
Identifying the High-Risk Population for COVID-19 Transmission in Hong Kong Leveraging Explainable Machine Learning

 , , ,
, , ,  and
and
Abstract
1. Introduction
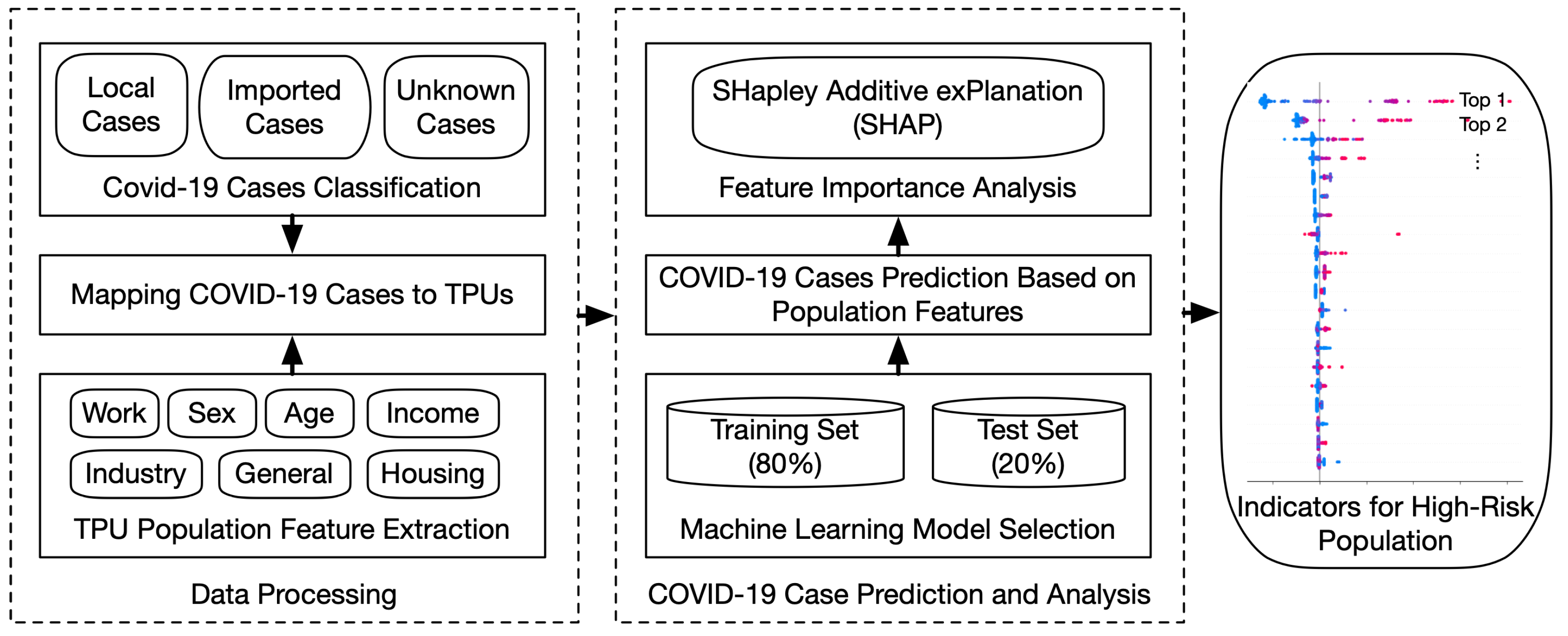
2. Materials and Methods
2.1. Dataset Description and Processing
2.2. COVID-19 Case Prediction and Feature Importance Analysis
- Linear Regression (LR) is a linear approach for modeling the relationship between features and output [24]. The objective is to minimize the residual sum of squares between the ground-truth values and the predicted values by the linear approximation. It is low-cost and easy to implement.
- K-Nearest Neighbor Regression (KN) only consider the k-nearest data samples assuming that the predicted value should be in the neighborhood. It averages the observations in the same neighborhood to model the relationship between features and output [25]. It requires few parameters, is easy to implement, and can be applied to various linear or non-linear regression tasks.
- Decision Tree (DT) is a model with a tree structure including the root node, internal nodes, leaf nodes, and branches, aiming to make a rational decision based on the features of the training set by answering all the questions on root and internal nodes [26]. The leaf nodes can be categories or real numbers, making it applicable to both classification and regression problems. Since every decision is made by all the information on each layer of the tree, it has good interpretability and is easy to understand.
- Random Forest (RF) consists of several randomly created decision trees, and the output prediction is aggregated from predictions of these decision trees, i.e., the average of outputs [27]. A random forest regression model is trained by constructing multiple decision trees with the training dataset in parallel. When testing the model, a new data point will go through all the decision trees, and the result will be the average value across all the predicted values. It can achieve high accuracy and is a robust algorithm.
- XGBoost (XGB) is eXtreme Gradient Boosting, an efficient implementation of distributed gradient boosting that can be used for building regression model [28]. It provides parallel tree boosting and has achieved outstanding performance in various domains. It stands out from other algorithms due to its high efficiency, low computational cost, good performance, and generalization [29].
3. Results
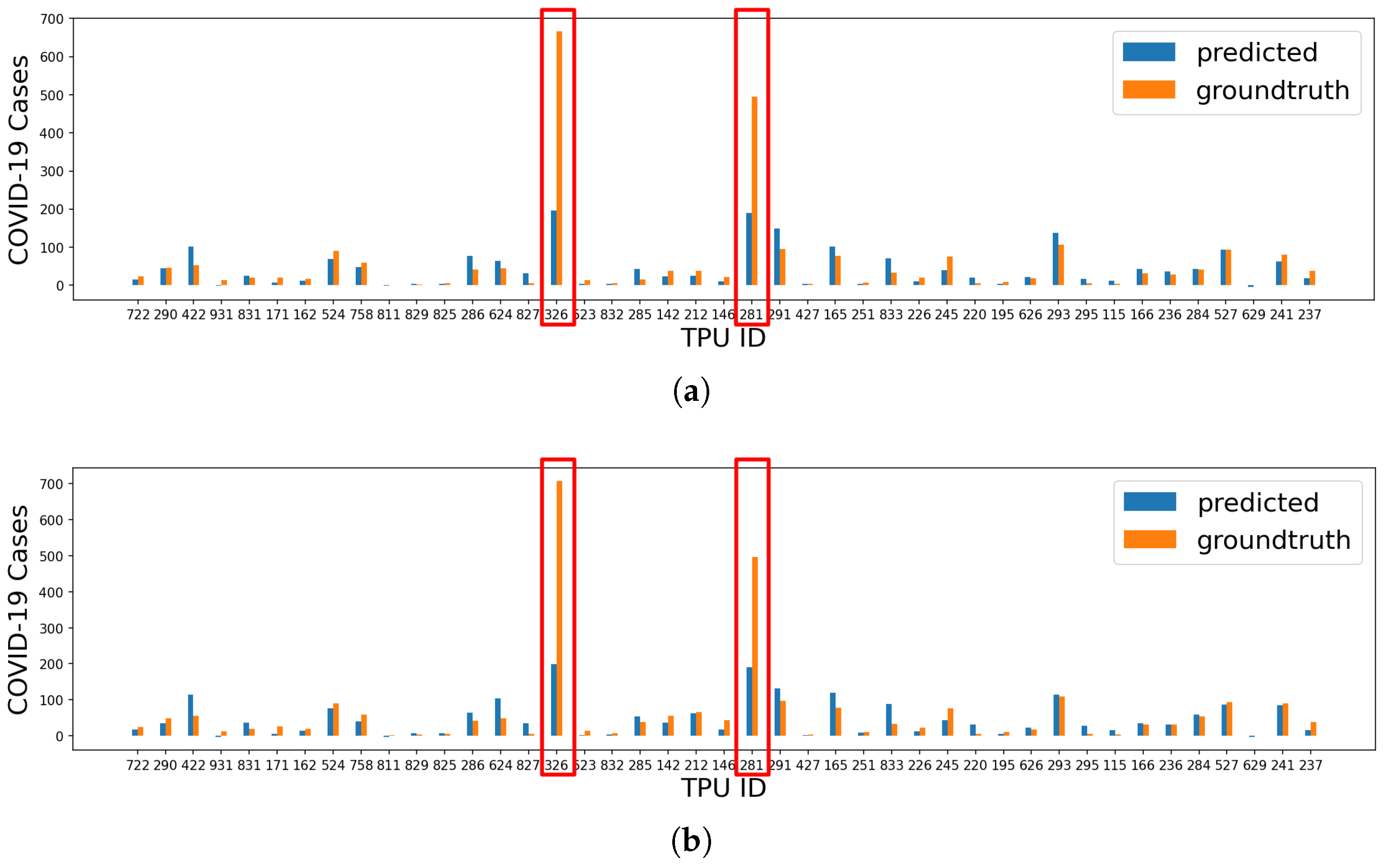
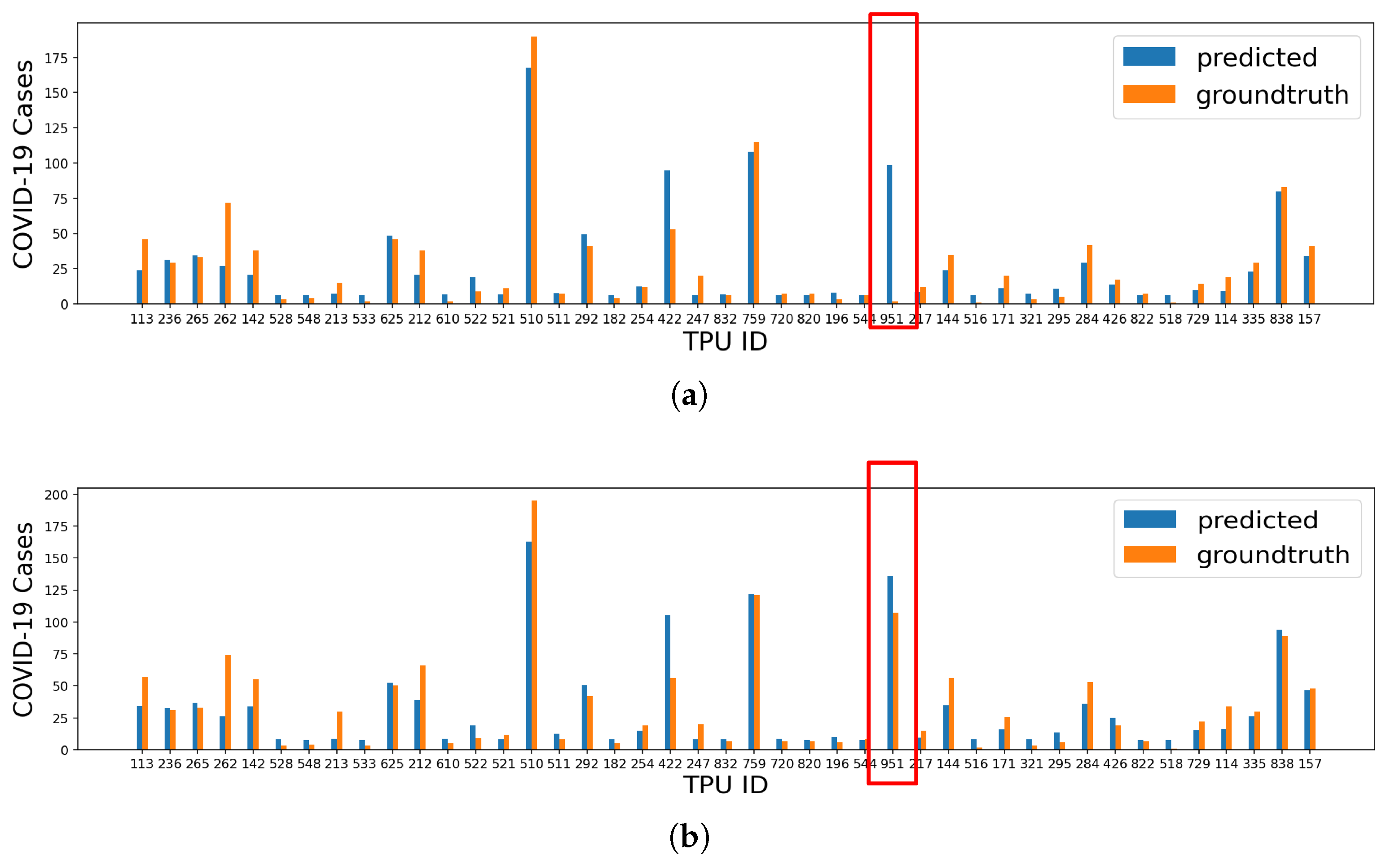
3.1. COVID-19 Case Prediction
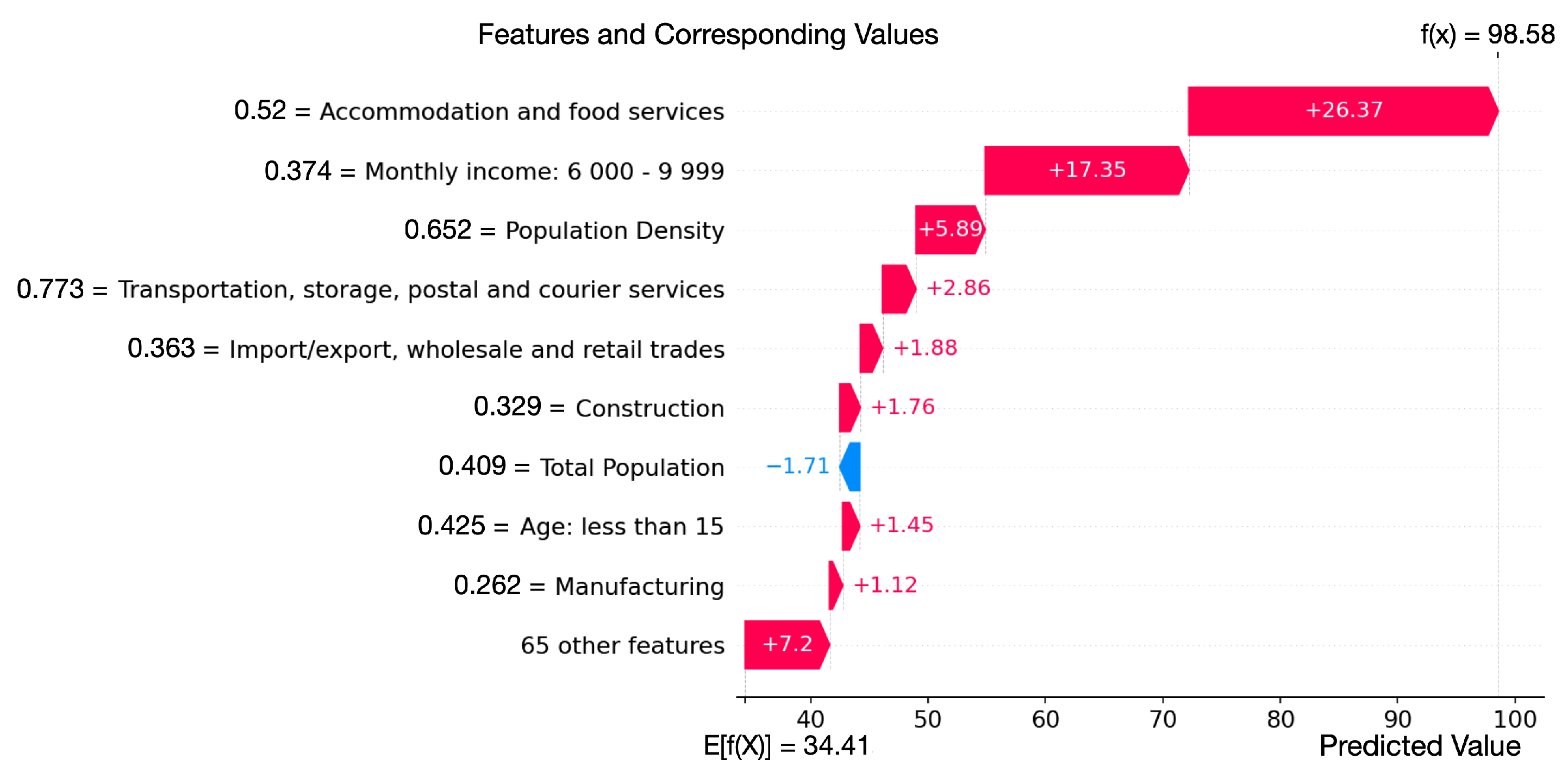
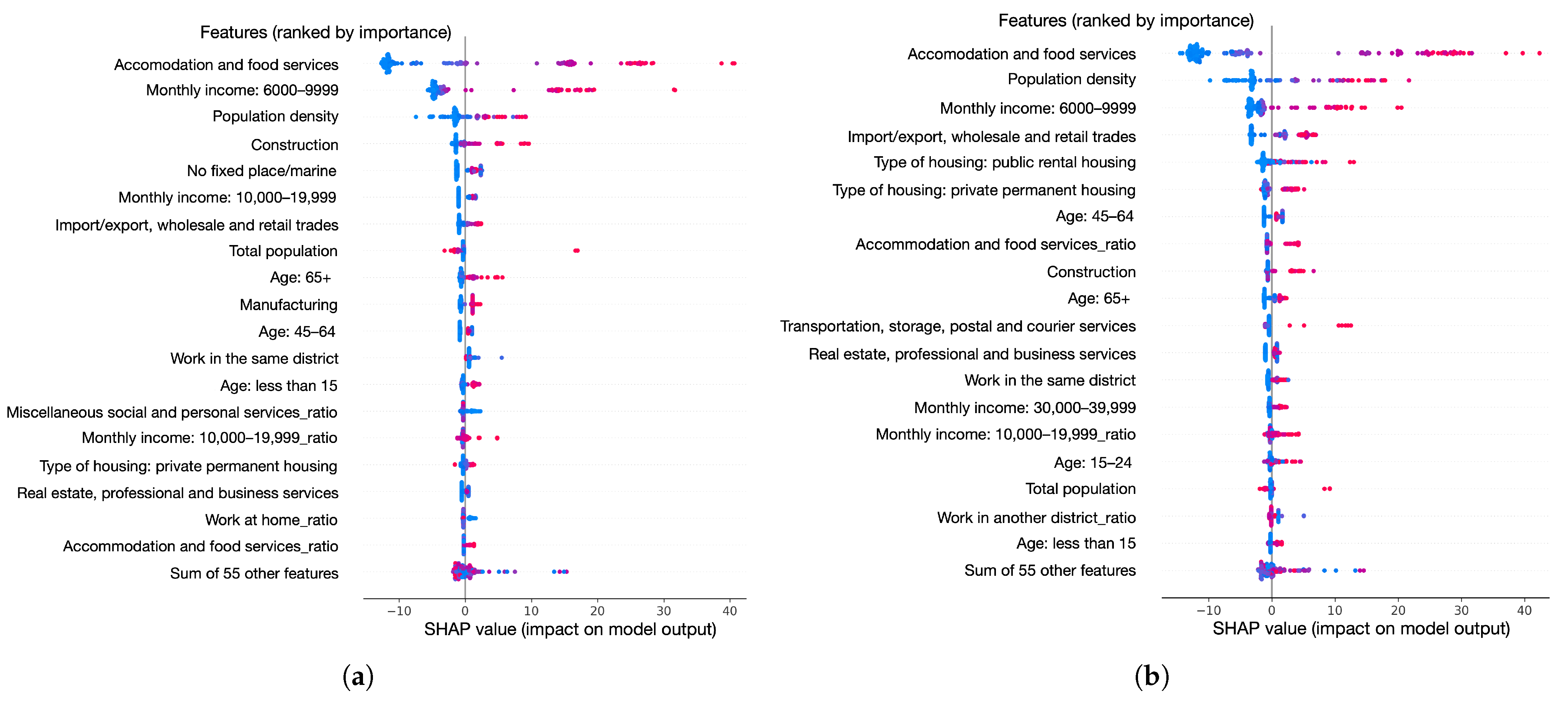
3.2. Feature Importance Analysis
4. Discussion
4.1. Implications
4.2. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| COVID-19 | Coronavirus Infectious Disease 2019 |
| TPU | Tertiary Planning Unit |
| SHAP | SHapley Additive exPlanation |
| LR | Linear Regression |
| KN | K-Nearest Neighbor Regression |
| DT | Decision Tree |
| RF | Random Forest |
| XGB | eXtreme Gradient Boosting |
References
- WHO. Statement on the Second Meeting of the International Health Regulations (2005) Emergency Committee Regarding the Outbreak of Novel Coronavirus (2019-nCoV); World Health Organization: Geneva, Switzerland, 2020. [Google Scholar]
- Burki, T. Hong Kong’s Fifth COVID-19 Wave—The Worst yet. Lancet Infect. Dis. 2022, 22, 455–456. [Google Scholar] [CrossRef]
- Miller, I.F.; Becker, A.D.; Grenfell, B.T.; Metcalf, C.J.E. Disease and Healthcare Burden of COVID-19 in the United States. Nat. Med. 2020, 26, 1212–1217. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Hu, T.; Bao, S.; Wu, H.; Peng, Z.; Wang, R. The Spatiotemporal Interaction Effect of COVID-19 Transmission in the United States. ISPRS Int. J. Geo-Inf. 2021, 10, 387. [Google Scholar] [CrossRef]
- Zhu, M.; Kleepbua, J.; Guan, Z.; Chew, S.P.; Tan, J.W.; Shen, J.; Latthitham, N.; Hu, J.; Law, J.X.; Li, L. Early Spatiotemporal Patterns and Population Characteristics of the COVID-19 Pandemic in Southeast Asia. Healthcare 2021, 9, 1220. [Google Scholar] [CrossRef]
- Kim, J.H.; Marks, F.; Clemens, J.D. Looking beyond COVID-19 Vaccine Phase 3 Trials. Nat. Med. 2021, 27, 205–211. [Google Scholar] [CrossRef]
- Bezzan, V.P.; Rocco, C.D. Predicting Special Care during the COVID-19 Pandemic: A Machine Learning Approach. Health Inf. Sci. Syst. 2021, 9, 34. [Google Scholar] [CrossRef] [PubMed]
- Assaf, D.; Gutman, Y.; Neuman, Y.; Segal, G.; Amit, S.; Gefen-Halevi, S.; Shilo, N.; Epstein, A.; Mor-Cohen, R.; Biber, A.; et al. Utilization of Machine-Learning Models to Accurately Predict the Risk for Critical COVID-19. Intern. Emerg. Med. 2020, 15, 1435–1443. [Google Scholar] [CrossRef]
- Yan, L.; Zhang, H.T.; Xiao, Y.; Wang, M.; Sun, C.; Liang, J.; Li, S.; Zhang, M.; Guo, Y.; Xiao, Y.; et al. Prediction of Survival for Severe COVID-19 Patients with Three Clinical Features: Development of A Machine Learning-Based Prognostic Model with Clinical Data in Wuhan. medRxiv 2020. [Google Scholar] [CrossRef]
- Pourhomayoun, M.; Shakibi, M. Predicting Mortality Risk in Patients with COVID-19 using Machine Learning to Help Medical Decision-Making. Smart Health 2021, 20, 100178. [Google Scholar] [CrossRef]
- Quiroz-Juárez, M.A.; Torres-Gómez, A.; Hoyo-Ulloa, I.; León-Montiel, R.d.J.; U’Ren, A.B. Identification of High-Risk COVID-19 Patients using Machine Learning. PLoS ONE 2021, 16, e0257234. [Google Scholar] [CrossRef]
- Ahmad, M.A.; Eckert, C.; Teredesai, A. Interpretable Machine Learning in Healthcare. In Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Washington, DC, USA, 29 August–1 September 2018; pp. 559–560. [Google Scholar]
- Bhatt, U.; Xiang, A.; Sharma, S.; Weller, A.; Taly, A.; Jia, Y.; Ghosh, J.; Puri, R.; Moura, J.M.; Eckersley, P. Explainable Machine Learning in Deployment. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 648–657. [Google Scholar]
- Kailkhura, B.; Gallagher, B.; Kim, S.; Hiszpanski, A.; Han, T. Reliable and Explainable Machine-Learning Methods for Accelerated Material Discovery. NPJ Comput. Mater. 2019, 5, 108. [Google Scholar] [CrossRef]
- Han, H.; Li, W.; Wang, J.; Qin, G.; Qin, X. Enhance Explainability of Manifold Learning. Neurocomputing 2022, 500, 877–895. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Parsa, A.B.; Movahedi, A.; Taghipour, H.; Derrible, S.; Mohammadian, A.K. Toward Safer Highways, Application of XGBoost and SHAP for Real-Time Accident Detection and Feature Analysis. Accid. Anal. Prev. 2020, 136, 105405. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Zheng, K.; Yang, Y.; Wang, X. An Explainable Machine Learning Framework for Intrusion Detection Systems. IEEE Access 2020, 8, 73127–73141. [Google Scholar] [CrossRef]
- Ng, Y.L.; Lo, M.C.; Lee, K.H.; Xie, X.; Kwong, T.N.; Ip, M.; Zhang, L.; Yu, J.; Sung, J.J.; Wu, W.K.; et al. Development of an Open-Access and Explainable Machine Learning Prediction System to Assess the Mortality and Recurrence Risk Factors of Clostridioides Difficile Infection Patients. Adv. Intell. Syst. 2021, 3, 2000188. [Google Scholar] [CrossRef]
- Mangalathu, S.; Hwang, S.H.; Jeon, J.S. Failure Mode and Effects Analysis of RC Members based on Machine-Learning-Based SHapley Additive exPlanations (SHAP) Approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- Yang, H.; Li, E.; Cai, Y.F.; Li, J.; Yuan, G.X. The Extraction of Early Warning Features for Predicting Financial Distress based on XGBoost Model and SHAP Framework. Int. J. Financ. Eng. 2021, 8, 2141004. [Google Scholar] [CrossRef]
- The Government of the Hong Kong Special Administrative Region, the Department of Census and Statistics. District Profiles. Available online: https://www.bycensus2016.gov.hk/en/bc-dp-tpu.html (accessed on 18 June 2022).
- The Government of the Hong Kong Special Administrative Region, the Department of Health. Together, We Fight the Virus! Available online: https://www.coronavirus.gov.hk/chi/index.html (accessed on 18 June 2022).
- Seber, G.A.; Lee, A.J. Linear Regression Analysis; John Wiley & Sons: New York, NY, USA, 2012. [Google Scholar]
- Maltamo, M.; Kangas, A. Methods based on K-Nearest Neighbor Regression in the Prediction of Basal Area Diameter Distribution. Can. J. For. Res. 1998, 28, 1107–1115. [Google Scholar] [CrossRef]
- Tso, G.K.; Yau, K.K. Predicting Electricity Energy Consumption: A Comparison of Regression Analysis, Decision Tree and Neural Networks. Energy 2007, 32, 1761–1768. [Google Scholar] [CrossRef]
- Svetnik, V.; Liaw, A.; Tong, C.; Culberson, J.C.; Sheridan, R.P.; Feuston, B.P. Random Forest: A Classification and Regression Tool for Compound Classification and QSAR Modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ogunleye, A.; Wang, Q.G. XGBoost Model for Chronic Kidney Disease Diagnosis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2020, 17, 2131–2140. [Google Scholar] [CrossRef] [PubMed]
- Ayon, S.I.; Islam, M.M. Diabetes Prediction: A Deep Learning Approach. Int. J. Inf. Eng. Electron. Bus. 2019, 12, 21–27. [Google Scholar]
- Rahayu, S.; Sugiarto, T.; Ludiro, M.; Subagyo, A. Application of Principal Component Analysis (PCA) to Reduce Multicollinearity Exchange Rate Currency of Some Countries in Asia Period 2004–2014. Int. J. Educ. Methodol. 2017, 3, 75–83. [Google Scholar] [CrossRef][Green Version]
- Bi, Y.; Xiang, D.; Ge, Z.; Li, F.; Jia, C.; Song, J. An Interpretable Prediction Model for Identifying N7-Methylguanosine Sites based on XGBoost and SHAP. Mol. Ther.-Nucleic Acids 2020, 22, 362–372. [Google Scholar] [CrossRef]
- Leung, H. COVID-19: Hong Kong Civil Servants Told to Work from Home as Kwai Chung Cluster Grows to over 170 Cases. Available online: https://hongkongfp.com/2022/01/24/covid-19-hong-kong-civil-servants-told-to-work-from-home-as-kwai-chung-cluster-grows-to-over-170-cases/ (accessed on 24 June 2022).
- Siu, J.Y.m. Health Inequality Experienced by the Socially Disadvantaged Populations during the Outbreak of COVID-19 in Hong Kong: An Interaction with Social Inequality. Health Soc. Care Community 2021, 29, 1522–1529. [Google Scholar] [CrossRef]
- Ran, L.; Chen, X.; Wang, Y.; Wu, W.; Zhang, L.; Tan, X. Risk Factors of Healthcare Workers with Corona Virus Disease 2019: A Retrospective Cohort Study in a Designated Hospital of Wuhan in China. Clin. Infect. Dis. 2020, 71, 2218–2221. [Google Scholar] [CrossRef]
- Baker, M.G.; Peckham, T.K.; Seixas, N.S. Estimating the Burden of United States Workers Exposed to Infection or Disease: A Key Factor in Containing Risk of COVID-19 Infection. PLoS ONE 2020, 15, e0232452. [Google Scholar] [CrossRef]
- International Labour Organization. COVID-19 and Accommodation and Food Service Activities Prevention and Control Checklist. Available online: https://www.ilo.org/sector/Resources/publications/WCMS_754201/lang-en/index.htm (accessed on 29 June 2022).
- World Health Organization COVID-19 and Food Safety: Guidance for Food Businesses: Interim Guidance, 07 April 2020; Technical Report; World Health Organization: Geneva, Switzerland, 2020.
- Zhang, A.; Shi, W.; Tong, C.; Zhu, X.; Liu, Y.; Liu, Z.; Yao, Y.; Shi, Z. The Fine-Scale Associations between Socioeconomic Status, Density, Functionality, and Spread of COVID-19 within a High-Density City. BMC Infect. Dis. 2022, 22, 274. [Google Scholar] [CrossRef]
- Mena, G.E.; Martinez, P.P.; Mahmud, A.S.; Marquet, P.A.; Buckee, C.O.; Santillana, M. Socioeconomic Status Determines COVID-19 Incidence and Related Mortality in Santiago, Chile. Science 2021, 372, eabg5298. [Google Scholar] [CrossRef]
- Hawkins, R.B.; Charles, E.J.; Mehaffey, J.H. Socio-Economic Status and COVID-19-Related Cases and Fatalities. Public Health 2020, 189, 129–134. [Google Scholar] [CrossRef] [PubMed]
- The Government of the Hong Kong Special Administrative Region. Hong Kong Vaccination Dashboard. Available online: https://www.covidvaccine.gov.hk/en/dashboard/eHealth (accessed on 22 June 2022).
- Low, Z.; Cheung, E.; Yau, C. Hong Kong’s Construction Sites Could Be Covid-19 Transmission Hotspots, Experts Say, but Blanket Work Stoppages are Unlikely to Help. Available online: https://www.scmp.com/news/hong-kong/health-environment/article/3113264/hong-kongs-construction-sites-could-be-covid-19 (accessed on 22 June 2022).
- Li, Y.; Yang, L.; Yang, B.; Wang, N.; Wu, T. Application of Interpretable Machine Learning Models for the Intelligent Decision. Neurocomputing 2019, 333, 273–283. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Features | Features |
|---|---|
| General Information | Total population |
| Population density | |
| Household per Room (excluding kitchens and toilets/bathrooms) | |
| Population by Sex | Male |
| Female | |
| Population by Age | <15 |
| [15, 24] | |
| [25, 44] | |
| [45, 64] | |
| ≥65 | |
| Population by Type of Housing | Public rental housing |
| Subsidised homeownership housing | |
| Private permanent housing | |
| Non-domestic housing | |
| Temporary housing | |
| Population by Monthly Income | <6000 |
| from Main Employment | [6000, 9999] |
| (excluding unpaid family workers, in HKD) | [10,000, 19,999] |
| [20,000, 29,999] | |
| [30,000, 39,999] | |
| [40,000, 59,999] | |
| ≥60,000 | |
| Population by Place of Work | Work in the same district in Hong Kong |
| Work in another district in Hong Kong | |
| No fixed place/marine | |
| Work from home | |
| Places outside Hong Kong | |
| Population by Industry | Manufacturing |
| Construction | |
| Import/export, wholesale and retail trades | |
| Transportation, storage, postal, and courier services | |
| Accommodation and food services | |
| Information and communications | |
| Financing and insurance | |
| Real estate, professional, and business services | |
| Public administration, education, human health, and social work activities | |
| Miscellaneous social and personal services | |
| Others |
| Results | LR | KN | DT | RF | XGB |
|---|---|---|---|---|---|
| 0.421 | 0.343 | 0.491 | 0.398 | 0.470 | |
| 0.429 | 0.333 | 0.445 | 0.383 | 0.444 | |
| 0.047 | 0.615 | 0.687 | 0.631 | 0.695 | |
| 0.394 | 0.801 | 0.248 | 0.812 | 0.830 | |
| 0.464 | 0.347 | 0.512 | 0.416 | 0.428 | |
| 0.471 | 0.357 | 0.382 | 0.390 | 0.440 | |
| 0.364 | 0.641 | 0.456 | 0.624 | 0.698 | |
| 0.688 | 0.811 | 0.321 | 0.812 | 0.838 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Z.; Yip, K.-M.; Zhang, X.; Deng, J.; Wong, W.; So, H.-K.; Ngai, E.C.H. Identifying the High-Risk Population for COVID-19 Transmission in Hong Kong Leveraging Explainable Machine Learning. Healthcare 2022, 10, 1624. https://doi.org/10.3390/healthcare10091624
Jiang Z, Yip K-M, Zhang X, Deng J, Wong W, So H-K, Ngai ECH. Identifying the High-Risk Population for COVID-19 Transmission in Hong Kong Leveraging Explainable Machine Learning. Healthcare. 2022; 10(9):1624. https://doi.org/10.3390/healthcare10091624
Chicago/Turabian StyleJiang, Zhihan, Ka-Man Yip, Xinchen Zhang, Jing Deng, Wilfred Wong, Hung-Kwan So, and Edith C. H. Ngai. 2022. "Identifying the High-Risk Population for COVID-19 Transmission in Hong Kong Leveraging Explainable Machine Learning" Healthcare 10, no. 9: 1624. https://doi.org/10.3390/healthcare10091624
APA StyleJiang, Z., Yip, K.-M., Zhang, X., Deng, J., Wong, W., So, H.-K., & Ngai, E. C. H. (2022). Identifying the High-Risk Population for COVID-19 Transmission in Hong Kong Leveraging Explainable Machine Learning. Healthcare, 10(9), 1624. https://doi.org/10.3390/healthcare10091624