For our purposes, given
, the conditional variable
can be written as,
where the coefficients
are now functions of realization
. Equation (
13), for large
m-values, holds for any
, particularly also for large
. As such the scheme can be interpreted as an
almost exact simulation scheme for an SDE under consideration. By the scheme in (
13) we can thus take large time steps in a highly accurate discretization scheme. More specifically, a sample from the known distribution
X can be mapped onto a corresponding unique sample of the conditional distribution
by the coefficient functions.
There are essentially two possibilities for using an ANN in the framework of the stochastic collocation method, the first being to directly learn the (time-dependent) polynomial coefficients,
, in (
13), the second to learn the collocation points,
. The two methods are equivalent mathematically, but the latter, our method of choice, appears more stable and flexible. Here, we explain how to learn the collocation points,
, which is then followed by inferring the polynomial coefficients. When the stochastic collocation points at time
are known, the coefficients in (
13) can be easily computed.
An SDE solution is represented by its cumulative distribution at the collocation points, plus a suitable accurate interpolation . In other words, the SCMC method forces the distribution functions (the target and the numerical approximation) to strictly match at the collocation points over time. The collocation points are dynamic and evolve with time.
3.1. Data-Driven Numerical Schemes
Calculating the conditional distribution function requires generating samples conditionally on previous realizations of the stochastic process. Based on a general polynomial expression, the conditional sample, in discrete form, is defined as follows,
where
, and the coefficients
, at time
, are functions of the variables
, see Equations (
6) and (
7).
In the case of a Markov process, the future does not dependent on past values. Given , the random variable only depends on the increment . The process has independent increments, and the conditional distribution at time given information up to time only depends on the information at .
Similar to these coefficient functions, the
m conditional stochastic collocation points at time
,
, with
, can be written as a functional relation,
A closed-form expression for function is generally not available. Finding the conditional collocation points can however be formulated as a regression problem.
It is well-known that neural networks can be utilized as universal function approximators (
Cybenko 1989). We then generate random data points in the domain of interest and the ANN should “learn the mapping function
”, in an offline ANN training stage. The SCMC method is here used to compute the corresponding collocation points at each time point, which are then stored to train the ANN, in a supervised learning fashion (see, for example,
Goodfellow et al. 2016).
3.2. The Seven-League Scheme
Next, we detail the generation of the stochastic collocation points to create the training data. Consider a stochastic process
,
, where
represents the maximum time horizon for the process that we wish to sample from. When the analytical solution of the SDE is not available (and we cannot use an exact simulation scheme with large time steps), a classical numerical scheme will be employed, based on
tiny constant time increments , a discretization in the time-wise direction with grid points
, to generate a sufficient number of highly accurate samples at each time point
, to approximate the corresponding cumulative functions highly accurately. Note that the training samples are generated with a fixed time discretization, and in the case of a Markov process, one can easily obtain discrete values for the underlying stochastic process for many possible time increments, e.g.,
,
. With the obtained samples, we approximate the corresponding marginal collocation points at time
, as follows,
where, with integer
,
,
, represent the approximate collocation points of
at time
, and
are optimal collocation points of variable
X. For simplicity, consider
, so that the points
are known analytically and do not depend on time point
. In the case of a normal distribution, these points are known quadrature points, and tabulated, for example, in (
Grzelak et al. 2019). After this first step, we have the set of collocation points,
, for
and
. Subsequently, the
from (
16) are used as the ground-truth to train the ANN.
In the second step, we determine the
conditional collocation points. For each time step
and collocation point indexed by
j, a
nested Monte Carlo simulation is then performed to generate the conditional samples. Similar to the first step, we obtain the conditional collocation points from each of these sub-simulations using (
16). With
being an integer representing the number of conditional collocation points, the above process yields the following set of
conditional collocation points,
where
is a conditional collocation point, and
,
,
. Note that, in the case of Markov processes, the above generic procedure can be simplified by just varying the initial value
instead of running a nested Monte Carlo simulation. Specifically, we then set
,
and
to generate the corresponding conditional collocation points.
The inverse function,
, is often not known analytically, and needs to be derived numerically. An efficient procedure for this is presented in (
Grzelak 2019). Of course, it is well-known that the computation of
is equivalent to the computation of the quantile at level
p.
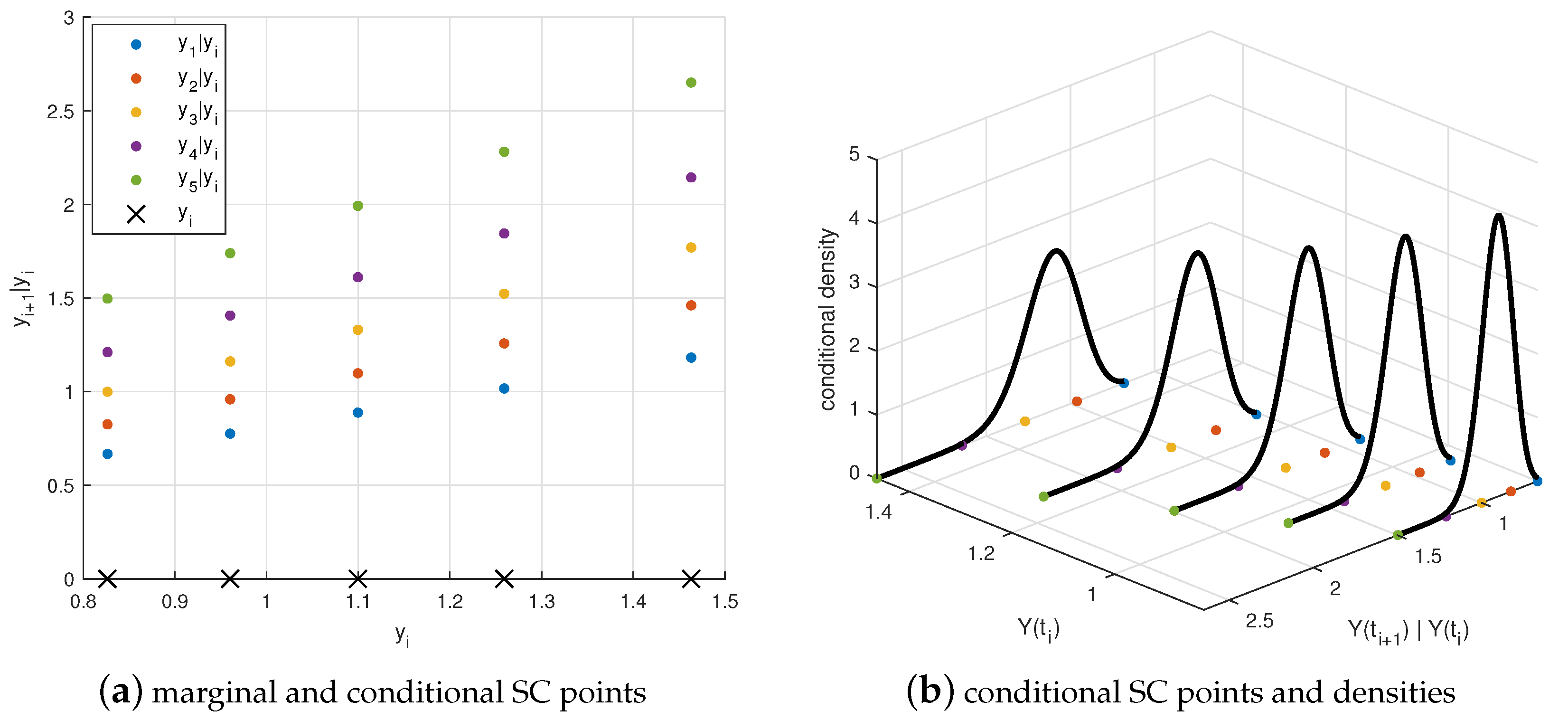
We encounter essentially four types of stochastic collocation (SC) points:
are called the original SC points,
are original conditional collocation points,
are the marginal SC points, and
are the conditional SC points. For example,
is conditional on a realization
. In the context of Markov processes, the marginal SC points
only depend on the initial value
, thus they are a special type of conditional collocation points, i.e.,
. When a previous realization happens to be a collocation point, e.g.,
, we have
, which will be used to develop a variation of the 7L scheme in
Section 4.
When the data generation is completed, the ANNs are trained in a supervised-learning fashion, on the generated SC points to approximate the function
H in (
15), giving us a learned function
. This is called the training phase. With the trained ANNs, we can approximate new collocation points, and develop a numerical solver for SDEs, which is the Seven-League scheme (7L), see Algorithm 2.
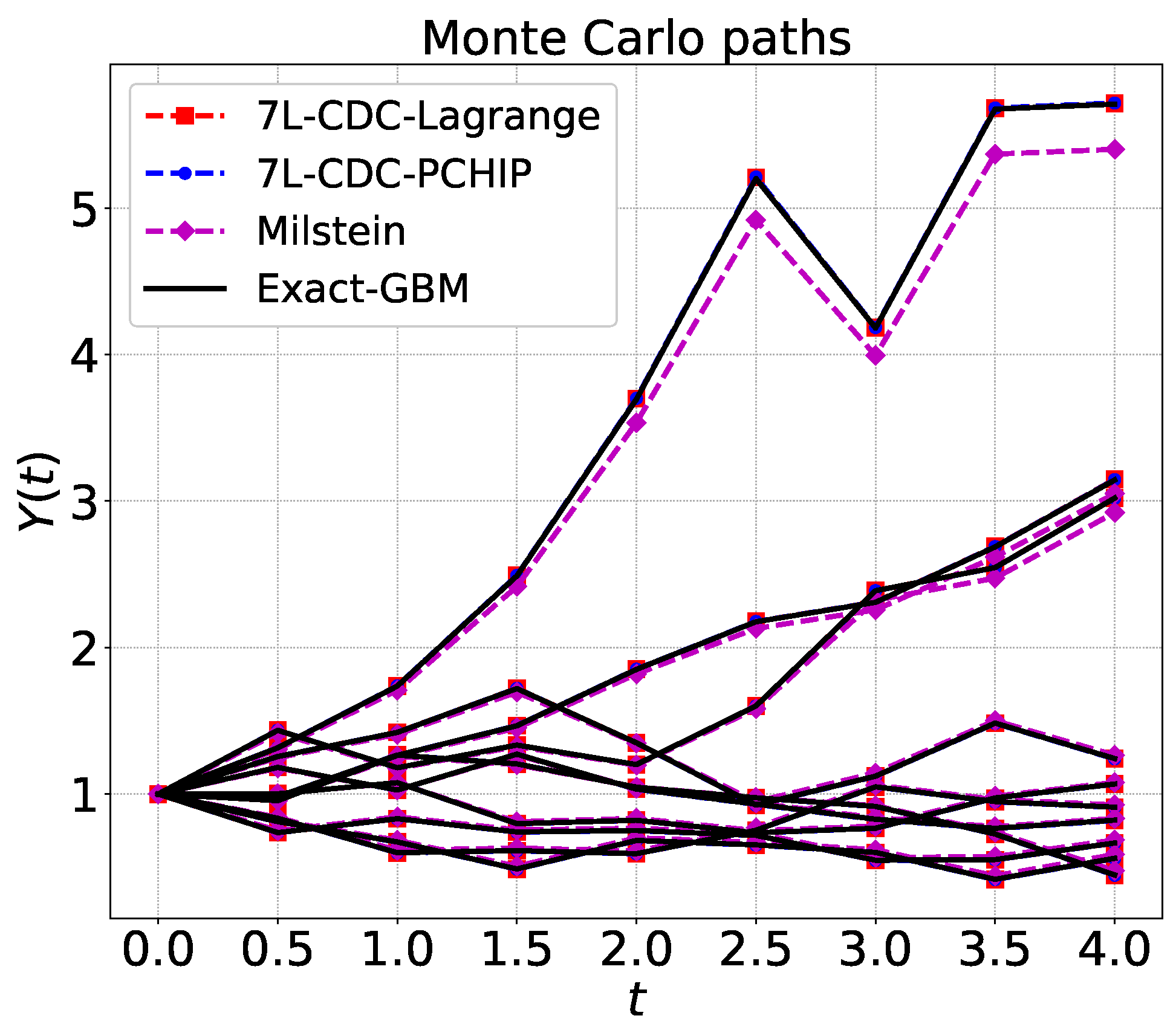
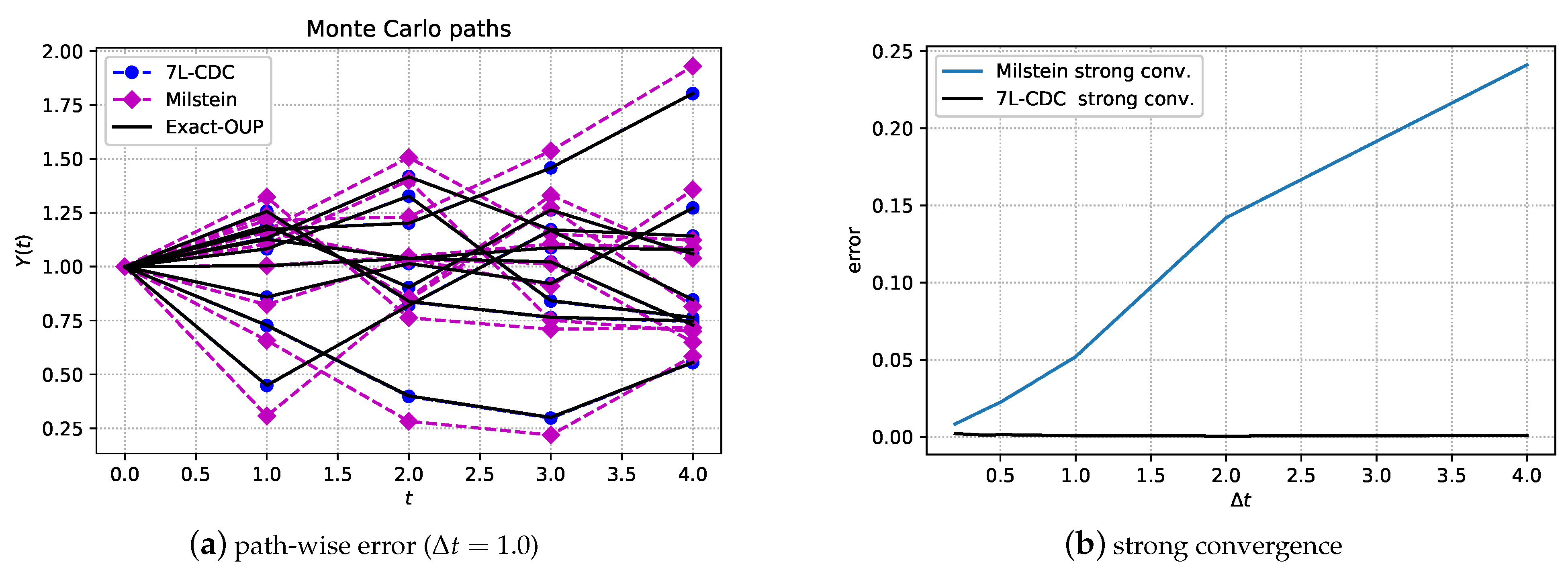
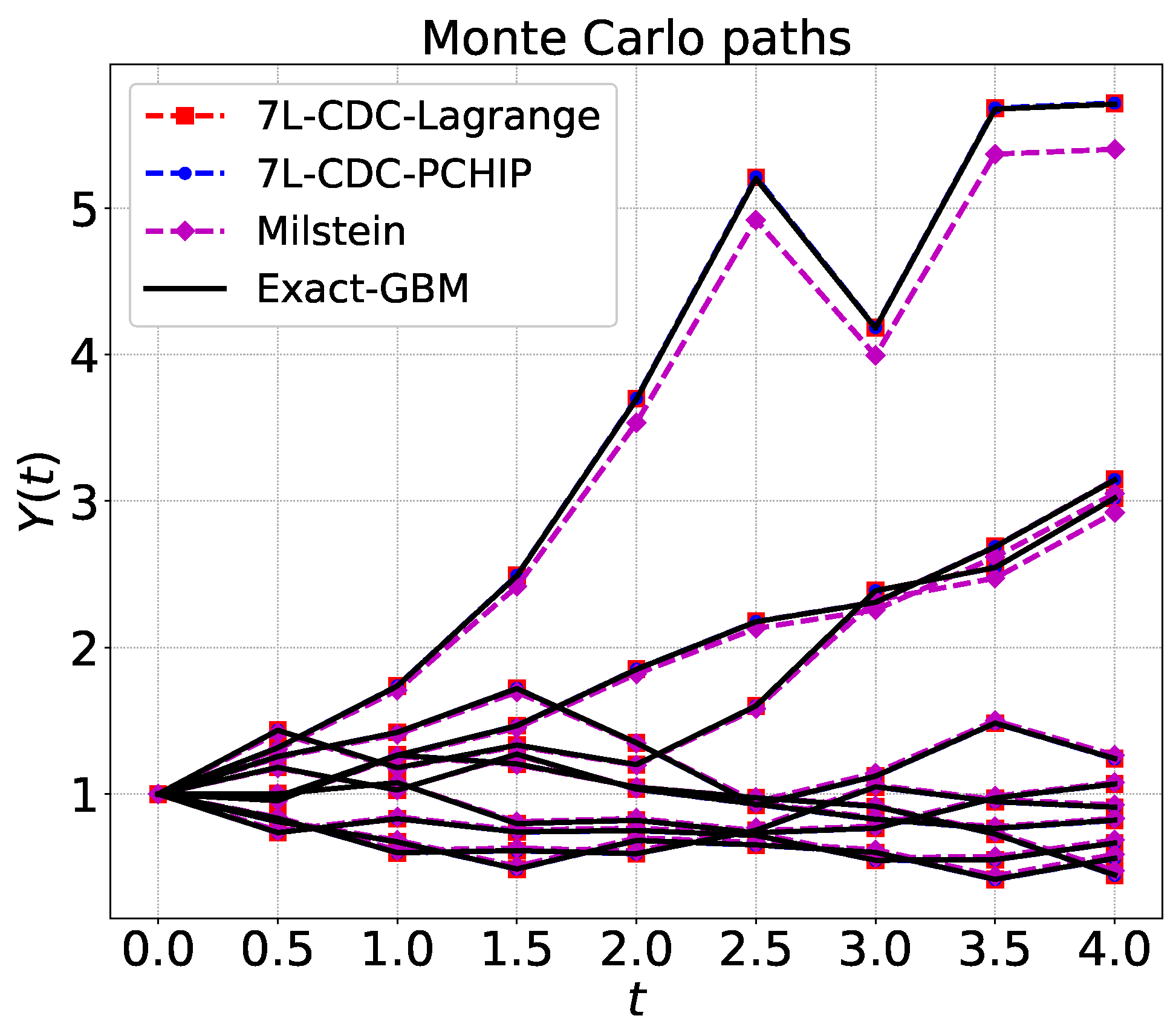
Figure 1 gives a schematic illustration of Monte Carlo sample paths that are generated by the 7L scheme.
| Algorithm 2: 7L Scheme |
Offline stage: train the ANNs to learn the stochastic collocation points. At this stage, we choose different values, simulate corresponding Monte Carlo paths, with small constant time increments in , generate the and collocation points, and learn the relation between input and output. So, we actually “learn” . See Section 3.3 for the ANN details. Online stage: Partition time interval , with equidistant time step . Given a sample at time , compute m collocation points at time using
and form a vector . Compute the interpolation function , or calculate the coefficients (if necessary):
where A is the corresponding matrix (e.g., the Vandermonde matrix in a polynomial interpolation) and more details on the computation of the original collocation points can be found in Algorithm 1. We will compare monotonic spline, Chebyshev, and the barycentric formulation of Lagrange interpolation for this purpose. See Section 4.2 for a detailed discussion. Sample from X and obtain a sample in the next time point, , by , or the coefficient form as follows,
Return to Step 2 by , iterate until terminal time T. Repeat this procedure for a number of Monte Carlo paths.
|
Remark 1 (Lagrange interpolation issue)
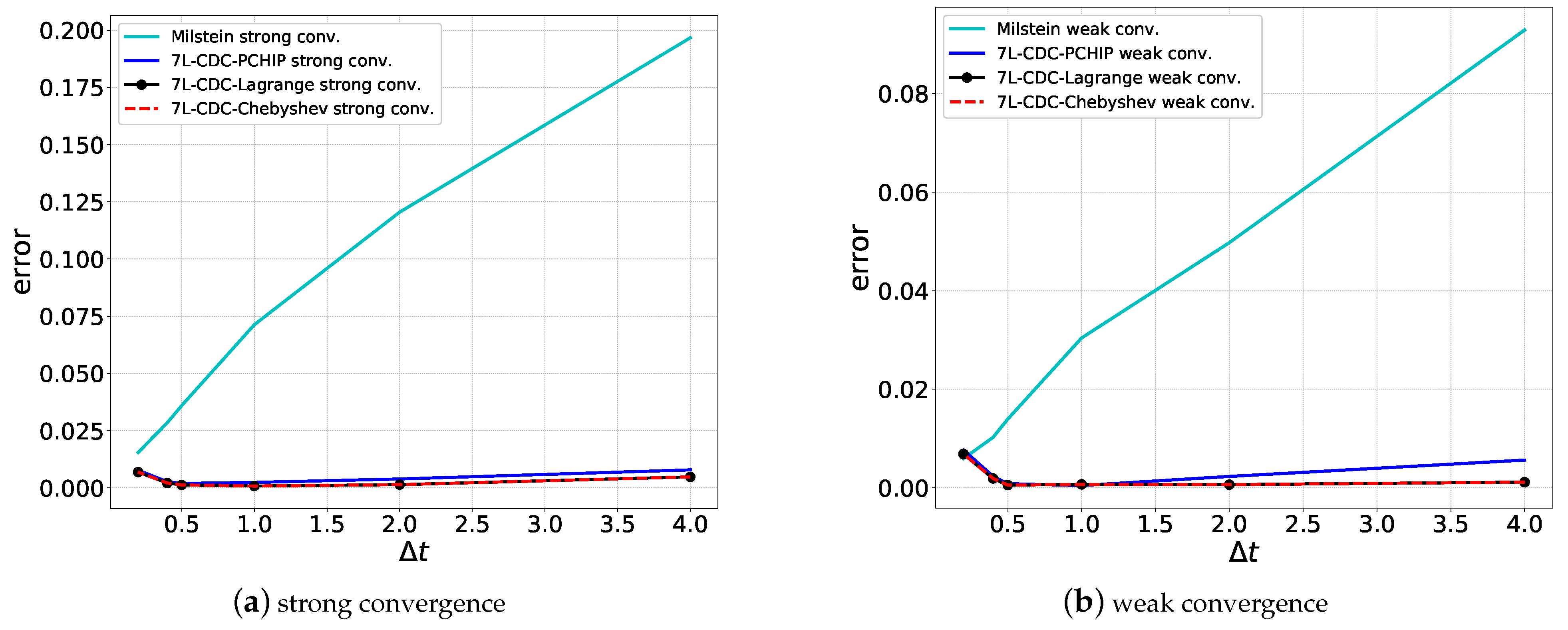
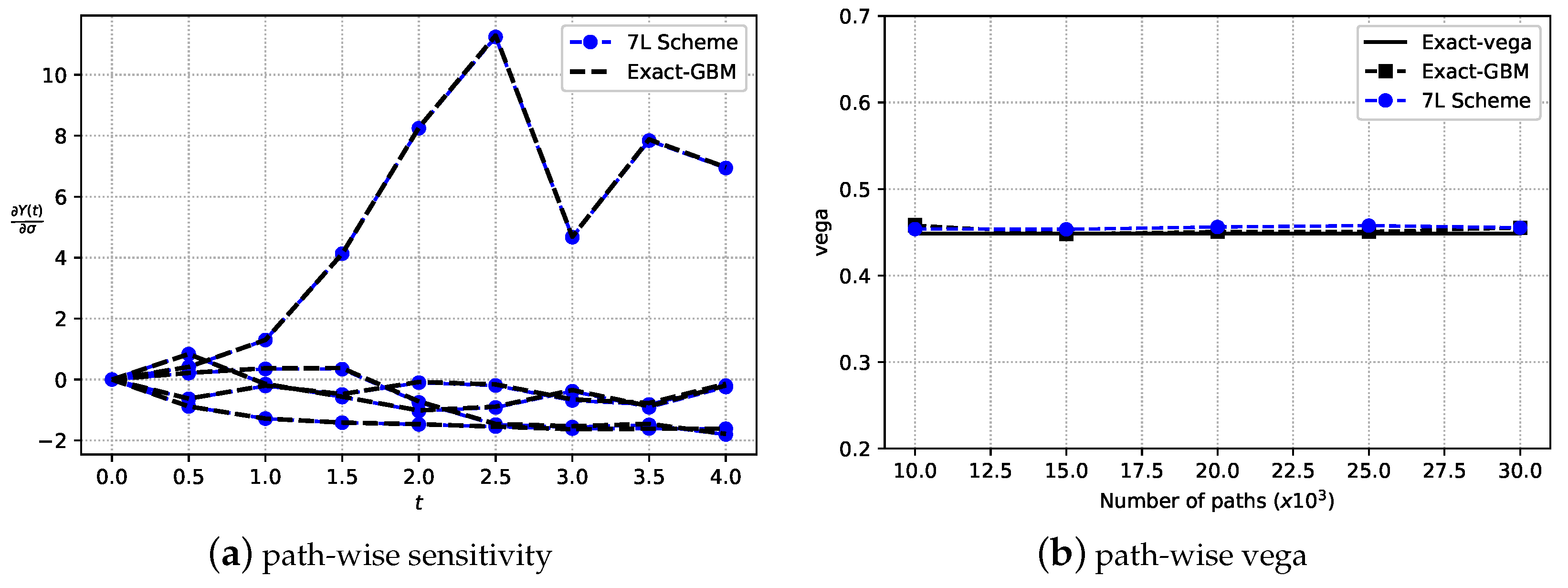
. In the case of classical Lagrange interpolation, Vandermonde matrix A should not get too large, as the matrix would then suffer from ill-conditioning. However, when employing orthogonal polynomials, this drawback is removed. More details can be found in Grzelak et al. (2019). When the approximation errors from the ANN and SCMC techniques are sufficiently small, the strong convergence properties of the 7L scheme can be estimated, as follows,
where time step
is used to define the ANN training data-set, and the actual time step
is used for ANN prediction, with
. Based on the trained 7L scheme, the strong error,
, thus, does not grow with the actual time step
. In particular, let us assume
, for example
, when employing the Euler–Maruyama scheme with time step
during the ANN learning phase, we expect a strong convergence of
, which then equals
, while the use of the Milstein scheme during training would result in
accuracy. When
, the time step during the learning phase is 100 times smaller than
, which has a corresponding effect on the overall scheme’s accuracy in terms of its strong, pathwise convergence.
The maximum value of the time step in the 7L scheme can be set up to for a Markov process. With a time step
, we solve the SDE in an iterative way until the actual terminal time
T, which can be much larger than the training time horizon
. An error analysis can be found in
Section 5.2.
3.3. The Artificial Neural Network
The ANN to learn the conditional collocation points is detailed in this subsection. Neural networks can be utilized as powerful functions to approximate a nonlinear relationship. In fact, we will employ a rather basic fully-connected neural network configuration for our learning task.
A fully connected neural network, without skip connections, can be described as a composition function, i.e.,
where
represents the input variables,
being the hidden parameters (i.e., weights and biases),
the number of hidden layers. We can expand the hidden parameters as,
where
and
represent the weight matrix and the bias vector, respectively, in the
ℓ-th hidden layer.
Each hidden-layer function, , takes input signals from the output of a previous layer, computes an inner product of weights and inputs, and adds a bias. It sends the resulting value in an activation function to generate the output.
Let
denote the output of the
j-th neuron in the
ℓ-th layer. Then,
where
,
, and
is a nonlinear transfer function (i.e., activation function). With a specific configuration, including the architecture, the hidden parameters, activation functions, and other specific operations (e.g., drop out), the ANN in (
21) becomes a deterministic, complicated, composite function.
Supervised machine learning (
Goodfellow et al. 2016) is used here to determine the weights and biases, where the ANN should learn the mapping from a given input to a given output, so that for a new input, the corresponding output will be accurately approximated. Such ANN methodology consists of basically two phases. During the (time-consuming, but offline) training phase the ANN learns the mapping, with many in- and output samples, while in the testing phase, the trained model is used to very rapidly approximate new output values for other parameter sets, in the online stage.
In a supervised learning context, the loss function measures the distance between the target function and the function implied by the ANN. During the training phase, there are many known data samples available, which are represented by input-output pairs
. With a user-defined loss function
, training neural networks is formulated as
where the hidden parameters are estimated to approximate the function of interest in a certain norm. More specifically, in our case, the input,
, equals
, and the output,
, represents the collocation points
, as in Equation (
18). In the domain of interest
, we have a collection of data points
,
, and their corresponding collocation points
, which form a vector of input-output pairs
. For example, using the
-norm, the discrete form of the loss function reads,
One of the popular approaches for training ANNs is to optimize the hidden parameters via backpropagation, for instance, using stochastic gradient descent (
Goodfellow et al. 2016).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}