
A Comparative Study on Distancing, Mask and Vaccine Adoption Rates from Global Twitter Trends


Abstract
1. Introduction
Contributions
2. Materials and Methods
2.1. Dataset
2.1.1. COVID Tweet
- Mask. mask, masking, mask-wearing, wear, covering, face
- Vaccine. vaccine, vaccination, immune, immunity, dose, injection, inoculate, shot
- Distancing. lockdown, distancing, distance, mobility, isolation, social distance, contact, quarantine
2.1.2. Latitude–Longitude Coordinates
2.1.3. Population Counts
2.1.4. Infection Counts
2.1.5. Red vs. Blue States
2.1.6. Demographic and Socioeconomic Features from the States of USA
- Age group (total range: 0–80+ years) in groups of 4 years and also normalized them based on the population [31] (filename: source/Data_age.xlsx, feature name: age_to_, Norm_to_, e.g., age8to12 or Norm8to12); we have also grouped them in classes of 20 years later on for some of the analysis.
- Percentage change in Gross Domestic Product [32] It is measured in all 50 states and District of Columbia in 2020. (filename: source/GDP.xlsx, feature name: GDP).
- Traffic or airport activity quantifies the airport passenger traffic; it is also normalized by total airport traffic across all 50 US states [33] (filename: source/Data_airport.xlsx, feature name: Busy airport score, Normalized busy airport).
- (filename: source/Data_gender.csv, feature name: Male, Female).
- Population density is simply the ratio between the population of a state and its total area [31] (filename: source/Data_population.csv, feature name: Population, Area, Population Density).
- Ethnicity denotes the fraction(s) of total population that are Asian, Hispanic, black, and white; we did not consider the other smaller ethnicities [35](filename: source/Data_ethnic.csv, feature name: Asian, Hispanic, Black and White).
- Homeless quantifies the total number of homeless individuals in each US state [36] (filename: source/Data_homeless.xlsx, feature name: Homeless). Similarly, for each state, the normalized homeless population designates the ratio between its homeless population and total population.
- Healthcare index is formally measured by the Agency for Healthcare Research and Quality (AHRQ). The quantification is done considering (1) the care setting (e.g., hospitals and nursing homes), (2) clinical area (e.g., caring for patients having diabetes, cancer), and (3) care type (e.g., chronic, preventive) [37] (filename: source/Data_health.xlsx, feature name: Health).
2.1.7. Preprocessing
2.2. Sentiment Analysis Approaches
2.2.1. Machine Learning Approaches
- K-fold cross validation. It is a standard approach to test the efficacy of a classification model [39]. The labeled training dataset is split into K partitions. The classifier is trained on all possible partitions and tested on the K-th partition. The overall performance of the estimator is a mean of the accuracy of the predictions from the K folds. We used the Python Scikit-learn library [40] to perform cross-validation.
- Naive Bayes (NB). It is a class of fast, probabilistic learning techniques that apply the Bayes’ theorem to assign labels to the data points [41]. We use NB to learn the sentiments in an iterative approach. We train the NB classifier with the labeled NLTK tweet dataset and iteratively predict the label of unlabeled COVID tweet dataset. At each step, we apply K-fold cross validation (see Section 2.2.1) to monitor the accuracy of the integrated dataset.
- Convolutional Neural Networks (CNN). It is a class of deep learning which can assign varying importance to different aspects of the input data. This helps them distinguish these aspects from one another [42]. After the processing step (see Section 2.1.7) is complete, we assign a unique ID to the meaningful tokens and vectorize each labeled tweet as follows. Each labeled tweet is filtered to preserve L most common words and converted to a vector of token IDs (see Section 1), allowing us to preserve the relative order of the tokens. The CNN classifier is then trained on the (tweet vector, sentiment) pair and the accuracy, estimated by cross-validation, is recorded. At the end of the training stage, a tweet is associated with a label 2 or 0, representing positive or negative sentiments, respectively.
- Multiple regression (MR). Considering a dependent and independent variable B and A respectively, their linear association designated by the function is captured by the statistical measure of MR. The linear association is generated by MR in the following form: ; here, is the error term, the intercept, and the coefficient quantifies how feature contributes to b, which is the dependent variable.
2.3. Performance Metrics
2.3.1. Accuracy
2.3.2. Euclidean Distance
2.3.3. One Sample t-Test
2.3.4. Pearson Correlation Coefficient
3. Results
3.1. Selection of Classifier
3.2. Correlation between Geographical Proximity and Sentiment
3.3. Effect of Sentiments on COVID-19 Infection Rates
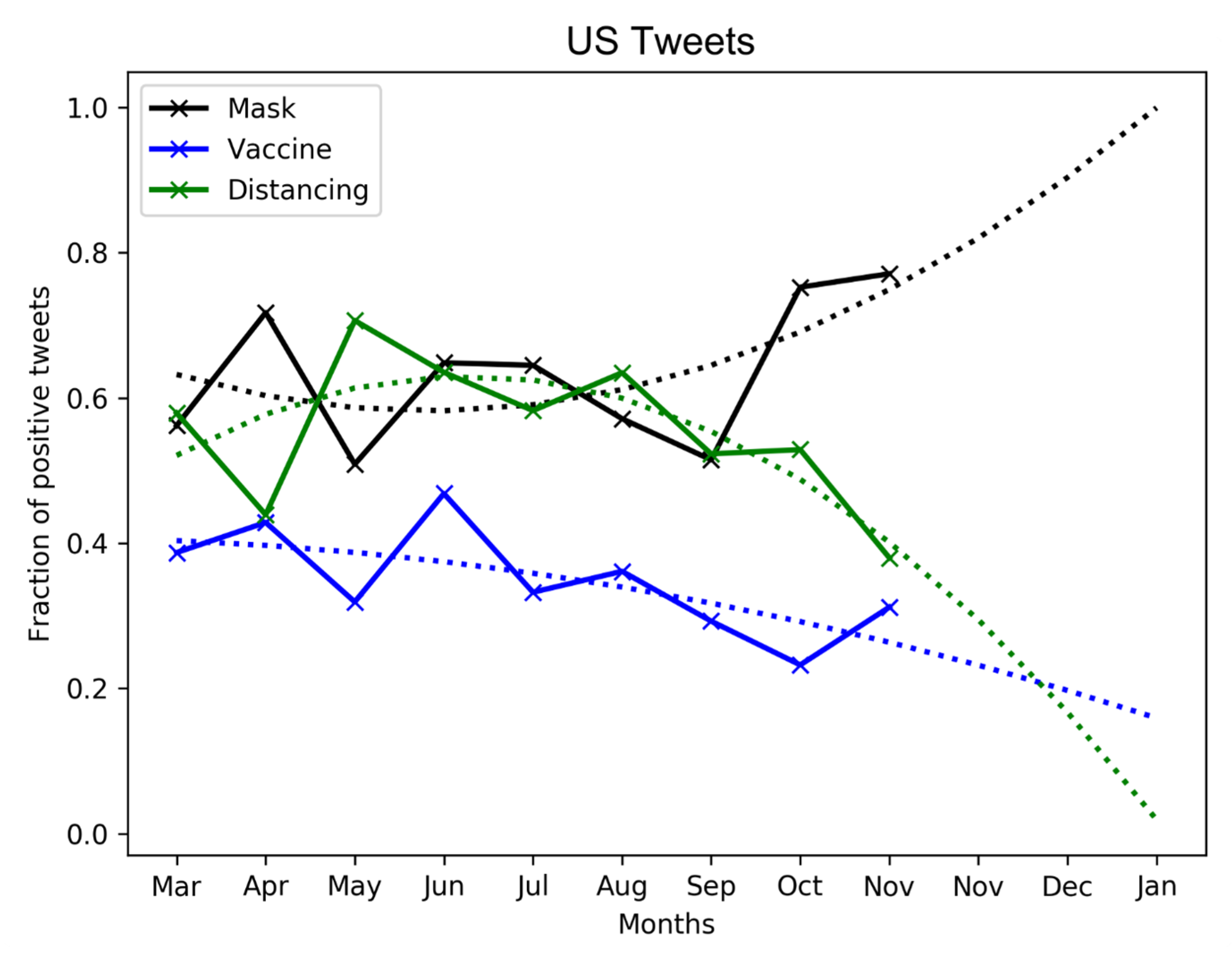
3.4. Evolution of Public Sentiment over COVID-19
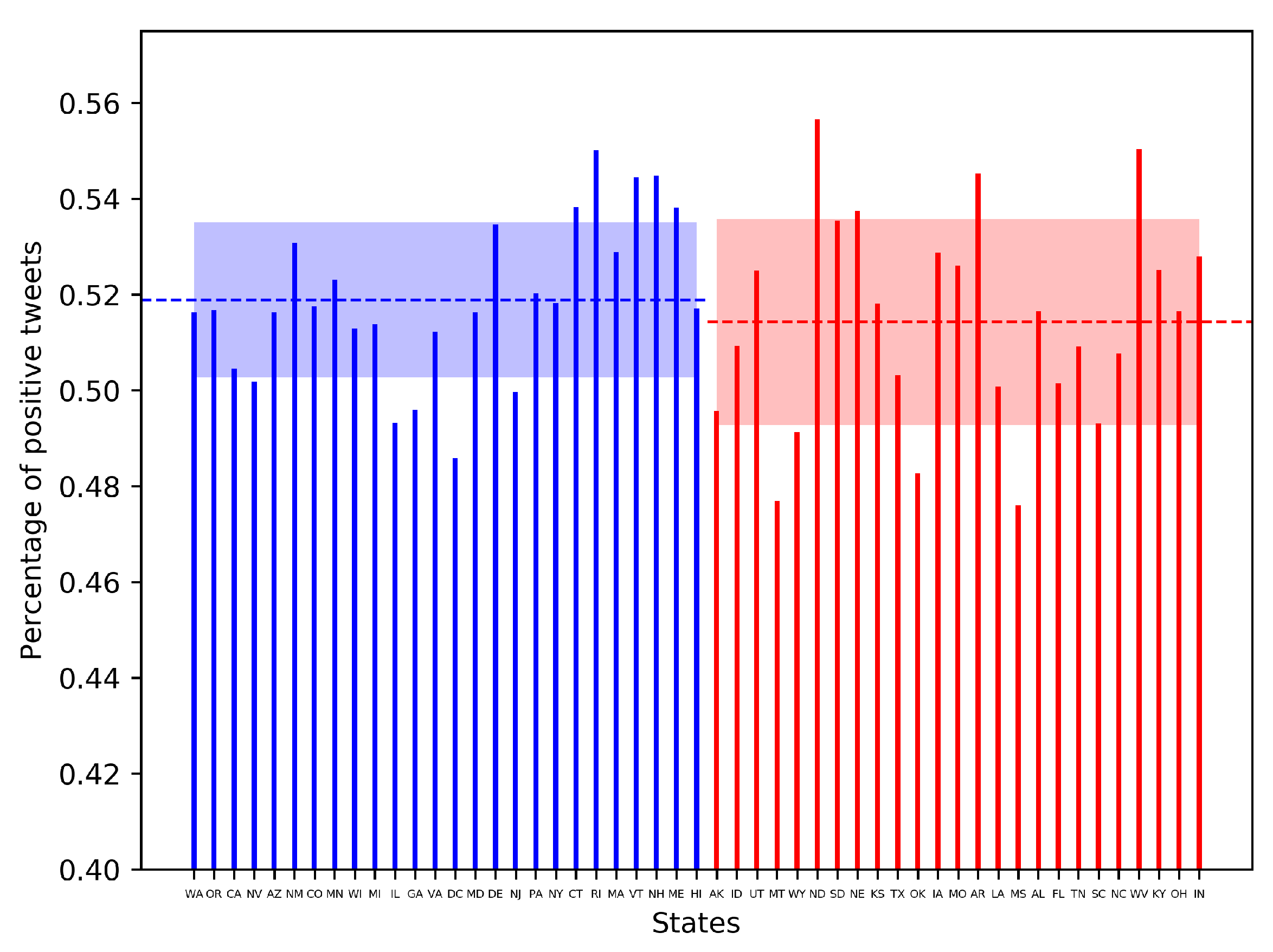
3.5. Effect of Political Ideology on Sentiments
3.6. Effect of Socioeconomic and Demographic Features on Sentiments on Adoption of COVID Mitigation Measures
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sibley, C.G.; Greaves, L.M.; Satherley, N.; Wilson, M.S.; Overall, N.C.; Lee CH, J.; Milojev, P.; Bulbulia, J.; Osborne, D.; Milfont, T.L.; et al. Effects of the COVID-19 pandemic and nationwide lockdown on trust, attitudes toward government, and well-being. Am. Psychol. 2020, 75, 618–630. [Google Scholar] [CrossRef]
- Coronavirus: What Have Been the Worst Pandemics and Epidemics in History? 2020. Available online: https://en.as.com/en/2020/04/18/other_sports/1587167182_422066.html (accessed on 20 February 2021).
- COVID-19 and the Least Developed Countries. 2020. Available online: https://www.un.org/development/desa/dpad/publication/un-desa-policy-brief-66-covid-19-and-the-least-developed-countries/ (accessed on 20 February 2021).
- Scudellari, M. How the pandemic might play out in 2021 and beyond. Nature 2020, 584, 22–25. [Google Scholar] [CrossRef] [PubMed]
- Coronavirus, Social and Physical Distancing and Self-Quarantine. 2020. Available online: https://www.hopkinsmedicine.org/health/conditions-and-diseases/coronavirus/coronavirus-social-distancing-and-self-quarantine (accessed on 20 February 2021).
- Ozili, P.; Arun, T. Spillover of COVID-19: Impact on the Global Economy. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Adhikari, S.; Meng, S.; Wu, Y.; Mao, Y.; Ye, R.; Wang, Q.; Sun, C.; Sylvia, S.; Rozelle, S.; Raat, H.; et al. Epidemiology, causes, clinical manifestation and diagnosis, prevention and control of coronavirus disease (COVID-19) during the early outbreak period: A scoping review. Infect. Dis. Poverty 2020, 9, 29. [Google Scholar] [CrossRef] [PubMed]
- Wynants, L.; Calster, B.V.; Bonten, M.; Collins, G.S.; Smeden, M.V. Prediction models for diagnosis and prognosis of covid-19: Systematic review and critical appraisal. BMJ 2020, 369. [Google Scholar] [CrossRef] [PubMed]
- Alimadadi, A.; Aryal, S.; Manandhar, I.; Munroe, P.; Joe, B.; Cheng, X. Artificial intelligence and machine learning to fight COVID-19. Physiol. Genom. 2020, 52, 200–202. [Google Scholar] [CrossRef] [PubMed]
- Randhawa, G.; Soltysiak, M.; El Roz, H.; de Souza, C.; Hill, K.; Kari, L. Machine learning using intrinsic genomic signatures for rapid classification of novel pathogens: COVID-19 case study. PLoS ONE 2020, 15, e0232391. [Google Scholar] [CrossRef]
- Holmdahl, I.; Buckee, C. Wrong but useful—What covid-19 epidemiologic models can and cannot tell us. N. Engl. J. Med. 2020, 383, 303–305. [Google Scholar] [CrossRef]
- Wang, P.; Zheng, X.; Li, J.; Zhu, B. Prediction of epidemic trends in COVID-19 with logistic model and machine learning technics. Chaos Solitons Fractals 2020, 139, 110058. [Google Scholar] [CrossRef] [PubMed]
- Khan, N.; Naushad, M.; Fahad, S.; Faisal, S.; Muhammad, A. COVID-2019 and World Economy. J. Health Econ. Forthcom. 2020. [Google Scholar] [CrossRef]
- Roy, S.; Ghosh, P. Factors affecting COVID-19 infected and death rates inform lockdown-related policymaking. PLoS ONE 2020, 15, e0241165. [Google Scholar] [CrossRef]
- Roy, S.; Dutta, R.; Ghosh, P. Recreational and philanthropic sectors are the worst-hit US industries in the COVID-19 aftermath. Soc. Sci. Humanit. Open 2021, 3, 100098. [Google Scholar] [CrossRef]
- Roy, S.; Dutta, R.; Ghosh, P. Towards Dynamic lockdown strategies controlling pandemic spread under healthcare resource budget. Appl. Netw. Sci. 2021, 6, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Roy, S.; Cherevko, A.; Chakraborty, S.; Ghosh, N.; Ghosh, P. Leveraging Network Science for Social Distancing to Curb Pandemic Spread. IEEE Access 2021, 9, 26196–26207. [Google Scholar] [CrossRef]
- Geldsetzer, P. Knowledge and perceptions of COVID-19 among the general public in the United States and the United Kingdom: A cross-sectional online survey. Ann. Intern. Med. 2020, 173, 157–160. [Google Scholar] [CrossRef]
- Samuel, J.; Ali, G.; Rahman, M.; Esawi, E.; Samuel, Y. Covid-19 public sentiment insights and machine learning for tweets classification. Information 2020, 11, 314. [Google Scholar] [CrossRef]
- Samuel, J.; Rahman, M.; Ali, G.; Samuel, Y.; Pelaez, A.; Chong, P.H.J.; Yakubov, M. Feeling Positive About Reopening? New Normal Scenarios From COVID-19 US Reopen Sentiment Analytics. IEEE Access 2020, 8, 142173–142190. [Google Scholar] [CrossRef]
- Medford, R.; Saleh, S.; Sumarsono, A.; Perl, T.; Lehmann, C. An “infodemic”: Leveraging high-volume Twitter data to understand early public sentiment for the coronavirus disease 2019 outbreak. In Open Forum Infectious Diseases; Oxford University Press US: New York, NY, USA, 2020; Volume 7, p. ofaa258. [Google Scholar]
- Dinh, L.; Parulian, N. COVID-19 pandemic and information diffusion analysis on Twitter. Proc. Assoc. Inf. Sci. Technol. 2020, 57, e252. [Google Scholar] [CrossRef]
- Curiel, R.P.; Ramírez, H.G. Vaccination strategies against COVID-19 and the diffusion of anti-vaccination views. Sci. Rep. 2021, 11, 1–13. [Google Scholar]
- Chung, M.; Dekker, D.; Gridley-Smith, C.; Dearing, J. Peer Reviewed: An Emergent Network for the Diffusion of Innovations Among Local Health Departments at the Onset of the COVID-19 Pandemic. Prev. Chronic Dis. 2021, 18, E19. [Google Scholar] [CrossRef]
- Fagiolo, G. Assessing the Impact of Social Network Structure on the Diffusion of Coronavirus Disease (COVID-19): A Generalized Spatial SEIRD Model. arXiv 2020, arXiv:2010.11212. [Google Scholar]
- Zhang, X.; Zhang, Z.; Wang, W.; Hou, D.; Xu, J.; Ye, X.; Li, S. Multiplex network reconstruction for the coupled spatial diffusion of infodemic and pandemic of COVID-19. Int. J. Digit. Earth 2021, 14, 401–423. [Google Scholar] [CrossRef]
- Chen, E.; Lerman, K.; Ferrara, E. Tracking social media discourse about the covid-19 pandemic: Development of a public coronavirus twitter data set. JMIR Public Health Surveill. 2020, 6, e19273. [Google Scholar] [CrossRef] [PubMed]
- Roesslein, J. Tweepy Documentation. 2009, 5. Available online: http://tweepy.readthedocs.io/en/v3 (accessed on 20 February 2021).
- Google. Google Public Data Explorer. 2010. Available online: http://www.google.com/publicdata/home (accessed on 20 February 2021).
- NPR Elections: Presidential Results. 2020. Available online: https://apps.npr.org/elections20-interactive/ (accessed on 20 February 2021).
- Census, U.S. State Population by Characteristics: 2010–2019. 2019. Available online: https://www.census.gov/data/datasets/time-series/demo/popest/2010s-state-detail.html (accessed on 20 February 2021).
- Bureau of Economic Analysis. Gross Domestic Product by State. 2020. Available online: https://www.bea.gov/news/2021/gross-domestic-product-state-4th-quarter-2020-and-annual-2020-preliminary (accessed on 20 February 2021).
- Wikipedia. List of the Busiest Airports in the United States. 2019. Available online: https://en.wikipedia.org/wiki/List_of_the_busiest_airports_in_the_United_States (accessed on 20 February 2021).
- KFF. Population Distribution by Gender. 2017. Available online: https://www.kff.org/other/state-indicator/distribution-by-gender/?currentTimeframe=0&sortModel=%7B%22colId%22:%22Location%22,%22sort%22:%22asc%22%7D (accessed on 20 February 2021).
- KFF. Population Distribution by Race/Ethnicity. 2018. Available online: https://www.kff.org/other/state-indicator/distribution-by-raceethnicity/?dataView=0¤tTimeframe=0&sortModel=%7B%22colId%22:%22Location%22,%22sort%22:%22asc%22%7D (accessed on 20 February 2021).
- Exchange, H. 2013 AHAR: Part 1—PIT Estimates of Homelessness in the U.S. 2013. Available online: https://www.hudexchange.info/resource/3300/2013-ahar-part-1-pit-estimates-of-homelessness/ (accessed on 20 February 2021).
- Agency for Healthcare Research and Quality. Health Care Quality: How Does Your State Compare? Available online: https://www.ahrq.gov/data/infographics/state-compare-text.html (accessed on 20 February 2021).
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions; Association for Computational Linguistics (ACL): Sydney, Australia, 2006; pp. 69–72. [Google Scholar]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Rish, I. An empirical study of the naive Bayes classifier. IJCAI 2001 Workshop Empir. Methods Artif. Intell. 2001, 3, 41–46. [Google Scholar]
- Albawi, S.; Mohammed, T.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Lesh, F. Multi-dimensional least-squares polynomial curve fitting. Commun. ACM 1959, 2, 29–30. [Google Scholar] [CrossRef]
- McKinney, W. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython; O’Reilly Media, Inc.: Newton, MA, USA, 2012. [Google Scholar]
- Liao, S.; Wang, J.; Yu, R.; Sato, K.; Cheng, Z. CNN for situations understanding based on sentiment analysis of twitter data. Procedia Comput. Sci. 2017, 111, 376–381. [Google Scholar] [CrossRef]
- Sunarya, P.; Refianti, R.; Mutiara, A.; Octaviani, W. Comparison of Accuracy between Convolutional Neural Networks and Naïve Bayes Classifiers in Sentiment Analysis on Twitter. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 77–86. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Haifa, Israel, 21–25 June 2010; pp. 233–240. [Google Scholar]
- Ross, A.; Willson, V. One-sample t-test. In Basic and Advanced Statistical Tests; Brill Sense: Leiden, The Netherlands, 2017; pp. 9–12. [Google Scholar]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer Topics in Signal Processing; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar] [CrossRef]
- GeoPy: Geocoding Library for Python. 2020. Available online: https://github.com/geopy/geopy (accessed on 20 February 2021).
- Alowibdi, J.; Buy, U.; Yu, P. Empirical evaluation of profile characteristics for gender classification on twitter. In Proceedings of the 2013 12th International Conference on Machine Learning and Applications, Miami, FL, USA, 4–7 December 2013; Volume 1, pp. 365–369. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Place | Positive | Total Tweets |
|---|---|---|
| Argentina | 359 | 520 |
| Brazil | 962 | 1651 |
| India | 4796 | 8051 |
| Indonesia | 794 | 1317 |
| Peru | 216 | 307 |
| Guam | 39 | 64 |
| Vermont | 169 | 293 |
| North Dakota | 166 | 289 |
| Rhode Island | 302 | 542 |
| West Virginia | 175 | 318 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roy, S.; Ghosh, P. A Comparative Study on Distancing, Mask and Vaccine Adoption Rates from Global Twitter Trends. Healthcare 2021, 9, 488. https://doi.org/10.3390/healthcare9050488
Roy S, Ghosh P. A Comparative Study on Distancing, Mask and Vaccine Adoption Rates from Global Twitter Trends. Healthcare. 2021; 9(5):488. https://doi.org/10.3390/healthcare9050488
Chicago/Turabian StyleRoy, Satyaki, and Preetam Ghosh. 2021. "A Comparative Study on Distancing, Mask and Vaccine Adoption Rates from Global Twitter Trends" Healthcare 9, no. 5: 488. https://doi.org/10.3390/healthcare9050488
APA StyleRoy, S., & Ghosh, P. (2021). A Comparative Study on Distancing, Mask and Vaccine Adoption Rates from Global Twitter Trends. Healthcare, 9(5), 488. https://doi.org/10.3390/healthcare9050488