
Machine Learning Techniques to Predict Timeliness of Care among Lung Cancer Patients



Abstract
:1. Introduction
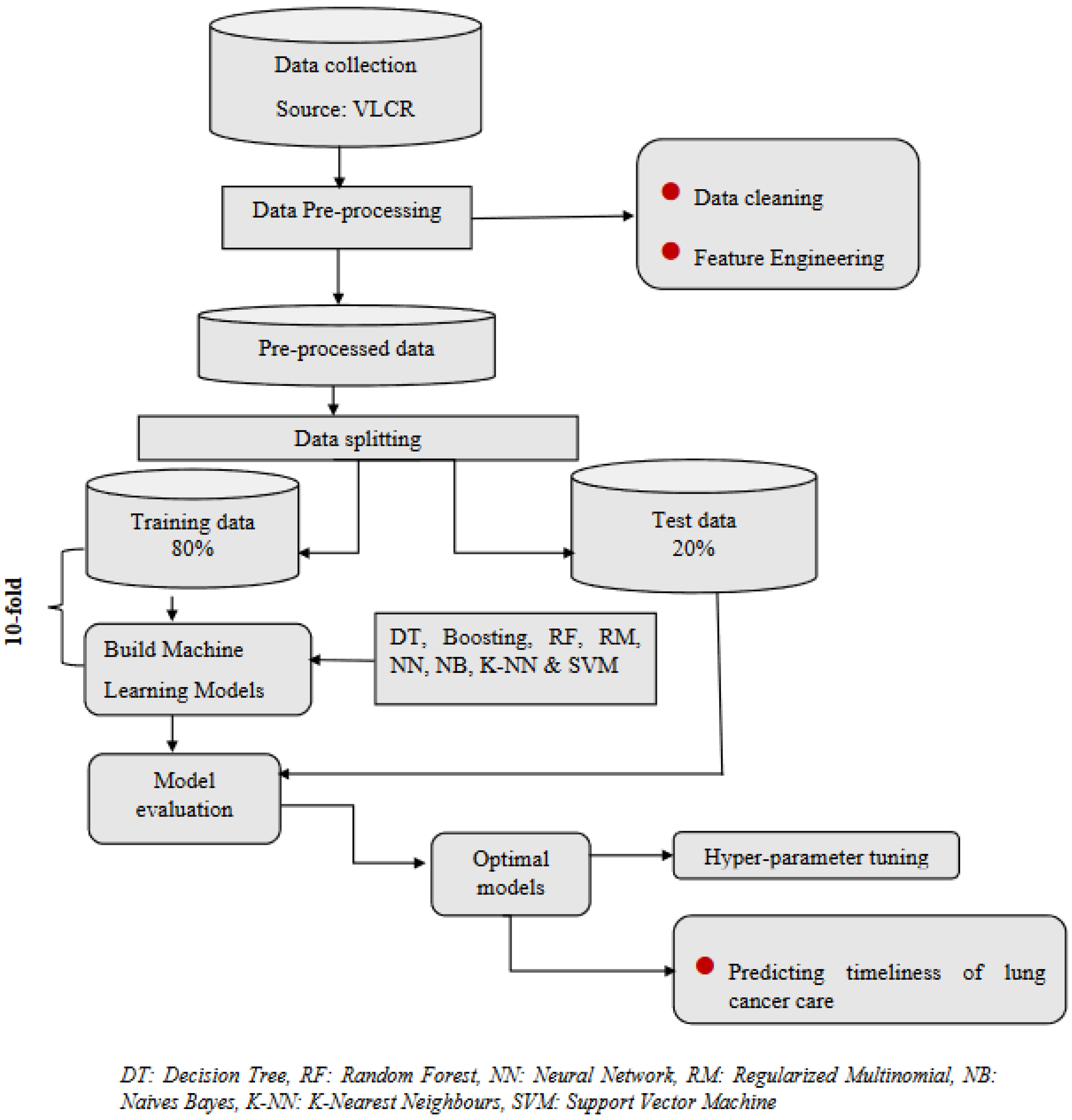
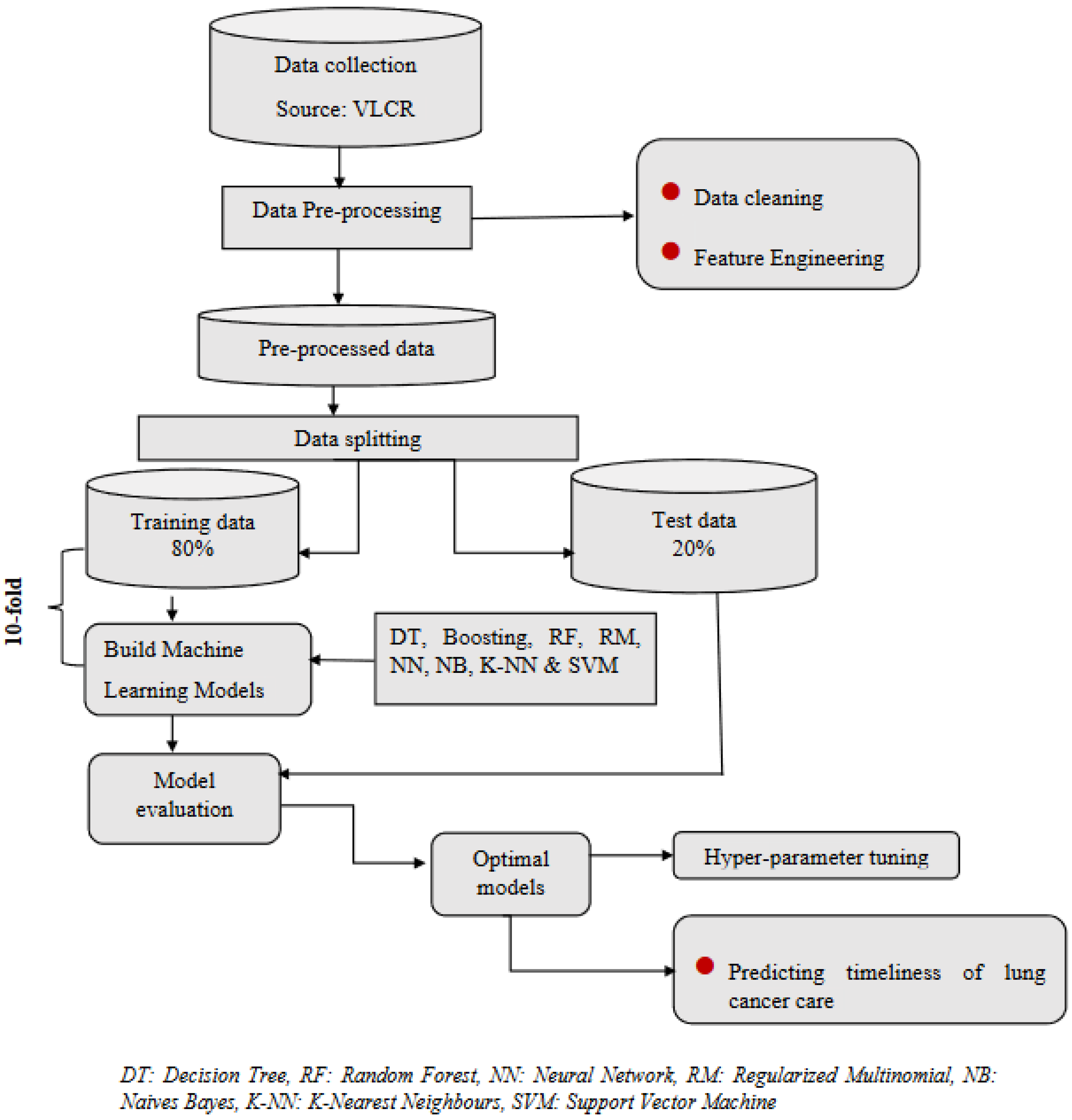
2. Materials and Methods
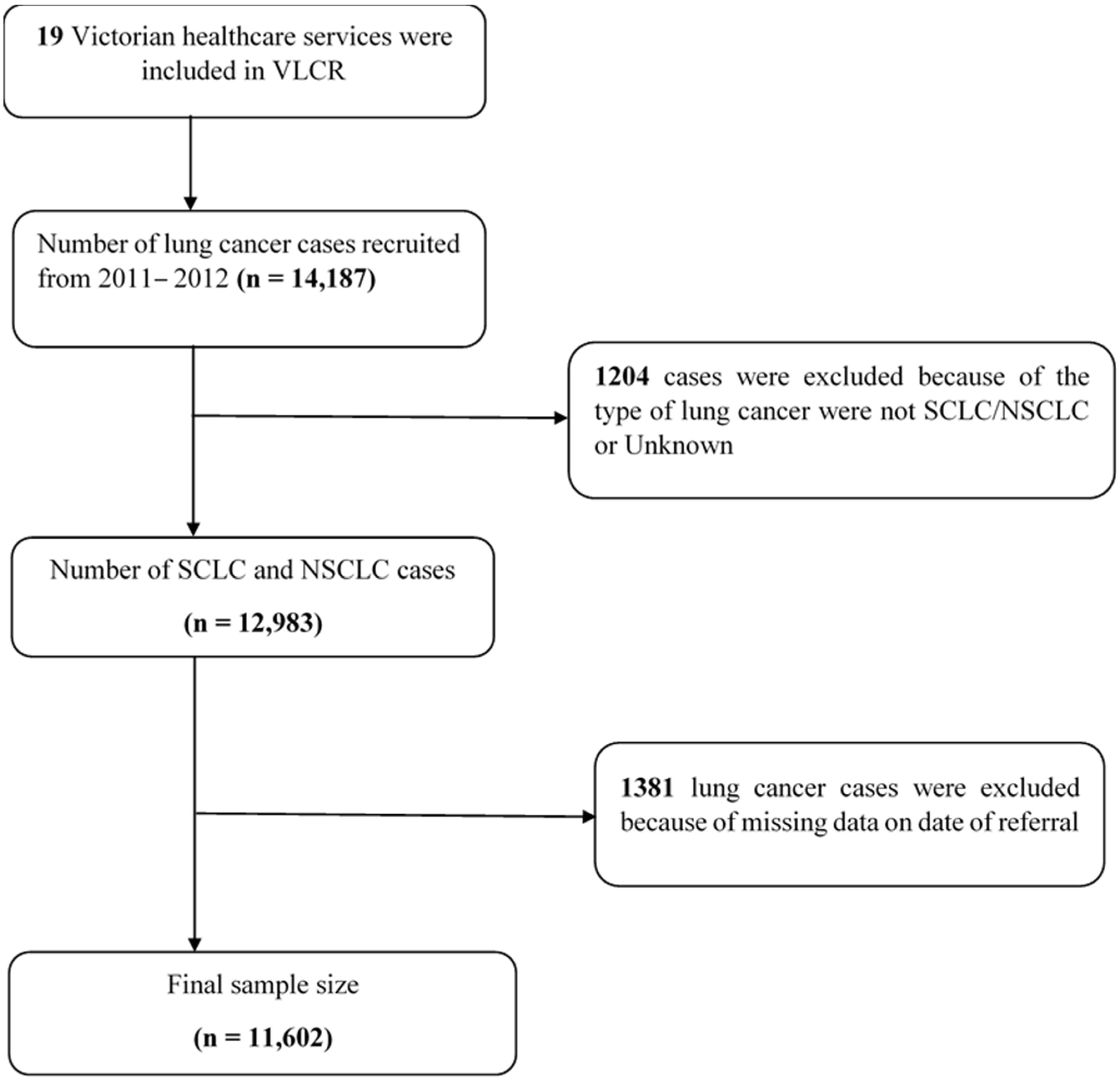
2.1. Setting
2.2. Outcome Measures
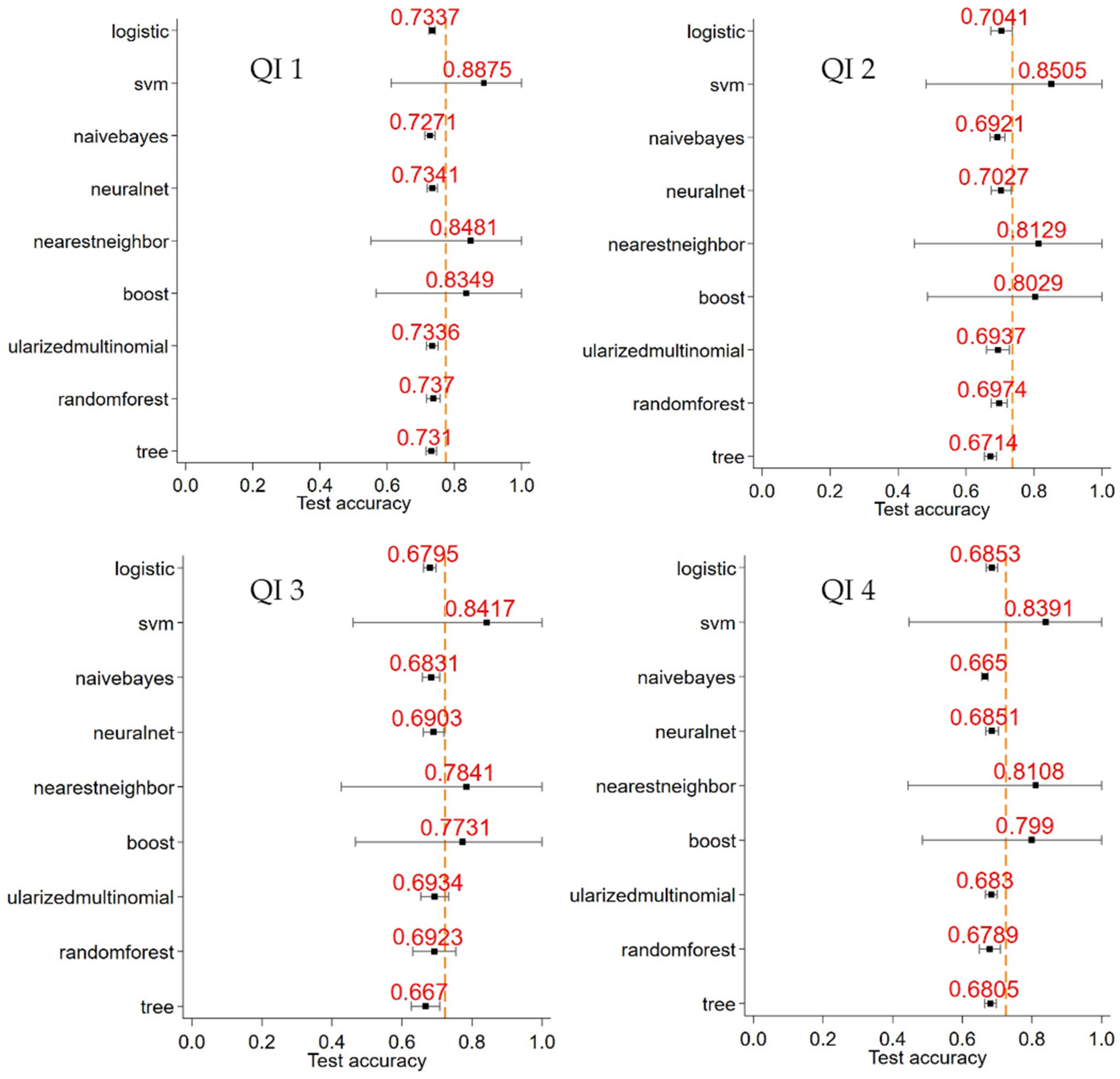
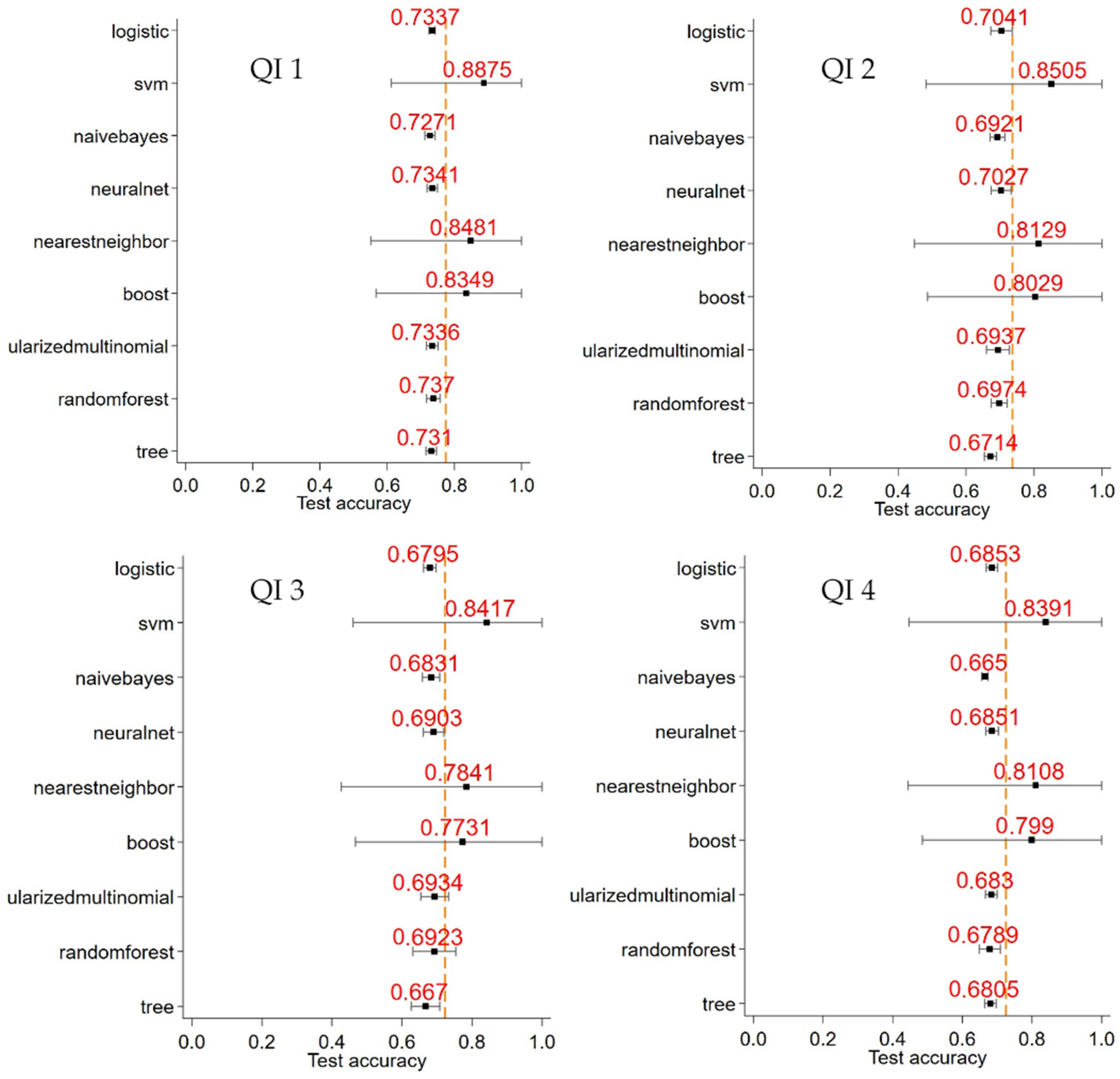
- The interval between initial referral for management and diagnosis (“referral to diagnosis”): Target ≤ 28 days (QI 1).
- The interval between diagnosis and initial surgery, chemotherapy, radiotherapy, or referral to palliative care (“diagnosis to initial definitive management”): Target ≤ 14 days (QI 2).
- Time from diagnosis date to surgical resection date among patients with NSCLC: Target ≤ 14 days (QI 3).
- The interval between referral and initial definitive management: Target ≤ 42 days (QI 4).
2.3. Predictive Features
2.4. Statistical Methods
2.5. Machine Learning Methods
- 2.
- 3.
- 4.
- Regularized Multinomial
- 5.
- 6.
- Naive Bayes
- 7.
- K-Nearest Neighbour
- 8.
- Support Vector Machine [47]
2.6. Model Evaluation
2.7. Parameter Tuning
3. Results
4. Discussion
5. Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Definition of Quality Indicators
| Indicator | Operational Definition |
| QI 1 | Number of patients where time from referral date to diagnosis is ≤28 days (numerator). Number of patients in Registry with a referral date available (denominator). |
| QI 2 | Number of patients where time from diagnosis date to first treatment date (any intent) is ≤14 days (numerator). Number of patients in Registry receiving any intent anti-cancer treatment with a defined date (denominator). |
| QI 3 | Number of patients with NSCLC where time from diagnosis date to surgical resection date is ≤14 days (numerator). Number of NSCLC patients in Registry undergoing surgical resection with defined dates available (denominator). |
| QI 4 | Number of patients where time from referral date to first treatment (any intent) is ≤42 days (numerator). Number of patients in Registry undergoing anti-cancer treatment with referral and treatment date available (denominator). |
Appendix B. Machine Learning Models and the Parameters Specified in the Grid Search
| Machine Learning Method | Parameters | Grid Search | ||||||
| Decision trees | Tree depth | 5 | 6 | 7 | 8 | 9 | 10 | 100 |
| Random forests | Tree depth | 10 | 11 | 12 | 13 | 14 | 15 | |
| # of splitting features | 5 | 10 | 20 | |||||
| # of trees | 10 | 100 | 1000 | |||||
| Regularised multinomial | L1 ratio | 0 | 0.5 | 1 | ||||
| Alpha | 0.01 | 0.05 | 0.5 | |||||
| Boosting | Tree depth | 5 | 10 | 15 | 20 | |||
| # of trees | 100 | 150 | 200 | |||||
| Learning rate | 0.01 | 0.1 | 0.2 | 0.3 | ||||
| Nearest neighbour | # of neighbours | 10 | 100 | 150 | 200 | |||
| Kernel | Uniform | Distance | ||||||
| Neural network | # of neurons L1 | 2 | 4 | 6 | 8 | |||
| # of neurons L2 | 1 | 2 | 3 | 4 | ||||
| Alpha | 0.5 | 1 | 1.1 | 1.5 | ||||
| Support vector machines | Margin parameter, C | 0.01 | 0.1 | 0.5 | 1 | 10 | ||
| Gamma | 0 | 1 | ||||||
Appendix C. Optimal Tuning of Machine Learning Method Parameters Based on Cross-Validation Classification for Quality Indicator One (QI 1)
- (a)
- Decision trees
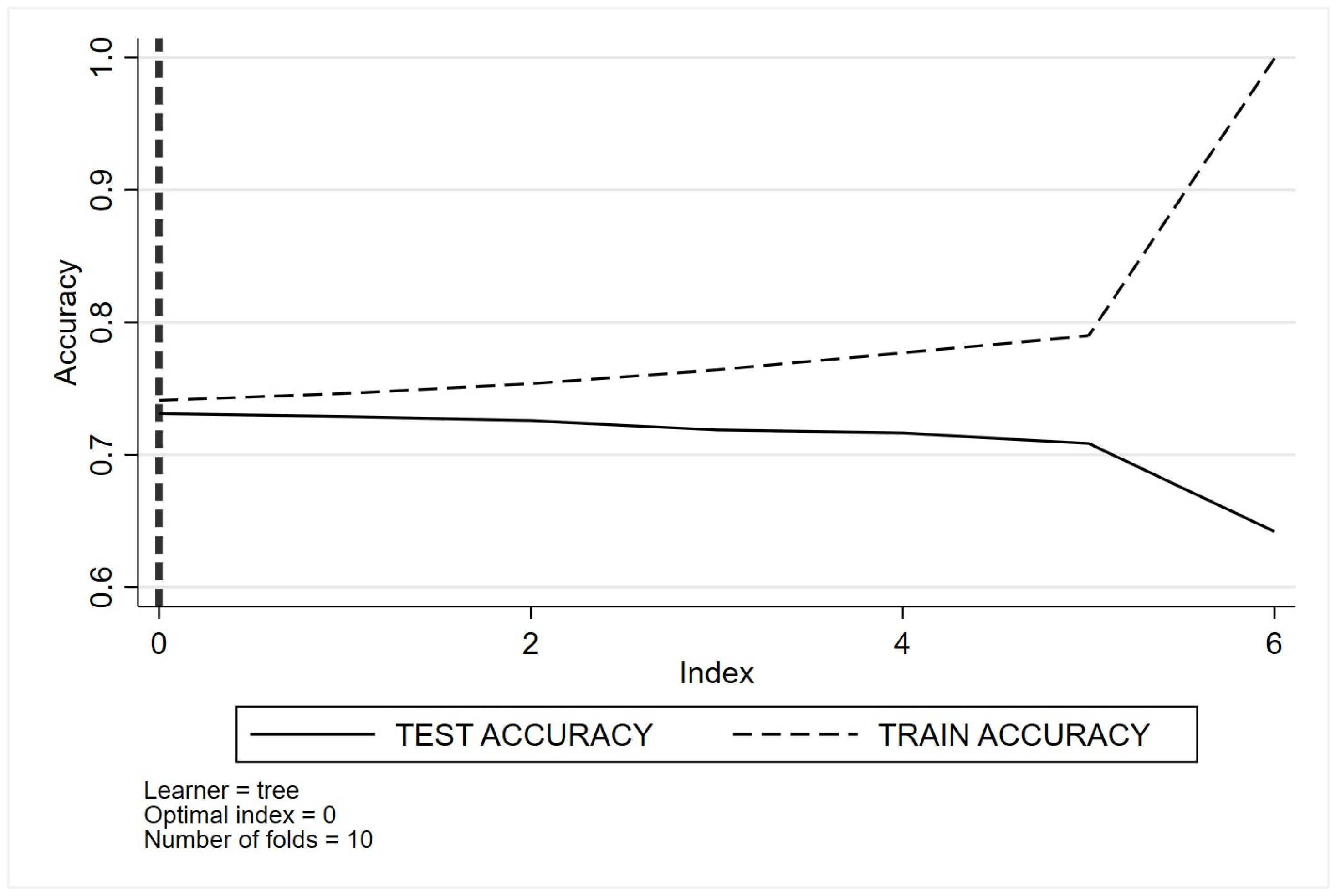
- (b)
- Random forests
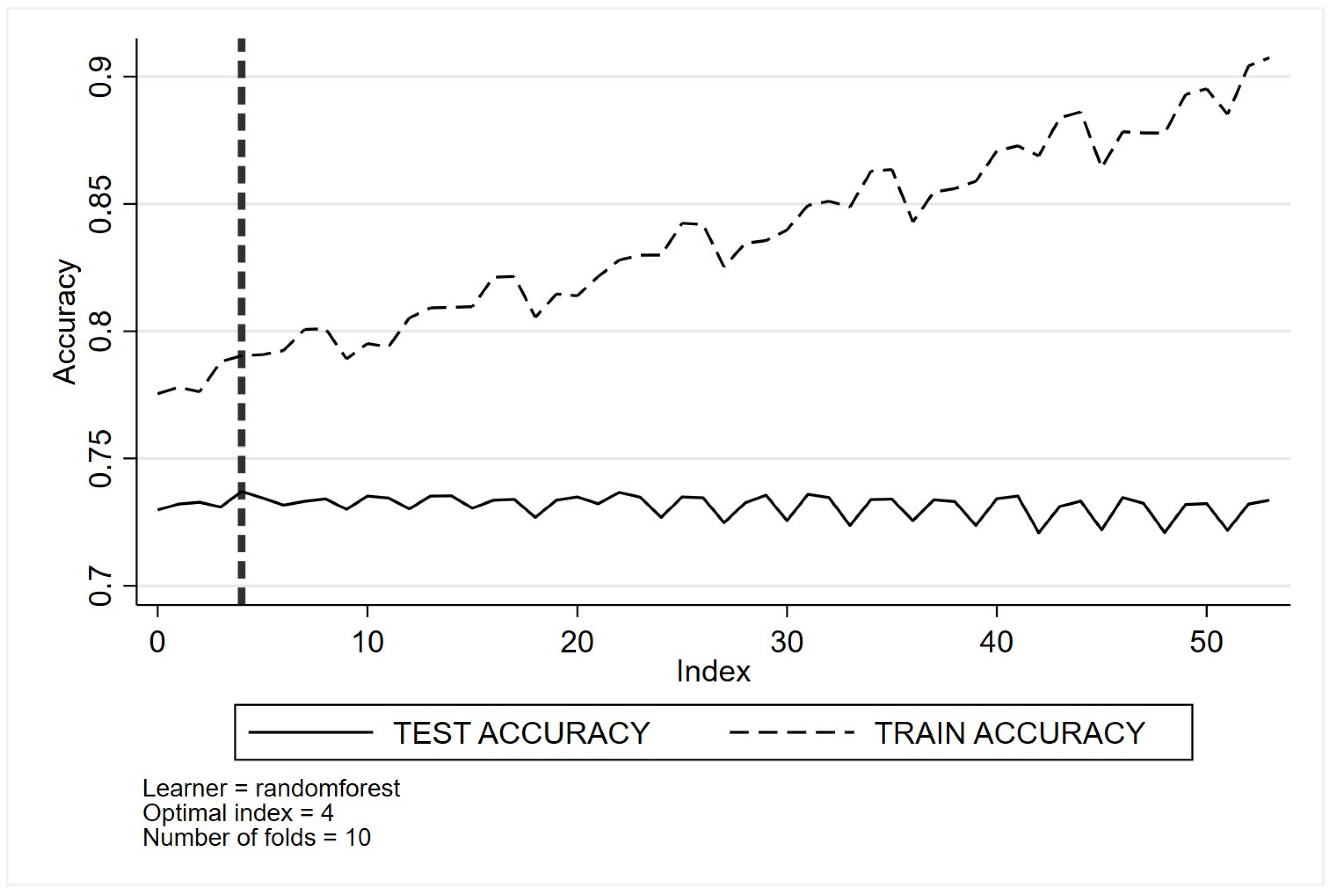
- (c)
- Regularised multinomial

- (d)
- Boosting
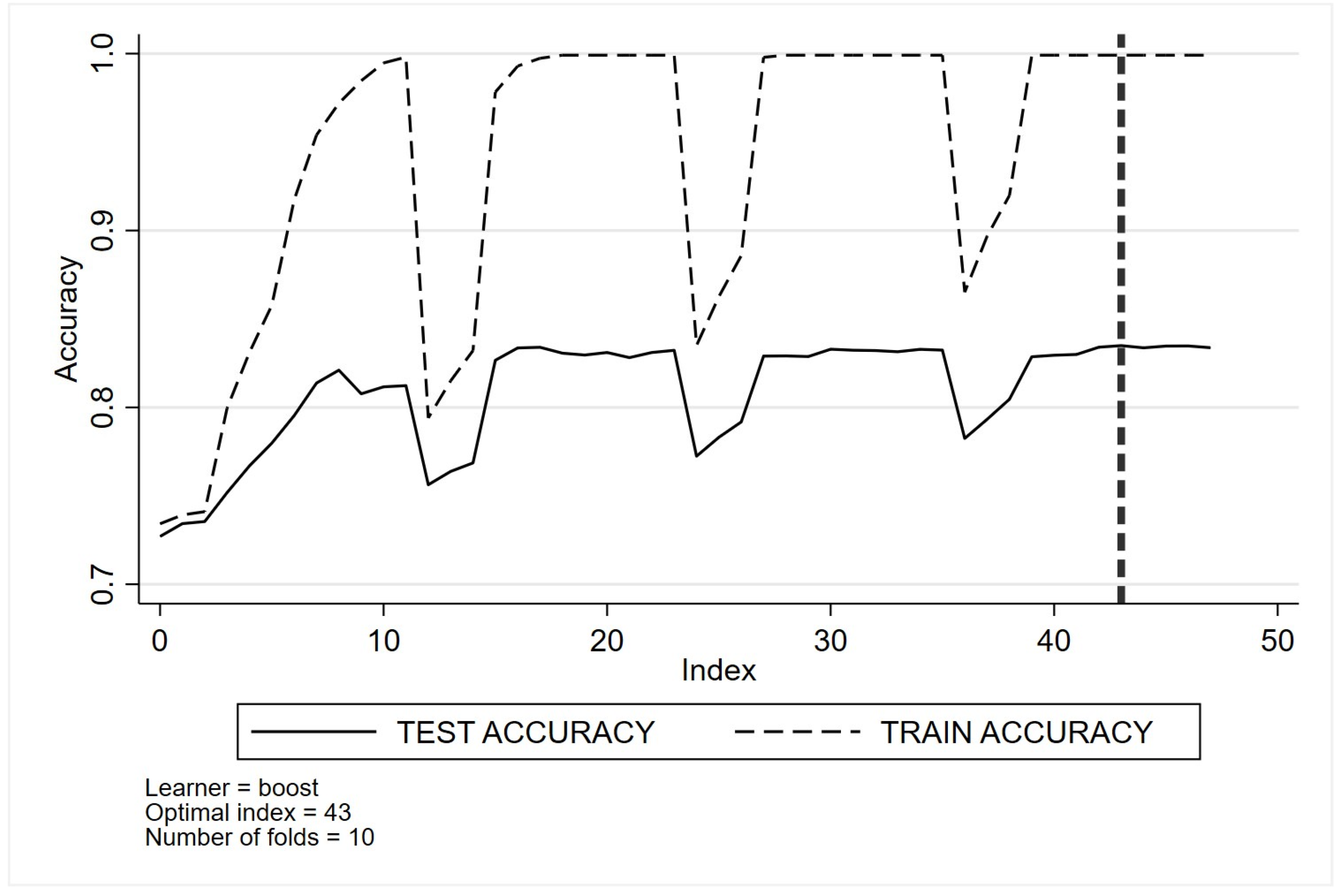
- (e)
- Nearest neighbour
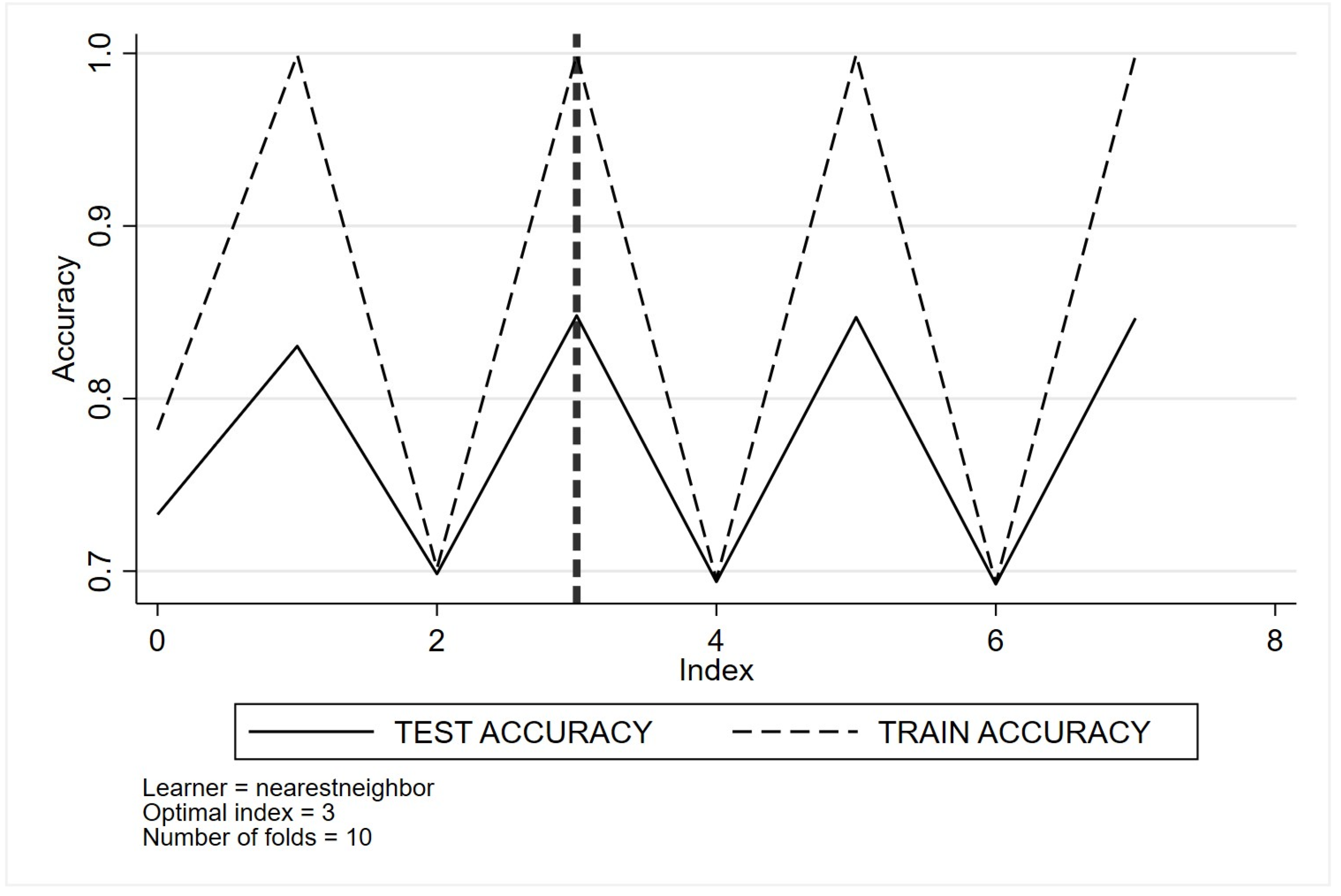
- (f)
- Neural networks
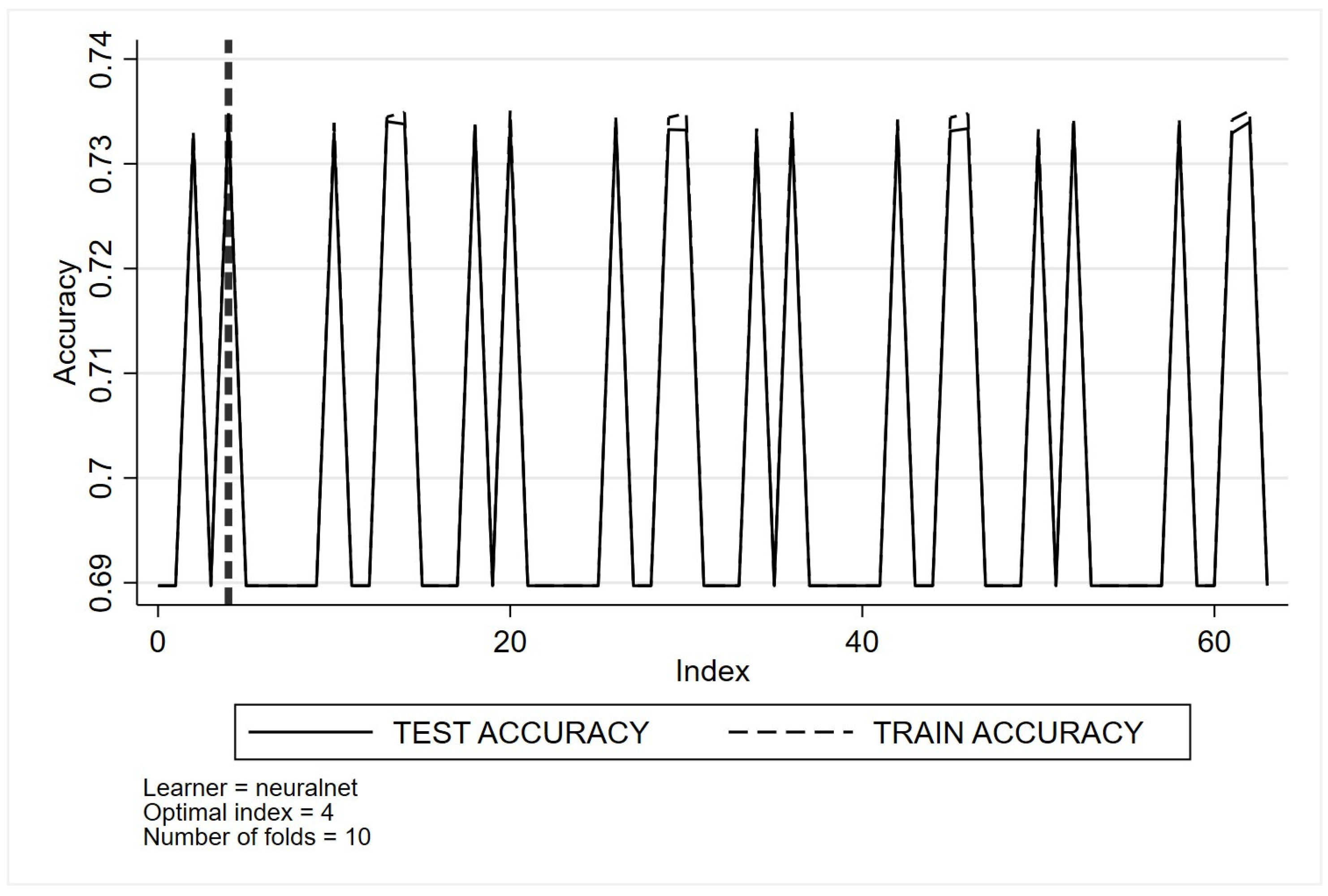
- (g)
- Naïve Bayes
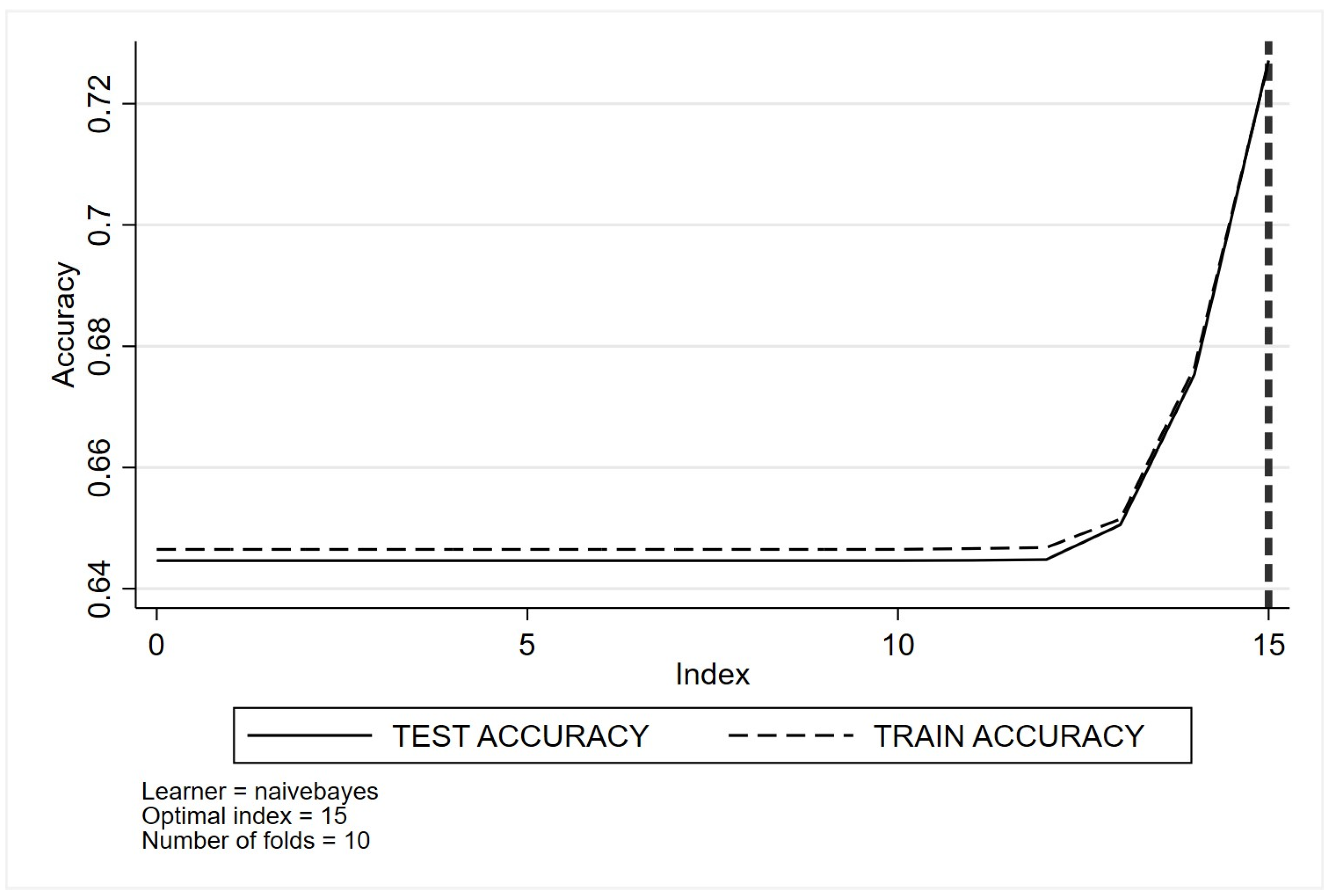
- (h)
- Support vector machines
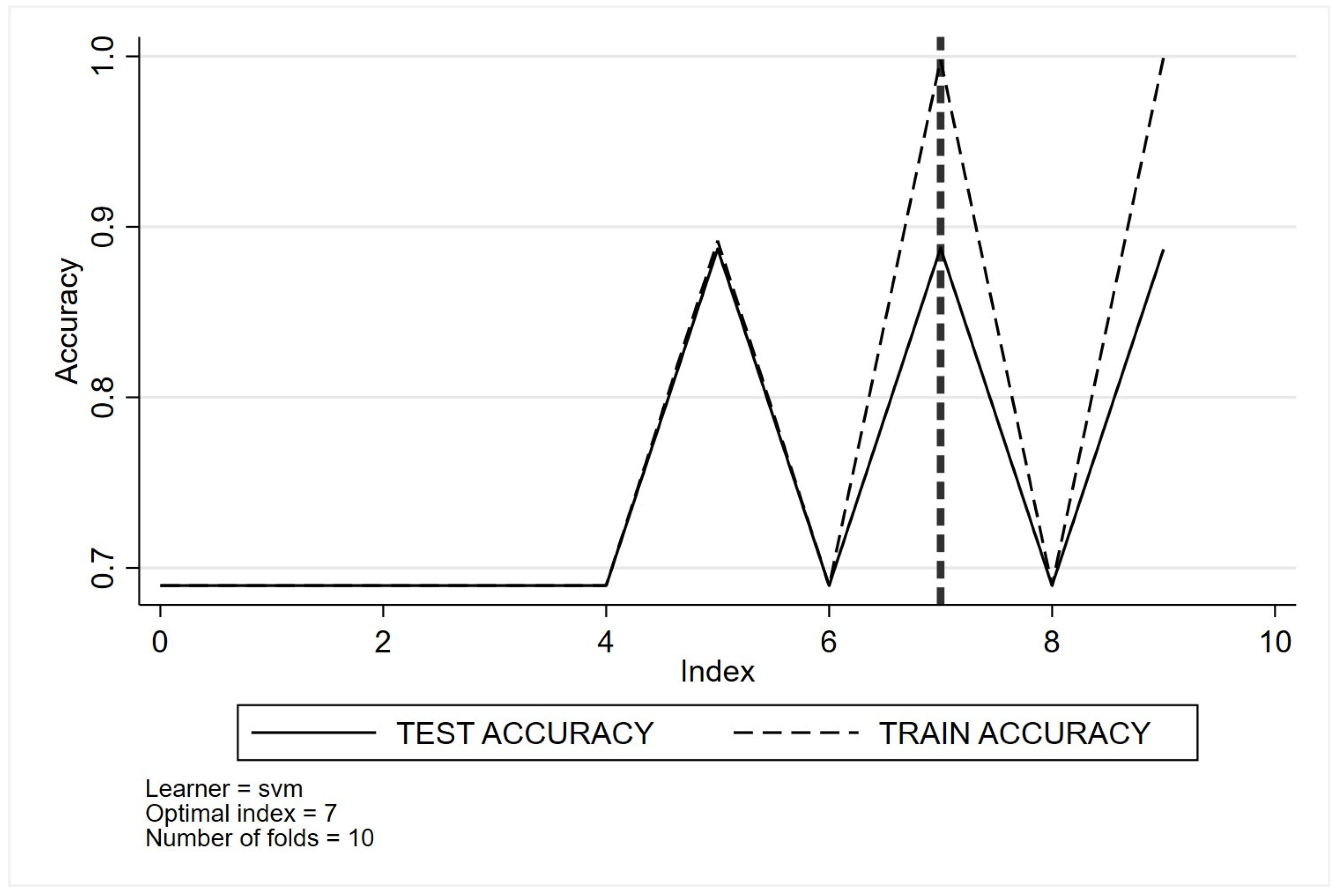
Appendix D. Descriptive and Demographic Characteristics Stratified by Quality Indicators 2 to 4
| Variables | QI 2 No | QI 2 Yes | p-Value | QI 3 No | QI 3 Yes | p-Value | QI 4 No | QI 4 Yes | p-Value |
| N | 5785 | 4063 | 1098 | 1614 | 5045 | 4803 | |||
| Sex | 0.012 | 0.14 | 0.25 | ||||||
| Male | 3286 (56.8%) | 2204 (54.2%) | 582 (53.0%) | 809 (50.1%) | 2841 (56.3%) | 2649 (55.2%) | |||
| Female | 2499 (43.2%) | 1859 (45.8%) | 516 (47.0%) | 805 (49.9%) | 2204 (43.7%) | 2154 (44.8%) | |||
| Age, mean (SD) | 69.1 (10.5) | 67.6 (10.2) | <0.001 | 68.0 (9.7) | 68.2 (9.4) | 0.62 | 69.6 (10.1) | 67.3 (10.6) | <0.001 |
| ECOG status at diagnosis | <0.001 | <0.001 | <0.001 | ||||||
| 0 | 1617 (28.0%) | 1057 (26.0%) | 474 (43.2%) | 541 (33.5%) | 1474 (29.2%) | 1200 (25.0%) | |||
| 1 | 1997 (34.5%) | 1056 (26.0%) | 244 (22.2%) | 257 (15.9%) | 1563 (31.0%) | 1490 (31.0%) | |||
| 2 | 572 (9.9%) | 322 (7.9%) | 21 (1.9%) | 33 (2.0%) | 439 (8.7%) | 455 (9.5%) | |||
| 3 | 166 (2.9%) | 135 (3.3%) | 5 (0.5%) | 11 (0.7%) | 117 (2.3%) | 184 (3.8%) | |||
| 4 | 10 (0.2%) | 14 (0.3%) | 0 (0.0%) | 1 (0.1%) | 6 (0.1%) | 18 (0.4%) | |||
| Not available | 9 (0.2%) | 9 (0.2%) | 1 (0.1%) | 3 (0.2%) | 8 (0.2%) | 10 (0.2%) | |||
| Not Stated | 1414 (24.4%) | 1470 (36.2%) | 353 (32.1%) | 768 (47.6%) | 1438 (28.5%) | 1446 (30.1%) | |||
| English as first language | 0.002 | 0.34 | <0.001 | ||||||
| No | 603 (10.4%) | 347 (8.5%) | 107 (9.7%) | 140 (8.7%) | 538 (10.7%) | 412 (8.6%) | |||
| Yes | 5182 (89.6%) | 3716 (91.5%) | 991 (90.3%) | 1474 (91.3%) | 4507 (89.3%) | 4391 (91.4%) | |||
| Smoking status | 0.090 | 0.003 | 0.26 | ||||||
| Current smoker | 2015 (34.8%) | 1452 (35.7%) | 360 (32.8%) | 441 (27.3%) | 1749 (34.7%) | 1718 (35.8%) | |||
| Ex-smoker | 2982 (51.5%) | 2000 (49.2%) | 559 (50.9%) | 843 (52.2%) | 2599 (51.5%) | 2383 (49.6%) | |||
| Never smoker | 687 (11.9%) | 531 (13.1%) | 164 (14.9%) | 292 (18.1%) | 610 (12.1%) | 608 (12.7%) | |||
| Not stated | 101 (1.7%) | 80 (2.0%) | 15 (1.4%) | 38 (2.4%) | 87 (1.7%) | 94 (2.0%) | |||
| Remoteness | <0.001 | <0.001 | 0.008 | ||||||
| Inner regional Australia | 1660 (28.7%) | 1004 (24.7%) | 317 (28.9%) | 355 (22.0%) | 1436 (28.5%) | 1228 (25.6%) | |||
| Major cities of Australia | 3676 (63.5%) | 2774 (68.3%) | 697 (63.5%) | 1156 (71.6%) | 3225 (63.9%) | 3225 (67.2%) | |||
| Outer regional Australia | 443 (7.7%) | 279 (6.9%) | 82 (7.5%) | 101 (6.3%) | 378 (7.5%) | 344 (7.2%) | |||
| Remote Australia | 6 (0.1%) | 5 (0.1%) | 2 (0.2%) | 2 (0.1%) | 6 (0.1%) | 5 (0.1%) | |||
| Clinical stage | <0.001 | <0.001 | <0.001 | ||||||
| Stage 1 | 836 (14.5%) | 704 (17.3%) | 478 (43.5%) | 677 (41.9%) | 1154 (22.9%) | 386 (8.0%) | |||
| Stage 2 | 546 (9.4%) | 279 (6.9%) | 249 (22.7%) | 221 (13.7%) | 596 (11.8%) | 229 (4.8%) | |||
| Stage 3 | 1300 (22.5%) | 370 (9.1%) | 156 (14.2%) | 118 (7.3%) | 1009 (20.0%) | 661 (13.8%) | |||
| Stage 4 | 2437 (42.1%) | 1828 (45.0%) | 23 (2.1%) | 20 (1.2%) | 1444 (28.6%) | 2821 (58.7%) | |||
| Cannot be assessed | 666 (11.5%) | 882 (21.7%) | 192 (17.5%) | 578 (35.8%) | 842 (16.7%) | 706 (14.7%) | |||
| Lung cancer type | <0.001 | <0.001 | |||||||
| NSCLC | 5465 (94.5%) | 3146 (77.4%) | 4776 (94.7%) | 3835 (79.8%) | |||||
| SCLC | 320 (5.5%) | 917 (22.6%) | 269 (5.3%) | 968 (20.2%) | |||||
| Australian born | 0.95 | 0.18 | 0.17 | ||||||
| Other/Not stated | 2242 (38.8%) | 1572 (38.7%) | 431 (39.3%) | 675 (41.8%) | 1987 (39.4%) | 1827 (38.0%) | |||
| Australia | 3543 (61.2%) | 2491 (61.3%) | 667 (60.7%) | 939 (58.2%) | 3058 (60.6%) | 2976 (62.0%) | |||
| Index of relative socio-economic disadvantage, mean (SD) | 998.3 (70.7) | 1005.2 (68.3) | <0.001 | 998.4 (72.5) | 1009.8 (67.4) | <0.001 | 998.2 (69.6) | 1.004.3 (69.9) | <0.001 |
| Index of economic resources, mean (SD) | 990.3 (60.2) | 995.4 (60.2) | <0.001 | 991.1 (58.9) | 998.9 (58.2) | <0.001 | 990.7 (59.5) | 994.3 (60.9) | 0.003 |
| Index of education and occupation, mean (SD) | 1004.1 (85.9) | 1012.0 (85.5) | <0.001 | 1004.7 (87.6) | 1017.1 (85.8) | <0.001 | 1003.1 (84.3) | 1011.9 (87.2) | <0.001 |
| Index of relative socio-economic advantage and disadvantage, mean (SD) | 996.1 (76.0) | 1004.3 (74.6) | <0.001 | 996.5 (77.9) | 1009.2 (74.9) | <0.001 | 995.5 (74.5) | 1003.6 (76.3) | <0.001 |
References
- Australian Government Cancer Australia. Lung Cancer in Australia Statistics; Australian Government Cancer Australia: Canberra, Australia, 2022.
- Cancer Council Victoria. Lung Cancer Statistics and Trends; Cancer Council Victoria: East Melbourne, Australia, 2023. [Google Scholar]
- Australian Institute of Health and Welfare. Australian Cancer Incidence and Mortality (ACIM) Books; AIHW: Canberra, Australia, 2021.
- Cancer Council Victoria. Victorian Cancer Registry. Cancer in Victoria; Cancer Council Victoria: East Melbourne, Australia, 2021. [Google Scholar]
- Goldsbury, D.E.; Weber, M.F.; Yap, S.; Rankin, N.M.; Ngo, P.; Veerman, L.; Banks, E.; Canfell, K.; O’Connell, D.L. Health services costs for lung cancer care in Australia: Estimates from the 45 and up Study. PLoS ONE 2020, 15, e0238018. [Google Scholar] [CrossRef]
- Risberg, T.; Sorbye, S.W.; Norum, J.; Wist, E.A. Diagnostic delay causes more psychological distress in female than in male cancer patients. Anticancer Res. 1996, 16, 995–999. [Google Scholar] [PubMed]
- Guirado, M.; Fernandez Martin, E.; Fernandez Villar, A.; Navarro Martin, A.; Sanchez-Hernandez, A. Clinical impact of delays in the management of lung cancer patients in the last decade: Systematic review. Clin. Transl. Oncol. 2022, 24, 1549–1568. [Google Scholar] [CrossRef]
- Jacobsen, M.M.; Silverstein, S.C.; Quinn, M.; Waterston, L.B.; Thomas, C.A.; Benneyan, J.C.; Han, P.K. Timeliness of access to lung cancer diagnosis and treatment: A scoping literature review. Lung Cancer 2017, 112, 156–164. [Google Scholar] [CrossRef] [PubMed]
- Cushman, T.R.; Jones, B.; Akhavan, D.; Rusthoven, C.G.; Verma, V.; Salgia, R.; Sedrak, M.; Massarelli, E.; Welsh, J.W.; Amini, A. The Effects of Time to Treatment Initiation for Patients With Non-small-cell Lung Cancer in the United States. Clin. Lung Cancer 2021, 22, e84–e97. [Google Scholar] [CrossRef] [PubMed]
- Di Girolamo, C.W.S.; Gildea, C.; Benitez Majano, S.; Rachet, B.; Morris, M. Can we assess Cancer Waiting Time targets with cancer survival? A population-based study of individually linked data from the National Cancer Waiting Times monitoring dataset in England, 2009–2013. PLoS ONE 2018, 13, e0201288. [Google Scholar] [CrossRef]
- Evans, S.M.; Earnest, A.; Bower, W.; Senthuren, M.; McLaughlin, P.; Stirling, R. Timeliness of lung cancer care in Victoria: A retrospective cohort study. Med. J. Aust. 2016, 204, 75. [Google Scholar] [CrossRef]
- Forrest, L.F.; Adams, J.; Rubin, G.; White, M. The role of receipt and timeliness of treatment in socioeconomic inequalities in lung cancer survival: Population-based, data-linkage study. Thorax 2015, 70, 138–145. [Google Scholar] [CrossRef]
- Khorana, A.A.; Tullio, K.; Elson, P.; Pennell, N.A.; Grobmyer, S.R.; Kalady, M.F.; Raymond, D.; Abraham, J.; Klein, E.A.; Walsh, R.M.; et al. Time to initial cancer treatment in the United States and association with survival over time: An observational study. PLoS ONE 2019, 14, e0213209. [Google Scholar] [CrossRef]
- Nadpara, P.; Madhavan, S.S.; Tworek, C. Guideline-concordant timely lung cancer care and prognosis among elderly patients in the United States: A population-based study. Cancer Epidemiol. 2015, 39, 1136–1144. [Google Scholar] [CrossRef]
- Vinod, S.K.; Chandra, A.; Berthelsen, A.; Descallar, J. Does timeliness of care in Non-Small Cell Lung Cancer impact on survival? Lung Cancer 2017, 112, 16–24. [Google Scholar] [CrossRef] [PubMed]
- Hall, H.; Tocock, A.; Burdett, S.; Fisher, D.; Ricketts, W.M.; Robson, J.; Round, T.; Gorolay, S.; MacArthur, E.; Chung, D.; et al. Association between time-to-treatment and outcomes in non-small cell lung cancer: A systematic review. Thorax 2022, 77, 762–768. [Google Scholar] [CrossRef] [PubMed]
- Tsai, C.H.; Kung, P.T.; Kuo, W.Y.; Tsai, W.C. Effect of time interval from diagnosis to treatment for non-small cell lung cancer on survival: A national cohort study in Taiwan. BMJ Open 2020, 10, e034351. [Google Scholar] [CrossRef] [PubMed]
- Wah, W.; Stirling, R.G.; Ahern, S.; Earnest, A. Influence of timeliness and receipt of first treatment on geographic variation in non-small cell lung cancer mortality. Int. J. Cancer 2021, 148, 1828–1838. [Google Scholar] [CrossRef]
- Stirling, R.; Brand, M.; Pellegrini, B.; Scarborough, R.; McNeil, J.; Evans, S.M.; Ahern, S.; Earnest, A.; Zalcberg, J.; on behalf of the Victorian Lung Cancer Registry. The Victorian Lung Cancer Registry Annual Report; Monash University, Department of Epidemiology and Preventive Medicine: Melbourne, Australia, 2020. [Google Scholar]
- Malalasekera, A.; Nahm, S.; Blinman, P.L.; Kao, S.C.; Dhillon, H.M.; Vardy, J.L. How long is too long? A scoping review of health system delays in lung cancer. Eur. Respir. Rev. 2018, 27, 149. [Google Scholar] [CrossRef]
- Ansar, A.; Lewis, V.; McDonald, C.F.; Liu, C.; Rahman, M.A. Factors influencing the timeliness of care for patients with lung cancer in Bangladesh. BMC Health Serv. Res. 2023, 23, 261. [Google Scholar] [CrossRef]
- Kim, M.L.; Matheson, L.; Garrard, B.; Francis, M.; Broad, A.; Malone, J.; Eastman, P.; Rogers, M.; Yap, C.H. Use of clinical quality indicators to improve lung cancer care in a regional/rural network of health services. Aust. J. Rural Health 2019, 27, 183–187. [Google Scholar] [CrossRef]
- Diaconescu, R.; Lafond, C.; Whittom, R. Treatment delays in non-small cell lung cancer and their prognostic implications. J. Thorac. Oncol. 2011, 6, 1254–1259. [Google Scholar] [CrossRef]
- Salomaa, E.-R.; Sällinen, S.; Hiekkanen, H.; Liippo, K. Delays in the diagnosis and treatment of lung cancer. Chest 2005, 128, 2282–2288. [Google Scholar] [CrossRef]
- Rudin, C.M.; Brambilla, E.; Faivre-Finn, C.; Sage, J. Small-cell lung cancer. Nat. Rev. Dis. Primers 2021, 7, 3. [Google Scholar]
- Latimer, K.M.; Mott, T.F. Lung cancer: Diagnosis, treatment principles, and screening. Am. Fam. Physician 2015, 91, 250–256. [Google Scholar]
- Niedzwiedz, C.L.; Knifton, L.; Robb, K.A.; Katikireddi, S.V.; Smith, D.J. Depression and anxiety among people living with and beyond cancer: A growing clinical and research priority. BMC Cancer 2019, 19, 943. [Google Scholar] [CrossRef] [PubMed]
- Koo, M.; Zhou, Y.; Lyratzopoulos, G. Delays in diagnosis and treatment of lung cancer: Lessons from US healthcare settings. Cancer Epidemiol. 2015, 39, 1145–1147. [Google Scholar] [CrossRef] [PubMed]
- Bi, Q.; Goodman, K.E.; Kaminsky, J.; Lessler, J. What is machine learning? A primer for the epidemiologist. Am. J. Epidemiol. 2019, 188, 2222–2239. [Google Scholar] [CrossRef]
- Li, L.; Lee, C.C.; Zhou, F.L.; Molony, C.; Doder, Z.; Zalmover, E.; Sharma, K.; Juhaeri, J.; Wu, C. Performance assessment of different machine learning approaches in predicting diabetic ketoacidosis in adults with type 1 diabetes using electronic health records data. Pharmacoepidemiol. Drug Saf. 2021, 30, 610–618. [Google Scholar] [CrossRef]
- Nagaraj, S.B.; Sidorenkov, G.; van Boven, J.F.M.; Denig, P. Predicting short- and long-term glycated haemoglobin response after insulin initiation in patients with type 2 diabetes mellitus using machine-learning algorithms. Diabetes Obes. Metab. 2019, 21, 2704–2711. [Google Scholar] [CrossRef]
- Guan, X.; Du, Y.; Ma, R.; Teng, N.; Ou, S.; Zhao, H.; Li, X. Construction of the XGBoost model for early lung cancer prediction based on metabolic indices. BMC Med. Inform. Decis. Mak. 2023, 23, 107. [Google Scholar] [CrossRef] [PubMed]
- Su, Z.; Huang, F.; Yin, C.; Yu, Y.; Yu, C. Clinical model of pulmonary metastasis in patients with osteosarcoma: A new multiple machine learning-based risk prediction. J. Orthop. Surg. 2023, 31, 10225536231177102. [Google Scholar] [CrossRef]
- Nunez-Benjumea, F.J.; Gonzalez-Garcia, S.; Moreno-Conde, A.; Riquelme-Santos, J.C.; Lopez-Guerra, J.L. Benchmarking machine learning approaches to predict radiation-induced toxicities in lung cancer patients. Clin. Transl. Radiat. Oncol. 2023, 41, 100640. [Google Scholar] [CrossRef]
- Weiss, J.; Raghu, V.K.; Bontempi, D.; Christiani, D.C.; Mak, R.H.; Lu, M.T.; Aerts, H.J. Deep learning to estimate lung disease mortality from chest radiographs. Nat. Commun. 2023, 14, 2797. [Google Scholar] [CrossRef]
- Shakir, H.; Aijaz, B.; Khan, T.M.R.; Hussain, M. A deep learning-based cancer survival time classifier for small datasets. Comput. Biol. Med. 2023, 160, 106896. [Google Scholar] [CrossRef] [PubMed]
- Albaradei, S.; Thafar, M.; Alsaedi, A.; Van Neste, C.; Gojobori, T.; Essack, M.; Gao, X. Machine learning and deep learning methods that use omics data for metastasis prediction. Comput. Struct. Biotechnol. J. 2021, 19, 5008–5018. [Google Scholar] [CrossRef] [PubMed]
- Ren, C.; Zhang, J.; Qi, M.; Zhang, J.; Zhang, Y.; Song, S.; Sun, Y.; Cheng, J. Machine learning based on clinico-biological features integrated (18)F-FDG PET/CT radiomics for distinguishing squamous cell carcinoma from adenocarcinoma of lung. Eur. J. Nucl. Med. Mol. Imaging 2021, 48, 1538–1549. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Xu, L.; Sun, L.; Zhang, P.; Farid, S.S. Machine learning application in personalised lung cancer recurrence and survivability prediction. Comput. Struct. Biotechnol. J. 2022, 20, 1811–1820. [Google Scholar] [CrossRef]
- Victoria Cancer Council and Department of Health. Optimal Care Pathway for People with Lung Cancer. Available online: https://www.cancer.org.au/assets/pdf/lung-cancer-optimal-cancer-care-pathway (accessed on 30 June 2023).
- Lababede, O.; Meziane, M.A. The Eighth Edition of TNM Staging of Lung Cancer: Reference Chart and Diagrams. Oncologist 2018, 23, 844–848. [Google Scholar] [CrossRef]
- Oken, M.M.; Creech, R.H.; Tormey, D.C.; Horton, J.; Davis, T.E.; McFadden, E.T.; Carbone, P.P. Toxicity and response criteria of the Eastern Cooperative Oncology Group. Am. J. Clin. Oncol. 1982, 5, 649–655. [Google Scholar] [CrossRef]
- Australian Bureau of Statistics. Census of Population and Housing: Socio-Economic Indexes for Areas (SEIFA), Australia; 2016. Available online: https://www.abs.gov.au/AUSSTATS/abs@.nsf/DetailsPage/2033.0.55.0012016?OpenDocument#Data (accessed on 30 June 2023).
- Australian Bureau of Statistics. Australian Statistical Geography Standard (ASGS): Volume 5—Remoteness Structure, July 2016. Available online: https://www.abs.gov.au/AUSSTATS/abs@.nsf/DetailsPage/1270.0.55.005July%202016?OpenDocument (accessed on 30 June 2023).
- Cerulli, G. Improving econometric prediction by machine learning. Appl. Econ. Lett. 2021, 28, 1419–1425. [Google Scholar] [CrossRef]
- Garavand, A.; Behmanesh, A.; Aslani, N.; Sadeghsalehi, H.; Ghaderzadeh, M. Towards Diagnostic Aided Systems in Coronary Artery Disease Detection: A Comprehensive Multiview Survey of the State of the Art. Int. J. Intell. Syst. 2023, 2023, 6442756. [Google Scholar] [CrossRef]
- Garavand, A.; Salehnasab, C.; Behmanesh, A.; Aslani, N.; Zadeh, A.H.; Ghaderzadeh, M. Efficient Model for Coronary Artery Disease Diagnosis: A Comparative Study of Several Machine Learning Algorithms. J. Healthc. Eng. 2022, 2022, 5359540. [Google Scholar] [CrossRef]
- Ghaderzadeh, M. Clinical decision support system for early detection of prostate cancer from benign hyperplasia of prostate. Stud Health Technol Inform. 2013, 192, 928. [Google Scholar]
- Sadoughi, F.; Ghaderzadeh, M. A hybrid particle swarm and neural network approach for detection of prostate cancer from benign hyperplasia of prostate. Stud. Health Technol. Inform. 2014, 205, 481–485. [Google Scholar] [PubMed]
- Altman, D.G. Practical Statistics for Medical Research; Chapman and Hall: London, UK, 1991. [Google Scholar]
- Frosch, Z.A.; Hasler, J.; Handorf, E.; DuBois, T.; Bleicher, R.J.; Edelman, M.J.; Geynisman, D.M.; Hall, M.J.; Fang, C.Y.; Lynch, S.M. Development of a Multilevel Model to Identify Patients at Risk for Delay in Starting Cancer Treatment. JAMA Netw. Open 2023, 6, e2328712. [Google Scholar] [CrossRef]
- Pitter, J.G.; Moizs, M.; Ezer, É.S.; Lukács, G.; Szigeti, A.; Repa, I.; Csanádi, M.; Rutten-van Mölken, M.P.; Islam, K.; Kaló, Z.; et al. Improved survival of non-small cell lung cancer patients after introducing patient navigation: A retrospective cohort study with propensity score weighted historic control. PLoS ONE 2022, 17, e0276719. [Google Scholar] [CrossRef] [PubMed]
- Damsees, R.; Jaghbir, M.; Salam, M.; Al-Omari, A.; Al-Rawashdeh, N. Unravelling the predictors of late cancer presentation and diagnosis in Jordan: A cross-sectional study of patients with lung and colorectal cancers. BMJ Open 2023, 13, e069529. [Google Scholar] [CrossRef] [PubMed]
- Hochhegger, B.; Alves, G.R.T.; Irion, K.L.; Fritscher, C.C.; Fritscher, L.G.; Concatto, N.H.; Marchiori, E. PET/CT imaging in lung cancer: Indications and findings. J. Bras. De Pneumol. 2015, 41, 264–274. [Google Scholar] [CrossRef]
- Desseroit, M.C.; Visvikis, D.; Tixier, F.; Majdoub, M.; Perdrisot, R.; Guillevin, R.; Cheze Le Rest, C.; Hatt, M. Development of a nomogram combining clinical staging with 18 F-FDG PET/CT image features in non-small-cell lung cancer stage I–III. Eur. J. Nucl. Med. Mol. Imaging 2016, 43, 1477–1485. [Google Scholar] [CrossRef]
- Mangiameli, G.; Cioffi, U.; Testori, A. Lung cancer treatment: From tradition to innovation. Front. Oncol. 2022, 12, 858242. [Google Scholar] [CrossRef]
- Forrest, L.; Adams, J.; White, M.; Rubin, G. Factors associated with timeliness of post-primary care referral, diagnosis and treatment for lung cancer: Population-based, data-linkage study. Br. J. Cancer 2014, 111, 1843–1851. [Google Scholar] [CrossRef]
- Lewis, R.; Pereira, P.; Thorlby, R.; Warburton, W. Understanding and sustaining the health care service shifts accelerated by COVID-19. Health Found. 2020. Available online: https://apo.org.au/node/308329 (accessed on 12 August 2023).
- Sutherland, K.; Chessman, J.; Zhao, J.; Sara, G.; Shetty, A.; Smith, S.; Went, A.; Dyson, S.; Levesque, J.F. Impact of COVID-19 on healthcare activity in NSW, Australia. Public Health Res. Pract. 2020, 30, 3042030. [Google Scholar] [CrossRef]
- Al-Quteimat, O.M.; Amer, A.M. The impact of the COVID-19 pandemic on cancer patients. Am. J. Clin. Oncol. 2020, 43, 452–455. [Google Scholar] [CrossRef] [PubMed]
- Wassie, L.A.; Tsega, S.S.; Melaku, M.S.; Aemro, A. Delayed treatment initiation and its associated factors among cancer patients at Northwest Amhara referral hospital oncology units: A cross-sectional study. Int. J. Afr. Nurs. Sci. 2023, 18, 100568. [Google Scholar]
- Dalton, S.O.; Frederiksen, B.L.; Jacobsen, E.; Steding-Jessen, M.; Østerlind, K.; Schüz, J.; Osler, M.; Johansen, C. Socioeconomic position, stage of lung cancer and time between referral and diagnosis in Denmark, 2001–2008. Br. J. Cancer 2011, 105, 1042–1048. [Google Scholar] [CrossRef] [PubMed]
- Forrest, L.F.; Sowden, S.; Rubin, G.; White, M.; Adams, J. Socio-economic inequalities in stage at diagnosis, and in time intervals on the lung cancer pathway from first symptom to treatment: Systematic review and meta-analysis. Thorax 2017, 72, 430–436. [Google Scholar] [CrossRef]
- Baldwin, D.R. Socioeconomic position and delays in lung cancer diagnosis: Should we target the more deprived? Thorax 2017, 72, 393–395. [Google Scholar] [CrossRef]
- De Souza, J.A.; Hunt, B.; Asirwa, F.C.; Adebamowo, C.; Lopes, G. Global health equity: Cancer care outcome disparities in high-, middle-, and low-income countries. J. Clin. Oncol. 2016, 34, 6. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. WHO Report on Cancer: Setting Priorities, Investing Wisely and Providing Care for All; World Health Organization: Geneva, Switzerland, 2020. [Google Scholar]
- Stump, T.K.; Eghan, N.; Egleston, B.L.; Hamilton, O.; Pirollo, M.; Schwartz, J.S.; Armstrong, K.; Beck, J.R.; Meropol, N.J.; Wong, Y.-N. Cost concerns of patients with cancer. J. Oncol. Pract. 2013, 9, 251–257. [Google Scholar] [CrossRef] [PubMed]
- Carrera, P.M.; Kantarjian, H.M.; Blinder, V.S. The financial burden and distress of patients with cancer: Understanding and stepping-up action on the financial toxicity of cancer treatment. CA A Cancer J. Clin. 2018, 68, 153–165. [Google Scholar] [CrossRef]
- Dickman, S.L.; Himmelstein, D.U.; Woolhandler, S. Inequality and the health-care system in the USA. Lancet 2017, 389, 1431–1441. [Google Scholar] [CrossRef]
- Ginzberg, E. Access to health care for Hispanics. In Health Policy and the Hispanic; Routledge: Oxfordshire, UK, 2019; pp. 22–31. [Google Scholar]
- Havlik, R.J.; Yancik, R.; Long, S.; Ries, L.; Edwards, B. The National Institute on Aging and the National Cancer Institute SEER collaborative study on comorbidity and early diagnosis of cancer in the elderly. Cancer 1994, 74, 2101–2106. [Google Scholar] [CrossRef]
- Munjal, N.K.; Clark, R.S.B.; Simon, D.W.; Kochanek, P.M.; Horvat, C.M. Interoperable and explainable machine learning models to predict morbidity and mortality in acute neurological injury in the pediatric intensive care unit: Secondary analysis of the TOPICC study. Front. Pediatr. 2023, 11, 1177470. [Google Scholar] [CrossRef] [PubMed]
- Institute of Medicine (US) Committee on Quality of Health Care in America. Crossing the Quality Chasm: A New Health System for the 21st Century; National Academies Press: Washington, DC, USA, 2001.


{kind=link}
{kind=link}
{kind=link}
| Variables | QI 1 No | QI 1 Yes | Whole Cohort | p-Value | Test |
|---|---|---|---|---|---|
| N | 3594 | 8008 | 11,602 | ||
| Sex | 0.027 | Pearson’s chi-squared | |||
| Male | 1969 (54.8%) | 4564 (57.0%) | 6533 (56.3%) | ||
| Female | 1625 (45.2%) | 3444 (43.0%) | 5069 (43.7%) | ||
| Age, mean (SD) | 70.1 (10.0) | 68.9 (10.9) | 69.3 (10.6) | <0.001 | Two-sample t test |
| ECOG status at diagnosis | <0.001 | Pearson’s chi-squared | |||
| 0—Fully active, able to carry on all normal activity without restriction | 1005 (28.0%) | 1809 (22.6%) | 2814 (24.3%) | ||
| 1—Restricted in physically strenuous activity but ambulatory and able to carry out light work | 955 (26.6%) | 2467 (30.8%) | 3422 (29.5%) | ||
| 2—Ambulatory and capable of all self-care but unable to carry out any work activities | 282 (7.8%) | 850 (10.6%) | 1132 (9.8%) | ||
| 3—Capable of only limited self-care, confined to bed or chair more than 50% of waking hours | 105 (2.9%) | 393 (4.9%) | 498 (4.3%) | ||
| 4—Completely disabled. Not able to care for self. Totally confined to bed or chair | 13 (0.4%) | 55 (0.7%) | 68 (0.6%) | ||
| 8—Not available at time of presentation | 4 (0.1%) | 17 (0.2%) | 21 (0.2%) | ||
| 9—Not stated | 1230 (34.2%) | 2417 (30.2%) | 3647 (31.4%) | ||
| English as first language | <0.001 | Pearson’s chi-squared | |||
| No | 414 (11.5%) | 712 (8.9%) | 1126 (9.7%) | ||
| Yes | 3180 (88.5%) | 7296 (91.1%) | 10,476 (90.3%) | ||
| Smoking status | 0.001 | Pearson’s chi-squared | |||
| Current smoker | 1212 (33.7%) | 2892 (36.1%) | 4104 (35.4%) | ||
| Ex-smoker | 1863 (51.8%) | 4005 (50.0%) | 5868 (50.6%) | ||
| Never smoker | 455 (12.7%) | 908 (11.3%) | 1363 (11.7%) | ||
| Not stated | 64 (1.8%) | 203 (2.5%) | 267 (2.3%) | ||
| Remoteness | 0.010 | Pearson’s chi-squared | |||
| Inner regional Australia | 954 (26.5%) | 2166 (27.1%) | 3120 (26.9%) | ||
| Major cities of Australia | 2410 (67.1%) | 5210 (65.1%) | 7620 (65.7%) | ||
| Outer regional Australia | 224 (6.2%) | 624 (7.8%) | 848 (7.3%) | ||
| Remote Australia | 6 (0.2%) | 7 (0.1%) | 13 (0.1%) | ||
| Clinical stage | <0.001 | Pearson’s chi-squared | |||
| Stage 1 | 1005 (28.0%) | 612 (7.6%) | 1617 (13.9%) | ||
| Stage 2 | 423 (11.8%) | 468 (5.8%) | 891 (7.7%) | ||
| Stage 3 | 509 (14.2%) | 1333 (16.6%) | 1842 (15.9%) | ||
| Stage 4 | 845 (23.5%) | 4474 (55.9%) | 5319 (45.8%) | ||
| Cannot be assessed | 812 (22.6%) | 1121 (14.0%) | 1933 (16.7%) | ||
| Lung cancer type | <0.001 | Pearson’s chi-squared | |||
| NSCLC | 3344 (93.1%) | 6836 (85.4%) | 10,180 (87.8%) | ||
| SCLC | 249 (6.9%) | 1172 (14.6%) | 1421 (12.2%) | ||
| Australian born | <0.001 | Pearson’s chi-squared | |||
| Other/Not stated | 1497 (41.7%) | 3027 (37.8%) | 4524 (39.0%) | ||
| Australia | 2097 (58.3%) | 4981 (62.2%) | 7078 (61.0%) | ||
| Index of relative socio-economic disadvantage, mean (SD) | 997.4 (70.7) | 1001.9 (70.0) | 1000.5 (70.2) | 0.001 | Two-sample t test |
| Index of economic resources, mean (SD) | 990.1 (60.7) | 992.4 (60.2) | 991.7 (60.3) | 0.054 | Two-sample t test |
| Index of education and occupation, mean (SD) | 1003.6 (85.2) | 1008.9 (86.7) | 1007.2 (86.3) | 0.002 | Two-sample t test |
| Index of relative socio-economic advantage and disadvantage, mean (SD) | 995.9 (75.2) | 1000.6 (76.1) | 999.1 (75.9) | 0.002 | Two-sample t test |
| Model | Parameters | Training CER | Validation CER | Training AUC | Testing AUC |
|---|---|---|---|---|---|
| Decision trees | Tree depth = 5 | 25.90% | 28.20% | 0.74 | 0.71 |
| Random forests | Tree depth = 10 | 21.60% | 23.40% | 0.79 | 0.74 |
| # splitting features = 10 | |||||
| # of trees = 100 | |||||
| Regularized multinomial | Penalisation parameter, alpha = 0.01 | 26.60% | 27.30% | 0.73 | 0.73 |
| Elastic parameter (regularization = 0) | |||||
| Boosting | Tree depth = 15 | 0.10% | 0.10% | 0.99 | 0.83 |
| # of trees = 150 | |||||
| Learning rate = 0.3 | |||||
| Nearest neighbour | # of neighbours = 100 | 0.10% | 0.10% | 0.99 | 0.85 |
| Kernel = distance | |||||
| Neural networks | # of layers = 4 | 31.00% | 31.10% | 0.73 | 0.73 |
| # of neurons = 1 | |||||
| L2 penalisation = 0.5 | |||||
| Naïve Bayes | Variance smoothing = 0.001 | 35.20% | 34.80% | 0.73 | 0.73 |
| Support vector machine | Margin parameter, C = 1 | 0.20% | 0.10% | 0.99 | 0.89 |
| Inverse distance, gamma = 1 | |||||
| Logistic regression | NA | 26.50% | 26.60% | 0.73 | 0.73 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Earnest, A.; Tesema, G.A.; Stirling, R.G. Machine Learning Techniques to Predict Timeliness of Care among Lung Cancer Patients. Healthcare 2023, 11, 2756. https://doi.org/10.3390/healthcare11202756
Earnest A, Tesema GA, Stirling RG. Machine Learning Techniques to Predict Timeliness of Care among Lung Cancer Patients. Healthcare. 2023; 11(20):2756. https://doi.org/10.3390/healthcare11202756
Chicago/Turabian StyleEarnest, Arul, Getayeneh Antehunegn Tesema, and Robert G. Stirling. 2023. "Machine Learning Techniques to Predict Timeliness of Care among Lung Cancer Patients" Healthcare 11, no. 20: 2756. https://doi.org/10.3390/healthcare11202756
APA StyleEarnest, A., Tesema, G. A., & Stirling, R. G. (2023). Machine Learning Techniques to Predict Timeliness of Care among Lung Cancer Patients. Healthcare, 11(20), 2756. https://doi.org/10.3390/healthcare11202756