
Effects of Anonymity versus Examinee Name on a Measure of Depressive Symptoms in Adolescents

 , , , ,
, , , , 
Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Instruments
2.3. Ethical Considerations
2.4. Procedure
2.5. Data Analysis
3. Results
3.1. Equivalence between Groups
3.2. Univariate Analysis
3.2.1. Items Level
3.2.2. Score Level
3.3. Internal Structure
3.3.1. Dimensionality
3.3.2. Differential Item Functioning: Anonymity vs. Examinee Name
3.3.3. Reliability
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Perinelli, E.; Gremigni, P. Use of social desirability scales in clinical psychology: A systematic review. J. Clin. Psychol. 2016, 72, 534–551. [Google Scholar] [CrossRef] [PubMed]
- van de Mortel, T.F. Faking it: Social desirability response bias in self-report research. Aust. J. Adv. Nurs. 2008, 25, 40–48. [Google Scholar]
- Whelan, T.J. Anonymity and confidentiality: Do survey respondents know the difference? In Proceedings of the 30th Annual Meeting of the Society of Southeastern Social Psychologists, Durham, NC, USA, 26–27 October 2007. [Google Scholar]
- Ash, P.; Abramson, E. The effect of anonymity on attitude-questionnaire response. J. Abnorm. Soc. Psychol. 1952, 47, 722–723. [Google Scholar] [CrossRef] [PubMed]
- Kraus, J. Effect of anonymity on response of adoptive parents to a child-problems questionnaire. Aust. Soc. Work 1975, 28, 37–39. [Google Scholar] [CrossRef]
- Rosen, N.A. Anonymity and Attitude Measurement. Public Opin. Q. 1960, 24, 675–679. [Google Scholar] [CrossRef]
- Lelkes, Y.; Krosnick, J.A.; Marx, D.M.; Judd, C.M.; Park, B. Complete anonymity compromises the accuracy of self-reports. J. Exp. Soc. Psychol. 2012, 48, 1291–1299. [Google Scholar] [CrossRef]
- Beatty, J.R.; Chase, S.K.; Ondersma, S.J. A randomized study of the effect of anonymity, quasi-anonymity, and certificates of confidentiality on postpartum women’s disclosure of sensitive information. Drug Alcohol Depend. 2014, 134, 280–284. [Google Scholar] [CrossRef]
- Caballero, R.; Sen, S.; Nygård, J.F. Anticipating anonymity in screening program databases. Int. J. Med. Inform. 2017, 103, 20–31. [Google Scholar] [CrossRef]
- Durant, L.E.; Carey, M.P.; Schroder, K.E. Effects of anonymity, gender, and erotophilia on the quality of data obtained from self-reports of socially sensitive behaviors. J. Behav. Med. 2002, 25, 438–467. [Google Scholar] [CrossRef]
- O’Malley, P.M.; Johnston, L.D.; Bachman, J.G.; Schulenberg, J. A Comparison of confidential versus anonymous survey procedures: Effects on reporting of drug use and related attitudes and beliefs in a national study of students. J. Drug Issues 2000, 30, 35–54. [Google Scholar] [CrossRef]
- Ong, A.D.; Weiss, D.J. The impact of anonymity on responses to sensitive questions. J. Appl. Soc. Psychol. 2000, 30, 1691–1708. [Google Scholar] [CrossRef]
- Meade, A.W.; Craig, S.B. Identifying careless responses in survey data. Psychol. Methods 2012, 17, 437–455. [Google Scholar] [CrossRef] [PubMed]
- Schneider, S.; May, M.; Stone, A.A. Careless responding in internet-based quality of life assessments. Qual. Life Res. 2018, 27, 1077–1088. [Google Scholar] [CrossRef] [PubMed]
- Ward, M.K.; Meade, A.W. Applying social psychology to prevent careless responding during online surveys. Appl. Psychol. 2018, 67, 231–263. [Google Scholar] [CrossRef]
- Martínez, I.M.M. Efectos del anonimato en la comunicación de grupos que utilizan tecnologías asistidas por ordenador. Un estudio cuantitativo y cualitativo. An. Psicol. Ann. Psychol. 2001, 17, 121–128. [Google Scholar]
- Matthey, S.; Petrovski, P. The children’s depression inventory: Error in cutoff scores for screening purposes. Psychol. Assess. 2002, 14, 146–149. [Google Scholar] [CrossRef]
- National Institute of Mental Health. Major Depression among Adolescents; National Institute of Mental Health: Bethesda, MD, USA, 2016.
- Bould, H.; Araya, R.; Pearson, R.M.; Stapinski, L.; Carnegie, R.; Joinson, C. Association between early temperament and depression at 18 years. Depress. Anxiety 2014, 31, 729–736. [Google Scholar] [CrossRef]
- Garber, J.; Brunwasser, S.M.; Zerr, A.A.; Schwartz, K.T.; Sova, K.; Weersing, V.R. Treatment and prevention of depression and anxiety in youth: Test of cross-over effects. Depress. Anxiety 2016, 33, 939–959. [Google Scholar] [CrossRef]
- Emons, W.H.; Sijtsma, K.; Meijer, R.R. On the consistency of individual classification using short scales. Psychol. Methods 2007, 12, 105–120. [Google Scholar] [CrossRef]
- Kruyen, P.M.; Emons, W.H.M.; Sijtsma, K. Test length and decision quality in personnel selection: When is short too short? Int. J. Test. 2012, 12, 321–344. [Google Scholar] [CrossRef]
- Kruyen, P.M.; Emons, W.H.M.; Sijtsma, K. On the shortcomings of shortened tests: A literature review. Int. J. Test. 2013, 13, 223–248. [Google Scholar] [CrossRef]
- Kruyen, P.M.; Emons, W.H.M.; Sijtsma, K. Assessing individual change using short tests and questionnaires. Appl. Psychol. Meas. 2014, 38, 201–216. [Google Scholar] [CrossRef]
- Ziegler, M.; Kemper, C.; Kruyen, P. Short scales—five misunderstandings and ways to overcome them. J. Individ. Differ. 2014, 35, 185–189. [Google Scholar] [CrossRef]
- Kovacs, M. The children’s depression inventory (CDI). Psychopharmacol. Bull. 1985, 21, 995–998. [Google Scholar] [PubMed]
- Volpe, R.J.; DuPaul, G.J. Assessment with brief behavior rating scales. In Handbook of Psychoeducational Assessment: Ability, Achievement, and Behavior in Children; Andrews, J., Janzen, H., Saklofske, D., Eds.; Academic Press: San Diego, CA, USA, 2001; pp. 357–387. [Google Scholar]
- Ailey, S.H.; Marks, B.; Heller, T. Evaluation of two self-report depression measures for adults with Down syndrome. NADD Bull. 2003, 5, 71–75. [Google Scholar]
- de la Vega, R.; Racine, M.; Sánchez-Rodríguez, E.; Solé, E.; Castarlenas, E.; Jensen, M.P.; Engel, J.; Miró, J. Psychometric properties of the short form of the Children’s Depression Inventory (CDI-S) in young people with physical disabilities. J. Psychosom. Res. 2016, 90, 57–61. [Google Scholar] [CrossRef]
- Davanzo, P.; Kerwin, L.; Nikore, V.; Esparza, C.; Forness, S.; Murrelle, L. Spanish translation and reliability testing of the Child Depression Inventory. Child Psychiatry Hum. Dev. 2004, 35, 75–92. [Google Scholar] [CrossRef]
- Holden, R.R.; Magruder, C.D.; Stein, S.J.; Sitarenios, G.; Sheldon, S. The effects of anonymity on the holden psychological screening inventory. Pers. Individ. Differ. 1999, 27, 737–742. [Google Scholar] [CrossRef]
- Sloan, D.M.; Marx, B.P.; Epstein, E.M.; Lexington, J.M. Does altering the writing instructions influence outcome associated with written disclosure? Behav. Ther. 2007, 38, 155–168. [Google Scholar] [CrossRef]
- Sitarenios, G.; Kovacs, M. Use of the children’s depression inventory. In The Use of Psychological Testing for Treatment Planning and Outcomes Assessment; Maruish, M.E., Ed.; Lawrence Erlbaum Associates Publishers: Mahwah, NJ, USA, 1999; pp. 267–298. [Google Scholar]
- del Barrio, V.; Roa, M.L.; Olmedo, M.; Colodrón, F. Primera adaptación del CDI- S en población española. Acción Psicol. 2002, 3, 263–272. [Google Scholar] [CrossRef]
- Sociedad Mexicana de Psicología. Código Ético del Psicólogo [Ethical Code of the Psychologist]; Trillas: Ciudad de México, Mexico, 2010. [Google Scholar]
- American Psychological Association. Ethical Principles of Psychologists and Code of Conduct. With the 2016 Amendment to Standard 3.04; American Psychological Association: Washington, DC, USA, 2017. [Google Scholar]
- World Medical Association. World Medical Association Declaration of Helsinki: Ethical principles for medical research involving human subjects. JAMA 2013, 310, 2191–2194. [Google Scholar] [CrossRef] [PubMed]
- Kolmogorov, A. Sulla determinazione empirica di una legge di distribuzione. Inst. Ital. Attuari, Giorn. 1933, 4, 83–91. [Google Scholar] [CrossRef][Green Version]
- Smirnov, N.V. Estimate of deviation between empirical distributions functions in two independent samples. Bull. Mosc. Univ. 1939, 2, 3–16. [Google Scholar]
- Bradley, E.L. Overlapping coefficient. In Encyclopedia of Statistical Sciences; Kotz, E.S., Johnson, N.L., Read, C.B., Eds.; Wiley: New York, NY, USA, 1985; pp. 546–547. [Google Scholar]
- Golsdtein, R. The overlapping coefficient and an “improved” rank-sum statistic. Stata Techical Bull. 1994, 22, 12–15. [Google Scholar]
- Satorra, A.; Bentler, P.M. Corrections to test statistics and standard errors in covariance structure analysis. In Latent Variables Analysis: Applications for Developmental Research; von Eye, A., Clogg, C.C., Eds.; Sage: Thousand Oaks, CA, USA, 1994; pp. 399–419. [Google Scholar]
- Boomsma, A. Reporting analyses of covariance structures. Struct. Equ. Model. 2000, 7, 461–483. [Google Scholar] [CrossRef]
- Lei, P.-W.; Wu, Q. Estimation in structural equation modeling. In Handbook of Structural Equation Modeling; Hoyle, R.H., Ed.; Guilford Press: New York, NY, USA, 2012; pp. 164–179. [Google Scholar]
- Tong, X.; Bentler, P.M. Evaluation of a new mean scaled and moment adjusted test statistic for SEM. Struct. Equ. Modeling 2013, 20, 148–156. [Google Scholar] [CrossRef]
- Lorenzo-Seva, U.; ten Berge, J.M.F. Tucker’s congruence coefficient as a meaningful index of factor similarity. Methodology 2006, 2, 57–64. [Google Scholar] [CrossRef]
- Elosua, P.; Wells, C. Detecting DIF in polytomous items using MACS, IRT and ordinal logistic regression. Psicológica 2013, 34, 327–342. [Google Scholar]
- Zumbo, B.D. A Handbook on the Theory and Methods of Differential Item Functioning (DIF): Logistic Regression Modeling as a Unitary Framework for Binary and Likert-Type (Ordinal) Item Scores; Directorate of Human Resources Research and Evaluation, Department of National Defense, Sociedad Mexicana de Psicología: Ottawa, ON, Canada, 1999. [Google Scholar]
- Crane, P.K.; Gibbons, L.E.; Jolley, L.; van Belle, G. Differential item functioning analysis with ordinal logistic regression techniques. DIFdetect and difwithpar. Med. Care 2006, 44, S115–S123. [Google Scholar] [CrossRef]
- Crane, P.K.; Gibbons, L.E.; Narasimhalu, K.; Lai, J.S.; Cella, D. Rapid detection of differential item functioning in assessments of health-related quality of life: The functional assessment of cancer therapy. Qual. Life Res. 2007, 16, 101–114. [Google Scholar] [CrossRef]
- Crane, P.K.; van Belle, G.; Larson, E.B. Test bias in a cognitive test: Differential item functioning in the CASI. Stat. Med. 2004, 23, 241–256. [Google Scholar] [CrossRef]
- Cronbach, L.J. Coefficient alpha and the internal structure of tests. Psychometrika 1951, 16, 297–334. [Google Scholar] [CrossRef]
- McDonald, R.P. Test Theory: A Unified Treatment; Lawrence Erlbaum Associates Publishers: Hillsdale, NJ, USA, 1999. [Google Scholar]
- Merino-Soto, C.; Dominguez-Lara, S. Respuesta a carta al editor. Diferenciando la espada de la mano. Rev. Latinoam. Cienc. Soc. Niñez Juv. 2017, 15, 629–631. [Google Scholar]
- Weber, R.; Popova, L. Testing equivalence in communication research: Theory and Application. Commun. Methods Meas. 2012, 6, 190–213. [Google Scholar] [CrossRef]
- Coe, R.; Soto, C.M. Magnitud del efecto: Una guía para investigadores y usuarios. Rev. Psicol. 2003, 21, 147–177. [Google Scholar] [CrossRef]
- Levene, H. Robust tests for equality of variances. In Contributions to Probability and Statistics: Essays in Honor of Harold Hotelling; Olkin, I., Ghurye, S.G., Hoeffding, W., Madow, W.G., Mann, H.B., Eds.; Stanford University Press: Menlo Park, CA, USA, 1960; pp. 278–292. [Google Scholar]
- Merino-Soto, C. Diferencias entre coeficientes alfa de Cronbach, con muestras y partes pequeñas: Un programa VB. An. Psicol. 2016, 32, 587–588. [Google Scholar] [CrossRef]
- Vargas-Halabi, T.; Mora-Esquivel, R. Sample sizes using structural equation modeling with latent variables: A practical method. Rev. Actual. Investig. Educ. 2017, 17, 25–60. [Google Scholar] [CrossRef]
- MacCallum, R.C.; Browne, M.W.; Sugawara, H.M. Power analysis and determination of sample size for covariance structure modeling. Psychol. Methods 1996, 1, 130–149. [Google Scholar] [CrossRef]
- MacCallum, R.; Lee, T.; Browne, M.W. The issue of isopower in power analysis for tests of structural equation models. Struct. Equ. Model. 2010, 17, 23–41. [Google Scholar] [CrossRef]
- Mundfrom, D.J.; Shaw, D.G.; Ke, T.L. Minimum sample size recommendations for conducting factor analyses. Int. J. Test. 2005, 5, 159–168. [Google Scholar] [CrossRef]
- Wolf, E.J.; Harrington, K.M.; Clark, S.L.; Miller, M.W. Sample size requirements for structural equation models: An evaluation of power, bias, and solution propriety. Educ. Psychol. Meas. 2013, 76, 913–934. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
| N | % | |
|---|---|---|
| Sex | ||
| Male | 99 | 50.5 |
| Female | 97 | 49.5 |
| Place of birth | ||
| Lima | 165 | 84.2 |
| Other | 31 | 15.8 |
| Family structure | ||
| I live with both parents | 122 | 62.2 |
| I live with one of my parents | 60 | 30.6 |
| I live with other people | 14 | 7.1 |
| Mother’s (father’s) education | ||
| Less than high school | 30 (25) | 15.3 (12.8) |
| Completed high school | 91 (81) | 46.4 (41.3) |
| Technical education (1 to 2 years) | 20 (13) | 10.2 (10.2) |
| Technical (3 years) | 10 (45) | 5.1 (6.6) |
| University | 41 (12) | 20.9 (23.0) |
| No information | 4.0 (2.0) | 2.0 (6.1) |
| Item | Descriptive Statistics | CFA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| M | 95% CI | SD | g1 | g2 | ritc | Floor | Ceiling | λ | h2 | |
| Group A (anonymous) | ||||||||||
| Item 1 | 0.094 | [0.01; 0.18] | 0.353 | 4.032 | 16.751 | 0.43 | 92.5 | 1.90 | 0.740 | 0.548 |
| Item 2 | 0.509 | [0.38; 0.64] | 0.521 | 0.168 | −1.51 | 0.396 | 50 | 0.90 | 0.604 | 0.365 |
| Item 3 | 0.179 | [0.08; 0.28] | 0.385 | 1.697 | 0.895 | 0.455 | 82.1 | 0.00 | 0.722 | 0.521 |
| Item 4 | 0.17 | [0.07; 0.27] | 0.402 | 2.224 | 4.229 | 0.496 | 84 | 0.90 | 0.792 | 0.628 |
| Item 5 | 0.094 | [0.01: 0.18] | 0.353 | 4.032 | 16.751 | 0.489 | 92.5 | 1.90 | 0.824 | 0.679 |
| Item 6 | 0.557 | [0.37: 0.74] | 0.757 | 0.946 | −0.603 | 0.313 | 60.4 | 16.0 | 0.377 | 0.142 |
| Item 7 | 0.575 | [0.45; 0.70] | 0.515 | −0.097 | −1.505 | 0.235 | 43.4 | 0.90 | 0.448 | 0.201 |
| Item 8 | 0.358 | [0.23; 0.49] | 0.52 | 1.009 | −0.128 | 0.614 | 66 | 1.90 | 0.794 | 0.631 |
| Item 9 | 0.321 | [0.19; 0.45] | 0.508 | 1.217 | 0.407 | 0.414 | 69.8 | 1.90 | 0.647 | 0.419 |
| Item 10 | 0.123 | [0.04; 0.20] | 0.33 | 2.334 | 3.513 | 0.431 | 87.7 | 0.00 | 0.810 | 0.656 |
| Group B (name of examinee) | ||||||||||
| Item 1 | 0.056 | [−0.01; 0.12] | 0.23 | 3.947 | 13.884 | 0.212 | 94.4 | 0.00 | 0.617 | 0.380 |
| Item 2 | 0.544 | [0.40; 0.69] | 0.523 | 0.06 | −1.462 | 0.475 | 46.7 | 1.10 | 0.601 | 0.362 |
| Item 3 | 0.189 | [0.08; 0.30] | 0.394 | 1.617 | 0.627 | 0.247 | 81.1 | 0.00 | 0.575 | 0.330 |
| Item 4 | 0.111 | [0.02; 0.21] | 0.35 | 3.289 | 11.138 | 0.453 | 90 | 1.10 | 0.757 | 0.574 |
| Item 5 | 0.067 | [−0.01; 0.15] | 0.292 | 4.814 | 24.931 | 0.443 | 94.4 | 1.10 | 0.876 | 0.768 |
| Item 6 | 0.556 | [0.34; 0.77] | 0.795 | 0.981 | −0.692 | 0.086 | 63.3 | 18.9 | 0.156 | 0.024 |
| Item 7 | 0.467 | [0.33; 0.61] | 0.524 | 0.376 | −1.331 | 0.316 | 54.4 | 1.10 | 0.521 | 0.271 |
| Item 8 | 0.356 | [0.21; 0.50] | 0.547 | 1.233 | 0.577 | 0.455 | 67.8 | 3.30 | 0.580 | 0.336 |
| Item 9 | 0.378 | [0.25; 0.51] | 0.488 | 0.513 | −1.777 | 0.296 | 62.2 | 0.00 | 0.323 | 0.104 |
| Item 10 | 0.178 | [0.07; 0.29] | 0.413 | 2.193 | 4.15 | 0.35 | 83.3 | 1.10 | 0.685 | 0.469 |
| Item | Distribution | Location (Mean) | Dispersion | ||
|---|---|---|---|---|---|
| KS-D | OVL | t (df) | d (95% CI) | FL (1, 194) | |
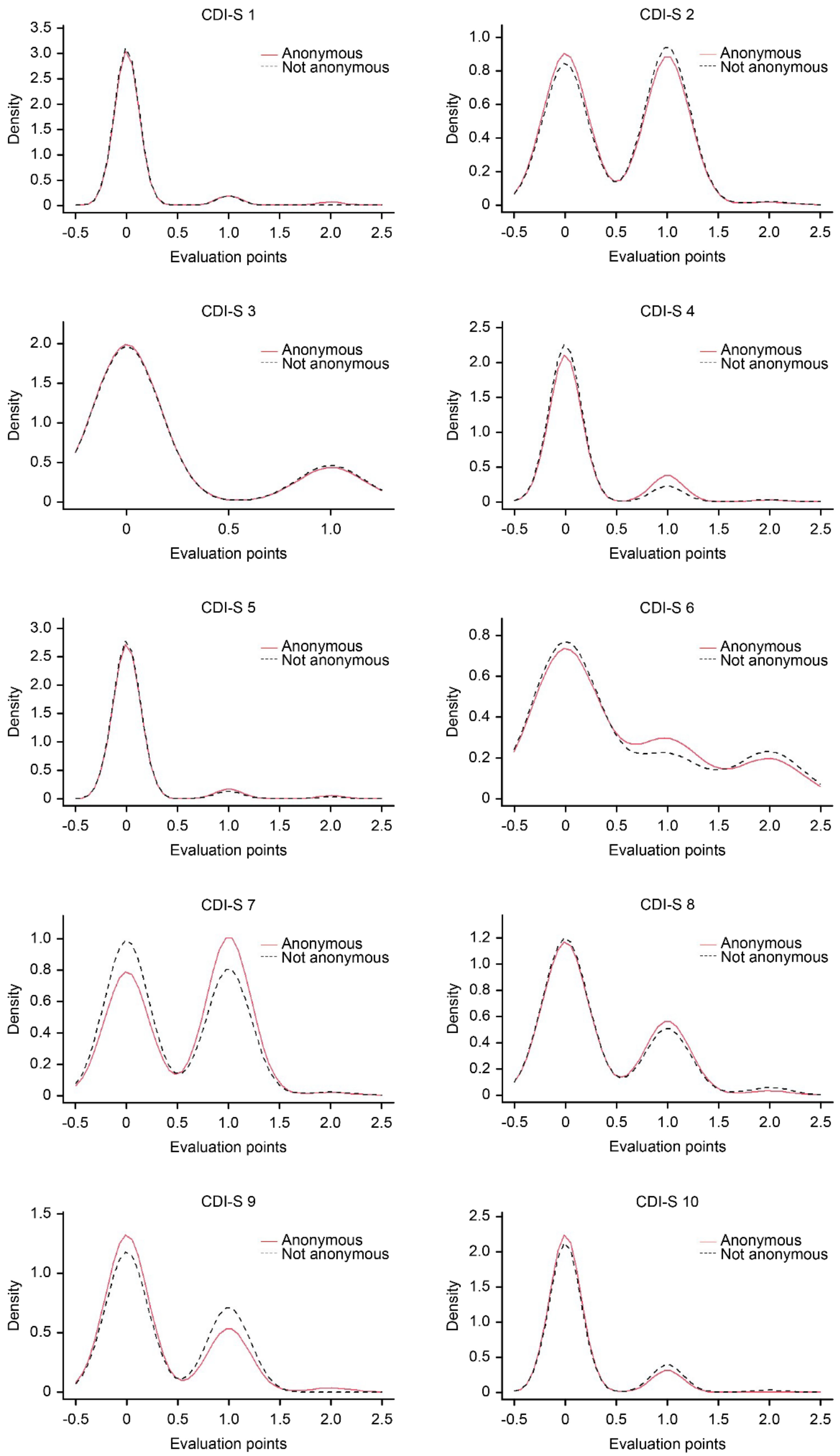
| Item 1 | 0.019 | 0.792 | 0.71 (182.440) | 0.099 (−0.18; 0.38) | 3.363 |
| Item 2 | 0.033 | 0.973 | −0.40 (188.645) | −0.057 (−0.34; 0.22) | 0.007 |
| Item 3 | 0.009 | 0.986 | −0.18 (187.401) | −0.025 (−0.31; 0.26) | 0.119 |
| Item 4 | 0.060 | 0.913 | 1.12 (193.870) | 0.150 (−0.12; 0.44) | 4.385 |
| Item 5 | 0.019 | 0.904 | 0.43 (193.878) | 0.061 (−0.22; 0.34) | 1.388 |
| Item 6 | 0.029 | 0.976 | 0.009 (185.561) | 0.000 (−0.28; 0.28) | 0.393 |
| Item 7 | 0.110 | 0.916 | 1.48 (187.786) | 0.210 (−0.07; 0.49) | 0.272 |
| Item 8 | 0.017 | 0.975 | 0.038 (185.438) | 0.000 (−0.28; 0.28) | 0.006 |
| Item 9 | 0.075 | 0.951 | −0.84 (191.038) | −0.120 (−0.40; 0.16) | 0.660 |
| Item 10 | 0.044 | 0.880 | −1.11 (169.440) | −0.160 (−0.44; 0.12) | 4.515 |
| Item | Non-Uniform DIF | Uniform DIF | ||
|---|---|---|---|---|
| PDif.(LL) | DIF | β1–β2 | DIF | |
| Item 1 | 0.226 | No | −0.0067 | No |
| Item 2 | 0.224 | No | −0.0032 | No |
| Item 3 | 0.461 | No | 0.0075 | No |
| Item 4 | 0.363 | No | −0.0044 | No |
| Item 5 | 0.981 | No | −0.0053 | No |
| Item 6 | 0.918 | No | 0.0007 | No |
| Item 7 | 0.278 | No | 0.0258 | No |
| Item 8 | 0.778 | No | −0.0000 | No |
| Item 9 | 0.712 | No | 0.0057 | No |
| Item 10 | 0.702 | No | 0.0517 | No |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Merino-Soto, C.; Copez-Lonzoy, A.; Toledano-Toledano, F.; Nabors, L.A.; Rodrígez-Castro, J.H.; Hernández-Salinas, G.; Núñez-Benítez, M.Á. Effects of Anonymity versus Examinee Name on a Measure of Depressive Symptoms in Adolescents. Children 2022, 9, 972. https://doi.org/10.3390/children9070972
Merino-Soto C, Copez-Lonzoy A, Toledano-Toledano F, Nabors LA, Rodrígez-Castro JH, Hernández-Salinas G, Núñez-Benítez MÁ. Effects of Anonymity versus Examinee Name on a Measure of Depressive Symptoms in Adolescents. Children. 2022; 9(7):972. https://doi.org/10.3390/children9070972
Chicago/Turabian StyleMerino-Soto, César, Anthony Copez-Lonzoy, Filiberto Toledano-Toledano, Laura A. Nabors, Jorge Homero Rodrígez-Castro, Gregorio Hernández-Salinas, and Miguel Ángel Núñez-Benítez. 2022. "Effects of Anonymity versus Examinee Name on a Measure of Depressive Symptoms in Adolescents" Children 9, no. 7: 972. https://doi.org/10.3390/children9070972
APA StyleMerino-Soto, C., Copez-Lonzoy, A., Toledano-Toledano, F., Nabors, L. A., Rodrígez-Castro, J. H., Hernández-Salinas, G., & Núñez-Benítez, M. Á. (2022). Effects of Anonymity versus Examinee Name on a Measure of Depressive Symptoms in Adolescents. Children, 9(7), 972. https://doi.org/10.3390/children9070972