A stepwise logistic regression was used, utilizing SAS and the data was divided into a ratio of 80 for training to 20 for testing. The coding more stable category was represented by a one “1” whilst the less stable by a zero “0”. The groupings into less stable and more stable is dependent on the agency rating the sovereign credit. The Fitch credit rating agency had data divided into less stable (BBp, BB and BBBn) with 30 observations and more stable (BBB and BBBp) with 50 observations. The Moody’s credit rating had the ratings Baa2 and Baa3 classified into less stable with 41 observations and Baa1 and A3 classified into more stable with 39 observations. The SNPoor credit rating had data divided into less stable (BBp and BBBn) with 36 observations and more stable (BBB and BBBp) with 44 observations. The results are shown in the next subdivisions for Fitch, Moodys, and SNPoors.
4.1.1. Stepwise Logistic Regression Model
A stepwise process of the logistic regression model was fitted on data from Fitch, Moody, and SNPoor with 80% of the observations being the train data and 20% being the test data and the model summary results are shown in
Table 4.
The −2 Log-likelihood (goodness of fit tests) values show how good the model is and higher values of −2logL mean a worse fit scenario for the data.
For Fitch, the model with only the intercept had a value of only 83.591, that with the intercept, and the independent variables had a value of 22.006, which is a decline of 61.585, indicating model improvement due to the addition of explanatory variables. It can be concluded that the addition of explanatory variables led to an improvement in the LR model fit. The R-squared under Cox & Snell R Square was 61.80% whereas the max-rescaled R-square termed Nagelkerke R Square was 84.76%. These values are high signifying a good fit for the model. The R-square values report the explanatory capacity of the respective independent variables in explaining the financial stability index. However, just like the R-square in multiple regression analysis cannot explain the amount of variation accounted for by the model, caution should be taken in using these R-squared values. The model with only the intercept had a value of 88.473 for the Moody data and that, with the intercept and the covariates, had a value of 6.068, which is a decline of 82.405, indicating that the model improved due to the addition of the explanatory variables. The Cox & Snell R Squared value was 72.41% and the max rescaled Nagelkerke R Squared) was 96.67% signifying a very good fit for the model.
The SNPoor under a logistic regression with only the intercept, had a value of 87.72 and that with the intercept and independent variables had a value of 39.832, which is a decline of 47.888 indicating model improvement due to the addition of explanatory variables. It can be concluded that adding explanatory variables resulted in the model fit improving. The Cox & Snell R Squared) was 52.8% and the max rescaled Nagelkerke R Square was 70.61%, these values are high, signifying a good fit for the model. The Moody data set gave the highest Cox & Snell R Squared and the max rescaled Nagelkerke R Square as compared to the other data set giving the best fit as compared to Fitch and Moody and the SNPoor had the lowest.
According to
Hair et al. (
2019), the Hosmer–Lemeshow test compares observed probabilities against predicted probabilities to check whether they are the same, meaning, a classification test of statistical significance on the actual versus the observed and non-significance with a
p-value less than 0.05 (
p-value > 0.05 indicates a well-fitting model. Results from testing the model using the Hoang et al. test are illustrated in
Table 5 below.
For Fitch, Moody, and SNPoor, a non-significant difference between observed and predicted probabilities was observed, indicating a good fit of the models with p-values of 0.4813, 0.9998 and 0.9756 respectively.
The logistics regression results for the data sets are shown in
Table 6.
The fitted model For Fitch is
where CPIH is Consumer Price Index Headline, HDDIR is Household Debt to Disposable Income Ratio and REER is the Real Effective Exchange Rates. At the 5% level of significance, the logistic coefficients for CPIH (−0.1680), HDDIR (0.6456), REER (0.3582), and the constant −61.8897) were all significant. All explanatory variables were significant and can be used to interpret in identifying the relationships impacting the predicted probabilities and subsequently group membership. The coefficient of CPIH was −0.1680, which implies that
=
. A one-unit increase in CPIH is associated with a (
) × 100% = 15.44% decrease in the predicted odds of the quarterly index being more stable. The coefficient of HDDIR was 0.6456, which implies that
=
. A one-unit increase in HDDIR leads to an increase of (1.9071
) × 100% = 90.71% in the predicted odds of the quarterly index being more stable. Thus, a high value of HDDIR is associated with the quarterly index being more stable. The coefficient of REER was 0.3582, which implies that
=
. A one-unit increase in REER leads to an increase of (1.4308
) × 100% = 43.08% in the predicted odds of the quarterly index being more stable. Thus, a high value of REER is associated with the quarterly index being more stable.
The fitted model for the Moody is
where CPIH is Consumer Price Index Headline and HDDIR is Household Debt to Disposable Income ratio. At the 10% level of significance, the logistic regression coefficients for CPIH (−0.9172), HDDIR (2.3015) and the constant (−95.629) were all significant and no other variables were entered into the model. All the variables showed significance at 10% and can be interpreted to identify the relationships affecting the predicted probabilities and subsequently group membership. The coefficient of CPIH was −0.9172, which implies that
=
. A one-unit increase in CPIH is associated with a (
) × 100% = 60.04% decrease in the predicted odds of the quarterly index being more stable. The coefficient of HDDIR was 2.3015, which implies that
=
. A one-unit increase in HDDIR leads to an increase of (9.9892
) × 100% = 898.92 in the predicted odds of the quarterly index being more stable. That is a high value of HDDIR is associated with the quarterly index being more stable.
The fitted model for SNPoor is
where HDDIR is Household Debt to Disposable Income ratio and REER is the Real Effective Exchange Rates. All the logistic coefficients are significant at the 5% level of significance and no other variables entered the model. All the variables in the model are significant at 5% and can be used in the interpretation of identifying the relationships affecting the predicted probabilities and subsequently group membership. The coefficient of HDDIR was 0.1844 which implies that
=
. A one-unit increase in HDDIR leads to an increase of (1.2025
) × 100% = 20.25% in the predicted odds of the quarterly index being more stable. Thus, a high value of HDDIR is associated with the quarterly index being more stable. The coefficient of REER was 0.3062, which implies that
=
. A one-unit increase in REER leads to an increase of (1.3583
) × 100% = 35.83% in the predicted odds of the quarterly index being more stable, thus, a high value of REER is associated with the quarterly index being more stable.
The SNPoor model retained only 2 out of the 9 independent variables, namely, REER and HDDIR. The findings agree with the analysis carried out by (
Mellios and Paget-Blanc 2006;
Chee et al. 2015) and concluded that real effective exchange rates are one of the crucial variables used by rating agencies to determine a country’s creditworthiness. The rest of the variables were insignificant.
From the models, HDDIR, CPIH, and REER were found to be some of the economic variables used by credit rating agencies to measure a country’s solvency and creditworthiness with HDDIR being the variable included in all the models.
The classification table is shown below in
Table 7.
The model sensitivity for Fitch was 92.7%, that is, the fitted model correctly predicted 92.7% of those more stable. The model specificity was 91.3% indicating that it correctly predicted 91.3% for those less stable. Generally, the full model correct classification was 92.2%. The percentage of correct predictions is known as the ‘HIT’ ratio and in this case, a value of 92.2% indicates good prediction. For Moody, the sensitivity and specificity values were 97.1% and 93.3%, respectively; thus, 97.1% correctly predicted those more stable, and 93.3% correctly predicted those less stable. The hit ratio was 95.3%, that is, the percentage of correct predictions was 95.3%, which is a very good fit. The sensitivity and specificity values for SNPoor were 83.3% and 89.3%, respectively; thus, 83.3% correctly predicted those more stable, and 89.3% correctly predicted those less stable. The hit ratio was 85.9%, that is, the percentage of correct predictions was 85.9% which is a very good fit. Looking at the classifications, for Fitch, only 7.8% were incorrectly specified, while for Moody 4.7% were incorrectly specified and SNPoor had 14.1% incorrectly specified. The Moody Model had the highest correctly predicted as compared to the other models with SNPoor having the lowest, even though, those correctly predicted were above 85%, signifying a good model fit.
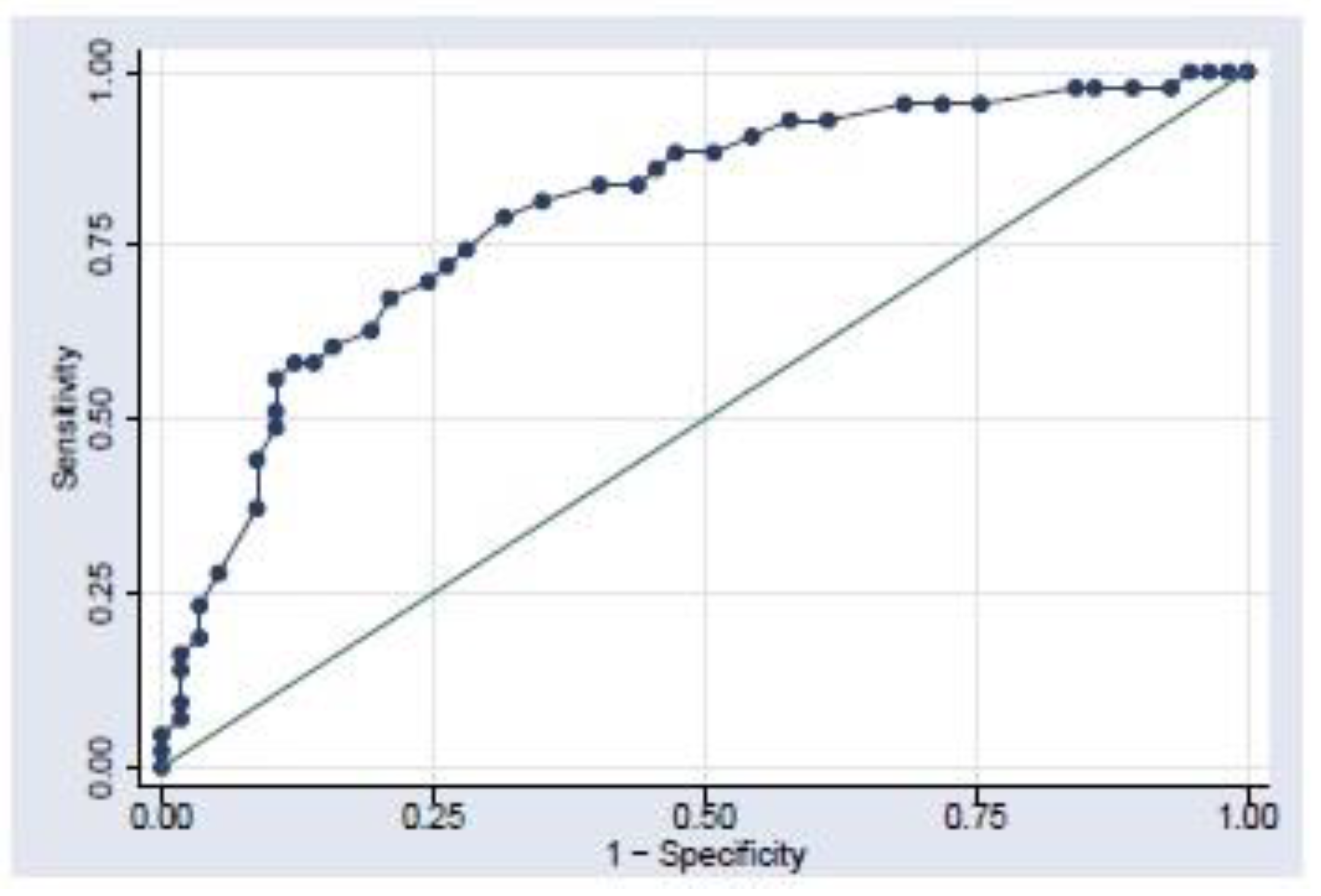
The validation of the logistic model was carried out by comparing the Receiver Operating Characteristic (ROC) curve. These curves for the models are shown in
Appendix A. According to
Hair et al. (
2019, p. 568), the “ROC curve was developed to provide a graphical representation of the trade-off across the entire range of cut-off values, and it shows how well a model simultaneously predicts both positives and negatives”. The area that falls under the curve (AUC), provides a value between 1 (perfect prediction) and 0.5 (a test of no difference from random chance) which is represented by the diagonal line, therefore, the far the curve is above the diagonal line, the better the fit. The fitch model train data set had an AUC of 0.9767 while the test data set had an AUC of 0.9841. Both the train data and the test data produced good predictive accuracy although the train data had the better predictive accuracy. The Moody model train data had an AUC of 0.998 while the test data had an AUC of 1.00. Both the train data and the test data produced good predictive accuracy although the test data had the better predictive accuracy, the test data correctly predicted all the indexes into their groups. Lastly, the SNPoor train data had an AUC of 0.9335 while the test data had an AUC of 0.9531, both the train data and the test data produced good predictive accuracy, although the test data had the better predictive accuracy. All the observations were correctly specified into more stable and less stable, respectively, in the test model.
The logistic regression model managed to capture and analyze sovereign credit ratings from Fitch, Moody’s, and SNPoors. The logistic regression model pointed out that CRAs’ use economic indicators like HDDIR, CPIH, REER in rating sovereigns. The variables prevalent on Fitch were REER, HDDIR, and CPIH, on Moody’s were HDDIR and CPIH and lastly on SNPoors were REER and HDDIR. The most outstanding variable was HDDIR, which Logistic regression highlighted as used by all CRAs.







{kind=link}
{kind=link}