2. The Mean Value Parametrization of NEFs
2.3. Polynomial VFs of Counting NEFs Supported on the Set of Nonnegative Integers
2.4. A New Class of Polynomial VFs—The ABM NEFs
- It is a class of counting distributions supported on the non-negative integers;
- It is overdispersed as ;
- It allows a mean value parameterization in a closed form;
- It is infinitely divisible, which allows the construction of an exponential dispersion model (EDM) with dispersion parameter space equal to . EDMs are used to describe the error distribution in generalized linear models (see Jorgensen 1987, 1997);
- is an unknown parameter to be estimated (see next section). is a parameter governing the particular model within the ABM class and is considered to be a decision variable (note that different values of determine different ABM NEFs). Accordingly, for given national datasets (i.e., those of US, Ireland and Ukraine), the goal will be to locate that value of , which minimizes a respective RMSE (see in the sequel). However, due to the rather cumbersome and intractable structure of the ABM probabilities (or likelihood) in (6) and the fact that the larger the , the larger the number of elements in the summands appearing in (6), no analytic solution for an optimal is feasible at all for achieving such a goal. Consequently, only numerical search algorithms are plausible. The search starts with (the Poisson NEF), (the negative binomial NEF), (the Abel NEF) and so on;
- As already noted, the ABM class is composed of infinitely countable set of families of counting NEFs supported on the non-negative integers and thus can also be used to model real datasets by employing the classical frequency approach (and not only Bayesian). Indeed, the ABM class has been compared in Bar-Lev and Ridder (2021a, 2021b) with other common counting probability models (such as Poisson-inverse Gaussian distribution, new logarithmic distribution, an exponentiated discrete Lindley distribution) for various real count datasets stemming from automobile insurance claims, marketing, biometry, health, and social sciences (none of which is related to mortality projections). Members of the ABM counting class have shown superiority with respect to various metrics for goodness-of-fit tests (chi-squared test, Akaike information criterion (AIC), root-mean-square error (RMSE) and Kullback–Leibler divergence (KL)), and provided a much better fit for each of the datasets considered (more details can be found in Bar-Lev and Ridder 2021b).
3. ABM Based LC Model and its Bayesian Framework
MH (Metropolis–Hastings) Algorithm for Estimating the Parameters and
- Draw from the proposal density function , such that is assumed known;
- Calculate the following probability:where
- Draw a value u from uniform probability function in range and decide in accordance with the following formula:
- Going over all values of t, we have:
- Transforming and to assure identifiably:where
- Repeat steps 1 to 5.
- Draw from the proposal density function , such that is assumed to be known;
- Calculate the following probability:where
- Draw a value u from uniform probability function in range and decide in accordance with the following formula:
- Going over all values of x, we have:
- Transforming and to assure identifiably:where
- Repeat steps 1 to 5.
- Draw from the proposal density function , such that is assumed known;
- Calculate the following probability:where
- Draw a value u from uniform probability function in range and decide in accordance with the following formula:
- Receiving in th iteration as follows:
- Repeat steps 1 to 4.
- Draw from the probability function , such that and are hyperparameters and are assumed known;
- Calculate the following probability:
- Draw a value u from uniform probability function in range and decide in accordance with the following formula:
- Then receiving in th iteration;
- Repeat steps 1 to 4.
4. Numerical Experiment
4.1. Methods
- Predicting mortality rates by age. In other words, after model parameters were estimated, mortality rates were predicted for a given age across years. For instance, predicting mortality rates for those age 70 was carried out over the years beyond 2000;
- Predicting mortality rates by cohort. In other words, after model parameters were estimated, mortality rates were predicted for a cohort that was at a particular age at the beginning of the test period. For example, predicted mortality rates in 2001–2007 for a cohort aged 70 in 2001.
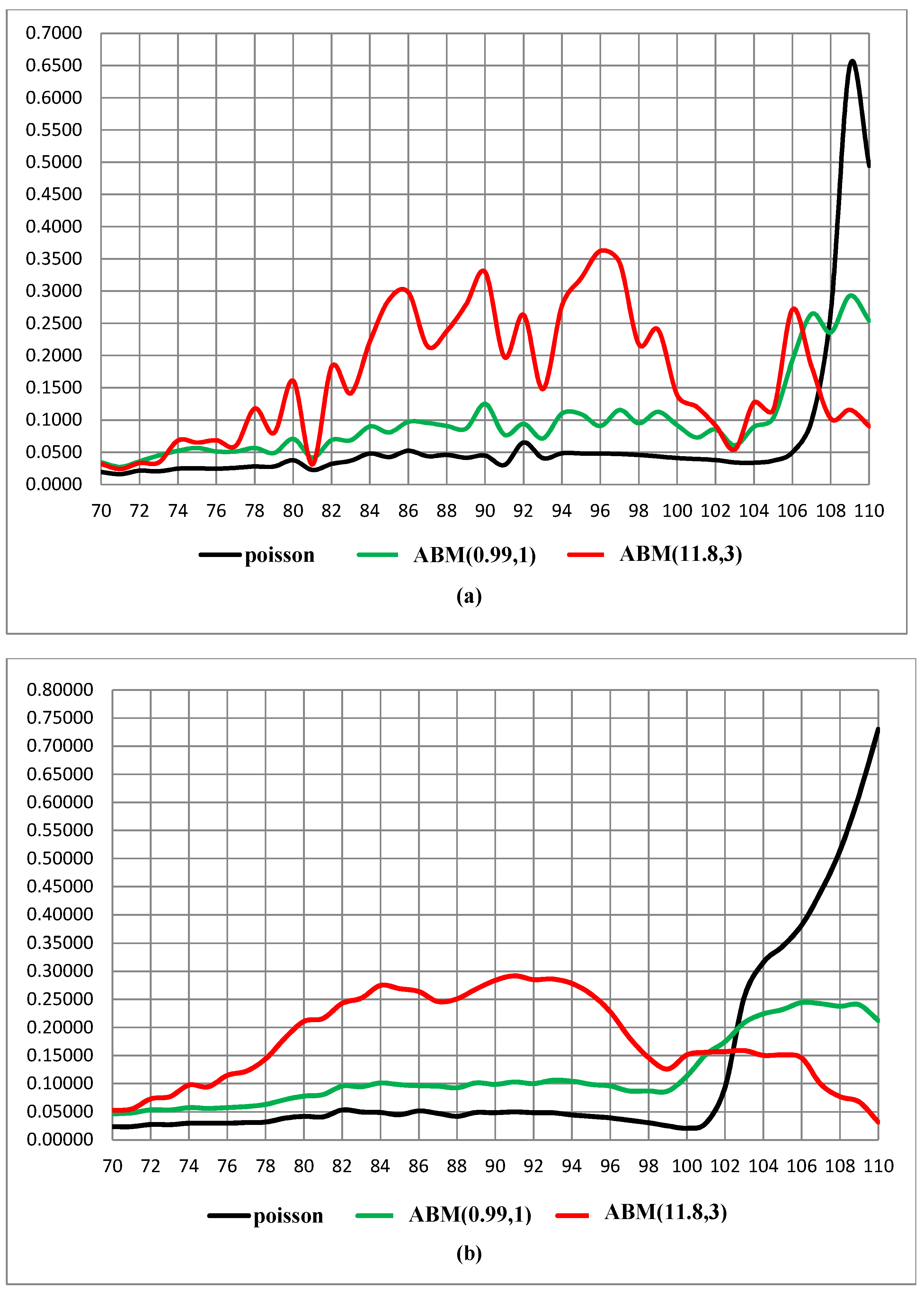
4.2. Results
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1
- For , the marginal posterior probability function of the time index is:where
- For , the marginal posterior probability function of the time index is:where
- For , the marginal posterior probability function of the time index is:where
Appendix A.2
Appendix A.3
References
- Antonio, Katrien, Anastasios Bardoutsos, and Wilbert Ouburg. 2015. Bayesian Poisson log-bilinear models for mortality projections with multiple populations. Eur. Actuar. J. 5: 245–281. [Google Scholar] [CrossRef]
- Awad, Yaser, Shaul K. Bar-Lev, and Udi Makov. 2016. A New Class Counting Distributions Embedded in the Lee–Carter Model for Mortality Projections: A Bayesian Approach. Technical Report No. 146. Israel: Actuarial Research Center, University of Haifa. [Google Scholar]
- Azman, Shafiqah, and Dharini Pathmanathan. 2020. The GLM framework of the Lee–Carter model: A multi-country study. Journal of Applied Statistics 49: 752–63. [Google Scholar] [CrossRef]
- Baltes, B. Paul, and Jacqui Smith. 2003. New frontiers in the future of aging: From successful aging of the young old to the dilemmas of the fourth age. Gerontology 49: 123–35. [Google Scholar] [CrossRef] [PubMed]
- Bar-Lev, K. Shaul, and Ad Ridder. 2019. Monte Carlo methods for insurance risk computation. International Journal of Statistics and Probability 8: 54–74. [Google Scholar] [CrossRef]
- Bar-Lev, K. Shaul, and Ad Ridder. 2021a. Exponential dispersion models for overdispersed zero-inflated count data. Communications in Statistics-Simulation and Computation. Available online: https://doi.org/10.1080/03610918.2021.1934020 (accessed on 10 August 2021).
- Bar-Lev, K. Shaul, and Ad Ridder. 2021b. New exponential dispersion models for count data—The ABM and LM classes. ESAIM: Probability and Statistics 25: 31–52. [Google Scholar] [CrossRef]
- Bar-Lev, K. Shaul, and Clestin C. Kokonendji. 2017. On the mean value parametrization of natural exponential families—A revisited review. Mathematical Methods of Statistics 26: 159–75. [Google Scholar] [CrossRef]
- Brouhns, Natacha, Michel Denuit, and Jeroen K. Vermunt. 2002. A Poisson log-bilinear regression approach to the construction of project life-table. Insurance: Mathematics and Economics 31: 373–93. [Google Scholar]
- Buettner, Thomas. 2002. Approaches and experiences in projecting mortality patterns for the oldest-old. North American Actuarial Journal 6: 14–29. [Google Scholar] [CrossRef]
- Czado, Claudia, Antoine Delwarde, and Michel Denuit. 2005. Bayesian Poisson log-bilinear mortality projections. Insurance: Mathematics and Economics 36: 260–84. [Google Scholar] [CrossRef] [Green Version]
- Danesi, L. Ivan, Steven Haberman, and Pietro Millossovich. 2015. Forecasting mortality in subpopulations using Lee—Carter type models: A comparison. Insurance: Mathematics and Economics 62: 151–61. [Google Scholar] [CrossRef]
- Delwarde, Antoine, Michel Denuit, and Christian Partrat. 2007. Negative binomial version of the Lee–Carter model for mortality forecasting. Applied Stochastic Models in Business and Industry 23: 385–401. [Google Scholar] [CrossRef]
- Ellison, Joanne, Erengul Dodd, and Jonathan J. Forster. 2020. Forecasting of cohort fertility under a hierarchical Bayesian approach. Journal of the Royal Statistical Society: Series A (Statistics in Society) 183: 829–56. [Google Scholar] [CrossRef]
- Graziani, Rebecca. 2020. Stochastic Population Forecasting: A Bayesian Approach Based on Evaluation by Experts. Developments in Demographic Forecasting 49: 21–42. [Google Scholar]
- Hilton, Jason, Erengul Dodd, Jonathan J. Forster, and Peter W. F. Smith. 2019. Projecting UK mortality by using Bayesian generalized additive models. Journal of the Royal Statistical Society: Series C (Applied Statistics) 68: 29–49. [Google Scholar] [CrossRef]
- Hunt, Andrew, and David Blake. 2020. A Bayesian Approach to Modeling and Projecting Cohort Effects. North American Actuarial Journal 25: S235–S254. [Google Scholar] [CrossRef]
- Ichikawa, Shota, Hiroyuki Yamamoto, and Takumi Morita. 2021. Comparison of a Bayesian estimation algorithm and singular value decomposition algorithms for 80-detector row CT perfusion in patients with acute ischemic stroke. La Radiologia Medica 126: 795–803. [Google Scholar] [CrossRef]
- Idrizi, Olgerta. 2018. The Heteroscedasticity Impact on Actuarial Science: Lee Carter Error Simulation. European Journal of Engineering and Formal Sciences 1: 1–12. [Google Scholar] [CrossRef]
- Jorgensen, Bent. 1987. Exponential dispersion models (with discussion). Journal of the Royal Statistical Society, Series B 49: 127–62. [Google Scholar]
- Jorgensen, Bent. 1997. The Theory of Exponential Dispersion Models. Monographs on Statistics and Probability 76. London: Chapman and Hall. [Google Scholar]
- Kogure, Atsuyuki, Takahiro Fushimi, and Shinichi Kamiya. 2019. Mortality Forecasts for Long-Term Care Subpopulations with Longevity Risk: A Bayesian Approach. North American Actuarial Journal 25: S534–44. [Google Scholar] [CrossRef]
- Lee, D. Ronald, and Lawrence R. Carter. 1992. Modelling and forecasting the time series of US mortality. Journal of the American Statistical Association 87: 659–71. [Google Scholar]
- Légaré, Jacques, Yann Décarie, Kim Deslandes, and Yves Carrière. 2015. Canada’s oldest old: A population group which is fast growing, poorly apprehended and at risk from lack of appropriate services. Population Change and Lifecourse Strategic Knowledge Cluster Discussion Paper Series/Un Réseau Stratégique de Connaissances Changements de Population et Parcours de vie Document de Travail 3: 1. Available online: https://ir.lib.uwo.ca/pclc/vol3/iss2/1 (accessed on 1 April 2021).
- Letac, Gerard, and Marianne Mora. 1990. Natural real exponential families with cubic variance functions. Annals of Statistics 18: 1–37. [Google Scholar] [CrossRef]
- Liu, Zhen, Xiaoqian Sun, Leping Liu, and Yu-Bo Wang. 2020. Bayesian Poisson Log-normal Model with Regularized Time Structure for Mortality Projection of Multi-population. arXiv arXiv:2010.04775. [Google Scholar]
- Njenga, N. Carolyn, and Michael Sherris. 2020. Modeling mortality with a Bayesian vector autoregression. Insurance: Mathematics and Economics 94: 40–57. [Google Scholar] [CrossRef]
- Pedroza, Claudia. 2006. A Bayesian forecasting model: Predicting U.S male mortality. Biostatistics 7: 530–50. [Google Scholar] [CrossRef]
- Renshaw, Arthur, and Steven Haberman. 2008. On simulation-based approaches to risk measurement in mortality with specific reference to Poisson Lee–Carter modelling. Insurance: Mathematics and Economics 42: 797–816. [Google Scholar] [CrossRef] [Green Version]
- Shair, N. Syazreen, Muhammad A. S. Rosmizan, Mohammad J. M. S. Ting, and Mohd A. A. Zaini. 2018. Projected Malaysian Lifetable: Evaluations of The Lee–Carter and Poisson Log-Bilinear Models. International Journal of Modern Trends in Social Sciences 1: 60–72. [Google Scholar]
- Wang, Duolao, and Pengjun Lu. 2005. Modelling and forecasting mortality distributions in England and Wales using the Lee—Carter model. Journal of Applied Statistics 32: 873–85. [Google Scholar] [CrossRef]
- Wong, S. T. Jackie, Jonathan J. Forster, and Peter W. F. Smith. 2018. Bayesian mortality forecasting with overdispersion. Insurance: Mathematics and Economics 83: 206–21. [Google Scholar] [CrossRef] [Green Version]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Awad, Y.; Bar-Lev, S.K.; Makov, U. A New Class of Counting Distributions Embedded in the Lee–Carter Model for Mortality Projections: A Bayesian Approach. Risks 2022, 10, 111. https://doi.org/10.3390/risks10060111
Awad Y, Bar-Lev SK, Makov U. A New Class of Counting Distributions Embedded in the Lee–Carter Model for Mortality Projections: A Bayesian Approach. Risks. 2022; 10(6):111. https://doi.org/10.3390/risks10060111
Chicago/Turabian StyleAwad, Yaser, Shaul K. Bar-Lev, and Udi Makov. 2022. "A New Class of Counting Distributions Embedded in the Lee–Carter Model for Mortality Projections: A Bayesian Approach" Risks 10, no. 6: 111. https://doi.org/10.3390/risks10060111
APA StyleAwad, Y., Bar-Lev, S. K., & Makov, U. (2022). A New Class of Counting Distributions Embedded in the Lee–Carter Model for Mortality Projections: A Bayesian Approach. Risks, 10(6), 111. https://doi.org/10.3390/risks10060111