
Improving Cohort-Hospital Matching Accuracy through Standardization and Validation of Participant Identifiable Information

 ,
,  , , ,
, , ,  and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Sampling Frame and Recruitment
2.2. Data Sources and Handling
2.3. Step 1 (Hospital): Initial Matching
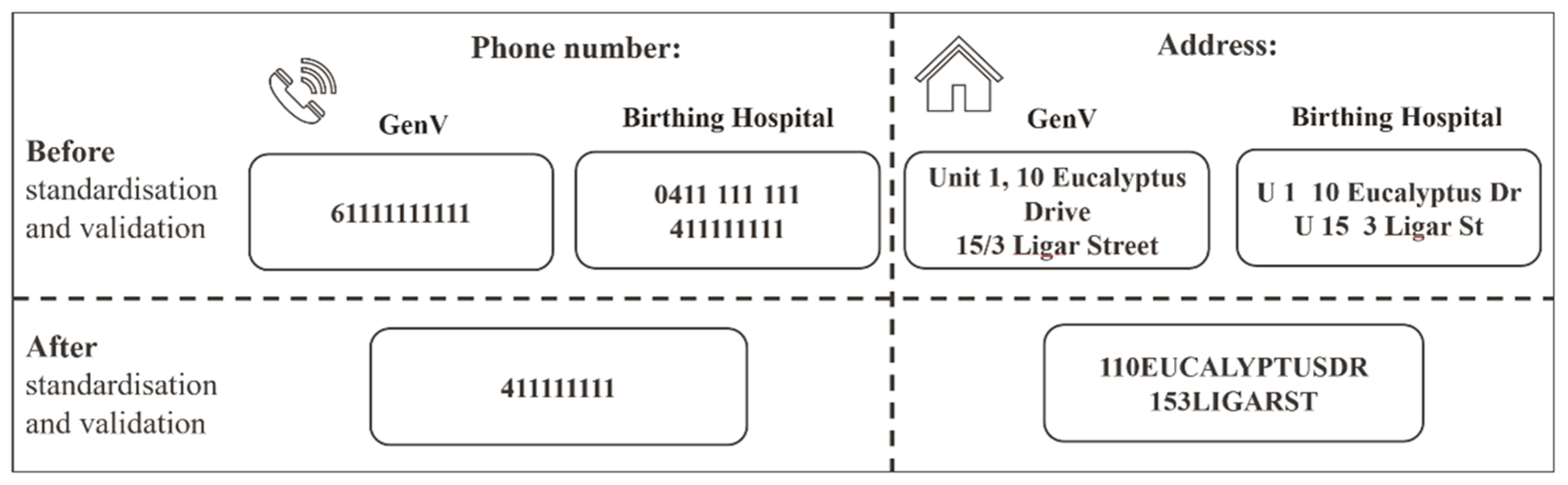
2.4. Step 2 (GenV): Standardization/Validation and Optimization of Matching Approaches
- Deterministic rule-based approach: Use all mothers’ and all babies’ PII (Detail in Table 2).
- Modified SLK-581 approach 1—SLK-5881: SLK-581 [28] is a 14-character code comprising the 2nd, 3rd and 5th characters of the family name, the 2nd and 3rd of the given/first name (‘5’), the date of birth (DDMMYYYY, ‘8’) and sex (‘1’). This has previously provided successful linkage in some datasets but less so in studies using data with a high rate of missing names [18]. As the GenV cohort includes twin and triplet babies with imprecise names (e.g., ‘Boy’, ‘Girl’, ‘Twin1’, ‘Twin2’) and the sex of the babies may also be imprecise, we modified the SLK-581 by adding babies’ B-DOB and BO as ‘birth order’ was the only unique identifier for twins. We removed the mother’s sex variable as mother’s sex was the same in both datasets. We named this new linkage method as SLK-5881 as the ‘5’ (2nd, 3rd letter of FN, and 2nd, 3rd, 5th letter of LN), the first ‘8’ remains the mother’s DOB, with the additional ‘8’ for baby’s DOB and ‘1’ for birth order.
- Modified SLK-581 approach 2—SLK5881.1: Additionally, we tested a modified linkage method using the first 2 letters of first name and the first 3 letters of last name. M-DOB, B-DOB, B-DOB and BO were used as per SLK-5881.1.
2.5. Statistical Analysis and Evaluation Metrics
2.6. Ethics, Privacy, and Data Protection
3. Results
3.1. The Sample
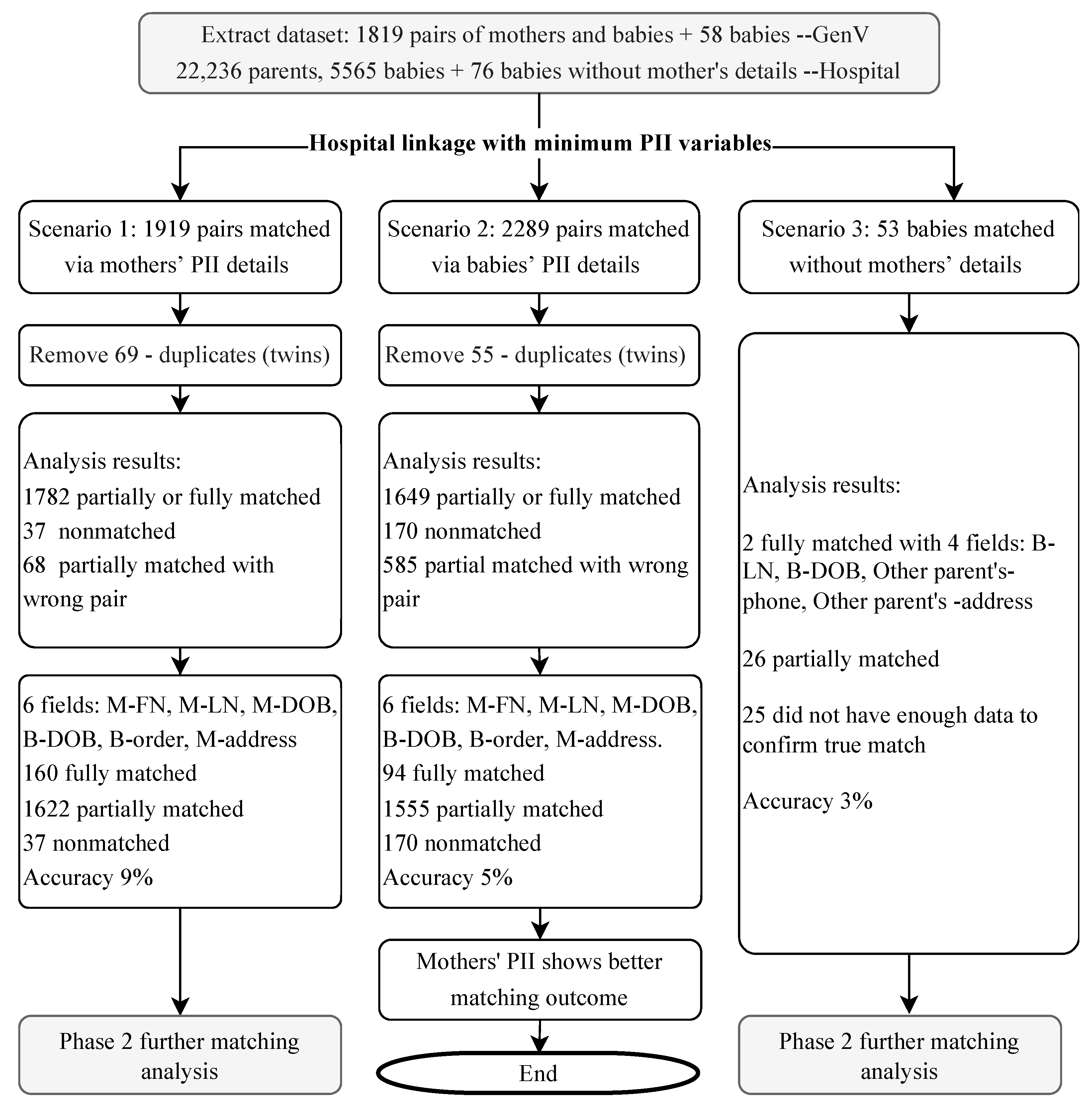
3.2. Step 1: Hospital Initial Matching in the Three Linkage Scenarios Analysis
3.3. Step 2 (GenV): Standardization/Validation and Optimization of Matching Approaches
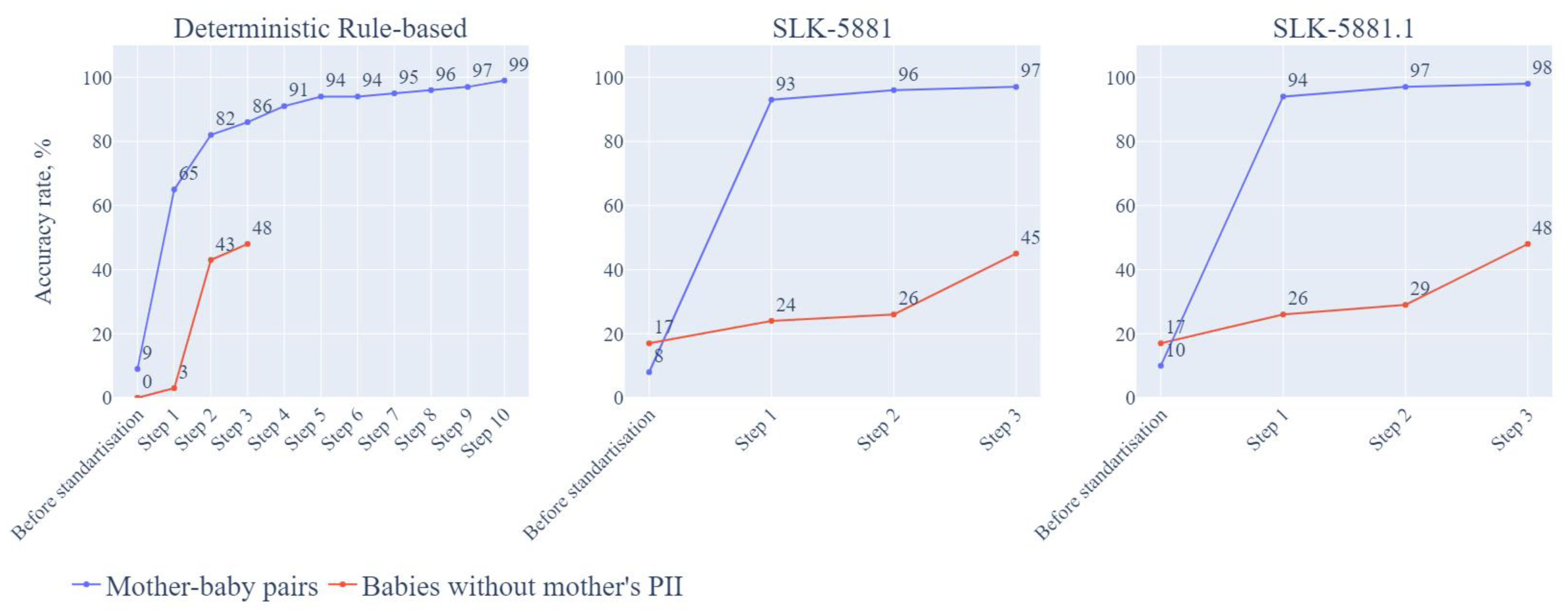
3.3.1. Deterministic Rule-Based Approach
Mother-Baby Pairs
Babies without Mother’s PII
3.3.2. SLK-5881 Matching Approach
Mother-Baby Pairs
Babies without Mother’s PII
3.3.3. SLK-5881.1 Matching Approach
Mother-Baby Pairs
Babies without Mother’s PII
4. Discussion
4.1. Principal Results
4.2. Comparisons with Published Studies
4.3. Implications
4.4. Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cowie, M.R.; Blomster, J.I.; Curtis, L.H.; Duclaux, S.; Ford, I.; Fritz, F.; Goldman, S.; Janmohamed, S.; Kreuzer, J.; Leenay, M.; et al. Electronic health records to facilitate clinical research. Clin. Res. Cardiol. 2017, 106, 1–9. [Google Scholar] [CrossRef]
- Farmer, R.; Mathur, R.; Bhaskaran, K.; Eastwood, S.V.; Chaturvedi, N.; Smeeth, L. Promises and pitfalls of electronic health record analysis. Diabetologia 2018, 61, 1241–1248. [Google Scholar] [CrossRef]
- Colombo, F.; Oderkirk, J.; Slawomirski, L. Health information systems, electronic medical records, and big data in global healthcare: Progress and challenges in oecd countries. In Handbook of Global Health; Springer: Berlin/Heidelberg, Germany, 2020; Chapter 71-1; pp. 1–31. [Google Scholar]
- Harron, K.; Dibben, C.; Boyd, J.; Hjern, A.; Azimaee, M.; Barreto, M.L.; Goldstein, H. Challenges in administrative data linkage for research. Big Data Soc. 2017, 4, 2053951717745678. [Google Scholar] [CrossRef] [PubMed]
- Smith, M.; Flack, F. Data linkage in australia: The first 50 years. Int. J. Environ. Res. Public Health 2021, 18, 11339. [Google Scholar] [CrossRef]
- Tew, M.; Dalziel, K.M.; Petrie, D.J.; Clarke, P.M. Growth of linked hospital data use in australia: A systematic review. Aust. Health Rev. 2017, 41, 394–400. [Google Scholar] [CrossRef]
- Wood, A.; Denholm, R.; Hollings, S.; Cooper, J.; Ip, S.; Walker, V.; Denaxas, S.; Akbari, A.; Banerjee, A.; Whiteley, W.; et al. Linked electronic health records for research on a nationwide cohort of more than 54 million people in england: Data resource. BMJ 2021, 373, n826. [Google Scholar] [CrossRef]
- Casey, J.A.; Schwartz, B.S.; Stewart, W.F.; Adler, N.E. Using electronic health records for population health research: A review of methods and applications. Annu. Rev. Public Health 2016, 37, 61–81. [Google Scholar] [CrossRef]
- Darke, P.; Cassidy, S.; Catt, M.; Taylor, R.; Missier, P.; Bacardit, J. Curating a longitudinal research resource using linked primary care ehr data-a uk biobank case study. J. Am. Med. Inform. Assoc. 2022, 29, 546–552. [Google Scholar] [CrossRef]
- Gao, L.; Leung, M.T.Y.; Li, X.; Chui, C.S.L.; Wong, R.S.M.; Yeung, S.L.A.; Chan, E.W.W.; Chan, A.Y.L.; Chan, E.W.; Wong, W.H.S.; et al. Linking cohort-based data with electronic health records: A proof-of-concept methodological study in Hong Kong. BMJ Open 2021, 11, e045868. [Google Scholar] [CrossRef]
- Mykletun, A.; Widding-Havneraas, T.; Chaulagain, A.; Lyhmann, I.; Bjelland, I.; Halmøy, A.; Elwert, F.; Butterworth, P.; Markussen, S.; Zachrisson, H.D.; et al. Causal modelling of variation in clinical practice and long-term outcomes of adhd using norwegian registry data: The adhd controversy project. BMJ Open 2021, 11, e041698. [Google Scholar] [CrossRef]
- Reed, B.D.; Schibler, K.R.; Deshmukh, H.; Ambalavanan, N.; Morrow, A.L. The impact of maternal antibiotics on neonatal disease. J. Pediatr. 2018, 197, 97–103.e3. [Google Scholar] [CrossRef] [PubMed]
- Young, A.; Flack, F. Recent trends in the use of linked data in australia. Aust. Health Rev. 2018, 42, 584–590. [Google Scholar] [CrossRef] [PubMed]
- Tingay, K.S.; Bandyopadhyay, A.; Griffiths, L.; Akbari, A.; Brophy, S.; Bedford, H.; Cortina-Borja, M.; Setakis, E.; Walton, S.; Fitzsimons, E.; et al. Record linkage to enhance consented cohort and routinely collected health data from a uk birth cohort. Int. J. Popul. Data Sci. 2019, 4, 579. [Google Scholar] [CrossRef]
- Cox, S.; Martin, R.; Somaia, P.; Smith, K. The development of a data-matching algorithm to define the ‘case patient’. Aust. Health Rev. 2012, 37, 54–59. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, L.; Stoové, M.; Boyle, D.; Callander, D.; McManus, H.; Asselin, J.; Guy, R.; Donovan, B.; Hellard, M.; El-Hayek, C. Privacy-preserving record linkage of deidentified records within a public health surveillance system: Evaluation study. J. Med. Internet Res. 2020, 22, e16757. [Google Scholar] [CrossRef] [PubMed]
- Coulson, T.G.; Bailey, M.; Reid, C.; Shardey, G.; Williams-Spence, J.; Huckson, S.; Chavan, S.; Pilcher, D. Linkage of australian national registry data using a statistical linkage key. BMC Med. Inform. Decis. Mak. 2021, 21, 37. [Google Scholar] [CrossRef]
- Taylor, L.K.; Irvine, K.; Iannotti, R.; Harchak, T.; Lim, K. Optimal strategy for linkage of datasets containing a statistical linkage key and datasets with full personal identifiers. BMC Med. Inform. Decis. Mak. 2014, 14, 85. [Google Scholar] [CrossRef] [PubMed]
- Australian Bureau of Statistics. Popuation: Census. 2021. Available online: https://www.abs.gov.au/statistics/people/population/2021-census-overcount-and-undercount/2021 (accessed on 1 October 2022).
- Bohensky, M.A.; Jolley, D.; Sundararajan, V.; Evans, S.; Ibrahim, J.; Brand, C. Development and validation of reporting guidelines for studies involving data linkage. Aust. N. Z. J. Public Health 2011, 35, 486–489. [Google Scholar] [CrossRef]
- Benchimol, E.I.; Smeeth, L.; Guttmann, A.; Harron, K.; Moher, D.; Petersen, I.; Sørensen, H.T.; von Elm, E.; Langan, S.M. The reporting of studies conducted using observational routinely-collected health data (record) statement. PLoS Med. 2015, 12, e1001885. [Google Scholar] [CrossRef]
- Generation Victoria (GenV). What’s Genv. 2020. Available online: https://genv.org.au/about-genv/what-is-genv/ (accessed on 11 June 2022).
- Department of Health Standard. Assignment of Unique Unit Record Number. Standard QH-IMP-280-3:2014. Queensland Department of Health. 2015. Available online: https://www.health.qld.gov.au/__data/assets/pdf_file/0030/397254/qh-imp-280-3.pdf (accessed on 11 June 2022).
- Sarkies, M.N.; Bowles, K.-A.; Skinner, E.H.; Mitchell, D.; Haas, R.; Ho, M.; Salter, K.; May, K.; Markham, D.; O’Brien, L.; et al. Data collection methods in health services research: Hospital length of stay and discharge destination. Appl. Clin. Inform. 2015, 6, 96–109. [Google Scholar] [CrossRef]
- Knight-Agarwal, C.R.; Williams, L.T.; Davis, D.; Davey, R.; Cochrane, T.; Zhang, H.; Rickwood, P. Association of bmi and interpregnancy bmi change with birth outcomes in an australian obstetric population: A retrospective cohort study. BMJ Open 2016, 6, e010667. [Google Scholar] [CrossRef] [PubMed]
- Horsley, A.; Gerrand, P. Major policy gaps in Australian telecommunications. Telecommun. J. Aust. 2011, 61, 1–6. [Google Scholar] [CrossRef]
- Alam, Q.; Grose, R. Australia post. In Regional Businesses in a Changing Global Economy: The Australian Experience; Routledge: London, UK, 2022. [Google Scholar]
- Australian Institute of Health and Welfare. Slk-581 Guide for Use. 2016. Available online: https://www.aihw.gov.au/getmedia/e1d4d462-8efa-4efa-8831-fa84d6f5d8d9/aodts-nmds-2016-17-SLK-581-guide.pdf.aspx (accessed on 1 October 2022).
- Grannis, S.J.; Xu, H.; Vest, J.R.; Kasthurirathne, S.; Bo, N.; Moscovitch, B.; Torkzadeh, R.; Rising, J. Evaluating the effect of data standardization and validation on patient matching accuracy. J. Am. Med Inform. Assoc. 2019, 26, 447–456. [Google Scholar] [CrossRef] [PubMed]
- Eze, B.; Kuziemsky, C.; Peyton, L. A patient identity matching service for cloud-based performance management of community healthcare. Procedia Comput. Sci. 2017, 113, 287–294. [Google Scholar] [CrossRef]
- Duckett, S. Expanding the breadth of medicare: Learning from australia. Health Econ. Policy Law 2018, 13, 344–368. [Google Scholar] [CrossRef]
- Bidargaddi, N.; van Kasteren, Y.; Musiat, P.; Kidd, M. Developing a third-party analytics application using australia’s national personal health records system: Case study. JMIR Med Inform. 2018, 6, e28. [Google Scholar] [CrossRef]
- Xafis, V. The acceptability of conducting data linkage research without obtaining consent: Lay people’s views and justifications. BMC Med. Ethics 2015, 16, 79. [Google Scholar] [CrossRef]
- Boyd, J.H.; Ferrante, A.M.; O’Keefe, C.M.; Bass, A.J.; Randall, S.M.; Semmens, J.B. Data linkage infrastructure for cross-jurisdictional health-related research in australia. BMC Health Serv. Res. 2012, 12, 480. [Google Scholar] [CrossRef]
- Costa, J.D.O.; Bruno, C.; Schaffer, A.L.; Raichand, S.; A Karanges, E.; Pearson, S.-A. Pearson. The changing face of australian data reforms: Impact on pharmacoepidemiology research. Int. J. Popul. Data Sci. 2021, 6, 1418. [Google Scholar] [CrossRef]
- Dixit, S.K.; Sambasivan, M. A review of the australian healthcare system: A policy perspective. SAGE Open Med. 2018, 6, 2050312118769211. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GenV Birthing Hospital | |
| Inclusion criteria | All children born in Victoria during the recruitment period whose parents/guardians have decisional capacity, and their parents Participants who leave Victoria may continue to take part via linked and contributed data Families who move to Victoria later and have children born within the recruitment period may join GenV GenV recruitment and data collection materials are offered in multiple languages to enhance accessibility |
| Exclusion criteria | Infants who die before recruitment to GenV (stillbirth or neonatal death) Families unable to consent in any available language |
| Linkage Matching Cohort | |
| Inclusion criteria | Baby is born between December 2020 and December 2021 Consented babies and parents who agreed to participate in GenV There is a record for admission between November 2020 and January 2022 at the selected Victorian birthing hospital. |
| Exclusion criteria | No additional exclusion criteria |
| Mother or Baby | PII Data Variables |
| Both | ID, generated by computer |
| Baby | First Name (B-FN) |
| Middle Name | |
| Last Name (B-LN) | |
| Birthdate (B-DOB) | |
| Birth Order (BO) for multiple births (e.g., twins, triplets) | |
| Gender (Sex, female, male and unknown) | |
| Biological Mother | First Name (M-FN) |
| Middle Name | |
| Last Name (M-LN) | |
| Birthdate (M-DOB) | |
| Mother’s Phone number (TN) Mother’s street Address (ADD) | |
| The other parent | Other parent’s Phone number (TN) Other parent’s Street Address (ADD) |
| Scenario | Details | Outcome |
|---|---|---|
| Scenario 1: Primarily using mother’s details to link the mother and baby | 1st letter of mother first name and first 2 letters of mother surname and mother’s date of birth (dd/mm/ or yyyy). Any inpatient management (iPM, inpatient admission data) data would be joined where the Unit Record (UR) number from above criterion joins to IP admission UR number, and the Child’s birthdate is between the IP admission date -1 day and separation date, and it is a maternity episode. Additional Birth Outcomes System (BOS)/iPM data will join where the UR number from the 1st criterion joined BOS UR number. | The hospital identified 1919 potential pairs |
| Scenario 2: Primarily using baby’s details to link the mother and baby | 1st two letters of baby surname OR Mother LN + baby (DOB). Join any inpatient episode through baby’s UR number In addition, BOS/iPM data were joined by their common UR number. | The hospital identified 2289 potential pairs |
| Scenario 3: Using all available variables for babies without information about their mothers | Using babies’ FN and LN, DOB Using baby’s PII and obtained baby’s other parent’s TN and ADD. | The hospital identified 53 out of 58 babies |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.J.; Fedyukova, A.; Wang, J.; Said, J.M.; Thomas, N.; Noble, E.; Cheong, J.L.Y.; Karanatsios, B.; Goldfeld, S.; Wake, M. Improving Cohort-Hospital Matching Accuracy through Standardization and Validation of Participant Identifiable Information. Children 2022, 9, 1916. https://doi.org/10.3390/children9121916
Hu YJ, Fedyukova A, Wang J, Said JM, Thomas N, Noble E, Cheong JLY, Karanatsios B, Goldfeld S, Wake M. Improving Cohort-Hospital Matching Accuracy through Standardization and Validation of Participant Identifiable Information. Children. 2022; 9(12):1916. https://doi.org/10.3390/children9121916
Chicago/Turabian StyleHu, Yanhong Jessika, Anna Fedyukova, Jing Wang, Joanne M. Said, Niranjan Thomas, Elizabeth Noble, Jeanie L. Y. Cheong, Bill Karanatsios, Sharon Goldfeld, and Melissa Wake. 2022. "Improving Cohort-Hospital Matching Accuracy through Standardization and Validation of Participant Identifiable Information" Children 9, no. 12: 1916. https://doi.org/10.3390/children9121916
APA StyleHu, Y. J., Fedyukova, A., Wang, J., Said, J. M., Thomas, N., Noble, E., Cheong, J. L. Y., Karanatsios, B., Goldfeld, S., & Wake, M. (2022). Improving Cohort-Hospital Matching Accuracy through Standardization and Validation of Participant Identifiable Information. Children, 9(12), 1916. https://doi.org/10.3390/children9121916