1. Introduction
The COVID-19 pandemic has had a significant impact on human life. The G20 Summit held in a virtual conference on March 2020 to discuss pending global issues resulting from COVID-19. Coping and confronting the pandemic includes activities such as protecting lives, protecting jobs and income, restoring trust, preserving financial stability, restoring growth, minimizing disruption of trade and global supply chains, and providing assistance to countries in need of support. COVID-19 has caused major economic losses, paralyzing national economies around the world. The International Monetary Fund (IMF) predicted that global trade volume would shrink by 10.4% on-year [
1]. The World Bank Group (WBG) is expecting that the global trade volume will drop 5.2% and to have its worst year since World War II [
2].
COVID-19 has been called a novel coronavirus (2019-nCoV), but on 11 March 2020, the World Health Organization (WHO) announced its official name as COVID-19 [
3]. On 13 February 2020, the International Committee on Taxonomy of Viruses (ICTV) officially announced the virus’ name as SARS-CoV-2. Coronavirus is a ribonucleic acid (RNA) virus that causes respiratory diseases, such as colds. It was named coronavirus because its outer skin is shaped like a crown surrounded by bumps. It causes infection in a variety of animals, including humans. The WHO classifies pandemic alarm levels from 1 to 6, according to the infectious disease risk. This pandemic corresponds to the highest warning level—6. When an infectious disease spreads worldwide and spreads across continents, it is called a pandemic. Thus far, the WHO has declared three pandemics: the Hong Kong Flu in 1968, the Swine Flu in 2009, and COVID-19 in 2020 [
4].
Until recently, the top five affected countries were as follows: the United States death toll record with 17 million, India with 10 million, Brazil with 7 million, Russia with 2.7 million, and France with 2.4 million. In terms of death rate, Mexico has the highest death rate at 9.1%, China has 5.3%, Iran has 4.7%, and Italy has 3.5%. In Korea, the cumulative number of confirmed cases is about 47,000, and the death rate is approximately 1.4% [
5].
Various studies have been conducted on past pandemic infections and disease. Guan et al. [
6] predicted the incidence of hepatitis A virus (HAV) using an auto regressive integrated moving average (ARIMA) model and an artificial neural network (ANN). Earnest et al. [
7] forecasted the number of confirmed cases by applying the ARIMA model to the number of confirmed cases per day for severe acute respiratory syndrome (SARS). By applying ARIMA to China’s HFRS data, Liu et al. [
8] predicted the incidence of hemorrhagic fever with renal syndrome (HFRS) from 2009 to 2011. Wu et al. [
9] predicted the incidence of HFRS over one year by using a hybrid model that combines ARIMA, a generalized regression neural network (GRNN), and the non-linear autoregressive neural network (NARNN) with ARIMA. Nsoesie et al. [
10] tried to predict the hantavirus pulmonary syndrome (HPS) using an ARIMA model. Chen et al. [
11] used the seasonal autoregressive integrated moving average (SARIMA) to predict the incidence of influenza in China; they found that the incidence rate varies according to region and season.
Based on past infectious diseases, research related to COVID-19 has also been actively conducted. Using a differential equation model that reflected social distancing and transmission rate as parameters, Webb et al. [
12] predicted and compared the number of confirmed cases considering the number of report and the presence of symptoms in Italy, Spain, and Korea. This demonstrates the importance of controlling COVID-19 infection through social distancing. Alakus et al. [
13] developed a prediction algorithm using deep learning and had a positive impact on clinical prediction studies of COVID-19. Pham [
14] studied the cumulative number of deaths, the mortality per capita per unit time, and the maximum total number of deaths as functions, and the solution of differential equations composed of the functions is proposed as the numerical model of COVID-19. Pham [
15] generalized by introducing a function of recovered cases to the model in [
14]. Additionally, Pham [
16] developed a new mathematical model by introducing the time-dependent effort of social restrictions—the resumption of states, wearing masks, and social distancing. Arias et al. [
17] suggested a generalized logistics regression to predict the number of cases of COVID-19.
In addition to the aforementioned methods, studies have also been conducted using the ARIMA model to estimate the spread of COVID-19, examples of which are as follows. Using ARIMA and Richard’s model, Kumar et al. [
18] conducted a study that forecast the population impact of COVID-19 in India compare goodness-of-fit for models. Petropoulos et al. [
19] predicted the number of COVID-19 patients in a short period of time using a simple time series in Denmark, Norway, and Sweden. Additionally, [
19] tracked and compared the stringency level of each country. Using the ARIMA model, Ceylan [
20] predicted the number of COVID-19 cases in Italy, Spain, and France. Alzahrani et al. [
21] forecasted the number of COVID-19 confirmed cases in Saudi Arabia for the next four weeks. Yang et al. [
22] predicted the number of cases in Italy for the next few days. Kufel [
23] presented ARIMA to forecast the rate of infection in 32 European countries over the next seven days. In addition, there is a variety of research that studies the impact of COVID-19 [
24,
25,
26,
27,
28,
29,
30].
In this paper, we apply the ARIMA model and empirical data analysis to forecast the number of confirmed COVID-19 cases in Korea. Using actual data, dividing the wave into several cases, predicting the number of cumulative confirmed cases for each case, and comparing the criteria. In doing so, we emphasize the importance of timing of forecasting to make a meaningful forecast. In particular, the period from 20 January 2020 (first confirmed case) to 26 October 2020 (the beginning of the third wave of COVID-19) is divided into five groups, which are subdivided into a total of 19 cases (the division is detailed in
Section 2).
Section 2 briefly describes the material and methods. Additionally, the current status of confirmed cases in Korea, empirical data analysis of group and case information, ARIMA models, and criteria are introduced.
Section 3 presents the analysis and results.
Section 4 concludes the paper.
2. Material and Methods
2.1. The Number of COVID-19 Confirmed Cases in Korea
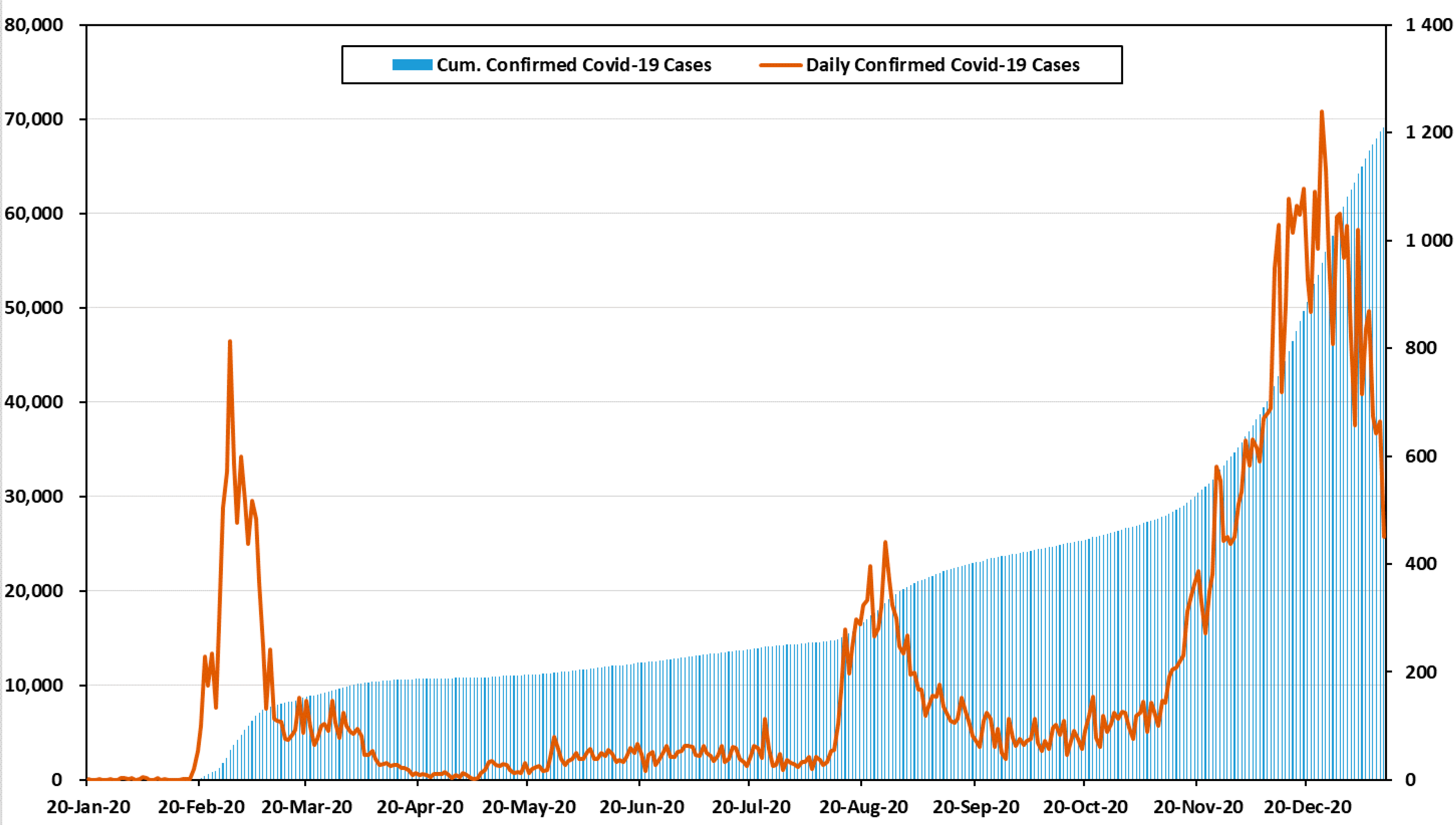
Figure 1 shows the number of confirmed cases and cumulative confirmed cases by month in Korea [
31]. On 20 January 2020, a tourist from Wuhan became the first confirmed case in Korea. Then, 11 cases were reported, bringing the cumulative number of confirmed cases to 12. In February and March, the number of confirmed cases increased sharply. The primary cause of infections was indoor religious gatherings. Within three months of the first outbreak, the cumulative number of confirmed cases reached 9887. The period between February and April 2020 is defined as the first wave of COVID-19 in Korea [
31,
32].
After the first wave, the number of confirmed cases decreased rapidly and there was a stable infection rate across the country. Nevertheless, in August and September, the second wave was generated by political rallies and church gatherings. During the second wave, the cases increased sharply, and the government raised social distancing to level 2. There were 2757 cases in October, which was only slightly lower than in September. This period showed a stable infection rate, in comparison to other waves, but it included the day with the largest increase in confirmed cases; this study did not thoroughly address the third wave, because it is still underway [
31,
33].
From November to present, the number of confirmed cases increased rapidly again. This is defined as the third wave. In November, the total number of cases was 8017. Small gatherings among families and friends accounted for more than 20% of the third wave’s infections. Some of the provincial governments decided to raise the social distancing level to 2.5, which is the second highest. Worst of all, the confirmed cases in Seoul are being housed in retrofitted containers because of hospital bed shortages. The government and citizens fear the need to raise social distancing to level 3 [
31,
34].
All information related to confirmed cases in this paper was provided by the government and was aggregated daily at midnight (00:00) [
31].
2.2. Information of Groups and Cases Using Empirical Data Analysis
2.2.1. Empirical Data Analysis
Empirical analysis is an evidence-based approach to the study and interpretation of information. The empirical approach relies on real-world data, metrics, and results, rather than theories and concepts. Empirical analysis is a common approach used to study probable answers through quantified observations of empirical evidence. However, empirical analysis never gives an absolute answer, only the most likely answer based on probability.
We can formulate the increasing number of confirmed cases of COVID-19 as follows:
where
illustrates the increasing number of confirmed cases of COVID-19 during the time interval
. Then,
is the observed cumulative number of confirmed cases of COVID-19 over time
. Therefore,
denotes the observed cumulative number of confirmed cases of COVID-19 over time
. Given different values of
, we are interested in investigating the pattern of
.
2.2.2. Information of Groups and Cases
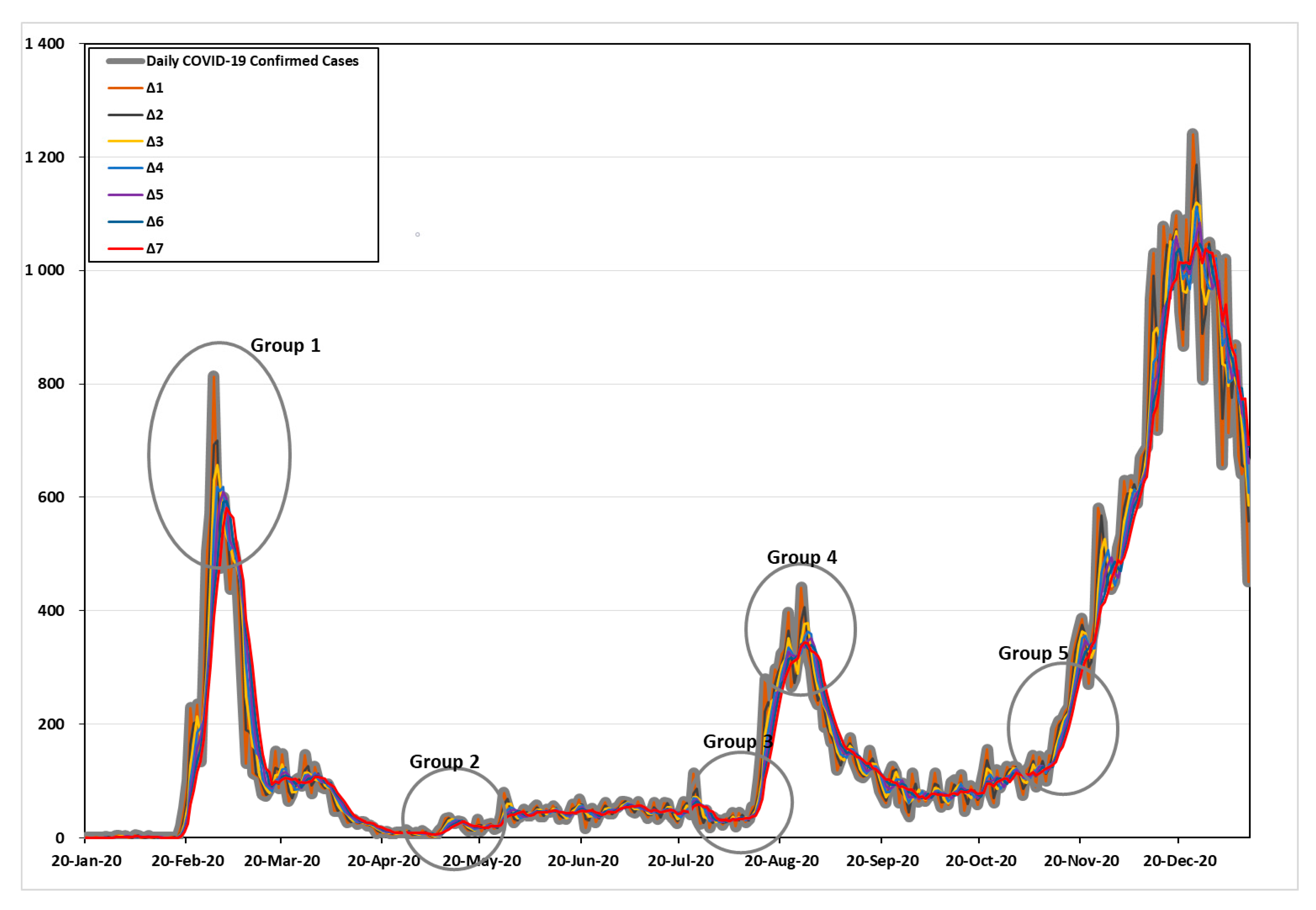
Figure 2 shows the increasing number of confirmed cases of COVID-19 during the time interval
. As shown in
Figure 2, the five points of high variability were divided and examined in detail. The criteria for defining the five groups are as follows: Group 1 and Group 4 were based on the day when the number of confirmed cases per day was the highest in the first and second waves. Group 2 was based on the day when the number of confirmed cases was the lowest. Last, Group 3 and Group 5 were based on the days with the greatest variability (the point at which more than 100 confirmed cases began to appear), which signaled the beginning of the second and third waves.
Details can be found in
Table 1. In Group 1, with the time interval
, the maximum frequency was 813 cases (28 February 2020), the time intervals
= 2–4 were 699.5, 656.7, and 618.8 cases (29 February 2020), and the time internals
= 4–5 were 618.8 and 609.2 cases (2 March 2020). Time internals
= 6–7 were 593.7 and 581.0 cases (3 March 2020) in the first wave of the COVID-19 pandemic, respectively.
In Group 2, with the time interval , 2, and 7, the minimum frequencies were 2, 2.5, and 6.4 cases (5 May 2020). The time intervals –4 and 6–7 were 3, 4.3, 6, and 6.4 cases (6 May 2020), and the time intervals was 5.8 cases (7 May 2020), respectively.
In Group 3, with the time interval , the frequency with high variability (based on more than 100 cases) was 103 cases (13 August 2020). The time intervals = 2–3 were 134.5 and 108.3 cases (14 August 2020). The time internals = 4–7 were 151, 131.6, 115.3, and 102.9 cases (15 August 2020) before the second wave of the COVID-19 pandemic, respectively.
In Group 4, with the time interval , the maximum frequency was 441 cases (26 August 2020). The time intervals and 6–7 were 406, 345.8, and 343.9 cases (27 August 2020). The time internals = 3–4 were 378.3 and 363.8 cases (28 August 2020). Time internals was 350.8 cases (29 August 2020) in the second wave of the COVID-19 pandemic.
In Group 5, with the time interval = 1–2, the frequency with high variability (based on more than 100 cases) was 119 and 105 cases (21 October 2020). The time intervals = 3–4 were 121.7 and 105.8 cases (22 October 2020). The time internals was 100 cases (23 October 2020); the time internals was 103.7 cases (25 October 2020); and the time internals was 101.4 cases (26 October 2020) before the third wave of the COVID-19 pandemic, respectively.
As shown in
Table 2, we set cases by date for forecast analysis based on the time point mentioned in each group. In addition, it was used for predictive analysis using the data up to the mentioned time point.
2.3. Time Series
In the autoregressive (AR) model, the partial autocorrelation coefficient (PAC) had a significant spike, and the autocorrelation coefficient (AC) decreased in sequence. In this case, the order of AR (p) is determined based on the number of significant spikes of the PAC. The formula for the AR (p) model is as follows:
Unlike AR, in the moving average (MA) model, the AC has a significant spike. The PAC decreases in sequence, and the order q of the MA model is determined based on the number of significant spikes of the AC. The formula for the MA (q) model is as follows:
The autoregressive moving average (ARMA) model shows a form of sequentially decreasing in both the AC and the PAC. The formula is as follows:
where
is called the error or white noise. The
is assumed to be independently normal distribution. The ARIMA model converts a non-stationary time series data into a stationary time series that is expressed as ARIMA (p,d,q), where p is the order of the AR model, d is the differencing order, and q is the order of the MA model. For example, AR (1) is equivalent to ARIMA (1,0,0), and MA (2) is equivalent to ARIMA (0,0,2).
There is no clear trend in the stationary time series, and the average and variance are constant over time. In the case of a known time series analysis model, analysis is possible when the data is in the form of time series data that shows normality without trend or seasonality. In the case of data having a long period, a trend with a sudden and unpredictable change in direction, or data showing seasonality, the analysis is conducted after making the data in the form of a stationary time series through the difference using the difference between observed values. To check whether it is a normal time series or a non-stationary time series, check through a sequence chart or ACF (auto correlation function) [
35].
This paper dealt only with the ARIMA (p,2,q) model. In general, a non-stationary time series becomes a stationary time series by a first or second differencing. In the data of this study, when the difference was 0 or 1, the sequence chart had an inconsistent form of mean and variance, and it can be seen that the ACF had an abnormal time series in the form of slowly decreasing. When the difference was 2, the mean and variance appeared in a certain form, indicating that the time series was normal.
When , the cumulative number of confirmed cases predicted by the ARIMA model, gradually decreased or showed a negative value, which is a contradiction. However, when , the predicted value of the cumulative cases increased stably, so the ARIMA (p,2,q) model was used.
2.4. Criteria for the Comparion of Goodness-of-Fit
To compare the goodness-of-fit by ARIMA for each case, the following four criteria were used:
First, root mean square error (RMSE) is as follows:
Second, mean absolute error (MAE) is as follows:
Third, mean absolute percentage error (MAPE) is as follows:
Finally, the sum of square error (SSE) is as follows:
Here, is the difference (error) between the actual cumulative number of cases and the predicted value of the ARIMA model at time . Additionally, is the length of time . The SSE was calculated as the difference between the predicted values and the data for 14 days—two weeks from the end of the truncated case. The smaller the values of all four criteria mentioned above, the better the fit, relative to other models.
3. Results
For the data set, the time series method was applied to compare the criteria of each section using SPSS 25 (IBM, Armonk, NY, USA). The ARIMA (p,d,q) models were fitted p = 0, 1, …, 5, d = 2, q = 0, 1, …, 5 for 19 cases, with 684 models to be compared. Among them, only the top six models of each case were selected based on the RMSE.
3.1. Prediction of Cumulative Confirmed Cases of COVID-19 by Group and Case Using ARIMA
3.1.1. Comparison of Goodness-of-Fit by Group and Case
As can be seen in
Table 3, in case 1, the RMSE of ARIMA (5,2,5) was 41.181, which was closer to the actual data than other models. In addition, the MAE of the model was 21.819, which was the smallest of all models. The MAPE of ARIMA (3,2,3) was 170.642, which was the smallest among case 1. In case 2, the RMSE and MAE of ARIMA (5,2,5) were the smallest. Based on MAPE, the value of ARIMA (4,2,2) was the closest to the actual data. In Cases 3 and 4, all criteria of ARIMA (5,2,5) appeared to be predictive models with the best descriptive.
As can be seen in
Table 4, in case 5, the RMSE of ARIMA (2,2,5) was 56.172, which was the smallest among case 5. Based on MAPE, the value of ARIMA (1,2,5) was 5.741, which was the smallest. The MAE of ARIMA (5,2,5) was 27.800, which was the smallest. In case 6, based on the RMSE, the value of ARIMA (2,2,5) was 55.895, which was the smallest. The MAPE of ARIMA (3,2,5) was 5.668, which appeared to be a predictive model with the best descriptive. The MAE of ARIMA (5,2,5) was 27.637, which was the smallest. In case 7, the RMSE and MAPE of ARIMA (2,2,5) were the closest among case 7, and the MAE of ARIMA (5,2,5) was the smallest of all the models.
As can be seen in
Table 5, in case 8, the RMSE and MAE of ARIMA (2,2,5) were the closest among case 8. The MAPE of ARIMA (3,2,5) was 3.324, which was the smallest among the other models. In case 9, the RMSE of ARIMA (2,2,5), the MAPE of ARIMA (4,2,5), and the MAE of ARIMA (3,2,5) were 41.912, 3.658, and 21.489, which were the closest to the actual data in comparison to the other models. In case 10, the RMSE of ARIMA (2,2,5) was 42.796, which was the closest to the others. The MAPE of ARIMA (2,2,3) and the MAE of ARIMA (5,2,4) appeared to be predictive models with the best goodness-of-fit.
As can be seen in
Table 6, in case 11, the RMSE of ARIMA (5,2,5) was 44.253, which was closer to the actual data than the other models. Based on the MAPE and MAE, the values of ARIMA (3,2,5) were the closest among case 11. In case 12, the RMSE of ARIMA (3,2,5) was 44.405, which appeared to be the best predictive value. The MAPE of ARIMA (1,2,5) was 4.467, which was the smallest. The MAE of ARIMA (4,2,5) was 23.207, which was the closest to the others. In cases 13 and 14, the RMSE and MAPE of ARIMA (3,2,5) provided the best fit. Based on MAE, ARIMA (4,2,4) appeared to be a predictive model with the best fit.
As can be seen in
Table 7, in case 15, the RMSE and MAE of ARIMA (3,2,5) provided the best fit. The MAPE of ARIMA (2,2,5) was 2.495, which was closer to the actual data than the other models. In case 16, the RMSE and MAE of ARIMA (4,2,5) provided the best fit. The MAPE of ARIMA (4,2,4) was 2.609, which predicted significantly better results than the others. In case 17, as in case 15, the RMSE and MAE of ARIMA (3,2,5) show the best fit. The MAPE of ARIMA (1,2,5) was the smallest. In case 18, all criteria of ARIMA (3,2,5) provided the best fit among the other models. In case 19, as in case 15, the RMSE and MAE of ARIMA (3,2,5) were predictive with the best fit. The MAPE of ARIMA (5,2,2) was 2.386, which was the closest to the actual data.
3.1.2. Comparison of Predictive Value by Group and Case
Table 8 describes the results of the ARIMA models for each group and case, based on SSE. Here, note means the time interval, including the variability (maximum, minimum, and high variability of the point at which more than 100 confirmed cases began to appear), elapsed from the base date of each group.
As can be seen in
Table 8, in Group 1, the SSE of ARIMA (4,2,5) for case 2 was 138,245,907, which was significantly smaller than the others. In Group 2, the SSE of ARIMA (5,2,5) for case 7 was 21,750, which was the smallest. The SSE of ARIMA (1,2,5) for case 10 in Group 3, ARIMA (4,2,5) for case 14 in Group 4, and ARIMA (2,2,5) for case 17 in Group 5 were the closest to actual data compared to the other models in the same group. We confirmed that the analysis should be performed taking into account the time interval of the last five days or more, including the maximum, minimum, and high variability (when more than 100 confirmed cases started to appear).
For reference, it was confirmed that the analysis should be performed taking into account the time interval of the last five days or more, including the maximum, minimum, and high degeneration (when more than 100 confirmed cases started to appear).
Note the consideration of the maximum, minimum, and expensive modification, (a confirmed case is the time more than 100 people begin to appear) over the last five days, confirmed that this analysis should be done.
Based on the note above, of the best model in Group 1 was 2, 3, and 4, a period that was the initial period of the COVID-19 outbreak. Thus, its data was small; was smaller than other groups. In Groups 2, 4, and 5, the values of the best models for each group were 5. In Group 3, of the best model was 4, 5, 6, and 7 and the minimum was 4. That is, we found that the best prediction in Group 3 was to analyze it using the data up to the point of high variability (minimum and maximum) over four days. Except for Group 1, which was unstable due to low data, the remaining groups were required to predict using the data up to the point of high variability (minimum and maximum) for the last five days.
3.2. Results of Fitting and Forecasting for the Latest Period Using ARIMA
The ARIMA model was fitted to the data set of confirmed COVID-19 cases, including the data set from the latest period of the third wave outbreak (up to 27 December 2020). As in
Section 3.1.1, ARIMA (p,d,q) models were fitted p = 0, 1, …, 5, d = 2, q = 0, 1, …, 5 for 19 cases.
Table 9 lists the top 10 based on the RMSE among the fitted ARIMA models.
Based on the RMSE, ARIMA (3,2,5) provides the best fit, the value was 53.031. Additionally, the MAE of the model was 29.780, the closest to actual model than others. Compared to other models based on MAPE, the value of ARIMA (1,2,5) was 3.860, appeared to be the best predictive model. The model with the least SSE in each group in
Table 8 also had smaller RMSE, MAPE, and MAE values compared to cases in the same group. Therefore, we estimated the predicted values and 95% confidence intervals over the next 14 days for the best models, ARIMA (3,2,5) and ARIMA (1,2,5) based on three criteria.
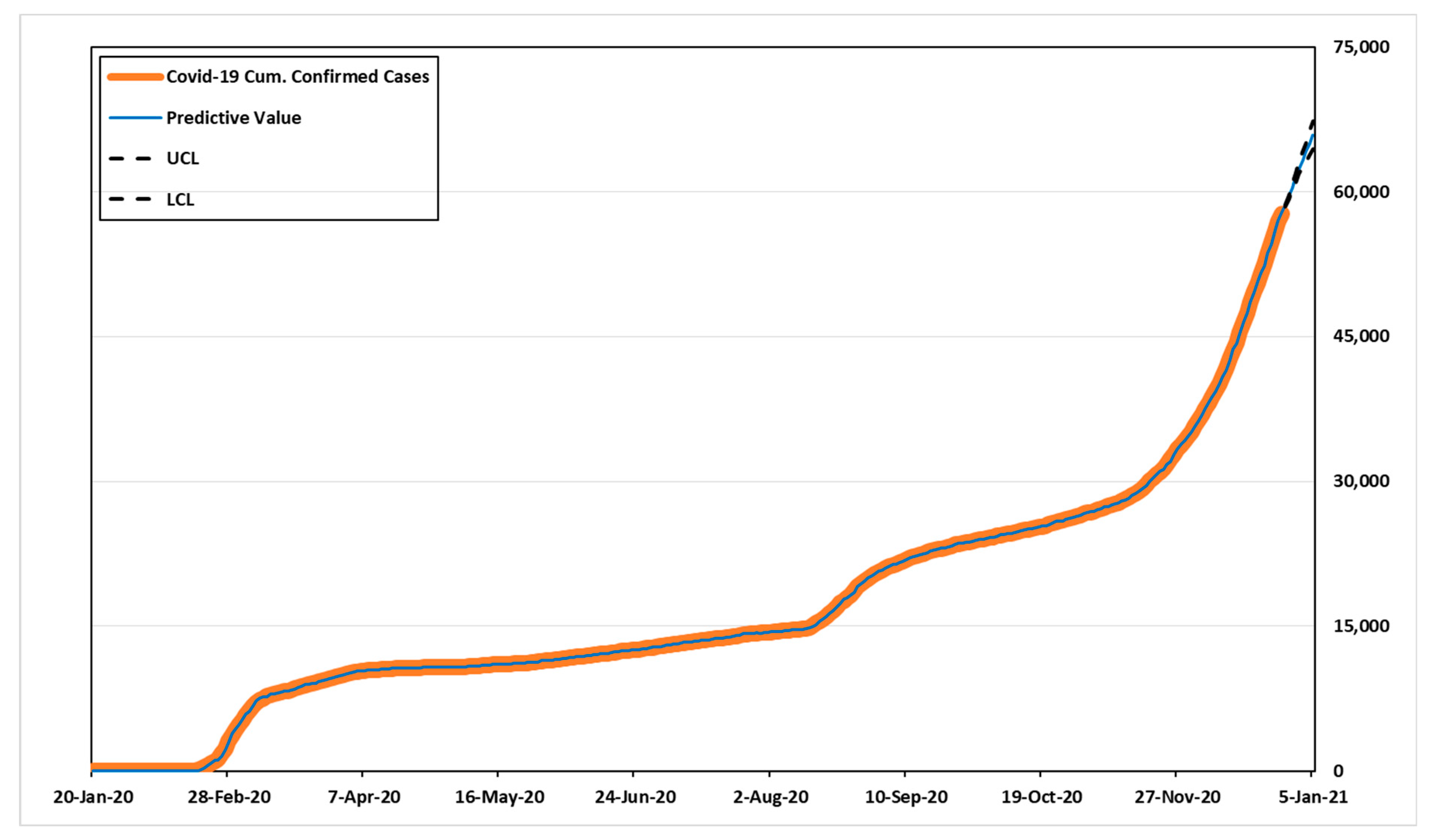
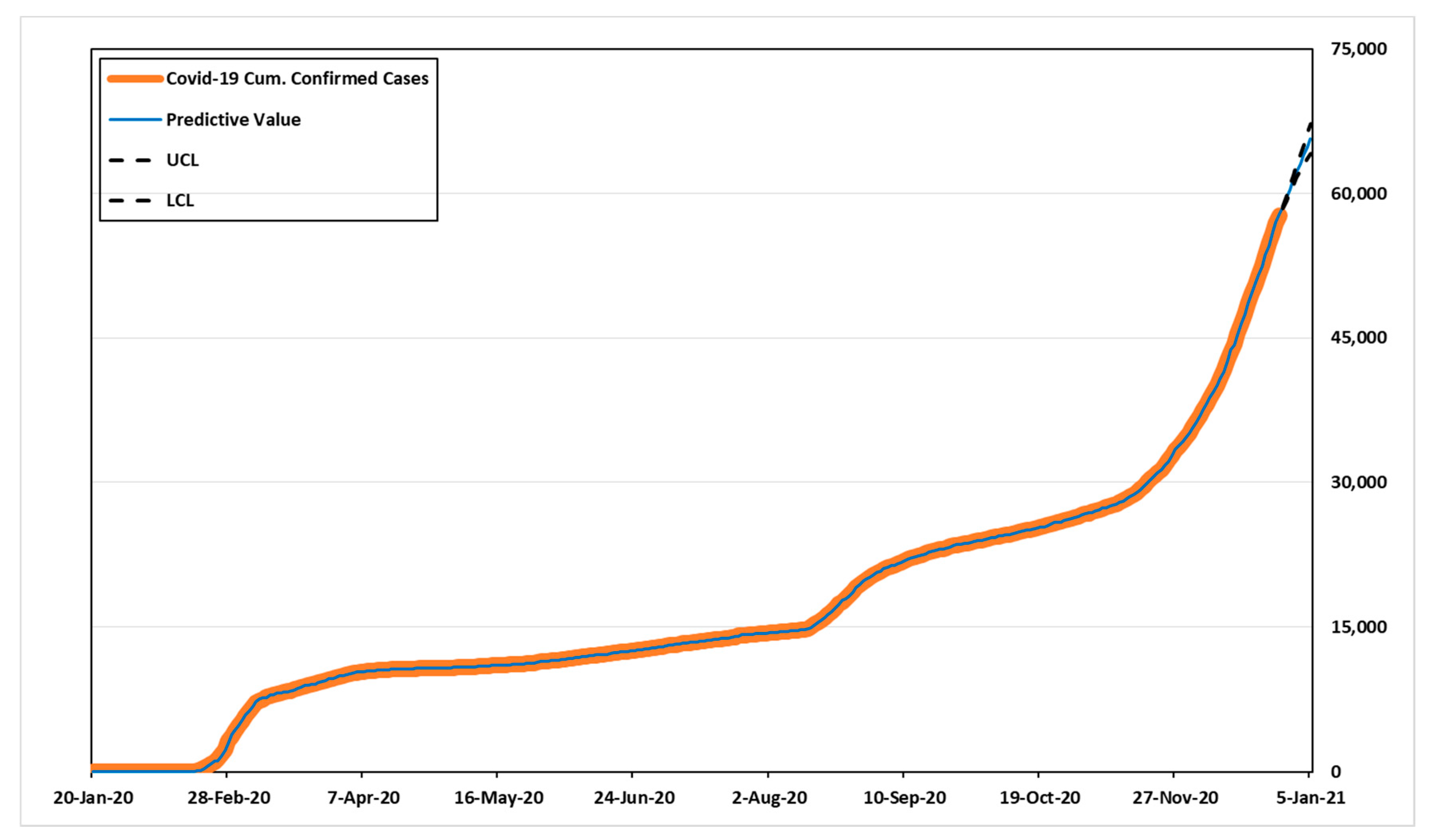
Table 10 shows the predicted values, UCL (upper confidence limit), and LCL (lower confidence limit). According to
Table 10, the number of cumulative confirmed cases for the next 14 days might be 58,532–70,389 in ARIMA (3,2,5), and 58,533–69,877 in ARIMA (1,2,5).
Figure 3 and
Figure 4 show the predicted values, 95% confidence intervals, and actual data values for each model.
4. Discussion
In
Section 3, we used ARIMA to compare the criteria of each case using data sets from Korea. The period between 20 January to 26 October 2020 was divided into five based on (1) peak of the first wave; (2) the day when the increase in confirmed cases is at its minimum; (3) the day when the variability of the confirmed case is high before the peak of the second wave; (4) peak of the second wave; and (5) the day when the variability of the confirmed cases is high before the peak of the third wave.
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7 show the top six results by comparing the goodness-of-fit of the ARIMA model for each group and case, and
Table 8 shows the top five results based on SSE to examine the predicted values.
In general, if the goodness-of-fit is high, the predicted value is thought to be high, but the results were different. As can be seen from the note of the results in
Table 8, the SSE value of the ARIMA model derived using
5 was significantly lower than that of other models.
It is recommended because it performs much better at predicting the number of confirmed cases using data at each point in time of the time interval 5, i.e., the average data of 5 days. By predicting the number of confirmed patients based on the results of analysis at various points in time using empirical data analysis and the ARIMA model using it, it is possible to preemptively respond to the variability (increase, decrease, rapid increase, etc.) of the number of confirmed patients through daily updates.
Additionally, in Korea, since the case definition is clear and data collection is almost in real time, the predictive power of the ARIMA model is relatively excellent and stable. There were unpredictable events due to the blind spot, but the blind spot is expected to gradually decrease due to the learning effect and preemptive examination on the similar exposure pathway. In addition, they successfully conducted a blind test as a way to cope with the phenomenon of avoiding tests due to social stigma, and there is a foundation for imposing legal sanctions in case of false reports on the route of infection. Prediction through the ARIMA model provides an important basis for KDCA to predict the necessary severe disease constant and prepare it in advance. In Korea, the proportion of public medical services is small, so the number of beds that can treat critically ill patients is limited. This is because it takes time to secure the number of severe illnesses by seeking cooperation from the private medical field. The accuracy of the prediction model is expected to improve as data is accumulated. However, there is a need for a model that can reflect the effects of external factors such as the effect of policy measures such as adjustment of the quarantine stage and the influx of mutant viruses.
5. Conclusions
This study aimed to suggest an appropriate prediction time point to significantly predict the number of confirmed cases. To significantly predict the number of confirmed COVID-19 cases in Korea, we proposed it should be analyzed and predicted using data at each point in time of the time interval 5, i.e., the average data of 5 days. Forecasting at this time can clearly confirm whether the number of cases will increase or decrease in the future.
The ARIMA model was fitted using the most recent data in progress for the third wave. As a result of predicting the number of cumulative confirmed cases for the next 14 days based on the best models of each criterion, the number of cumulative confirmed cases by the beginning of next year was expected to reach 70,000. Currently, Korea has a shortage of hospital beds. The results are expected to effectively estimate at the point the number of beds required by predicting variability (decrease and, increase) and the number of confirmed cases. In addition, this study is expected to help the government and Korea Disease Control and Prevention Agency (KDCA) to respond systematically to a future surge in confirmed cases.
However, it is difficult to accurately predict the changing cases, because various factors affect the increase in the number of confirmed cases. Furthermore, the influence of mass inflection is large. Therefore, it is necessary to study various techniques, such as reinforcement of machine learning, modeling research based on deep learning, and the application of prediction algorithms.








{kind=link}
{kind=link}
{kind=link}
{kind=link}