
DeepDRG: Performance of Artificial Intelligence Model for Real-Time Prediction of Diagnosis-Related Groups

 ,
,  ,
,
Abstract
:1. Introduction
2. Literature Review
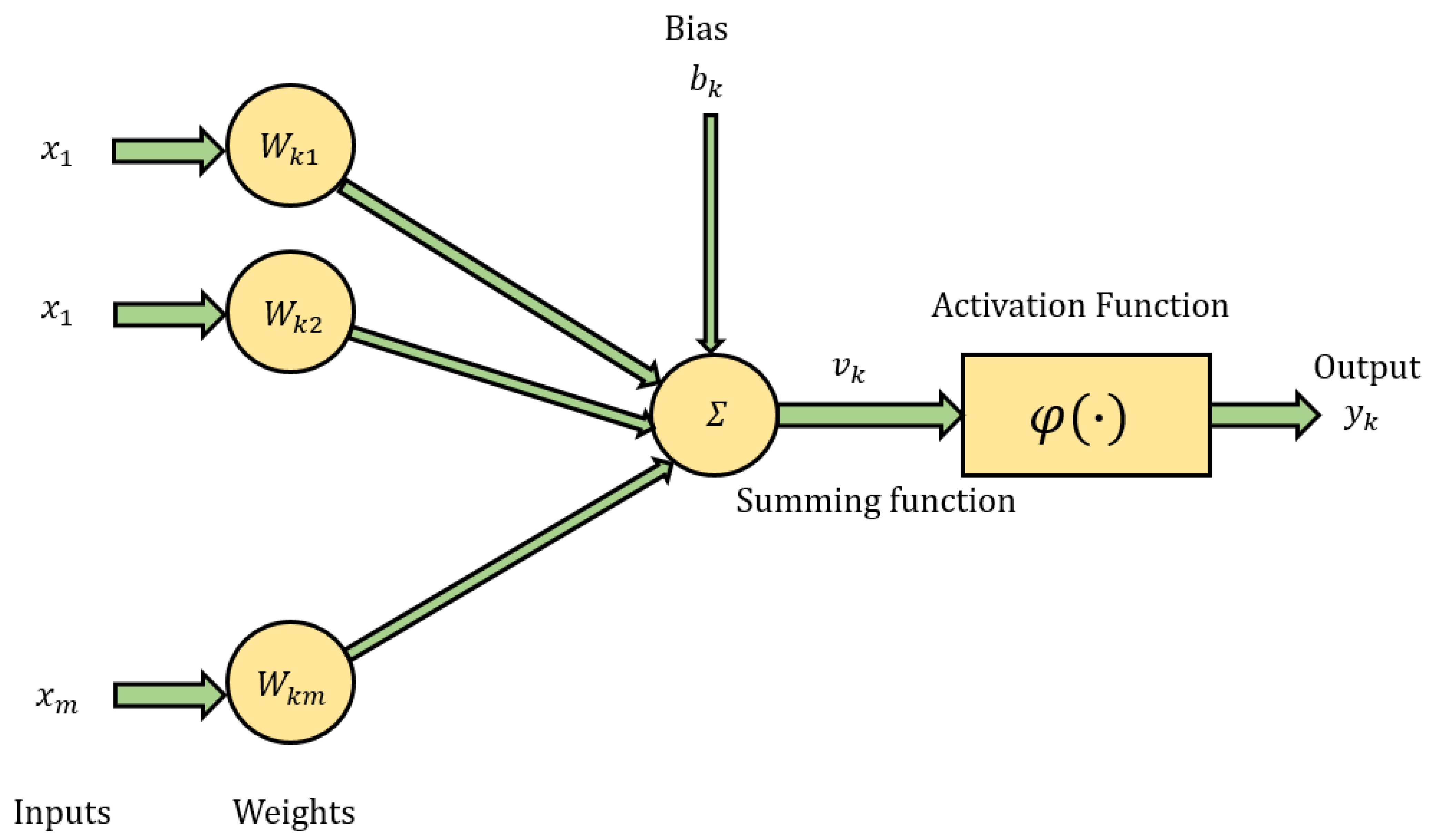
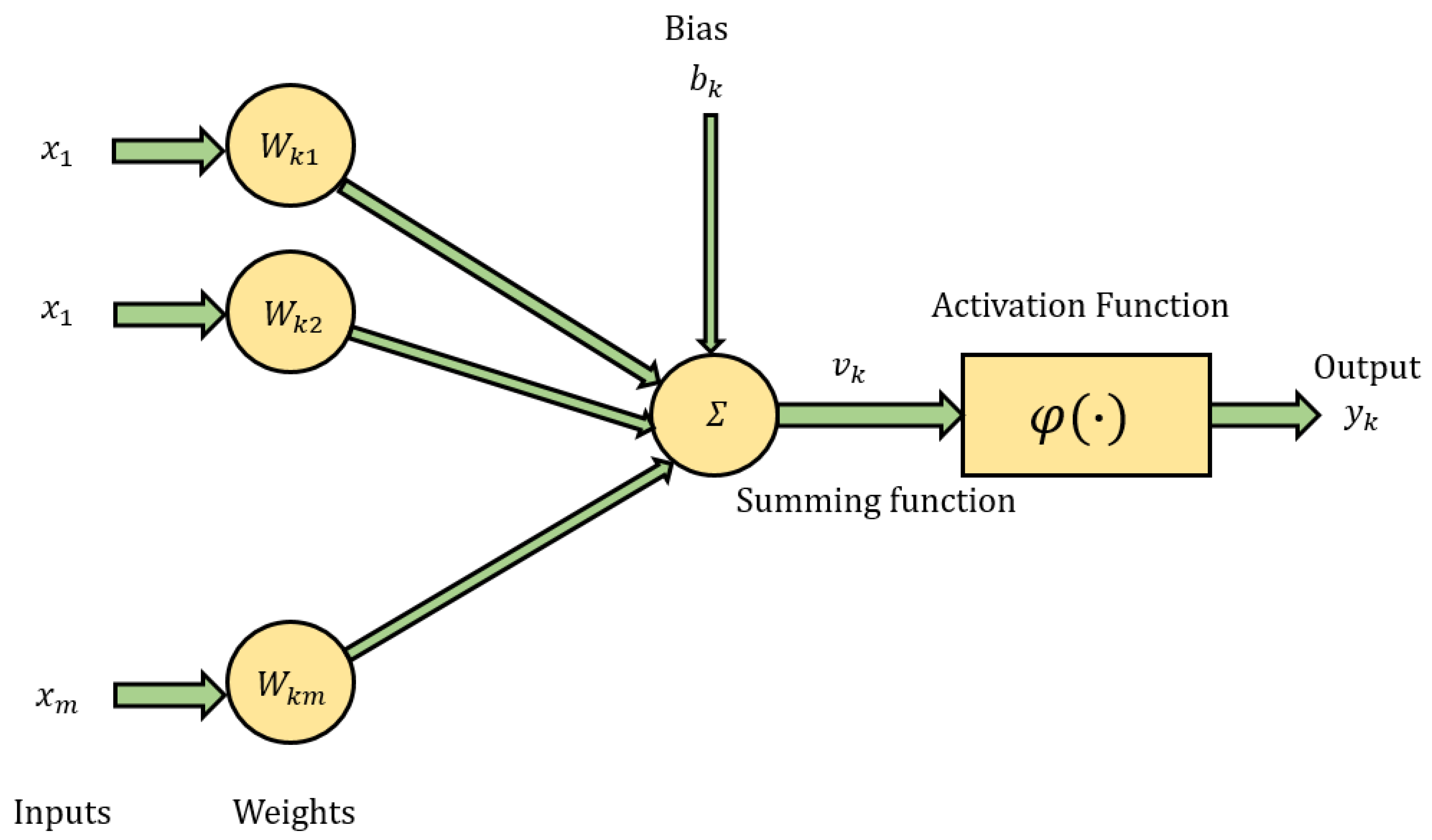
2.1. Artificial Neural Networks
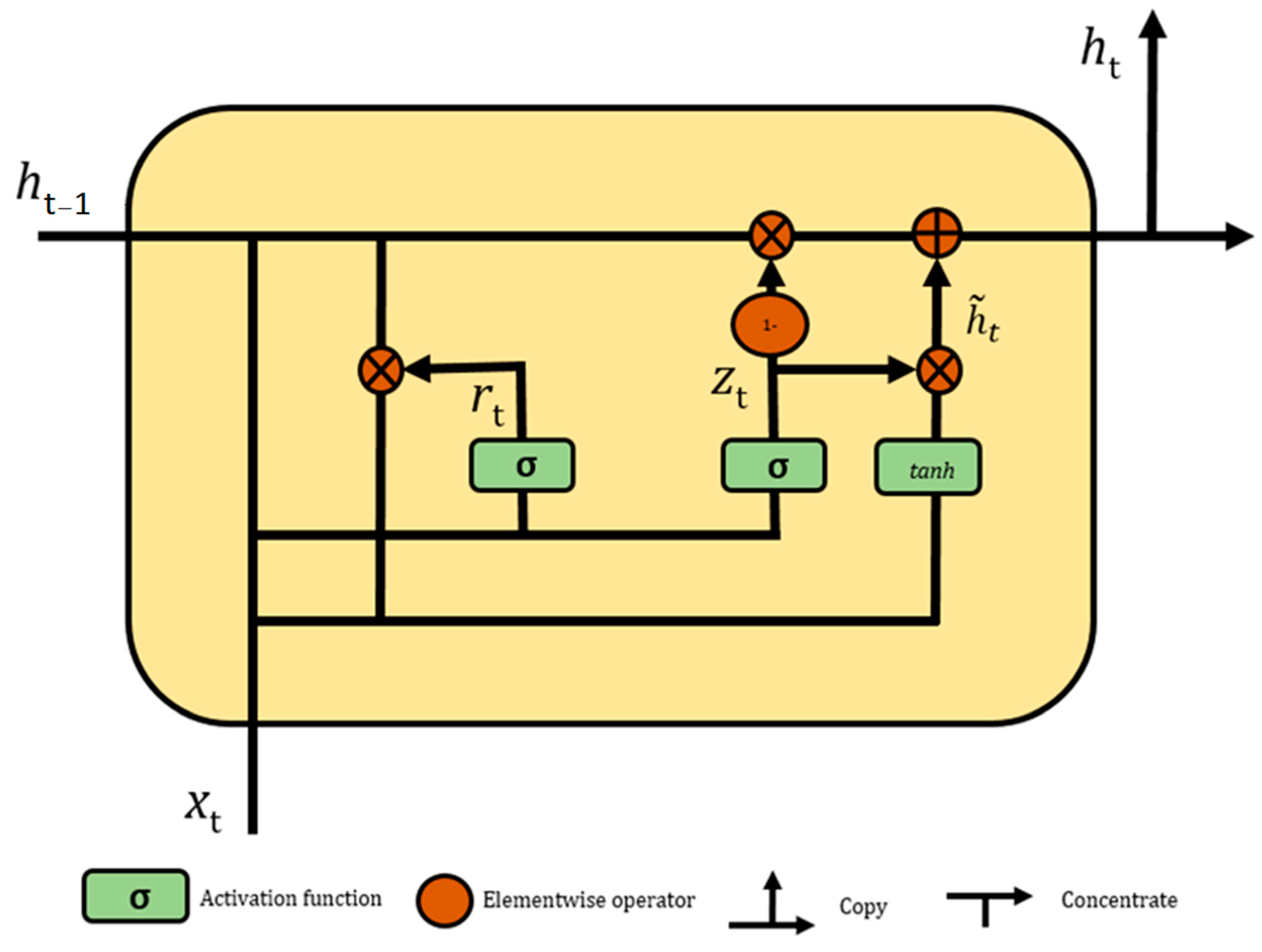
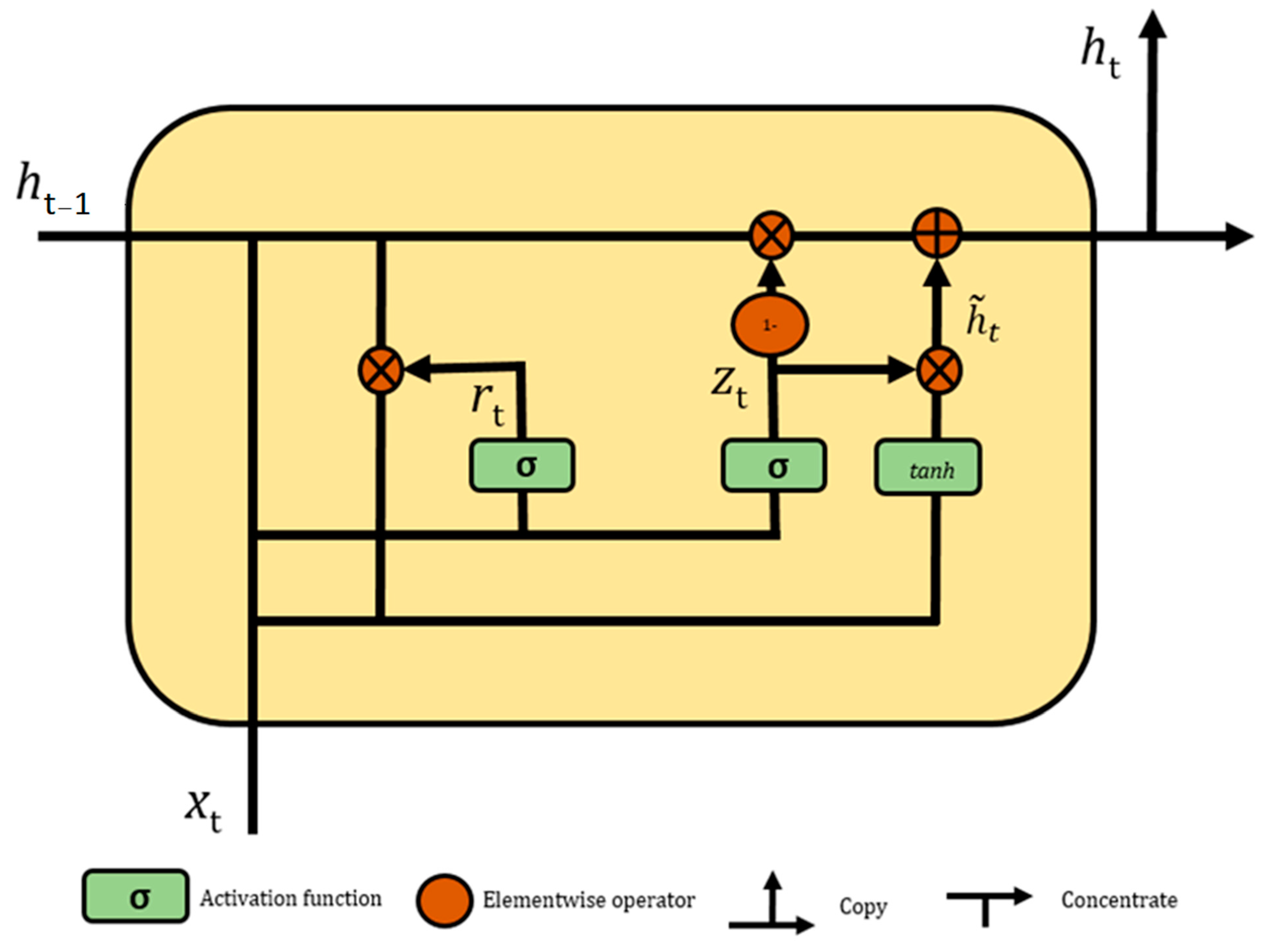
2.2. Gated Recurrent Unit
3. Materials and Methods
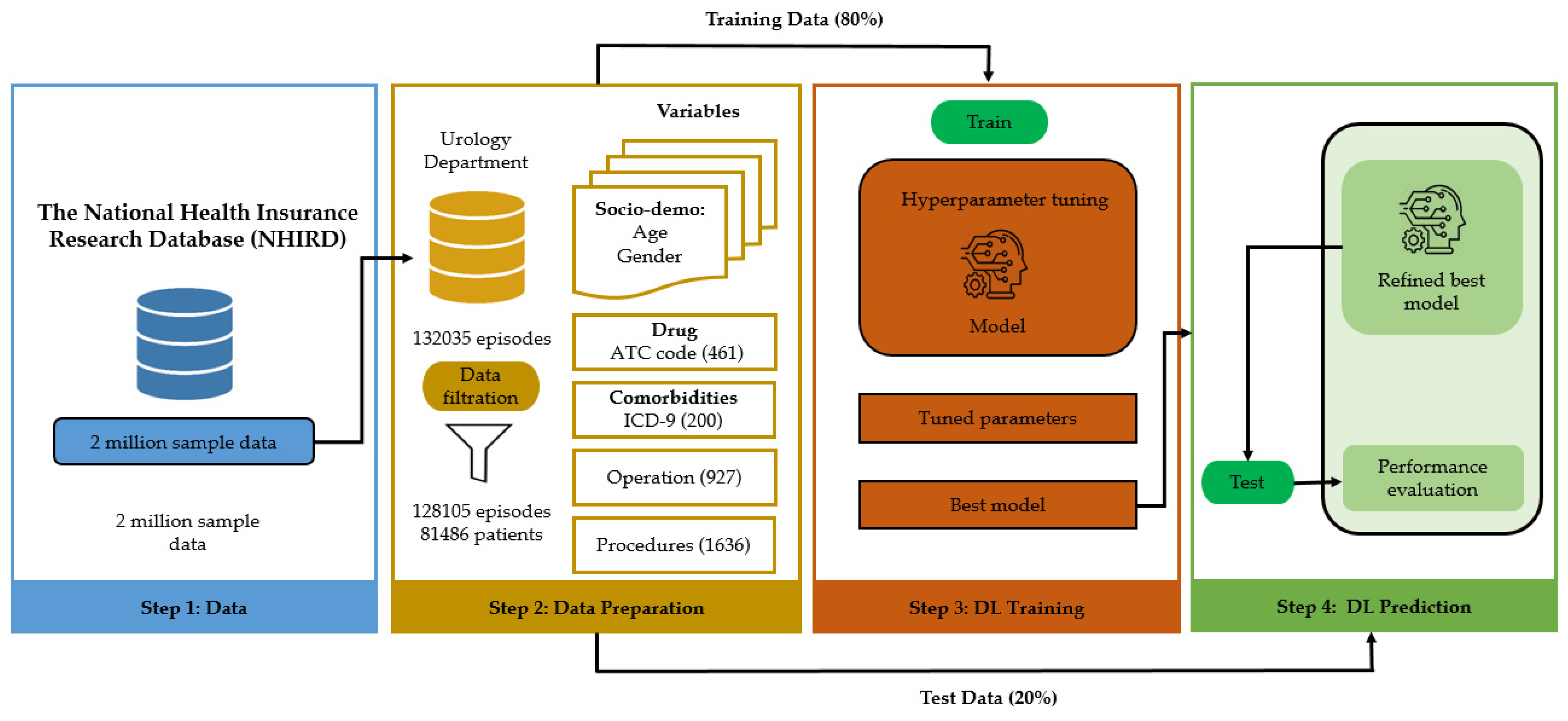
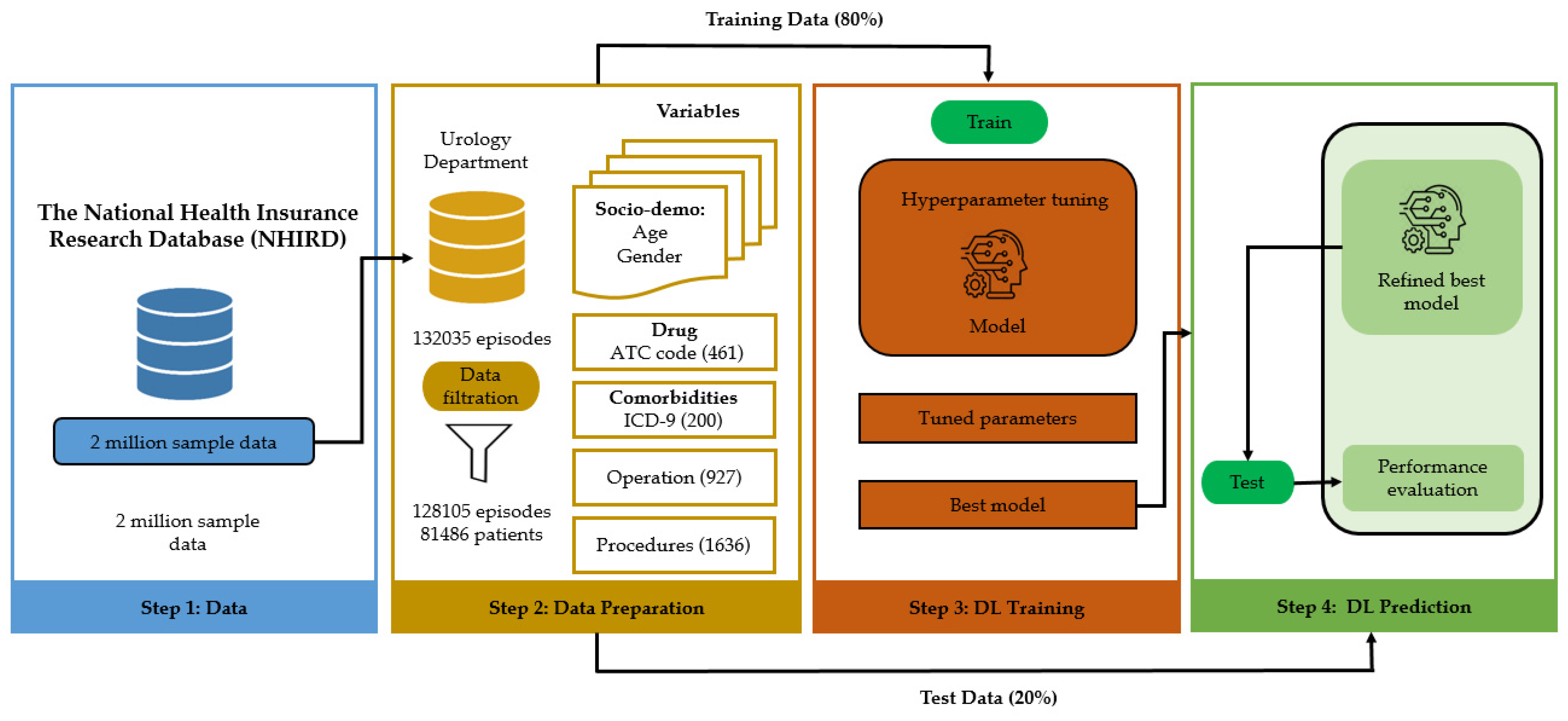
3.1. Study Approval and Propose Methodology
3.2. Data Source
3.3. Data Descriptions
3.4. Data Preprocessing
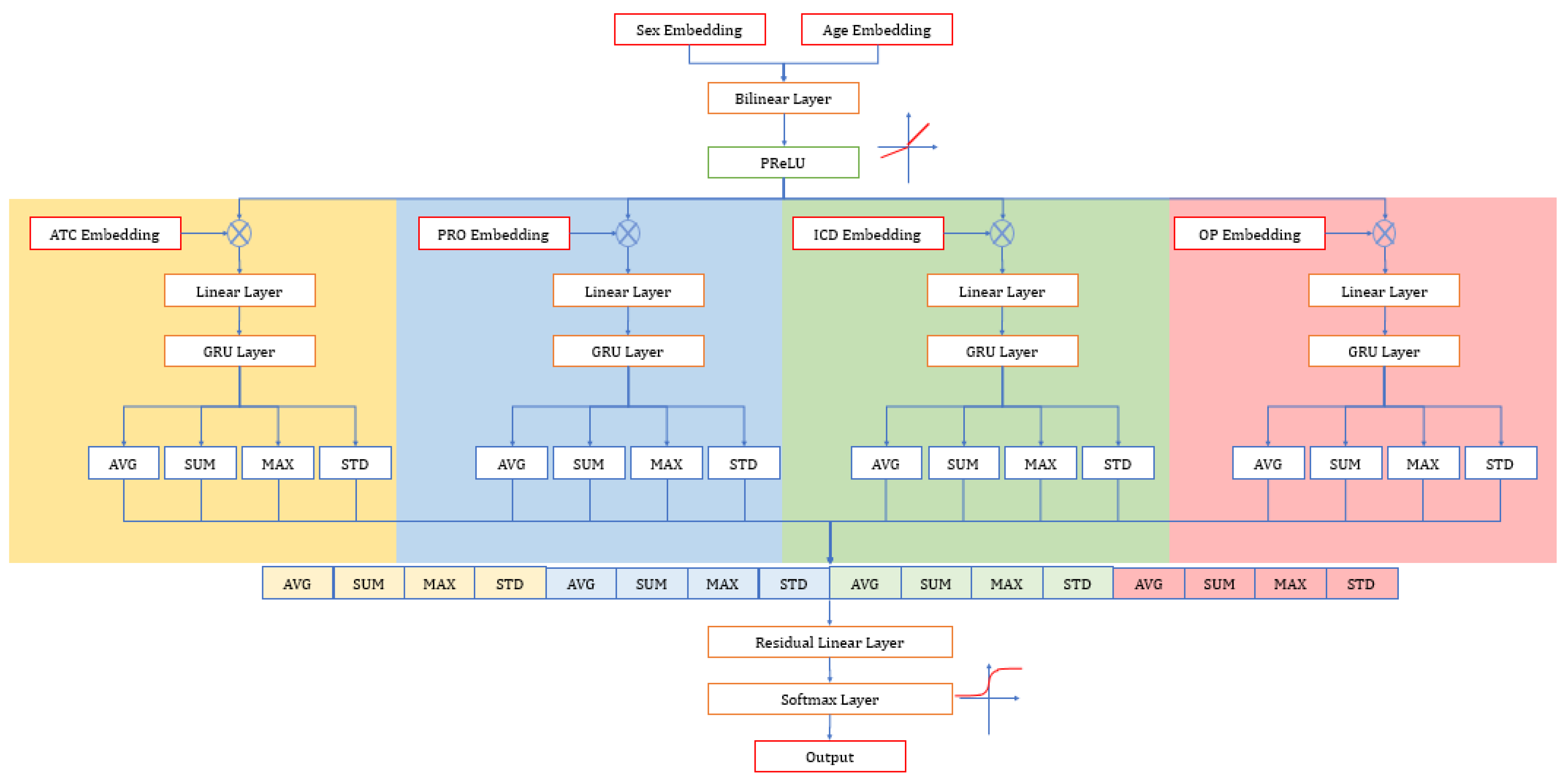
3.5. Model Development
3.6. Evaluation Matrices
4. Results
4.1. Patient Characteristics
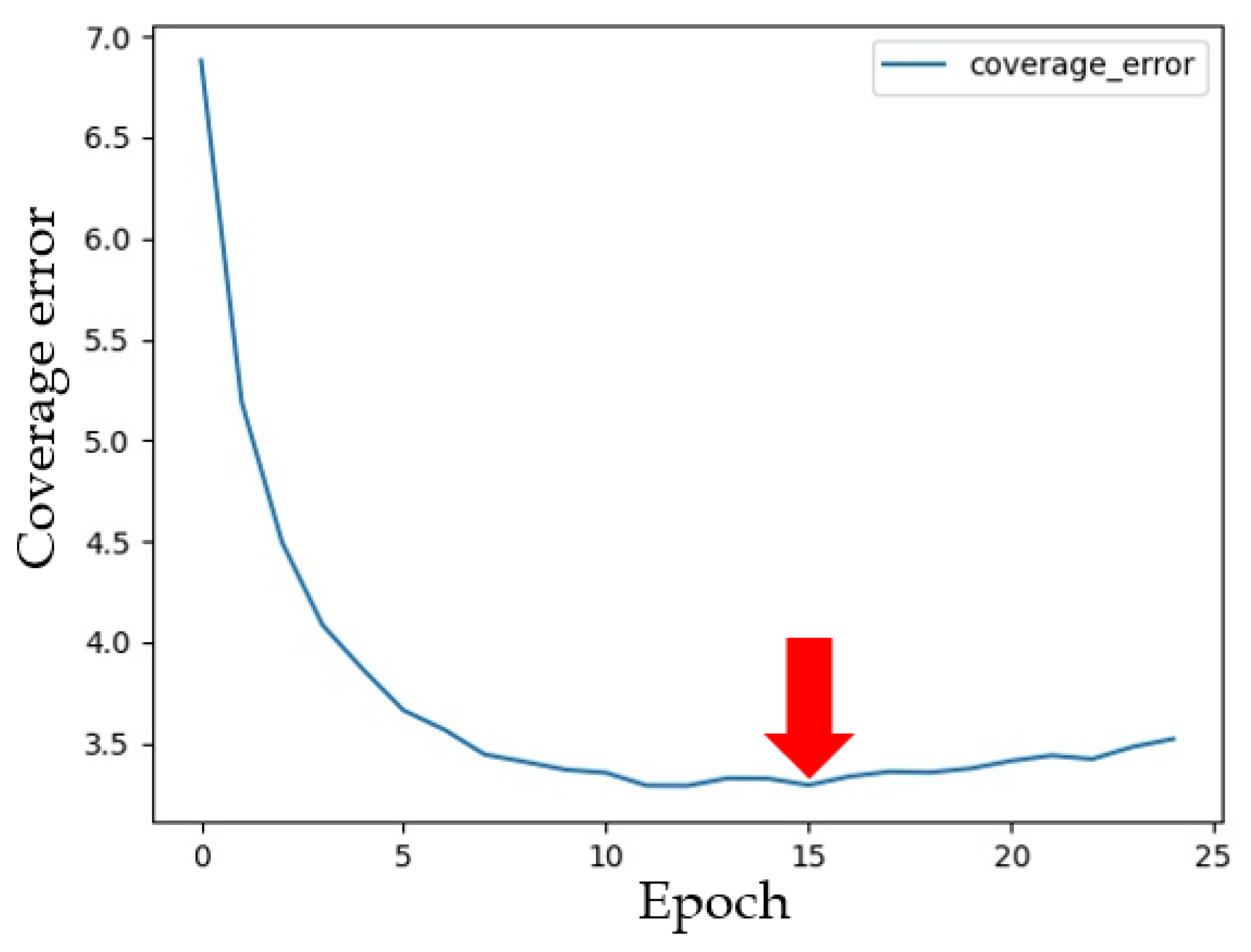
4.2. Performance of Deep Learning Model
4.3. Sensitivity Analysis
4.4. Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Muka, T.; Imo, D.; Jaspers, L.; Colpani, V.; Chaker, L.; van der Lee, S.; Mendis, S.; Chowdhury, R.; Bramer, W.; Falla, A.; et al. The global impact of non-communicable diseases on healthcare spending and national income: A systematic review. Eur. J. Epidemiol. 2015, 30, 251–277. [Google Scholar] [CrossRef]
- Bayati, M.; Mehrolhassani, M.H.; Yazdi-Feyzabadi, V. A paradoxical situation in regressivity or progressivity of out of pocket payment for health care: Which one is a matter of the health policy maker’s decision to intervention? Cost Eff. Resour. Alloc. 2019, 17, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Jung, Y.W.; Pak, H.; Lee, I.; Kim, E.H. The Effect of Diagnosis-Related Group Payment System on Quality of Care in the Field of Obstetrics and Gynecology among Korean Tertiary Hospitals. Yonsei Med. J. 2018, 59, 539–545. [Google Scholar] [CrossRef]
- Chien, T.-W.; Lee, Y.-L.; Wang, H.-Y. Detecting hospital behaviors of up-coding on DRGs using Rasch model of continuous variables and online cloud computing in Taiwan. BMC Health Serv. Res. 2019, 19, 630. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schwartz, A.L.; Chernew, M.E.; Landon, B.E.; McWilliams, J.M. Changes in Low-Value Services in Year 1 of the Medicare Pioneer Accountable Care Organization Program. JAMA Intern. Med. 2015, 175, 1815–1825. [Google Scholar] [CrossRef] [PubMed]
- Mihailovic, N.; Kocic, S.; Jakovljevic, M. Review of diagnosis-related group-based financing of hospital care. Health Serv. Res. Manag. Epidemiol. 2016, 3, 2333392816647892. [Google Scholar] [CrossRef] [Green Version]
- Mathauer, I.; Wittenbecher, F. Hospital payment systems based on diagnosis-related groups: Experiences in low- and middle-income countries. Bull. World Health Organ. 2013, 91, 746–756A. [Google Scholar] [CrossRef]
- Busse, R.; Geissler, A.; Aaviksoo, A.; Cots, F.; Häkkinen, U.; Kobel, C.; Mateus, C.; Or, Z.; O’Reilly, J.; Serdén, L.; et al. Diagnosis related groups in Europe: Moving towards transparency, efficiency, and quality in hospitals? BMJ 2013, 346, f3197. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.J.; Han, K.T.; Kim, W.; Kim, S.J.; Park, E.C. Early Impact on Outpatients of Mandatory Adoption of the Diagnosis-Related Group-Based Reimbursement System in Korea on Use of Outpatient Care: Differences in Medical Utilization and Presurgery Examination. Health Serv. Res. 2018, 53, 2064–2083. [Google Scholar] [CrossRef]
- Wu, S.-W.; Pan, Q.; Chen, T. Research on diagnosis-related group grouping of inpatient medical expenditure in colorectal cancer patients based on a decision tree model. World J. Clin. Cases 2020, 8, 2484–2493. [Google Scholar] [CrossRef]
- Ayub, S.; Scali, S.T.; Richter, J.; Huber, T.S.; Beck, A.W.; Fatima, J.; Berceli, S.A.; Upchurch, G.R.; Arnaoutakis, D.; Back, M.R.; et al. Financial implications of coding inaccuracies in patients undergoing elective endovascular abdominal aortic aneurysm repair. J. Vasc. Surg. 2018, 69, 210–218. [Google Scholar] [CrossRef]
- Cheng, P.; Gilchrist, A.; Robinson, K.M.; Paul, L. The Risk and Consequences of Clinical Miscoding Due to Inadequate Medical Documentation: A Case Study of the Impact on Health Services Funding. Heal. Inf. Manag. J. 2009, 38, 35–46. [Google Scholar] [CrossRef] [Green Version]
- Lee, M.-T.; Su, Z.-Y.; Hou, Y.-H.; Liao, H.-C.; Lian, J.-D. A decision support system for diagnosis related groups coding. Expert Syst. Appl. 2011, 38, 3626–3631. [Google Scholar] [CrossRef]
- Yang, H.-C.; Nguyen, P.A.A.; Islam, M.; Huang, C.-W.; Poly, T.N.; Iqbal, U.; Li, Y.-C.J. Gout drugs use and risk of cancer: A case-control study. Jt. Bone Spine 2018, 85, 747–753. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.-Y.; Yeh, C.-F.; Shiao, A.-S.; Tu, T.-Y. Effects of diagnosis-related group payment on health-care provider behaviors: A consecutive three-period study. J. Chin. Med. Assoc. 2015, 78, 678–685. [Google Scholar] [CrossRef] [Green Version]
- Badgery-Parker, T.; Pearson, S.-A.; Chalmers, K.; Brett, J.; Scott, I.A.; Dunn, S.; Onley, N.; Elshaug, A.G. Low-value care in Australian public hospitals: Prevalence and trends over time. BMJ Qual. Saf. 2018, 28, 205–214. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Colla, C.H.; Morden, N.E.; Sequist, T.D.; Mainor, A.J.; Li, Z.; Rosenthal, M.B. Payer Type and Low-Value Care: Comparing Choosing Wisely Services across Commercial and Medicare Populations. Health Serv. Res. 2017, 53, 730–746. [Google Scholar] [CrossRef]
- Howard, D.H.; Gross, C.P. Producing Evidence to Reduce Low-Value Care. JAMA Intern. Med. 2015, 175, 1893–1894. [Google Scholar] [CrossRef] [PubMed]
- Kutz, A.; Gut, L.; Ebrahimi, F.; Wagner, U.; Schuetz, P.; Mueller, B. Association of the Swiss Diagnosis-Related Group Reimbursement System With Length of Stay, Mortality, and Readmission Rates in Hospitalized Adult Patients. JAMA Netw. Open 2019, 2, e188332. [Google Scholar] [CrossRef] [PubMed]
- Ijaz, M.F.; Attique, M.; Son, Y. Data-Driven Cervical Cancer Prediction Model with Outlier Detection and Over-Sampling Methods. Sensors 2020, 20, 2809. [Google Scholar] [CrossRef]
- Mandal, M.; Singh, P.K.; Ijaz, M.F.; Shafi, J.; Sarkar, R. A Tri-Stage Wrapper-Filter Feature Selection Framework for Disease Classification. Sensors 2021, 21, 5571. [Google Scholar] [CrossRef]
- Hsing, A.W.; Ioannidis, J.P. Nationwide population science: Lessons from the Taiwan national health insurance research database. JAMA Intern. Med. 2015, 175, 1527–1529. [Google Scholar] [CrossRef] [PubMed]
- Cheng, C.-L.; Kao, Y.-H.Y.; Lin, S.-J.; Lee, C.-H.; Lai, M.L. Validation of the national health insurance research database with ischemic stroke cases in Taiwan. Pharmacoepidemiol. Drug Saf. 2011, 20, 236–242. [Google Scholar] [CrossRef]
- Wang, C.-H.; Nguyen, P.A.; Li, Y.C. (.; Islam, M.; Poly, T.N.; Tran, Q.-V.; Huang, C.-W.; Yang, H.-C. Improved diagnosis-medication association mining to reduce pseudo-associations. Comput. Methods Programs Biomed. 2021, 207, 106181. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.-C.; Islam, M.; Nguyen, P.A.A.; Wang, C.-H.; Poly, T.N.; Huang, C.-W.; Li, Y.-C.J. Development of a Web-Based System for Exploring Cancer Risk With Long-term Use of Drugs: Logistic Regression Approach. JMIR Public Heal. Surveill. 2021, 7, e21401. [Google Scholar] [CrossRef]
- Liang, C.-W.; Yang, H.-C.; Islam, M.; Nguyen, P.A.A.; Feng, Y.-T.; Hou, Z.Y.; Huang, C.-W.; Poly, T.N.; Li, Y.-C.J. Predicting Hepatocellular Carcinoma With Minimal Features From Electronic Health Records: Development of a Deep Learning Model. JMIR Cancer 2021, 7, e19812. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Capurro, D.; Nguyen, A.; Verspoor, K. Early prediction of diagnostic-related groups and estimation of hospital cost by processing clinical notes. NPJ Digit. Med. 2021, 4, 1–8. [Google Scholar] [CrossRef]
- Gartner, D.; Kolisch, R.; Neill, D.B.; Padman, R. Machine Learning Approaches for Early DRG Classification and Resource Allocation. INFORMS J. Comput. 2015, 27, 718–734. [Google Scholar] [CrossRef] [Green Version]
- Fitch FBMcCulloch Warren, S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [Green Version]
- Minsky, M.; Papert, S.A. Perceptrons: An Introduction to Computational Geometry; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:14123555. [Google Scholar]
- Atique, S.; Hsieh, C.-H.; Hsiao, R.-T.; Iqbal, U.; Nguyen, P.A.; Islam, M.; Li, Y.-C.; Hsu, C.-Y.; Chuang, T.-W.; Syed-Abdul, S. Viral warts (Human Papilloma Virus) as a potential risk for breast cancer among younger females. Comput. Methods Programs Biomed. 2017, 144, 203–207. [Google Scholar] [CrossRef]
- Chen, K.C.; Iqbal, U.; Nguyen, P.A.; Hsu, C.H.; Huang, C.L.; Hsu, Y.H.E.; Atique, S.; Islam, M.M.; Li, Y.; Jian, W. The impact of different surgical procedures on hypoparathyroidism after thyroidectomy: A population-based study. Medicine 2017, 96, e8245. [Google Scholar] [CrossRef]
- Li, W.; Logenthiran, T.; Woo, W.L. Multi-GRU prediction system for electricity generation’s planning and operation. IET Gener. Transm. Distrib. 2019, 13, 1630–1637. [Google Scholar] [CrossRef]
- Li, Z.; Wang, P.; Lu, H.; Cheng, J. Reading selectively via Binary Input Gated Recurrent Unit. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Macao, China, 15–16 August 2019; pp. 5074–5080. [Google Scholar]
- Schlembach, D.; Hund, M.; Schroer, A.; Wolf, C. Economic assessment of the use of the sFlt-1/PlGF ratio test to predict preeclampsia in Germany. BMC Health Serv. Res. 2018, 18, 603. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Farhan, J.; Al-Jummaa, S.; Al-Rajhi, A.; Al-Rayes, H.; Al-Nasser, A. Documentation and coding of medical records in a tertiary care center: A pilot study. Ann. Saudi Med. 2005, 25, 46–49. [Google Scholar] [CrossRef] [PubMed]
- Nouraei SA, R.; Hudovsky, A.; Frampton, A.E.; Mufti, U.; White, N.B.; Wathen, C.G.; Sandhu, G.S.; Darzi, A. A study of clinical coding accuracy in surgery: Implications for the use of administrative big data for outcomes management. Ann. Surg. 2015, 261, 1096–1107. [Google Scholar] [CrossRef] [PubMed]
- Zafirah, S.A.; Amrizal, M.N.; Sharifah EW, P.; Aljunid, S.M. Incidence of clinical coding errors and implications on casemix reimbursement in a teaching hospital in Malaysia. Malays. J. Public Health Med. 2017, 17, 19–28. [Google Scholar]
- Zafirah, S.A.; Nur, A.M.; Puteh, S.E.W.; Aljunid, S.M. Potential loss of revenue due to errors in clinical coding during the implementation of the Malaysia diagnosis related group (MY-DRG®) Casemix system in a teaching hospital in Malaysia. BMC Health Serv. Res. 2018, 18, 38. [Google Scholar] [CrossRef] [Green Version]
- Pongpirul, K.; Robinson, C. Hospital manipulations in the DRG system: A systematic scoping review. Asian Biomed. 2013, 7, 301–310. [Google Scholar]
- Maryati, W.; Yuliani, N.; Susanto, A.; Wannay, A.O.; Justika, A.I. Reduced hospital revenue due to error code diagnosis in the implementation of INA-CBGs. Int. J. Public Health Sci. (IJPHS) 2021, 10, 354. [Google Scholar] [CrossRef]
- Nouraei, S.A.R.; Virk, J.S.; Hudovsky, A.; Wathen, C.; Darzi, A.; Parsons, D. Accuracy of clinician-clinical coder information handover following acute medical admissions: Implication for using administrative datasets in clinical outcomes management. J. Public Health 2015, 38, 352–362. [Google Scholar] [CrossRef] [PubMed] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
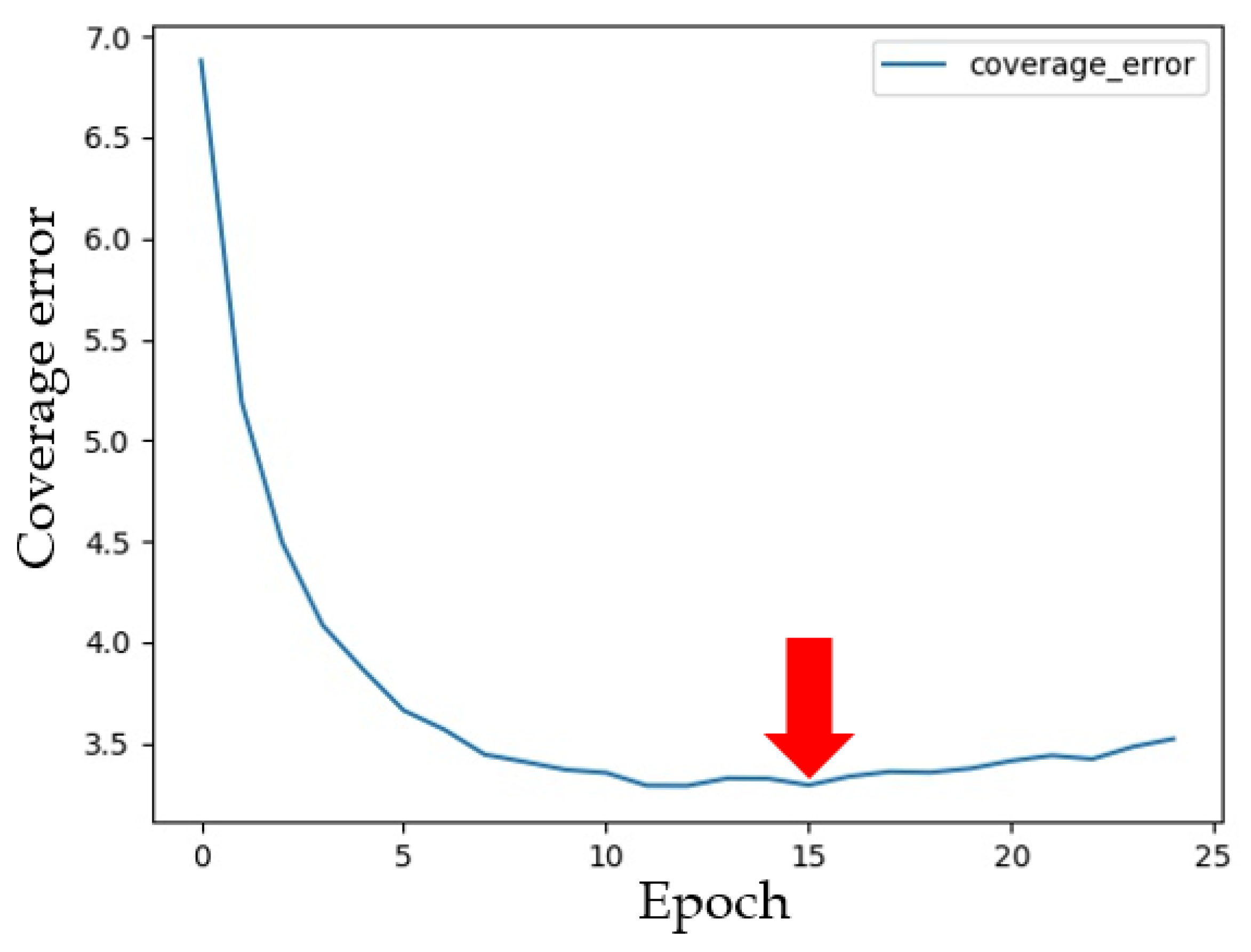{kind=link}
| Variable | Number/Percentage |
|---|---|
| Total number of episodes | 128,105 |
| Total number of patients | 81,486 |
| Age range | |
| Age group | |
| 0~20 | 4.51% |
| 20~40 | 54.76% |
| 40~60 | 42.79% |
| >60 | 0.02% |
| Gender | |
| Male | 74.65% |
| Female | 25.35% |
| Operation | |
| Yes | 87.78% |
| No | 12.22% |
| Additional diagnosis | |
| Yes | 70.98% |
| No | 29.02% |
| Procedure | |
| Yes | 98.82% |
| No | 1.18% |
| Drug | |
| Yes | 99.58% |
| No | 0.42% |
| Number of drugs input | 461 |
| Number of diseases input | 200 |
| Number of procedures input | 1636 |
| Number of operations input | 927 |
| Number of output | 200 |
| Model | Precision | Recall | F1-Score | Accuracy | AUROC | Ranking Loss |
|---|---|---|---|---|---|---|
| GRU | 0.83 | 0.66 | 0.73 | 0.72 | 0.99 | 0.01 |
| ANN | 0.82 | 0.57 | 0.67 | 0.68 | 0.99 | 0.01 |
| Basic Info | Drug | Procedure | Operation | Additional ICD | Precision | Recall | F1-Score | Accuracy | Micro-AUC | Label Ranking Loss |
|---|---|---|---|---|---|---|---|---|---|---|
| V | V | V | V | V | 0.83 | 0.65 | 0.73 | 0.726 | 0.99 | 0.01 |
| V | V | V | V | 0.76 | 0.60 | 0.67 | 0.671 | 0.99 | 0.01 | |
| V | V | V | V | 0.70 | 0.31 | 0.43 | 0.481 | 0.97 | 0.03 | |
| V | V | V | V | 0.55 | 0.42 | 0.47 | 0.465 | 0.92 | 0.06 | |
| V | V | V | V | 0.81 | 0.56 | 0.66 | 0.632 | 0.98 | 0.03 | |
| V | V | 0.08 | 0.02 | 0.04 | 0.059 | 0.79 | 0.16 | |||
| V | V | 0.26 | 0.04 | 0.07 | 0.211 | 0.92 | 0.08 | |||
| V | V | 0.52 | 0.33 | 0.41 | 0.373 | 0.88 | 0.09 | |||
| V | V | 0.01 | 0.005 | 0.006 | 0.026 | 0.75 | 0.19 | |||
| V | 0.001 | 0 | 0.001 | 0.006 | 0.73 | 0.21 |
| Example | Age | Sex | Original Primary Diagnosis | Predicted Primary Diagnosis | Top 5 Primary Diagnoses |
|---|---|---|---|---|---|
| Patient #1 | 20–40 | Male | Calculus of ureter | Calculus of ureter | 1. Calculus of ureter. 2. Calculus of kidney. 3. Urinary tract infection, site not specified. 4. Calculus in urethra. 5. Acute pyelonephritis without lesion of renal medullary necrosis. |
| Patient #2 | 20–40 | Female | Calculus of kidney | Calculus of kidney | 1. Calculus of kidney. 2. Acute pyelonephritis without lesion of renal medullary necrosis. 3. Urinary tract infection, site not specified. 4. Pyelonephritis, unspecified. 5. Renal colic. |
| Patient #3 | 20–40 | Male | Malignant bladder neoplasm, part unspecified. | Malignant bladder neoplasm, part unspecified. | 1. Malignant bladder neoplasm, part unspecified. 2. Malignant bladder neoplasm, lateral wall. 3. Malignant bladder neoplasm, other specified sites. 4. Neoplasms of unspecified nature, bladder. 5. Benign neoplasm of bladder. |
| Patient #4 | 20–40 | Male | Malignant bladder neoplasm, other specified sites. | Malignant bladder neoplasm, part unspecified. | 1. Malignant bladder neoplasm, part unspecified. 2. Neoplasms of unspecified nature, bladder. 3. Malignant bladder neoplasm, lateral wall. 4. Malignant bladder neoplasm, other specified sites. 5. Hematuria. |
| Patient #5 | 20–40 | Male | Acute pyelonephritis without lesion of renal medullary necrosis. | Urinary tract infection, site not specified. | 1. Urinary tract infection, site not specified. 2. Acute pyelonephritis without lesion of renal medullary necrosis. 3. Acute cystitis. 4. Hematuria. 5. Orchitis and epididymitis, other, without mention of abscess. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, M.M.; Li, G.-H.; Poly, T.N.; Li, Y.-C. DeepDRG: Performance of Artificial Intelligence Model for Real-Time Prediction of Diagnosis-Related Groups. Healthcare 2021, 9, 1632. https://doi.org/10.3390/healthcare9121632
Islam MM, Li G-H, Poly TN, Li Y-C. DeepDRG: Performance of Artificial Intelligence Model for Real-Time Prediction of Diagnosis-Related Groups. Healthcare. 2021; 9(12):1632. https://doi.org/10.3390/healthcare9121632
Chicago/Turabian StyleIslam, Md. Mohaimenul, Guo-Hung Li, Tahmina Nasrin Poly, and Yu-Chuan (Jack) Li. 2021. "DeepDRG: Performance of Artificial Intelligence Model for Real-Time Prediction of Diagnosis-Related Groups" Healthcare 9, no. 12: 1632. https://doi.org/10.3390/healthcare9121632
APA StyleIslam, M. M., Li, G.-H., Poly, T. N., & Li, Y.-C. (2021). DeepDRG: Performance of Artificial Intelligence Model for Real-Time Prediction of Diagnosis-Related Groups. Healthcare, 9(12), 1632. https://doi.org/10.3390/healthcare9121632