
Multiple-Perspective Data-Driven Analysis of Online Health Communities

Abstract
:1. Introduction
1.1. Health-Related Social Media and Stakeholder Perspectives
1.1.1. Individual Perspective
1.1.2. Professional Perspective
1.1.3. Organisational Perspective
1.2. Related Work
1.3. Data Subject Matter
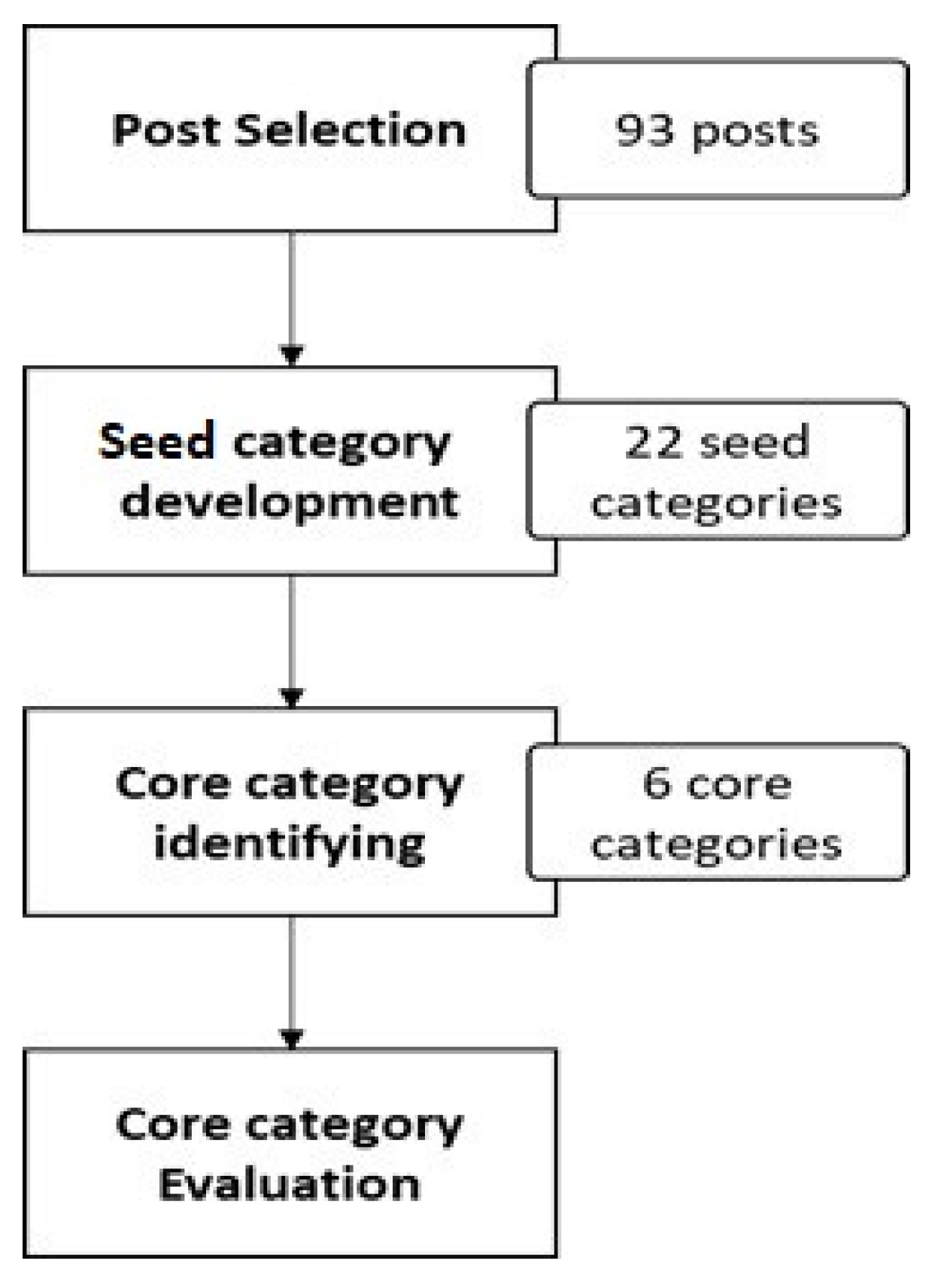
2. Materials and Methods
2.1. Sentiment Analysis
2.1.1. Domain-Dependent Categories Identification
2.1.2. Sentiment Classification
2.1.3. Feature Sets Generation
2.2. Content Analysis
2.3. Topic Analysis
3. Results
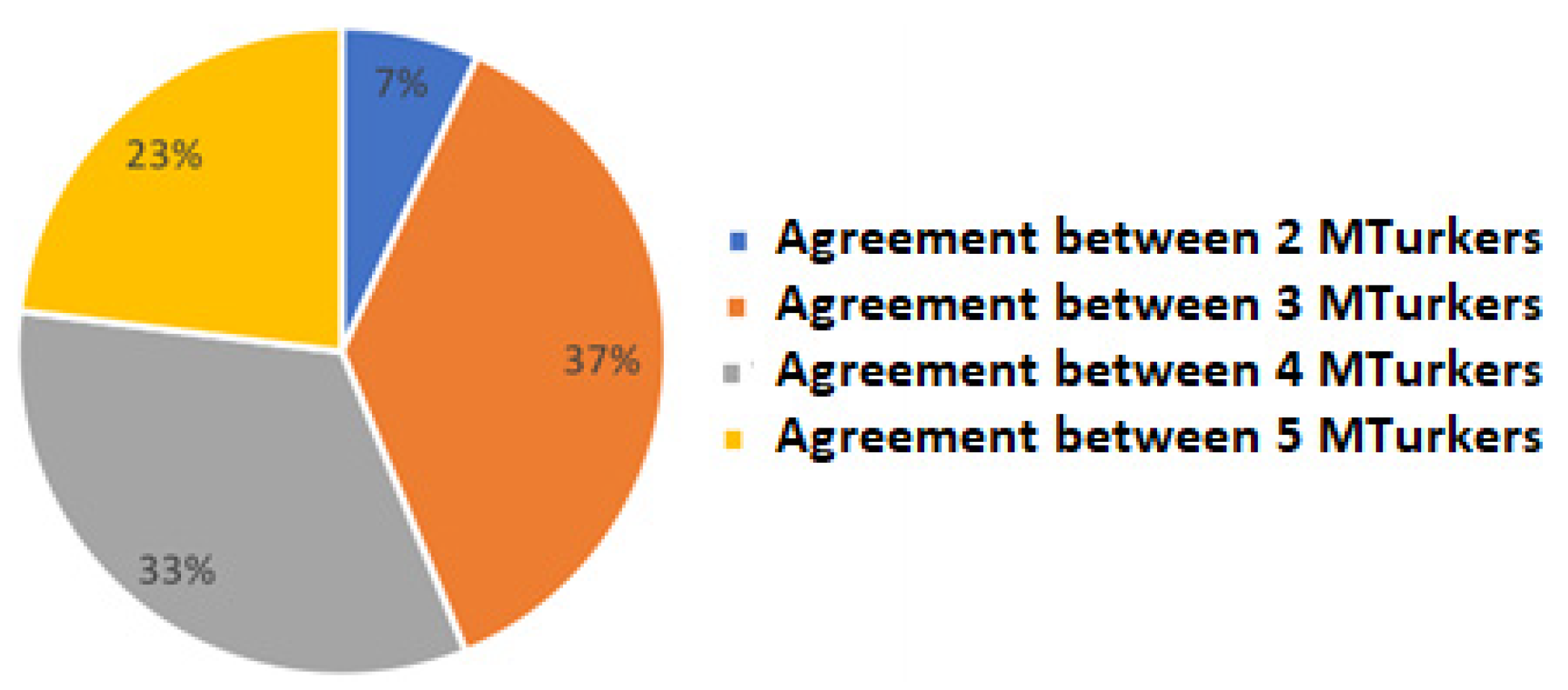
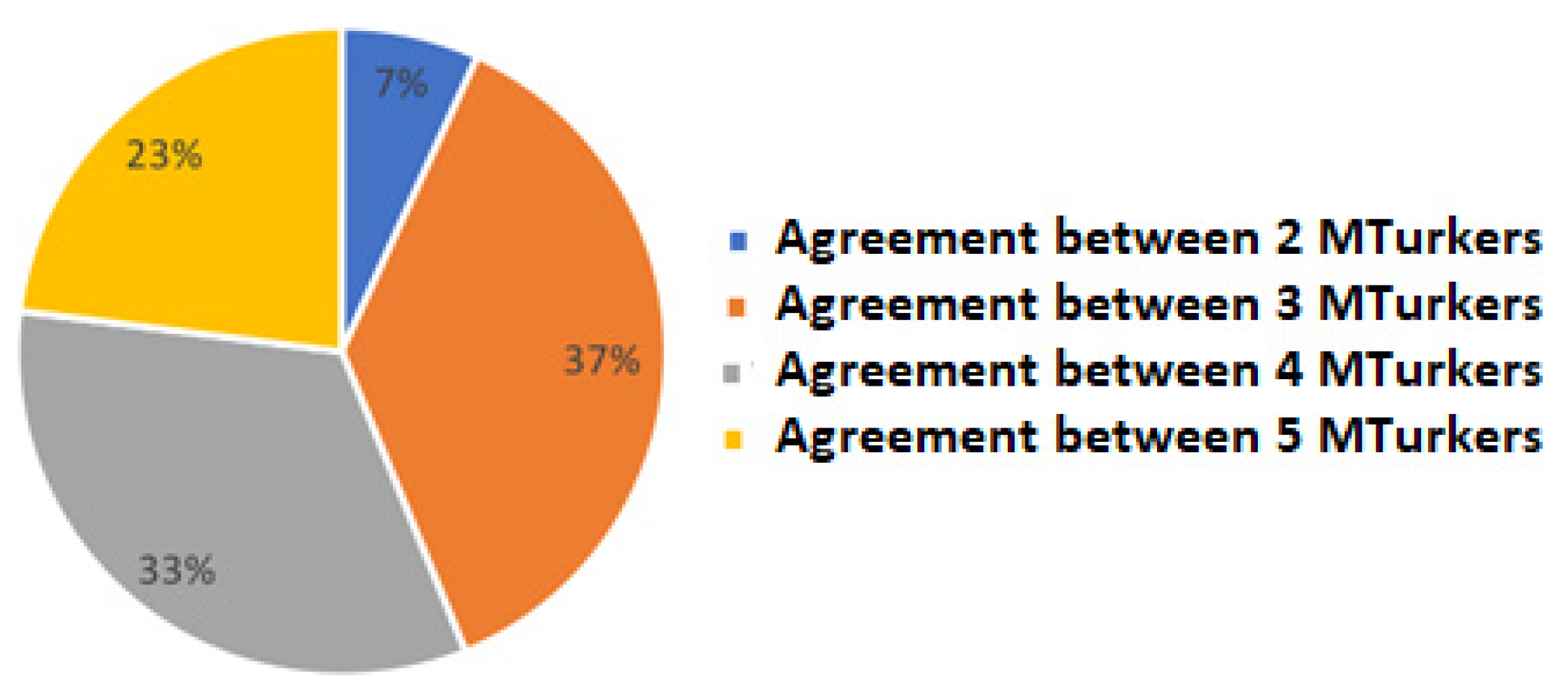
3.1. Accuracy of Sentiment Analysis
Comparison with Expert Opinion
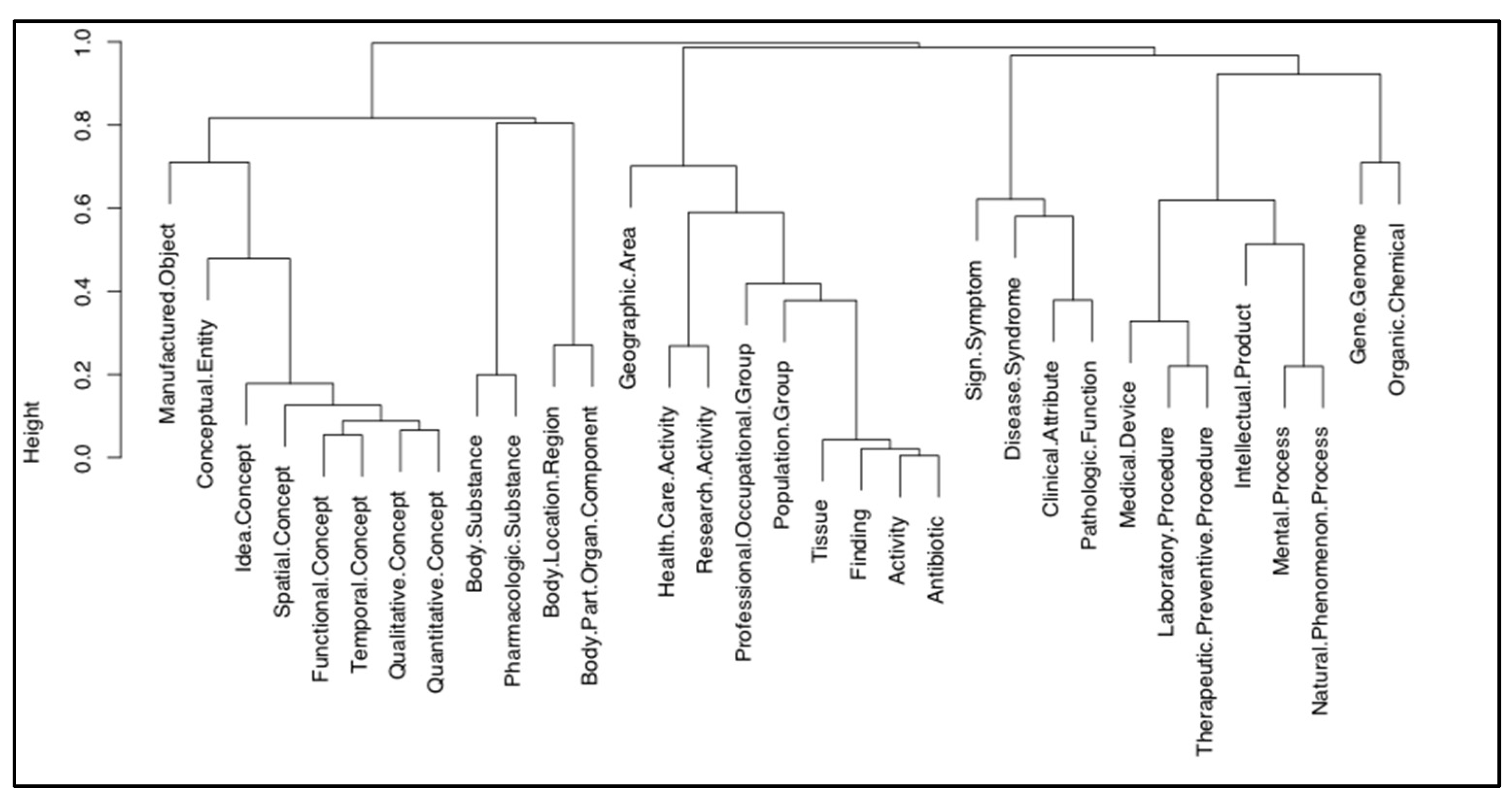
3.2. Content Analysis Results
3.3. Topic Analysis Results
Comparison with Patient Information Leaflets
4. Discussion
4.1. Interpretation of Sentiment Analysis
4.2. Interpretation of Content Analysis
4.3. Interpretation of Topic Analysis
4.4. Further Discussion: Benefits to Stakeholders
4.5. Further Discussion: Generalisability of Sentiment Classes, Concepts, and Topics
5. Conclusions
Scope for Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Denecke, K. Health Web Science: Social Media Data for Healthcare; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Van De Belt, T.H.; Engelen, L.J.; Berben, S.A.; Schoonhoven, L. Definition of Health 2.0 and Medicine 2.0: A systematic review. J. Medical Internet Res. 2010, 12, e18. [Google Scholar] [CrossRef] [PubMed]
- Lenzi, A.; Maranghi, M.; Stilo, G.; Velardi, P. The social phenotype: Extracting a patient-centered perspective of diabetes from health-related blogs. Artif. Intell. Med. 2019, 101, 101727. [Google Scholar] [CrossRef] [PubMed]
- Amelung, D.; Whitaker, K.L.; Lennard, D.; Ogden, M.; Sheringham, J.; Zhou, Y.; Walter, F.M.; Singh, H.; Vincent, C.; Black, G. Influence of doctor-patient conversations on behaviours of patients presenting to primary care with new or persistent symptoms: A video observation study. BMJ Qual. Saf. 2020, 29, 198–208. [Google Scholar] [CrossRef]
- Declercq, J. Talking about chronic pain: Misalignment in discussions of the body, mind and social aspects in pain clinic consultations. Health 2021, 27, 378–397. [Google Scholar] [CrossRef] [PubMed]
- Furst, D.E.; Tran, M.; Sullivan, E.; Pike, J.; Piercy, J.; Herrera, V.; Palmer, J.B. Misalignment between physicians and patient satisfaction with psoriatic arthritis disease control. Clin. Rheumatol. 2017, 36, 2045–2054. [Google Scholar] [CrossRef] [PubMed]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–67. [Google Scholar]
- Schwartz, H.A.; Ungar, L.H. Data-driven content analysis of social media: A systematic overview of automated methods. Ann. Am. Acad. Political Soc. Sci. 2015, 659, 78–94. [Google Scholar] [CrossRef]
- Blei, D.M. Probabilistic topic models. Commun. ACM. 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Moorhead, S.A.; Hazlett, D.E.; Harrison, L.; Carroll, J.K.; Irwin, A.; Hoving, C. A new dimension of health care: Systematic review of the uses, benefits, and limitations of social media for health communication. J. Med. Internet Res. 2013, 15, e85. [Google Scholar] [CrossRef]
- Sarasohn-Kahn, J. The Wisdom of Patients: Health Care Meets Online Social Media. California HealthCare Foundation. 2008. Available online: https://www.chcf.org/wp-content/uploads/2017/12/PDF-HealthCareSocialMedia.pdf (accessed on 17 July 2023).
- Fox, S.; Duggan, M. Health Online 2013. Pew Research Centre. 2013. Available online: https://www.pewresearch.org/internet/2013/01/15/health-online-2013/ (accessed on 17 July 2023).
- Greenhalgh, T. Patient and public involvement in chronic illness: Beyond the expert patient. BMJ 2009, 338, b49. [Google Scholar] [CrossRef]
- Rodrigues, R.G.; das Dores, R.M.; Camilo-Junior, C.G.; Rosa, T.C. SentiHealth-Cancer: A sentiment analysis tool to help detect mood of patients in online social networks. Int. J. Med. Inform. 2016, 85, 80–95. [Google Scholar] [CrossRef] [PubMed]
- Antheunis, M.L.; Tates, K.; Nieboer, T.E. Patients’ and health professionals’ use of social media in health care: Motives, barriers and expectations. Patient Educ. Couns. 2013, 92, 426–431. [Google Scholar] [CrossRef] [PubMed]
- Brownstein, J.S.; Freifeld, C.C.; Madoff, L.C. Digital disease detection—Harnessing the Web for public health surveillance. N. Engl. J. Med. 2009, 360, 2153. [Google Scholar] [CrossRef] [PubMed]
- Short, J.; Williams, E.; Christie, B. The Social Psychology of Telecommunications; Wiley: Toronto, ON, Canada; London, UK; New York, NY, USA, 1976. [Google Scholar]
- Ubel, P.A.; Jepson, C.; Baron, J. The inclusion of patient testimonials in decision aids: Effects on treatment choices. Med. Decis. Mak. 2001, 21, 60–68. [Google Scholar] [CrossRef]
- Greaves, F.; Ramirez-Cano, D.; Millett, C.; Darzi, A.; Donaldson, L. Harnessing the cloud of patient experience: Using social media to detect poor quality healthcare. BMJ Qual. Saf. 2013, 22, 251–255. [Google Scholar] [CrossRef]
- Denecke, K.; Nejdl, W. How valuable is medical social media data? Content analysis of the medical web. Inf. Sci. 2009, 179, 1870–1880. [Google Scholar]
- Lu, Y.; Wu, Y.; Liu, J.; Li, J.; Zhang, P. Understanding health care social media use from different stakeholder perspectives: A content analysis of an online health community. J. Med. Internet Res. 2017, 19, e109. [Google Scholar] [CrossRef]
- Pattisapu, N.; Gupta, M.; Kumaraguru, P.; Varma, V. A distant supervision based approach to medical persona classification. J. Biomed. Inform. 2019, 49, 103205. [Google Scholar] [CrossRef]
- Sedereviciute, K.; Valentini, C. Towards a more holistic stakeholder analysis approach. Mapping known and undiscovered stakeholders from social media. Int. J. Strateg. Commun. 2011, 5, 221–239. [Google Scholar]
- Stanek, G.; Wormser, G.P.; Gray, J.; Strle, F. Lyme borreliosis. Lancet 2012, 379, 461–473. [Google Scholar] [CrossRef]
- Feder, H.M., Jr.; Johnson, B.J.; O’Connell, S.; Shapiro, E.D.; Steere, A.C.; Wormser, G.P. Ad Hoc International Lyme Disease Group. A critical appraisal of “chronic Lyme disease”. N. Engl. J. Med. 2007, 357, 1422–1430. [Google Scholar] [CrossRef] [PubMed]
- Lantos, P.M. Chronic Lyme disease: The controversies and the science. Expert Rev. Anti-Infect. Ther. 2011, 9, 787–797. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Xiao, W.; Fang, C.; Zhang, X.; Lin, J. Social support, belongingness, and value co-creation behaviors in online health communities. Telemat. Inform. 2020, 50, 101398. [Google Scholar] [CrossRef]
- Lederman, R.; Fan, H.; Smith, S.; Chang, S. Who can you trust? Credibility assessment in online health forums. Health Policy Technol. 2014, 3, 13–25. [Google Scholar]
- Yiannakoulias, N.; Tooby, R.; Sturrock, S.L. Celebrity over science? An analysis of Lyme disease video content on YouTube. Soc. Sci. Med. 2017, 191, 57–60. [Google Scholar] [PubMed]
- Shearer, C. The CRISP-DM model: The new blueprint for data mining. J. Data Warehous. 2000, 5, 13–22. [Google Scholar]
- Denecke, K.; Deng, Y. Sentiment analysis in medical settings: New opportunities and challenges. Artif. Intell. Med. 2015, 64, 17–27. [Google Scholar] [CrossRef] [PubMed]
- Bobicev, V.; Sokolova, M. Thumbs up and down: Sentiment analysis of medical online forums. In Proceedings of the 2018 EMNLP Workshop SMM4H: The 3rd Social Media Mining for Health Applications Workshop & Shared Task, Brussels, Belgium, 31 October 2018; pp. 22–26. [Google Scholar]
- Carrillo-de-Albornoz, J.; Rodriguez Vidal, J.; Plaza, L. Feature engineering for sentiment analysis in e-health forums. PLoS ONE 2018, 13, e0207996. [Google Scholar] [CrossRef]
- Jiménez-Zafra, S.M.; Martín-Valdivia, M.T.; Molina-González, M.D.; Ureña-López, L.A. How do we talk about doctors and drugs? Sentiment analysis in forums expressing opinions for medical domain. Artif. Intell. Med. 2019, 93, 50–57. [Google Scholar]
- Korkontzelos, I.; Nikfarjam, A.; Shardlow, M.; Sarker, A.; Ananiadou, S.; Gonzalez, G.H. Analysis of the effect of sentiment analysis on extracting adverse drug reactions from tweets and forum posts. J. Biomed. Inform. 2016, 62, 148–158. [Google Scholar] [CrossRef]
- Yang, F.C.; Lee, A.J.; Kuo, S.C. Mining health social media with sentiment analysis. J. Med. Syst. 2016, 40, 236. [Google Scholar] [CrossRef] [PubMed]
- Ali, T.; Schramm, D.; Sokolova, M.; Inkpen, D. Can I Hear You? Sentiment Analysis on Medical Forums. In Proceedings of the Sixth International Joint Conference on Natural Language Processing (IJCNLP), Nagoya, Japan, 14–19 October 2013; pp. 667–673. [Google Scholar]
- Nguyen, A.X.L.; Trinh, X.V.; Wang, S.Y.; Wu, A.Y. Determination of patient sentiment and emotion in ophthalmology: Infoveillance tutorial on web-based health forum discussions. J. Med. Internet Res. 2021, 23, e20803. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.L.; He, Y.; Yu, L.C.; Lai, K.R. Identifying emotion labels from psychiatric social texts using a bi-directional LSTM-CNN model. IEEE Access 2020, 8, 66638–66646. [Google Scholar] [CrossRef]
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 378. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Zheng, R.; Li, J.; Chen, H.; Huang, Z. A framework for authorship identification of online messages: Writing-style features and classification techniques. J. Am. Soc. Inf. Sci. Technol. 2006, 57, 378–393. [Google Scholar] [CrossRef]
- Yang, Y. An evaluation of statistical approaches to text categorization. Inf. Retr. 1999, 1, 69–90. [Google Scholar] [CrossRef]
- Guo, B.; Nixon, M.S. Gait feature subset selection by mutual information. IEEE Trans. Syst. Man Cybern. 2009, 39, 36–46. [Google Scholar]
- Stemler, S. An overview of content analysis. Pract. Assess. Res. Eval. 2000, 7, 17. [Google Scholar]
- Krippendorff, K. Content Analysis: An Introduction to its Methodology; Sage: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- Berelson, B. Content Analysis in Communication Research; Free Press: Glencoe, UK, 1952. [Google Scholar]
- Chew, C.; Eysenbach, G. Pandemics in the age of Twitter: Content analysis of Tweets during the 2009 H1N1 outbreak. PLoS ONE 2010, 5, e14118. [Google Scholar] [CrossRef]
- Gottschalk, L.A.; Gleser, G.C. The Measurement of Psychological States through the Content Analysis of Verbal Behavior; University of California Press: Los Angeles, CA, USA, 2022. [Google Scholar]
- Li, J.; Xu, Q.; Cuomo, R.; Purushothaman, V.; Mackey, T. Data mining and content analysis of the Chinese social media platform Weibo during the early COVID-19 outbreak: Retrospective observational infoveillance study. JMIR Public Health Surveill. 2020, 6, e18700. [Google Scholar] [CrossRef] [PubMed]
- Van Eenbergen, M.C.; van de Poll-Franse, L.V.; Krahmer, E.; Verberne, S.; Mols, F. Analysis of content shared in online cancer communities: Systematic review. JMIR Cancer 2018, 4, e6. [Google Scholar] [CrossRef] [PubMed]
- Spärck Jones, K. IDF term weighting and IR research lessons. J. Doc. 2004, 60, 521–523. [Google Scholar] [CrossRef]
- Humphreys, B.L.; Lindberg, D.A.; Schoolman, H.M.; Barnett, G.O. The unified medical language system: An informatics research collaboration. J. Am. Med. Inform. Assoc. 1998, 5, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Aronson, A.R. Effective mapping of biomedical text to the UMLS Metathesaurus: The MetaMap program 2001. In Proceedings of the AMIA Symposium 2001; American Medical Informatics Association: Bethesda, MY, USA.
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Frameworks for Topic Modelling with Large Corpora. In Proceedings of the LREC Workshop in New Challenges for NLP Framweorks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- Sorensen, T. A method of establishing groups of equal amplitude in plant sociology based on similarity of species and its application to analyses of the vegetation on Danish commons. Biol. Skrifter 1948, 5, 1–34. [Google Scholar]
- Zhao, W.X.; Jiang, J.; Weng, J.; He, J.; Lim, E.P.; Yan, H.; Li, X. Comparing twitter and traditional media using topic models. In Proceedings of the Advances in Information Retrieval: 33rd European Conference on IR Research, ECIR 2011, Dublin, Ireland, 18–21 April 2011; pp. 338–349. [Google Scholar]
- Ozyurt, B.; Akcayol, M.A. A new topic modeling based approach for aspect extraction in aspect based sentiment analysis: SS-LDA. Expert Syst. Appl. 2021, 168, 114231. [Google Scholar] [CrossRef]
- Onan, A. Biomedical text categorization based on ensemble pruning and optimized topic modelling. Comput. Math. Methods Med. 2018, 2018, 2497471. [Google Scholar] [CrossRef]
- Zhan, Y.; Liu, R.; Li, Q.; Leischow, S.J.; Zeng, D.D. Identifying topics for e-cigarette user-generated contents: A case study from multiple social media platforms. J. Med. Internet Res. 2017, 19, e24. [Google Scholar] [CrossRef]
- Miller, M.; Banerjee, T.; Muppalla, R.; Romine, W.; Sheth, A. What are people tweeting about Zika? An exploratory study concerning its symptoms, treatment, transmission, and prevention. JMIR Public Health Surveill. 2017, 3, e38. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Barde, B.V.; Bainwad, A.M. An overview of topic modeling methods and tools. In Proceedings of the 2017 International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 15–16 June 2017; pp. 745–750. [Google Scholar]
- Röder, M.; Both, A.; Hinneburg, A. Exploring the space of topic coherence measures. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 399–408. [Google Scholar]
- Rodriguez, M.G.; Gummadi, K.; Schoelkopf, B. Quantifying information overload in social media and its impact on social contagions. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–6 June 2014. [Google Scholar]
- Wurman, R.S. Information Anxiety; Doubleday: New York, NY, USA, 2001. [Google Scholar]
- Wang, C.; Xiao, Z.; Liu, Y.; Xu, Y.; Zhou, A.; Zhang, K. SentiView: Sentiment analysis and visualization for internet popular topics. IEEE Trans. Hum. Mach. Syst. 2013, 43, 620–630. [Google Scholar] [CrossRef]
- Zhang, J.; Wolfram, D.; Wang, P.; Hong, Y.; Gillis, R. Visualization of health-subject analysis based on query term co-occurrences. J. Am. Soc. Inf. Sci. Technol. 2008, 59, 1933–1947. [Google Scholar] [CrossRef]
- Park, J.; Ryu, Y.U. Online discourse on fibromyalgia: Text-mining to identify clinical distinction and patient concerns. Med. Sci. Monit. Int. Med. J. Exp. Clin. Res. 2014, 20, 1858–1864. [Google Scholar]
- He, K.; Hong, N.; Lapalme-Remis, S.; Lan, Y.; Huang, M.; Li, C.; Yao, L. Understanding the patient perspective of epilepsy treatment through text mining of online patient support groups. Epilepsy Behav. 2019, 94, 65–71. [Google Scholar] [CrossRef]
- Smith, C.A. Consumer language, patient language, and thesauri: A review of the literature. J. Med. Libr. Assoc. 2011, 99, 135–144. [Google Scholar] [CrossRef]
- Bauer, A.M.; Alegría, M. Impact of patient language proficiency and interpreter service use on the quality of psychiatric care: A systematic review. Psychiatr. Serv. 2010, 61, 765–773. [Google Scholar] [CrossRef]
- Dirckx, J.H. The Language of Medicine: Its Evolution, Structure and Dynamics, 2nd ed.; Harper & Row: Hagerstown, MD, USA, 1983. [Google Scholar]
- Cole, J.; Watkins, C.; Kleine, D. Health advice from internet discussion forums: How bad is dangerous? J. Med. Internet Res. 2016, 18, e4. [Google Scholar] [CrossRef]
- Guo, B.; Ding, Y.; Yao, L.; Liang, Y.; Yu, Z. The future of false information detection on social media: New perspectives and trends. ACM Comput. Surv. 2020, 53, 1–36. [Google Scholar] [CrossRef]
- Hargittai, E. Potential biases in big data: Omitted voices on social media. Soc. Sci. Comput. Rev. 2020, 38, 10–24. [Google Scholar] [CrossRef]
- Wicks, P.; Massagli, M.; Frost, J.; Brownstein, C.; Okun, S.; Vaughan, T.; Heywood, J. Sharing health data for better outcomes on PatientsLikeMe. J. Med. Internet Res. 2010, 12, e1549. [Google Scholar] [CrossRef] [PubMed]
- Sadah, S.A.; Shahbazi, M.; Wiley, M.T.; Hristidis, V. A study of the demographics of web-based health-related social media users. J. Med. Internet Res. 2015, 17, e194. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
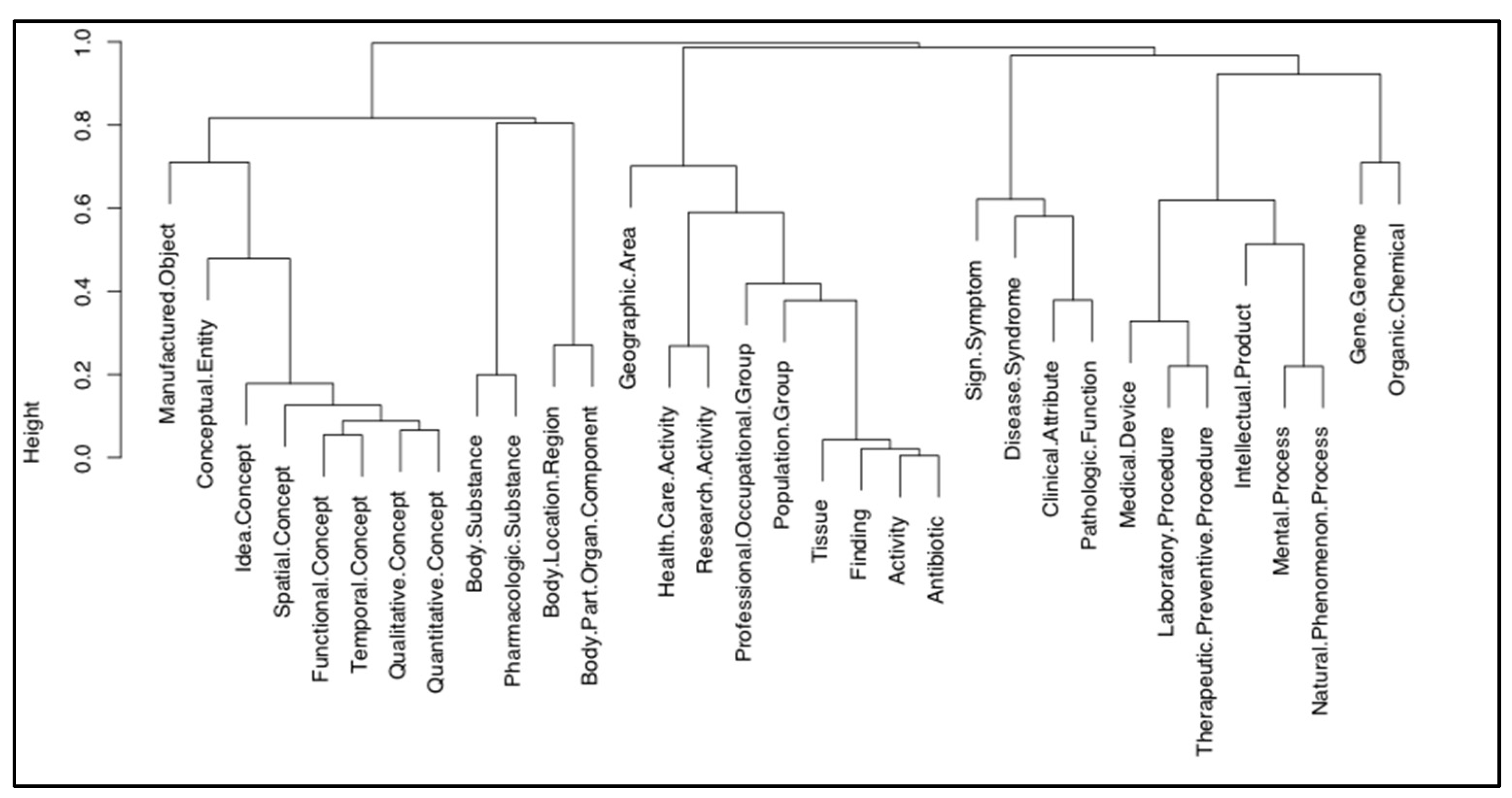{kind=link}
| Category | Includes Seed Category |
|---|---|
| 1. Asking about treatment |
|
| 2. Depressed and frustrating |
|
| 3. Lyme infection confusion |
|
| 4. Lyme symptoms confusion |
|
| 5. Awareness and encouragement |
|
| 6. Seeking general information |
|
| Classification Category | Number of Posts | Percentage |
|---|---|---|
| 1. Asking about treatment | 377 | 25.3 |
| 2. Depressed and frustrating | 118 | 7.9 |
| 3. Lyme infection confusion | 235 | 15.8 |
| 4. Lyme symptoms confusion | 317 | 21.3 |
| 5. Awareness and encouragement | 335 | 22.5 |
| 6. Seeking general information | 109 | 7.3 |
| Total | 1491 | 100 |
| Baseline | DI Features | DI + DD Features | All Features +FS | ||
|---|---|---|---|---|---|
| Multiclass LR | Overall accuracy | 0.607 | 0.638 | 0.715 | 0.732 |
| Micro-average precision | 0.607 | 0.638 | 0.715 | 0.732 | |
| Macro-average precision | 0.628 | 0.676 | 0.705 | 0.74 | |
| Micro-average recall | 0.607 | 0.638 | 0.715 | 0.732 | |
| Macro-average recall | 0.539 | 0.567 | 0.66 | 0.678 | |
| Multiclass NN | Overall accuracy | 0.55 | 0.631 | 0.721 | 0.745 |
| Micro-average precision | 0.55 | 0.631 | 0.721 | 0.745 | |
| Macro-average precision | 0.516 | 0.594 | 0.7 | 0.73 | |
| Micro-average recall | 0.55 | 0.631 | 0.721 | 0.745 | |
| Macro-average recall | 0.516 | 0.595 | 0.671 | 0.705 |
| Main Takeaway Points | Perspective | ||
|---|---|---|---|
| Medical | Patient | Organisation | |
| A method of being able to “listen to the patient” | ✓ | ||
| Could help practitioners with active learning as part of healing (constant) as the science changes (variable) | ✓ | ||
| Assists understanding of the conflict in diagnosing Lyme disease | ✓ | ✓ | ✓ |
| Supports psychiatrists in providing a direct link for interpreting thought patterns to assist in therapies such as CBT | ✓ | ||
| Plays a role in supporting experts to protect patients’ health | ✓ | ||
| Helps understand the hysteria and chaos surrounding this infection | ✓ | ✓ | |
| Enhances patient-focused communication by providing relevant and needed information | ✓ | ||
| Can be a way of reaching the right data | ✓ | ✓ | ✓ |
| Allows observation of the variations in Lyme disease symptoms people have experienced or what treatments work | ✓ | ||
| There is no value to this work | _ | _ | _ |
| Topic Name | Top 20 Words | |
|---|---|---|
| 1 | Initial symptoms after exposure | Start, day, week, month, time, ago, rash, doctor, long, back, doxy 1, bite, bit, notice, year, experience, area, recently, idea, develop |
| 2 | Online patient communication | Post, disease, find, patient, support, information, share, great, group, site, call, read, article, info, make, story, cure, issue, news, forum |
| 3 | Mental state | Feel, bad, time, thing, make, sick, good, hard, work, lot, anxiety, give, life, today, back, night, live, part, year, lose |
| 4 | Outline of the disease | Disease, tick, chronic, find, doctor, treat, year, patient, treatment, infection, illness, medicine, people, include, diagnosis, bacteria, research, health, case, dr |
| 5 | Treatment modalities | Treatment, antibiotic, good, experience, llmd 2, hear, treat, work, read, med, year, eat, people, herx 3, put, supplement, abx 4, make, continue, give |
| 6 | Symptoms | Pain, symptom, feel, body, leg, muscle, joint, head, problem, eye, severe, hand, foot, leave, normal, fatigue, arm, feeling, back, headache |
| 7 | Diagnostic testing | Test, symptom, blood, positive, result, year, doctor, negative, diagnose, show, low, high, came_back, lyme, doc, band, lab, western_blot, question, genex |
| Topics | WHO | CDC | NHS | PHE | Health Canada | |
|---|---|---|---|---|---|---|
| 1 | Initial symptoms after exposure | ✓ | ✓ | ✓ | ✓ | ✓ |
| 2 | Online patient communication | |||||
| 3 | Mental state | Post-infectious Lyme disease mentioned | ||||
| 4 | Outline of the disease | ✓ | ✓ | ✓ | ✓ | ✓ |
| 5 | Treatment modalities | ✓ | ✓ | ✓ | ✓ | ✓ |
| 6 | Symptoms | ✓ | ✓ | ✓ | ✓ | ✓ |
| 7 | Diagnostic testing | ✓ | ✓ | ✓ | ✓ | ✓ |
| A | Location | ✓ | ✓ | ✓ | ||
| B | Prevention | ✓ | ✓ | Link provided | ✓ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alnashwan, R.; O’Riordan, A.; Sorensen, H. Multiple-Perspective Data-Driven Analysis of Online Health Communities. Healthcare 2023, 11, 2723. https://doi.org/10.3390/healthcare11202723
Alnashwan R, O’Riordan A, Sorensen H. Multiple-Perspective Data-Driven Analysis of Online Health Communities. Healthcare. 2023; 11(20):2723. https://doi.org/10.3390/healthcare11202723
Chicago/Turabian StyleAlnashwan, Rana, Adrian O’Riordan, and Humphrey Sorensen. 2023. "Multiple-Perspective Data-Driven Analysis of Online Health Communities" Healthcare 11, no. 20: 2723. https://doi.org/10.3390/healthcare11202723
APA StyleAlnashwan, R., O’Riordan, A., & Sorensen, H. (2023). Multiple-Perspective Data-Driven Analysis of Online Health Communities. Healthcare, 11(20), 2723. https://doi.org/10.3390/healthcare11202723